输入输出重定向:把命令的三条通道接到正确位置
一条命令在终端里运行时,我们最容易看到的是文字:输入从键盘进来,结果和报错都出现在屏幕上。可如果把注意力只放在屏幕上,重定向语法很快就会变成一堆难记的符号。真正稳定的理解方式,是先忘掉“屏幕”,只看进程持有的通道。
每个进程通常从父进程继承三条已经打开的标准流:标准输入、标准输出和标准错误。Shell 负责在命令启动前重新接线,命令只管从编号通道读取或写入。>、2>、2>&1、| 看起来各不相同,底层问题却只有三个:要改哪条通道、接到哪里、按什么顺序改。
这一篇会沿着这套心智模型展开。我们先拆清 fd 0、1、2,再讨论文件的覆盖与追加、here-document、额外文件描述符、管道状态和 tee。所有容易混淆的地方都配有可复现的隔离实操。
三条标准流是进程的默认接口
标准流不是三块固定设备,而是三条约定好的连接。终端只是常见的默认端点:交互式 Shell 启动命令时,通常让三条流都连到当前终端,所以 stdout 与 stderr 看起来混在同一处。只要重接其中一条,它们立刻会表现出不同去向。
文件描述符(file descriptor,fd)是进程文件描述符表中的非负整数索引。进程调用读写接口时使用 fd;这个编号背后可以连着终端、常规文件、设备或管道。把它理解成“插孔编号”很合适,但要记住:描述符指向的是一个已经打开的连接,不是文件内容本身。
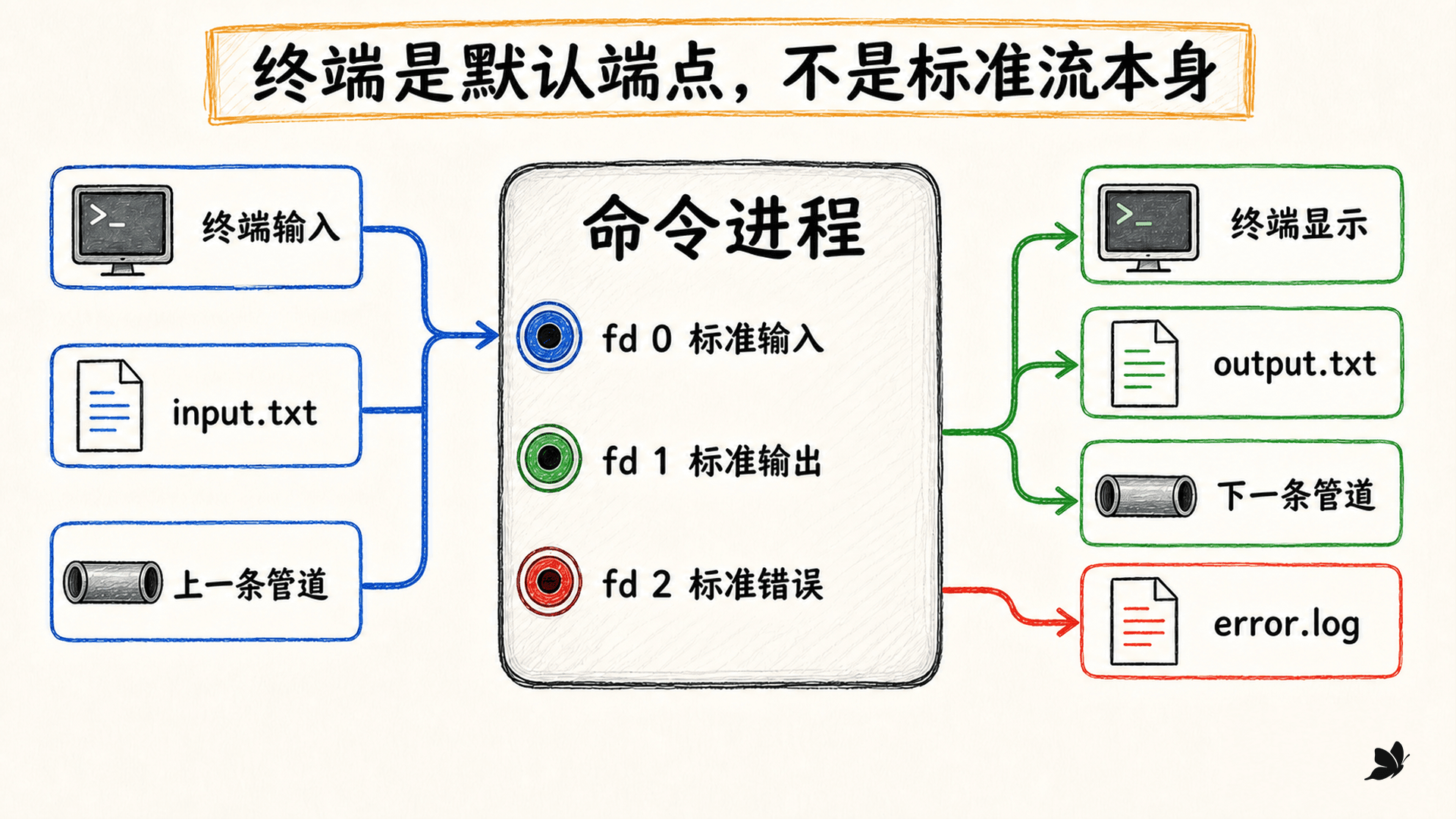
图:终端只是默认端点,fd 0、1、2 才是进程看到的稳定接口。
1
stdout 和 stderr 默认都显示在终端,所以它们是同一条流。
fd 0、1、2 各自负责什么
三条标准流的职责可以先记成这张表:
stdin、stdout、stderr 说的是约定用途,不是数据格式。三条流本质上都传递字节。一个设计良好的命令会把可供下游处理的结果写到 stdout,把不属于结果的诊断写到 stderr。这样,即使正常结果进入文件或管道,错误仍能被操作者看到或单独记录。
例如下面的函数分别写两条输出流:
bash
emit_pair() {
printf '正常结果\n'
printf '诊断信息\n' >&2
}
emit_pair >out.txt 2>err.txtout.txt 只有“正常结果”,err.txt 只有“诊断信息”。>&2 表示让这次 printf 的 stdout 复制 fd 2 的连接,于是文字实际沿 stderr 的目的地送出。
