Go 并发编程:从 goroutine、channel 到可取消任务系统
并发代码最难的地方,通常不是“怎么启动更多 goroutine”,而是把四件事同时说清楚:任务由谁创建,数据由谁发送,channel 由谁关闭,以及每条退出路径最终会走到哪里。
这一章会从一个能同时服务多个连接的网络程序出发,逐步搭出流水线、并行循环、有界 worker pool、可取消目录扫描和消息广播器。你会反复看到同一套设计方法:让数据沿 channel 流动,让资源有明确的所有者,让取消信号沿调用链传播,让每个 goroutine 都有可证明的终点。
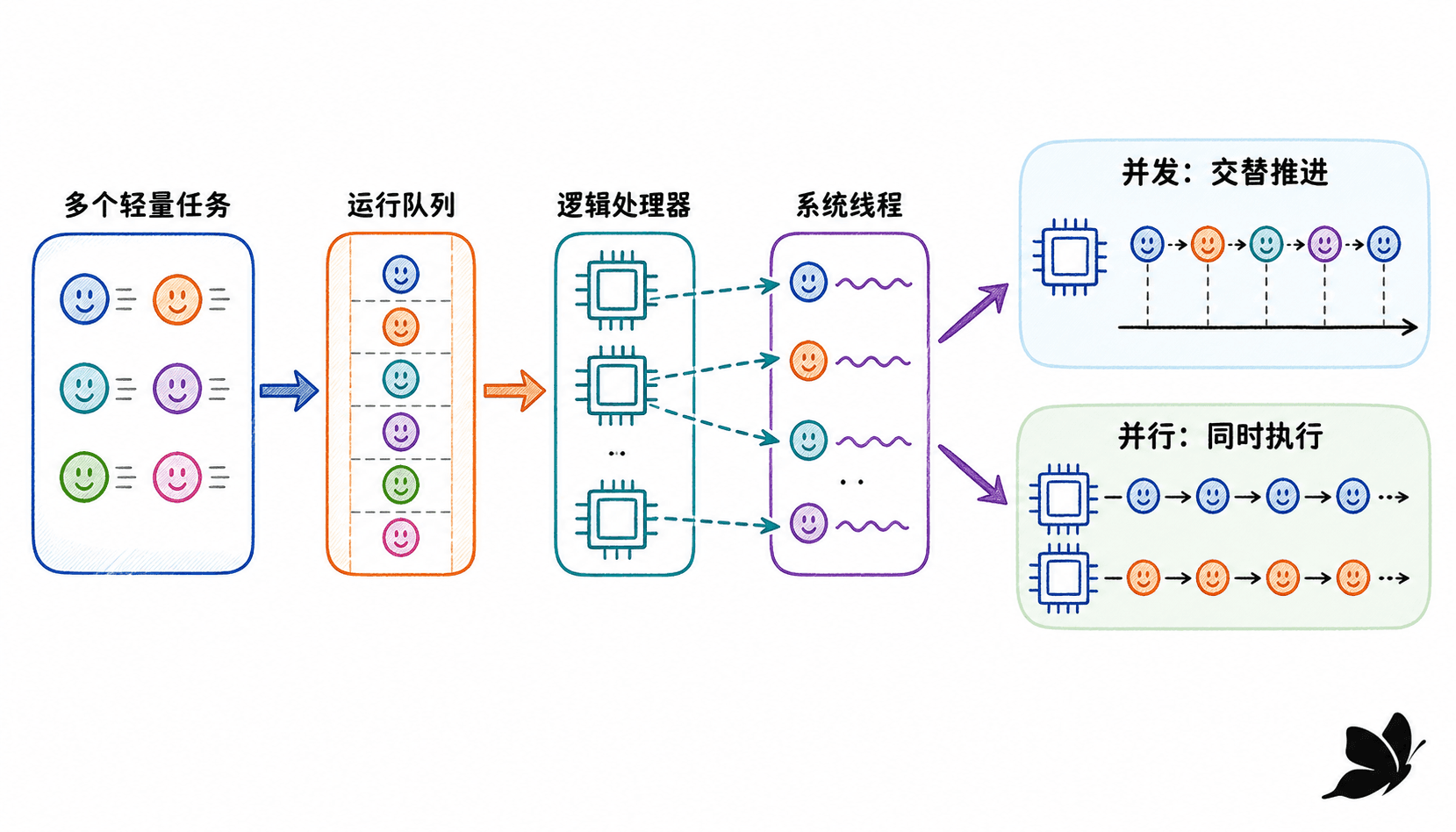
并发描述的是程序结构:多个相对独立的活动可以交错推进。并行描述的是执行状态:两个或更多计算在同一时刻占用不同处理器执行。并发程序可以只在一个线程上交错运行;并行也不等于一定更快,瓶颈可能仍在网络、磁盘、锁竞争或下游服务。
先建立正确的并发模型
goroutine 是一次并发执行的函数调用
程序启动时,main 在主 goroutine 中运行。函数调用前加 go,调用的函数值与实参会先在当前 goroutine 求值,随后函数体在新 goroutine 中执行;go 语句本身不会等待它返回。
下面的程序没有依赖 Sleep 猜测结束时间。主 goroutine 用结果 channel 等待后台计算,因此退出路径是确定的。
go
package main
import "fmt"
func sum(nums []int, out chan<- int) {
total := 0
for _, n := range nums {
total += n
}
out <- total // sum 是唯一发送者
}
func main() {
result := make(chan int)
go sum([]int{3, 5, 8, 13}, result)
fmt.Println("合计:", <-result)
}这个例子故意没有关闭 result。关闭 channel 的意义是告诉接收方“不会再有值”,并不是释放资源的必做动作。主 goroutine 只接收一次,而且发送方恰好发送一次,所以没有必要额外关闭。
1-1
只要启动了 goroutine,main 返回后它仍会继续完成工作。
生命周期比创建方式更重要
Go 没有“从外部强行杀死某个 goroutine”的安全操作。强行终止会让它持有的状态停在任意位置。工程上要做的是协作式退出:工作函数在 channel、网络读写、定时器或 context.Done() 等等待点观察停止信号,然后自己返回。
分析一个 goroutine 时,可以按顺序问:
- 它会在哪些地方阻塞?
