用 StatefulSet、PVC 与 Job 保存任务
上一章结束时,TaskBoard 的 API 已经有两个可替换副本,可以滚动发布,也能根据 CPU 负载扩缩容。此时 Deployment、Service、ConfigMap、Secret、探针和 HPA 都处于可用状态,taskboard Namespace 中还保留着用于集群内请求的 toolbox-safe。这些是本章的前置状态。
但任务数据还没有可靠的归宿。现在即使 API 返回正常,也只能说明计算部分可用。只要把进程内存、容器可写层或某个 Pod 的临时目录当成数据库,Pod 重建就可能让任务消失。这个问题不能通过“多开几个 Deployment 副本”解决,因为多个副本之间没有天然共享的持久状态。
本章要把 TaskBoard 从“能处理请求”推进到“能在 Redis Pod 被替换后继续读到任务”。我们会先弄清容器可写层为什么短暂,再把 Volume、PV、PVC、StorageClass 和 CSI 放回各自的职责位置。随后部署一个由 StatefulSet 管理的 Redis,通过 PVC 保存 AOF 文件,用 Job 初始化数据,并让 TaskBoard 的 readiness 真正检查 Redis。最后主动删除 redis-0,比较 Pod UID、卷绑定和业务数据三个证据。
完成后,项目应处于下面的状态:
redis-0由 StatefulSet 维持,且为1/1 Running;data-redis-0PVC 为Bound,容量为256Mi;taskboard-initJob 为Complete 1/1;- TaskBoard 的
/api/tasks能返回 Job 写入的任务; - 删除并重建 Redis Pod 后,Pod UID 改变,但 PVC 绑定和任务内容不变。
这些目标刻意分成控制器、存储和业务三层。只看 Running 无法证明数据还在,只看 Bound 也无法证明应用真的能读到数据。
先恢复这一章的课程会话
存储实验会创建 PVC 并写入数据,比无状态对象更需要先锁定操作边界。新终端不会继承 PATH、KUBECONFIG 或工作目录;如果这些值缺失,后面的相对清单可能找不到,甚至可能查询错误的集群。
下面只恢复当前 Shell、读取课程 context 并进入项目目录,不会创建卷或改动数据。先理解检查目标,再执行:
bash
COURSE_ROOT="$HOME/welearn-kubernetes-course"
if ! { [ -d "$COURSE_ROOT" ] && \
printf 'welearn-kubernetes-course\n' | cmp -s - "$COURSE_ROOT/.course-owned"; }; then
echo '停止:课程目录不存在或归属标记不匹配' >&2
exit 1
fi
case ":$PATH:" in
*":$COURSE_ROOT/bin:"*) ;;
*) export PATH="$COURSE_ROOT/bin:$PATH" ;;
esac
export KUBECONFIG="$COURSE_ROOT/welearn-course.kubeconfig"
COURSE_CONTEXT="$(kubectl config current-context 2>/dev/null)" || { echo '停止:无法读取课程 context' >&2; exit 1; }
if [ "$COURSE_CONTEXT" != 'kind-welearn-course' ]; then
echo "停止:当前 context 不是 kind-welearn-course,而是 $COURSE_CONTEXT" >&2
exit 1
fi
CLUSTER_NAME='welearn-course'
NODE_NAME='welearn-course-control-plane'
CLUSTER_LABEL='io.x-k8s.kind.cluster=welearn-course'
CLUSTER_MARKER="$COURSE_ROOT/.kind-cluster-owned"
KIND_CLUSTERS="$(kind get clusters 2>&1)" || { echo '停止:无法读取 kind 集群列表' >&2; exit 1; }
printf '%s\n' "$KIND_CLUSTERS" | grep --fixed-strings --line-regexp --quiet "$CLUSTER_NAME" || { echo '停止:课程 kind 集群不存在' >&2; exit 1; }
LABEL_IDS="$(docker ps -aq --no-trunc --filter "label=$CLUSTER_LABEL" 2>&1)" || { echo '停止:无法按 kind 标签读取节点容器' >&2; exit 1; }
NAME_IDS="$(docker ps -aq --no-trunc --filter "name=$NODE_NAME" 2>&1)" || { echo '停止:无法按名称读取节点容器' >&2; exit 1; }
LABEL_COUNT="$(printf '%s\n' "$LABEL_IDS" | awk 'NF { count += 1 } END { print count + 0 }')"
NAME_COUNT="$(printf '%s\n' "$NAME_IDS" | awk 'NF { count += 1 } END { print count + 0 }')"
if [ "$LABEL_COUNT" -ne 1 ] || [ "$NAME_COUNT" -ne 1 ] || [ "$LABEL_IDS" != "$NAME_IDS" ]; then
echo '停止:课程节点容器的名称、标签或数量不一致' >&2
exit 1
fi
COURSE_NODE_ID="$LABEL_IDS"
case "$COURSE_NODE_ID" in
*[!0-9a-f]*|'') echo '停止:课程节点容器 ID 格式无效' >&2; exit 1 ;;
esac
[ "${#COURSE_NODE_ID}" -eq 64 ] || { echo '停止:课程节点容器 ID 不是完整 64 位' >&2; exit 1; }
printf 'cluster=%s\nnode=%s\nnode_id=%s\nlabel=%s\n' "$CLUSTER_NAME" "$NODE_NAME" "$COURSE_NODE_ID" "$CLUSTER_LABEL" | \
cmp -s - "$CLUSTER_MARKER" || { echo '停止:当前节点与集群归属账本不匹配' >&2; exit 1; }
NODE_FACTS="$(docker inspect --format '{{.Id}}|{{.Name}}|{{index .Config.Labels "io.x-k8s.kind.cluster"}}' "$COURSE_NODE_ID" 2>&1)" || { echo '停止:无法检查课程节点身份' >&2; exit 1; }
[ "$NODE_FACTS" = "$COURSE_NODE_ID|/$NODE_NAME|$CLUSTER_NAME" ] || { echo '停止:课程节点不可变身份校验失败' >&2; exit 1; }
cd "$COURSE_ROOT/taskboard" || { echo '停止:TaskBoard 项目目录不存在' >&2; exit 1; }
printf 'context=%s\nproject=%s\n' "$COURSE_CONTEXT" "$(pwd -P)"
printf 'cluster_identity=verified node_id_prefix=%.12s\n' "$COURSE_NODE_ID"结果展示
text
context=kind-welearn-course
project=<用户目录>/welearn-kubernetes-course/taskboard
cluster_identity=verified node_id_prefix=<动态 12 位>三行都满足才继续。若失败,保留现状并回到第 2–3 章恢复连接、集群身份或项目文件,不要为了让 PVC 命令运行而临时切换到来源不明的 context,也不要伪造四行归属账本。
状态为什么不能留在容器里
我们先从一个容易误会的地方讲起:容器镜像看起来像一个完整文件系统,容器也确实可以在很多目录中写文件,为什么这些文件不能直接当作持久数据?
