泛型算法:把数据清洗写成可验证的流水线
一批请求日志到达内存后,程序通常要做几件事:丢掉非法记录,统一服务名,按延迟排序,合并重复项,再统计慢请求。如果每一步都手写循环,边界判断、目标空间和删除规则会散落在代码里,很难确认哪一步改变了数据。
C++ 的泛型算法把这些动作整理成一组统一接口。算法面对的不是某一种容器,而是迭代器描述的范围;业务规则则通过谓词、函数对象或 lambda 传入。这样,同一套处理逻辑可以用于完整容器,也可以只处理其中一段。
本文以 C++17 为基准。重点不是背算法名,而是读懂四件事:输入范围是什么、算法需要哪类迭代器、会不会写入数据、返回的迭代器表示什么。
先把一次清洗任务拆成算法流水线
假设每条记录包含到达序号、服务名和延迟:
cpp
struct Request {
int sequence;
std::string service;
int latency_ms;
};一条可维护的清洗流程可以拆成下面几段:
这不是必须照搬的固定顺序。顺序来自业务语义:如果大小写不同的服务名应视为同一个服务,就要先规范化再排序和去重;如果先去重,"API" 与 "api" 会被当成不同值。
给每次算法调用写一张契约卡
看到一个算法调用时,可以按四个问题检查:
- 输入是哪个
[first, last)范围? - 算法只读、写入,还是重排元素?
- 返回值是命中位置、输出末端,还是新的逻辑末端?
- 调用前必须满足哪些条件,例如目标空间、排序状态或迭代器能力?
例如,下面两行看起来都返回迭代器,含义却不同:
cpp
auto found = std::find(values.begin(), values.end(), 42);
auto new_end = std::remove(values.begin(), values.end(), 42);found 指向第一个值为 42 的元素,找不到时等于 values.end()。new_end 则划出“保留元素”的逻辑范围 [values.begin(), new_end);它不是一次查找结果。
算法名只说明动作,完整语义还包括范围、迭代器要求、前置条件和返回约定。先读这四项,再把算法接入流水线。
小节测试
1
阅读一个陌生算法调用时,最先应确认什么?
2
日志清洗流水线中,哪些顺序依赖业务语义?
从半开范围读懂返回迭代器
标准算法通常用 algorithm(first, last, ...) 表示输入范围。这个范围写作 [first, last):包含 first 指向的元素,不包含 last;last 是尾后位置,不能解引用。空范围自然表示成 first == last,算法无需额外的“空容器分支”。
find 返回命中位置或传入的 last
find 从前向后查找,返回第一个等于目标值的元素。找不到时,它返回调用者传入的 last。如果查找的是子范围,失败值就是子范围的终点,不一定是整个容器的 end()。
下面的程序只查下标 [1, 4),所以会检查 42.5、7.0、42.5:
cpp
#include <algorithm>
#include <iostream>
#include <iterator>
#include <numeric>
