C++17 专用标准库设施:让数据、规则与格式各归其位
标准库里有一些工具很难归入“容器”或“算法”这样的主线,却会频繁出现在真实程序中。函数需要一次返回几项临时结果,可以用 std::tuple;固定数量的布尔开关,可以用 std::bitset;文本要按模式验证或提取,可以用 std::regex;测试需要可重放的随机样本,可以组合随机引擎与分布;输出需要稳定的列宽和精度,则交给流操纵符。
这些工具解决的是不同问题。用得恰当时,代码会更短,边界也更明确。把它们混用或放错位置,反而容易得到位置含义不清的元组、难以维护的巨大正则、不可复现的随机测试,以及悄悄污染后续输出的流状态。
本文以 C++17 为基准,从“该不该选这个工具”开始,再分别处理对象模型、异常、状态持续时间和可测试性。最后会把五类设施组合成一个可编译的小程序。
选择专用设施时,先问数据的形状是否稳定,再问规则发生在编译期还是运行时,最后确认对象是否保存状态。类型、长度和状态持续时间一旦判断错,局部写法再精巧也很难补救。
先按问题形状选择工具
元组适合短暂的异构结果
std::pair 表示恰好两项数据,std::tuple 把同样的做法扩展到任意项数。
它们最适合局部、短暂、调用者立刻拆开的结果。例如解析函数同时返回“是否成功、读到的数量、耗时”,这些值只在函数边界上传递一次,调用端马上给它们命名。
如果这些字段会进入长期业务模型,位置就不够用了。std::get<2>(value) 无法告诉读者第三项是耗时、比例还是错误码。此时应定义带命名成员的 struct。
例如,std::tuple<bool, int, double> 可以表示一次检查的“是否通过、数量、耗时”。同一组值若会长期保存,则应改成带 accepted、token_count 和 elapsed_ms 成员的 Inspection 结构体。
第一种形式适合很小的函数边界。第二种形式适合跨模块保存、扩展或反复传递的数据。
固定位集合不等于动态布尔序列
std::bitset<N> 的 N 是类型的一部分,必须在编译期确定。
协议中的 8 个标志位、设备寄存器的 16 个开关、固定权限表的 32 个槽位,都符合这个形状。长度来自用户输入,或位数会在运行时增长时,就不应强行使用 bitset。
固定 8 位可以声明 std::bitset<8> protocol_flags;运行时长度则需要动态序列。
vector<bool> 有特殊的压缩表示和代理引用语义。若代码需要普通布尔对象的引用行为,也可以改用 std::vector<unsigned char>。这里的重点不是给动态位序列指定唯一答案,而是不要让 bitset 承担运行时改长度的任务。
正则描述文本形状,不证明业务语义
正则表达式适合说明文本“长什么样”。账号由哪些字符组成、日志里是否出现某类编号、配置行能否分成几个字段,都可以先用模式描述。
正则不会自动理解业务。例如 2026-99-99 可以通过一个只检查“4 位数字、短横线、2 位数字、短横线、2 位数字”的模式,但这不是有效日期。
复杂的递归语法、带转义嵌套的语言、高吞吐热路径,也不一定适合交给一个越来越大的模式。此时分阶段解析或使用专用解析器更清楚。
随机引擎与分布各管一层
随机引擎产生一个确定的伪随机整数序列。分布把引擎的输出映射到需要的范围或数学形状。
想把整数范围从 1..6 改成 10..20,通常只改分布。想固定测试序列,才设置引擎种子。直接计算 engine() % n 会自行承担映射偏差等问题,不如使用标准分布。
操纵符修改流的解释方式
std::hex、std::fixed 和 std::setprecision 不只是“打印一个标记”。它们会改变流对象的格式状态,并可能影响后面的值。
std::setw 是显眼的例外:它只设置下一次格式化字段的宽度。专用输出函数若修改共享流而不恢复状态,调用者后面的输出可能在很远的位置才出错。
小节测试
1.1
下列哪些场景适合直接使用专用标准库设施?
1.2
程序把随机整数范围从 1..6 改为 10..20,通常应优先更换什么?