镜像层是只读模板。容器启动时,容器运行时会在只读镜像层上面叠加一个可写层。进程看到的是合并后的文件系统,所以写入动作看起来与普通目录没有区别;实际变化却落在这个具体容器的可写层里。容器被替换时,新容器会从同一镜像重新得到一层干净的可写层,不会继承旧容器那一层的修改。
Pod 还把这个问题放大了一层。Kubernetes 管理的是期望状态,不承诺保留某个具体容器或 Pod。镜像更新、探针触发重启、节点维护、驱逐和控制器自愈,都可能让旧实例消失。我们在前面已经利用这种可替换性获得了自愈和滚动发布;到了数据层,同一种可替换性就要求我们把状态从计算实例中拆出去。
这里要区分三个生命周期:
emptyDir 的名字容易让人误会。它在 Pod 创建时开始为空,容器重启不会删除它;但 Pod 被删除后,emptyDir 也随之消失。因此第 10 章会继续使用 emptyDir 给只读根文件系统提供 /tmp,本章却不能用它保存 Redis AOF。
持久化不是“找一个不会被删除的目录”这么简单。真正的问题包括卷由谁创建、Pod 调度到哪台节点后如何挂载、谁有权申请多大容量、卷删除时数据是否保留,以及故障后如何恢复。Kubernetes 存储 API 的价值,是把这些责任拆成可以独立管理的对象。
Kubernetes 官方的 Volume 文档把容器文件描述为临时数据,并用 Volume 抽象解决持久化与多容器共享问题;PV 文档进一步明确,计算实例管理与存储管理是不同的问题。接下来出现的每个对象,都是在回答其中一类责任,而不是同一个概念的不同名字。
从容器目录到持久卷
为什么要分出 PV 与 PVC
早期管理服务器时,应用团队常常直接拿到一块磁盘路径:运维人员先挂载磁盘,再把目录写进部署脚本。这种方式在机器数量少时还能工作,一旦应用会在节点间调度,路径就同时泄露了基础设施细节和节点位置。开发者需要知道“我需要 256Mi、可读写的持久空间”,却不应该被迫知道某块云盘 ID、NFS 地址或节点目录;集群管理员则需要控制可提供的存储类型、回收策略和成本。
Kubernetes 因而把“存储资源”和“对存储的请求”分成两个 API 对象:
- PersistentVolume,简称 PV,是集群范围的存储资源。它描述容量、访问模式、回收策略和实际卷实现,生命周期独立于使用它的某个 Pod。
- PersistentVolumeClaim,简称 PVC,是 Namespace 内的存储申请。工作负载说明容量、访问模式和 StorageClass,控制面再寻找或供应一个合适的 PV 与它绑定。
你可以把 PVC 理解成一张需求单,但准确机制不是“PVC 里装着数据”。数据位于 PV 所代表的后端介质中;PVC 保存的是一次排他绑定关系,Pod 再通过 persistentVolumeClaim 引用这份关系。把 PVC 删除,并不等同于立刻擦除物理数据,最终行为还取决于 PV 的 persistentVolumeReclaimPolicy。
最早的做法是管理员预先创建一批 PV,PVC 到来后由控制面匹配,这叫静态供应。问题是管理员必须提前猜容量与类型,容易出现“有 100Gi 卷,却没有申请所需的 20Gi 类型”之类的库存错配。StorageClass 引入动态供应后,PVC 可以触发供应器按需创建 PV。StorageClass 因此不是一块卷,而是一套供应参数:由哪个 provisioner 创建、使用什么参数、采用哪种回收策略、何时绑定。
CSI 解决的是驱动发布问题
存储还涉及另一个历史包袱。早期 Kubernetes 的许多存储插件代码直接放在 Kubernetes 主仓库和核心二进制里,称为 in-tree 插件。厂商支持一种新存储或修复驱动,就要跟随 Kubernetes 自身的代码审查和发布节奏。核心项目也不得不长期维护大量供应商实现。
Container Storage Interface,简称 CSI,是容器编排系统与存储驱动之间的标准接口。Kubernetes 在 v1.9 引入 CSI alpha 支持,v1.10 进入 beta,v1.13 达到 GA。驱动可以在核心代码之外发布,Kubernetes 通过控制器侧组件和节点侧组件调用标准接口完成创建、附加、挂载和卸载。CSI 解决的是“如何让不同存储实现接入编排系统”,并不取代 PV、PVC 和 StorageClass 这些面向使用者的 API。
把职责放在一条请求链里,会更清楚:
- Pod 模板引用 PVC,表达“这个工作负载要用哪份申请”。
- PVC 表达容量、访问模式与存储类别。
- StorageClass 指定供应器和供应策略。
- 外部 provisioner 根据 PVC 创建后端卷与 PV。
- PV 记录后端卷如何被集群使用,并与 PVC 绑定。
- 调度器选择节点后,CSI 相关组件让卷在该节点可用,kubelet 再把它挂到容器目录。
本课程的 rancher.io/local-path 是轻量供应器,不是通用 CSI 高可用存储。我们仍然使用同一套 PVC、PV 和 StorageClass API,因此可以学到对象关系;但它最终把数据放在某个节点相关的路径中,无法展示多可用区云盘的附加、故障转移和快照能力。
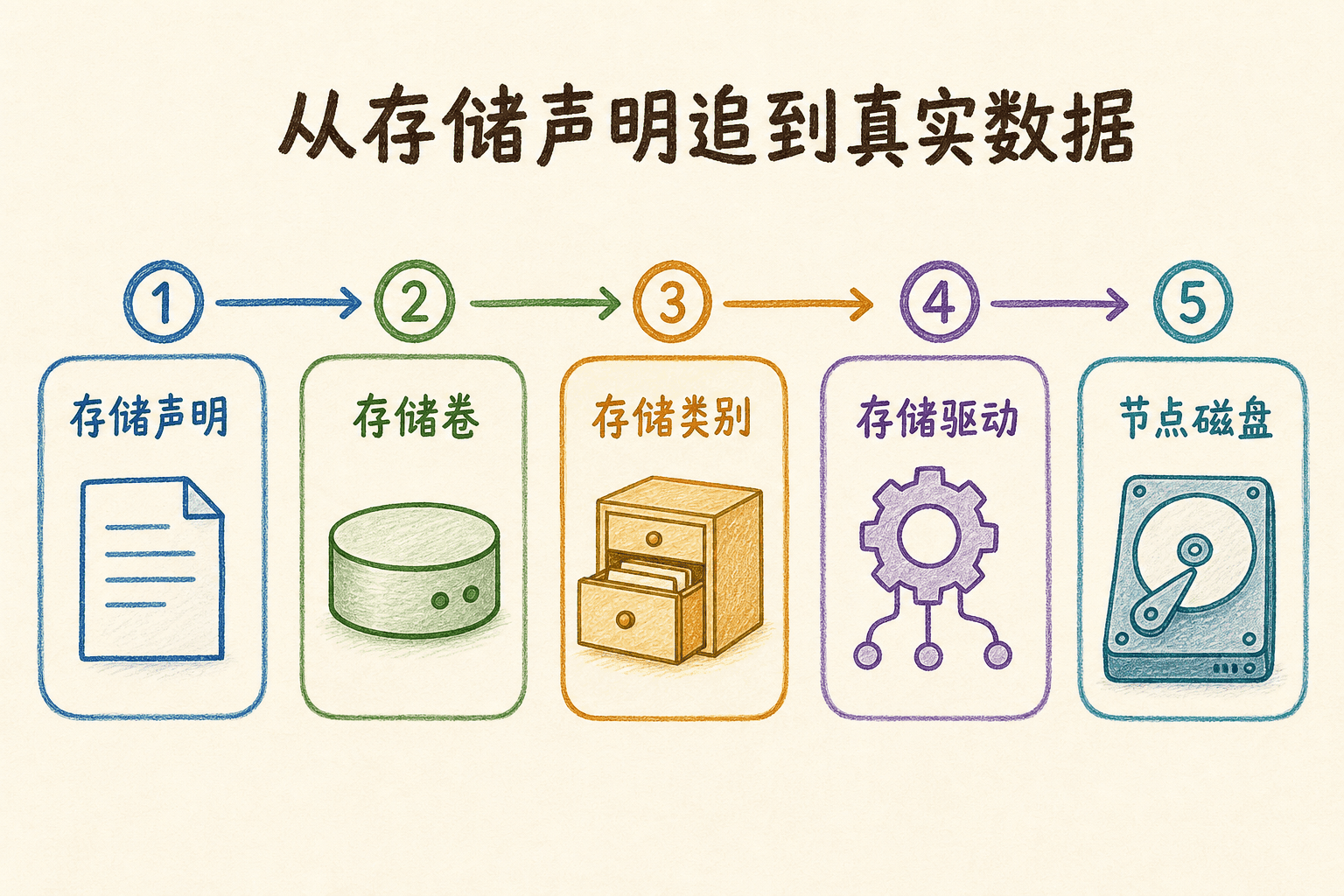
Kubernetes 存储常见对象之间的关系是:
text
StorageClass
定义如何供应存储
↓
PersistentVolumeClaim(PVC)
工作负载提出容量和访问模式要求
↓
PersistentVolume(PV)
集群中实际供应出的卷
↓
Pod volume
把 PVC 挂载到容器目录在这个隔离练习集群中,默认 StorageClass 使用 rancher.io/local-path 动态供应卷。PVC 创建后,供应器会生成一个 PV,再把两者绑定。Redis 只需要引用 PVC,不必知道底层目录在哪里。
执行前先确定要读什么
这一步只读取集群提供的存储类别,不会创建或修改资源。kubectl get storageclass 没有加名称,是因为我们还要确认哪一个带有 (default) 标记;没有默认 StorageClass 时,后面未写 storageClassName 的 PVC 可能一直保持 Pending。输出中的 PROVISIONER 告诉我们谁负责供应,RECLAIMPOLICY 告诉我们释放申请后的默认回收行为,VOLUMEBINDINGMODE 则告诉我们何时选定或创建卷。
理解这三个字段后再执行读取:
bash
kubectl get storageclass结果展示
text
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
standard (default) rancher.io/local-path Delete WaitForFirstConsumer false <动态时间>时间是动态值。WaitForFirstConsumer 表示供应器会等到使用 PVC 的 Pod 参与调度后,再结合节点选择创建卷。Delete 表示 PVC 删除后,相应动态 PV 通常也会被回收。
为什么要等第一个消费者?某些卷受到拓扑限制,例如只能在特定可用区或节点使用。如果 PVC 一创建就随意供应,后来 Pod 被调度到另一个区域,卷可能无法挂载。WaitForFirstConsumer 让调度约束与供应决策一起发生。这里的单节点集群看不出跨区差异,但字段语义相同。