#include <vector>
int main() {
const std::vector<double> latency{18.5, 42.5, 7.0, 42.5, 31.5};
auto first = latency.cbegin() + 1;
auto last = latency.cbegin
输出:
text
命中下标: 1
99 未找到: true
42.5 出现: 2 次
整数初值: 140
浮点初值: 142只有在 found != last 后才能写 *found。如果先解引用再检查,就可能读取尾后位置,行为未定义。
count 返回数量,accumulate 返回累加器
count 和 count_if 返回匹配数量,不返回位置。accumulate 定义在 <numeric>,它把 [first, last) 中的值依次合并到初值,并返回最终累加器。
初值不仅是“从多少开始”,还决定累加器类型。上例用 0 时,累加器是 int,每一步的小数部分都会在赋回累加器时丢失;用 0.0 时,累加器是 double。
四参数重载可以替换加法,例如传入 std::multiplies<double>{} 计算乘积。此时初值应是单位元 1.0;若误用 0.0,非空范围的结果也会一直是零。
返回迭代器要立即解释
常见返回约定可以这样区分:
返回值接到 auto 里并不会自动记录这些语义。变量名应写成 found、output_end 或 new_end,让后续代码知道该怎样使用它。
小节测试
3
对任意非空容器,end() 都可以先减一并解引用。
4
std::find(first, last, value) 未找到目标时返回 ____。
让迭代器能力匹配算法要求
迭代器不是一种固定类型,而是一组操作能力。算法只要求完成工作所需的最低能力;容器或适配器提供的迭代器必须达到这个要求。
五类能力逐步增加
这里的层次描述能力,不是类继承关系。随机访问迭代器也能完成双向和前向操作,但反过来不成立。
算法要求决定能否调用
因此,std::find、std::reverse 和 std::unique 都可以处理 list 的范围,std::sort 不行。链表要使用自己的 list::sort()。
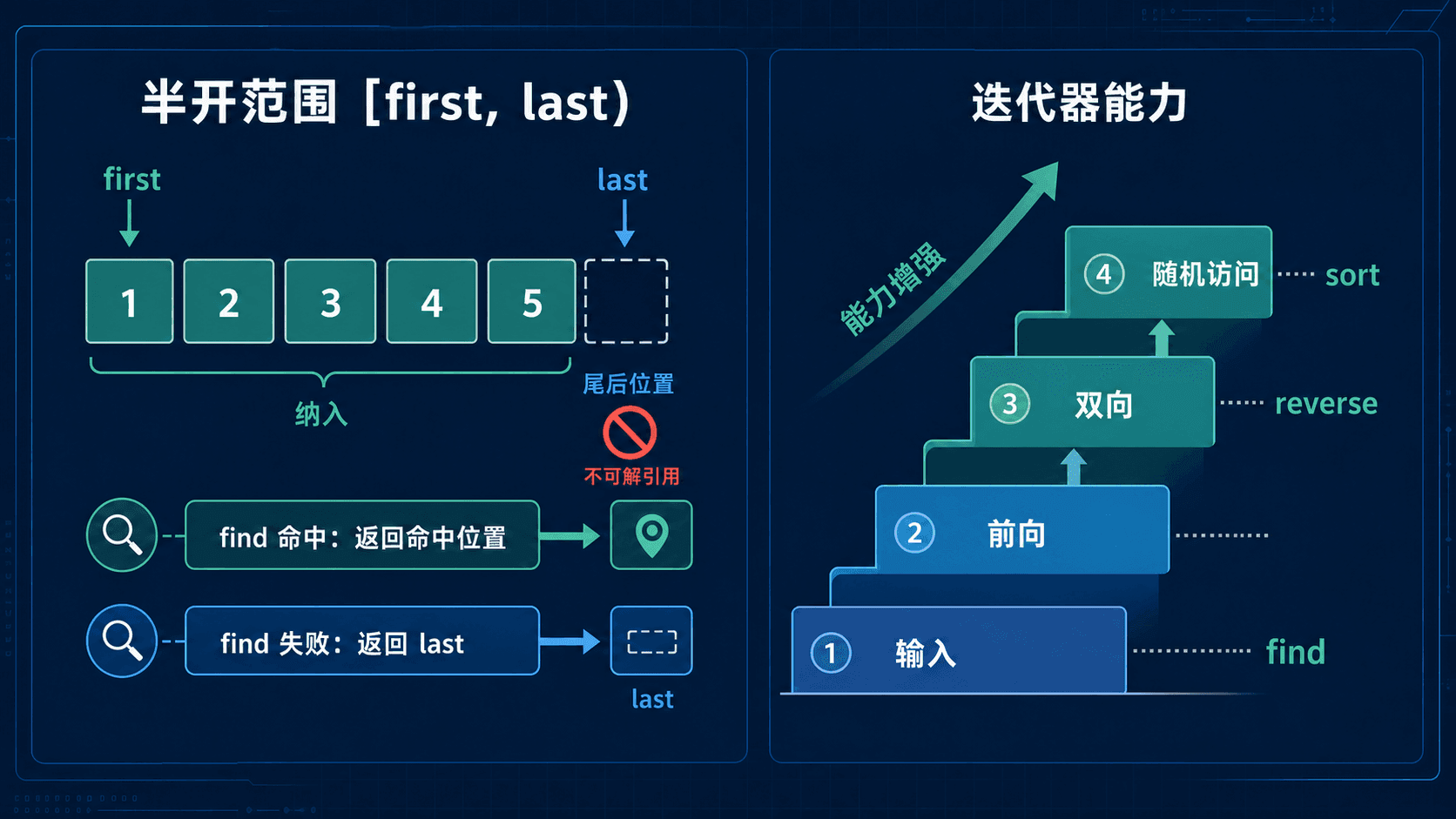
[first, last) 让尾后位置自然充当失败哨兵;算法能否调用,则取决于迭代器是否达到输入、前向、双向或随机访问的最低能力。advance 与 distance 隐藏了不同成本
通用代码可以用 std::advance(it, n) 移动迭代器,用 std::distance(first, last) 计算距离。对随机访问迭代器,它们通常能直接加减;对链表,它们需要逐个节点前进,成本与距离成正比。
输入流迭代器更特殊:它是单遍输入。用 distance 走过一段流会消费输入,不能再假设旧副本仍指向可重复读取的同一序列。
不要因为迭代器支持 ++ 就假设它也支持 + n、相减或重复遍历。泛型代码应使用算法承诺的最低能力,并把成本一起考虑。
小节测试
5
下列哪些泛型算法可以直接处理 std::list<int> 的迭代器范围?
