Go 声明与程序结构
一段 Go 代码能否被读懂,往往不取决于它用了多少语法,而取决于几个名字在哪里声明、指向什么对象,又能在哪些位置被看见。变量保存状态,类型约束状态,函数组织行为,包再把这些声明组合成可以复用的单元。程序结构就是这些关系的总和。
这一节从名字开始,顺着声明、变量、赋值、类型、包和作用域向前推进。你会看到 var 与 := 什么时候各自合适,为什么交换两个变量不需要临时值,new(T) 到底创建了什么,以及一个看似普通的 := 为什么可能悄悄遮蔽外层变量。
所有示例都可以单独复制到本地验证。阅读时不要只盯着某一行“做了什么”,还要问三个问题:这个名字由哪条声明引入?它当前指向哪一个实体?它的作用域到哪里结束?这三个问题能解释本节几乎所有常见错误。
命名决定代码如何被找到
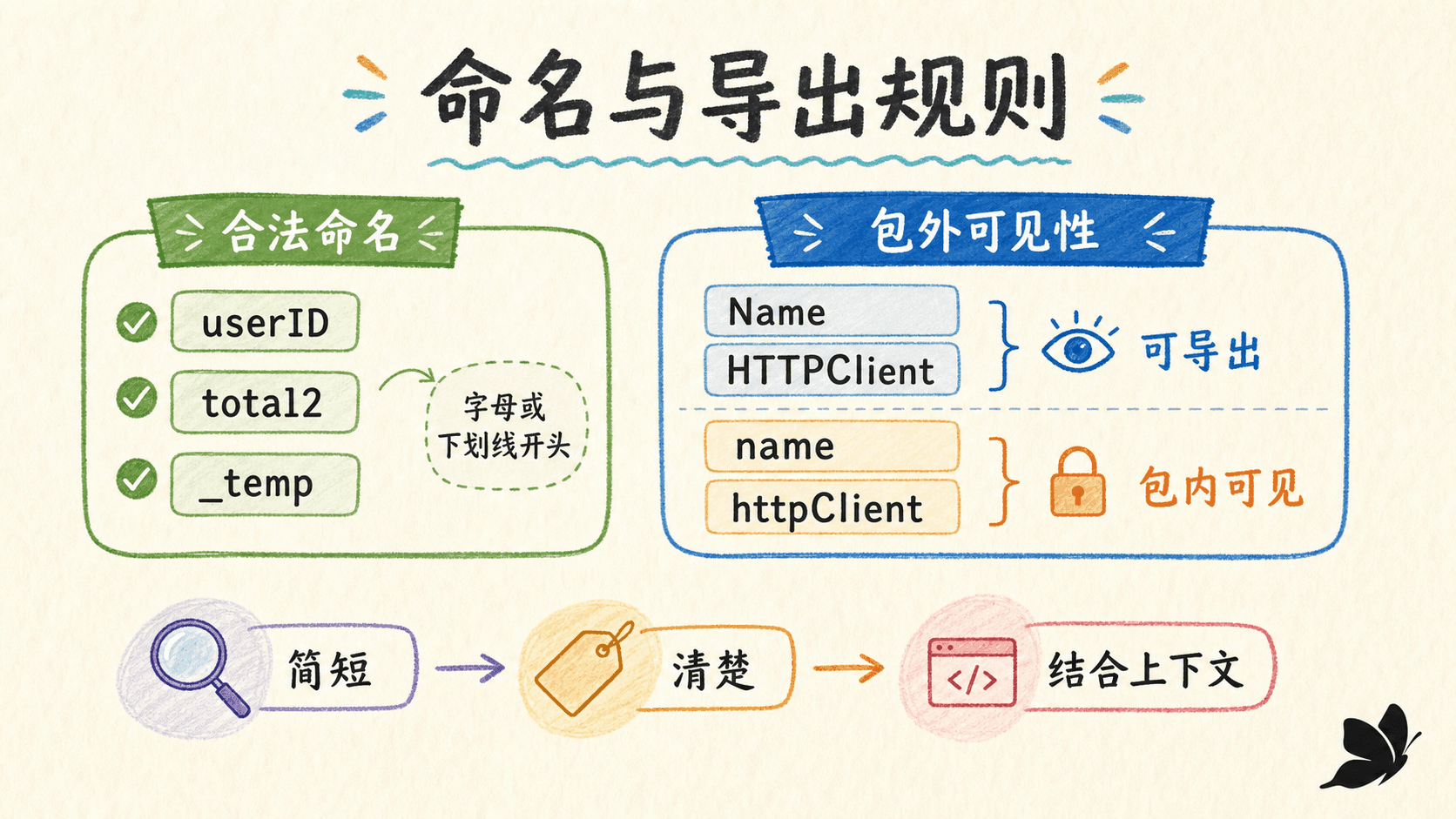
Go 的标识符可以用来命名变量、常量、类型、函数、方法、标签和包。合法标识符必须以 Unicode 字母或下划线开头,后面可以继续出现 Unicode 字母、Unicode 数字或下划线。Go 区分大小写,所以 retryCount、RetryCount 和 retrycount 是三个不同的名字。
go
package main
import "fmt"
func main() {
订单数 := 3
retryCount := 2
RetryCount := 5
fmt.Println(订单数, retryCount, RetryCount)
}语言关键字不能拿来命名,例如 func、var、if、for、return。预声明标识符则不同:int、true、len、new、any、clear、min 等名字来自最外层的预声明环境,却不是关键字。你可以在内层重新声明它们,但通常不值得这样做,因为读者会自然地把 len 理解为内置函数。
go
func count(items []string) int {
len := 10
// return len(items) // 编译错误:这里的 len 是 int 变量,不是内置函数
return len
}大写开头是一条语言规则
包外可见性不是注解,也不靠 public 关键字。一个标识符要被其他包访问,需要同时满足两个条件:它的首字符是 Unicode 大写字母,并且它声明在包级,或者它是字段名或方法名。函数里的局部变量即使写成 Total,也不会因此“导出”。
go
package invoice
var TaxRate = 0.06 // 包外可通过 invoice.TaxRate 访问
var rounding = 2 // 只在 invoice 包内可见
func Total(price float64) float64 { // 导出函数
return round(price * (1 + TaxRate))
}
func round(v float64) float64 { // 包内辅助函数
return v
导出只是“可以被包外引用”,并不等于“设计得适合公开”。导出的名字会成为包的使用界面,改名会影响调用方,因此公开前要想清楚它表达的契约。包内实现细节用小写开头,可以保留更大的重构空间。
1A
函数内部声明的局部变量 Total 会因为首字母大写而被其他包访问。
名字的长度应该匹配作用域
小作用域中的 i、n、err 通常一眼就能结合上下文理解;跨越整个包的名字则应该更具体。名字不是越长越好。invoice.CalculateInvoiceTotalWithTax 在调用处会显示成一段重复的 invoice.CalculateInvoiceTotalWithTax,而 invoice.Total 往往更清楚。
Go 代码通常用 mixedCaps 或 MixedCaps 连接单词,不使用下划线分隔普通名字。包名倾向于简短、全小写、单个单词。常见首字母缩写通常保持同一大小写,例如 userID、HTTPClient、parseURL,而不是 userId 或 HttpClient。
命名与导出判断器
输入一个名字,再切换它的声明位置。这个小工具会区分“语法合法”和“可以导出”这两个问题。
1
下面哪些关于 Go 名字的说法正确?