2
标准错误对应的文件描述符编号是 ____。
命令参数和标准输入不是一回事
很多工具既接受文件名参数,也能从 stdin 读取数据,因此两种写法常常得到相似内容:
bash
wc -l records.txt
wc -l <records.txt第一条把 records.txt 作为参数交给 wc,由 wc 自己打开文件;第二条由 Shell 打开文件并接到 fd 0,wc 只知道自己在读 stdin。区别会反映在输出上:GNU wc 接受文件名参数时通常把文件名一起显示,从 stdin 读取时没有可报告的文件名。
这个区别也解释了为什么 < 不能随意替代参数。有些程序只认路径参数,有些程序只读 stdin,还有些程序两者都支持但行为略有不同。判断时要看命令接口,而不是看到文件就机械加 <。
3
执行 wc -l <records.txt 时,谁负责打开 records.txt 并把它接到 fd 0?
Shell 先接线,再启动命令
重定向符号由 Shell 解释,不会原样传给命令。对于一条简单命令,可以用下面的顺序理解:
- Shell 解析命令结构,并完成需要的展开。
- Shell 按从左到右的顺序处理每个重定向:打开文件、复制描述符或关闭描述符。
- 全部重定向成功后,Shell 才执行内建命令或启动外部程序。
- 新程序继承调整后的文件描述符。
这会产生一个很反直觉、却非常重要的结果:
bash
printf '旧内容\n' >early.txt
definitely_missing_command >early.txt即使命令根本不存在,early.txt 也可能已经被截断为 0 字节。原因是 >early.txt 在命令查找失败前就成功打开并清空了目标。反过来,如果目标文件无法打开,例如目录不可写,那么重定向失败,命令不会开始执行。

图:文件变化可能早于程序执行,排错时要把重定向阶段单独看待。
4
外部命令不存在时,写在它后面的 >target 一定不会改变 target。
用覆盖和追加控制文件输出
省略描述符编号时,以 > 开头的重定向默认操作 fd 1。最常见的四种写法是:
“覆盖”和“追加”描述的是打开文件的方式。它们不是命令输出完以后才发生的一次复制;程序运行时,fd 1 已经直接连到目标文件。
5
哪条命令会保留 report.log 的已有内容,并在末尾继续写入?
