程序安全:从边界检查到纵深防御
程序处在不可信输入与高价值资源之间。一个长度计算错误、一次未验证的路径拼接或一种错误的输出编码,都可能把普通功能变成越权入口。程序安全的核心不是预测每一种攻击字符串,而是明确假设、强制边界、选择安全接口,并让失败停在可控范围。
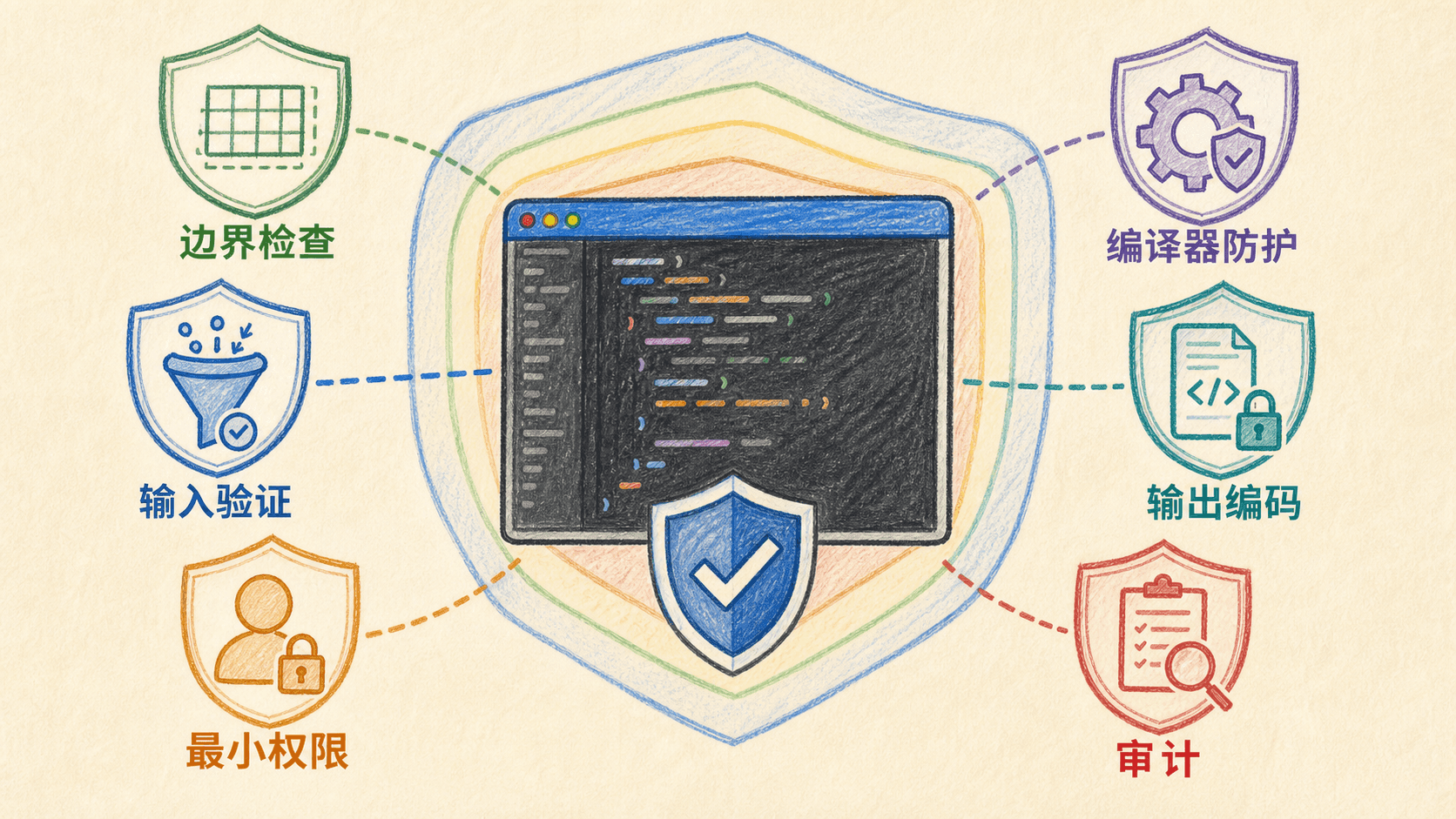
学习目标与威胁模型
完成本章后,你应该能够解释栈、堆和全局区越界的后果,使用长度检查和安全接口修复内存错误,设计输入验证与输出编码,安全调用操作系统与其他程序,并理解编译器、运行时和最小权限如何组成纵深防御。
软件质量关注程序是否按正常需求工作,软件安全还必须考虑恶意输入、异常顺序、资源耗尽和权限滥用。防御式编程要求所有外部数据都先被视为不可信,包括网络请求、文件、环境变量、命令行、进程间消息、数据库记录和来自其他组件的返回值。
安全假设必须写成可检查的条件:长度、类型、范围、编码、状态、权限和资源上限。仅在注释中声称“调用者会保证”不构成边界。
1
防御式编程对外部输入的默认态度是什么?