用 tuple 组织短暂的多返回值
构造和按位置访问
使用元组需要包含 <tuple>。可以直接写出元素类型,也可以让 std::make_tuple 根据实参推导。
cpp
std::tuple<bool, int, double> result{true, 4, 2.75};
auto another = std::make_tuple(false, 0, std::string{"empty"});
std::cout << std::get<0>(result) << ' '
<< std::get<
std::get<I> 的下标从 0 开始。I 是模板实参,不是普通函数参数,因此必须在编译期确定。
下面的循环思路不能用于按运行时位置访问异构元组:
cpp
// for (std::size_t i = 0; i < 3; ++i) {
// std::cout << std::get<i>(result); // 错误:i 不是编译期常量
// }这不是少了某个强制转换,而是元组各位置的类型可以不同。运行时的 i 无法决定表达式应该产生哪一种静态类型。
结构化绑定要分清值与引用
C++17 的结构化绑定可以立刻为各位置命名:
cpp
#include <iostream>
#include <string>
#include <tuple>
int main() {
auto record = std::make_tuple(std::string{"alpha"}, 3, true);
auto [name_copy, count_copy, enabled_copy] = record;
count_copy = 99;
auto& [name_ref, count_ref, enabled_ref] = record;
count_ref = 7
输出为:
text
99 7auto [...] 建立自己的绑定对象,修改它不会回写 record。auto& [...] 建立引用绑定,修改会作用到原元组。const auto& [...] 适合只读访问,并避免复制较大的元素。
结构化绑定看起来都像“给字段起名字”,但
auto、auto& 与 const auto& 的对象关系不同。需要回写时必须明确使用引用;只读且不想复制时使用常量引用。make_tuple 默认保存值
std::make_tuple(x) 通常保存衰减后的值。实参是左值,不代表元组会自动保存对它的引用。
cpp
int counter = 10;
auto by_value = std::make_tuple(counter);
auto by_reference = std::make_tuple(std::ref(counter));
std::get<0>(by_value) = 20;
std::get<0>(by_reference) = 30; // counter 变为 30最终输出 30。第一次赋值只改元组里的副本,第二次通过 std::reference_wrapper 回写 counter。
引用元组必须注意生命周期。不要让元组中的引用指向已经离开作用域的局部对象。
tie 把结果写入已有变量
结构化绑定会声明新名字。调用者已经有变量时,可以用 std::tie 生成引用元组,再进行元组赋值。
cpp
std::tuple<int, std::string, bool> load_status() {
return {200, "ready", true};
}
int code = 0;
bool ready = false;
std::tie(code, std::ignore, ready) = load_status();std::ignore 表示这个位置的值不需要保存。std::tie 里的其他位置引用已有变量,因此赋值会写入这些变量。
何时改成命名结构体
三项元组并没有天然优于结构体。可以用下面几条判断:
- 结果只在一个很短的局部调用链中出现,元组通常足够。
- 调用者总是立刻结构化绑定,位置含义也很稳定,元组仍可读。
- 字段需要文档、校验成员函数或默认值,应定义结构体。
- 字段会增加、删除或跨模块传递,应优先定义结构体。
- 多处出现
get<3>、get<4>这样的访问,通常说明位置已经遮住了语义。
小节测试
2.1
对元组使用 `auto [a, b] = value` 后,修改 a 一定会修改 value 的第一个元素。
2.2
用 std::tie 接收返回元组时,如果不需要第二项,可在该位置写 std::____。
用 bitset 表示固定数量的开关
位数属于类型
std::bitset<N> 表示恰好 N 个位。默认构造时所有位都是 0,也可以从无符号整数或只含 0、1 的字符串构造。
cpp
std::bitset<8> empty;
std::bitset<8> from_number{0b00101101u};
std::bitset<8> from_text{std::string{"10110000"}};输出中的字符串总是从高位写到低位。from_text 的最左字符进入高位,最右字符进入低位。
std::bitset<8> 与 std::bitset<16> 是不同类型。位数不能在对象构造后调整,也不能用运行时变量形成 std::bitset<n>。
bit 0 在打印结果的最右边
位下标从最低有效位开始。bits[0] 对应输出字符串最右侧字符,而不是最左侧字符。
cpp
#include <bitset>
#include <iostream>
int main() {
std::bitset<8> bits{"10010000"};
std::cout << bits << '\n'
<< bits.test(0) << ' '
<< bits.test(4) << ' '
<< bits.test
输出为:
text
10010000
0 1 1从 0 到 size()-1 逐位打印,会得到与标准流输出相反的方向:
cpp
for (std::size_t i = 0; i < bits.size(); ++i) {
std::cout << bits[i];
}
// 输出 00001001这种方向差异是位协议中常见的错误点。写转换代码时要明确外部文本的高低位顺序。
用具名枚举消除魔法下标
直接写 flags.set(5) 需要读者记住第 5 位的含义。固定功能位更适合配合枚举:
cpp
enum class Feature : std::size_t { logging = 0, preview = 4, metrics = 5 };
constexpr std::size_t index(Feature value) {
return static_cast<std::size_t>(value);
}
std::bitset<8> flags;
flags.set
set(pos) 把一位设为 1,reset(pos) 设为 0,flip(pos) 取反。无位置参数的版本会操作所有位。
查询接口包括:
count()返回 1 的数量。any()判断是否至少有一位为 1。all()判断是否每一位都为 1。none()判断是否每一位都为 0。test(pos)做带范围检查的读取。
test 与下标的边界不同
test(pos) 会检查位置,越界时抛出 std::out_of_range。带位置的 set、reset 和 flip 也会检查范围。
operator[] 适合位置已经由程序逻辑保证有效的情况,不提供同等的越界检查契约。
cpp
try {
std::cout << bits.test(20) << '\n';
} catch (const std::out_of_range& error) {
std::cout << "bad bit index: " << error.what() << '\n';
}处理外部输入换算出来的下标时,优先使用检查版本。内部常量下标则可以直接使用枚举转换后的值。
字符串、整数与异常
字符串构造要求被读取部分只含 0 和 1。遇到其他字符会抛出 std::invalid_argument。
to_string() 可以得到 0/1 字符串。to_ulong() 与 to_ullong() 可以转换为整数,但有效高位超过目标类型范围时会抛出 std::overflow_error。
cpp
try {
std::bitset<8> bad{std::string{"10x10000"}};
} catch (const std::invalid_argument&) {
std::cout << "flag text must contain only 0 and 1\n";
}bitset 不是标准容器,不提供普通的 begin() 和 end() 迭代器。需要逐位处理时,可以使用下标循环;需要交给容器算法时,先转换为合适的序列表示。
小节测试
3.1
一个 8 位 bitset 的初始字符串为 10010000,哪一项正确?
