关系数据库设计:从业务事实到可验证的模式
一张表能把数据装进去,不等于它经得起长期使用。真正的关系数据库设计,要回答三类问题:同一事实是否被重复保存,更新后是否可能出现矛盾,以及拆表以后能否无歧义地还原信息、就地检查约束。
下面我们围绕“云帆学习平台”展开。平台管理学员、课程、开课班次、讲师、院系与成绩。我们会先把自然语言规则写成函数依赖,再用闭包、候选键和范式判断模式,最后把理论落到主键、外键、时间区间与实际设计流程中。
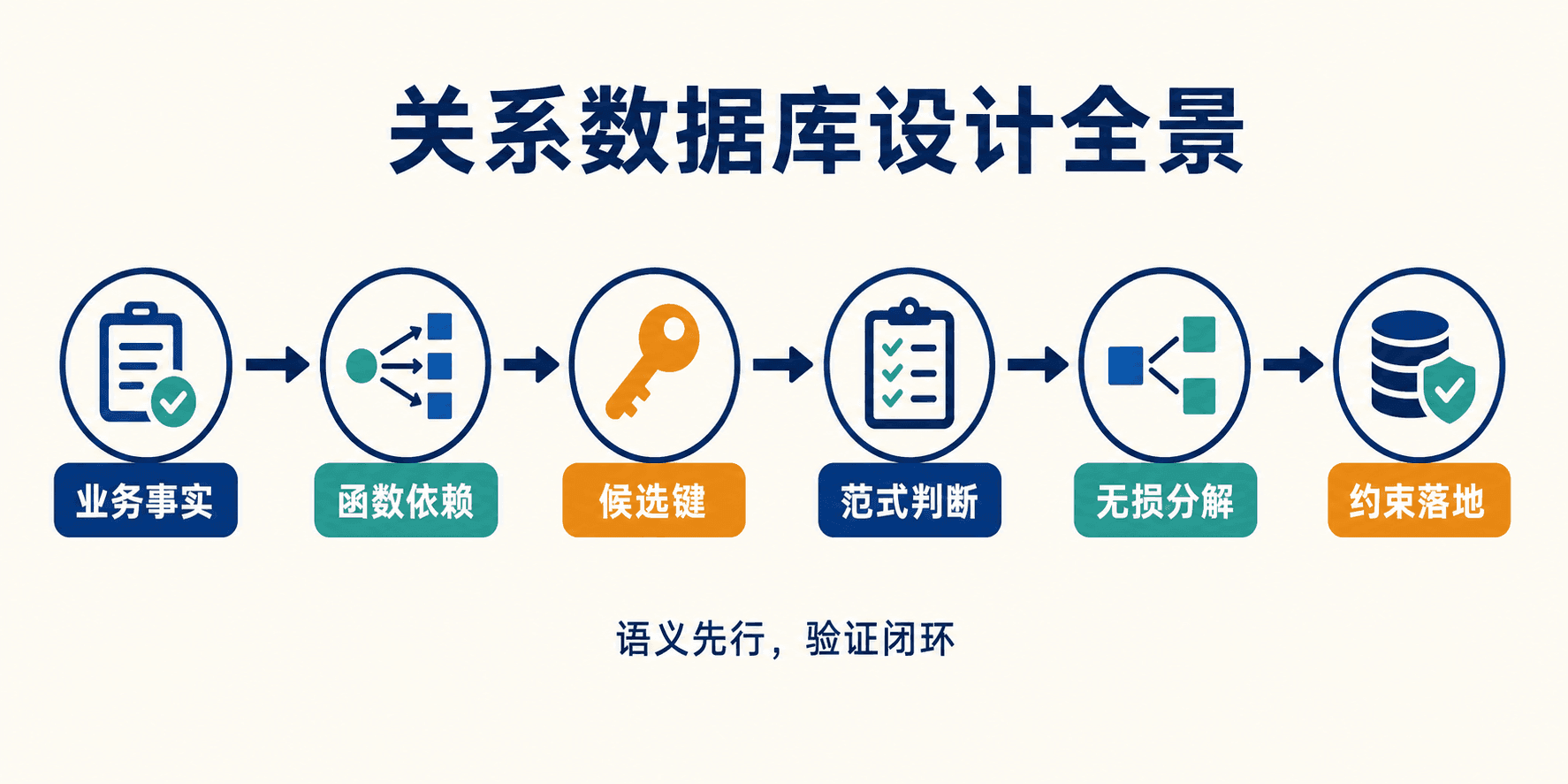
图:关系模式不是表名清单,而是一条从业务语义、依赖推理到约束落地的完整链路。
好设计先解决异常,再谈范式
假设平台最初只建了一张 learning_record 表:
这张表查询方便,却把几种不同粒度的事实挤在一起:一条成绩记录对应一个学员与开课班次;课程名属于课程;院系名和校区属于院系;讲师姓名属于讲师。事实粒度一旦混合,异常就会出现。
更新、插入和删除异常
如果计算机学院搬到西校区,所有包含 D02 的记录都要一起更新。漏掉任意一行,同一个院系就会同时属于两个校区,这叫更新异常。
如果平台已经批准课程 C20,但还没有创建开课班次,单表设计无法在不伪造成绩记录的情况下保存课程,这叫插入异常。
如果某门课程目前只有一条选课记录,删除这条记录时,课程名、所属院系等事实也随之消失,这叫删除异常。三种异常的共同根源,是同一个业务事实被绑定到了不属于它的记录粒度上。
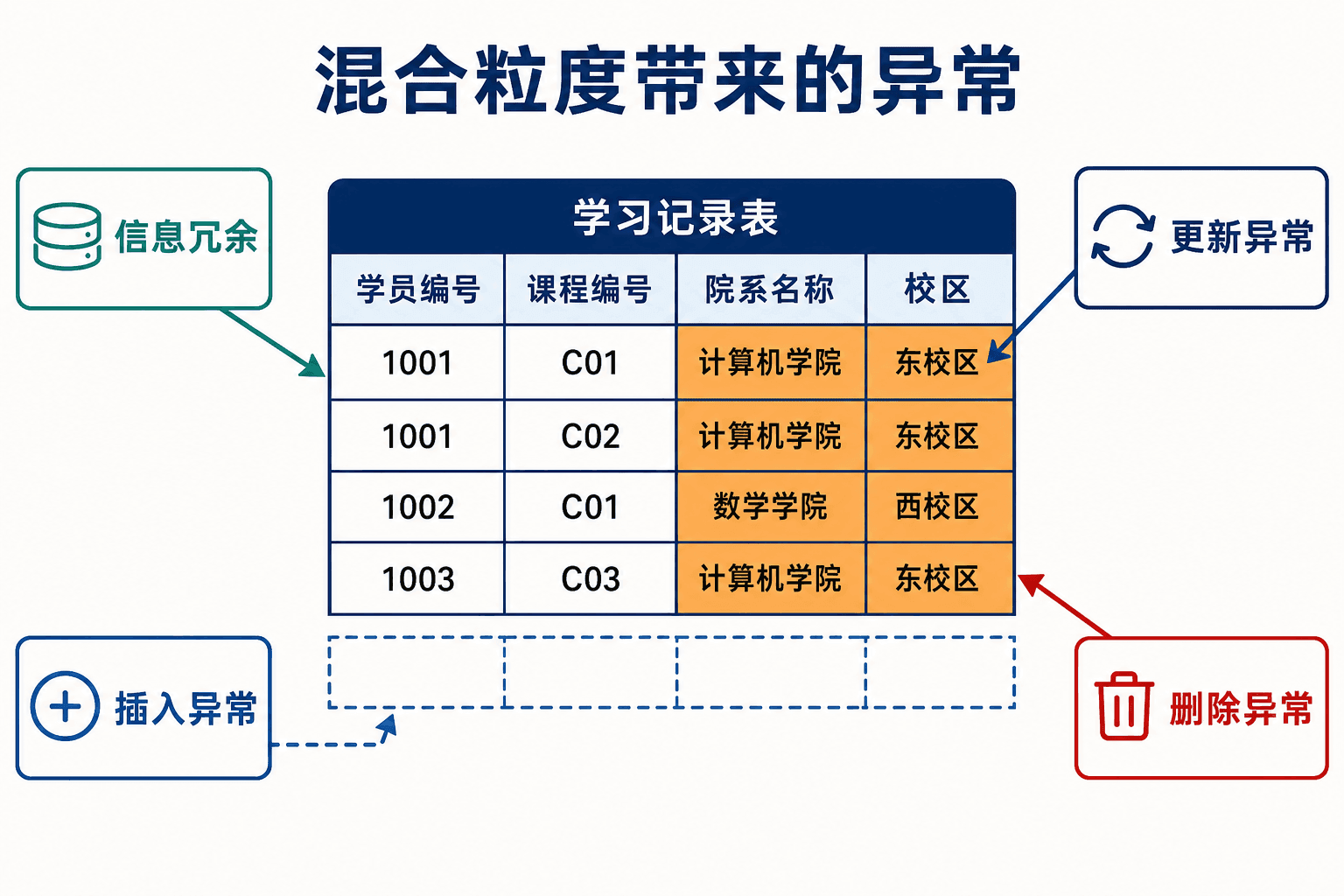
图:冗余不只是占空间;它会把一次业务变更扩散成多行同步任务。
分解的目标不是“表越小越好”
合理做法是把事实放回各自的决定因素旁边,例如拆成:
student(student_id, student_name)department(department_id, department_name, campus)teacher(teacher_id, teacher_name, department_id)course(course_id, course_title, department_id)offering(offering_id, course_id, teacher_id, term)learning_record(record_id, student_id, offering_id, score)
现在,院系校区只保存一次,新课程可以独立创建,删除成绩也不会删除课程。不过,分解并非越细越好。若把 employee(employee_id, name, city) 拆成 employee_name(employee_id, name) 与 name_city(name, city),两个同名员工会在自然连接时交叉组合,产生原来不存在的地址归属。