6
哪一种迭代器主要承诺单遍读取?
分清只读、写入与重排算法
按行为给算法分类,比按名字背清单更实用。分类能直接提示 const、目标空间和迭代器失效风险。
只读算法观察范围
find、find_if、count、count_if 和 accumulate 都只读输入范围。传入 cbegin()、cend() 可以把只读意图写进类型:
cpp
auto slow = std::count_if(requests.cbegin(), requests.cend(),
[](const Request& request) {
return request.latency_ms >= 100;
});谓词也应只判断属性。不要在 count_if 的谓词里修改元素或依赖调用次数;算法可能复制可调用对象,调用顺序之外的细节也不应成为业务状态。
写入算法需要真实的目标位置
copy 和 transform 的输出参数通常只是一个起点。它不携带容器边界,也不会让空 vector 自动增长。
cpp
#include <algorithm>
#include <iostream>
#include <iterator>
#include <vector>
int main() {
const std::vector<int> source{3, -1, 5, -2};
std::vector<int> copied(source.size());
auto output_end = std::copy(source.cbegin(), source.
输出:
text
写入数量: 4
绝对值: 3 1 5 2 copied 和 absolute 都先构造了四个元素,因此 begin() 后有足够的可写位置。下面的写法不成立:
cpp
std::vector<int> empty;
// std::copy(source.begin(), source.end(), empty.begin()); // 没有可写元素目标需要增长时,使用 back_inserter(empty)。如果目标长度固定,则先按所需大小构造或 resize。
重排算法不等于改变容器大小
sort、stable_sort、reverse、remove 和 unique 会移动或交换元素。普通算法只看到迭代器,不知道背后是不是容器,所以通常不能调用容器的插入或删除成员。
重排后,原来的迭代器可能仍是一个可用位置,却不再指向原来那条业务记录。随后若再调用 erase,还会触发容器自己的失效规则。稳妥做法是分阶段处理,每次重排或结构修改后重新取得所需位置。
写入范围还有重叠前置条件