3.2
下列关于 std::bitset 的说法哪些正确?
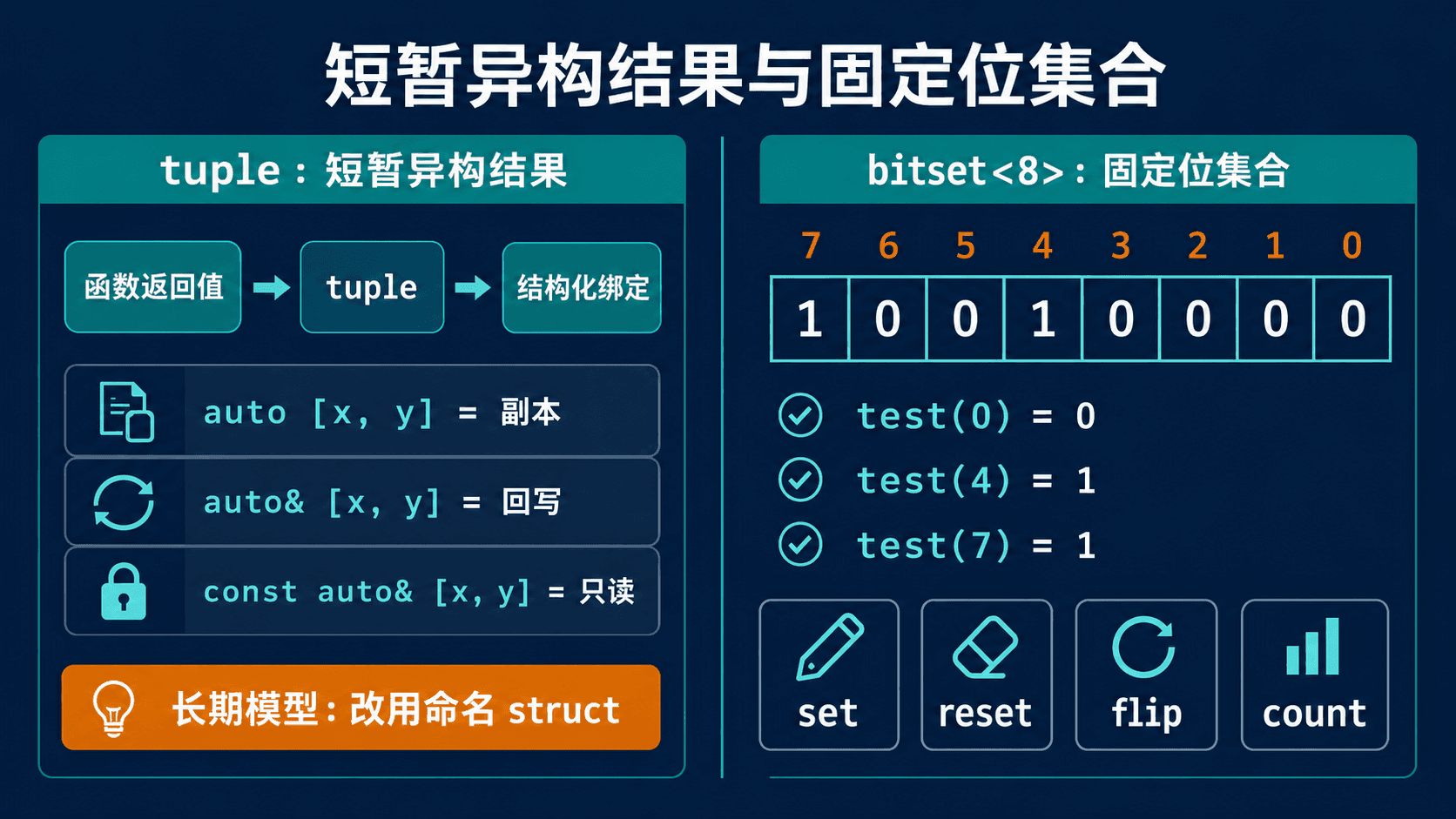
tuple 适合承载短暂异构结果,结构化绑定中的 auto、auto& 与 const auto& 分别对应副本、回写与只读;bitset<8> 则把固定八个位的方向和操作写进类型边界。用 regex 验证、搜索与改写文本
原始字符串让模式少一层转义
C++ 字符串和正则语法都使用反斜杠。普通字符串字面量会让两层转义叠在一起:
普通字符串需要写成 "^[A-Za-z]+\\\\s+\\\\d{4}$"。原始字符串字面量通常更容易核对:
cpp
#include <regex>
std::regex clearer{R"(^[A-Za-z]+\s+\d{4}$)"};如果模式内部可能出现 )",可以自定义分隔符:
cpp
std::regex quoted_name{R"rule(^name="([^"]*)"$)rule"};分隔符 rule 只是 C++ 原始字符串的边界,不属于正则模式。
match 要求覆盖整串,search 只找子串
std::regex_match 要求整个输入都被模式覆盖。它适合账号、配置行和表格记录等完整格式验证。
std::regex_search 只要找到一个匹配子串就成功。它适合从日志或自然文本中提取编号。
cpp
#include <iostream>
#include <regex>
#include <string>
int main() {
const std::regex ticket{R"(BUG-\d{4})"};
const std::string exact = "BUG-2048";
const std::string line = "retry BUG-2048 after timeout";
std::cout << std::boolalpha
<< std::regex_match(exact, ticket) << '\n'
三次结果依次是 true、false、true。
^ 与 $ 可以在模式里明确行首和行尾。使用 regex_match 时,API 已经要求整串匹配;保留锚点有时仍能让模式的意图更直观。
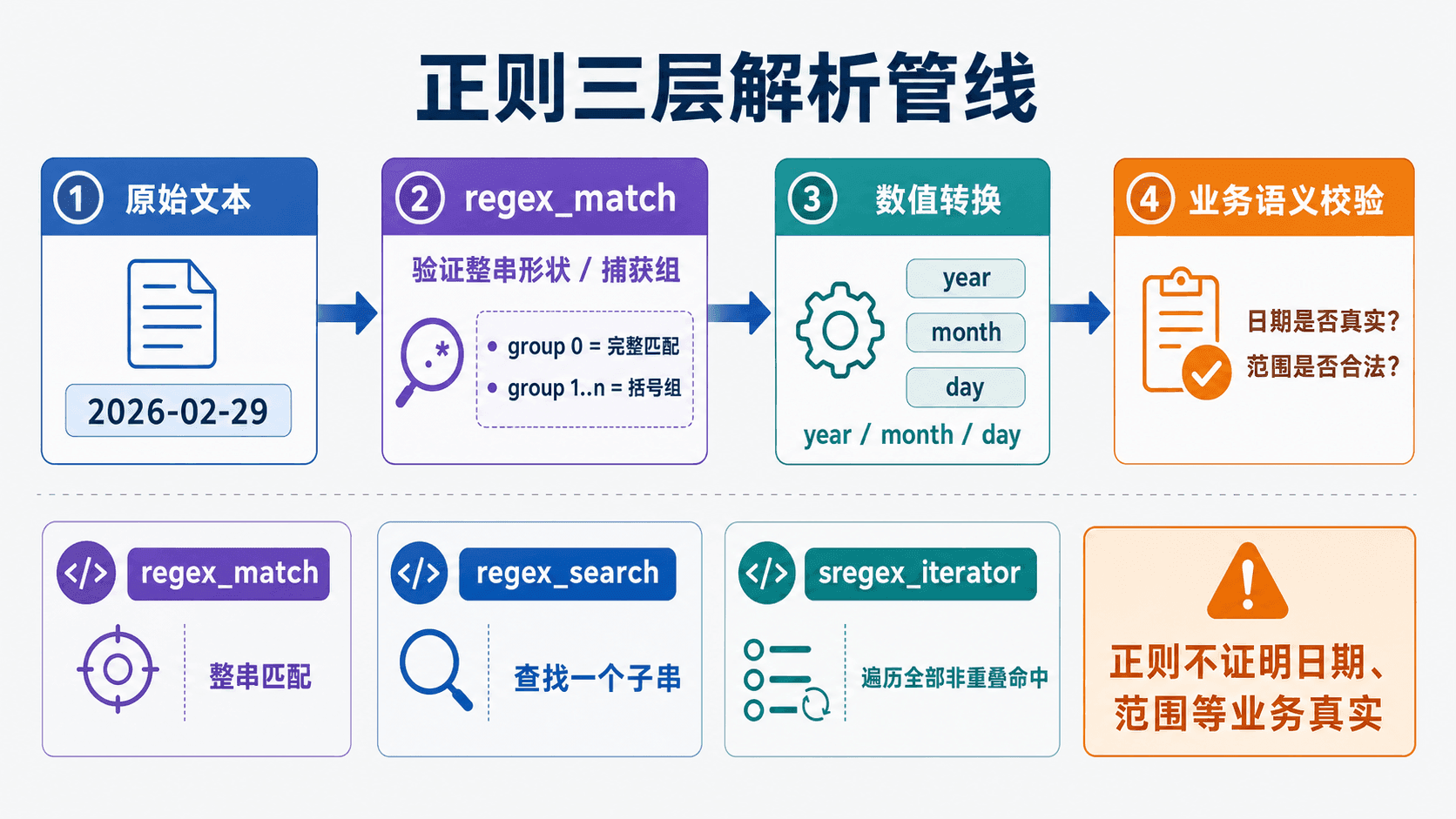
regex_match、regex_search 与 sregex_iterator 的结果范围也各不相同。捕获组从 1 开始
std::smatch 保存字符串匹配结果。下标 0 是完整匹配,第一对括号对应下标 1,之后依次增加。