- 谁能让这些阻塞解除?
- 调用方提前返回时,它是否仍能收到退出信号?
- 它返回前需要关闭连接、停止计时器或通知等待者吗?
如果最后两个问题答不上来,这段代码就有泄漏风险。
1-2
下面哪种做法最适合等待后台任务完成?
用网络服务理解 goroutine 的边界
从串行连接处理到并发连接处理
TCP 监听器的 Accept 会等待新连接。串行服务器在 Accept 之后直接调用连接处理函数,这意味着当前客户端不退出,服务器就不会回到下一次 Accept。并发版本只改一个结构:每个成功接受的连接交给独立 goroutine;监听循环马上继续接收下一个连接。
先看一个并发时钟服务。每条连接都有自己的 ticker,每秒向客户端写入当前时间;客户端断开后写操作失败,处理函数返回并关闭连接。监听器只负责接受连接,不负责关闭已经移交给处理器的连接。
go
package main
import (
"fmt"
"log"
"net"
"time"
)
func serveClock(conn net.Conn) {
defer conn.Close()
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for now
2-1
并发时钟服务为什么能同时服务多条长连接?
回声服务把连接读写放进同一个生命周期
回声服务读取一行文本,再写回转换后的结果。连接处理器同时拥有读取循环和连接关闭责任,因此对端断开、扫描错误和正常返回都会汇聚到同一条清理路径。
go
package main
import (
"bufio"
"fmt"
"log"
"net"
"strings"
)
func handle(conn net.Conn) {
defer conn.Close() // handle 拥有这个连接的关闭责任
input := bufio.NewScanner(conn)
for input.
这里的所有权很清楚:监听 goroutine 创建连接处理任务;handle 接管 conn,并保证返回时关闭它。读操作因为对端断开而结束,处理 goroutine 随即退出。
2-2
并发服务器中,每个连接处理函数最常用 ____ 保证退出时关闭连接。
一个连接里也可能有多个并发活动
回声服务可以一边继续读取客户端输入,一边让先前的响应延迟输出。此时要先确认 net.Conn 的并发使用规则,并设计连接何时关闭。只给内部调用加 go 很容易产生悬空任务:外层扫描结束后立刻关闭连接,仍在延迟输出的 goroutine 会写入已关闭连接。
更可靠的结构是把响应任务交给固定 worker 或用 WaitGroup 等待连接内任务结束。Go 1.25 起 sync.WaitGroup 提供 Go 方法;它会登记任务、启动函数,并在函数返回时减少计数。任务函数不应 panic。