缓冲区溢出与内存布局
缓冲区溢出发生在写入超出对象边界时。栈上的局部缓冲区与其他局部变量、保存的控制信息相邻,越界可能先改变逻辑状态,也可能破坏返回流程;堆缓冲区与其他动态对象和分配器元数据相邻,越界可能污染对象字段、长度或函数引用;全局与静态区越界则会破坏相邻长期状态。
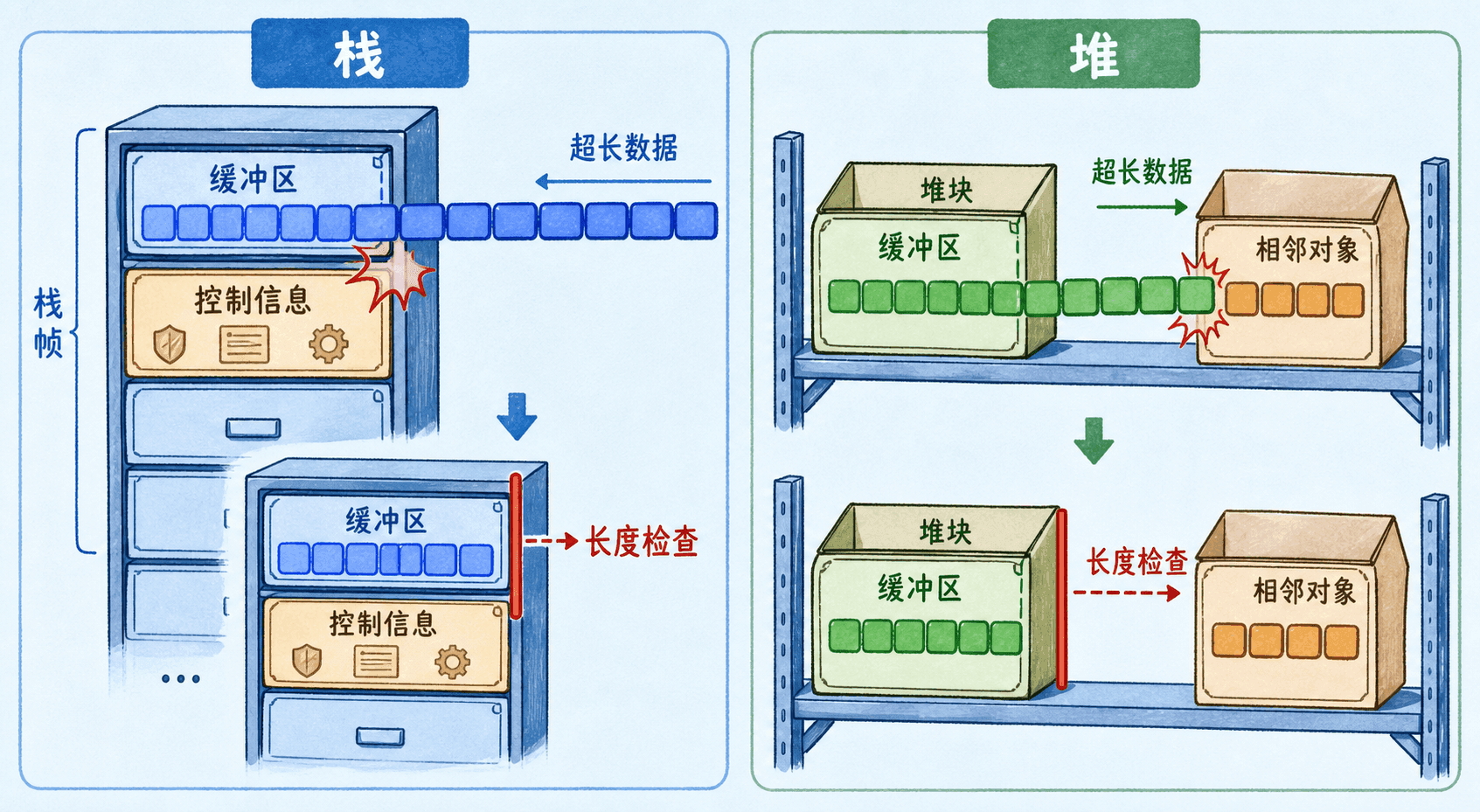
读越界会泄露本不应返回的内存,写越界会造成崩溃、数据破坏或控制流异常。整数溢出也会间接制造缓冲区问题:元素数量与元素大小相乘若发生回绕,分配空间小于后续写入量。格式化字符串把外部数据当格式模板,也可能读取或写入非预期内存。
2
越界写入可能造成哪些后果?