设关系模式为 ,分解为 与 。对每一个满足业务约束的合法关系实例 ,若投影后再自然连接总能得到原关系,就称为无损分解:
如果连接结果严格包含原关系,新增的行叫伪元组,这就是有损分解:
“无损”说的是信息关联没有丢失,并不意味着行数不能增加。恰恰相反,有损分解常常因为错误组合而产生更多行,却丢掉了“谁和谁本来有关”的信息。
规范化的基本动作可以概括为:先判断模式是否处于合适的范式;若不是,就依据真实依赖分解;每一次分解都必须保住原有信息。范式负责控制冗余,无损性负责保证分解可逆,两者不能互相替代。
1
一张表把院系校区重复写在每条成绩记录上。哪种改动最直接地消除更新异常,同时允许尚未开课的院系独立存在?
函数依赖把业务规则变成可推理的约束
函数依赖描述“给定一组属性值,另一组属性值是否被唯一确定”。对关系模式 ,若任意两个合法元组 只要在属性集 上相同,就必然在属性集 上相同,那么函数依赖 在 上成立:
在平台场景中,业务人员确认了这些规则:
这里的箭头不是根据当前几行数据“猜”出来的统计规律,而是所有合法状态都必须遵守的业务承诺。某个样本中恰好每位同名学员都来自同一院系,并不能推出 student_name → department_id。只要业务上允许两个同名学员属于不同院系,这个依赖就不成立。
超键、候选键与主键
若属性集 能决定关系 的全部属性,即 ,那么 是 的超键。超键可以包含多余属性,例如 record_id 已能标识一条成绩记录,那么 {record_id, student_name} 仍是超键。
如果从超键中删除任意属性后都不再是超键,它就是候选键。候选键表达最小唯一性,可能不止一个。设计者从候选键中选择一个作为主键,其余候选键通常用 UNIQUE 表达。
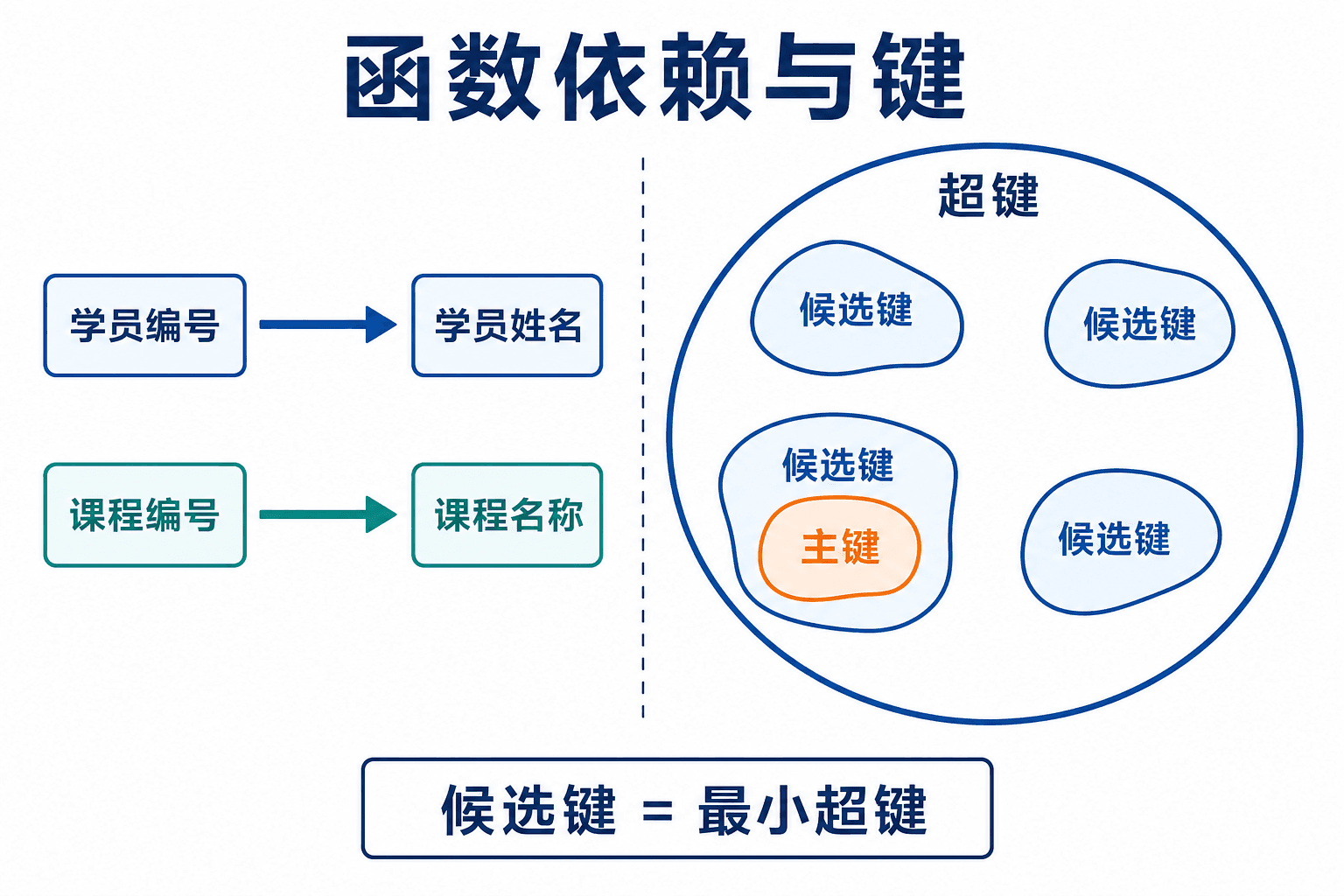
图:候选键是最小超键;“最小”按集合包含关系判断,不是按字符串长度或业务观感判断。
平凡依赖与非平凡依赖
当 时, 对任何关系都成立,称为平凡函数依赖。例如:
它只是在说一组属性当然能决定其中的一部分,没有增加业务知识。若 ,则依赖是非平凡的;若 ,还可称为完全非平凡依赖。范式判断主要关注非平凡依赖,因为冗余正是由“非键属性被非键决定因素决定”引起的。
依赖闭包不是输入清单
设业务明确给出的依赖集合为 ,所有能从 逻辑推出的依赖组成 。例如:
与
共同推出:
因此检查范式时不能只盯着原始清单 ,还要考虑 中隐藏的依赖。后面我们会用属性闭包避免显式枚举庞大的 。
2
关于候选键和函数依赖,哪些说法正确?
无损连接与依赖保持回答两个不同问题
