判断的逆转
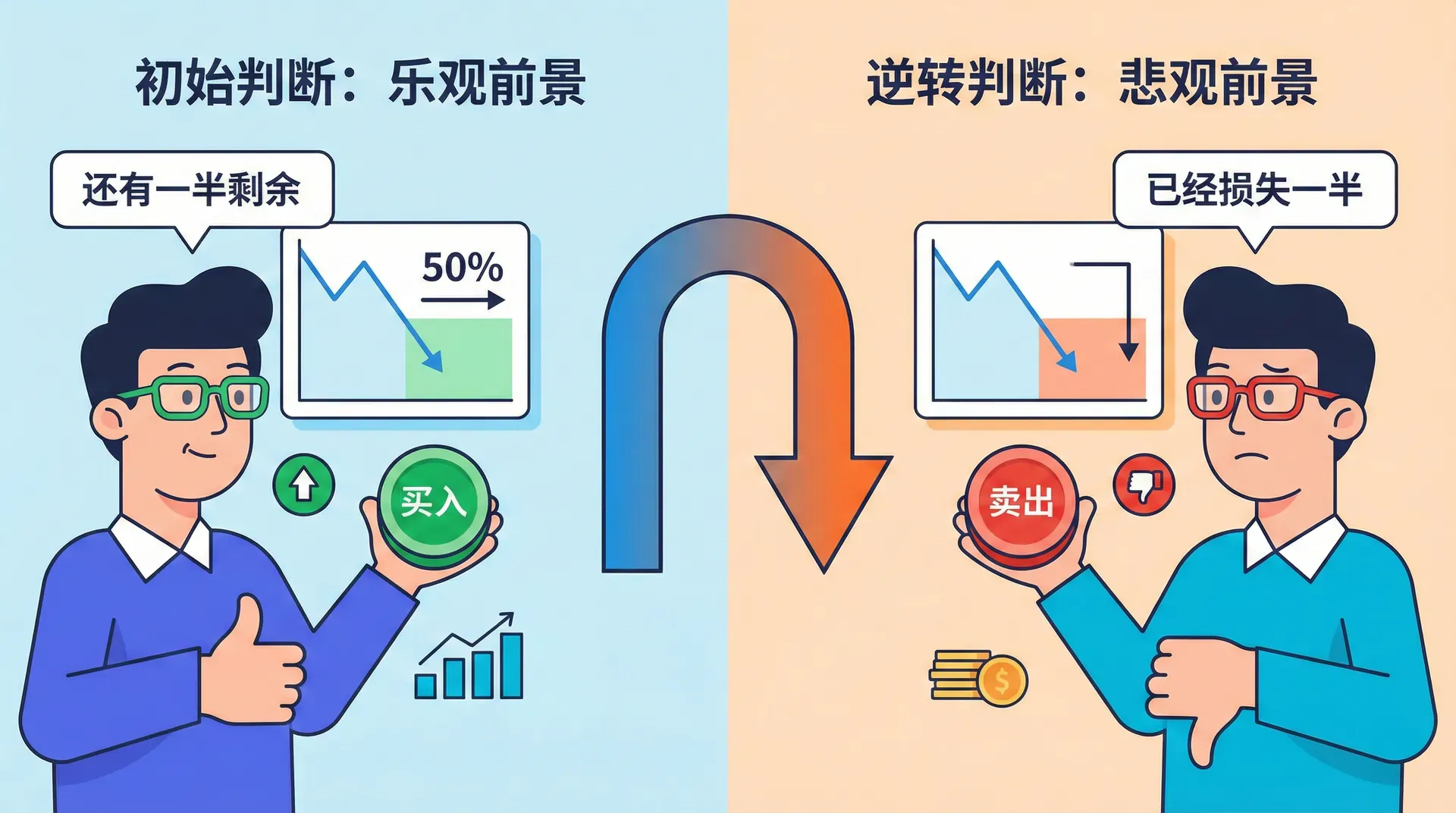
在我们的日常生活和工作中,你是否注意到:一些看似简单的决定,换个场景或者描述方式,自己的答案却往往大相径庭?比如,面对同一个选择题,在独自思考和和朋友讨论时,你可能会做出不同的决策。这种现象并非偶然,它在心理学里被称为“判断逆转”。
这种逆转意味着,我们的判断和选择极易受情境、问题表达方式,甚至当下感受的影响,从而出现自相矛盾或前后不一的结果。心理研究表明,这类判断逆转是人类思维中普遍存在的一种偏误,揭示了即使我们自认为理智客观,实际决策过程也远比我们想象的更容易左右摇摆。
补偿案例中的情感偏差
设想一下:你是中国某地法院的一名法官,需要为暴力犯罪受害者裁定合理的赔偿金额。现在有这样一起案件:
一名男子在小区附近的便利店遭遇抢劫,被砍伤左手致残,部分失去了生活自理能力。案发前,他日常大多数时间都会去A便利店购物,但因为A店临时装修,当天他只能前往B便利店,意外就在这里发生了。
现在分两种情况考虑:
多数人在同时看到这两种情形时会觉得:赔偿金额理应一致。毕竟受害人受到的伤害和损失是相同的,去哪个便利店看上去不应影响结果。
但实际心理学实验发现,当上述两种情况分别、单独地呈现给不同人的时候,人们对“情况二”往往会判更高的赔偿。因为“如果那天便利店没装修,他本该不会受伤”的反事实思维,让人们涌现痛惜与遗憾,进而倾向于“补偿”更多。
情感强度对判断的影响
这种现象正是“痛惜感”影响判断的典型例子。类似情况在生活中也常见,例如:2022年江西某地突发洪灾,当对比不同家庭受灾情形时,人们对“本想去外地避险,但因交通管制被困而受灾”的家庭往往表达更多同情,甚至主张应补发更多救助金。
下表可以直观展示这种情感偏差:
这就是系统1(快速、情绪化思维)的作用:直接用内心的感受强度(如惋惜、同情)替代复杂的价值评估,通过“强度匹配”把心理感受换算为实际数额。
而在生活的很多领域,这种“单独评估”——例如只从一个维度考虑问题、缺少横向对比——极易放大情感偏差。比如,单独听说“上海小区封控14天”会觉得很严厉,但当对比武汉2个月封城或海外几乎无管控时,判断标准立刻改变。同理,一件衣服在高端商场觉得划算,在地摊却可能被评价为贵。
偏好逆转的现实案例
在20世纪70年代,美国心理学家首次发现了著名“偏好逆转”现象。其实,这一现象在中国的行为决策实验中同样普遍,只不过题材略有不同。请看以下现实案例:
购房选择与定价的悖论
假如你北京想购房,有两套房子可供选择:
- 方案A:离地铁站200米,50㎡,总价380万。
- 方案B:离地铁站1000米,70㎡,总价410万。
你会选哪个?绝大多数人选方案A。毕竟位置更好,“地铁房”上班方便。
但是,若让同样一批人“假设你已拥有这些房子,愿意以多少钱出售?”——结果却大多给方案B标更高的价格,因为面积更大、总价更高。
下方对照了选择任务与定价任务中的偏好分布:
这就是经典的“偏好逆转”现象:在选择时偏爱A,在定价时认为B更值钱。即便是同一个人、面对同样的两套房,也会给出前后矛盾的答案。
锚定效应与信息突显
为何选择与定价会产生如此大的反差?关键在于定价任务时,人们容易被某一显眼特征(如70㎡的“面积”或“总价”)作为锚点,影响价值判断。而在实际选房时,通勤便利(位置)成为主导标准,导致决策标准转变。
这种“锚定效应”(anchoring)广泛存在于中国实际生活中,比如二手车售价、房租议价、甚至电商大促的“原价划线”——一个高锚点很容易让人对产品、服务的实际价值产生偏差认知。
对传统理论的挑战
“偏好逆转”挑战了经济学里对人的理性假设:如果一个人认为B比A更值钱,那他在真正要买的时候也应该选B。但现实是——选房时重视地铁,给房定价时觉得面积=更值钱。
中国多项消费者调研和司法裁判案例也屡屡出现“场景不同,态度截然相反”,比如对于同一品牌手机:
现实中,我们的许多决策都混杂了主观情感与局部理性,评估方式的微小变化就能带来认知上的“大逆转”。
这些心理实验提示我们,在中国社会的实际判案、消费乃至投资选择中,唯有充分理解“判断逆转”与情境对决策的影响,才能设计出更公平公正的制度与流程。
分类思维的局限性
我们的大脑天生会按照类别对外部信息进行整理。 “分类思维”不仅有助于快速理解世界,也让我们在日常决策中少走弯路,但有时却会让我们的判断产生偏差甚至冲突。
身高比较的启示
假设你在小学和高中分别问学生:“王伟,身高150厘米,算高吗?”小学生会说很高,因为他们参照的是同龄同学;但在高中,150厘米大概率属于偏矮。你的直觉评价其实受限于比较的那个范畴。
来看实际案例:
但如果你直接问:“这两个王伟一样高吗?”大家都会回答“是”。这类悖论在生活中其实非常常见:信息在各自的参照体系下评估不会有问题,但一旦跨范畴,判断标准即刻混乱。
跨类别比较的困境
想象下面的情境——
- 你更喜欢西瓜还是葡萄?