请判断 type、订单2、2ndOrder、_cache 中哪些能作变量名。
声明搭起程序骨架
声明把名字和程序实体绑定起来。Go 最常见的四类顶层声明是 var、const、type、func:变量保存可以更新的值,常量绑定编译期可确定的值,类型声明建立类型名称,函数声明把名字绑定到一段可调用的行为。
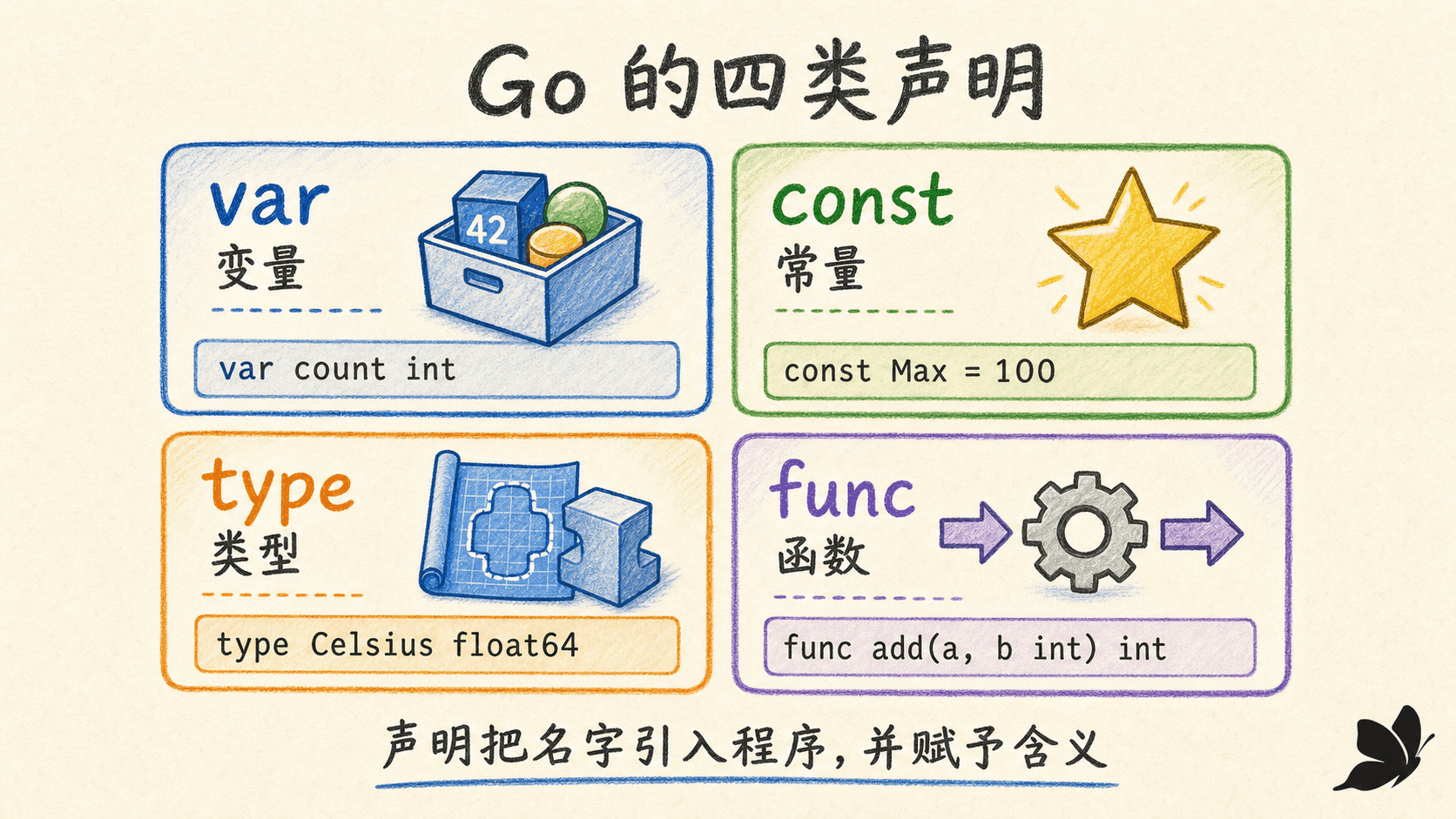
一个 .go 源文件先写 package 子句,再写该文件需要的 import,之后才是包级的变量、常量、类型和函数声明。包级声明的先后顺序通常不限制彼此引用,所以函数可以调用写在后面的函数;初始化顺序则另有规则,我们会在后面单独处理。
go
package main
import "fmt"
const serviceName = "checkout"
type Cents int64
var processed int
func main() {
price := Cents(2599)
processed++
fmt.Println(serviceName, price, processed)
}这里的 serviceName、Cents、processed 和 main 都在包级。price 在函数体内,只是局部变量。包级名字对同一个包的所有文件可见;局部名字通常只在包含它的词法块中可见。
函数声明先看边界,再看实现
函数声明包含函数名、参数列表、结果列表和函数体。参数与命名结果本身也是局部变量。没有结果时可以省略结果列表;有结果的函数必须沿所有可达路径提供相应结果。
go
func discount(price Cents, percent int) (Cents, error) {
if percent < 0 || percent > 100 {
return 0, fmt.Errorf("折扣必须在 0 到 100 之间")
}
return price * Cents(100-percent) / 100, nil
}读函数时可以先忽略函数体,只看签名:它接收什么,返回什么,调用方必须处理什么。签名给出边界,函数体给出实现。把重复计算收进函数的意义,也正是让同一条规则只有一个实现位置。
2
在同一个包的另一个 .go 文件中,可以直接使用下面哪个名字?
