访问控制:从“能登录”到“只做被允许的事”
成功登录只能说明系统相信了你的身份,并不意味着你可以读取全部文件、修改任意订单或调用所有接口。访问控制真正回答的是:哪个主体,在什么条件下,可以对哪个客体执行哪种操作。它既要挡住未获授权的请求,也要让合法工作顺畅完成。
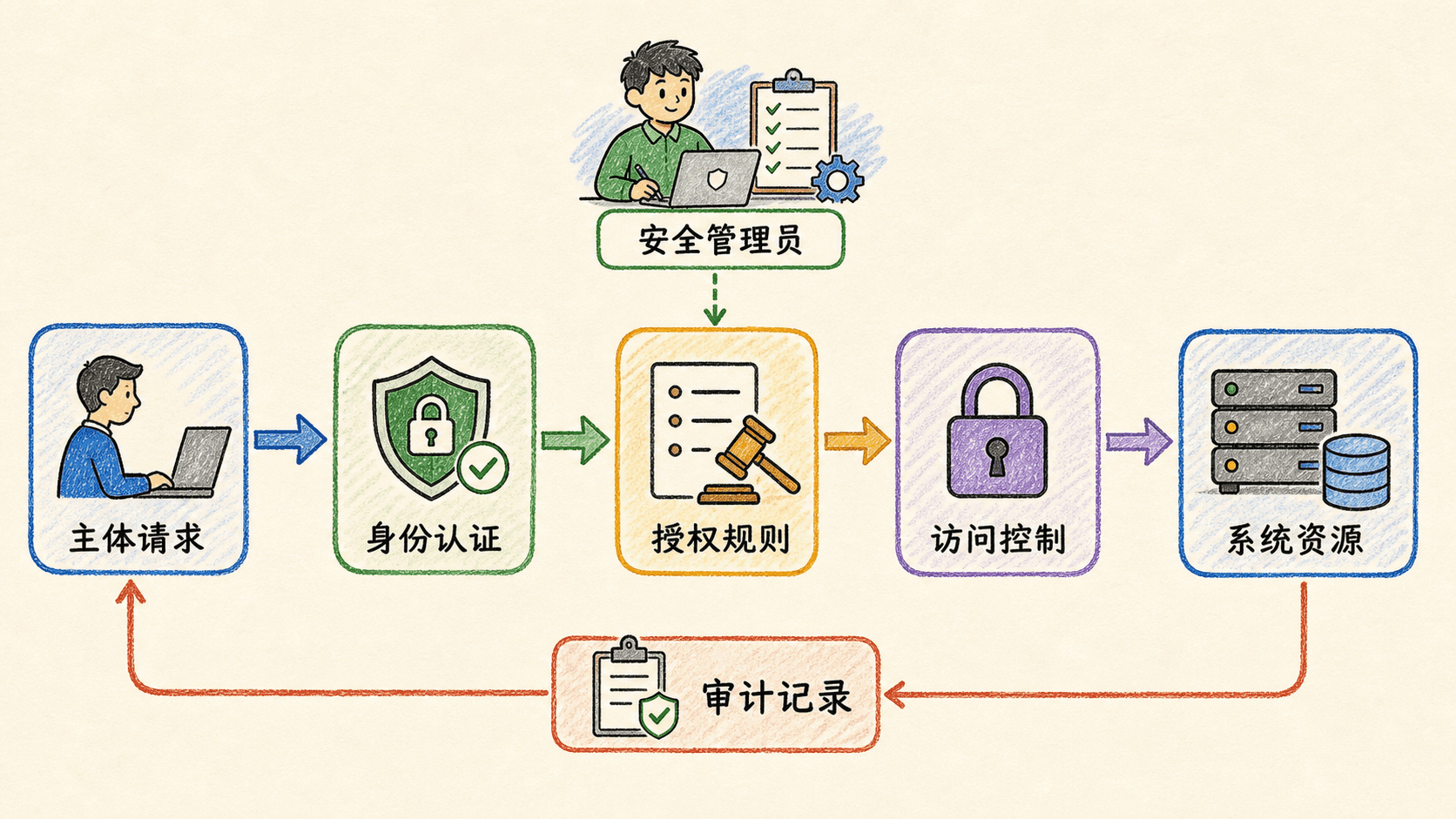
可靠身份是输入,授权规则是依据,执行点在每次访问发生前作出决定,审计记录让事后追责和规则改进成为可能。本章从这个闭环出发,逐层建立访问矩阵、DAC、UNIX 权限和 RBAC 的完整认识。
学习目标
学完本章,你应当能够区分认证、授权、访问控制执行和审计;用主体、客体、操作和上下文描述请求;从访问矩阵推导 ACL 与能力列表;正确解释 UNIX 文件与目录权限、特殊位和扩展 ACL;用角色、会话、层级与职责分离设计 RBAC;用默认拒绝和最小权限控制风险。
2.1
用户已通过密码和二次验证。系统接下来检查他能否修改某份报表,这一步属于什么?