如果输出没有 (default),下一条证据应是 kubectl get storageclass -o yaml,检查默认类注解;如果 PROVISIONER 与这里不同,不要把结果强行改成课程值,应查阅该供应器的参数与拓扑行为。若看到多个默认类,则需要先由集群管理员消除歧义,或者在 PVC 中明确写 storageClassName。
local-path 卷依附于某个节点,它适合课程和开发集群,不提供跨节点复制。看到 PVC 为 Bound 只能证明卷已经绑定,不能把它理解成生产级高可用存储。
访问模式不是并发写入保证
后面的 PVC 使用 ReadWriteOnce,命令行会缩写为 RWO。它表示卷可以由一个节点以读写方式挂载,并不自动限制为一个 Pod;同一节点上的多个 Pod 是否能同时使用,还取决于卷类型和应用协调。它也不证明文件系统支持安全的多进程并发写入。
如果业务严格要求整个集群同一时刻只能有一个 Pod 读写某卷,应评估 ReadWriteOncePod 与相应 CSI 支持。如果业务需要多节点共享,则要寻找支持 ReadWriteMany 的存储。访问模式是调度和挂载约束,不是数据库一致性协议,不能替代 Redis、数据库或文件系统自身的主从、锁和事务机制。
为什么 Redis 使用 StatefulSet
Deployment 的设计前提是副本可互换:控制器只要维持指定数量的 Ready Pod,具体由哪个 Pod 承担请求并不重要。这个模型非常适合 TaskBoard API,却无法表达数据库副本常见的约束,例如“0 号是固定成员”“这个成员必须继续使用自己的数据目录”“节点间需要稳定名字完成发现”。
StatefulSet 最初以 PetSet 的名字进入 Kubernetes,后来更名并逐步稳定。旧名称中的“宠物”比喻强调单个实例有名字、身份和照料方式;现在官方更准确地把它定义为管理有状态应用的工作负载 API。它与 Deployment 一样通过控制循环创建 Pod,但额外维持以下语义:
- 稳定序号:副本名称由 StatefulSet 名称和序号组成,
redis的第一个副本是redis-0。 - 稳定网络身份:配合 Headless Service,Pod 可以得到与序号关联的 DNS 名称。
- 稳定存储关联:
volumeClaimTemplates为每个序号生成独立 PVC,重建同一序号时继续引用同名 PVC。 - 有序操作:默认
OrderedReady策略按序创建和删除 Pod;扩容下一个序号前,会等待前一个 Ready。
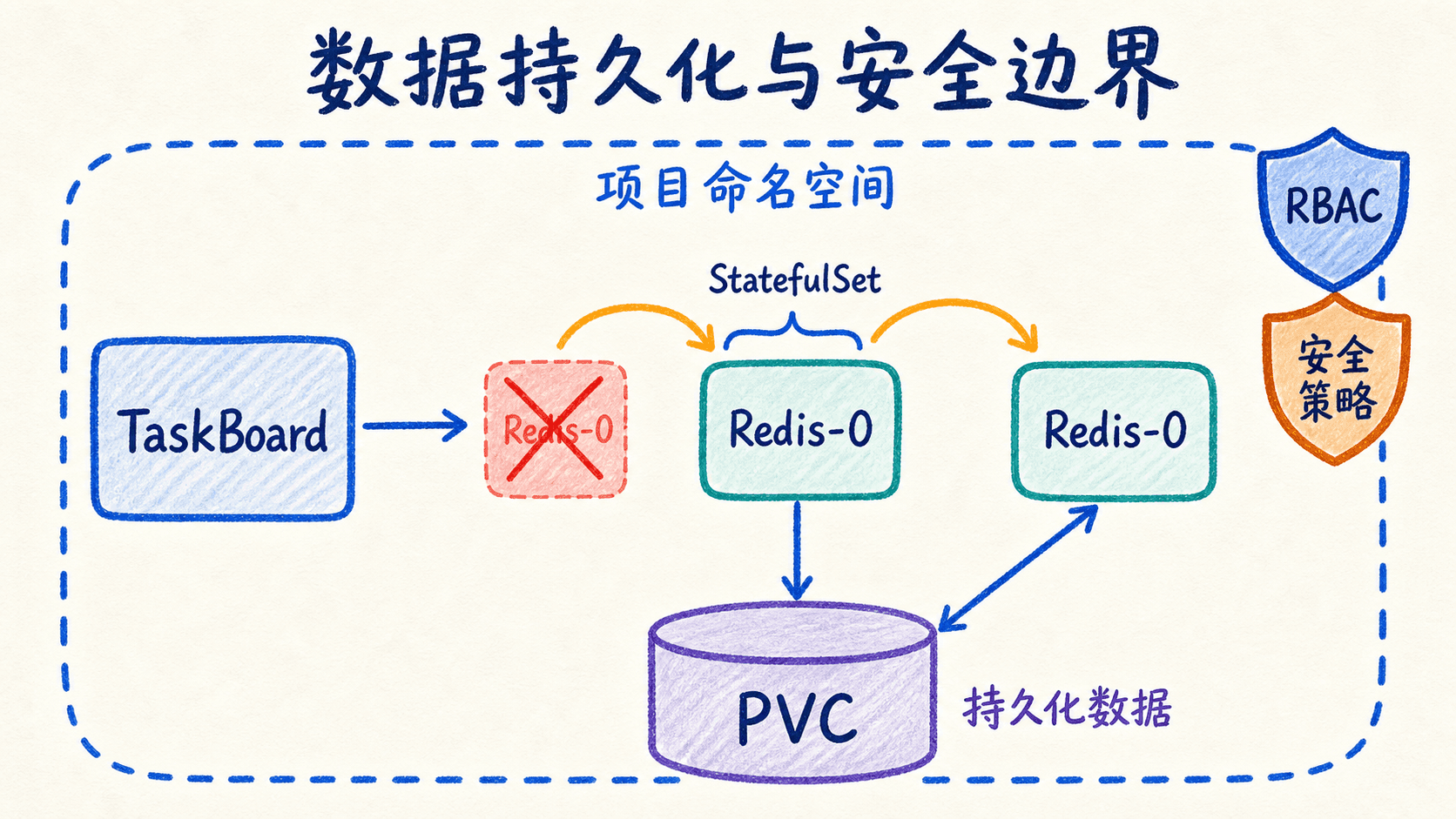
这里的“稳定”不表示 Pod 对象永远不变。Pod UID 才是对象实例的唯一身份,删除后 UID 一定变化;稳定的是可供应用识别的序号和与该序号关联的资源名称。这个区别正是本章最后要验证的内容。
Deployment 创建的 Pod 名称和存储通常都可以替换。StatefulSet 则为每个副本提供稳定序号,例如 redis-0,并通过 volumeClaimTemplates 为这个序号创建稳定 PVC。
我们只运行一个 Redis 副本。StatefulSet 保证的是对象身份和有序管理,不会自动把单个 Redis 变成高可用数据库。这里使用它,是为了观察 Pod 重建时 PVC 如何继续绑定到 redis-0。
Redis 前面还需要一个 Headless Service:
clusterIP: None表示不分配普通虚拟 IP。- DNS 会直接返回后端 Pod 地址。
- StatefulSet 通过
serviceName: redis关联这个 Service。 redis-0会得到稳定域名redis-0.redis.taskboard.svc.cluster.local。
TaskBoard 配置中的 REDIS_HOST=redis 使用较短的 Service 名称即可连接当前 Redis 端点。
Headless Service 仍然是 Service API 对象,但 clusterIP: None 让它不提供一个由服务代理负载均衡的虚拟 IP。DNS 可以根据后端端点返回 Pod 地址,并为 StatefulSet 成员形成稳定记录。spec.serviceName: redis 不是随意的备注,它把 StatefulSet 的网络身份域与这个 Headless Service 关联起来。
本课程只有一个 Redis 副本,所以 TaskBoard 使用 redis 就足够。若运行需要成员身份的复制集,应用通常会使用 redis-0.redis.taskboard.svc.cluster.local 这一类完整名字发现特定成员。但 StatefulSet 只提供身份和顺序,不理解 Redis 的复制、选主、脑裂、故障转移或数据一致性。把 replicas 从 1 改成 3,只会得到三个分别有卷的 Redis 进程,不会自动组成正确集群。
StatefulSet 是编排原语,不是数据库高可用产品。生产环境更常见的选择是托管数据库、经过验证的 Operator,或由数据库团队维护的复制拓扑。无论选择哪一种,都还需要备份、恢复演练、容量规划和故障域设计。
创建 Redis Headless Service 与 StatefulSet
知识点与预期变化
Redis 从 taskboard-secret 读取口令,把 /data 挂载到名为 data-redis-0 的 PVC,并使用 AOF 记录写操作。Pod 和容器安全上下文显式设置非 root 用户、默认 seccomp 配置,并移除 Linux capabilities。
提交后会发生一条控制器链:API Server 保存 Service 与 StatefulSet;StatefulSet 控制器创建 redis-0 和由模板生成的 data-redis-0 PVC;动态供应器创建 PV 并完成绑定;调度器为 Pod 选择节点;kubelet 准备卷、拉取镜像并启动 Redis;探针通过后,Pod 才变成 Ready。kubectl apply 返回 created 只证明前两个对象被接受,不代表这条链已经走完,所以后面必须分别等待和读取状态。
先读下面清单时,重点跟住这些字段:
- Service 的
clusterIP: None创建 Headless Service,selector: app: redis把它与 Redis Pod 关联。 - StatefulSet 的
serviceName: redis指定稳定网络身份所依赖的 Service;selector.matchLabels必须与 Pod 模板标签一致。 command和args用 shell 展开REDIS_PASSWORD,最后用exec让 Redis 进程成为容器主进程,便于正确接收终止信号。服务端的--requirepass最终会进入 Redis 进程参数,这种启动方式存在同一容器进程命令行可见边界;课程不打印该命令行,也不把它当作理想的密钥分发方案。--appendonly yes开启 AOF,--appendfsync everysec在性能和最多约一秒写入窗口之间取舍;它不是“零数据丢失”承诺。secretKeyRef只把指定键注入 Redis 容器;YAML 中没有写入口令值。automountServiceAccountToken: false明确禁止挂载默认 API token。Redis 只连接自己的 Service 与数据卷,不调用 Kubernetes API,不应持有无关凭据。- readiness 表示“现在能否接收连接”,liveness 表示“进程是否陷入需要重启的故障”。二者都执行带口令的