从源头修复边界错误
首选内存安全语言或带边界检查的容器。必须使用 C/C++ 时,应让接口同时接收目标容量和源数据长度,在任何复制前验证 需要长度 + 结束符 <= 容量,并检查加法与乘法是否溢出。避免无界复制、无界格式化和由输入直接决定的栈数组。
截断不是普适修复:标识符、路径或安全令牌被静默截断可能与另一合法值碰撞。更稳妥的策略通常是明确拒绝,并返回稳定错误。若确实允许截断,应在接口契约中声明并保证字符串终止。
先以字节为单位确定目标容量,并明确是否包含结束符。
验证输入长度和所有长度运算不会回绕,再决定接受或拒绝。
使用具有容量参数的接口完成复制,并测试边界值:零、容量减一、容量和超大值。
3
固定8字节字符缓冲区最多安全保存多少字节内容并保留结束符?
编译器与运行时纵深防御
栈保护在敏感控制数据附近放置校验值,返回前若发现变化就终止;地址空间布局随机化降低位置可预测性;不可执行内存阻止数据页直接作为代码运行;控制流保护限制间接跳转目标;安全分配器与检测器帮助发现越界、释放后使用和重复释放。
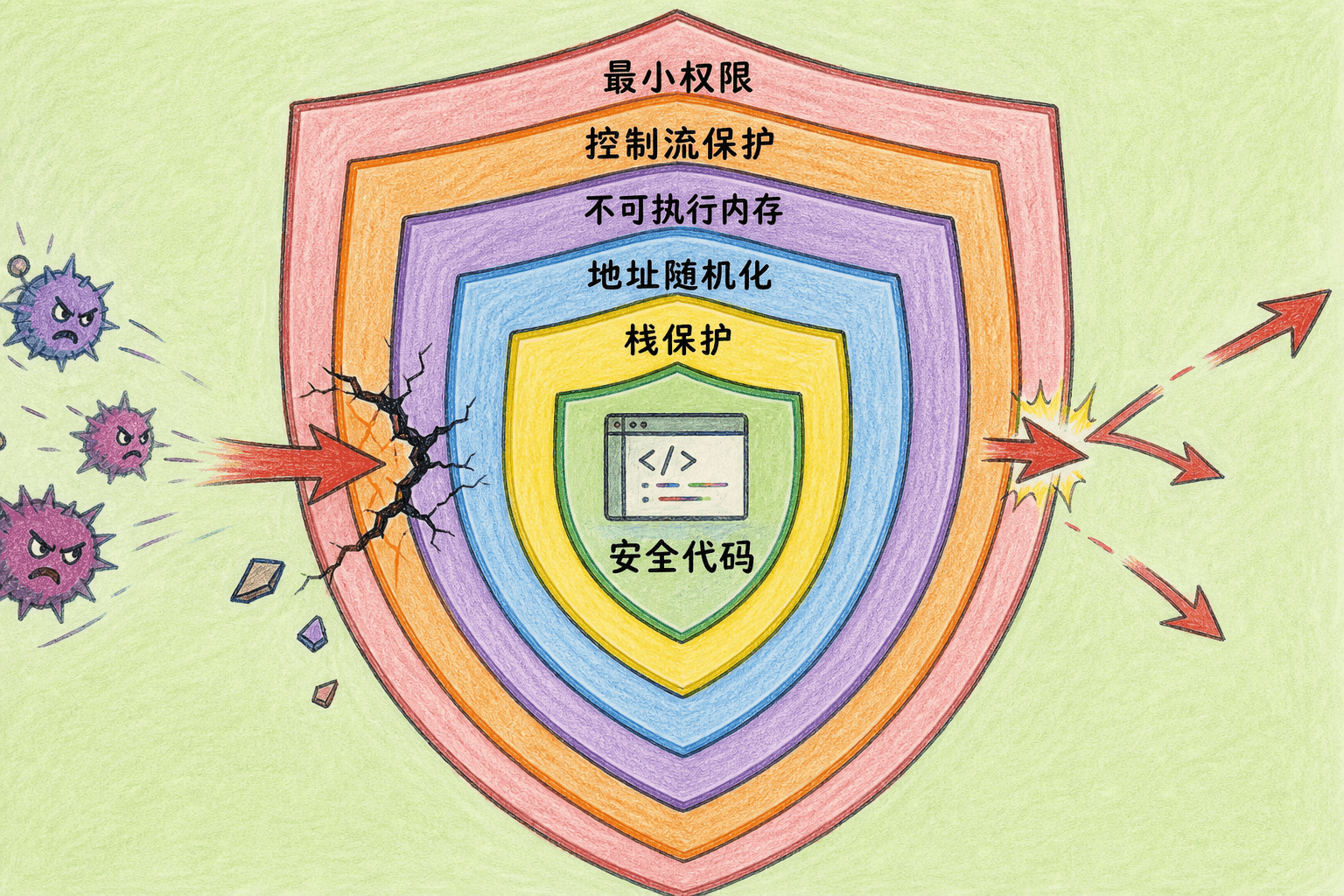
这些措施提高利用难度,却不能替代源代码修复。信息泄露可能削弱地址随机化,逻辑数据破坏不一定触发栈保护,合法代码复用也可能绕过不可执行内存。发布构建应启用平台支持的加固选项,测试构建再配合地址、未定义行为和模糊测试工具。
4
启用栈保护后,程序中的所有越界错误都已被修复。
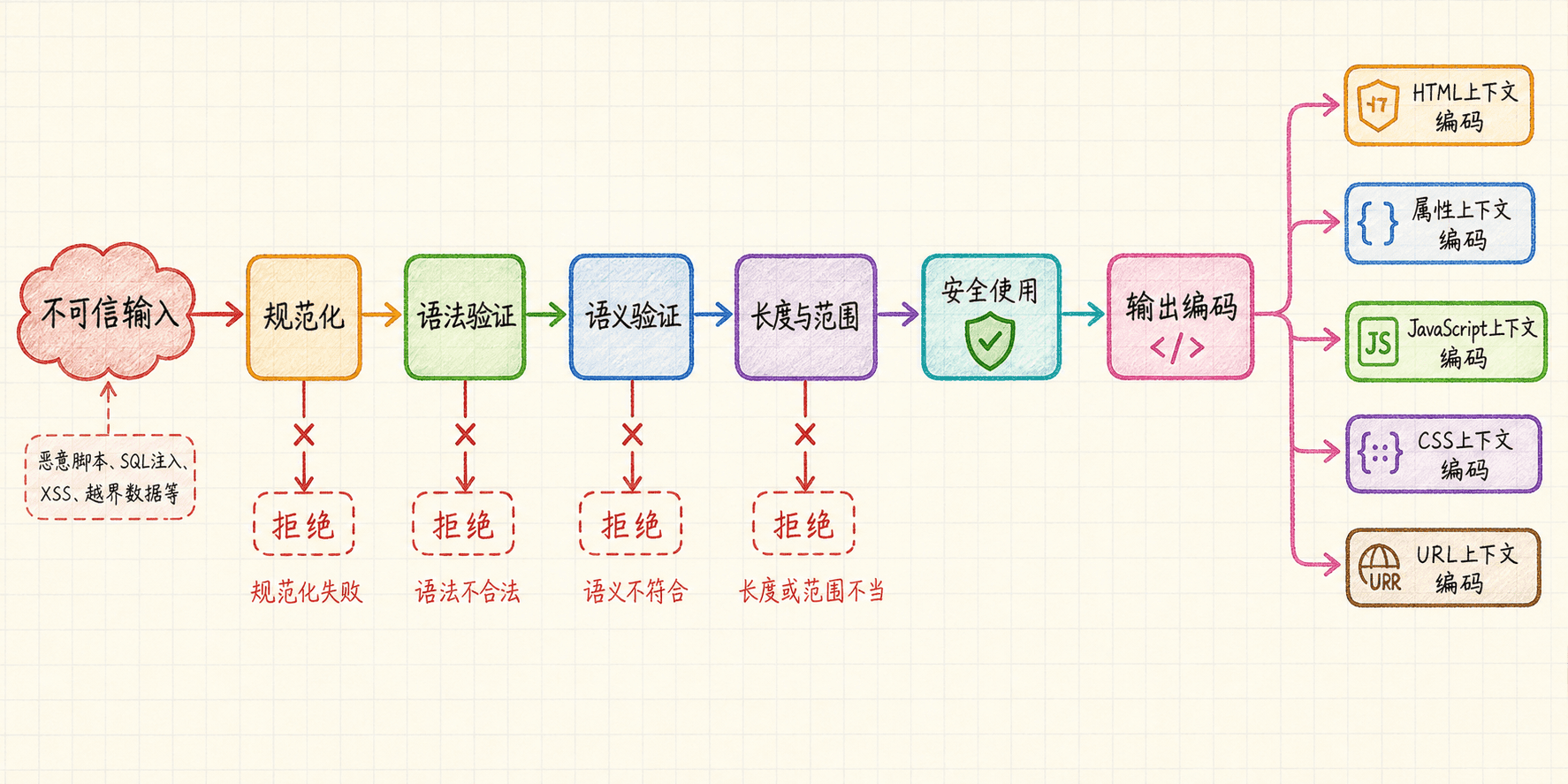
输入验证:规范化、语法与语义
验证顺序应清晰:先按协议解码并规范化,再检查整体长度与结构,然后验证类型、允许字符、数值范围、字段关系和当前业务状态。验证必须在服务端权威边界进行,并对整条输入完成;只删除“危险字符”的黑名单容易被编码、替代语法和多阶段解析绕过。