一次访问决定是怎样产生的
一次完整请求至少包含四类信息:主体是发起动作的活动实体,通常是代表用户运行的进程,也可能是服务账户、容器任务或设备;客体是被保护的文件、目录、数据库行、端口、API 或内存区;操作可以是读取、写入、执行、删除、创建或搜索;上下文则包括时间、网络位置、设备状态、会话角色和风险等级。
系统先验证主体的凭据,再把请求交给访问控制执行点。执行点查询授权规则,得到允许或拒绝的结果,然后把主体、客体、操作、时间和结果写入审计轨迹。管理员负责维护规则,却不应绕过相同的审计要求。
- 认证回答“你是谁,凭据是否可信”。
- 授权回答“按策略,你拥有哪些许可”。
- 访问控制执行回答“这一次具体请求是否放行”。
- 审计回答“谁在何时请求了什么,结果如何”。
如果请求 IP 能影响决定,系统必须确信地址没有被不可信代理伪造;如果部门字段来自目录服务,目录同步也必须可信。授权算法再严谨,输入错误仍会产生错误决定。
前端隐藏按钮不是访问控制。攻击者可以直接构造请求,真正的检查必须发生在后端资源被读取或修改之前,并且每次请求都要重新绑定当前主体与目标客体。
2.2
下列哪些信息可以成为一次访问控制决定的输入?
策略原则:默认拒绝、最小权限与职责分离
自主访问控制(DAC)依据请求者身份和授权条目决定访问,资源所有者通常可以把自己的部分权限授予别人。强制访问控制(MAC)比较客体安全标签与主体许可级别,获准读取的人通常不能自行转授。基于角色的访问控制(RBAC)先把权限交给岗位角色,再把用户分配到角色。
三者可以叠加:文件系统用 DAC 表达所有者授权,敏感数据再受标签约束,业务应用同时以 RBAC 管理岗位职责。多个策略冲突时必须预先定义合并规则,高敏感场景通常采用“任一策略拒绝即拒绝”。
