撤销、暂存与找回丢失提交
会提交只是 Git 的一半。另一半是判断“错误发生在哪一层”,再选择不会扩大损失的恢复方式。本节会分别处理工作区、暂存区、已发布提交、未发布历史和临时工作。
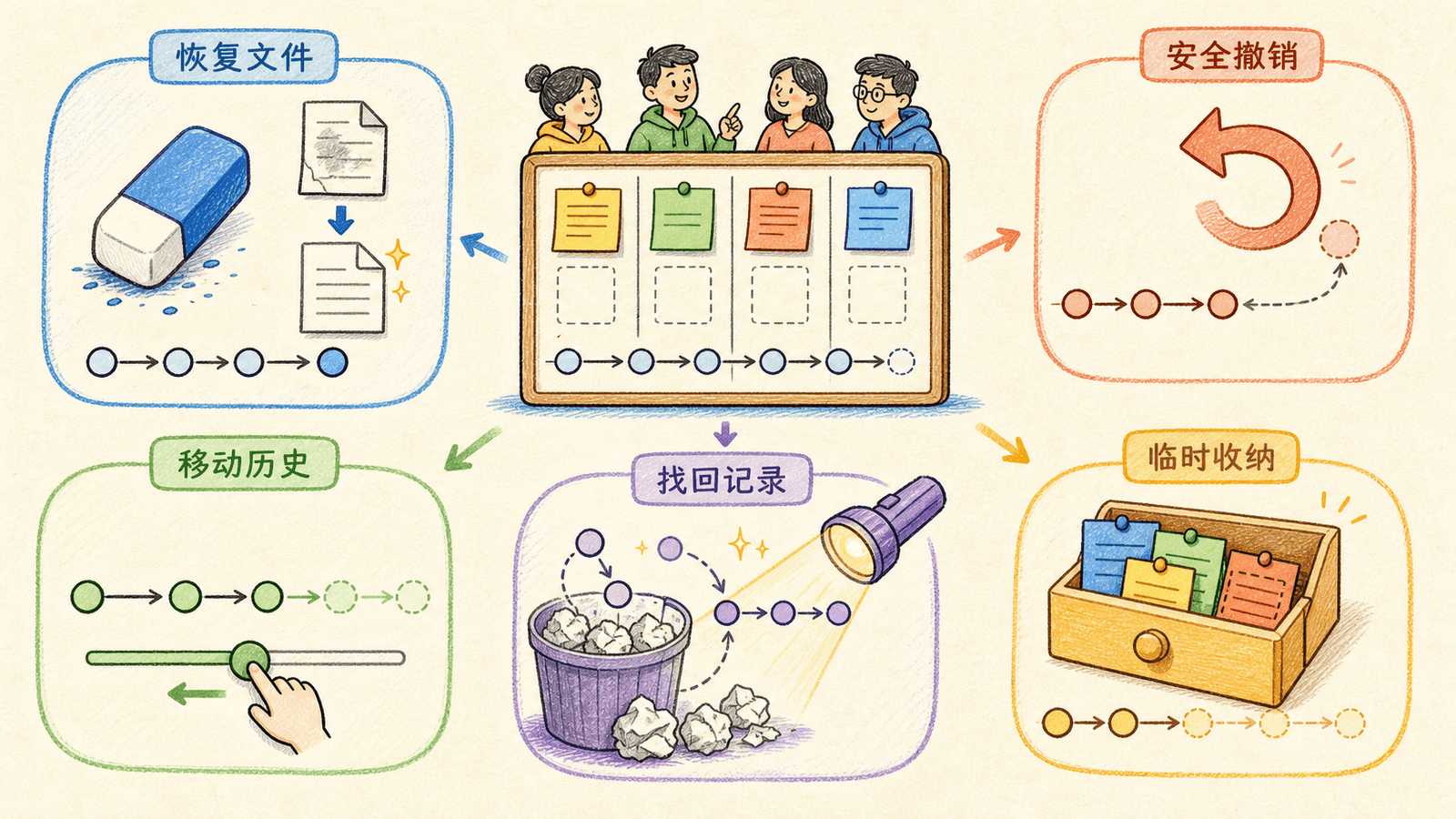
先用状态确定错误在哪
看到错误时先停一下,不要立刻执行 reset --hard。按顺序查看:
bash
git status --short
git diff
git diff --cached
git log --oneline -5判断依据:
恢复工作区文件
先制造一处不需要的修改:
bash
printf '\n这行稍后撤销。\n' >> README.md
git diff --stat结果:
text
README.md | 2 ++
1 file changed, 2 insertions(+)确认确实不要这处修改后:
bash
git restore README.md
git status --short最后一条命令没有输出,说明工作区恢复到暂存区中的版本。
git restore 文件 会覆盖尚未提交的工作区修改。Git 通常不能从历史中找回这些内容,执行前必须先看 git diff。
取消暂存但保留修改
给任务清单加一行并暂存:
bash
printf '\n- [ ] 演示暂存撤销\n' >> tasks.md
git add tasks.md
git status --short结果:
text
M tasks.md现在只想把内容移出暂存区,不想删除编辑结果:
bash
git restore --staged tasks.md
git status --short结果:
text
M tasks.mdM 从左列移到右列,修改仍在工作区。若这行也不需要,再执行 git restore tasks.md。
用 revert 撤销已共享提交
假设错误开关已经提交:
bash
printf 'debug=true\n' > status.txt
git add status.txt
git commit -m "chore: add temporary debug switch"如果这条提交已经被别人获取,不要移动公共历史。创建一条反向提交:
bash
git revert --no-edit HEAD结果示例:
text
[main 427a9c7] Revert "chore: add temporary debug switch"
1 file changed, 1 deletion(-)
delete mode 100644 status.txt历史会同时保留错误和修正:
text
427a9c7 Revert "chore: add temporary debug switch"
e67b83e chore: add temporary debug switch
bc6bde7 merge: resolve task owner conflict这正是公共分支需要的可追踪性:没有让别人已经看到的提交突然消失。
用 reset 整理未发布提交
reset 会移动当前分支指针。只在确认提交尚未共享时使用。建立实验分支:
bash
git switch -c experiment/reset
printf '\n草稿说明。\n' >> README.md
git add README.md
git commit -m "draft: add unfinished note"先软重置一条提交:
bash