把下面四个需求分别配给最直接的声明关键字:保存请求计数、固定重试上限、创建业务类型 OrderID、定义校验行为。
变量从零值开始,也可能活得比函数久
变量是一块带类型的存储,声明为它绑定名字;数组元素、结构体字段和通过指针间接访问的对象也都可以表示变量。Go 不存在“内容未定义”的变量:只要没有提供显式初值,它就得到所属类型的零值。
var 的三种常见写法
go
var count int // 指定类型,初值为 0
var enabled = true // 由初值推断为 bool
var rate float64 = 0.8 // 同时写类型与初值var name type = expression 中,类型或初始化表达式可以省略一边,但不能两边都省。数字的零值是 0,布尔值是 false,字符串是 "",指针、函数、接口、切片、映射和通道的零值是 nil。数组与结构体会递归地把元素、字段设为零值。
这条规则让类型设计有一个实用目标:尽可能让零值直接可用。例如计数器的零值自然表示“尚未计数”,bytes.Buffer 的零值也可以直接写入。零值可用并不等于所有操作都成功;例如 nil 映射可以读取,却不能直接写入,这属于具体类型的行为。
多变量声明可以接收一组表达式,也可以接收函数返回的多个值:
go
var width, height int = 1280, 720
var debug, label = false, "生产环境"
var file, err = os.Open("config.json")3
var name string 声明后,name 的内容处于不可预测状态。
:= 只在函数内部声明局部变量
函数内部最常用的形式是短变量声明:
go
name := "小虎"
tries := 3
file, err := os.Open("config.json"):= 是声明,= 是赋值。短声明左侧必须至少有一个非空白标识符是当前块里的新变量。若其他名字已经在同一个词法块中声明,并且类型一致,那么它们不会被重新创建,只会接收新值。
go
in, err := os.Open("input.txt") // 新建 in 和 err
out, err := os.Create("output.txt") // 新建 out,更新同一块中的 err
// in, err := os.Open("again.txt")
// 编译错误:左侧没有任何新变量
_, _ = in, out“同一个块”是这里的重点。外层已经有 err,不代表内层的 := 会更新它。若短声明出现在更内层的块中,它可以创建一个新的同名变量并遮蔽外层变量。
如果当前块就是函数体,函数参数和命名结果参数也按这个块里的已有名字处理。例如命名结果中已经有 err 时,file, err := os.Open(name) 会新建 file,并把新错误值赋给原来的结果参数 err。短声明左侧的非空白名字还必须彼此不同,x, x := 1, 2 本身就不合法。
短声明作用域实验台
点击不同场景,观察左侧名字究竟是“新变量”还是“更新已有变量”。
4
已在函数体中执行 f, err := os.Open(a) 后,下一行 f, err := os.Open(b) 会怎样?