普通 copy 不能随意把一个范围复制到与它重叠的右侧位置。需要在同一序列内向右搬移时,通常使用 copy_backward;向左复制时则让目标起点位于输入起点之前,并确认接口的重叠条件。
这类代码若只是“在一次运行中输出正确”,不能证明没有越界或重叠错误。边界条件必须从算法契约确认。
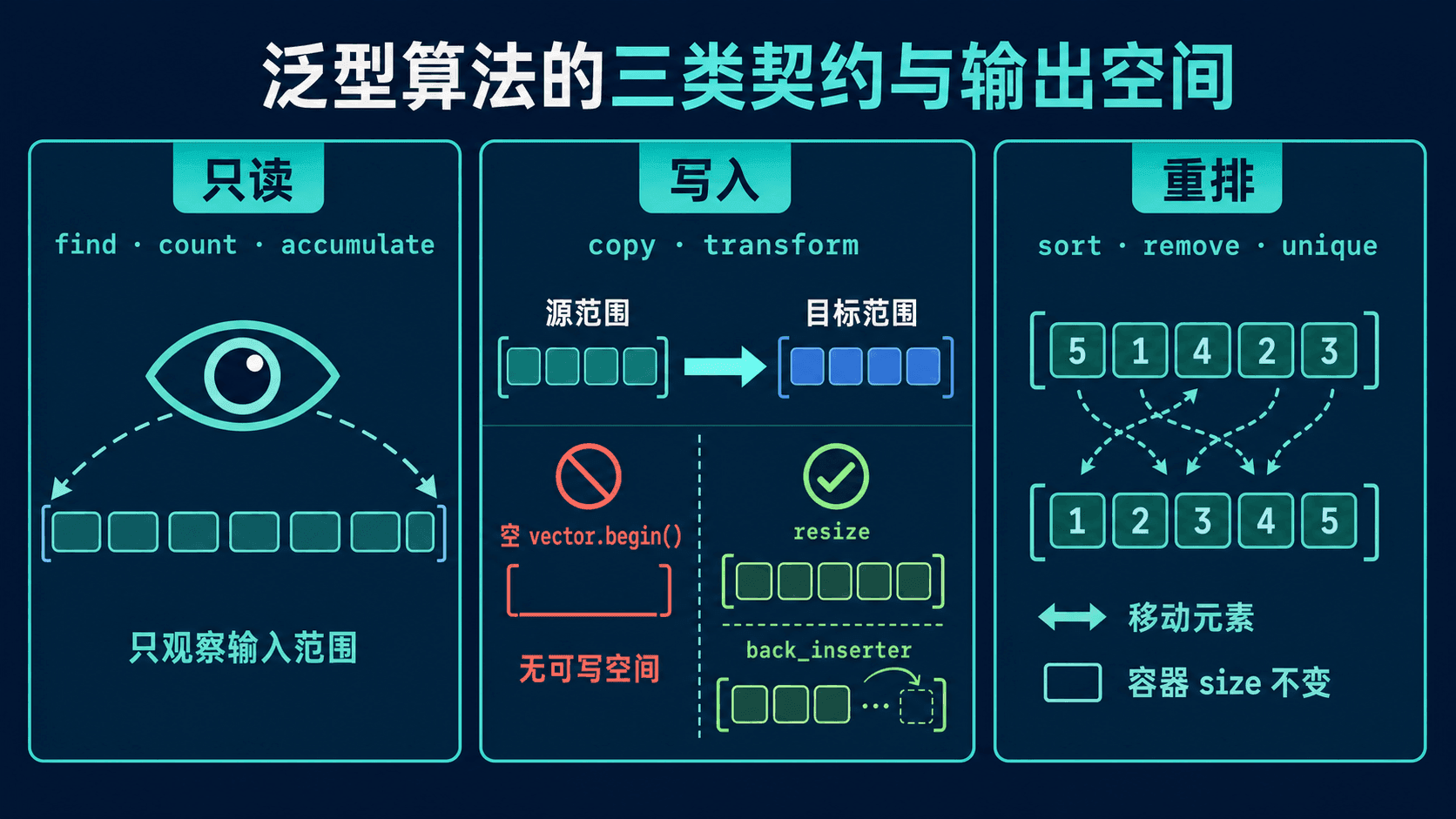
vector 的 begin() 并不是可写空间。小节测试
7
向 target.begin() 复制 N 个元素前,target 的 ____ 至少应为 N。
8
std::transform 把结果写到空 vector 的 begin() 时,会自动调用 push_back。
用稳定排序和逻辑尾完成清洗
数据清洗经常需要“排序后去重”和“按条件删除”。这两条链都依赖一个关键概念:算法先得到逻辑结果,容器成员再真正改变大小。
sort 与 stable_sort 的差别是业务承诺
sort 默认按 < 排成非降序,不保证等价元素保持原有顺序。stable_sort 会保留等价元素的相对顺序,适合“同一优先级仍按到达顺序处理”的场景。
cpp
#include <algorithm>
#include <iostream>
#include <iterator>
#include <string>
#include <vector>
struct Event {
std::string service;
int latency_ms;
int arrival;
};
int main() {
std::vector<Event> events{
{"api", 80, 1},
{"web",
输出:
text
稳定排序: web#2 api#3 web#4 api#1 api#5
unique 后 size: 6
逻辑长度: 3
最终标签: debug warn 延迟同为 40 的三条记录仍按到达序号 2、3、4 排列;延迟同为 80 的记录仍是 1、5。这正是稳定性带来的业务结果。
比较器必须是严格关系
排序比较器回答“左边是否严格排在右边之前”。相等时必须返回 false,所以常见写法是 <,不能改成 <=。
比较器还应保持一致:不能这次比较按延迟、下次比较随机改成按服务名,也不应在比较时修改记录。算法用下面的条件判断两个值在排序意义下是否等价:
cpp
!comp(a, b) && !comp(b, a)这种等价不要求 a == b。例如只按延迟排序时,服务名不同但延迟相同的两条记录仍属于同一排序等价组。
unique 只折叠相邻重复项
unique 把每组相邻等价项的第一个保留在前部,返回新的逻辑末端。它不会改变 size()。上例先排序,是为了让相同标签相邻。