go
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
messages := []string{"你好", "并发", "再见"}
for _, msg := range messages { // Go 1.22+:msg 每轮是新变量
wg.
旧代码常见“循环变量被所有 goroutine 共享”的问题。当前 Go 中,range 使用 := 声明的迭代变量每轮独立;但如果循环变量是在外部声明、循环里只做赋值,它仍然是同一个变量。阅读旧项目时还要结合模块声明的语言版本判断。
2-3
并发连接处理器必须明确哪些问题?
把 channel 当作协议而不是容器
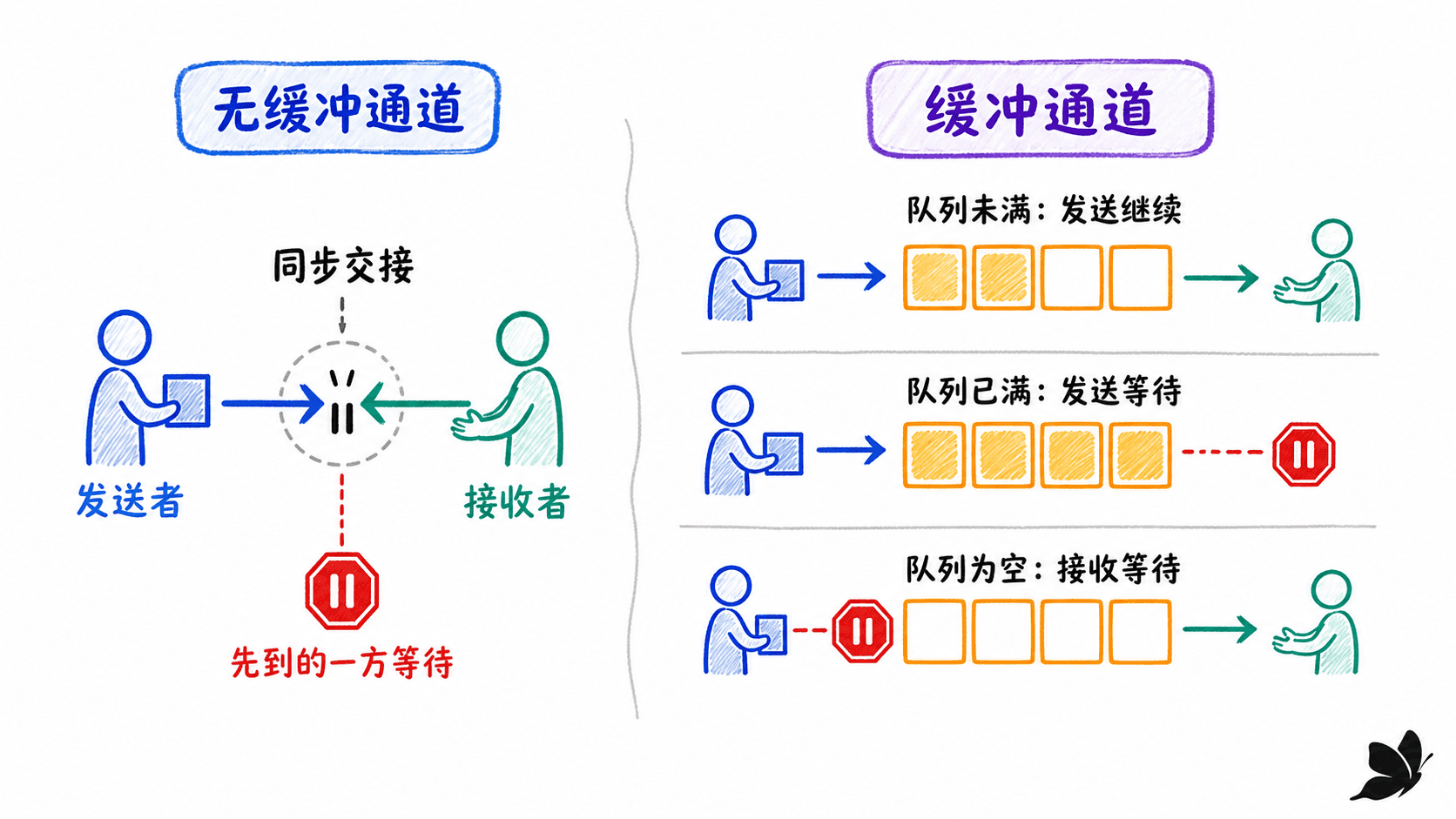
无缓冲 channel 是一次同步交接
make(chan T) 创建无缓冲 channel。发送只有在接收方已经能够接收时才能完成;接收也会等待发送方。值的交接同时形成同步关系:接收完成发生在对应发送完成之前,双方都能据此推理事件顺序。
有缓冲 channel 用 make(chan T, n) 创建。发送在缓冲区未满时可以完成,接收在缓冲区非空时可以完成。缓冲削弱了发送方和接收方的同步耦合,它适合吸收短暂速率差或表达有界容量,但不是“加上就更快”的开关。
len(ch) 只是读取瞬间的缓冲元素数,下一条语句执行前它就可能变化。不要先判断 len(ch) 再决定发送或接收;需要非阻塞通信时用带 default 的 select。
3-1
容量为 2 的 channel 已有两个值,此时第三次发送会怎样?
方向类型把协议写进函数签名
chan<- T 只允许发送,<-chan T 只允许接收。双向 channel 传入函数时可以隐式收窄为单向 channel,反向转换不允许。方向类型不会创建新通道,它只是限制当前引用能做的操作。
下面的发送方拥有输出 channel,因此它负责关闭;接收方只消费,既不能发送,也不能关闭这个只读引用。
go
package main
import "fmt"
func produce(out chan<- int) {
defer close(out)
for i := 1; i <= 4; i++ {
out <- i
}
}
func consume(in <-chan int) int {
total
3-2
接收方发现暂时没有数据时,应该主动 close 输入 channel。
close、range 与零值要一起理解
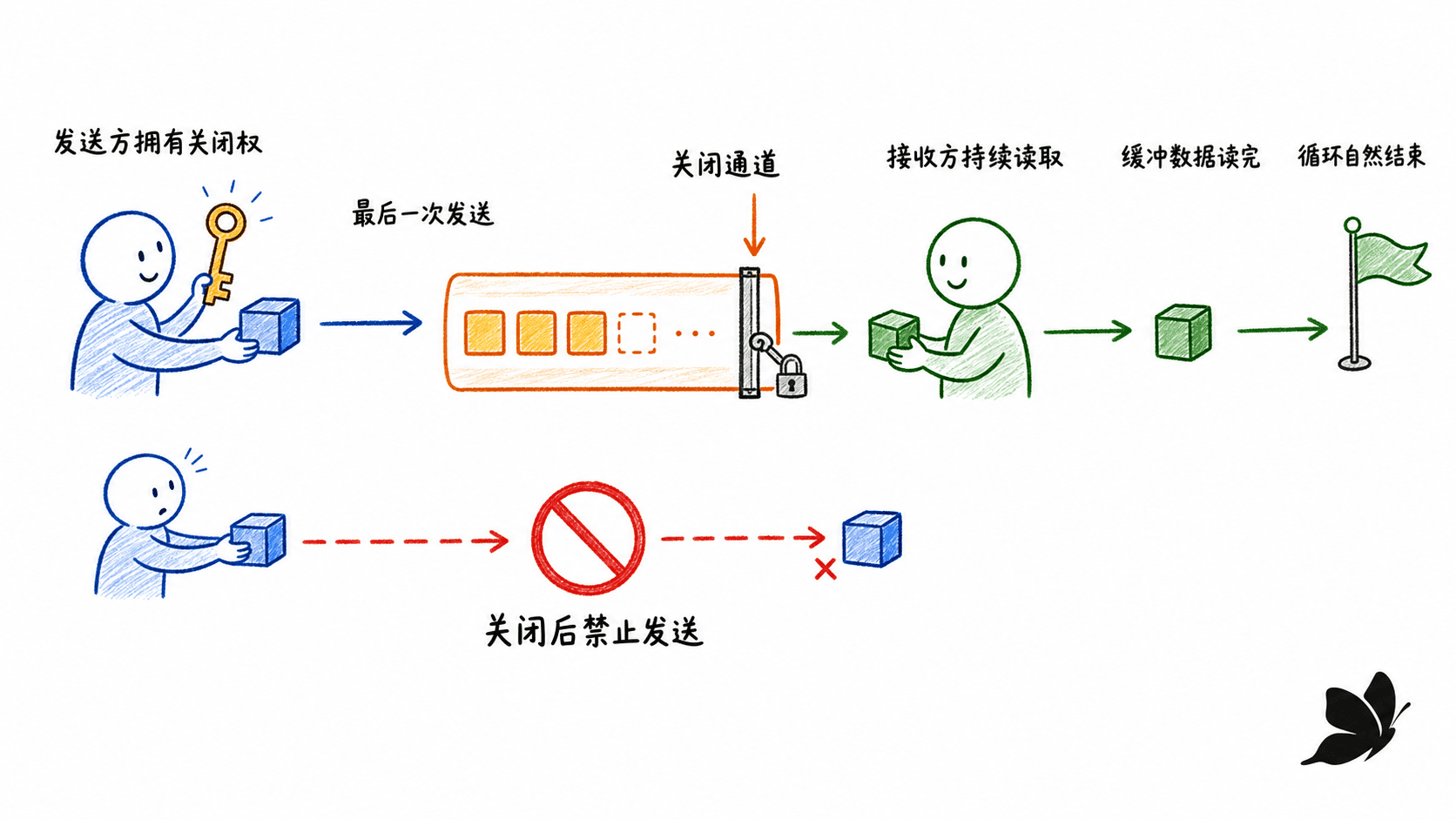