cpp
#include <iostream>
#include <regex>
#include <string>
int main() {
const std::regex row{R"(^([A-Z]{2})-(\d{4})(?:-([a-z]+))?$)"};
const std::string input = "CN-2026-beta";
std::smatch match;
if (std::regex_match(input, match, row)) {
std::cout << "whole: " << match[0].str() << '
(?:...) 是不捕获分组,用来组织模式但不占捕获下标。可选捕获组没有参与匹配时,可通过 .matched 判断,不要仅凭结果字符串为空推断。
遍历全部非重叠匹配
一次 regex_search 只报告一次成功和一组匹配结果。要遍历字符串中所有非重叠命中,可以使用 std::sregex_iterator。
cpp
const std::string log = "BUG-1001 then BUG-1002 and BUG-2048";
const std::regex ticket{R"(BUG-(\d{4}))"};
for (std::sregex_iterator it{log.begin(), log.end(), ticket}, end;
it != end; ++it) {
std::cout << (*it)[1].str() << '\n';
}输出是三个编号,不包括 BUG- 前缀,因为程序打印的是捕获组 1。
replace 可以引用捕获组
std::regex_replace 会生成替换后的字符串。默认 ECMAScript 替换模板中,$1、$2 等引用对应捕获组。
cpp
const std::string text = "phone=13812345678";
const std::regex phone{R"((\d{3})\d{4}(\d{4}))"};
std::cout << std::regex_replace(text, phone, "$1****$2") << '\n';输出是 phone=138****5678。
替换只改变文本表现,不表示输入已经通过其他业务校验。手机号是否真实、号段是否有效,都属于后续规则。
非法模式和维护成本
构造非法 std::regex 会抛出 std::regex_error。固定模式应尽量构造一次并复用,不要在循环中反复解析相同模式。