PING,但客户端通过REDISCLI_AUTH读取口令,不把-a <口令>放进redis-cli参数列表。 volumeMounts.name: data对应volumeClaimTemplates.metadata.name: data。控制器把模板名、StatefulSet 名和序号组合为data-redis-0。resources.requests供调度器计算最低资源需求,limits给运行时约束上限;这些数值只适合这个小型练习负载。
我们没有显式写 storageClassName,因此 PVC 使用前面确认的默认 standard。也没有设置 persistentVolumeClaimRetentionPolicy;PVC 不会因为普通的 Pod 重建而删除,StatefulSet 缩容或删除时也应把数据安全放在自动清理之前。最终章节会通过删除整个 Namespace,再结合 StorageClass 的 Delete 回收策略完成有边界的清理。
在项目工作目录创建 k8s/redis.yaml:
yaml
apiVersion: v1
kind: Service
metadata:
name: redis
namespace: taskboard
spec:
clusterIP: None
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: redis
---
apiVersion:
fsGroup: 999 让挂载卷对 Redis 进程组可写。ReadWriteOnce 表示同一时刻以读写方式挂载到一个节点,不等于“只能被一个 Pod 使用”,也不等于“数据已经复制到多个节点”。
REDISCLI_AUTH 只是减少口令出现在 redis-cli -a ... 命令行和部分进程查看工具中的机会,不会让口令脱离容器环境。能读取 Pod 规格、进入容器、读取 Secret 或访问节点进程环境的高权限主体仍可能得到它。真正的边界仍包括 RBAC、禁用无关 token、限制 exec、etcd 静态加密、日志纪律和凭据轮换。Redis 服务端这里仍通过 --requirepass 接收口令;更严格的部署应使用经过验证的配置文件投影、Redis ACL 或外部密钥集成,并检查所用镜像的实际启动方式。
这里设置 runAsUser: 999 是因为所选 Redis 镜像中的 Redis 用户使用这个 UID。换镜像前应检查镜像实际用户,不能机械复制;如果 UID 与镜像不匹配,容器可能无法读取配置或写 /data。fsGroup 可能触发 kubelet 调整卷中文件组所有权,大卷上会延长挂载时间,生产环境应结合 CSI 驱动支持和 fsGroupChangePolicy 评估。
实操
提交清单后等待 StatefulSet 完成,再同时查看 StatefulSet、Pod 和 PVC。rollout status 读取控制器的滚动状态,并在 120 秒后停止等待;它不会替我们验证数据。三条 get 分别回答“控制器有几个 Ready 副本”“具体实例是否运行”“存储申请是否绑定”。这样可以把控制器状态、运行实例和存储绑定放在一起核对:
bash
kubectl apply -n taskboard -f k8s/redis.yaml
kubectl rollout status statefulset/redis -n taskboard --timeout=120s
kubectl get statefulset redis -n taskboard
kubectl get pod redis-0 -n taskboard
kubectl get pvc data-redis-0 -n taskboard结果展示
text
service/redis created
statefulset.apps/redis created
NAME READY AGE
redis 1/1 <动态时间>
NAME READY STATUS RESTARTS AGE
redis-0 1/1 Running 0 <动态时间>
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-redis-0 Bound <动态 PV 名称> 256Mi RWO standard <动态时间>PV 名称、UID 和时间会变化。稳定字段是 PVC 名 data-redis-0、状态 Bound、容量 256Mi 和访问模式 RWO。Redis Pod 已经通过口令验证探针并进入 1/1 Running。
逐行理解这份结果:statefulset redis 1/1 表示期望的一个副本已经 Ready;redis-0 1/1 Running 中,第一个 1 是 Ready 容器数,第二个 1 是容器总数;PVC 的 Bound 表示控制面已经把申请与一个 PV 建立一对一绑定。它们共同证明运行链路成立,但还没有证明 AOF 能恢复业务任务。
如果 StatefulSet 等待超时,不要立即删除重建。先执行 kubectl describe pod redis-0 -n taskboard 看事件:FailedScheduling 常指向资源或 PVC,FailedMount 指向卷准备,ErrImagePull 指向镜像,readiness 失败则要继续看 kubectl logs redis-0 -n taskboard。如果 PVC 为 Pending,下一条命令应是 kubectl describe pvc data-redis-0 -n taskboard,再对照 kubectl get storageclass;这比反复 apply 更接近根因。
从 PVC 追到实际 PV
PVC 表格只给出绑定后的 PV 名,还没有展示这块卷究竟绑定给谁、使用哪种回收策略以及被限制在哪个节点。下一组命令先从 namespaced PVC 的 .spec.volumeName 取出集群范围 PV 名,并断言它非空;再从 PV 读取 claimRef、storageClassName、persistentVolumeReclaimPolicy 和 nodeAffinity。这一步只读对象,不挂载、删除或修改存储。
JSONPath 中的 claimRef.namespace/name 应精确回指 taskboard/data-redis-0;nodeAffinity 的键、操作符和值解释为什么 local-path 卷只能与特定节点组合。先确认 PVC 已是 Bound,再执行:
bash
PV_NAME="$(kubectl get pvc data-redis-0 -n taskboard \
-o jsonpath='{.spec.volumeName}')"
if [ -z "$PV_NAME" ]; then
echo '停止:PVC 尚未绑定 PV' >&2
exit 1
fi
kubectl get pv "$PV_NAME" -o jsonpath='claim={.spec.claimRef.namespace}/{.spec.claimRef.name}{"\n"}storageClass={.spec.storageClassName}{"\n"}reclaimPolicy={.spec.persistentVolumeReclaimPolicy}{"\n"}nodeAffinity={.spec.nodeAffinity.required.nodeSelectorTerms[0].matchExpressions[0].key}{" "}{.spec.nodeAffinity.required.nodeSelectorTerms[0].matchExpressions[0].operator}{" "}{.spec.nodeAffinity.required.nodeSelectorTerms[0].matchExpressions[0].values[0]}{"\n"}'结果展示