关闭 channel 不是塞入一个特殊值,而是改变通道状态。已发送到缓冲区的值仍可被接收;排空之后,接收会立刻返回元素类型零值,并令双返回值形式中的 ok 为 false。for v := range ch 会一直接收到关闭且排空为止。
向已关闭 channel 发送、再次关闭它、关闭 nil channel 都会 panic。对 nil channel 的发送或接收会永久阻塞;在 select 中,涉及 nil channel 的 case 永远不会就绪,这一点可以用来动态启用或禁用分支。
3-3
关于关闭后的 channel,哪些说法正确?
用流水线组织数据流
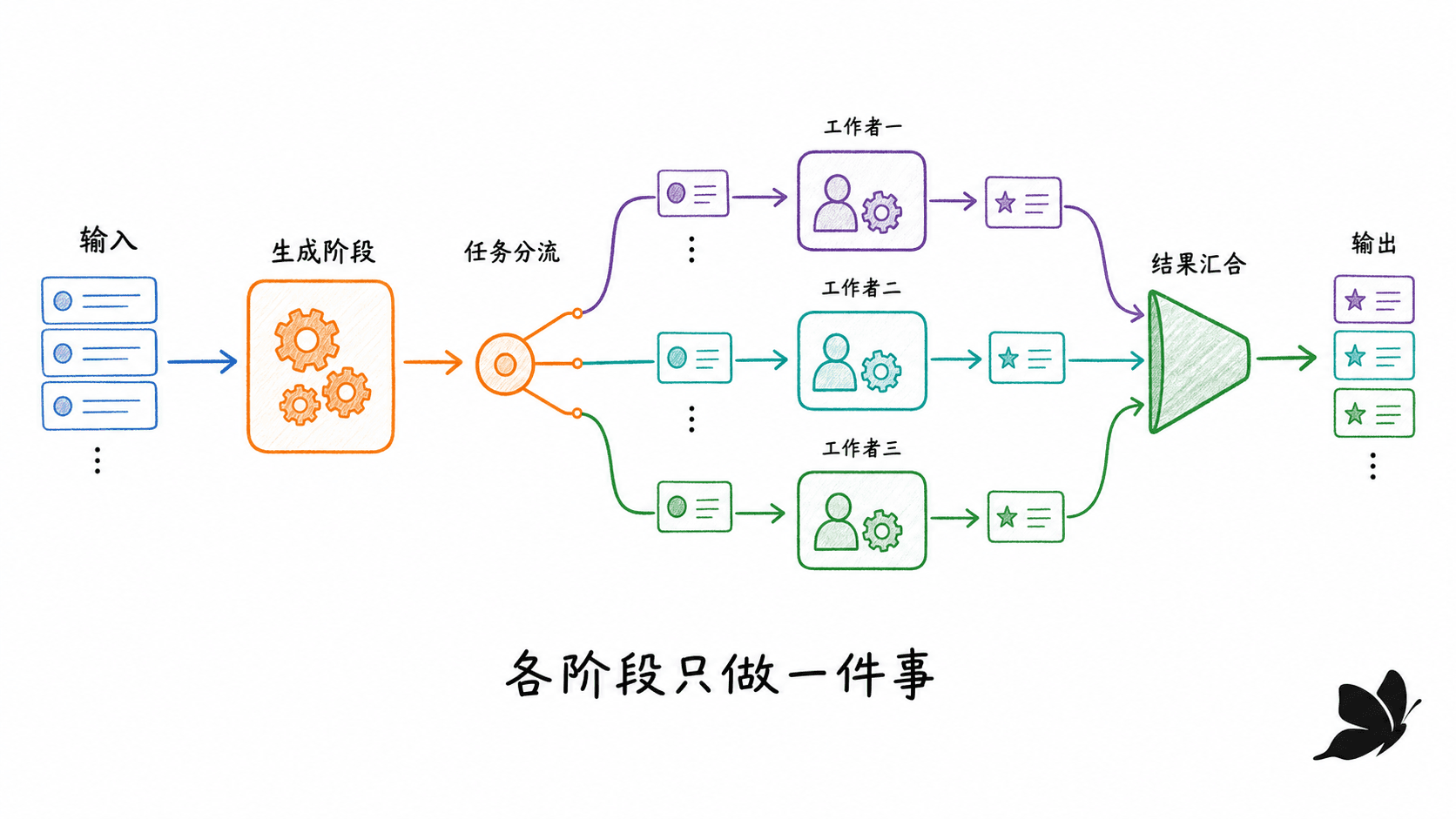
每个阶段都要说明输入、输出和关闭责任
流水线把处理拆成多个阶段:每个阶段从入站 channel 接收值,完成一种变换,再把结果发送到出站 channel。源阶段只输出,汇阶段只输入,中间阶段同时拥有输入和输出。
一条稳定的关闭规则是:阶段只关闭自己创建并负责发送的出站 channel;阶段从不关闭入站 channel。这样关闭信号会从上游自然向下游传播。
go
package main
import "fmt"
func generate(nums ...int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for _, n := range nums {
out <- n
}
}()
return out
4-1
流水线阶段通常由负责发送的一方关闭它的 ____ channel。
fan-out 与 fan-in
当一个阶段成为瓶颈,可以让多个同构 worker 同时从同一个输入 channel 取值,这叫 fan-out。每个输入值只会被其中一个接收者取得,天然实现任务分发。
fan-in 把多个结果 channel 合并成一个输出。合并器通常为每个输入启动一个转发 goroutine,再用 WaitGroup 等待所有输入耗尽。只有等待全部转发任务结束的协调 goroutine 才能关闭合并后的输出;如果任意 worker 自行关闭公共输出,就可能与其他发送者竞争。
go
package main
import (
"fmt"
"sync"
)
func worker(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in {
out
输出顺序不固定,因为两个 worker 的完成顺序不固定。如果业务需要保持输入顺序,要在任务里携带索引,汇总后按索引落位,不能把调度顺序当成协议。
4-2
fan-in 合并器为什么要等所有转发任务结束后再关闭输出?