cpp
try {
std::regex invalid{"([a-z"};
} catch (const std::regex_error& error) {
std::cout << "invalid pattern: " << error.code() << '\n';
}如果模式来自用户输入,应在边界捕获并报告错误。如果模式是程序常量,异常通常说明开发阶段漏掉了测试。
正则验证的是字符结构。范围、日期、字段间关系和权限等语义要在捕获后继续检查。模式越来越长时,可维护性本身就是改用分阶段解析的理由。
小节测试
4.1
下列任务分别适合哪些正则接口?
4.2
在 std::smatch 中,下标 ____ 表示整个匹配结果。
用 random 构造可重放的随机过程
引擎保存序列状态
标准随机引擎是可调用对象。每调用一次,它就产生下一个值并推进内部状态。
std::mt19937 是常用的确定性伪随机引擎。相同初始状态会得到相同后续序列,适合测试、模拟回放和问题复现。
cpp
std::mt19937 engine{20260711u};
std::cout << engine() << '\n'
<< engine() << '\n'
<< engine() << '\n';固定种子不是让结果“更随机”,而是让序列可重复。测试失败时,只要种子和调用顺序相同,就能再次得到同一过程。
分布决定目标范围
均匀整数分布的两个端点都可能取到。std::uniform_int_distribution<int>{1, 6} 可以产生 1 到 6,包括 1 和 6。
均匀实数分布通常按左闭右开区间理解。std::uniform_real_distribution<double>{0.0, 1.0} 产生大于等于 0.0 且小于 1.0 的值。
cpp
std::mt19937 engine{42u};
std::uniform_int_distribution<int> die{1, 6};
std::uniform_real_distribution<double> ratio{0.0, 1.0};
std::cout << die(engine) << ' ' << ratio(engine) << '\n';不要把某一组具体输出写成跨所有实现的永久快照。mt19937 的引擎算法有明确规定,但标准分布把引擎值映射到结果的具体过程不要求所有标准库实现逐项相同。跨平台逐值重放需要固定工具链,或自行定义映射规范。
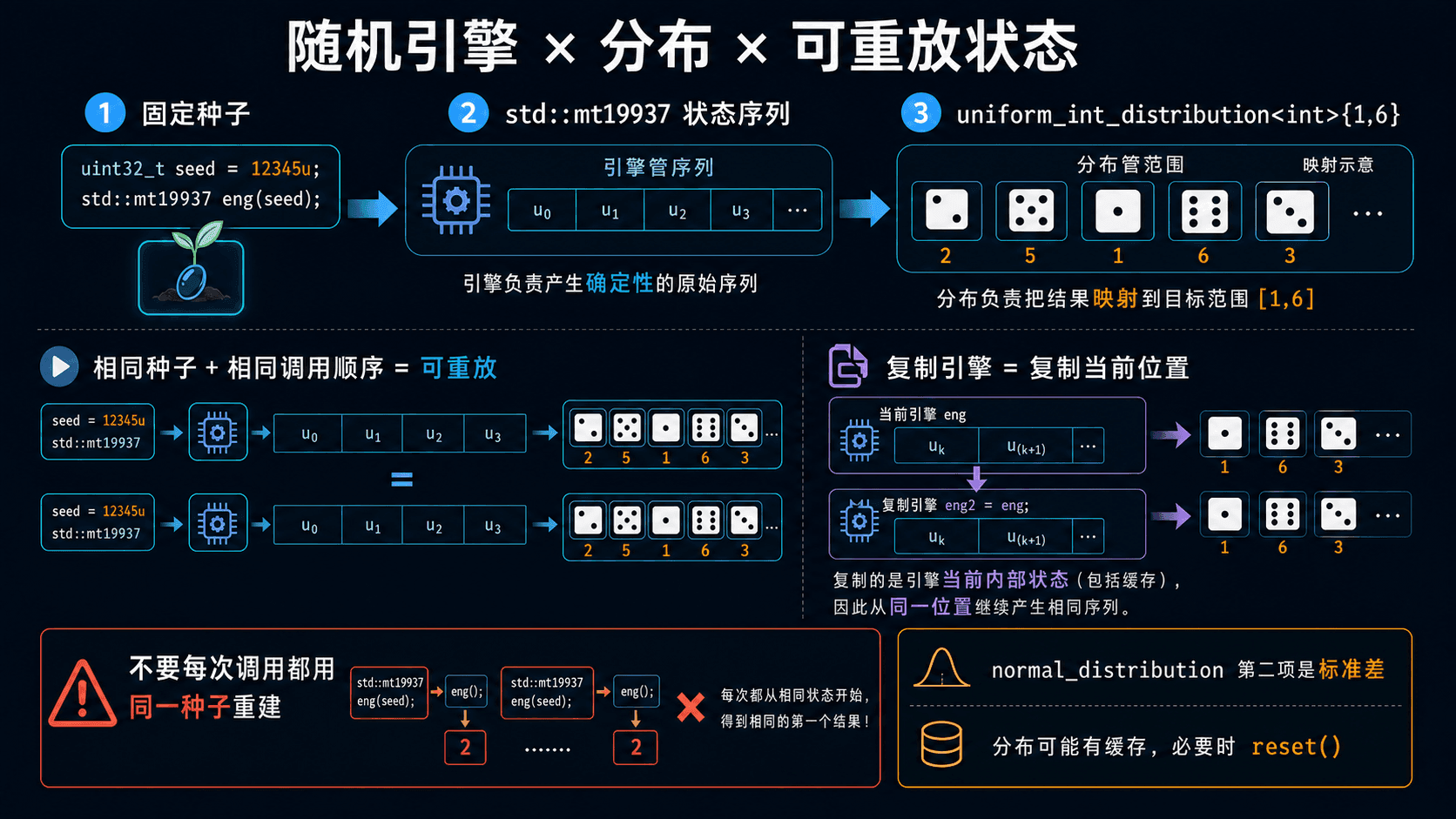