text
claim=taskboard/data-redis-0
storageClass=standard
reclaimPolicy=Delete
nodeAffinity=kubernetes.io/hostname In welearn-course-control-plane节点名来自当前单节点集群,其他执行中的值可能不同;稳定验收字段是 claim 回指正确、StorageClass 为 standard、回收策略为 Delete,并且 nodeAffinity 把卷限制到供应时选定的节点。若 claim 指向其他 PVC,应立即停止后续写入并检查绑定;若 nodeAffinity 为空,说明所用供应器没有以这种字段表达节点约束,不能伪造课程输出,应读取完整 PV YAML 和供应器文档。
Delete 回收策略不会在 Redis Pod 删除时触发,也不会因为 StatefulSet 创建替代 Pod 而触发。它讨论的是 PVC 被删除、PV 与声明解绑并进入 Released 之后,控制面和供应器如何处理 PV 及后端资产。动态供应的 local-path PV 可能很快从 Released 进入删除,未必能在一次人工查询中观察到中间状态。最终清理会在删除 PVC 所在 Namespace 前记录这个精确 PV 名,再按名称等待它变成 NotFound。
生产环境中的存储验收
课程验收只证明 Pod 替换后同一节点上的数据仍在。上线前还应把“持久”拆成可测试指标:
- 节点不可用后,卷能否在另一个节点重新附加,恢复时间多长;
- 删除 PVC 时使用
Delete还是Retain,谁负责处理遗留 PV; - 存储系统是否提供跨故障域复制,写入确认代表何种持久性;
- 快照是否应用一致,备份是否保存在独立故障域;
- 从备份恢复到新 Namespace 后,应用能否通过业务校验;
- 容量、IOPS、吞吐和 inode 耗尽时,告警与扩容路径是什么。
PVC Bound 只覆盖上述问题中的“已经匹配并可供挂载”。它不是备份成功、故障转移成功或数据正确的替代证据。
用 Job 写入一次性初始化数据
知识点与预期变化
Job 适合有明确完成条件的任务,例如数据迁移、初始化和离线处理。它与 Deployment 的区别在于:容器成功退出后,Job 的期望状态就是 Complete,不会为了保持常驻副本而再次启动。
这仍然是 Kubernetes 的控制循环,只是期望状态变了。Deployment 持续追求“始终有若干可用副本”,Job 控制器追求“累计得到指定数量的成功完成”。最简单的 Job 默认需要一次成功完成:控制器创建 Pod,容器以退出码 0 结束后,Pod 进入 Succeeded,Job 的成功计数达到目标并设置 Complete 条件。若 Pod 或节点在完成前失败,控制器可以创建替代 Pod。
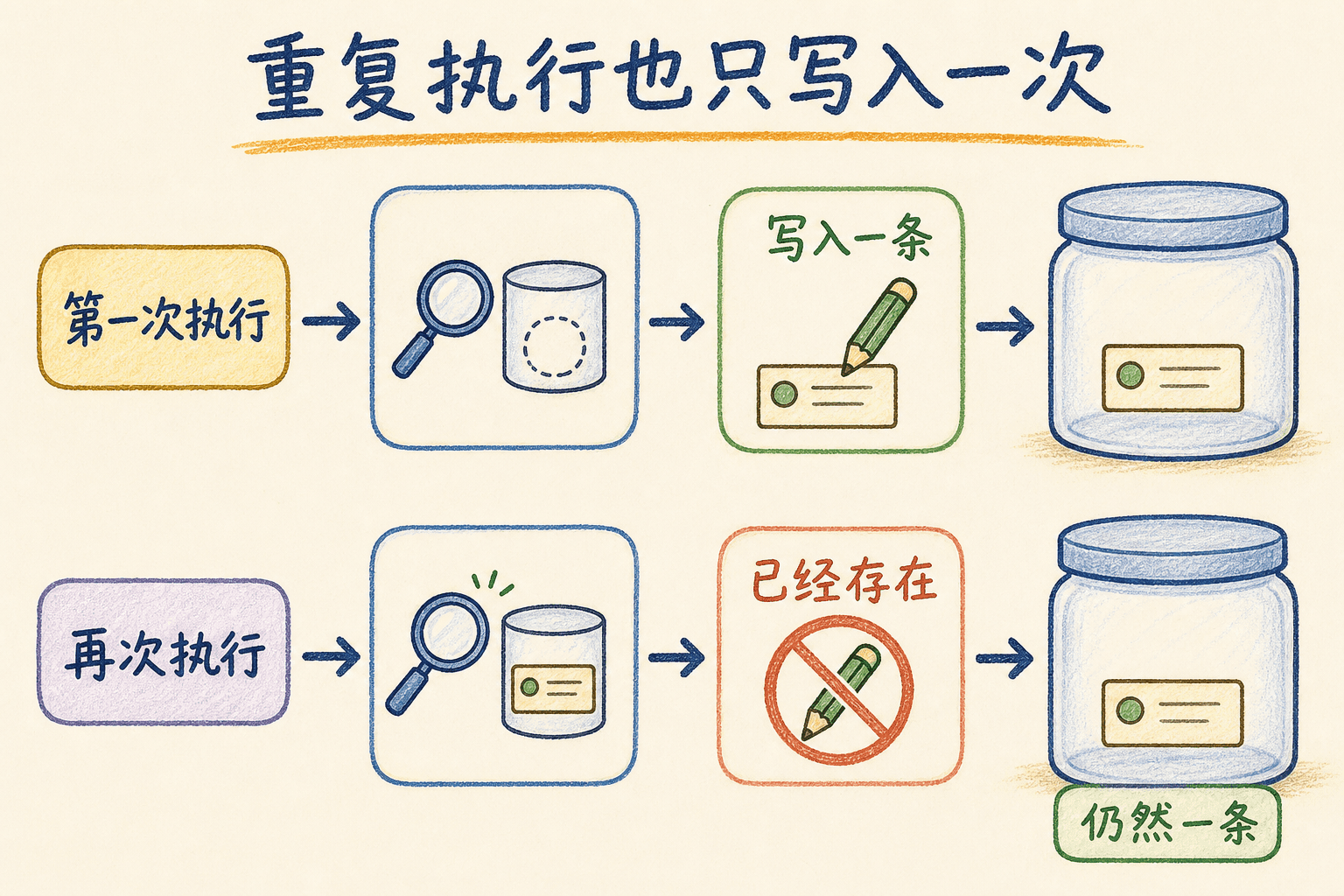
“最终成功一次”不等于程序只会被启动一次。官方 Job 文档明确提醒,即使 parallelism: 1、completions: 1 且 restartPolicy: Never,同一个程序在某些情况下仍可能启动两次。这来自分布式控制的现实:控制器可能在观察到完成状态前遇到通信或节点故障,需要优先保证任务最终完成。因此写入外部系统的 Job 必须容忍重试。
幂等的意思是:同一个逻辑操作执行一次和执行多次,最终可观察状态相同。数据迁移可以用版本表记录已经应用的版本;创建默认数据可以使用唯一键;转账类任务则需要业务幂等键和事务,不能只靠 Kubernetes 限制重试次数。
这次 Job 不再裸执行 LPUSH,而是让 Redis 在一个 Lua 脚本中完成“检查初始化版本标记、写入任务、写入完成标记”。Redis 执行 Lua 脚本时不会与其他命令交错,所以并发重试只会有一个调用看到标记不存在并写入;后来调用返回 already-initialized。版本键使用 taskboard:init:v1,任务列表仍为 taskboard:tasks。
这个设计还要处理失败语义。如果 Redis 无法解析、认证失败或命令执行失败,redis-cli 必须返回非零,Job 才会进入失败与重试路径。不能无论发生什么都 echo success。shell 使用 set -eu:-e 让未处理的非零命令终止脚本,-u 让未设置变量直接失败;只有 Lua 明确返回两个预期值之一时,容器才以 0 退出。
清单中的 restartPolicy: Never 属于 Pod 模板:容器失败后不在同一个 Pod 内重启,Job 控制器根据 Job 状态决定是否创建另一个 Pod。它便于保留每次失败实例和日志进行诊断。若没有写 backoffLimit,默认值是 6,失败 Pod 会按指数退避重试;生产迁移还常设置 activeDeadlineSeconds 防止无限等待,并用 podFailurePolicy 区分“值得重试的基础设施中断”和“应立即失败的业务退出码”。这些字段没有出现在本次真实清单中,因此本章不声称验证过它们。
初始化 Job 同样不调用 Kubernetes API,所以 Pod 模板也显式设置 automountServiceAccountToken: false。Job 需要 Redis 口令,不代表它还需要集群 API 凭据;两类凭据解决不同问题,不能因为都在容器里使用就默认一起挂载。
在项目工作目录创建 k8s/init-job.yaml:
yaml
apiVersion: batch/v1
kind: Job
metadata:
name: taskboard-init
namespace: taskboard
spec:
template:
metadata:
labels:
app: taskboard-init
spec:
restartPolicy: Never
automountServiceAccountToken: false
securityContext:
runAsNonRoot: true
这里不设置 ttlSecondsAfterFinished,让已完成的 Job 保留到结课验收,便于再次确认 Complete 条件。最后删除 taskboard Namespace 时,Job 和它的 Pod 会一起被回收。对长期集群,可以根据审计保留期再设置 TTL。
执行前再核对关键路径:redis-cli -h redis 通过 Service DNS 找 Redis,不依赖 redis-0 的当前 Pod IP;REDISCLI_AUTH 从 Secret 注入口令,避免把口令写在客户端参数中;--raw 让 Lua 返回值保持为纯文本。EVAL 后的数字 2 表示随后两个参数是 KEYS[1] 与 KEYS[2],最后一个 JSON 才是 ARGV[1]。Redis 连接或认证失败时,命令替换的退出状态会让 set -e 终止容器。
Lua 脚本的原子执行不等于所有脚本天然事务回滚:若脚本在已经写入后发生运行时错误,Redis 不会自动撤销此前写操作。这里先执行可能因数据类型不符而失败的 LPUSH,再对原本不存在的版本键执行 SET,并保持脚本短小。更复杂的数据迁移仍需设计可恢复步骤、版本状态和失败补偿。