下游提前退出必须通知上游
如果消费者只取第一个结果就返回,上游可能永远阻塞在发送上。垃圾回收不会替你终止这些 goroutine。流水线必须满足二选一:下游保证接收完所有上游输出,或者下游能广播取消,让每个可能阻塞的发送点都可退出。
在新代码里通常把 context.Context 传入各阶段,并在发送时使用 select 同时监听 ctx.Done()。后文会给出完整写法。
4-3
消费者停止接收后,阻塞在发送上的 goroutine 会因为不可达而自动被垃圾回收。
并行循环、爬虫与并发上限
等待全部结果,而不是启动完就返回
把循环体前面加 go 只完成了“启动”,没有完成“等待”和“收集错误”。并行循环至少需要三部分:登记任务数、每条路径报告完成、调用方等待全部任务。若结果通过 channel 返回,还要安排一个协调者在全部发送结束后关闭结果 channel。
WaitGroup.Add 必须在启动 goroutine 之前完成,否则主 goroutine 可能先执行到 Wait,看到计数为零并提前返回。当前版本可用 WaitGroup.Go 减少手工配对 Add/Done 的机会。
5-1
为什么不能在新 goroutine 内部先调用 wg.Add(1)?
无界并发会把压力传给系统
并发爬虫若为每个新链接立即启动 goroutine,很快会撞上文件描述符、DNS、连接数、内存或远端限流。并发上限应靠近真正稀缺的资源:限制 HTTP 请求,就在发请求前取得额度;限制磁盘读取,就在打开目录或文件前取得额度。
一种写法是容量为 n 的 channel 信号量。发送空结构体取得令牌,接收释放令牌。取得令牌也应响应取消,否则任务可能在等待额度时泄漏。固定 worker pool 往往更直接:启动 n 个长期 worker 从有界队列取任务,队列满后生产者自然承受背压。
go
package main
import (
"context"
"fmt"
"sync"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 300*time.Millisecond)
defer cancel()
jobs := make(chan int,
5-2
固定 worker pool 能直接限制哪些量?
爬虫还需要去重与在途计数
并发爬虫不仅要限制请求数,还要知道何时结束。常见结构是让一个协调 goroutine 独占 seen 集合,避免并发读写 map;worker 只负责抓取并返回发现的链接。协调者对每个已派发任务增加在途计数,对每批完成结果减少计数。当在途计数归零且没有新链接时,才能确认遍历结束。
这个结构体现了“通过通信共享状态”:seen 只属于协调者,不需要锁。若多个 goroutine 都要直接访问它,就必须改用互斥锁或其他同步方案。
用 select 处理多个事件源
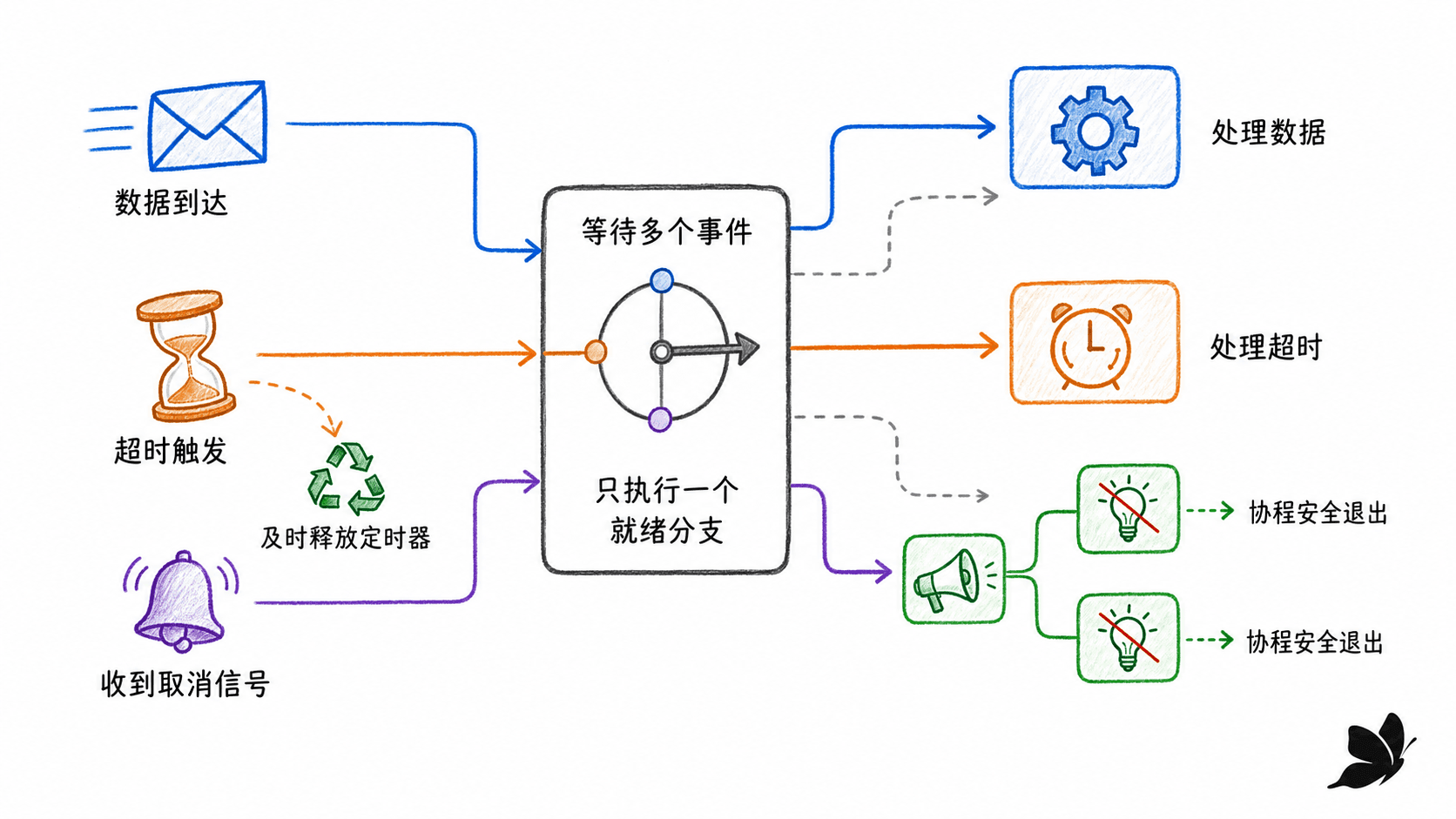
select 只考虑当前可执行的通信
select 的每个 case 是一次 channel 发送或接收。没有 case 就绪且没有 default 时,select 阻塞;存在 default 时立即执行它。多个 case 同时就绪时,规范要求从可执行项中做均匀伪随机选择。
这条规则不能被夸大成“每个 channel 长期公平”或“某个 case 最迟若干轮必被选中”。调度、输入到达时刻和每轮就绪集合都会变化。如果业务需要优先级、配额或严格轮询,要把它写成显式状态机。
6-1