指针提供同一变量的另一条访问路径
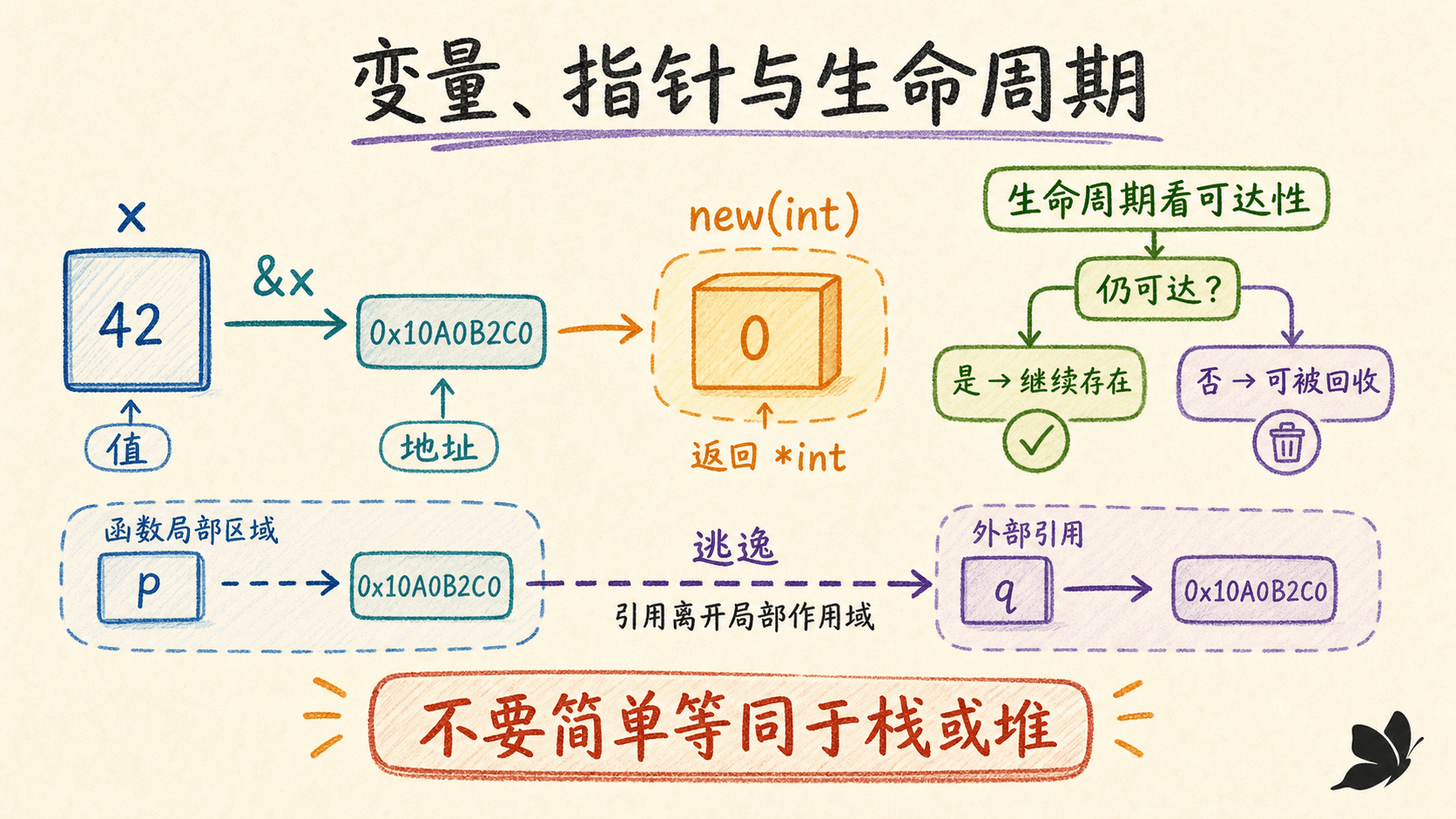
表达式 &x 取得变量 x 的地址,结果类型是 *T;若 p 的类型是 *T,*p 就是它所指向的变量。*p 既可以读取,也可以放在赋值左侧。
go
func addOne(p *int) int {
*p++ // 等价于 (*p)++,增加所指向的值
return *p
}
func main() {
n := 10
p := &n
fmt.Println(*p) // 10
fmt.Println(addOne(p)) // 11
fmt.Println(n)
指针的零值是 nil。两个指针指向同一个变量时相等;两个指针都是 nil 时也相等。通过指针访问同一变量会产生别名:n 与 *p 是同一块状态的两种写法。别名很有用,但也让状态更新不再只出现在变量名旁边,所以应限制共享可变状态的范围。
内置函数 new(T) 创建一个匿名的 T 类型变量,把它初始化为零值,并返回 *T:
go
p := new(int)
fmt.Println(*p) // 0
*p = 42
fmt.Println(*p) // 42从语言语义看,new(int) 与“声明一个 int 变量再返回它的地址”很接近。new 不会初始化切片、映射或通道内部所需的运行时结构;它只返回指向相应零值的指针。还要避免用地址是否不同来区分零尺寸变量,因为实现可以让不同的零尺寸变量拥有相同地址,也可以不同。
5
表达式 new(int) 的结果类型是 ____。
生命周期由可达性决定,不由写法决定
包级变量通常从包初始化开始存活到程序结束。局部变量则在每次执行到声明时产生一个新实例,并在不再可达后具备被回收的条件。函数返回后,局部变量不一定立刻消失:如果返回了它的地址,调用方仍能到达它,它就必须继续存在。
go
func counter() *int {
n := 0
return &n
}
func main() {
a := counter()
b := counter()
*a++
fmt.Println(*a, *b) // 1 0
}栈还是堆是编译器的存储选择,不是 var 与 new 的语义差别。局部变量的地址逃出函数时,它可能被放到堆上;反过来,new(T) 创建的对象如果没有逃逸,也可能由编译器放在栈上。写正确代码时应依据可达性推理,不要依据想象中的存储位置。优化时才需要借助编译器诊断确认逃逸情况。
长生命周期对象如果一直持有短期数据的指针,会让这些数据保持可达。垃圾回收免去了手动释放,却没有取消我们管理引用关系的责任。
6
只要使用 new(T),变量就一定分配在堆上。
赋值更新的是已有状态
声明引入变量,赋值替换变量当前保存的值。最简单的赋值左侧是一个变量名,但也可以是解引用、字段、数组或切片元素,以及映射索引。
go
count = 1
*p = 20
order.Status = "paid"
scores[i] = 100