分解质量至少要过两道检查。无损连接问的是“投影后连接能否精确还原原关系”;依赖保持问的是“原约束能否只检查各子关系,而不用先做连接”。一个分解可以无损但不保持依赖,也可以保持某些依赖却有损,二者不能混为一谈。
二元分解的无损判据
把 分解为 和 ,若公共属性能决定其中任意一边,分解就是无损的:
或:
例如,将 course_department(course_id, course_title, department_id, department_name, campus) 分成:
course(course_id, course_title, department_id)department(department_id, department_name, campus)
公共属性是 department_id,而 department_id → department_name, campus,所以公共属性是 department 的超键,分解无损。
在数据库实现中,这种结构通常对应两类约束:公共属性是被决定一侧的主键或唯一键;另一侧用外键引用它。主键表达“公共属性决定该关系”,外键保证引用侧的元组在被引用侧确实有匹配行。只有函数依赖而没有引用完整性时,两个独立表仍可能出现无法在连接中找回的悬空元组。
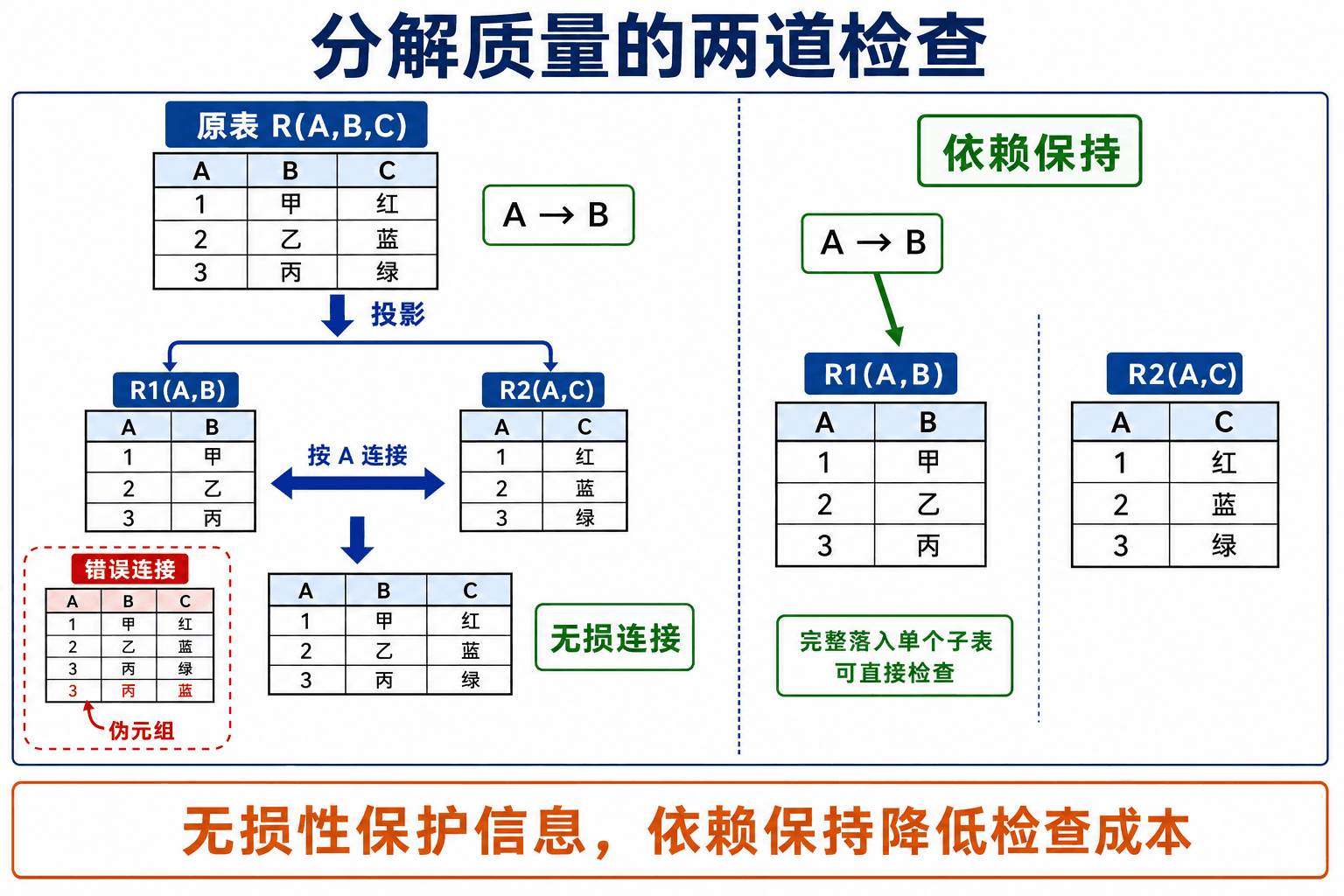
图:无损性保护信息关联;依赖保持降低约束检查成本。两条轴必须分别验证。
依赖保持的正式判断
设分解为 。把 限制在 内,得到只涉及 属性的依赖集 。若这些局部依赖的并集能够推出原依赖的全部闭包,即:
则分解保持依赖。注意 来自 的限制,而不是简单挑出原始 中“看起来属于 ”的几条。
实务中可以先用一个充分条件快速判断:若 中每条依赖都完整落在某个子关系内,那么分解一定保持依赖。但这个条件失败时不能立即判定“不保持”,因为局部依赖组合后仍可能推出原依赖。
更一般的多项式时间检查,对每条 执行如下传播:从 result = α 开始,轮流查看每个 ,计算 ,只保留仍在 内的属性并加入 result;直到不再变化。若最终包含 ,这条依赖被保持。所有依赖都通过,整个分解才保持依赖。
3
只要分解是无损的,原有的每条函数依赖就一定能在某一个子关系中单独检查。
BCNF 与第三范式是一组有取舍的标准
BCNF 试图消除所有能由函数依赖发现的冗余。关系模式 关于依赖集 属于 BCNF,当且仅当对 中每个 ,至少满足一项:
- 该依赖平凡,即 ;
- 是 的超键。
直观地说,任何真正带来新信息的决定因素,都必须足以标识整行。以:
为例,department_id → department_name, campus 是非平凡依赖,而 department_id 不能决定课程,因此它不是超键,模式不满足 BCNF。
用违反依赖进行 BCNF 分解
若非平凡依赖 违反 BCNF,可以把 替换为:
当选择的右侧与左侧不相交时,也常写成 与 。交集是 ,且 ,所以这一步无损。分解后要继续检查每个子模式,直到都满足 BCNF。
第三范式为什么多留一扇门
先定义主属性:出现在至少一个候选键中的属性。关系模式 关于 属于第三范式(3NF),当 中每个 至少满足一项:
- 依赖平凡;
- 是超键;
- 中的每个属性都是主属性。
第三项是 3NF 相对 BCNF 的放宽。它允许某些“左侧不是超键”的依赖存在,但右侧新增属性必须参与某个候选键。任何 BCNF 模式一定是 3NF,反过来不成立。
考虑平台的导师安排:
业务规则是每位导师只代表一个院系,每位学员在一个院系至多有一位导师:
候选键包括 {student_id, mentor_id} 与 {student_id, department_id}。mentor_id → department_id 违反 BCNF,因为 mentor_id 不是超键;但 department_id 是主属性,所以模式满足 3NF。
若按 BCNF 分成 (student_id, mentor_id) 与 (mentor_id, department_id),分解无损,却没有任何一个关系同时含有 student_id, department_id, mentor_id,约束 student_id, department_id → mentor_id 不能直接在单表内检查。这正是 BCNF 与依赖保持发生冲突的典型情况。
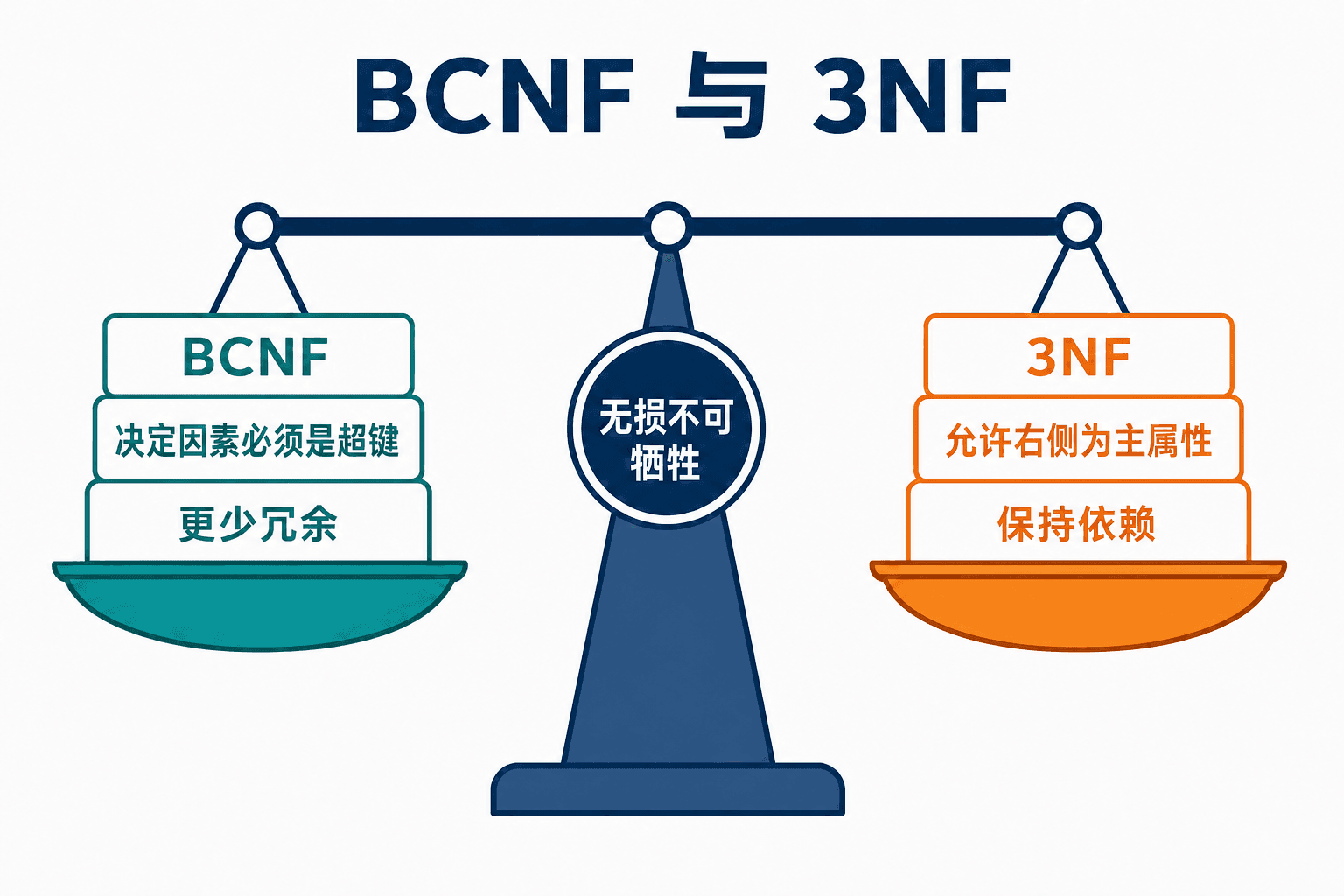
图:BCNF 更严格地压缩函数依赖造成的冗余;3NF 在必要时保留可局部检查的约束。
该选哪一个
设计目标通常同时包括:达到 BCNF、保证无损、保持依赖。但三者并非总能同时实现。稳妥顺序是:
- 无损性不可牺牲,否则模式无法忠实表示原事实。
- 优先尝试无损且依赖保持的 BCNF 设计。
- 若 BCNF 必然破坏关键依赖的局部检查,再评估使用无损、依赖保持的 3NF。
- 把未能由主键、唯一键、外键表达的约束明确交给事务逻辑或数据库触发机制,不能假设它会自动成立。
SQL 能直接声明的函数依赖主要是主键和唯一约束所表达的“键决定整行”。一般函数依赖缺少通用声明语法。因此“理论上依赖保持”与“数据库产品能低成本强制执行”仍有一段距离,设计评审必须把约束落地方式写清楚。
4
某非平凡依赖 X → A 中,X 不是超键,但 A 出现在一个候选键里。仅据此可以得到什么结论?
