效用理论

在维多利亚时代,哲学家和经济学家普遍将“效用”视为衡量个人整体福利的标准。效用被定义为个人幸福感的一种数量化表达。按照这一思路,人们通常假定消费者会选择能使自身效用达到最大化的方案,也就是让自己尽量满意。
但问题在于,这些古典经济学家其实并未真正说明如何具体衡量效用。我们如何才能给不同选择关联的效用分配一个明确的“数值”?一个人的效用能否与他人的直接比较?比如,如果我说喝一杯咖啡所带来的效用是读一本小说带来的效用的三倍,这到底意味着什么?除了作为人们追求最大化的“目标”之外,效用是不是还有其他独立的意义?
出于这些理论概念上的难题,经济学家逐渐放弃了把效用直接作为幸福感度量的传统观点。相反,现代消费者行为理论已经完全以消费者偏好为基础进行表述,效用仅仅被视为描述偏好关系的一种工具。
理论范式的转变
经济学家逐渐认识到,从选择行为的角度来看,效用真正起作用的地方仅在于它对消费束进行排序:对于任意两种消费束A和B,如果A相较于B的效用更高(即),那么消费者就会选择A而非B。至于A比B高出多少效用,这个数值差异本身并没有直接的经济含义。换句话说,效用的绝对数值和差值并不重要,重要的是效用在消费束之间的比较顺序。
在传统观点下,经济学家认为“效用”可以量化幸福感或满足感,偏好基于效用的大小来定义。例如,若表示消费束的效用,表示另一消费束的效用,那么
即如果一个消费束的效用数字更高,被认为偏好程度也更高。
然而,现代观点发生了根本转变:经济学家更强调偏好(preference)本身才是选择行为的基础性描述,而效用(utility)只是形式化表达偏好排序的一种“工具”或“编码方式”。我们可以反过来说:偏好关系的存在赋予了效用函数的定义——效用函数的主要任务就是为消费束排序,使得:
- 如果消费者偏好A大于B,则;
- 如果消费者对A和B无所谓,则。
总结来说,现代效用理论强调“效用函数仅需保持偏好排序一致”,而不是衡量幸福或满足的绝对数量。数量本身没有独立意义,只有顺序有意义。
效用函数的现代定义
效用函数的概念
效用函数(utility function)是用来刻画消费者偏好的一种数学工具。它的核心功能是:为每一种可能的消费束分配一个数字(即效用值),使得消费者更偏好的消费束拥有更高的效用值,而相对不偏好的消费束效用值较低。换句话说,效用函数提供了一种通过数字表示、比较消费方案优劣顺序的方法。效用函数的形式并不唯一,关键在于分配的数值能正确反映出消费束间的偏好排序,而非其具体的数值大小。
正式定义: 若消费束 被消费者视为优于 ,则效用函数需满足: 这一定义意味着,对一组给定的偏好关系,总可以找到一种方式(即某个效用函数)用数值把这些偏好顺序“编码”下来。
假如A、B、C为三种不同消费选择,一个可能的效用排序是 ,,,则表示A优于B优于C。事实上,体现这种顺序即可,不需要固定的数值。如果把效用全部加100、乘3或取对数,只要顺序不变,还是同样的合理效用函数。
序数效用的本质
在现代效用理论中,效用函数主要用于描述和反映消费束之间的相对偏好顺序(排序),而不是测量某种绝对的“满足”或“幸福感”。这意味着效用值的绝对大小和消费束之间效用差值并无经济学上的实质意义;关键只在于对于任意两组消费束,哪一组被偏好——用更大的数字表示即可。
因此,这种只关心消费束排序、不关心数值大小和间隔的效用被称为序数效用(ordinal utility)。
如上表,即使三种效用函数形式完全不同(甚至有负数或极小小数),只要它们分配给A的数大于B,B又大于C,就都能有效地表示相同的消费偏好关系。
为什么“序数”重要?