select 有多个 case 同时就绪时,运行时保证每个 case 在有限轮数内一定被选择。
default 是非阻塞操作,不是等待策略
带 default 的 select 常用于“能发送就发送,否则丢弃”“能收到就处理,否则继续”。如果放在没有任何阻塞或休眠的循环里,会形成忙轮询,占满 CPU。
go
package main
import "fmt"
func main() {
updates := make(chan string, 1)
updates <- "版本 2"
select {
case value := <-updates:
fmt.Println("收到:", value)
default:
fmt.Println("当前没有更新")
6-2
在无限循环中反复执行只有 channel case 和 default 的 select,最可能出现什么?
超时、定时器与周期事件
一次性超时可以使用 time.After,需要重置或主动停止时使用 time.NewTimer。周期事件可用 time.NewTicker,不再需要周期事件时调用 Stop 仍能表达清楚的生命周期。
Go 1.23 引入了新的 timer 实现:垃圾回收器能够回收不再被引用、尚未停止的 timer/ticker;timer 的 channel 也改为无缓冲,Stop/Reset 返回后不会再收到旧配置留下的陈旧时间值。这套语义默认用于 go.mod 声明 go 1.23 或更高版本的主模块;GODEBUG=asynctimerchan=1 可以强制使用旧实现。即便如此,业务上不再需要事件时主动停止,仍能避免无意义的唤醒并让所有权更清楚。
go
package main
import (
"fmt"
"time"
)
func main() {
result := make(chan string, 1)
go func() {
time.Sleep(30 * time.Millisecond)
result <- "完成"
}()
timer := time.
6-3
要让 select 在 200ms 后进入超时分支,可以接收 ____ 返回的 channel。
并发目录遍历:递归、进度与收尾
目录树天然适合分解,但磁盘并不喜欢无限并发
目录扫描可以把每个子目录交给新 goroutine,并将普通文件大小发送到汇总 channel。调用方一边接收大小一边累计文件数和字节数。关键难点是:递归过程中才知道还会产生多少子任务,谁来判断“最后一个任务已结束”?
可用 WaitGroup 记录正在进行的目录任务。每发现一个子目录,先登记,再启动;每个遍历函数返回时报告完成。独立协调 goroutine 等待计数归零,然后关闭结果 channel。打开目录的操作还应受信号量或固定 worker 数限制,避免同时占用过多文件描述符。
go
package main
import (
"fmt"
"os"
"path/filepath"
"sync"
)
func main() {
roots := []string{"."}
sizes := make(chan int64)
sem := make(chan struct{},
这个版本用于说明动态任务计数,但还没有取消传播。若主 goroutine 提前停止接收 sizes,遍历任务会阻塞。生产代码应把取得信号量和发送大小都放进监听 ctx.Done() 的 select,下一节会补齐这条退出路径。
7-1
并发目录遍历中,协调 goroutine 的主要职责有哪些?