默认拒绝只允许明确授权的请求;最小权限只给主体完成当前任务所需的最小资源、最小操作集合与最短持续时间。职责分离把高风险流程拆给不同的人,例如经办人录入付款、审批人复核、执行系统划款、审计员只读检查。双人控制进一步要求多人共同完成一个动作。
粒度也要可调:数据库可以对普通员工做表级拒绝,对财务应用做行级授权,对某些字段做列级脱敏。越细越精准,但规则、查询和审计成本也越高。
2.3
只要用户有权读取机密文件,他就必然有权把读取权限授予别人。
访问矩阵:把授权关系变成可推理的结构
设主体集合为 S,客体集合为 O,权限集合为 R。访问矩阵 A 的单元格 A[s,o] 保存主体 s 对客体 o 的权限集合。若开发者可以读写代码仓库,就写成 A[开发者,代码仓库]={读,写}。行回答“这个主体能访问什么”,列回答“谁能访问这个资源”。
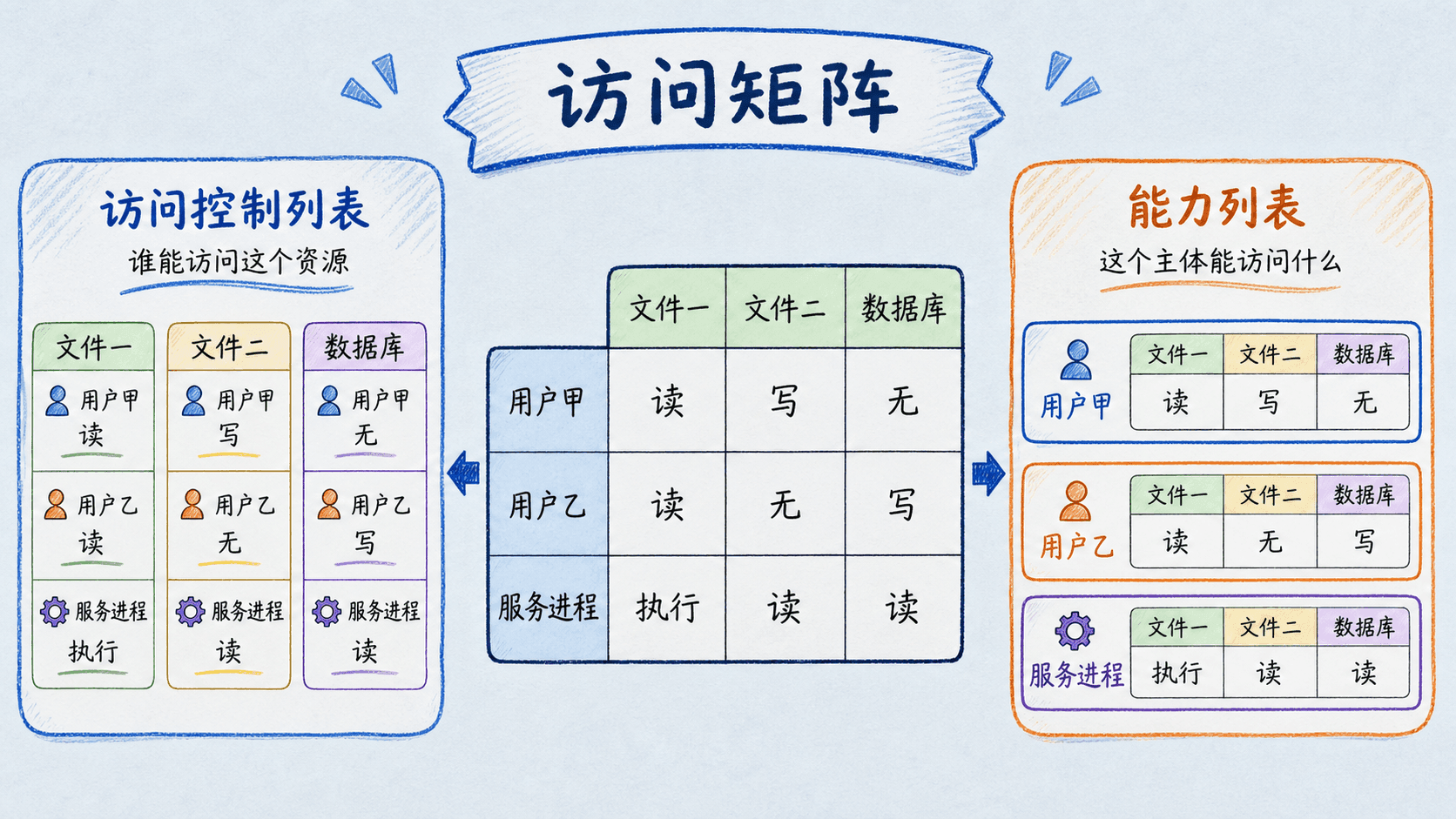
矩阵通常非常稀疏,因此按列分解成 ACL:每个客体保存用户或组及其权限,便于查看和撤销某资源上的授权。按行分解成 能力列表:每个主体持有不可伪造的能力凭证,凭证指向客体并携带允许操作,便于快速判断进程能做什么。
ACL 不擅长快速枚举某用户的全部资源;能力列表的难点是撤销,常需间接表、版本号、短有效期或撤销表。矩阵还可以表示“所有”“控制”“可复制”等管理权:所有者可授予目标客体的权限,控制者可调整主体权限,可复制标记决定接收者能否继续转授。
矩阵的一行也可视为一个保护域:一组客体及其可用操作。进程不必继承用户全部权限,可以在更小的域中运行不完全可信的程序。域还能动态切换,例如普通代码处在用户态,受控系统调用才进入权限更高的内核态。
2.4
关于 ACL 与能力列表,下列哪些说法正确?