visits["/home"] = 8复合赋值 x += y、x *= y 等不只是少写一次变量名;左侧的地址计算只进行一次。a[index()] += 2 不会调用两次 index()。++ 与 -- 在 Go 中是语句,不是产生值的表达式,因此不能写 y = x++。
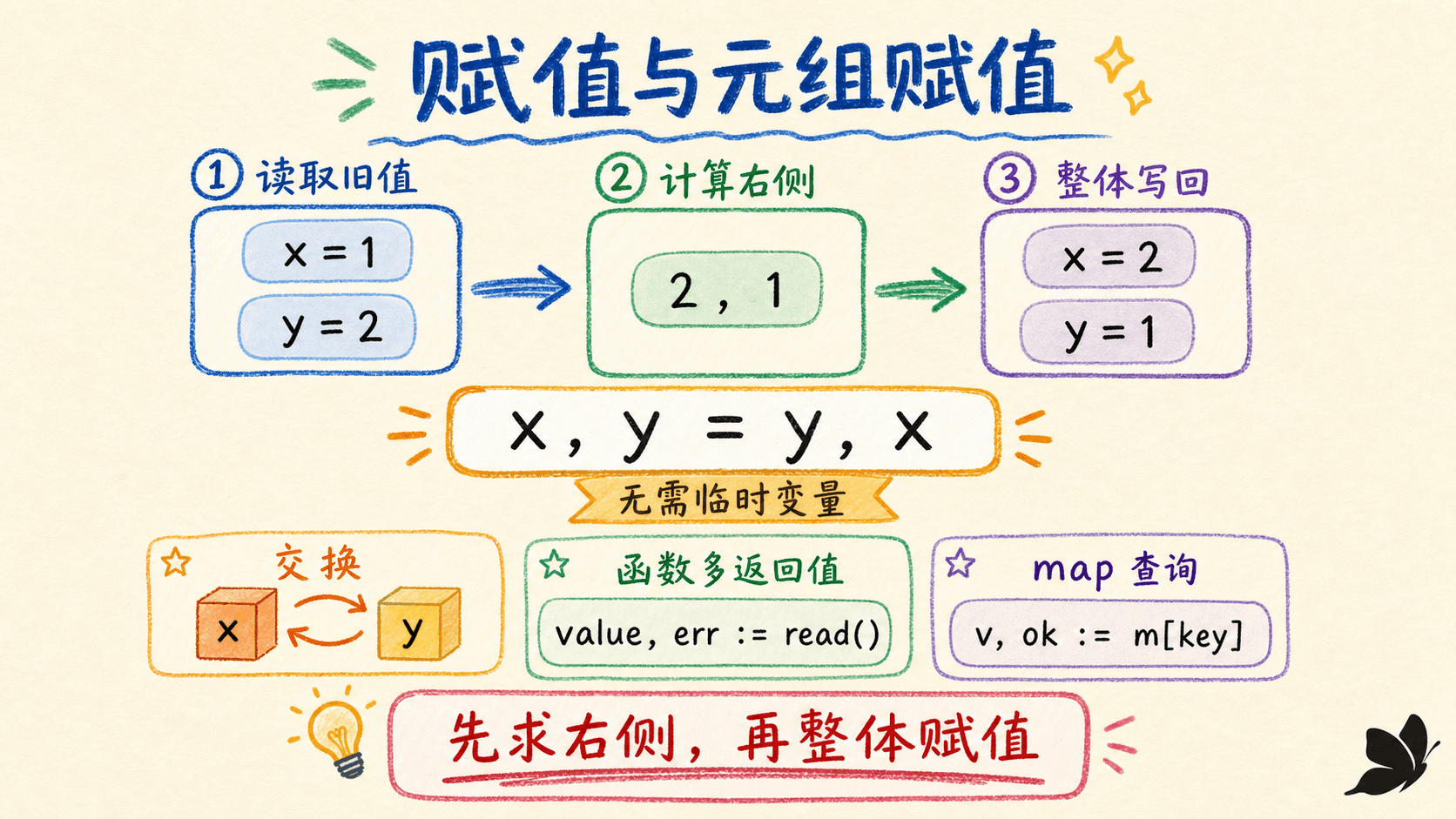
元组赋值先求值,再从左到右写入
多重赋值最实用的性质是:在任何写入发生前,左侧索引或指针位置以及右侧表达式都会先求值;之后再从左到右执行各项赋值。因此可以直接交换两个变量。
go
x, y = y, x
items[i], items[j] = items[j], items[i]同一规则也适合迭代状态:
go
func gcd(x, y int) int {
for y != 0 {
x, y = y, x%y
}
return x
}
func fibonacci(n int) int {
current, next := 0, 1
for i := 0; i <
函数可以一次返回多个值,左侧数量必须与结果数量匹配。不需要的结果交给空白标识符 _。_ 不会建立可供之后读取的变量。
go
file, err = os.Open("data.txt")
_, err = io.Copy(dst, src)
value, ok = cache[key]复杂表达式不要为了“少写几行”硬塞进一次多重赋值。多重赋值适合交换、成组状态更新和多返回值接收;当每项都有独立含义时,拆开通常更容易检查。
元组赋值两阶段演示
调整初值并选择操作,观察右侧快照和最终写入结果。
7
执行 x, y = y, x+y 前 x=2、y=3,执行后结果是什么?
可赋值性比“看起来能转换”更严格
每次显式或隐式赋值,右侧值都必须可赋给左侧类型。函数调用把实参隐式赋给形参,return 把返回表达式隐式赋给结果,复合字面量也会把各项隐式赋给元素或字段。
常用的可赋值规则可以压缩成下面几类:
- 源类型与目标类型完全相同,可以赋值。
- 两者底层类型相同,并且至少一方不是命名类型时,可以赋值。
- 目标是接口且源值实现了该接口时,可以赋值。
nil可以赋给指针、函数、切片、映射、通道和接口类型。- 无类型常量只要能由目标类型表示,就可以赋值。
通道方向和类型参数还有各自的补充规则,等用到相关类型时再展开。现阶段最容易踩的坑是:两个不同的已定义类型即使底层类型相同,也通常需要显式转换;Go 不会因为它们在内存里看起来相同就自动混用。
go
type UserID int64
type OrderID int64
var user UserID = 7
var order OrderID
// order = user // 编译错误:UserID 不能直接赋给 OrderID
order = OrderID(user) // 显式说明语义转换
var small uint8 = 255
// small = 256 // 编译错误:常量 256 不能由 uint8 表示底层类型相同并不自动意味着任意值都可直接混用。可赋值性还会考虑命名类型、接口实现、通道方向等情况。遇到疑问时,不要靠猜测“内存布局一样就该能赋”,应回到静态类型关系判断。
8
下列哪些场景包含隐式赋值?