文件名与路径尤其需要注意规范化后的结果,不能只检查原始字符串。数值转换要处理空值、符号、进制、溢出与尾随字符。自由文本可以允许丰富内容,但进入 SQL、HTML、网址或命令时必须使用相应安全接口,而不是企图用一次“清理”适配全部上下文。
5
可靠输入验证通常包含哪些步骤?
安全代码、状态与错误处理
安全代码应最小化共享可变状态,明确对象所有权和生命周期,检查每个关键返回值,并在异常时进入安全状态。认证或授权组件出错时默认拒绝;事务失败时回滚;临时权限使用后立即释放;敏感缓冲区在不再需要时按平台能力清理。
竞争条件常来自“先检查、后使用”:检查文件属性后再打开,目标可能已经被替换。应使用原子操作、不可预测且安全创建的临时文件、适当锁和句柄级验证。日志要保留诊断价值,但不能记录口令、密钥、会话令牌或完整敏感输入。
6
权限检查服务异常时,最符合失败安全的行为是什么?
与操作系统和其他程序安全交互
程序调用命令解释器时,外部输入可能改变命令结构。应优先调用目标程序并传递参数数组,而不是拼接命令字符串;可选动作使用固定映射。环境变量、搜索路径、当前目录、文件权限和资源限制都属于执行上下文,特权程序不能盲目信任它们。
文件操作应限制根目录,规范化后确认路径仍在允许范围内,防止符号链接和路径穿越;创建文件时采用最小权限和排他创建。子进程应继承尽可能少的句柄、环境和权限,并设置时间、内存、输出大小与进程数上限。
7
安全启动外部程序的做法有哪些?
输出处理与上下文编码
输入验证不能替代输出编码。同一字符串放在网页正文、属性、脚本、样式和网址组件中,解释规则不同,必须在最终输出点按上下文编码。模板应默认转义;需要富文本时使用经过审计的结构化净化器,并限制允许的元素、属性和协议。