实操
创建 Job 后等待 Complete 条件,再读取状态、完整初始化结果和业务任务数量。kubectl wait --for=condition=Complete 监听 Job 的 status condition,最长等待 90 秒;kubectl logs job/taskboard-init 让 kubectl 找到该 Job 管理的 Pod。shell 会断言首次日志必须为 initialized,TaskBoard JSON 必须同时包含目标标题和以逗号或右花括号结束的数值字段 count: 1;这个数字边界不会把 10 或 11 误判成 1。任何 API、日志或业务请求失败都会执行 exit 1。
bash
kubectl apply -n taskboard -f k8s/init-job.yaml
kubectl wait -n taskboard \
--for=condition=Complete \
job/taskboard-init \
--timeout=90s
kubectl get job taskboard-init -n taskboard
if ! FIRST_RESULT="$(kubectl logs job/taskboard-init -n taskboard | tail -n 1)"; then
echo '停止:无法读取首次初始化 Job 日志'
结果展示
text
job.batch/taskboard-init created
job.batch/taskboard-init condition met
NAME STATUS COMPLETIONS DURATION AGE
taskboard-init Complete 1/1 <动态时间> <动态时间>
first_result=initialized
first_tasks={"items":[{"title":"由 Job 初始化","done":false}],"count":1}时长会变化,JSON 字段顺序也不应作为判断条件。稳定验收字段是 Job 为 Complete 1/1、first_result=initialized、业务 count 为 1。这里的 API 读取补上了控制器之外的业务证据;如果日志成功但任务不是 1,Job 仍不能算通过。
重新创建 Job,验证重试不会重复写入
已完成 Job 的 Pod 模板不能原地重跑。为了模拟控制器重试或运维重复执行,我们只删除 taskboard-init Job 及其已完成 Pod,不删除 Redis、PVC 或版本键,然后用同一份清单重新创建。第二次 Lua 执行应看到 taskboard:init:v1 已存在,返回 already-initialized;任务数量仍必须为 1。
删除动作带 -n taskboard 和精确 Job 名。后面的断言与首次执行相同,但期望结果改为 already-initialized:
bash
kubectl delete job taskboard-init -n taskboard --wait=true
kubectl apply -n taskboard -f k8s/init-job.yaml
kubectl wait -n taskboard \
--for=condition=Complete \
job/taskboard-init \
--timeout=90s
if ! SECOND_RESULT="$(kubectl logs job/taskboard-init -n taskboard | tail -n 1)"; then
echo '停止:无法读取第二次初始化 Job 日志'
结果展示
text
job.batch "taskboard-init" deleted
job.batch/taskboard-init created
job.batch/taskboard-init condition met
second_result=already-initialized
second_tasks={"items":[{"title":"由 Job 初始化","done":false}],"count":1}already-initialized 证明第二个 Job 实际连接到 Redis 并执行了 Lua 的已完成分支,count:1 证明没有第二次 LPUSH。若第二次仍返回 initialized,说明版本键没有持久化、键名改变或连接到了另一实例;若 Job 为 Failed,先读日志与退出码,不能把失败改写成 already-initialized。
如果等待超时,先执行 kubectl get pods -n taskboard -l job-name=taskboard-init。Pod 为 Pending 时看 kubectl describe pod <名称> -n taskboard 的调度或镜像事件;Pod 为 Failed 时看 kubectl logs job/taskboard-init -n taskboard 和容器退出码;Job 出现多个失败 Pod 时,再用 kubectl describe job taskboard-init -n taskboard 检查失败计数和退避。不要在没看日志前删除重建;本节的 Lua 逻辑能抵抗重复执行,但诊断证据仍可能随 Pod 删除而消失。
在长期集群中,已完成 Job 和 Pod 不会默认立刻消失,保留它们有利于查看状态和日志,也会逐渐增加 API 对象数量。ttlSecondsAfterFinished 可以让 TTL 控制器在完成或失败后一段时间清理;具体保留多久应由故障调查、审计和成本要求决定。CronJob 则负责按计划创建 Job,也存在重复或错过调度的边界,所以其任务同样应保持幂等。
让 TaskBoard 把 Redis 纳入 readiness
知识点与预期变化
前一节为了保证 Redis 尚未部署时 TaskBoard 仍可启动,把 REQUIRE_REDIS_READY 设为 false。现在 Redis 已经就绪,可以把它改为 true。新 Pod 的 /readyz 会先向 Redis 发送 PING;连接或认证失败时,Pod 会留在运行状态,但不会进入 Service 后端。
readiness 回答的是“这个实例此刻是否应该接收流量”,不是“进程是否活着”。Redis 暂时重启时,TaskBoard 进程仍能响应 /healthz,让 liveness 失败并重启应用只会增加扰动;让 /readyz 返回失败,则会使 EndpointSlice 把该 Pod 标为非 Ready,Service 不再向它发送普通请求。依赖恢复后,探针重新成功,Pod 可以在不重启的情况下回到后端集合。
把下游依赖放进 readiness 也有取舍。如果所有 TaskBoard Pod 同时依赖同一个 Redis,Redis 短暂故障会让所有副本一起退出流量,形成整体不可用;但继续接收必然失败的任务请求也没有价值。生产应用可以区分端点:只读或不依赖 Redis 的接口保持可用,需要 Redis 的接口快速失败;也可以引入缓存、熔断和降级。课程应用功能很小,所以用一个统一 readiness 清楚展示依赖传播。
ConfigMap 通过环境变量注入,所以修改后仍要滚动重启 Deployment。我们预计新 Pod 就绪,并能通过 /api/tasks 读到 Job 写入的一条任务。