UNIX 文件访问控制:九个权限位并不简单
UNIX 文件由 inode 保存所有者 ID、组 ID、权限位等元数据;目录把名称映射到 inode。一个文件名不等同于文件本体,同一 inode 还可能有多个硬链接名称。
传统权限分为所有者、所属组、其他人三组,每组有读 r、写 w、执行 x。匹配按最具体类别选择:请求者是所有者就只看所有者三位,否则检查匹配组,最后才看其他人。系统不会把所有者位和其他人位求并集。
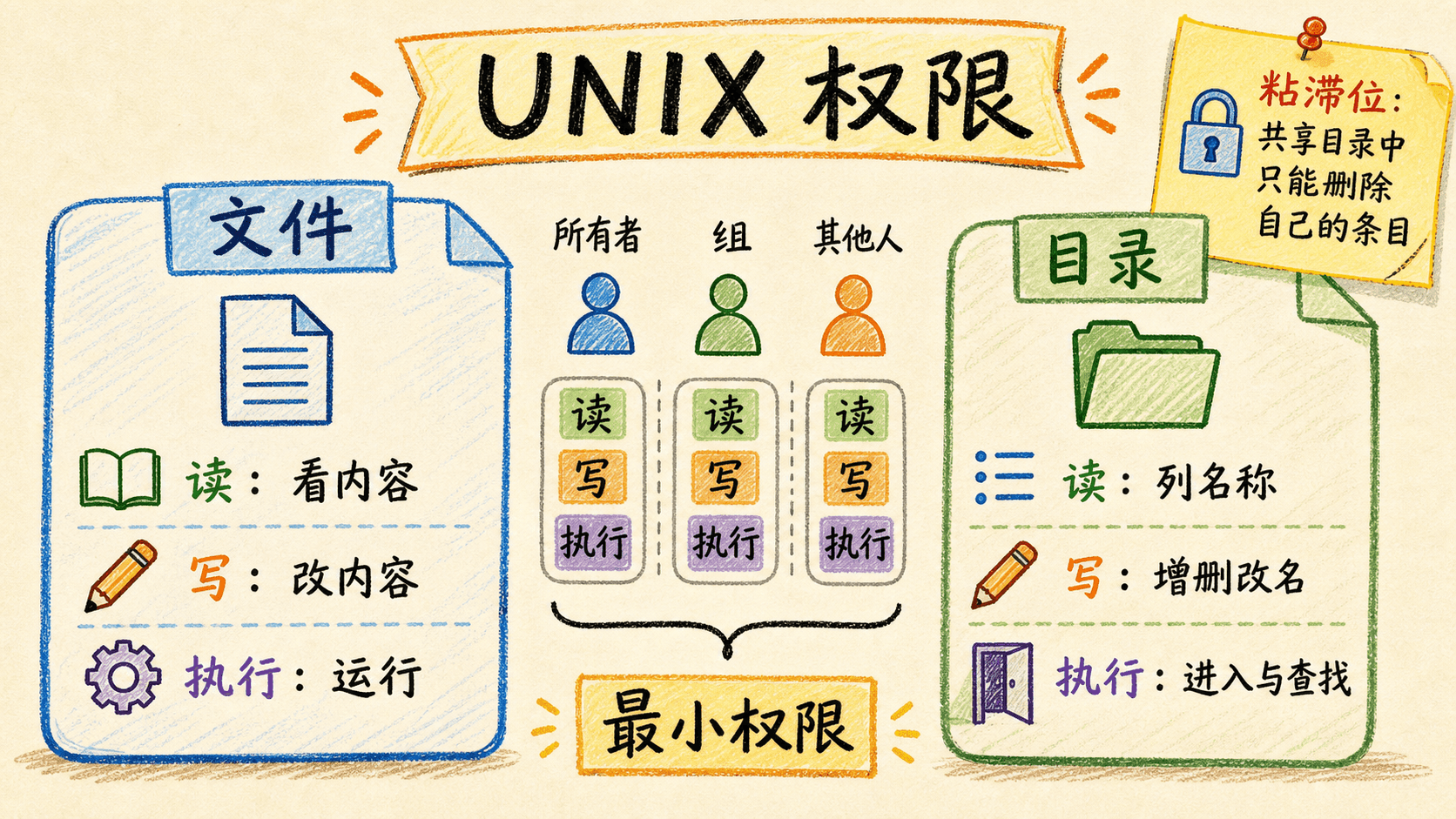
对普通文件,r 是读取内容,w 是修改内容,x 是执行程序。对目录,r 是列出名称,w 是创建、删除或重命名目录项,x 是穿越目录并按名称查找。因此,拥有父目录写和执行权限的人可能删除一个自己不能写的文件,因为删除改变的是目录项。
可执行文件上的 SetUID 或 SetGID 会让进程临时获得文件所有者或组的有效身份,能封装受控高权限操作,也会放大输入验证漏洞。目录上的 SetGID 让新对象继承目录组。目录粘滞位 t 限制删除和重命名:即使多人可写,也只能处理自己的条目或由目录所有者处理。常见 1777 就是“人人可创建,但不能随便删除别人文件”。