- 你更喜欢火锅还是干锅?
- 你更喜欢西瓜还是火锅?
前两个问题因属于同一食物类别,判断起来很顺畅。可当你需要在西瓜和火锅之间做选择时,难度大幅提升,因为评价标准不一致。这就是分类思维为生活带来便利,也带来限制的直观例子。
同一大类里的选择,我们的评判标准一致;跨类别比较,容易出现评估混乱或偏好逆转。
慈善捐赠:儿童与国宝动物的抉择
在现实生活中,类似的选择困境常见于慈善捐赠。看一组中国例子:
选项一:大熊猫繁育保护基金
“我国大熊猫受栖息地破坏影响,种群数量徘徊不前,急需资金进行保护。”
选项二:困境儿童关爱基金
“许多偏远山区的儿童陷于贫困,急需资金改善生活与教育条件。”
如果分别宣传,上百名中国公众在捐赠时往往会倾向于为大熊猫捐更多钱——因为大熊猫在所有动物里有最高的情感召唤力。但当两个选项同时出现,并强调“都是宝贵的生命”时,大多数人会选择给孩子们更多帮助。
以实验结果表格展示(单位:元):
单独评估时,大熊猫因“萌”获得更高捐赠;联合评估下,“对人类儿童的关怀”成了决定性因素,大熊猫反而处于劣势。
可评估性假说
芝加哥大学的谢教授提出“可评估性假说”,意思是某一属性只有在对比中才显现其重要性。
举例说明:
- 一本2020年出版、无任何翻页折痕、但只有300页的教材。
- 一本同出版社、2019年出版、500页,但封面有折印的教材。
单独评估时,大家可能更愿意为“99新”的那本(虽然薄)支付高价,因为“新”属性很直观。
联合展示时,500页的厚书价值显然更高,买家会忽略那点表面瑕疵。
在手机、家电等消费者决策中同样常见——一款手机单独看,漂亮外观吸引人;一旦多台手机横向对比,“内存、性能参数”跃升为主导决策的因素。
总结
判断逆转现象揭示了人类认知的一个基本特征:我们的判断和偏好高度依赖于具体情境和呈现方式。这种依赖性不是人类思维的缺陷,恰恰是我们适应复杂世界、在有限认知资源下快速作出决策的演化结果。然而,这种灵活性在面对需要“一致性”“可比性”或“公平正义”的社会制度和规则设计时,有时会引发预料之外的后果,比如同一个人对同一问题在不同环境下会给出截然不同的选择。
因此,理解并正视这些认知偏差,并不是为了批判人性或追求完美理性,而是希望以此为基础,设计出更合乎人性的制度。无论是在经济决策、道德判断还是司法实践中,我们都应创造条件——例如清晰的比较标准、多元的评估视角、冲突情况下的外部约束——帮助人们作出更全面、更一致的判断,从而减少误判或偏见的发生。
只有当我们真正理解了人类判断的局限性和其产生的心理机制,才能在现实制度设计中兼顾“人性”与“公正”,建立起既适应复杂社会、又能最大程度减少认知误区的科学评价体系。