这意味着我们无法、也不需要说“A比B好多少”有多大意义,只需知道A“比”B好即可。例如,即使 ,,这些差距本身不代表任何消费直观。经济学只关注偏好的顺序,不关注其“距离”。
实际上,只要能将原始效用函数做任何保持递增次序的单调变换(例如、、(当时)),就能得到另外一个完全等价的效用函数。偏好关系不会因这些变换而受影响。
既然只有排序有意义,为消费束分配效用的方式就并不唯一。任何严格递增的函数变换都得出同样的偏好排序。效用理论的核心在于用数学方法刻画有序的“喜欢”与“不喜欢”,而非量化幸福或满足的绝对程度。
单调变换
单调变换的定义
在现代效用理论中,单调变换 是一个核心概念。设是某一种消费束的效用分配方法,如果我们用乘以2、加7、取对数、甚至取三次方——只要所用函数本身是严格递增函数——我们就得到另一个同样合理的效用分配方法。这种将所有效用数字用“顺序保持”的方式替换的过程,就称为单调变换。它的数学本质是:
数学定义:
设为一个严格单调递增的函数,则对于任意两个消费束,如果,那么。换句话说,偏好顺序的传递性与一致性完全保留。
通俗理解:
单调变换相当于把试卷分数“重新打分”,但排行榜名次始终不会变化。例如把所有人的分数都乘以2,第一名依然是第一名,最后一名还是最后一名。正因为效用只用于排序,“100分”和“200分”之间的差距在经济学里没有真实含义,只有高低先后有经济学意义。
单调变换的例子
常见的单调变换有:
- 线性变换:
- 平移:
- 幂函数(奇次/正幂):,只要并且保持严格递增
实际上,只要是严格递增的连续函数,都可以作为效用的单调变换,意味着你可以用无穷多种方式给相同偏好分配数字,只要保证排序不变。
- 反例:,并不是单调递增,因此会把原来高的效用变成低的,排序被颠倒,这就不能算作有效的单调变换。
- 在应用中,两种形状看似不同、数字范围完全不同的效用函数(如和),只要它们的偏好排序一致,作为消费选择的描述,它们是完全等价的。
单调变换的重要性质与意义
核心定理:
如果能正确表示某种偏好关系,那么任何严格递增函数下的新效用,也能且只会表示相同的偏好排序。
证明流程为:
经济学直观:
- 单调变换后的效用函数就像给每条无差异曲线贴不同的标签,曲线本身及其经济含义没有任何变化,只是名字和数字换了而已。
- 在任何决策、福利、选择行为、最优分配的理论分析中,单调变换并不会改变人的选择预测、无差异曲线的形状,更不会影响实际政策比较结论。
- 人们真正关心的,是“你更喜欢A还是B”,至于“喜欢A比B多123还是多456分”,这完全随意。
在效用理论的几何表述下,效用函数实际上就是用数字“标号”平面上的无差异曲线。无差异曲线本身代表相同效用水平的集合,无论你给曲线分配什么具体数字,只要高的永远比低的“大”,这种标号是可以自由变换的。单调变换正体现了这种数字标号的自由,因此“效用数字的具体大小”永远没有独立经济含义。
基数效用与序数效用
基数效用理论
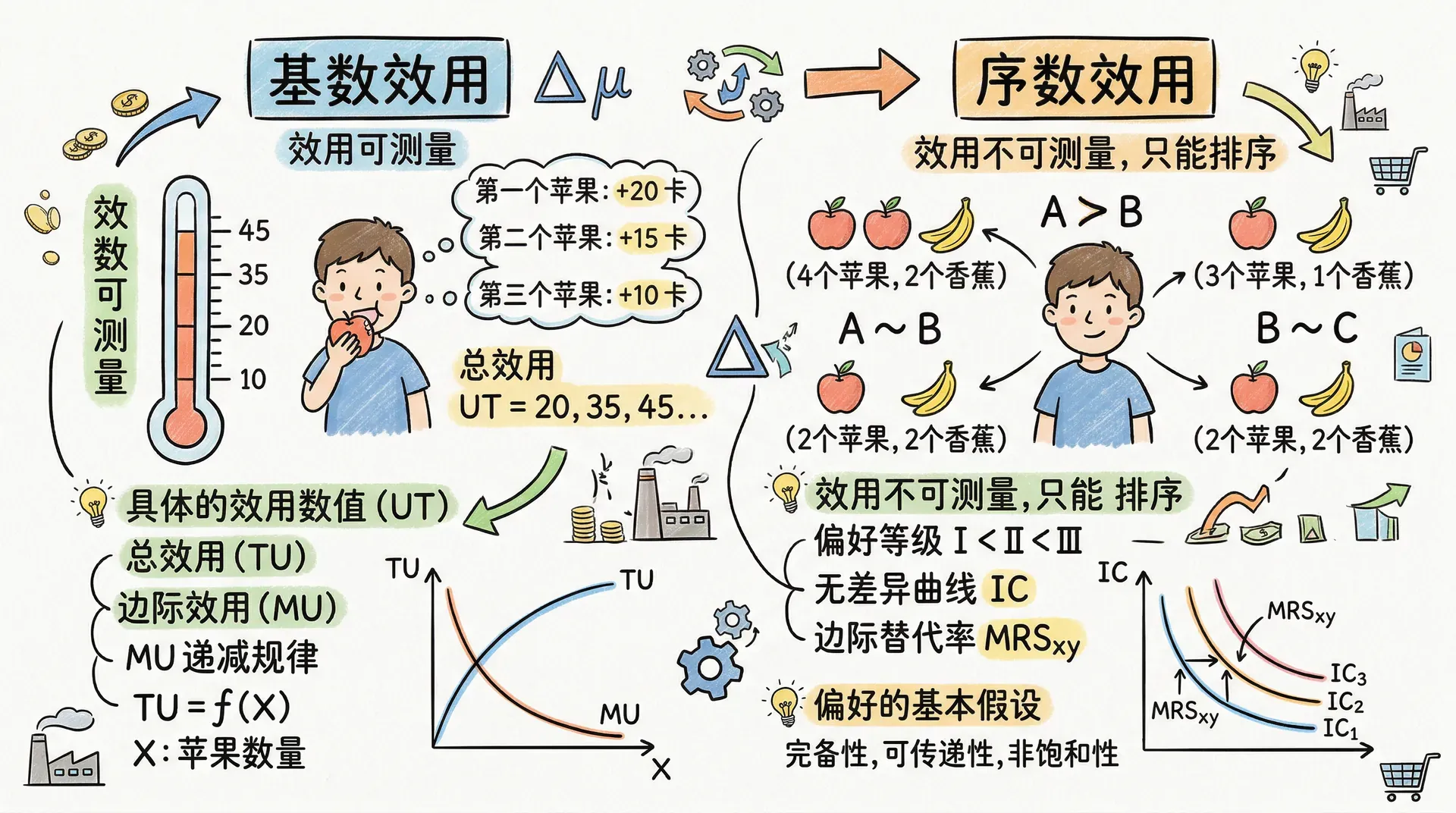
在经济学中,效用理论是刻画消费者偏好和行为基础的核心工具。大体而言,效用可分为基数效用理论(cardinal utility)和序数效用理论(ordinal utility)两种思想体系。
基数效用理论认为,效用的数值大小有实际意义。例如,若某人分配给商品束A的效用为20,商品束B为10,那么不仅有,而且效用差为10,甚至可以讨论“喜欢A是B的2倍”这样更强的断言。基数效用理论常见于早期边际效用学派和部分行为经济学分析,比如描述风险和不确定性的冯-诺伊曼-摩根斯坦公理体系。
但实际操作中,我们面临着“效用基数化”的根本难题——到底怎样才算“喜欢两倍”?
“喜欢两倍”如何定义?