闭包把依赖推理变成可执行算法
范式判断、超键识别、无损检查与依赖保持都要回答“这些依赖还能推出什么”。直接枚举 很快会失控:若 有 个属性,左右两侧各有 种属性子集,潜在函数依赖数量达到 。更实用的办法,是用推理规则证明需要的依赖,并用属性闭包回答局部问题。
Armstrong 公理与常用派生规则
Armstrong 公理由三条规则组成,它们既可靠又完备:不会推出错误依赖,也能推出所有逻辑蕴含的函数依赖。
- 自反律:若 ,则 。
- 增广律:若 ,则 。
- 传递律:若 且 ,则 。
这里的 表示集合并 ,不是字符串拼接。由三条公理可推出常用规则:
- 合并律: 且 ,推出 ;
- 分解律:,推出 与 ;
- 伪传递律: 且 ,推出 。
例如已知 与 。先对第一条增广得到 ,再传递得到 ;也可直接使用伪传递律。
属性闭包的计算
属性集 在 下的闭包 ,是所有能由 函数决定的属性。算法很朴素:
用 初始化结果。自反律保证 至少能决定自身。
扫描每条依赖 。若 ,就把 并入 。
重复扫描,直到一整轮都没有新属性加入;此时的 就是 。
设:
计算 时,初值为 。由 加入 ,由 加入 ;此时已有 ,再加入 与 ,最终:

图:每次只有当依赖左侧完全进入结果集,右侧属性才可以被点亮。
属性闭包有三种高频用途:若 包含 的所有属性, 是超键;若 ,则 ;对每个属性子集求闭包,还可以构造 ,只是代价较高。
候选键的可复现搜索方法
候选键不能只靠直觉。一个实用搜索流程如下:
- 把从未出现在任何依赖右侧的属性加入必选集 。这些属性无法由其他属性推出,因此每个候选键都必须包含它们。
- 计算 。若已经覆盖 ,检查 是否最小;若是,它就是候选键。
- 从剩余属性中按集合大小递增地选择组合 ,计算 。
- 若闭包覆盖 ,再逐一删除属性验证最小性。只有删除任一属性都会失去超键性质,才记录为候选键。
- 已找到候选键 后,所有包含 的更大组合都不必继续搜索,因为它们不会是最小超键。
例如 ,。右侧从未出现的只有 ,所以 必选。计算得到 ,因此 {A} 已是超键;它没有真子集可删,于是是候选键。若闭包只得到 AB,就需要继续组合剩余属性,而不能把必选集误当成候选键。
5
设 R(A,B,C,D),F={A→B, B→C, AC→D}。A 的属性闭包是什么?
正则覆盖删除的是多余表达,不是业务约束
同一组业务约束常被写成多种等价形式。依赖越冗长,更新检查和 3NF 合成都越难。正则覆盖(也常称规范覆盖、最小覆盖的一个合并形式)是与原依赖集合等价、但去除了无关属性并合并相同左侧后的依赖集 。
两个依赖集等价,指它们的闭包相同:
因此简化不是随意删规则。删除前后,允许的合法关系实例必须完全一致。
无关属性如何判断
设 。
若属性 ,删除它会让左侧更小、约束可能更强。令 ,若在当前依赖集下 ,则 在左侧无关。
若属性 ,删除它会让约束可能更弱。先把当前依赖替换为 得到 ;若在 下仍有 ,则 在右侧无关。
左右两侧的测试方向不能颠倒。左侧删属性要证明“更小的决定因素仍能推出完整右侧”;右侧删属性要证明“删掉后仍能从剩余依赖推出被删属性”。
计算步骤与示例
计算正则覆盖时,反复执行两件事,直到不再变化:
- 用合并律把相同左侧的 与 合并为 。
- 在当前 中寻找左侧或右侧无关属性并删除。若右侧被删空,则整条空依赖删除。
设:
A→BC 与 A→B 左侧相同,合并后仍是 A→BC。在 AB→C 中,A 是无关的,因为已有 B→C。在 A→BC 中,C 也是无关的,因为 A→B 与 B→C 已能推出 A→C。得到:
正则覆盖可能不唯一。若一次有多个无关属性可选,删除顺序不同可能得到不同结果,但合格结果都与 等价。不要在同一轮里把“各自看似可删”的多个属性同时删掉;前一次删除会改变后续闭包,必须逐次重算。
正则覆盖的“最小”不是依赖条数绝对最少,也不是字符最短。它要求没有无关属性、相同左侧已经合并,并与原集合逻辑等价。若没有做双向等价检查,得到的只是一个更短的清单,不一定是同一组业务规则。
6
计算正则覆盖时,哪些操作是正确的?