响应头要设置正确内容类型和字符集,下载内容应避免被浏览器误判为可执行页面。错误响应不应泄露堆栈、内部路径、查询或密钥信息,但服务器端应记录关联编号和必要上下文用于调查。
8
对网页正文做过一次编码后,该值可以原样安全用于脚本和网址参数。
原理案例:边界读取与命令解释
Heartbleed 类问题的核心是“声明长度”与真实数据长度不一致,程序信任外部长度而越界读取,导致相邻内存随响应泄露。防御重点是交叉验证长度、使用内存安全抽象、最小化进程中的秘密,并在修复后轮换可能泄露的密钥。
Shellshock 类问题的核心是数据跨越环境变量与命令解释器边界后被重新解释为代码。防御重点是及时修补、避免不必要的解释器、清理执行环境、使用参数化进程接口和最小权限。这些案例用于理解边界与解释层次,不需要复现可滥用步骤。
9
两个案例共同揭示了什么?
安全实践与小结
我们在沙盒环境中编译并运行了一个只演示修复的 C 程序。函数在复制前比较源长度与目标容量,构建启用 -Wall -Wextra -Werror -O2 -fstack-protector-strong。真实输出如下:
text
input_len=6 result=accepted value=xiaohu
input_len=21 result=rejected
tmp/safe-copy-protected: Mach-O 64-bit executable arm64第一次输入可连同结束符放入8字节数组,第二次在复制前被拒绝,没有触发越界。程序安全由正确边界检查打底,再叠加编译器保护、输入验证、安全系统接口、上下文输出编码、最小权限、日志和测试。
10
本次实践体现了哪些安全做法?