[unique_end, tags.end()) 仍是容器的一部分,其中对象仍然有效,但值不应再被业务依赖。随后调用 erase(unique_end, tags.end()) 才会真正缩短 vector。
如果必须保留第一次出现的全局顺序,就不能为了去重随意排序。可以把结果逐个加入新序列并检查是否已出现;数据量大时,再选择专门的索引结构。
remove 也返回逻辑尾
remove 和 remove_if 把要保留的元素移到前部,并返回逻辑末端。经典 erase-remove 写法是:
cpp
values.erase(std::remove_if(values.begin(), values.end(),
[](int value) { return value < 0; }),
values.end());remove_if 阶段不缩短容器,erase 阶段才删除尾部。不要把逻辑尾之后的元素理解成一份可靠的“被删除项列表”。
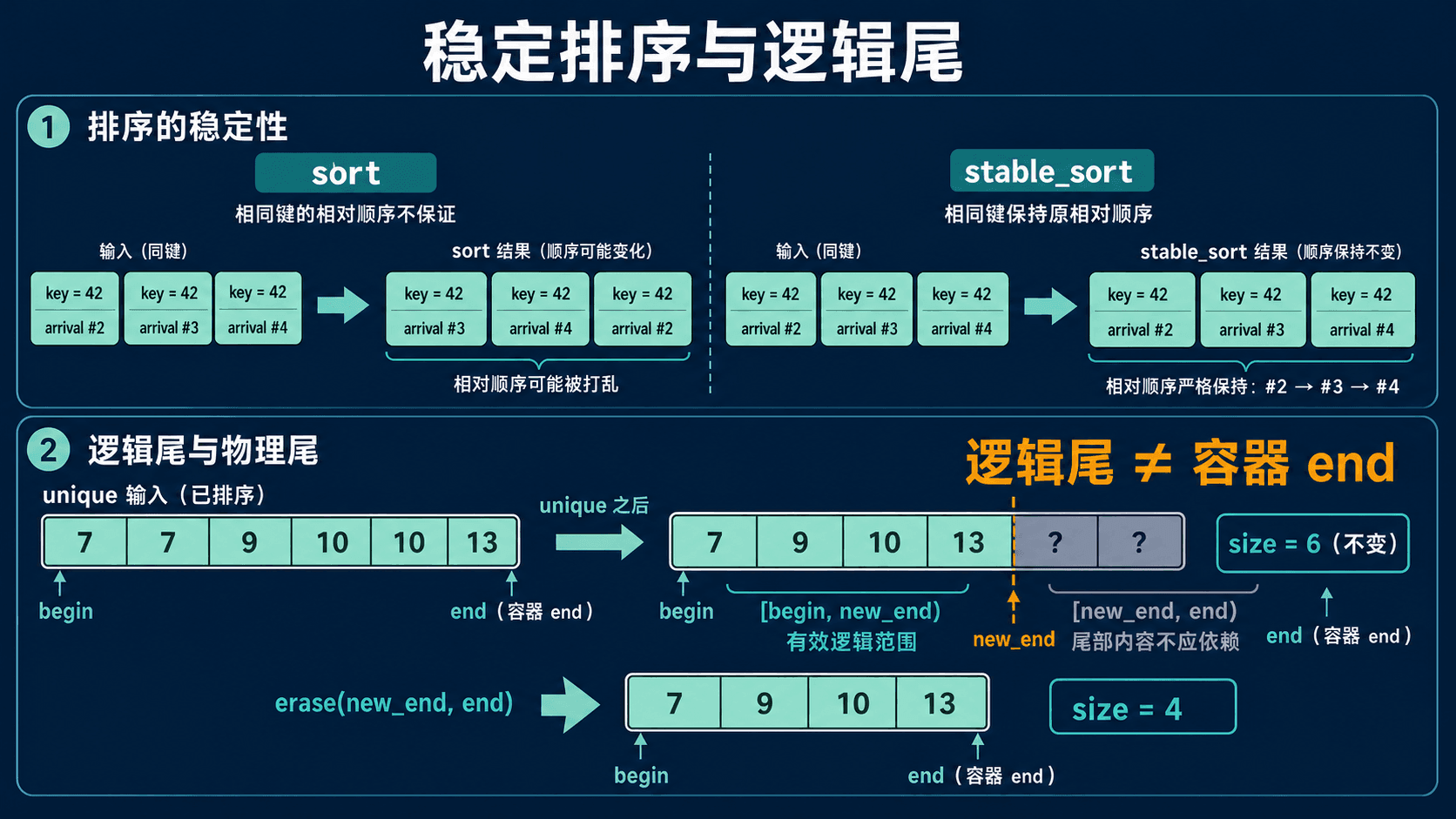
stable_sort 保留等价项的原相对顺序;unique 只把有效结果整理到 [begin, new_end),随后调用 erase(new_end, end) 才会把物理大小从 6 缩到 4。小节测试
9
同一优先级的任务必须继续保持到达顺序,应使用哪个排序算法?
10
关于 remove 和 unique,哪些说法正确?
用谓词和可调用对象表达业务规则
算法把遍历和边界处理固定下来,把“什么算命中”“谁排在前面”留给可调用对象。函数、函数对象、lambda 和 std::bind 产生的适配器,只要调用签名匹配,都能承担这个角色。
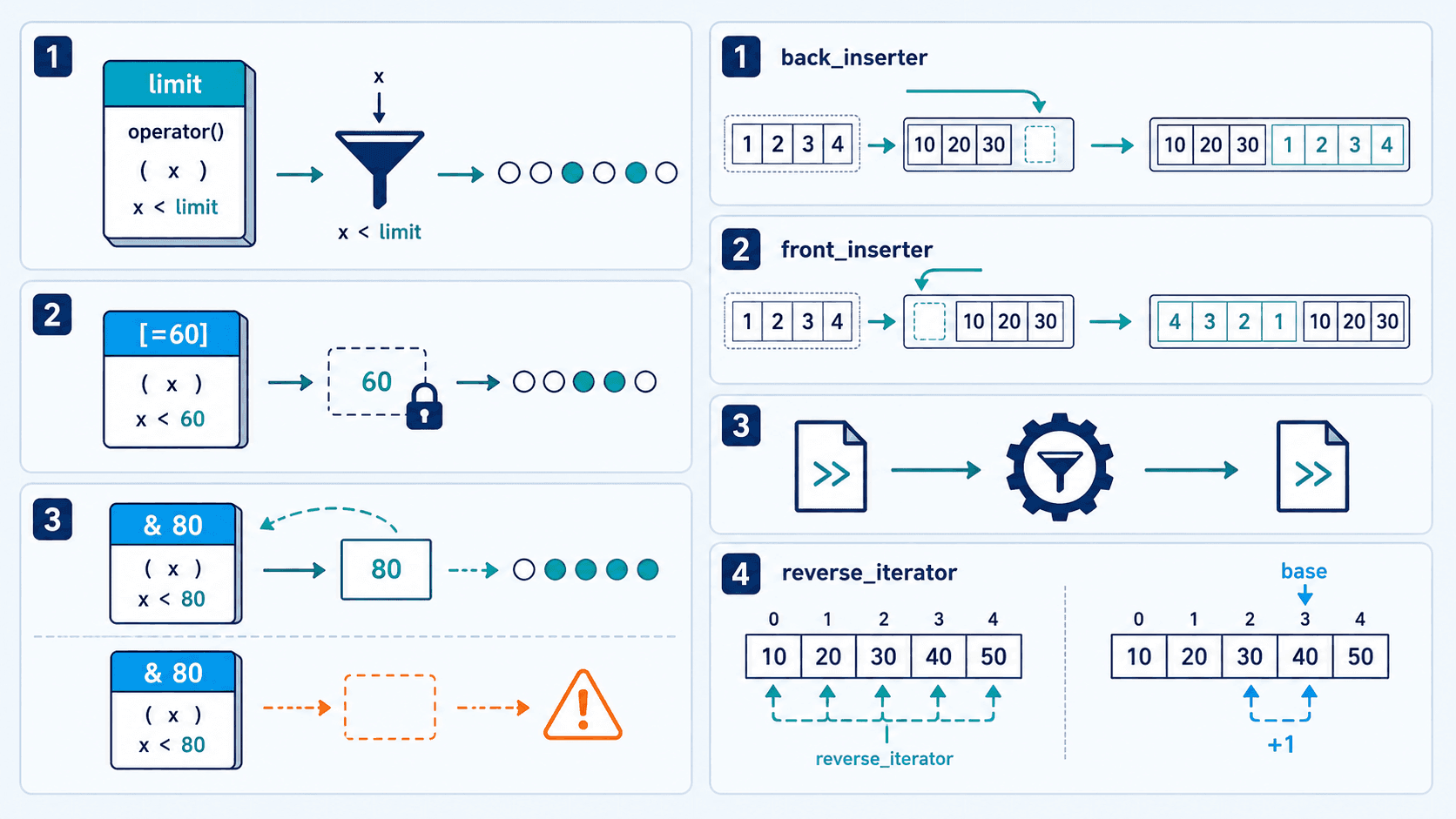
一元谓词筛选,二元谓词比较
find_if、count_if、copy_if 和 remove_if 使用一元谓词:每次接收一个元素。sort 使用二元比较器:每次接收两个元素。
谓词返回的值要能转换成 bool。它应该表达稳定的判断,不要把日志输出、计数器修改或随机数塞进排序比较器。
函数对象能携带状态
一个定义了 operator() 的对象可以保存阈值:
cpp
struct AtLeast {
int limit;
bool operator()(int value) const {
return value >= limit;
}
};AtLeast{60} 是一个保存阈值 60 的可调用对象。算法调用它时,语法仍是 predicate(value)。
lambda 的捕获决定它看到哪份状态
下面的程序同时演示函数对象、值捕获、引用捕获和 bind:
cpp