先修改项目中的 k8s/config.yaml,不要只 patch 运行对象。下面给出完整文件,四个键保留第 7 章含义,只把 REQUIRE_REDIS_READY 从字符串 "false" 改为 "true"。完整上下文能避免手工编辑时意外删掉 Redis 地址或欢迎语:
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: taskboard-config
namespace: taskboard
data:
WELCOME_MESSAGE: "你好,配置已经更新"
REDIS_HOST: "redis"
REDIS_PORT: "6379"
REQUIRE_REDIS_READY: "true"保存文件后,源声明与集群对象将通过 apply 收敛到同一状态。随后用 JSONPath 精确回读服务端的 REQUIRE_REDIS_READY 并断言为 true,而不是只相信 configured。
实操
先应用完整 ConfigMap,再滚动替换 TaskBoard Pod。环境变量只在容器启动时生成,所以现有进程不会自动看到新值。rollout restart 通过改变 Pod 模板注解触发新 ReplicaSet,rollout status 等待替换完成。最后一条命令从 toolbox-safe 经 TaskBoard Service 请求任务 API,同时穿过 Service、应用和 Redis 三段链路。
发布完成意味着新 Pod 已经通过包括 Redis 在内的 readiness 检查。理解了将要发生的对象变化后再执行:
bash
kubectl apply -n taskboard -f k8s/config.yaml
CONFIG_READY="$(kubectl get configmap taskboard-config -n taskboard \
-o jsonpath='{.data.REQUIRE_REDIS_READY}')"
if [ "$CONFIG_READY" != 'true' ]; then
echo "停止:服务端 REQUIRE_REDIS_READY=$CONFIG_READY" >&2
exit 1
fi
printf 'require_redis_ready=%s\n' "$CONFIG_READY"
kubectl rollout
结果展示
text
configmap/taskboard-config configured
require_redis_ready=true
deployment.apps/taskboard restarted
deployment "taskboard" successfully rolled out
{"items":[{"title":"由 Job 初始化","done":false}],"count":1}API 返回一条任务,说明这条完整路径已经打通:TaskBoard Service 到应用 Pod,应用通过 Redis Headless Service 连接 redis-0,Redis 再从 AOF 数据中返回任务。
前四行是控制面结果,JSON 是业务结果。configured 说明完整文件改变了 ConfigMap,require_redis_ready=true 是服务端字段回读,successfully rolled out 说明新 ReplicaSet 达到 Deployment 的可用条件;count:1 和任务标题才证明初始化写入可被应用读取。前面已经重新创建过 Job,数量仍为 1,这与 already-initialized 一起证明版本标记阻止了重复 LPUSH。
如果 rollout 卡住,先看新 Pod 是否 0/1 Ready,再执行 kubectl describe pod <新 Pod 名> -n taskboard 和 kubectl logs <新 Pod 名> -n taskboard。若日志显示 Redis 连接失败,依次核对 kubectl get pod redis-0 -n taskboard、kubectl get endpointslice -n taskboard -l kubernetes.io/service-name=redis 和 Secret 键名。若 rollout 成功但 API 返回空列表,则问题更可能位于 Job 写入的数据键或 TaskBoard 读取逻辑,而不是探针。
删除 redis-0 并验证数据仍在
知识点与预期变化
删除 redis-0 后,StatefulSet 会创建一个同名新 Pod。名称相同不代表它还是同一个对象,Pod UID 必须变化;data-redis-0 PVC 和它绑定的 PV 则应保持不变。
这次故障注入是在验证生命周期边界。我们不删除 StatefulSet,也不删除 PVC,只删除控制器管理的一个 Pod。StatefulSet 控制器观察到序号 0 缺失后,会依据同一模板创建新的 redis-0;模板中的 data 卷仍映射到 data-redis-0。新 kubelet 挂载同一 PV 后,Redis 从 /data 中打开 AOF 并恢复命令。
为什么同时记录 UID 和 PV 名?只看 Pod 名会误判,因为 StatefulSet 有意复用名字;只看任务还在,也可能是应用缓存或 Job 又写了一次;只看 PVC 名则无法确认它有没有换绑。UID 变化证明计算实例被替换,.spec.volumeName 相同证明 PVC 绑定未变,API 返回同一任务证明业务状态恢复。三个证据合起来才支持结论。
我们用完整 UID 做严格比较,只在输出中截取前四位,避免把一次运行的长动态值写成固定答案。PV 同样用完整名称比较,但不打印具体名称。展示可以缩写,判定不能缩写:四位前缀理论上可能碰撞,只有完整 UID 不相等才足以证明对象已经更换。
实操
先记录旧 UID 和 PVC 绑定的 PV,再删除 Pod,并等待同名新 Pod 就绪。JSONPath {.metadata.uid} 读取 API 对象唯一标识,{.spec.volumeName} 读取 PVC 当前绑定的 PV 名;shell 变量只存在于当前终端。--wait=true 等旧 Pod 删除完成,随后 kubectl wait --for=condition=Ready 等新对象通过探针。test 不打印敏感或动态卷名,只在两个值完全相同时给出布尔证据。
最后一条带标签选择器的 kubectl wait 会等待所有匹配的 TaskBoard Pod Ready。Redis 重启期间它们可能暂时从 Service 后端移除;等依赖恢复后再发业务请求,可以避免把恢复窗口中的预期失败误写成持久化失败。
理解这些读取和等待条件后再执行:
bash
OLD_UID="$(kubectl get pod redis-0 -n taskboard -o jsonpath='{.metadata.uid}')" || { echo '读取旧 Pod UID 失败' >&2; exit 1; }
OLD_VOLUME="$(kubectl get pvc data-redis-0 -n taskboard -o jsonpath='{.spec.volumeName}')" || { echo '读取旧 PV 绑定失败' >&2; exit 1; }
test -n "$OLD_UID" || { echo
结果展示
text
old_uid_prefix=487f
pod "redis-0" deleted
pod/redis-0 condition met
new_uid_prefix=58ae
uid_changed=true