超级用户和 SetUID 程序能跨越普通权限边界。高权限程序应功能单一、严格校验输入、尽早降权,并避免把用户可控路径交给高权限环境。
2.5
用户对共享目录有写和执行权限,但对其中某文件没有写权限。他通常仍可能做什么?
扩展 ACL:命名用户、命名组与掩码
三分法无法自然表达“给小王读写、给审计组只读,但不改变原所属组”。扩展 ACL 增加命名用户和命名组条目,同时保留所有者、所属组和其他人条目。
关键是 mask 掩码:它是命名用户、命名组和所属组条目的权限上限,不限制文件所有者,也不限制 other。某条目写着 rw-,但 mask 为 r-- 时,有效权限仍只有读。
典型匹配顺序是文件所有者、精确命名用户、所属组及匹配命名组、其他人。组阶段可同时匹配多项;请求权限只要被某个匹配组允许且未被 mask 削减即可。
bash
setfacl -m u:xiaowang:rw report.txt
setfacl -m m::r report.txt
getfacl report.txt这时小王条目请求 rw,但有效结果受 mask 限制为 r。改变传统组权限位时,一些实现也会同步改变 ACL mask,自动化脚本要防止意外削减已有命名授权。
2.6
扩展 ACL 中,限制命名用户和组条目最大有效权限的字段叫做 ____。
RBAC:用岗位稳定性吸收人员变化
直接给每名用户配置每个资源的权限会形成难以审计的关系网。RBAC 把它拆为两层:用户分配到角色,权限分配给角色。岗位通常比人员稳定,入职、调岗、离职时主要调整用户—角色关系。
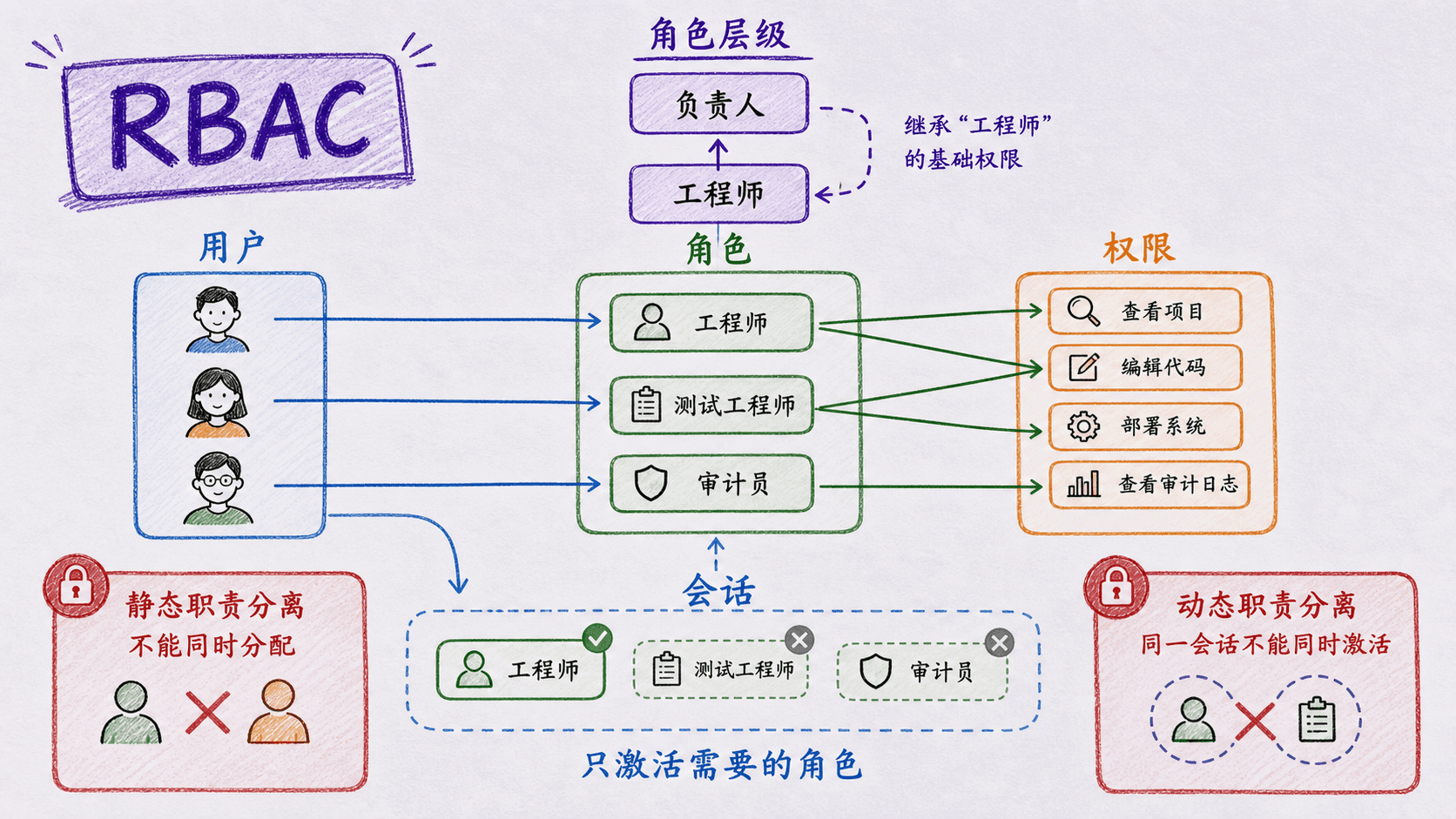
核心元素是用户、角色、权限、会话。会话是用户本次登录中激活的已分配角色子集。一个用户可以有多个角色,却不应全部激活;开发负责人修复代码时只激活工程师角色,审批发布时再启用审批角色,这就是动态最小权限。
角色层级让高级角色继承低级角色的权限。一般层级允许多重继承,表达能力强;受限层级接近树,实现和审计更简单。层级过深会让有效权限难以解释,因此系统应分别展示直接权限与继承权限。
静态职责分离(SSD)禁止用户同时被分配到冲突角色,例如不能兼任付款经办和审批。动态职责分离(DSD)允许拥有两个角色,但禁止在同一会话同时激活,适合轮班和临时代理。约束还可限制角色人数、用户角色数、敏感权限覆盖角色数,或规定高级角色的先决角色。
2.7
用户可以拥有经办员和审批员两个角色,但一次会话不能同时启用。这是哪种约束?