#include <algorithm>
#include <functional>
#include <iostream>
#include <vector>
struct AtLeast {
int limit;
bool operator()(int value) const {
return value >= limit;
}
};
bool within(int value, int low, int high) {
输出:
text
至少 60: 3
值捕获: 3
引用捕获: 1
全部合法: true[threshold] 在创建时保存副本,所以仍使用 60;[&threshold] 读取外部对象,所以看到修改后的 80。
引用捕获不会延长局部变量的生命周期。若 lambda 被保存到更长寿命的对象中,局部变量销毁后再调用它,捕获的引用就会悬空。
mutable 只修改捕获的副本
值捕获在 lambda 的调用运算符中默认只读。[count = 0]() mutable { return ++count; } 可以修改闭包对象里的副本,却不会修改外部变量。算法还可能复制可调用对象,因此不要把这类内部计数当成可靠的全局调用次数。
bind 用于适配已有调用接口
std::bind(within, _1, 0, 100) 固定了 low 和 high,保留第一个参数等待算法传入。绑定参数默认按值保存;需要明确保存引用时,使用 std::ref 或 std::cref。
简单规则通常用 [](int value) { return within(value, 0, 100); } 更清楚。bind 仍常见于适配已有多参数函数和阅读既有代码,理解占位符与复制规则很有必要。
小节测试
11
lambda 按引用捕获局部变量后,即使局部变量已经销毁,捕获仍然安全。
12
函数对象通过重载 ____ 获得函数调用语法。
用特殊迭代器连接容器与流
普通容器迭代器指向已经存在的元素。迭代器适配器可以改变“读取、写入、前进”的含义,让算法直接追加容器、读写流或反向观察序列。
三种插入迭代器
front_inserter 每次都在开头插入,所以输入顺序会反转。inserter 会更新自己保存的位置,连续插入可以保持输入顺序。
插入会改变容器结构。不要把同一容器中可能失效的普通迭代器同时保存在外部,再假设算法追加后它仍然有效。
流迭代器把输入输出变成序列
istream_iterator<T> 在构造和每次前进时从输入流取得一个 T,解引用读取当前值;默认构造的实例表示输入结束。ostream_iterator<T> 把赋值转换成 <<,还可以在每个值后输出分隔符。
反向迭代器的 base 有一个位置偏移