类型声明用来隔离不同含义
两个值即使都由整数表示,也可能有完全不同的业务含义。用户编号不能误当订单编号,米不能直接当千米,摄氏温度也不能直接当华氏温度。类型定义把这种区别交给编译器检查。
go
type Celsius float64
type Fahrenheit float64
func CToF(c Celsius) Fahrenheit {
return Fahrenheit(c*9/5 + 32)
}
func main() {
var room Celsius = 24
outside := Fahrenheit(75)
// fmt.Println(room == outside) // 编译错误:类型不同
type Celsius float64 创建一个新的已定义类型,它与 float64、Fahrenheit 都不同,但底层类型仍是 float64,所以它保留底层数值类型支持的运算。跨类型使用时要显式转换,这让含义变化出现在代码表面。
转换 Celsius(x) 只改变静态类型,通常不会替你完成单位换算。若 x 表示华氏 212 度,Celsius(x) 仍是数值 212,只是类型标签变成了 Celsius。真正的单位换算应由 FToC 这样的函数完成,因为它包含数值变换规则。
类型定义与类型别名不是一回事
go
type UserID int64 // 类型定义:UserID 是新类型
type Identifier = int64 // 类型别名:Identifier 与 int64 是同一类型等号决定了语义。类型定义建立新的类型身份,可以绑定方法,也能阻止不同语义的值被无意混用。类型别名只是为同一类型提供另一个拼写,常用于兼容迁移或跨包重构,不提供新的类型隔离。
go
type Meter float64
func (m Meter) String() string {
return fmt.Sprintf("%.2f m", m)
}已定义类型可以拥有自己的方法。它不会因为底层类型是另一个已定义类型,就自动继承那个类型的方法;代码复用和类型身份是两个问题。
9
若 type Celsius float64,表达式 Celsius(212.0) 会做什么?
10
type UserID = int64 会创建一个与 int64 不同的新类型。
包和文件共同组成编译单元
Go 程序按包组织。位于同一目录、声明同一个包名的一组源文件会一起编译;同一个包内,一个文件的包级类型、变量、常量和函数可以被其他文件直接使用。文件可以按职责拆分,却仍共享包级声明。
text
shop/
├── go.mod
├── order.go // package shop
├── price.go // package shop
└── order_test.go // package shop 或 package shop_test模块是发布和版本管理的一组相关包,go.mod 中的 module 路径是模块内包导入路径的前缀。包是编译和命名空间单元;文件是组织同一个包源代码的载体。不要把“模块、包、文件”当成三个同义词。
包级声明共享,导入却属于文件
假设 price.go 使用 fmt.Sprintf,它必须自己导入 fmt。即使 order.go 已经导入 fmt,price.go 也看不到那个文件作用域中的包名。反过来,price.go 声明的包级 formatPrice 可以直接被 order.go 调用。
go
// price.go
package shop
import "fmt"
type Cents int64
func formatPrice(v Cents) string {
return fmt.Sprintf("¥%.2f", float64(v)/100)
}go
// order.go
package shop