正态分布的第二项是标准差
std::normal_distribution<double>{mean, stddev} 的第二个参数是标准差,不是方差。
cpp
#include <random>
std::mt19937 engine{314159u};
std::normal_distribution<double> latency{120.0, 15.0};
double sample = latency(engine);这里的均值是 120,标准差是 15。写成 225 会把“方差 225”误当成标准差 225,结果分散程度会完全不同。
分布对象也可能保存状态。例如正态分布的实现可能缓存一次计算产生的另一个结果。要清除分布的内部缓存,可调用 distribution.reset()。
不要在每次调用中用同一种子重建
下面的函数每次都返回同一个序列的第一项:
若函数内部每次都执行 std::mt19937 engine{7u},它每次都会从同一状态开始,只取得序列第一项。
更合理的方式是让引擎活得足够久,或显式把引擎引用传入函数:
cpp
int next_value(std::mt19937& engine) {
return std::uniform_int_distribution<int>{1, 100}(engine);
}这样调用者控制种子与生命周期,函数只负责目标范围。
复制引擎会复制当前位置
引擎是普通对象,复制会复制当前状态。两个副本之后会产生相同的后续序列。
cpp
std::mt19937 first{99u};
first();
first();
auto second = first;
assert(first() == second());
assert(first() == second());这对分支模拟很有用,但无意复制引擎也可能让两个模块生成相同序列。接口应明确接收引用、移动所有权,还是故意复制状态。
随机用途决定种子选择
固定常量种子适合单元测试和教学示例。运行时模拟若希望每次不同,可以从外部配置、记录过的种子或 std::random_device 获取初始材料,同时把最终种子记入日志,便于复现。
普通 <random> 引擎不提供密码学安全保证。密钥、会话令牌、找回码和验证码应使用平台提供的安全随机接口,不要用 mt19937。
小节测试
5.1
uniform_int_distribution<int>{2, 5} 可能产生整数 2 和整数 5。
5.2
固定伪随机引擎种子对测试最直接的价值是什么?