rbegin() 指向反向序列的第一个元素,也就是原序列最后一个元素;rend() 表示反向序列的尾后位置。
反向迭代器 rit 的 base() 指向 rit 所指元素之后的正向位置。这个偏移让“最后一个分隔符之后的内容”很好截取。
下面的程序把三类适配器放在一起:
cpp
#include <algorithm>
#include <iostream>
#include <iterator>
#include <list>
#include <sstream>
#include <string>
#include <vector>
int main() {
std::istringstream input{"8 -3 5 2"};
std::vector<int> numbers{
std::istream_iterator<int>{input},
std::istream_iterator<int>{}
};
std::vector<int> nonnegative;
输出:
text
非负数: 8 5 2
头插结果: 2 5 -3 8
文件名: report.csv流输入是单遍的。构造 numbers 后,输入已经被消费;如果格式错误,输入迭代器也会进入结束状态。复杂格式、逐行错误报告和恢复逻辑通常更适合显式读取。
ostream_iterator 会在每个值后放分隔符,因此上例最后一个数字后也有空格。如果输出格式不允许尾随分隔符,需要单独处理第一个或最后一个元素。
若要从反向命中位置取得对应的正向元素,应在确认 rit != rend() 后使用 std::prev(rit.base())。直接把 base() 当成同一元素,会偏移一位。
小节测试
13
把 copy_if 的结果追加到空 vector,最合适的输出迭代器是什么?
14
反向迭代器 rit 与 rit.base() 指向正向序列中的同一个元素。
处理链表专用操作并组装完整流水线
泛型算法只通过迭代器观察序列,无法利用链表节点的内部连接。list 因此提供一组成员算法,直接重连、删除或转移节点。
list 成员算法与同名泛型算法不同
list::remove_if 会改变链表大小,不需要 erase-remove。list::unique 仍只处理相邻等价项,若要全局去重,仍要先使等价项相邻。
merge 不负责先排序。两个输入必须已经按同一个比较规则有序;否则不满足前置条件。
splice 转移节点身份
下面的程序先合并两个有序队列,再把紧急队列整体接到前面,最后删除一个已取消任务:
cpp
#include <iostream>
#include <list>
#include <string>