> 的清空发生在打开目标时
目标不存在时,> 通常创建文件;目标是已有常规文件时,它以可写、截断方式打开,文件长度立即变成 0。正因为截断发生得早,下面的写法不能用来“原地读取并重写同一个文件”:
bash
sort data.txt >data.txtsort 开始读以前,Shell 已经清空 data.txt,结果往往是空文件。安全做法是写到临时文件,检查成功后再替换:
bash
tmp=$(mktemp)
if sort data.txt >"$tmp"; then
mv -- "$tmp" data.txt
else
rm -f -- "$tmp"
fi权限也由执行重定向的 Shell 检查。sudo command >protected.log 只提升 command,> 仍由当前 Shell 处理;若当前身份无权打开目标,命令会在重定向阶段失败。需要管理权限时,应把“打开目标”的动作也放进明确受控的高权限边界,而不是只在命令名前加 sudo。
6
关于 command >file,哪些说法正确?
>> 和 2>> 只改变写入位置
追加适合日志、批次结果和逐步收集:
bash
printf '开始\n' >>run.log
do_work >>run.log 2>>error.log
printf '结束 status=%s\n' "$?" >>run.log>>run.log 只追加 stdout,2>>error.log 只追加 stderr。追加并不会自动加时间、分隔符或换行,这些内容仍由写入命令决定。
在常规的本地文件系统上,追加模式会让每次底层写入定位到末尾,但它不是多进程日志事务。一个逻辑行如果被拆成多次写入,多个进程的内容仍可能交错;网络文件系统也可能有额外限制。需要严格结构和并发保证时,应使用专门的日志设施。
7
使用 >> 后,Shell 会自动在每次输出前加入时间并保证多进程整行不交错。
用 noclobber 减少误覆盖
Bash 可以开启覆盖保护:
bash
set -C # 等价于 set -o noclobber
printf '新内容\n' >important.txt