用 I/O 操纵符控制表示与状态
进制状态会保留
std::hex、std::oct 和 std::dec 改变后续整数的进制。std::showbase 控制八进制与十六进制前缀,也会持续生效,直到 std::noshowbase 恢复。
cpp
#include <iomanip>
#include <iostream>
int main() {
std::cout << std::showbase << std::hex
<< 26 << ' ' << 27 << '\n'
<< std::dec << std::noshowbase
<< 26 << ' ' << 27 << '\n';
可能的输出为:
text
0x1a 0x1b
26 27进制状态也能影响格式化输入。解析固定协议时,应明确指定进制,不要让前面代码留下的流状态决定解释方式。
setprecision 的含义依赖浮点格式
在 std::defaultfloat 下,std::setprecision(n) 控制总有效数字。在 std::fixed 与 std::scientific 下,它控制小数点后的位数。
cpp
#include <iomanip>
#include <iostream>
int main() {
const double value = 1234.56789;
std::cout << std::defaultfloat << std::setprecision(5)
<< value << '\n';
std::cout << std::fixed << std::setprecision
典型输出依次是 1234.6、1234.56789 和 1.23457e+03。
fixed、scientific 和精度都会留在流中。需要回到通用浮点格式时写 std::defaultfloat,精度仍需按调用者约定恢复。
setw 只管紧随其后的一项
std::setw(n) 设置下一次格式化字段的最小宽度,随后宽度恢复为 0。字段容不下数据时不会截断值。
cpp
#include <iomanip>
#include <iostream>
int main() {
std::cout << '|' << std::setw(6) << 42
<< '|' << 43
<< '|' << std::setw(2) << 12345
<< "|\n";
}输出是 | 42|43|12345|。
std::setfill、std::left 和 std::right 会保留。打印表格时,通常每一列都要重新设置 setw,而填充字符和对齐方式只在需要改变时设置。
boolalpha 与 quoted
std::boolalpha 让布尔值输出为 true 或 false,并让格式化输入接受对应文字。std::noboolalpha 恢复数字形式。
std::quoted(text) 只包装当前字符串的插入或提取。它能让带空格、引号和反斜杠的字符串在流中往返,不会把“所有后续字符串都加引号”保存成流状态。
cpp
const std::string original = "nightly build \"A\"";
std::ostringstream output;
output << std::quoted(original) << ' ' << std::boolalpha << true;
std::istringstream input{output.str()};
std::string restored;
bool enabled = false;
input >> std::quotedstd::quoted 定义在 <iomanip>。它对当前字符串执行带引号的格式化,不是持久开关。
辅助函数应恢复调用者的格式状态
一个接收 std::ostream& 的函数通常不拥有流。它若修改 hex、fixed、精度或填充字符,应在返回前恢复。
可以用小型 RAII 守卫在构造时保存 flags()、precision() 和 fill(),在析构时逐项恢复。综合示例会给出完整实现。字段宽度不需要保存,因为 setw 对当前一项使用后就会复位。