设想你能判断自己更喜欢苹果还是橘子,但你能量化出“喜欢苹果是橘子的几倍”吗?这种数量上的倍数,往往很难科学赋值。常见的尝试包括:
除此之外,心理学实验有时尝试用主观自评打分量表,但这类主观赋值的尺度本身随问卷、环境、心情等可变性巨大,并无一致标准。因此,基数效用虽然有理论魅力,但在现实中因为难以找到可重复、可靠的量度依据而难以施行。
值得一提的是,在存在“概率选择”、“风险”和“期望效用”问题时,基数效用的某些刻画变得更为有用。例如,冯-诺伊曼与摩根斯坦证明了:如果一个人的选择满足一组公理化的概率偏好,那么一定可以用一个线性变换下不变的效用函数表达其风险选择。在现实中,这通常体现为在风险决策、保险、赌博等领域,效用大小(至少是线性变换下的区间尺度)有更实质性含义。但这些领域对效用的尺度要求严格受限,仅部分满足“基数化”直觉。
为什么选择序数效用
面对基数赋值的困难,大多数日常消费与偏好分析采用序数效用理论。序数效用只关心排序:哪个商品束更受偏好,不关心偏好“强度有多少”或“倍数关系”。
简单来说,序数效用认为:只要商品束A的效用高于B,就代表A更受偏好,至于高出多少对解释和预测选择行为并没有作用。无差异曲线理论、消费选择理论等都建立于这种“只需排序、不必定量”的基础之上。
对于绝大多数经济行为,只需识别“更喜欢哪个”,而无需量化“喜欢多少”。我们能通过选择实验判断偏好,但几乎没有科学、一致的方法衡量偏好强度或倍数关系。因此,序数效用更切合实际,同时具备更强的理论普适性和稳健性。基于这一理由,主流理论和政策分析通常采用纯粹的序数效用框架。
- 基数效用可以加减/线性变换(如等价于温度的“摄氏度”刻度),但常常难以赋值实现,仅在特定公理体系下(如风险选择中的预期效用理论)可行。
- 序数效用仅需排序,无需单位与间距的含义,就如名次排名,适用性更广,贴合实际观测。
最终,尽管基数效用理论在某些领域有特定意义,经济学主流仍以序数效用为分析基础。效用具体数值的大小以及两个效用之差的幅度,并非描述选择的必要工具。我们更关心人的排序和无差异曲线的形状,而这些,序数效用完全可以满足。
效用函数的构造
存在性问题
在实际经济学建模中,我们通常假设能够找到效用函数“代表”个体的偏好,即同样的商品束排序方式会对应其效用数值上的排序。那么,这样的效用函数究竟在多大范围内存在?有什么样的数学保证?
不可表示的偏好:
首先需要明确,并非任意一种偏好关系都可由效用函数来表征。最著名的例子就是非传递性偏好:比如有的人偏好A于B、B于C,却又偏好C于A(即A ≻ B ≻ C ≻ A)。如果这样,我们很难找到一个分配给A、B、C的效用数,使得u(A) > u(B) > u(C) > u(A),因为这会导致数学上的不可能(数轴不闭环)。
偏好的性质与效用的存在:
那怎样的偏好才能被效用函数“刻画”呢?一般来说,只要满足下列“合理”条件的偏好(通常称为理性偏好),常常都可被效用函数所表示:
- 完全性(Completeness):任意两种商品束和,个体都能比较——要么,要么。
- 传递性(Transitivity):如果且,则必有。这就是避免“绕圈排列”的关键。
在二维甚至更高维度的商品空间下,上述条件往往就足够保证效用存在性定理(Utility Existence Theorem)。也就是说,使得对于所有满足这些条件的偏好,都能找到某种函数,让当且仅当。