分解算法把范式目标变成确定步骤
面对真实模式,靠肉眼反复拆表很容易漏掉隐藏依赖。BCNF 分解与 3NF 合成提供了两条可复查路线:前者不断使用违反 BCNF 的依赖向下分解;后者从正则覆盖出发向上合成关系。
无损 BCNF 分解
初始结果集只有 。只要结果集中仍有关系 不满足 BCNF,就选择一个在 上成立的非平凡依赖 ,满足 不是 的超键,并把 替换为:
为了使用更直观的 写法,应先把右侧整理为与左侧不相交。每一步的公共属性 都决定第一张子表,所以每一步无损,递归结果也无损。
判断初始模式 是否为 BCNF 时,只检查给定 中的依赖是否违反 BCNF就足够;但判断分解后的 时不能只挑原始 中完全落入 的依赖,因为 里可能有新依赖落在 上。例如 与 可推出 ,后者可能揭示子模式的 BCNF 违规。
保持依赖的 3NF 合成
3NF 算法从 的正则覆盖 开始:
对 中每条 创建关系模式 。这样每条正则覆盖依赖都能在某张表内检查。
检查已创建的关系是否有一张包含原模式 的某个候选键。若没有,额外加入一张只含该候选键的关系,以保证无损性。
若某个关系模式完全包含于另一个关系模式,则删除较小者。它能检查的依赖在较大关系中仍可检查,无损性也不会因此破坏。
3NF 算法保证结果属于 3NF、无损且保持依赖。它叫“合成”是因为从依赖逐张创建关系,而不是不断切开原关系。正则覆盖可能不唯一,所以合成结果也可能不唯一;这不影响三项保证。
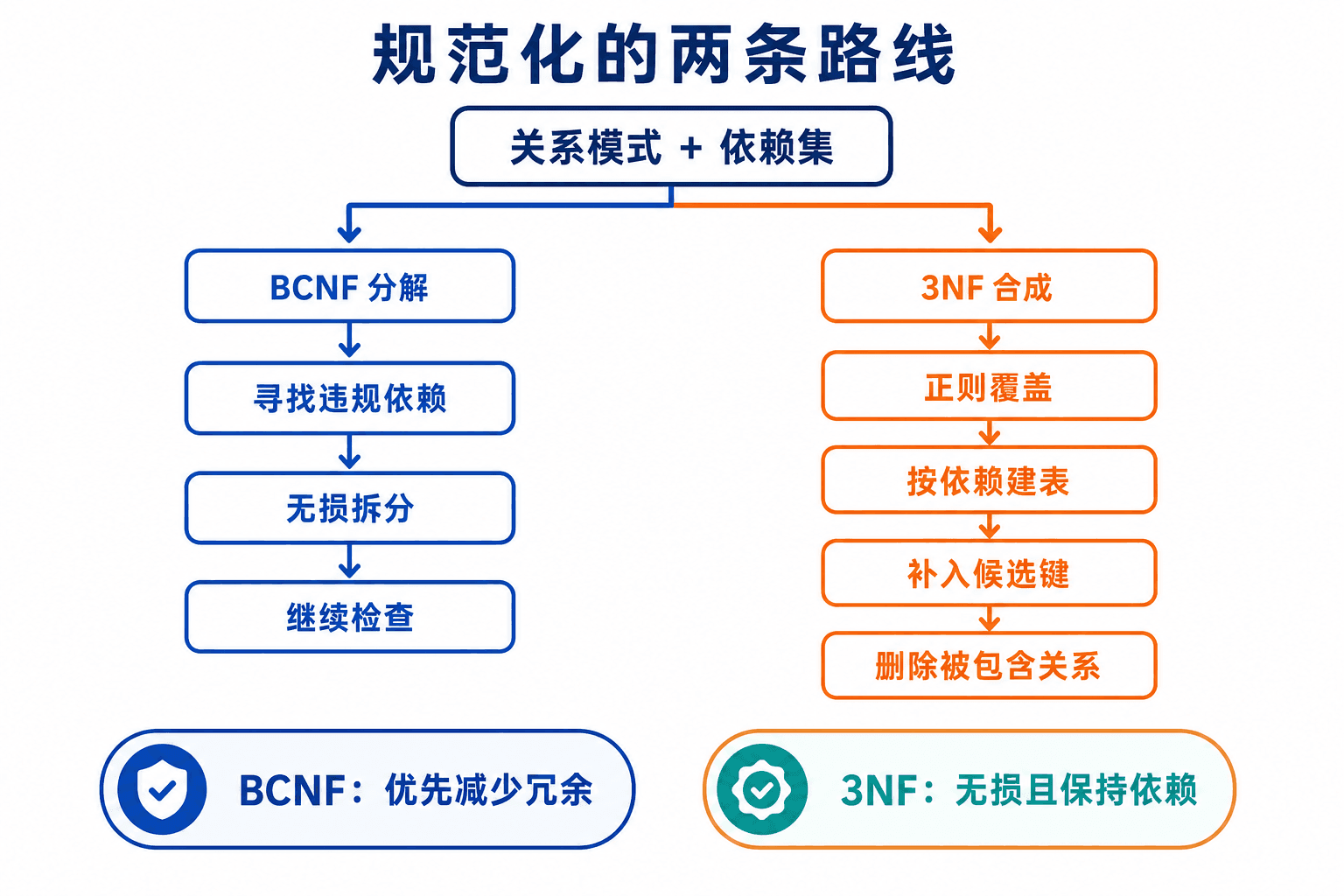
图:BCNF 路线优先消除违规决定因素;3NF 路线优先把依赖放进可局部检查的关系。
一个可操作的选择流程
工程上可以先运行 3NF 合成,再检查所得关系是否已经是 BCNF。很多实际模式会同时达到两者。若某张表仍不满足 BCNF,再尝试 BCNF 分解并验证依赖保持;若关键依赖丢失,保留 3NF 版本并记录冗余控制策略。
下面的实验台会枚举当前子模式内的属性子集,通过原依赖闭包寻找 BCNF 违规,并演示一步一步分解。它也计算候选键和 3NF 状态,便于观察“3NF 但非 BCNF”的情况。
7
3NF 合成后,没有任何一个生成关系包含原模式的候选键。算法下一步应做什么?