实践:观察 chmod 如何改变保护域
本机临时实验先用 640 表达“所有者读写、组只读、其他人无权限”,再收紧为 600;最后创建带粘滞位的共享目录。所有对象在结束时清理。
bash
tmp=$(mktemp -d /tmp/access-control-lab.XXXXXX)
umask 077
printf '季度预算:仅项目成员可读\n' > "$tmp/report.txt"
chmod 640 "$tmp/report.txt"
stat -f '文件=%N 权限=%Sp 八进制=%OLp 所有者=%Su 组=%Sg' "$tmp/report.txt"
chmod 600 "$tmp/report.txt"
stat -f '收紧后 权限=%Sp 八进制=%OLp' "$tmp/report.txt"
mkdir "$tmp/shared"
真实输出:
text
文件=/tmp/access-control-lab.ivVjrz/report.txt 权限=-rw-r----- 八进制=640 所有者=zhengxiaohu 组=wheel
收紧后 权限=-rw------- 八进制=600
共享目录=/tmp/access-control-lab.ivVjrz/shared 权限=drwxrwxrwt 八进制=777最后一行的 stat 数值只显示基础三组权限;字符串末尾的 t 才证明粘滞位存在。实验说明权限设计应从业务意图翻译:先选 640,再用 stat 核对实际所有者、组和权限;敏感度提高后改为 600,使组成员退出保护域;共享目录则以粘滞位保留协作创建同时限制删除。
2.8
关于实验结果,下列哪些解释正确?
从模型落到真实系统:管理面与执行面
大型组织若让每台主机和每个应用分别维护每名员工的授权,配置会重复、变更会延迟、错误难发现。更稳健的结构把职责拆开:人员管理方维护身份、岗位和任职状态;应用管理方定义操作与客体;授权管理方把角色映射到权限并生成安全配置;应用执行点在每次请求前检查;审计系统独立收集允许和拒绝事件。
角色不应简单等于职级。同一职级在财务分析、客户服务和运维中需要完全不同的权限。可将“职能 + 责任级别”组合成角色,再用层级复用共同权限。集中管理也不代表单点盲信:身份、角色、权限定义与执行日志应由不同职责维护并定期对账。
权限有完整生命周期:入职时从零按岗位授权;转岗时先撤旧角色再加新角色;临时代理使用到期角色;离职时立即禁用会话、凭据和角色。复核要检查角色是否仍对应真实职责、权限是否长期未用、用户是否因多次转岗积累权限,以及冲突角色能否同时激活。
2.9
采用 RBAC 后,只需维护角色定义,不再需要处理入职、转岗、代理和离职。
小结与自查清单
访问控制把认证得到的身份、授权规则和本次请求的主体—客体—操作—上下文组合起来,在访问发生前作出决定并留下审计记录。访问矩阵提供统一推理框架;ACL 与能力列表分别是按客体和按主体的稀疏实现;保护域让进程在当前任务所需的最小权限中运行。
UNIX 用所有者、组、其他人与 rwx 构成高效基础模型,目录权限、SetUID/SetGID、粘滞位和扩展 ACL 补足协作与细粒度需求。RBAC 把快速变化的用户和稳定岗位权限解耦,并通过会话、层级、静态与动态职责分离落实最小权限。
部署前应检查:所有入口是否在后端授权;身份和上下文输入是否可信;未明确允许是否默认拒绝;能否查询资源授权者与主体有效权限;目录权限、ACL mask、角色继承是否造成意外权限;高风险动作是否有职责分离和独立审计;临时权限是否到期;转岗离职是否及时撤权。
2.10
一套完整访问控制方案通常应同时具备哪些能力?