用 ticker 报告进度
汇总循环可以用 select 同时接收文件大小和 ticker 事件:收到大小就更新总计,收到 tick 就打印快照,结果 channel 关闭后打印最终值并退出。若不开启进度显示,可把 tick channel 保持为 nil,对应 case 会被禁用,不必维护两套循环。
7-2
把 select 中某个接收 channel 设为 nil,可以临时禁用该 case。
取消传播与 context
关闭信号 channel 可以广播
向一个 channel 发送一个值只能唤醒一个接收者;关闭 channel 后,所有接收者都能立刻观察到关闭,所以关闭适合广播取消。只有取消源可以关闭它,其他 goroutine 只持有接收方向。
标准库把这套约定封装成 context.Context。Done() 返回一个只读 channel;父 context 取消时,派生 context 也会取消。Err() 区分主动取消与截止时间到期。Context 应作为第一个参数显式传递,不要传 nil,也不要为了省参数把它随意存进长期结构体。
8-1
一个父 context 被取消后,通常会发生什么?
每个可能长时间阻塞的点都要能取消
只在函数入口检查一次 ctx.Err() 不够。goroutine 可能随后阻塞在发送、接收、取得信号量、网络请求或等待计时器上。要缩短取消延迟,就把这些等待改为 select,同时监听 ctx.Done()。
go
package main
import (
"context"
"fmt"
"time"
)
func produce(ctx context.Context, out chan<- int) error {
defer close(out)
for i := 1; ; i++ {
select {
case
错误 channel 容量为 1,保证生产者即使在调用方改变接收顺序时也能报告一次最终错误。谁创建 ctx, cancel := context.WithCancel/WithTimeout(...),谁就应在所有退出路径调用 cancel,通常紧跟 defer cancel()。
8-2
哪些等待点通常应该响应 ctx.Done()?
HTTP 请求要携带 context
客户端请求可用 http.NewRequestWithContext 创建。请求的 context 控制获取连接、发送请求以及读取响应头和响应体的整个生命周期。服务端处理器从 r.Context() 取得请求上下文;客户端断开、HTTP/2 请求被取消或处理函数返回时,它会被取消。
context 值只适合携带跨 API 边界的请求级元数据,不适合塞可选参数或大对象。超时也要分层:请求总期限、连接超时、响应头超时可能解决不同问题。
8-3
为 HTTP 客户端请求绑定取消信号,优先使用 http.____。
常见泄漏、死锁与数据竞争
泄漏通常来自“没人再接收”
最典型的泄漏是后台 goroutine 试图向无缓冲结果 channel 发送,而调用方因超时或错误已经返回。修复不能只靠“把 channel 缓冲改大一点”;若结果数无上限,缓冲只会推迟问题。需要让发送可取消、保证排空,或为确定数量的一次性结果提供恰好足够的缓冲。
另一个常见问题是 worker 在等待永远不会关闭的任务 channel。channel 的创建者必须把关闭时机写入协议,或者 worker 同时监听 context。
9-1
遇到 goroutine 泄漏时,把所有 channel 容量统一改成 1000 就能根治。
死锁是等待关系形成闭环
单个 goroutine 向无缓冲 channel 发送后才准备接收,会立刻自锁;多个 goroutine 也可能互相等待。排查时把每个阻塞点画成边:G1 等 G2 接收,G2 等 G3 释放令牌,G3 又等 G1 发送结果,闭环就是根因。
全局死锁时运行时往往会报告所有 goroutine 都在休眠,但局部泄漏未必触发报告,因为程序其他部分仍在运行。测试可结合超时、goroutine dump 和 go test -race;race 检测器找的是未同步的共享内存访问,不会自动证明没有逻辑死锁。
9-2
go test -race 主要帮助发现什么?
慢消费者会拖住广播器
聊天广播器通常由一个 goroutine 独占在线客户端集合,通过 select 处理加入、离开和消息。这样 map 不需要锁。但如果广播器逐个向无缓冲客户端 channel 发送,一个不读消息的客户端会让所有人停住。
解决策略必须是产品协议的一部分:给每个客户端有界队列;队列满时断开慢客户端、丢弃新消息或丢弃旧消息;无论哪种都要记录指标。不能无限扩容,否则慢消费者会转化为内存问题。
9-3
广播系统面对慢客户端时,可接受的有界策略有哪些?