git reset --soft HEAD~1
git status --short结果:
text
M README.md提交消失了,但修改仍在暂存区。继续执行默认的混合重置:
bash
git reset HEAD
git status --short结果:
text
M README.md现在修改回到工作区。三种常见模式可以这样区分:
git reset --hard 会丢弃工作区和暂存区中的修改。课程不把它当成普通清理命令;只有已经检查并确认可丢弃时才使用。
结束练习:
bash
git restore README.md
git switch main
git branch -D experiment/reset这个分支的草稿有意丢弃,所以这里明确使用强制删除。
用 reflog 找回分支移动前的提交
引用日志记录 HEAD 和分支最近移动到过的位置。即使分支被重置,提交对象通常不会立刻消失。
假设执行重置后忘记了提交 ID,先看:
bash
git reflog -4 --oneline结果示例:
text
427a9c7 HEAD@{0}: reset: moving to HEAD~1
13217c7 HEAD@{1}: commit: docs: add recovery note
427a9c7 HEAD@{2}: checkout: moving from main to recovery-demoHEAD@{1} 指向重置前的提交。不要再次移动当前分支,先创建救援分支固定它:
bash
git branch rescued 13217c7
git show rescued:recovery.md结果:
text
一段需要找回的说明。提交短 ID 会不同,应该从你自己的 reflog 读取。确认内容后,可以把提交合并或拣选回需要的分支。
用 stash 暂存半成品
当工作还不适合提交,却需要马上切换任务时,可以连同未跟踪文件一起收起:
bash
printf '\n- [ ] 通知功能草稿\n' >> tasks.md
printf '未跟踪草稿\n' > scratch.md
git stash push -u -m "draft: notifications"
git status --short-u 会包含未跟踪文件。状态没有输出,工作区恢复干净。查看储藏列表:
bash
git stash list结果:
text
stash@{0}: On main: draft: notifications恢复并从列表中删除这一项:
bash
git stash pop如果只想恢复但暂时保留备份,使用 git stash apply。储藏也可能和新修改发生冲突,恢复后仍要检查 git status 和 git diff。
这份草稿只用于演示,恢复后清理它,让下一节从干净状态开始:
bash
git restore tasks.md
rm scratch.md
git status --short最后一条命令应没有输出。
清理未跟踪文件要先预演
git clean 处理未跟踪文件,不处理已跟踪修改。先只看它准备删除什么:
bash
git clean -nd确认清单后才执行:
bash
git clean -fd被 .gitignore 忽略的文件默认不会删除。不要为了“清得彻底”随手加 -x,它会把依赖、构建缓存和可能包含凭据的忽略文件也纳入删除范围。
恢复决策练习
1
哪些操作默认不会改写已经存在的公共提交历史?
2
重置后发现一条提交不见了,优先用什么命令寻找旧位置?