更一般的存在性背后—Debreu定理简介:
在更高阶的理论研究中,最著名的存在性数学证明由Debreu在1954年给出:“若偏好关系具备完全性、传递性和局部非饱和性及连续性,则存在连续效用函数代表偏好。” 该结果为现代微观经济学的效用理论奠定了严密基础。
即使没有“连续性”,只要偏好关系是完全且传递的,在有限集合上,也总能构造出序数效用函数来排序。例如排名打分、选择投票等社会决策中,每个人都可以被赋予一个符合自己排序的“效用分数”。
构造效用函数的几何方法
我们来看一个形象的构造方法:对角线法(Diagonal Method)。此方法尤其适用于连续的偏好空间、且偏好关系是单调且微分的情形。
- 如图所示,先画出一条穿过原点的对角线:,表示商品1和商品2等量组合的路径。
- 以单调性为前提(即在和同时增加时,效用增加),保证每条穿过原点、向右上延展的射线都会恰好与每一条无差异曲线相交一次。
这种方法的本质是用“标号”唯一确定每条无差异曲线,把复杂的二维甚至多维消费空间简化成一条数轴上的排序。只要偏好是合理的(单调、连续、无圈),就总有对应的效用函数。其实际数学实现可以很复杂,但原理是一样的:为偏好的排序找到一把“绝不打架的尺子”。
从微观经济学角度,效用函数的存在性为利用数理工具分析消费者行为提供了坚实基础。即使效用数值本身没有直接物理含义,只要排序不变,所有理论推导(如最大化、无差异曲线分析等)都具备合理性。
效用函数的具体例子
在前面的内容中,我们介绍了偏好和无差异曲线的概念,现在进一步通过效用函数的具体构造和推导,来深入理解它们之间的对应关系,并讨论实际应用中常见的效用函数的特性。
从效用函数到无差异曲线
如果给定一个效用函数 ,我们可以通过令 ( 为常数),绘制出所有满足这个等式的 点,这些点的集合就是一条无差异曲线。每一条无差异曲线都对应一个特定的效用水平 ,表示消费者在消费这两种商品时获得的相同满足程度。
从效用函数推导无差异曲线
假设效用函数为 ,这是一个非常经典的“柯布-道格拉斯”类型效用函数。现在我们来求无差异曲线的表达式:
无差异曲线是所有满足 的 的集合,其中 为常数。可以将 写成 的函数,即 。
下图展示了 三种效用水平下的无差异曲线。可以看到,效用水平越高的无差异曲线离原点越远,表示“越高的偏好”或“更大的满足”。
经济学解释与微分分析
对于 ,其边际效用分别为:
表示商品1(或2)对效用的边际贡献正比于另一商品的消费量。实际上,只有两种商品都为正且不为零时,消费者才能获得效用。
无差异曲线的斜率即边际替代率(MRS),由全微分 可得:
这和无差异曲线“向右上凸”的形状相吻合。
单调变换的实例与本质
效用函数的“单调变换”是指对原有的效用函数 应用一个单调递增函数 ,即 。它不会改变偏好的顺序,也不会改变无差异曲线的形状,但会改变效用的实际“数值”。
考虑另一个效用函数:
通过代数可以看到:,也就是将原函数平方。因为平方是严格递增的单调函数,所以 和 描述的是完全相同的偏好。
从无差异曲线的定义来看, 的集合,就是 的集合。也就是说:
- 对应
因此两者的无差异曲线形状完全重叠,只是“数值”标签不同。