volume_unchanged=true
pod/taskboard-<模板哈希>-<后缀 A> condition met
pod/taskboard-<模板哈希>-<后缀 B> condition met前缀从 487f 变为 58ae 只是方便人观察;真正的证据是脚本已比较完整 UID,只有不相等才会打印 uid_changed=true。volume_unchanged=true 同样是在完整 PV 名相等后才打印。最后两行表示 TaskBoard 的 readiness 已经从 Redis 重建期间的断连中恢复,此时才进行业务请求。
这里展示的 487f 和 58ae 来自一次真实执行,只用于说明格式;你的前缀应该不同,也不能仅凭前缀决定成功。Pod 后缀和模板哈希也是动态值。若任一断言停止,先在当前终端核对完整变量,并执行 kubectl get pvc data-redis-0 -n taskboard -o yaml,不要继续假设数据安全。若新 Pod 一直不 Ready,则看 Redis 日志是否有 AOF 损坏、权限或认证错误。
实操
最后再通过 TaskBoard 读取任务。命令不直接进入 Redis,而是沿用户真实使用的 TaskBoard API 路径取数据,因此同时验证 Redis 已经从 AOF 恢复、应用重新连上依赖、TaskBoard readiness 已经通过以及 Service 有可用后端:
bash
TASKS_RESPONSE="$(kubectl exec -n taskboard toolbox-safe -- \
wget -qO- http://taskboard/api/tasks)" || { echo '读取 TaskBoard 任务失败' >&2; exit 1; }
printf '%s\n' "$TASKS_RESPONSE"
printf '%s\n' "$TASKS_RESPONSE" | \
grep --fixed-strings --quiet '"title":"由 Job 初始化"' || { echo '初始化任务不存在' >&2
结果展示
text
{"items":[{"title":"由 Job 初始化","done":false}],"count":1}
task_persisted=true前一行是 API 原始 JSON,后一行只会在标题与数量两个断言都通过后出现。这样请求成功但返回空数组也会以非零状态停止,而不会被误写成持久化成功。任务仍然存在,说明数据生命周期已经与 Redis Pod 生命周期分离。但这个结果只覆盖单副本、单节点存储路径:
redis-0仍是单点,Redis 进程故障期间应用会暂时不就绪。- local-path PV 依赖所在节点,节点磁盘损坏会造成数据丢失。
- RWO 没有提供副本复制、备份或跨可用区恢复。
- 生产方案需要评估托管数据库、Redis 高可用拓扑、网络存储、备份与恢复演练。
StatefulSet 解决稳定身份和稳定卷关联,不会替我们完成数据库层的高可用设计。
PVC 到底何时会被删除
Pod 删除不会删除 StatefulSet 通过 volumeClaimTemplates 创建的 PVC,这是数据安全优先的默认行为。缩容 StatefulSet 或删除 StatefulSet 时,关联卷也不会像普通临时对象那样自动消失,除非显式配置相应的 PVC 保留策略。这样可以降低一次误操作连同数据一起删除的概率,也意味着长期集群可能留下不再使用、仍然计费的 PVC。
PVC 被删除后,PV 的回收策略才决定下一步。Delete 通常让供应器删除后端卷并回收 PV;Retain 会留下 PV 和后端数据,管理员需要确认数据归属并手工处理。即使使用 Delete,供应器故障也可能留下后端资产,所以生产清理应同时核对 Kubernetes 对象与存储平台库存。
本章不单独删除 Redis 或 PVC,因为下一章仍要读取这些资源并验证安全边界,最终章节也需要做整体验收。清理顺序是课程设计的一部分:先验收,再删除 Namespace,检查 PV 回收,最后删除具名集群。提前删除 PVC 会破坏后续证据链。
本章项目状态与验收清单
在进入安全章节前,用下面的清单核对状态。这里不要求再执行新命令;对应证据都已经在本章结果中出现:
- StorageClass
standard的 provisioner、Delete回收策略和WaitForFirstConsumer已经读懂; - StatefulSet
redis显示1/1,Podredis-0显示1/1 Running; - PVC
data-redis-0显示Bound、256Mi、RWO; - 从 PVC 追到的 PV 回指
taskboard/data-redis-0,StorageClass、回收策略和 nodeAffinity 均已回读; - Job
taskboard-init显示Complete 1/1,首次日志为initialized; - 重建 Job 后日志为
already-initialized,TaskBoard API 的任务数量仍为 1; - 删除
redis-0前后 UID 不同,PVC 的.spec.volumeName相同; - Redis 重建后 TaskBoard Pod 重新 Ready,任务仍可读取;
- 能明确说明:这次结果没有证明 local-path 跨节点高可用,也没有证明单副本 Redis 无单点故障。
如果任一控制面状态不满足,沿 Pod、PVC、事件和日志继续诊断;如果对象状态都满足但业务数据不对,就回到 Job 写入、AOF 和 TaskBoard 读取路径。不要用一个绿色状态替代另一层的验收。
检查你的理解
1
删除 redis-0 后,新 Pod 的 UID 改变但任务仍然存在,最直接的原因是什么?
2
关于本节的 ReadWriteOnce 与 local-path 存储,哪些说法正确?
3
为什么一个只要求成功完成一次的 Job,写入逻辑仍然应该幂等?
4
PVC 为 Bound 且 StatefulSet 为 Ready,已经足以证明数据可以从备份恢复。
资料依据与继续阅读
本章的对象语义和历史沿革以 Kubernetes 项目的一手资料为准:
- Volumes 解释容器文件的临时性、临时卷与持久卷的生命周期区别。
- Persistent Volumes 定义 PV、PVC、静态与动态供应以及声明生命周期。
- Storage Classes 说明 provisioner、回收策略与
WaitForFirstConsumer。 - Container Storage Interface 达到 GA 记录 CSI 从 v1.9 alpha、v1.10 beta 到 v1.13 GA 的演进,以及 out-of-tree 驱动要解决的问题。
- StatefulSet 在 Kubernetes 1.5 进入 beta 记录它从 PetSet 更名,以及稳定身份、有序操作和持久存储的早期设计目标。
- StatefulSets 定义稳定身份、有序操作、Headless Service 与卷保留边界。
- Jobs 说明完成计数、重试、退避、终止条件,以及程序可能被启动多次的边界。
- Redis Persistence 是 Redis 项目对 AOF 重放、
appendfsync everysec取舍与备份边界的一手说明。
读官方文档时,把“API 保证什么”和“存储系统或数据库自己保证什么”分开。Kubernetes 能保证对象关系与控制循环,不会替 Redis 提供复制,也不会替备份系统证明恢复可用。