func Summary(total Cents) string {
return "合计:" + formatPrice(total)
}导入路径标识要使用的包,导入声明则在当前文件绑定一个短包名。默认短名通常是被导入包声明的包名,也可以为解决冲突显式起别名。导入后却不使用会编译失败,这能及时清理失效依赖。
11
同一包的 a.go 已导入 fmt 后,b.go 可以直接使用 fmt.Println 而不再导入。
初始化遵循依赖,不是简单地从上往下扫文件
包级变量先按依赖关系初始化。系统反复选择“尚未初始化、且不再依赖其他未初始化变量”的最早声明;如果存在依赖环,程序无效。
go
package main
import "fmt"
var message = prefix + name
var name = loadName()
var prefix = "你好,"
func loadName() string {
return "Go"
}
func main() {
fmt.Println(message) // 你好,Go
}虽然 message 写在最前面,它依赖 prefix 与 name,所以要等两者准备好。声明在多个文件中时,语言规范以编译器接收文件的顺序定义声明顺序,并建议构建系统使用文件名词法顺序保证可复现。工程代码不应把关键逻辑建立在文件名排序这种偶然细节上;显式依赖更可靠。
包级变量都完成后,才按源代码呈现顺序调用该包的 init 函数。一个包、一个文件都可以有多个 init。它不能带参数、不能返回结果,也不能被普通代码显式调用或引用。
完整程序按依赖顺序逐包初始化:被导入的包先完成,一个包只初始化一次。每个包内部先完成包级变量,再运行 init。main 包也遵循同样步骤,最后才调用 main.main。初始化过程按包逐个、顺序推进;某个 init 即使启动 goroutine,下一个 init 仍要等当前函数返回后才会被调用。
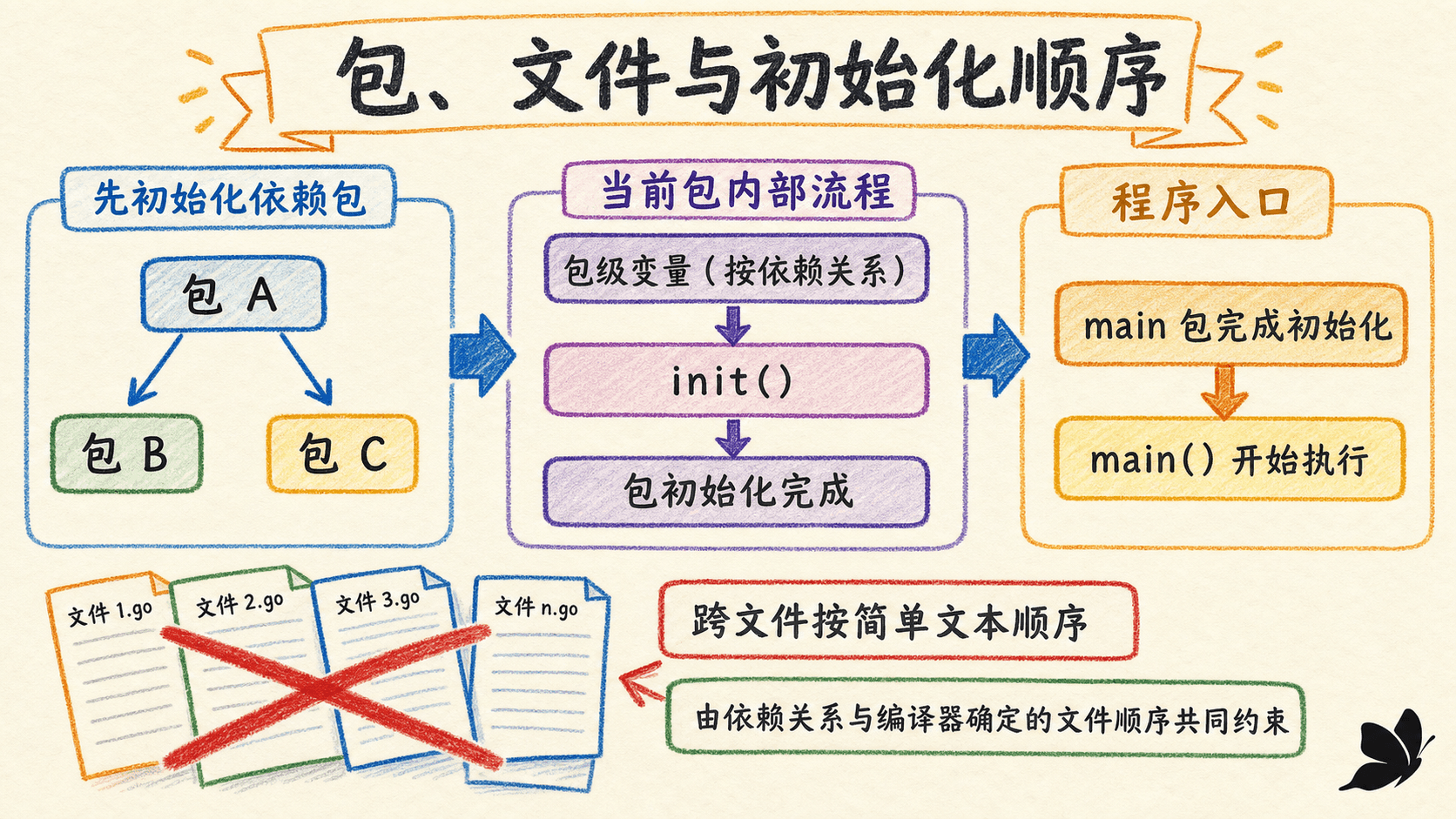
初始化顺序推演器
选择一个场景,逐步播放“依赖包 → 包级变量 → init → main”的顺序。
12
一个包的初始化顺序通常是哪一项?
如果两个包级变量存在直接或间接初始化依赖环,Go 会怎样处理?
作用域回答“这个名字在这里指谁”
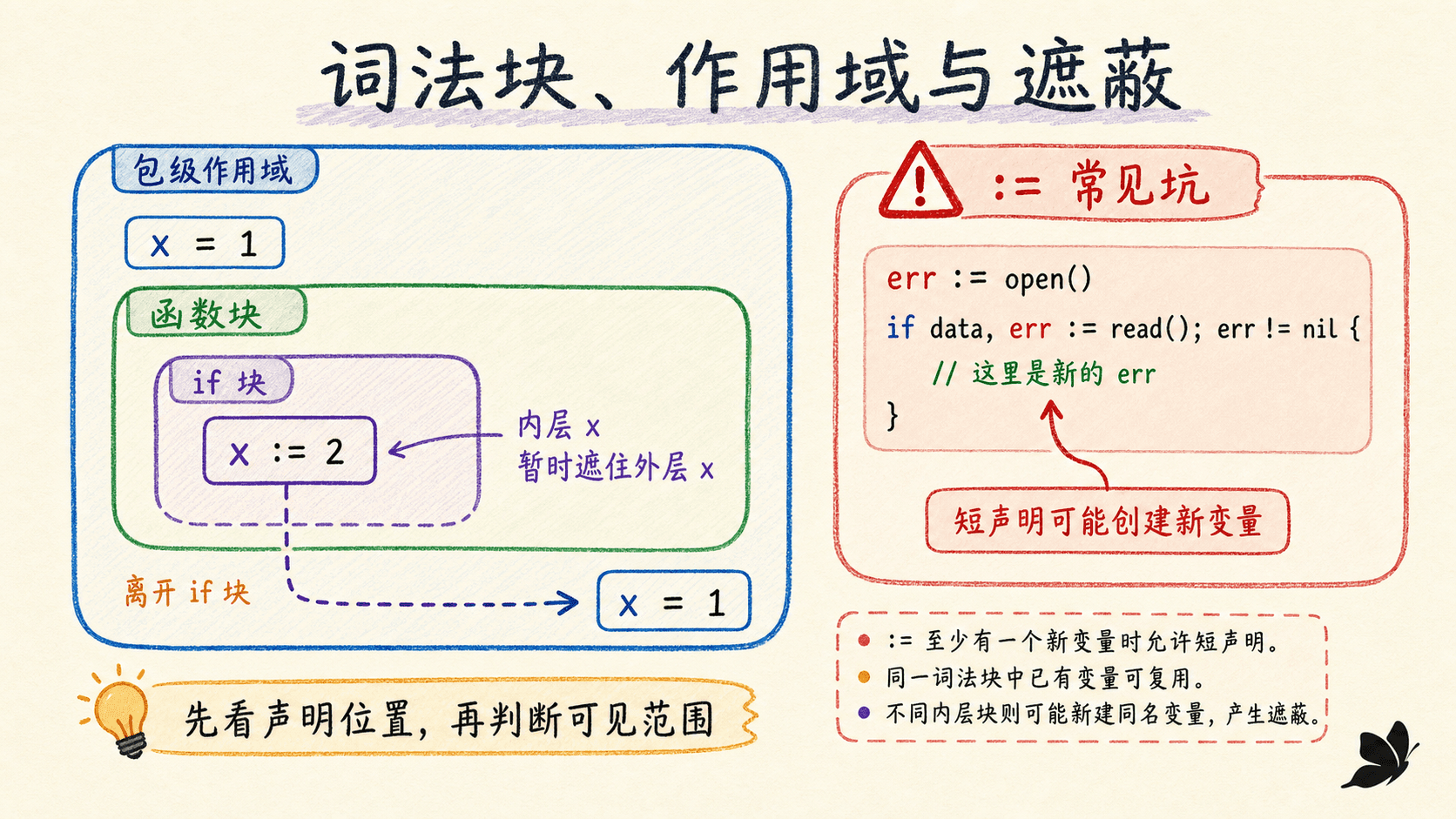
作用域是源代码文本中的区域,是编译期概念;生命周期是变量实例在运行时保持存在的时间。一个变量可能已经离开声明点所在函数的执行过程,却因为仍被指针引用而继续存活。反过来,一个名字仍在文本作用域内,也不意味着程序当前一定执行到了那一行。
Go 使用词法作用域。显式大括号形成块,语言还定义了一组隐式块:整个源代码的预声明块、每个包、每个文件、每个 if、for、switch,以及 switch 或 select 的每个分支都有自己的块。
从最内层向外查找
编译器解析一个名字时,从当前位置最内层的块向外查找,找到第一条匹配声明就停止。内层声明与外层同名时,外层名字在内层作用域中被遮蔽。
go
var status = "包级"
func main() {
status := "函数级"
fmt.Println(status) // 函数级
if ready := true; ready {
status := "if 块"
fmt.Println(status) // if 块
}
fmt.Println(status) // 函数级
}局部变量的作用域从声明结束处开始,到包含它的最内层块结束。正因为作用域从声明之后才开始,x := x + 1 右侧的 x 可以引用外层名字,左侧则引入当前块的新名字。
导入的包名属于文件块;包级常量、类型、变量和函数属于包块;标签的规则又不同,它的作用域是包含它的函数体。多数日常错误集中在函数内的显式块和 if、for 的隐式块。