必然具有与 完全相同形状的无差异曲线,只是原先 的 等高线,现在变成 。但本质所描述的偏好和排序完全一致。这说明效用函数的“数值”本身没有行为意义(不可比性),只有“排序”具有经济学意义。
不同偏好类型的效用函数
本内容将介绍几类常见的效用函数,分别对应不同类型的消费偏好。这些偏好类型揭示了消费者对不同商品的替代或互补关系。理解各种偏好类型,对于后续预算约束下的最优化分析也非常重要。
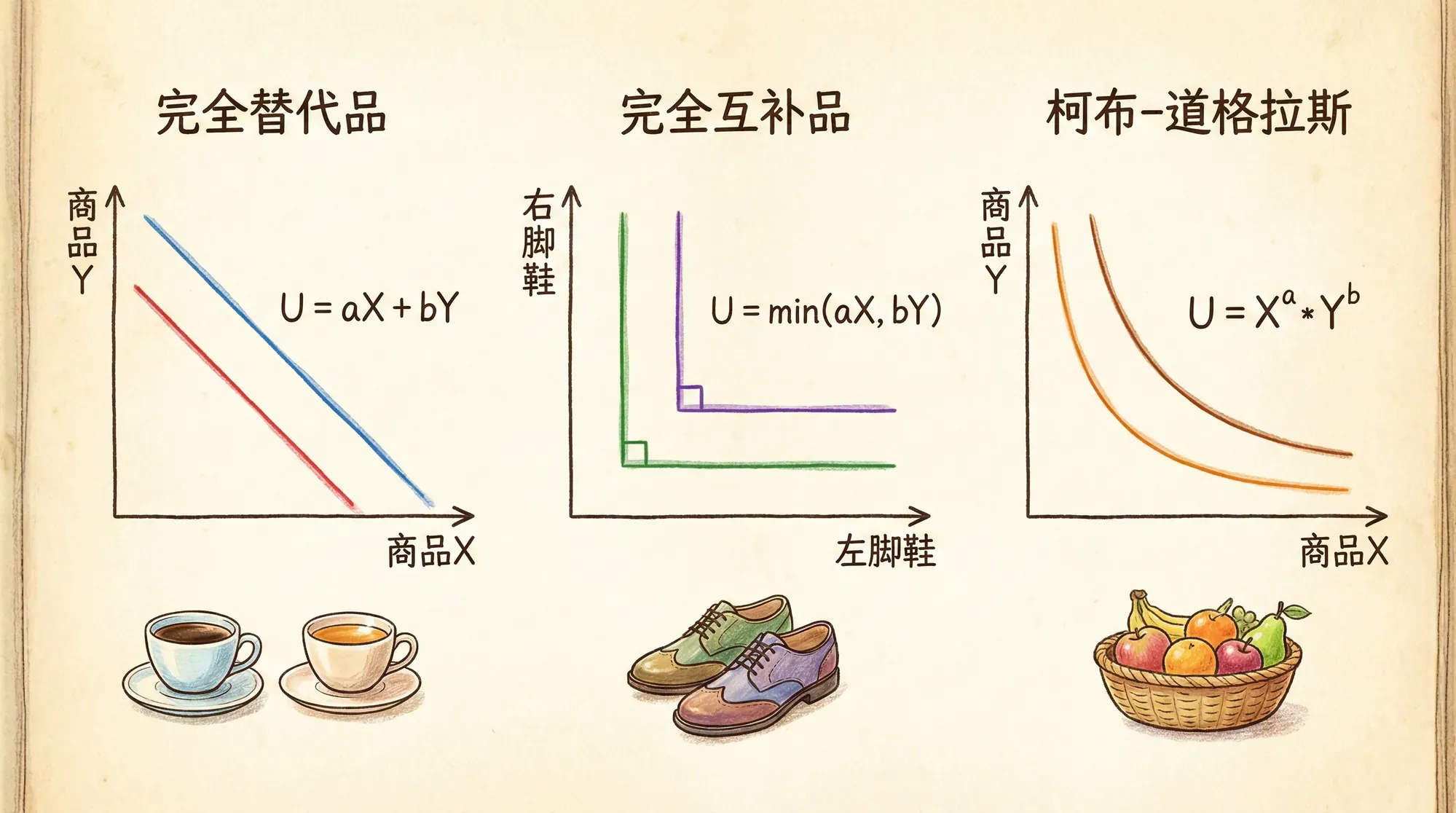
完全替代品
例如,你在选择红笔和蓝笔,无论是哪种颜色,你都只在意总共有多少支。比如10只红笔、0只蓝笔,和5只红笔、5只蓝笔你同样喜欢。这就是完全替代品——一种可以相互完全替代的商品类别。
效用函数:
理由与验证:
- 在无差异曲线上, 恒为常数,所以所有 只要总数一样,偏好完全相同;
拓展情形:
如果消费者愿意用1单位商品1换2单位商品2,比如红笔价值高于蓝笔,那么效用函数变为:
完全替代品的一般公式:
其中。无差异曲线是一组斜率为 的平行直线。这种偏好下,边际替代率恒定,消费选择一般取极端角点解。
直观图示:
- 无差异曲线是斜线,倾斜度等于商品边际替代值比率;
- 对于,消费主要集中在商品1;反之,则集中在商品2。
完全互补品
比如左鞋和右鞋:只有配成一对才有用,多了左鞋没右鞋也没意义。你关心的只是配成几双鞋。
效用函数:
理由与验证:
- 选择(10,10)和(11,10):,缺哪一样都不能多获得效用;
- 只有两件商品按比例配套才能有效提升效用。
一般比例拓展:
比如喝一杯茶需要两勺糖,则效用函数为
表示茶杯与糖要按搭配才能获得效用。
完全互补品的一般公式:
其中 表示商品1、2的搭配比例。
直观图示:
- 每条无差异曲线是“L”型折线,弯折点表达特定比例关系;
- 消费束只能沿着比例增长提升效用,多买单一商品没意义。
拟线性偏好
拟线性偏好的无差异曲线都是沿商品2方向的垂直平移。即,对商品2增加(减少)不会影响对商品1的边际替代率。
常见形式:
其中可为任意单调函数,如、。商品2进入效用函数为线性——每增加一个单位商品2,效用增加恒定。
解释与应用:
- 对商品1的边际替代率只由决定,与无关;
- 在收入或价格变动分析下,可用于沃尔什分解和补偿变换等专题,非常常见于理论推导。
示例:
这些用于建模“部分商品是钱”的情况,对数或根号函数常见于关于风险、效用递减的建模。
柯布-道格拉斯偏好
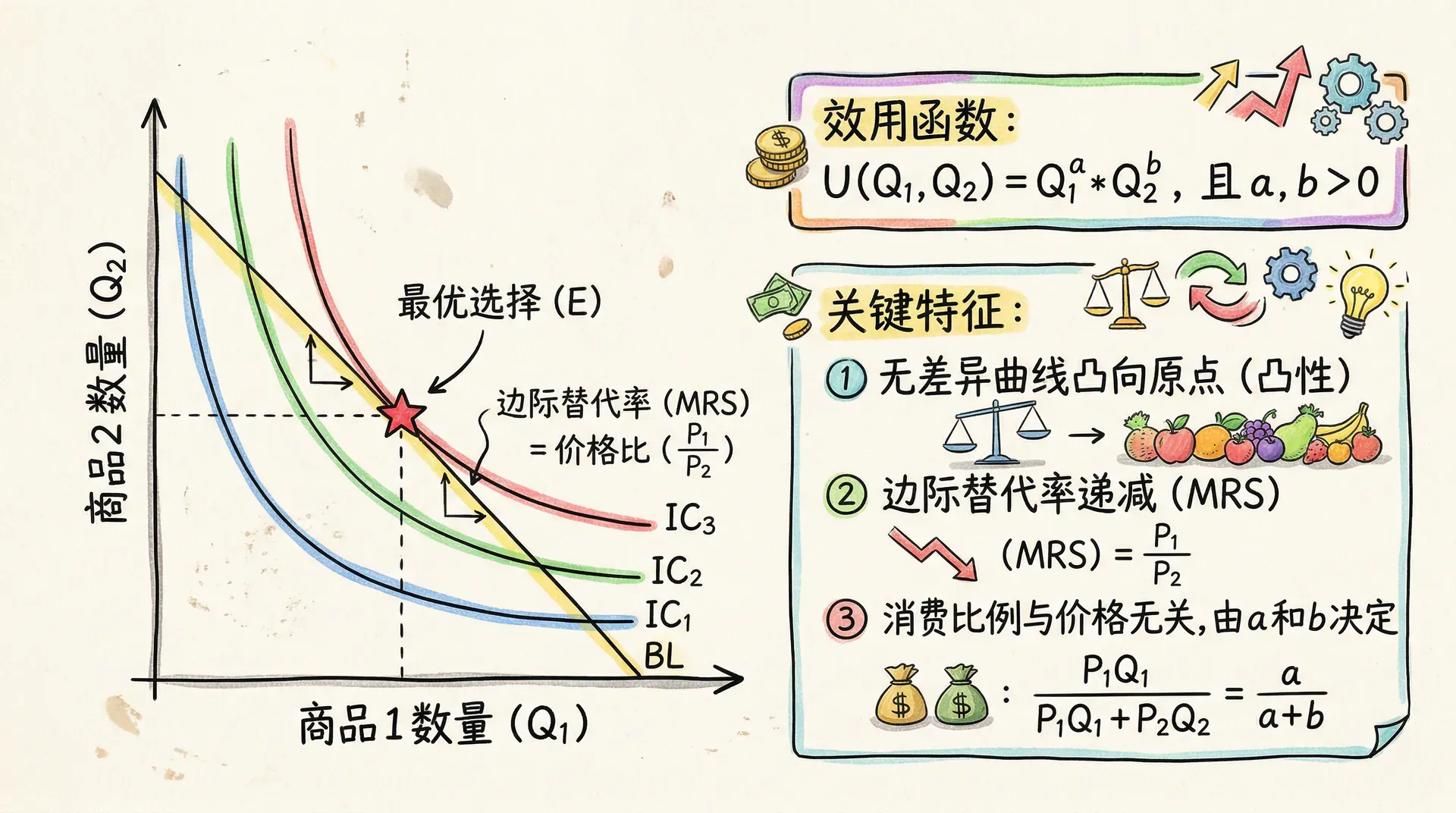
柯布-道格拉斯效用函数是经济学中最经典和广泛使用的一类效用函数,常用于描述消费者在两种(或多种)商品之间的联合消费偏好。该形式能够灵活地反映消费者对各商品的重要性权重,以及两种商品之间的替代和互补关系。
其中 , 分别表示两类商品的消费量, 和 则刻画了对各自商品的重视程度。 越大,说明消费者对商品1越偏好,反之亦然。
经济含义及性质:
- 边际效用递减:消费者每多消费一单位某商品,带来的效用增量会递减;
- 两类商品不可或缺:当 或 时,整体效用为0,反映两类商品必须搭配才能获得效用;
- 无差异曲线为双曲线:“向右上凸”,代表消费一种商品的同时,必须用另一种商品做补偿才能保持效用不变;