综合任务系统:把所有权和退出路径落到代码里
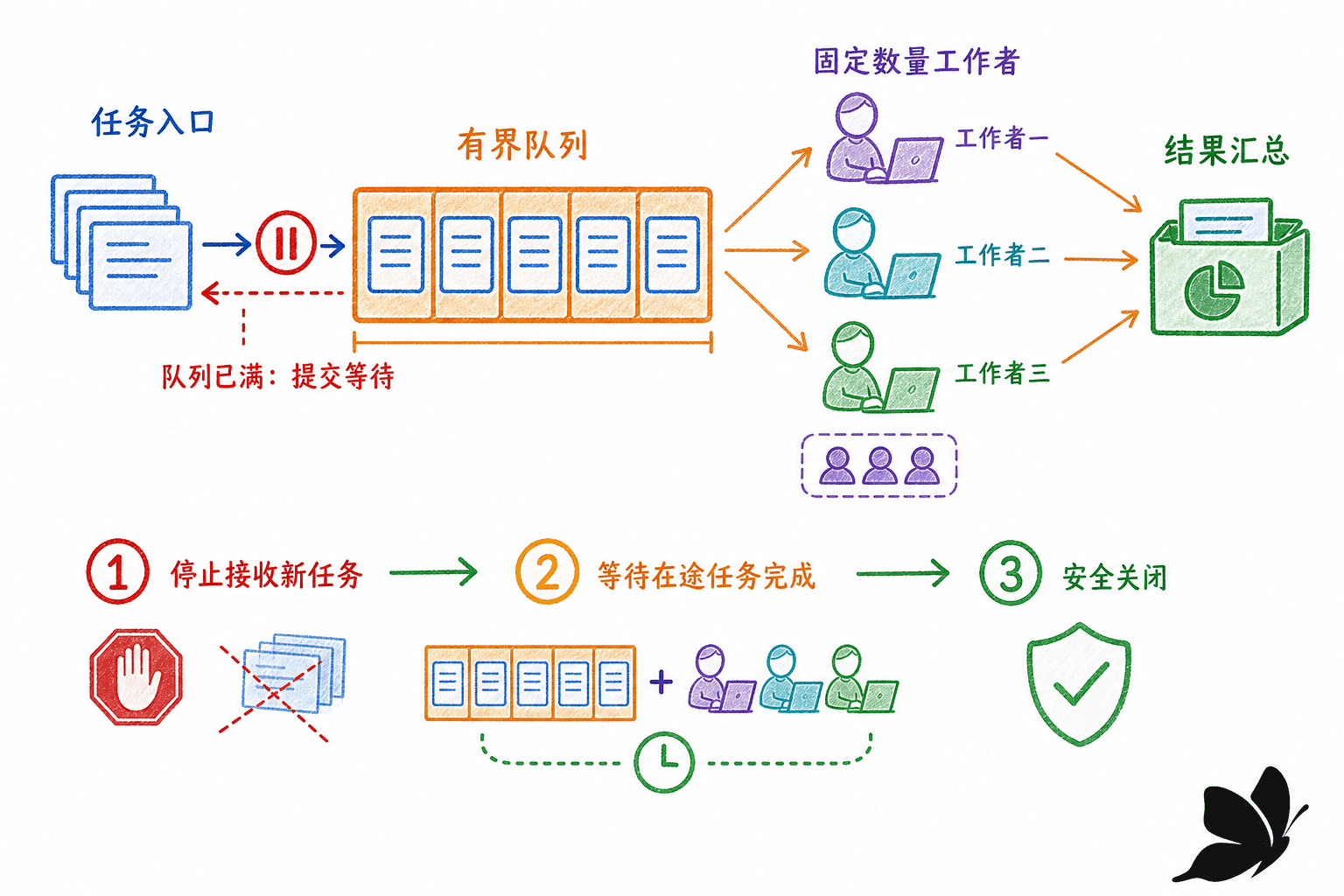
设计协议
我们要实现一个批量任务系统:调用方提交整数任务,固定数量 worker 并发处理;每个结果携带任务编号和错误;调用方可取消;结果 channel 在所有 worker 退出后关闭。
协议如下:
Run创建jobs与results,因此它安排两者的生命周期。- 投递 goroutine 是
jobs的唯一发送者和关闭者。 - 多个 worker 是
results的发送者,但谁都不单独关闭它。 - 收尾 goroutine 等全部 worker 返回,再关闭
results。 - 投递和结果发送都监听
ctx.Done(),所以消费者提前退出不会留下阻塞发送者。
go
package main
import (
"context"
"errors"
"fmt"
"sync"
"time"
)
type Task struct {
ID int
Value int
}
type Result struct {
TaskID int
Value int
Err
这个系统保证“停止接收”能沿 context 传播,但调用方仍应决定错误策略:遇到第一个错误就调用 cancel(),还是继续收集全部结果。并发层不应偷偷替业务层决定。
10-1
综合示例中,谁负责关闭 results?
把聊天服务器映射到同一结构
聊天服务器也可以看成任务系统:连接处理器产生“加入、离开、消息”事件;广播器是唯一状态拥有者;每个客户端 writer 是消费 worker。广播器在离开事件中删除客户端并关闭该客户端的出站 channel,writer 的 range 随之结束并关闭网络连接。
区别在于聊天服务是长生命周期系统,不能等输入自然关闭。它要响应服务器 context,停止 Accept,通知广播器关闭所有客户端队列,并等待连接 goroutine 收尾。生产实现还要设置读写截止时间、消息长度上限和慢客户端策略。
10-2
让广播器 goroutine 独占 clients map,可以避免其他 goroutine 与它并发访问该 map。
综合练习
练习一:可取消的 fan-out/fan-in
实现 Map(ctx, workers, input, fn) <-chan Result:固定 workers 个 worker 从输入读取;fn 处理数据;输出包含原索引;任一阶段取消时全部退出;公共输出只关闭一次。最后在调用方恢复输入顺序。
练习二:有界并发爬虫
实现只访问同一主机的爬虫,最多同时发出 8 个 HTTP 请求。协调 goroutine 独占去重集合,维护待派发队列和在途计数;请求使用 http.NewRequestWithContext;在途为零时正常结束,首个不可恢复错误出现时取消全部请求。
11-1
验收这个爬虫时,哪些测试最有价值?
练习三:不会被慢客户端拖死的聊天室
为每个客户端建立容量为 32 的出站队列。广播器使用非阻塞发送;队列满时把客户端移出集合并关闭其 channel。服务器收到取消后关闭监听器、停止接收新连接、让广播器清理全部客户端,并等待现有连接任务结束。
练习四:写出并发不变量
选取你自己的一个并发函数,在代码注释中写出五条不变量:谁拥有共享状态、谁发送、谁关闭、最大并发数是多少、取消后每个 goroutine 如何到达返回点。然后故意删除一个取消分支或关闭动作,用带超时的测试复现泄漏或死锁,再修复它。
11-2
判断一个 goroutine 设计是否完整,最关键的问题是它是否拥有可证明的 ____。
到这里,可以把整章浓缩成一句可执行的检查原则:启动 goroutine 时,同时写下它的等待点、所有者和退出路径;创建 channel 时,同时写下发送者与唯一关闭者;引入并发时,同时设置资源上限和取消传播。代码能把这三组关系讲清楚,才算真正完成了并发设计。