多值依赖解释了 BCNF 看不见的冗余
函数依赖适合描述“一个值决定另一个值”,但有些重复来自两组彼此独立的多值事实。假设平台允许一位讲师参加多个教研组,也允许登记多个办公地点:
讲师 T11 属于“数据库组”和“数据工程组”,办公地点有“东区 302”和“西区 508”。如果组别与办公地点相互独立,表中必须保存四种组合:
这里可能没有任何非平凡函数依赖,所以模式甚至可能已经是 BCNF;但每增加一个教研组,就要重复全部办公地点,反之亦然。
多值依赖的含义
在关系模式 上, 表示:固定 后, 的取值集合独立于 的取值集合。若有两个元组在 上相同,那么交换它们的 部分后,形成的另外两个元组也必须存在。
对元组 ,若 ,则必须存在 ,使:
函数依赖会禁止某些元组组合,例如 禁止同一个 对应不同 ;多值依赖则要求补齐元组组合,因此前者常被理解为产生等值约束,后者是产生元组约束。
若 ,或 ,则 是平凡多值依赖。每个函数依赖都蕴含对应的多值依赖:
多值依赖还满足互补性:
所以在示例中,teacher_id ↠ group_name 与 teacher_id ↠ office 表达的是同一独立性结构的两面。
第四范式与分解
设 包含函数依赖和多值依赖。关系模式 属于第四范式(4NF),当 中每个 至少满足一项:
- 多值依赖是平凡的;
- 是 的超键。
4NF 比 BCNF 更严格。因为每个函数依赖都是多值依赖,若模式违反 BCNF,也必然违反 4NF;但满足 BCNF 的模式仍可能因独立多值事实而违反 4NF。
若非平凡多值依赖 的左侧不是超键,可以按与 BCNF 类似的方式分解:
示例被分为:
teacher_group(teacher_id, group_name)teacher_office(teacher_id, office)
二元分解在多值依赖下的无损判据更一般:若公共属性多值决定任意一侧,即 或 ,分解无损。4NF 分解算法通过选择这样的违规多值依赖,保证每一步无损。
8
一个关系已经满足 BCNF,就不可能再有由独立多值事实造成的冗余。
第一范式与更高范式处理的是不同边界
1NF 关心属性值的形状,BCNF、3NF 关心函数依赖,4NF 关心多值依赖。把它们排成“数字越大越高级”的单一路线,容易忽略每种范式实际解决的约束类型。
原子域与第一范式
若关系中每个属性的域都被当作不可再分的单元,关系满足第一范式(1NF)。例如在 student 表中把多个电话号码塞进一个逗号分隔字符串,会让一个单元格承载集合;更合适的设计是:
student(student_id, student_name)student_phone(student_id, phone_number, phone_type)
复合地址也要按使用方式判断。如果系统需要按省、市、街道筛选或分别校验,应把它们建成独立属性;若系统始终把一段地址当作不可解释的投递标签,数据库层面可以把它视作原子值。
“原子”不是由底层类型天然决定的,而是由应用如何解释它决定。整数可以拆成数字,但正常业务不会把员工数量的百位与十位分开查询,所以整数通常是原子的。类似 CS-204 的课程编号虽然人能看出前缀,但只要应用不解析前缀来推导院系,并另有 department_id 保存院系,它仍可作为原子标识符。若应用依赖前缀含义,编码就在偷偷承担复合属性职责,一旦院系调整就会引发级联改号。
集合值还会诱发双向冗余。若讲师行内保存“所授班次集合”,班次行内又保存“讲师集合”,一次排课变更要更新两个位置。保留其中一份又会让反向查询依赖集合拆解。关系表 teaches(teacher_id, offering_id) 用一行表达一个关联,既符合 1NF,也能从两个方向建立索引。
现代数据库可以存数组、JSON、范围和复合类型。使用非原子类型并非天然错误,但要明确它的事务边界、查询方式和约束能力。规范化分析建立在关系属性可按语义独立比较的前提上;若把关键业务事实藏进 JSON 字符串,依赖和唯一性通常更难由数据库强制执行。
2NF、PJNF 与 DKNF 的位置
第二范式(2NF)排除非主属性对候选键真子集的部分依赖。它在历史上用于解释复合键造成的重复,但 3NF 与 BCNF 给出了更强且更统一的标准,实际设计通常直接以 3NF 或 BCNF 为目标。
多值依赖还不是约束表达的终点。连接依赖推广了“一个关系可以无损分解为多个投影”的条件,对应投影连接范式(PJNF),也常称第五范式(5NF)。更一般的域约束和键约束引出域键范式(DKNF)。这些范式能处理更隐蔽的冗余,但约束识别和推理成本很高,缺少像函数依赖那样易用的完整工具链,因此日常系统里较少直接以它们驱动设计。
高范式不是目的本身。先准确表达业务事实,再识别真实依赖;如果约束只存在于想象中,强行分解会制造连接成本和无法表达的关联。
9
关于原子性,哪些判断符合 1NF 的语义?
规范化要嵌入完整的数据库设计流程
规范化不是拿到上线表以后才做的清洁工作。它应当贯穿概念建模、关系转换、约束评审与性能验证。
从概念模型到关系模式
关系模式可能来自三条路径:由实体—关系模型转换;先把所有属性放进一个通用关系再分解;或由开发者凭需求先写出若干表,再检查范式。三条路径都能工作,但风险不同。
细致的概念建模通常天然产生较好的关系:实体各有自己的关系,多对多联系有独立关系,多值属性被拆成“实体键 + 属性值”的关系。如果由实体生成的表仍有 department_id → campus 之类非键决定因素,往往说明概念模型漏掉了 department 实体;优先回到概念层修正,比只在物理表层打补丁更清楚。
多对多联系与多值属性被正确转换后,通常也会自然避开 4NF 的独立多值冗余。相反,把所有属性先放入一个“万能大表”,虽然便于集中列出函数依赖,却容易把不同实体的可选关系混在一起,产生大量空值和异常。
命名也属于约束表达
同名属性应当表达相同角色,不同含义不要共用一个模糊名字。例如 phone_number 与 room_number 都叫 number,会让自然连接、查询生成和代码阅读产生歧义。若学员姓名与讲师姓名未来都会抽象为人员姓名,可以统一使用 name;如果同一关系中同时出现两种角色,则应写成 student_name、teacher_name。
属性顺序在关系理论中没有意义,但把主键放在模式定义前部便于阅读。实体名用单数还是复数都可以,关键是整个系统一致。联系表名称应表达角色,如 teaches、enrollment,不要机械拼成难以区分的 person_person。
反规范化必须带着维护责任
若页面每次都要展示课程及其全部先修课,规范化设计需要连接 course 与 prerequisite。为了读性能把结果直接存成一张冗余表,叫反规范化。它不是免费优化:课程名修改时,所有重复副本都必须同步,应用要承担额外编码、事务与故障恢复成本。
在数据库支持良好时,物化视图通常比手工冗余表更容易管理,因为刷新和一致性维护由数据库负责。但它仍消耗存储与更新计算,且约束是否能直接施加在物化结果上取决于具体系统。应先用真实查询计划、数据量和延迟目标证明连接确实是瓶颈,再决定是否引入冗余。
范式无法识别所有坏设计
一个模式满足 BCNF,也可能非常难维护。若按年份创建 enrollment_2025、enrollment_2026 等表,每年都要改模式和查询;或者用 count_2025、count_2026 做列,也要每年加列。这些表内部可能都满足 BCNF,却把“年份这个数据值”写进了表名或列名。
更稳定的结构是 department_year(department_id, year, student_count),让年份成为行中的属性。交叉表适合报表展示,数据库可以在查询输出阶段旋转行列;它不适合作为长期存储模式。
一个完整评审顺序可以是:先确认事实粒度与实体边界,再写出依赖和候选键;检查 1NF、BCNF/3NF、必要时 4NF;验证每次分解的无损性与整体依赖保持;最后审查命名、时间、可选关系、约束落地和查询性能。
10
按年份建立 enrollment_2025、enrollment_2026 等结构,即使每张表都满足 BCNF,主要设计问题是什么?