- 边际替代率递减:用一单位商品1去替代商品2时,需要付出的商品1数量会越来越多。
推导性质:
-
无差异曲线方程:
固定效用 ,则 。这类曲线不会与坐标轴相交,且曲线一直位于第一象限。
常用单调变换与标准化:
-
对数变换:对柯布-道格拉斯效用可以取对数,得到线性形式:
实际应用场景:
- 柯布-道格拉斯效用涵盖了最常用的消费建模情形,包括最优消费(消费内点解)、测度均衡、微观福利分析等;
- 在博弈论中,它描述了协作或资源分配时的偏好;
- 在宏观经济学,柯布-道格拉斯形式也可用于表示生产函数。
柯布-道格拉斯偏好能刻画“良好表现”(well-behaved)偏好:它的效用函数既表达了商品间的替代性,又体现边际效用递减,是消费者理论中最通用且可解析的基本模型。
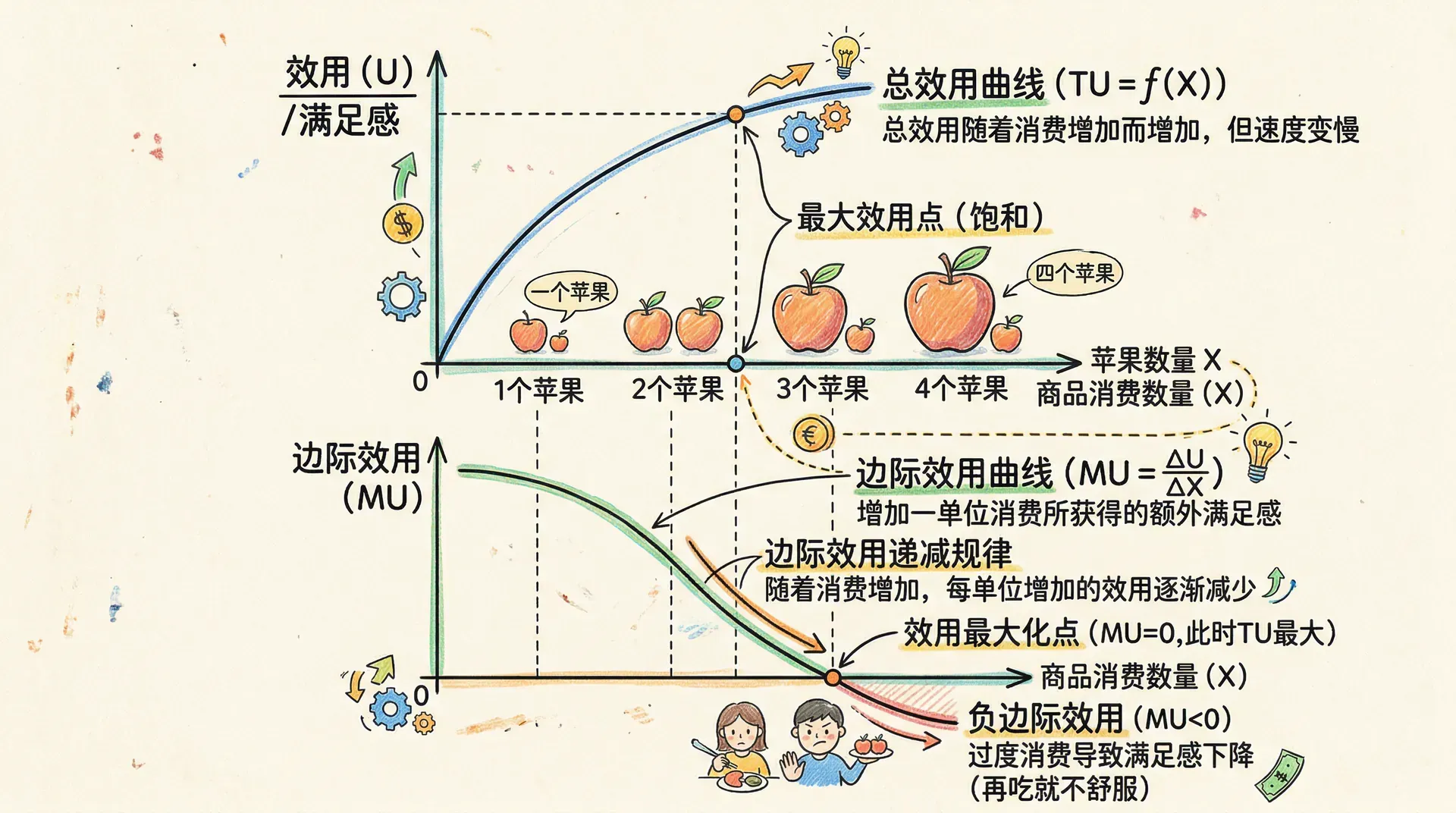
边际效用
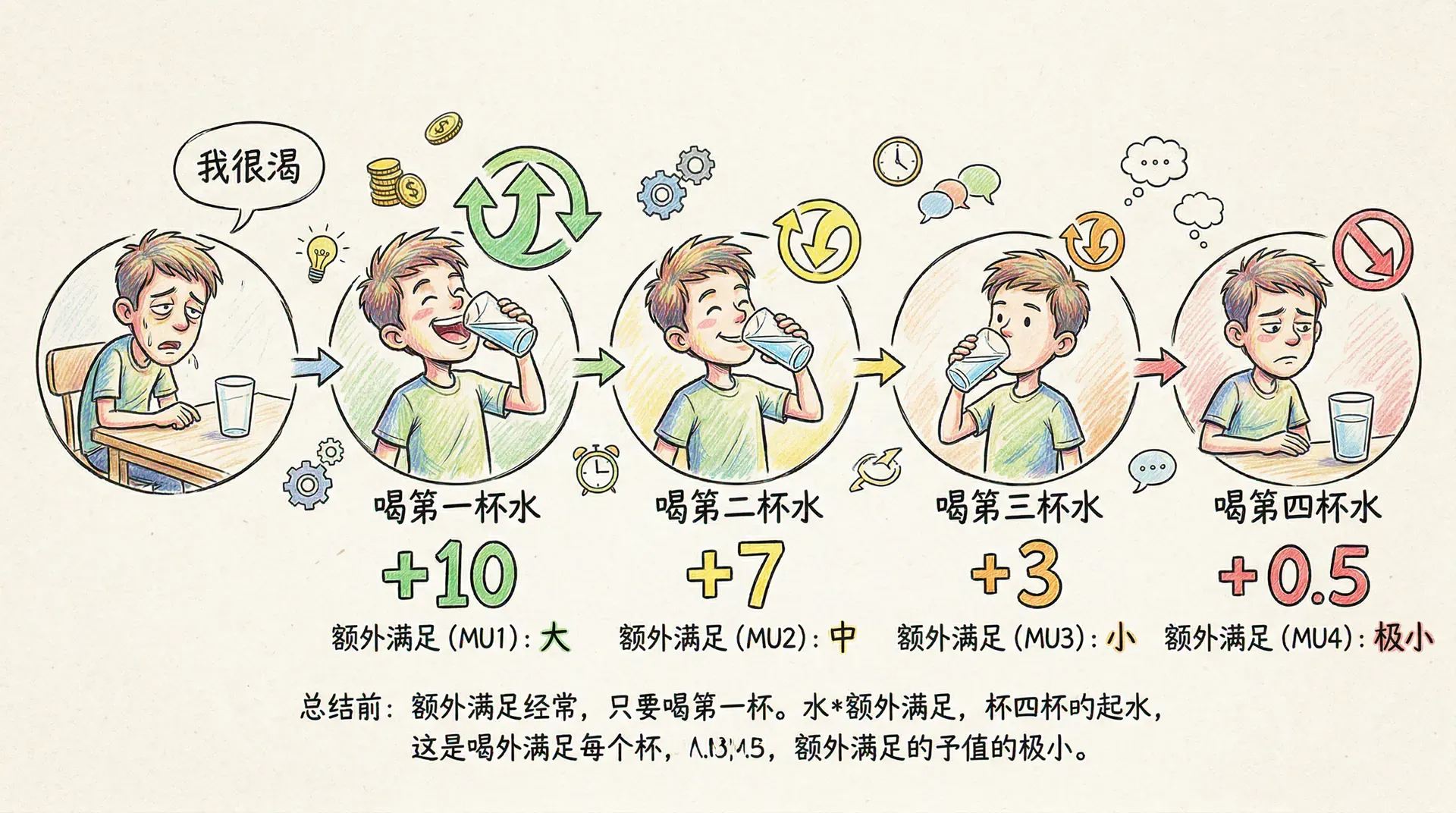
边际效用的定义
边际效用(Marginal Utility, MU)是微观经济学中非常核心的概念。它描述的是:当消费者正在消费某一商品组合 时,增加一单位商品1,消费者效用的变化有多少。这个变化率,就是对商品1的边际效用。这种思想可以推广到任何商品。
对于商品1的边际效用
这里, 通常取非常小的值(趋近于0),于是我们也常用偏导数来精确描述:
意义解释:
- 衡量“在其它商品(例如 )保持不变的前提下,增加一点 ,整体幸福感提升(效用提升)多少”。
- 同理,。
几何直观:
- 以 为横轴, 为纵轴,效用 水平线上的点构成“无差异曲线”。
应用公式:
- (对商品2的边际效用类似定义)
边际效用的几个重要性质
1. 依赖于效用的计量方式(只反映主观排序的变化率)
边际效用的绝对数值并无可观察的行为意义。如果我们把效用的度量整体乘以2,边际效用也会乘2,但消费者的偏好排序和选择不会改变。因此,边际效用受到效用函数选择的影响,重点是“变化趋势”而不是绝对数值。
例子:
- 若 与 表达的是同样一个偏好,则 也被乘以2。
2. 边际效用递减规律
多数商品满足边际效用递减(diminishing marginal utility):随着某种商品消费量越多,该商品的边际效用会下降。也就是说,每多消费一单位该商品所得的“幸福感增量”比前一单位要低。
若 随 增大而递减(保持 不变),就说明“边际效用递减”。
经济学解释: 这一规律在实际中很常见。例如,第一个面包解决了饥饿,第二个面包只是让你更饱,第三个面包可能完全吃不下去了。正因如此,消费者会将有限的预算分配到多种商品,以达到效用最大化。
3. 正常商品的边际效用为正
对“正常商品”,边际效用永远是正数。即增加该商品不会让幸福感下降。例如,多吃一点水果、多穿一件衣服,效用只会增加不会减少。
4. 例子分析:柯布-道格拉斯效用函数的边际效用
以 为例,其边际效用可求为:
可以发现,无论 固定还是变化, 增大时 一般是递减的。
边际效用的观念不仅限于经济学消费理论,还渗透到福利分析、博弈论等领域。比如,边际效用的分配均等是最优资源配置的一个必要条件(见后续的最优化问题)。
另外,虽然边际效用的绝对值没有行为意义,但不同比例的边际效用比较构成了“边际替代率”(MRS)等具有实际选择意义的量。