这个守卫只负责格式状态,不恢复流的错误位、异常掩码、locale 或缓冲区。RAII 类型应清楚声明自己保存的范围,不要用一个模糊的“全部状态”名称掩盖边界。
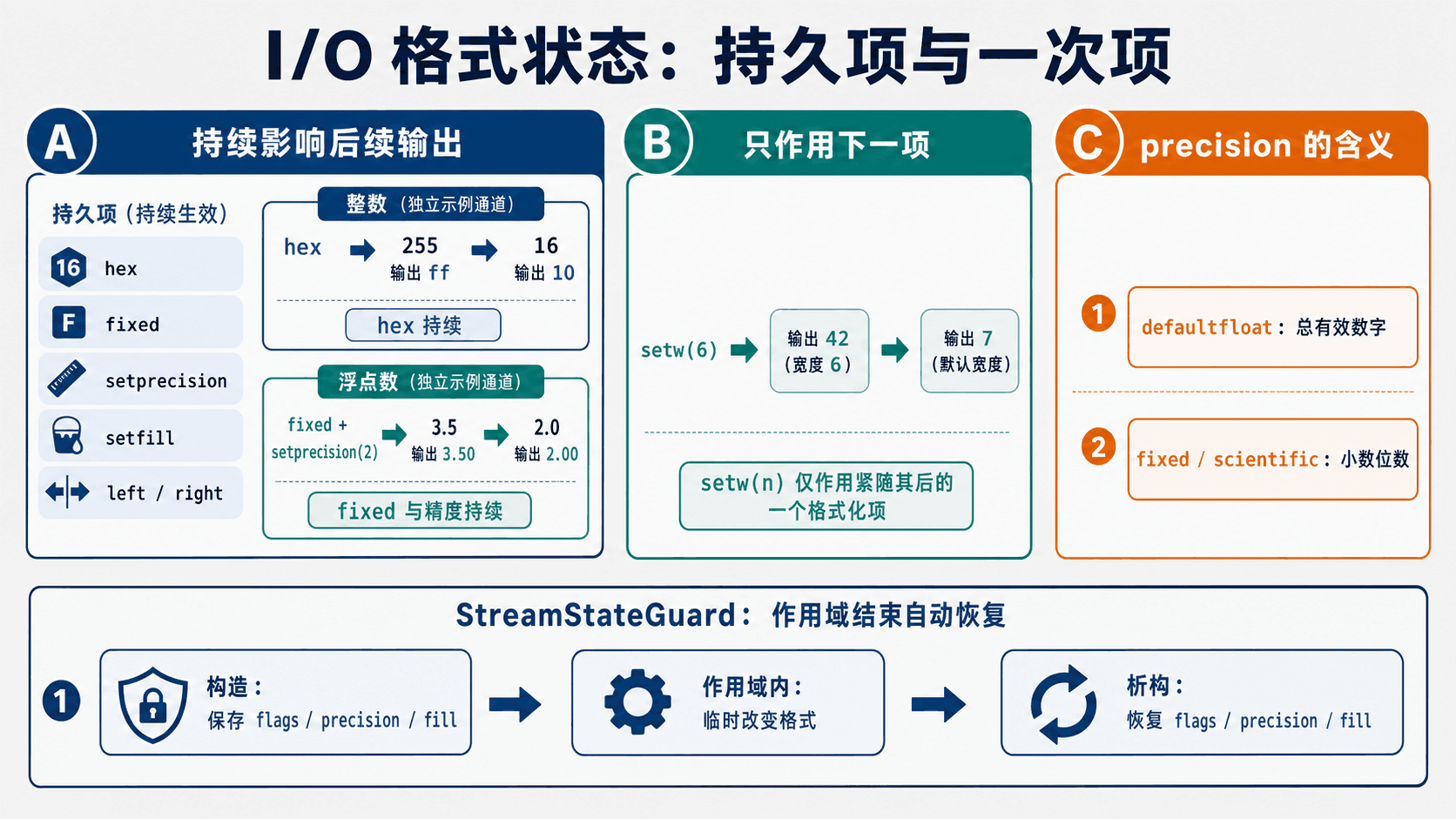
hex、fixed 等格式状态会持续影响后续输出,setw(n) 仅影响下一项;RAII 守卫可在作用域结束时恢复调用者的 flags、precision 与 fill。小节测试
6.1
下列哪些设置通常会影响后续多个输出值?
6.2
在 defaultfloat 下,setprecision(4) 控制 4 个总 ____;在 fixed 下则控制小数点后 4 位。
把五类设施组合成可重放任务报告
下面实现一个小型命令解析器。输入行包含带空格的任务名、8 位开关串、随机整数范围和样本数量:
text
task "night build" flags=10100101 range=3..7 samples=5处理过程分成五步:
用 regex_match 验证整行,确保没有未消费的前缀或后缀,并把五个字段捕获出来。
解析函数用 tuple 返回成功标志、任务名、位集合、范围、样本数和错误消息;调用端用结构化绑定立即命名。
把 8 位文本构造成 bitset,统计开启数量,并读取具名功能位。
用固定种子的 mt19937 与均匀整数分布生成可重放样本。
完整程序
cpp
#include <bitset>
#include <cstddef>
#include <iomanip>
#include <ios>
#include <iostream>
#include <limits>
#include <random>
#include <regex>
#include <stdexcept>
#include <string>
#include <tuple>
enum class Feature : std::size_t {
logging = 0,
cache = 1,
为什么先验证形状,再检查范围
正则先保证五个捕获组存在,并限制开关文本恰好为 8 位。随后 stoi 和 stoll 负责数值转换,再由普通条件检查 low <= high 与样本数上限。
如果把所有范围语义都塞进正则,模式会迅速失去可读性。分成“字符形状、数值转换、业务约束”三层后,每种错误都有明确位置。
样本数先读成 long long,检查在 1..1000 后再转换为 int。这样循环次数有清楚上限,也不会让超大文本数值悄悄绕过边界。
为什么这里可以用 tuple
ParseResult 的字段较多,已经接近元组的可读性边界。这里仍使用它,是为了展示解析边界上的一次性拆包:调用端立刻用结构化绑定命名,结果不会跨模块长期保存。
如果任务配置成为稳定领域对象,应改为带 name、flags、low、high 和 sample_count 命名成员的结构体。错误通道也可以改为项目统一的结果类型。
为什么把引擎交给报告函数
print_report 接收 std::mt19937&,因此调用者控制种子和状态。单元测试可以传入固定种子的引擎,生产程序可以从配置得到种子并写入日志。
函数内部只创建分布,表达“在当前任务范围内取样”。它不会每次调用都把引擎重置到序列起点。
格式状态在哪里结束
报告函数使用 std::boolalpha 和 std::setw。setw 每次只作用于一个样本,所以循环中每轮都要重新写。
boolalpha 会保留,因此由 StreamStateGuard 在函数结束时恢复。将来如果报告增加十六进制标志值、固定小数或自定义填充字符,同一个守卫也会恢复对应状态。
验证清单
测试时至少覆盖正常输入、空名称、含非 0/1 字符的开关、反向范围和超过 1000 的样本数。它们分别触达成功路径、字段语义、字符形状、字段关系和数量上限。
小节测试
7.1
综合程序为什么使用 regex_match 而不是 regex_search?
7.2
综合程序中哪些设计有助于稳定测试和清楚维护?
7.3
如果 ParseResult 会在多个模块长期传递,继续增加 tuple 位置通常比定义命名结构体更清楚。