struct Job {
int priority;
std::string name;
};
int main() {
auto by_priority = [](const Job& left, const Job& right) {
return left.priority < right.priority;
};
std::list<Job
输出:
text
incoming: 0
urgent: 0
ready: hotfix cache index report 指向被转移节点的迭代器仍然有效,但节点现在属于目标链表的序列。指向被删除节点的迭代器会失效。使用自定义分配器时,参与 splice 的链表还必须满足分配器兼容条件;同一链表内部转移一个范围时,目标位置不能落在被转移范围内部。
一次完整的请求清洗
下面的程序把本文的主要规则连成一条可运行流水线:
cpp
#include <algorithm>
#include <cctype>
#include <iostream>
#include <iterator>
#include <numeric>
#include <string>
#include <vector>
struct Request {
int sequence;
std::string service;
int latency_ms;
};
int main() {
std::vector<Request> requests{
{1, "API",
输出:
text
清洗后:
api 80 #2
api 120 #1
db 90 #8
web 200 #4
慢请求: 2
平均延迟: 122.5
慢请求列表: api#1 web#4 规范化字符时,先把 char 转成 unsigned char 再交给 std::tolower,可以避开负 char 带来的未定义行为。统计平均值时用 0.0 建立浮点累加器。
这条流水线在每个结构修改之后都重新使用容器的当前范围,没有把旧迭代器带到下一阶段。排序比较器与 unique 的等价规则也使用同一组业务键,因此相邻去重的前置条件成立。
落地时的检查顺序
- 先写清输入范围和空范围行为。
- 再核对迭代器能力与算法最低要求。
- 写入算法要确认目标已经有元素,或使用插入迭代器。
- 排序、合并、有序查找要确认比较规则和有序前置条件。
remove、unique后立即处理逻辑尾,不读取尾部猜测结果。- 结构修改和重排之后,重新取得业务需要的位置。
小节测试
15
关于 std::list 的成员算法,哪些说法正确?
16
对 vector 调用 unique 得到逻辑尾后,还要调用成员函数 ____ 才会真正缩短容器。