13A
内层块和外层块都声明了 status,内层代码读取 status 时会使用哪一个?
if 初始化语句适合限制临时值
go
if value, ok := cache[key]; ok {
fmt.Println("命中:", value)
}
// value 和 ok 在这里不可见这正适合只为条件判断服务的临时值。但如果成功路径还要继续使用文件句柄,就不该把它关在 if 的作用域里:
go
file, err := os.Open(name)
if err != nil {
return err
}
defer file.Close()
// 后续成功路径继续使用 file
return process(file)先处理错误并尽早返回,可以让成功路径保持在较浅的缩进层级,也让 file 的作用域覆盖真正需要它的代码。
13B
在 if value, ok := cache[key]; ok { ... } 中,value 和 ok 在对应的 else 分支也可见。
最危险的遮蔽通常来自 :=
go
var workingDir string
func init() {
var err error
workingDir, err = os.Getwd()
if err != nil {
log.Fatal(err)
}
}这里特意先声明 err,再用 = 更新包级 workingDir。如果写成下面这样:
go
func init() {
workingDir, err := os.Getwd()
if err != nil {
log.Fatal(err)
}
log.Println(workingDir)
}函数块里原本没有 workingDir 和 err,所以 := 会新建两个局部变量。日志看起来正常,包级 workingDir 却仍是空字符串。编译器只能在局部变量完全没被使用时帮助发现问题;一旦日志使用了局部变量,代码就可能通过编译。
13
包级已有 var cwd string,在 init 中执行 cwd, err := os.Getwd() 会怎样?
14
作用域是编译期的源代码区域;变量实例在运行时存在的时间称为 ____。
把结构规则用在真实代码里
到这里,我们可以用一套稳定顺序阅读陌生代码:先找声明,再画出块;遇到同名标识符,从最内层向外定位;看到 :=,检查当前块是否至少有一个新名字;看到多重赋值,先保存右侧旧值;看到包级初始化,先沿依赖关系排序。
这比记零散结论更有效。程序越大,名字、作用域和依赖越需要清楚表达。好的结构不是让代码显得“高级”,而是让编译器和读者对同一个名字得到同一个答案。
综合判断
15
下面哪些代码会建立新变量?
16
希望阻止 Meter 与 Second 被意外相加,最合适的声明是什么?
17
表达式 x, x = 1, 2 最终会让 x 等于 2。
18
接收函数的第二个返回值但忽略第一个,可以在左侧使用特殊标识符 ____。
代码推演
不运行程序,写出下面代码的输出,并说明每一行的 n 来自哪个块。
go
package main
import "fmt"
var n = 1
func main() {
n := n + 1
fmt.Println(n)
if n := n * 10; n > 0 {
fmt.Println(n)
}
fmt.Println(n)
}动手改错
下面函数希望把当前工作目录写入包级变量,却没有达到目的。请给出最小修改。
go
var cwd string
func loadWorkingDir() error {
cwd, err := os.Getwd()
if err != nil {
return err
}
fmt.Println("当前目录:", cwd)
return nil
}19
审查一条短变量声明时,最先应该确认什么?