时间数据让“同一事实”多出有效区间
普通关系保存某一时刻的状态;时间数据库还要保存事实在哪段时间内成立。例如课程 C07 曾叫“数据库原理”,后来更名为“数据库系统”。若只覆盖 course_title,历史成绩单就无法显示学员修课当时的课程名。
一种直接设计是在需要追踪变化的关系中加入 valid_start 与 valid_end:
时间区间最好统一为左闭右开 :事实在 start 时刻生效,在 end 时刻已经失效。相邻版本可以让前一条的结束时间等于后一条的开始时间,不会在交界点重叠。
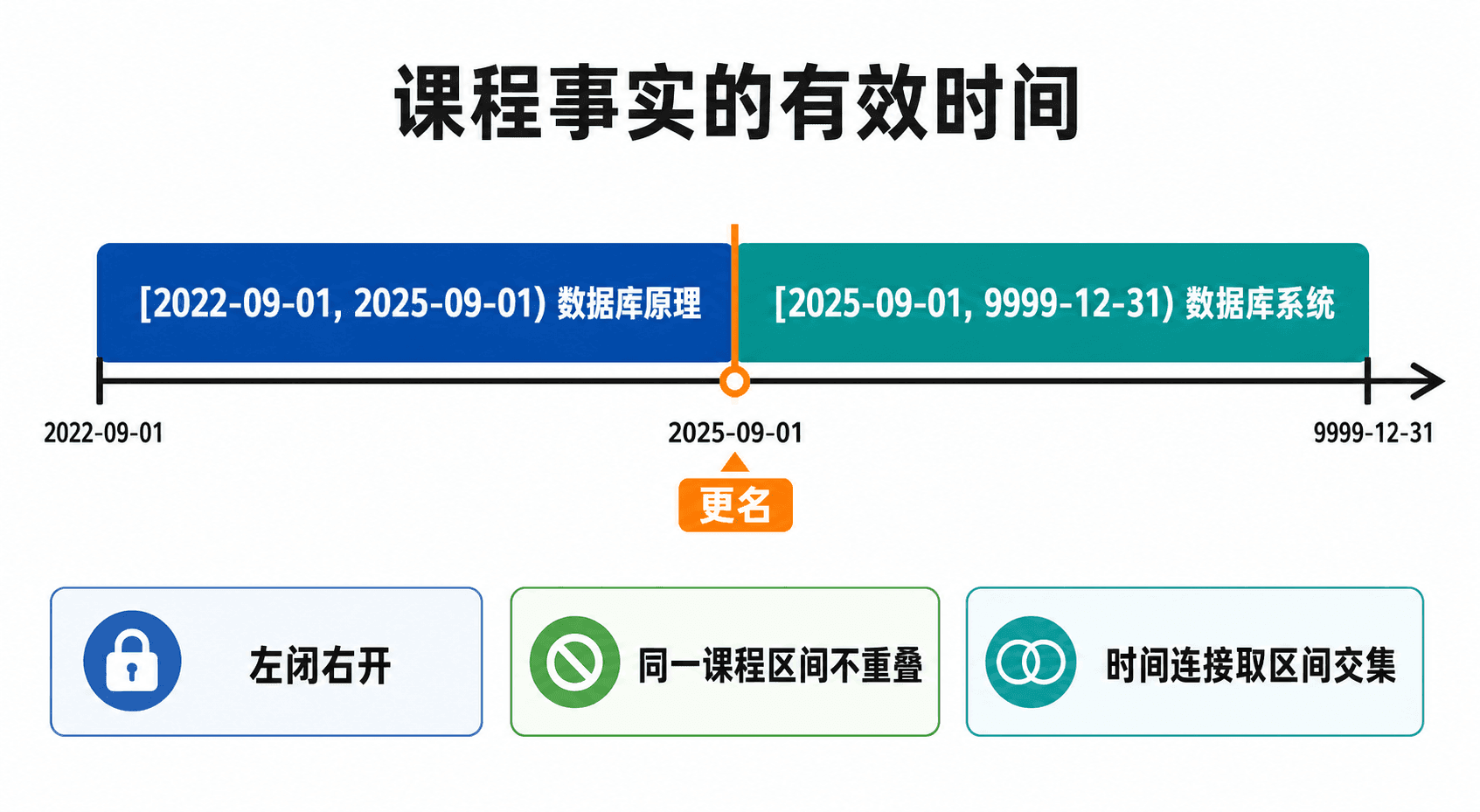
图:更新历史事实不是覆盖旧行,而是截短旧区间并创建从同一边界开始的新版本。
快照函数依赖与时间主键
加入时间以后,普通依赖 course_id → course_title 在整张历史表上不再成立,因为同一课程可以有多个标题。真正成立的是:在任意时刻 的数据快照中,一个课程编号只有一个标题和所属院系。可写成时间函数依赖:
把 valid_start、valid_end 简单加入普通主键仍不够。两条记录可以有不同端点却区间重叠,例如 [2025-01-01,2025-08-01) 与 [2025-06-01,2025-12-01)。时间主键的真实约束是:相同业务键的有效区间不得重叠。
更新当前版本时,应在同一事务中完成两步:把旧版本的 valid_end 改为变更时刻;插入以该时刻为 valid_start 的新版本。还要检查 valid_start < valid_end、同键区间不重叠,以及是否允许时间轴出现空洞。
时间外键要求覆盖,不只是命中
普通外键只要在被引用表中找到相同键值。时间外键还要求引用事实的整个有效区间,被一个或多个匹配的被引用版本覆盖。
例如开课记录在 [2026-02-20,2026-07-01) 引用课程 C07。课程表可以用两个首尾相接的版本共同覆盖这段时间,不必存在一条区间完全相同的课程记录;但覆盖不能中断。若只在某一天能找到 C07,不代表整个学期的引用都有效。
历史成绩单还需要明确“按哪个时间点解释课程”。可以把学期映射为一个代表日期,寻找包含该日期的课程版本;也可以给选课记录本身保存学期区间,选择与之重叠的版本。若课程可能在学期中更名,必须先确定成绩单显示规则,而不是让查询偶然返回多行。
时间连接使用区间交集
时间选择和投影通常保留输入元组的有效区间。时间连接则只连接有效区间相交的元组,结果区间取二者交集:
若交集为空,这一对元组不会进入结果。实现查询时常用 overlaps、contains、before、after 等区间谓词,并显式计算交集。
另一种做法是保留当前表,再建历史表记录每次变更。它适合审计“数据库何时写入了什么”,却不一定能回答“业务事实在何时有效”。这里要区分有效时间与事务时间:前者描述现实世界何时成立,后者描述数据库何时知道或记录。仅有变更日志,无法自动把历史成绩精确关联到当时有效的课程版本。
时间建模不只是多加两个日期字段。你需要同时定义区间端点语义、当前记录表示法、重叠与空洞规则、时间主键、时间外键、版本更新事务,以及历史查询应按有效时间还是记录时间解释。
11
关于有效时间设计,哪些说法正确?