关键要点:
- 保持 不变, 增加 ,使消费者移动到更高的无差异曲线,效用增加 。
边际效用与边际替代率
MRS(边际替代率)的效用函数推导
边际替代率(Marginal Rate of Substitution, MRS)是微观经济学中刻画消费者在保持效用水平不变的情况下,愿意以多少单位商品2,去换取一单位商品1的数量。更严格地说,MRS描述的是无差异曲线上每一小段,商品2的减少量与商品1的增加量之比。
总效用的全微分与MRS的导出
设两种商品的效用函数为 ,其全微分为:
其中:
- :商品1的边际效用,
- :商品2的边际效用。
在无差异曲线上移动时,效用保持不变,即 ,则有:
即:
把关于 (或)的项移项解出:
这就是无差异曲线的斜率,也即边际替代率MRS。写为数学表达式:
也可以写成有限增量的近似表达:
- 注意: MRS的符号为负,即增加商品1需要减少商品2才能保持同一效用水平。
左边是“2对1”的比例,右边是“1对2”的边际效用之比,一定不要混淆。
几何直观与无差异曲线
MRS的重要性质归纳
1. 符号特征
- 负号与替代关系:
,代表商品1增加时,为保持效用不变,商品2必须减少,二者满足替代关系。 - 可写作绝对值表达:
2. 行为可测性
- 含义: MRS可以通过实际的选择行为观测、测量,即市场中消费者以多少商品2去换取单位商品1。
- 测量方法: 找到让消费者刚好保持无差异的交换比率。
3. 不变性(关于单调变换)
-
MRS与效用函数变换的关系:
若效用函数做单调变换 ,边际效用也许改变,但MRS保持不变:设新函数,则
尽管边际效用(, )会因效用的单调变换而变化,但边际效用的比率(即MRS)始终不变,因此MRS具有真实的行为意义,是实际可观测的量。也就是说,MRS反映了消费者的偏好性质,而单独的边际效用没有行为意义。
通勤行为的效用分析
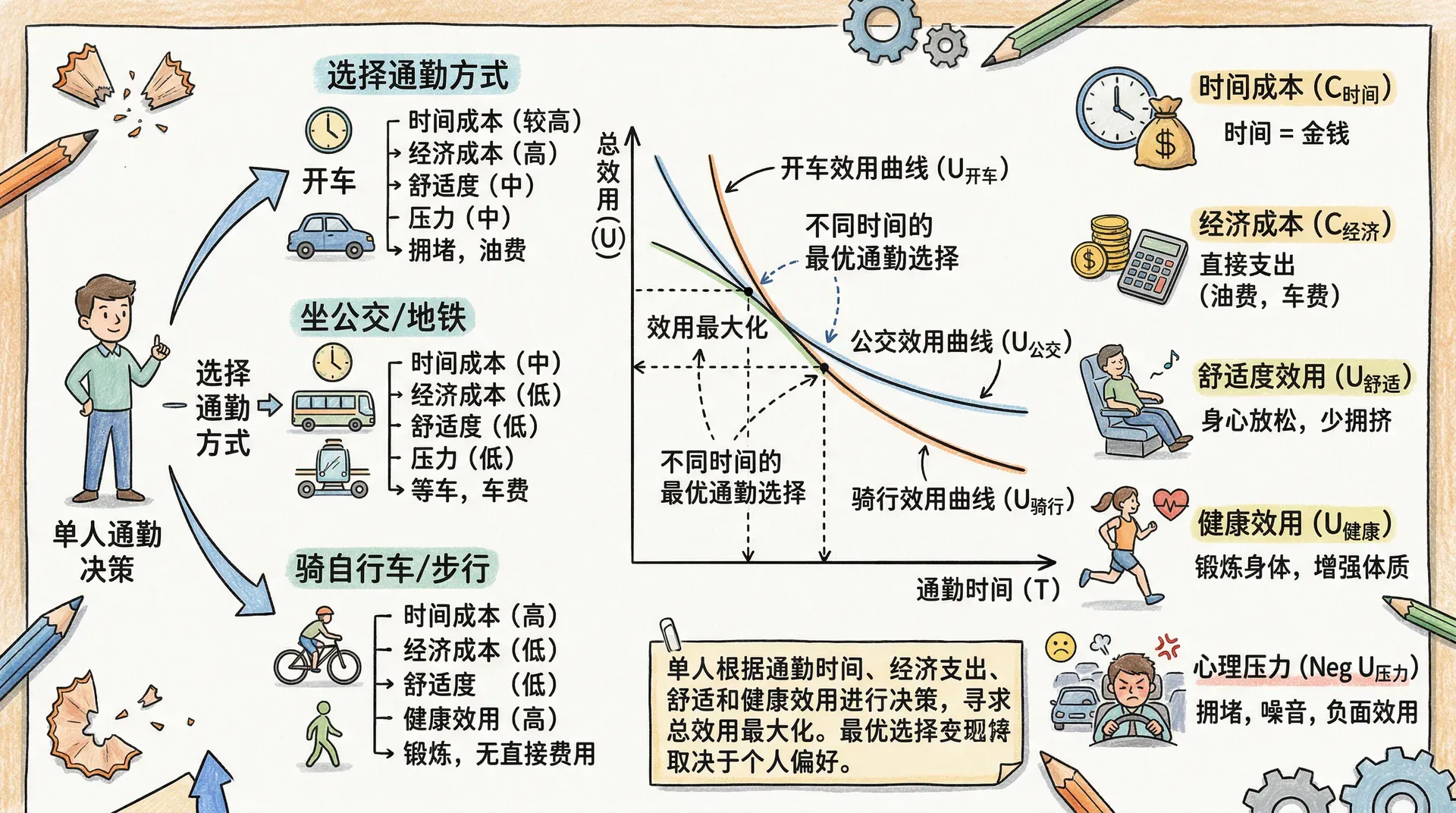
交通选择模型的结构化表达
在现实生活中,效用函数(utility function)是用来刻画消费者如何在不同选择间做出决策的核心工具。用数学表达是:
其中 和 均为不同特征组合(商品束)。
交通出行情景:
对于通勤者而言,其选择的每一种出行方式可抽象为多个特征变量的集合。常用变量及符号表示如下:
- :出行时间(travel time)
- :等待时间(waiting time)
- :自付费用(cost)
- :舒适度(comfort)
各种出行选择(如公交、私家车、地铁)即为在 空间中的备选点。目标是用效用函数 来描述消费者的选择规律。
线性效用模型公式化
最常用的实证建模方法是假设效用函数为变量的线性组合:
其中为待估参数,为未观测因素或误差项。
每个衡量了相应特征对选择的影响程度。通过收集数据并对实际选择行为建模,可以使用极大似然、最小二乘法等方法拟合出的数值。
实际估算与解释
以研究样本为例,估计出的效用函数为:
- :往返的步行时间(walking time, 分钟)
- :行程总时间(total travel time, 分钟)
- :行程总费用(cost, 美元)
该模型可用于预测:对于备选方案和,若,则更有可能选择方案。
模型拟合表现: 上述效用函数能正确解释样本中93%家庭在汽车与公交之间的选择。
系数的含义与边际替代率公式
对上述效用函数,各变量系数可以用边际替代率(Marginal Rate of Substitution, MRS)公式解析:
步行时间和行程时间的MRS
含义:消费者愿意多花3.6分钟行程时间以节省1分钟步行时间,说明步行的不适程度被认为比行程时间大3.6倍。
时间价值的计算
换算为
具体政策分析举例
例如,为节省分钟的行程时间,消费者愿意支付:
根据上述计算结果,我们可以得出以下几点结论:
-
通过边际替代率(MRS)的计算,即,可以看出步行时间在通勤者眼中被认为是不便度较高的因素,具体来说,步行时间的不便度大约是行程时间的3.6倍。这意味着通勤者愿意用3.6分钟的行程时间来换取1分钟的步行时间减少。
-
在时间与费用的权衡分析中,的结果表明,每减少一分钟行程时间,通勤者愿意为此支付约美元,由此换算得每小时的时间价值为美元。作为参照,1967年美国的平均小时工资大约是2.85美元,因此时间价值大约占了当时收入的38%。这一指标在交通政策评估中有着重要作用,可用来衡量通勤时间改善带来的经济效益。
交通政策评估与模型应用
-
成本-效益对比(Cost-benefit)
运营更多公交车的费用 由此减少的出行时间的货币价值。 -
预测模拟(Choice Prediction)
通过效用函数预测通勤者选择概率,计算方案调整后乘客变化乃至收入影响。 -
政策收益测算(Policy Valuation)
利用边际替代率、时间价值等计算政策优化的期望收益。
通勤者根据估算的时间价值,愿意为节省20分钟行程时间支付0.37美元,为交通政策定价和资源配置提供了量化依据。该建模框架还能推广至医疗、住房等多种领域,刻画实际决策行为。
总结
现代经济学认为,效用函数的本质作用在于刻画和排序消费者的偏好,而其具体数值没有内在意义。序数效用的重点在于反映选择的顺序,并不关心各选项之间效用差异的绝对大小,用任何单调变换变换后的效用函数仍可表示同一组偏好。理论上,只要偏好满足一定的合理性条件,就总可以用某种效用函数来表示,不过这种表示具有非唯一性,任何能保持偏好排序的效用函数都可以。几何上,效用函数就是标记无差异曲线的方法。常见的效用函数类型包括完全替代型(线性)、完全互补型(L形)、拟线性与柯布-道格拉斯等,不同的函数形式反映了不同的偏好特征。
边际效用反映了增加一单位商品所带来的效用变化,而边际替代率(MRS)则衡量消费者愿意以多少单位某种商品来交换另一单位的另一商品,两者在实际选择中有着明确的行为含义。实际应用中,经济学家通过分析选择数据来估计效用函数,用边际替代率等工具考察政策变化的经济价值,并借助效用理论框架预测消费者行为的变化。
通过本内容的学习,我们掌握了区分序数效用与基数效用、理解单调变换特性、构造不同偏好结构的效用函数,以及计算和应用边际效用和边际替代率等基本方法,同时具备了将效用分析理论用于实际选择建模和政策评估的能力。
总之,效用理论是经济学分析中重要的定量与抽象工具。它不仅帮助我们从可观察行为反推出消费者的深层偏好,更鼓励我们关注理论的预测能力,并以此指导具体的政策设计与评估。后续我们将进一步应用这些工具,研究消费者在预算约束下如何实现最优选择。