# bash: important.txt: cannot overwrite existing file开启后,常规 > 遇到已存在的常规文件会失败。确实需要覆盖某一个目标时,用 >| 明确表达这次例外:
bash
printf '确认覆盖\n' >|important.txt
set +C # 用完关闭保护noclobber 是防手滑的护栏,不是备份策略,也不能代替权限控制。脚本若临时改变 Shell 选项,应在清楚的作用域内恢复,避免后面的命令行为悄悄变化。
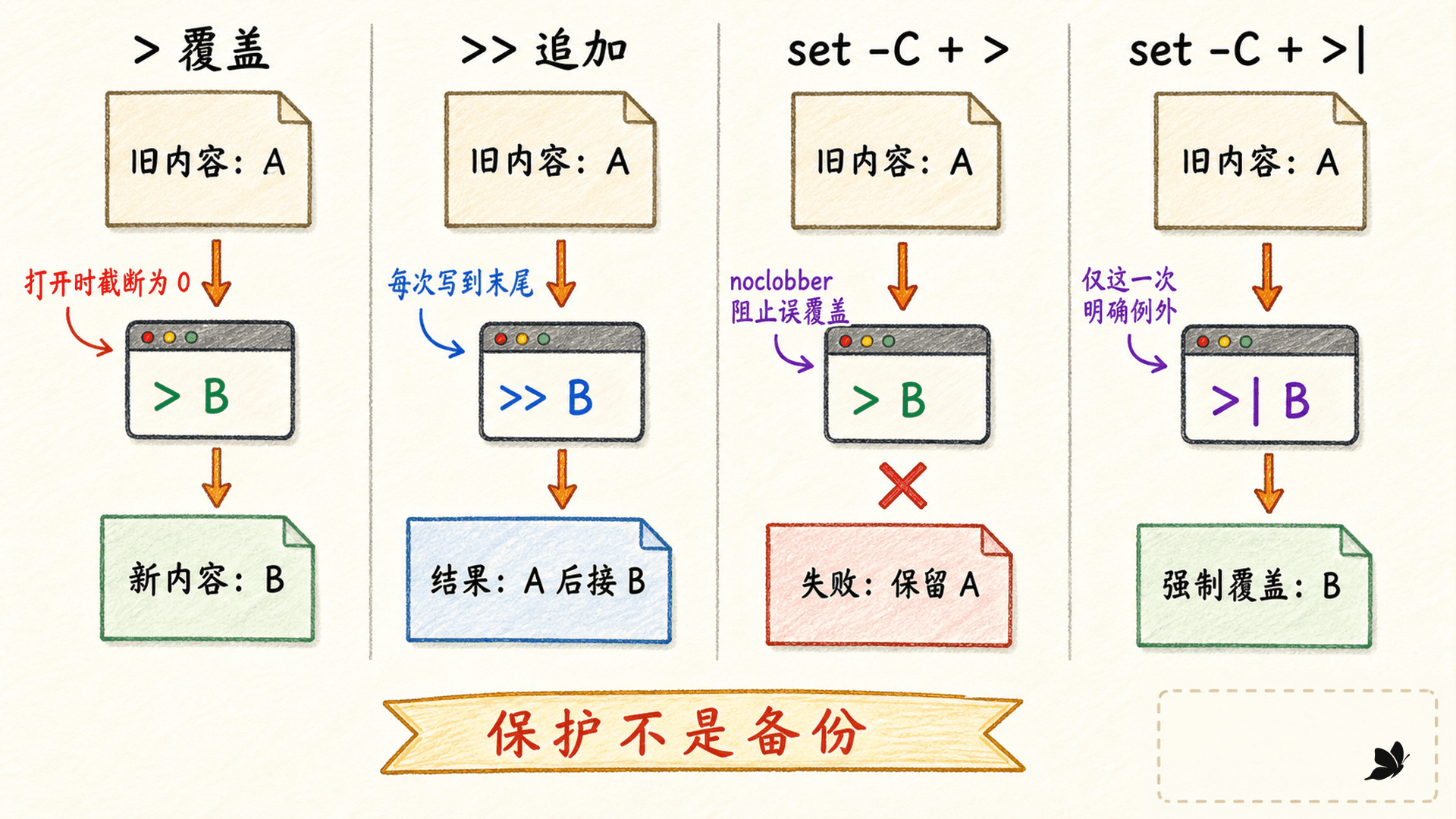
图:>| 不是另一种追加,而是在覆盖保护开启时显式要求覆盖。
8
Bash 开启 noclobber 后,要对某个已存在文件明确强制覆盖,可以使用操作符 ____。
把正常结果和诊断信息分开处理
错误信息默认不跟随 >,不是因为 Shell 漏掉了它,而是因为 > 只改 fd 1。保留独立 stderr 能让命令组合更可靠:下游程序只接收正常数据,操作者仍能看到诊断,自动化流程也可以分别归档两类信息。
判断一条命令是否成功,应该读取退出状态;判断它说了什么,再检查 stdout 和 stderr。屏幕安静不代表成功,屏幕出现文字也不一定是错误。
9
执行 report >out.txt 后,错误仍显示在终端,最直接的原因是什么?
分离、合流、追加和丢弃
常用组合可以按目的选择:
bash
# 分开覆盖
report >out.log 2>err.log
# 分开追加
report >>out.log 2>>err.log
# 两条流写入同一文件:Bash 简写
report &>all.log
# 同一语义的传统写法
report >all.log 2>&1
# 只丢弃 stderr
report 2>/dev/null
# 丢弃两条流
report >/dev/null 2>&1/dev/null 是一个会接收并丢弃写入数据的设备。把流接过去只是放弃观察,不会跳过命令,也不会把失败状态改成成功。自动化任务若把两条流都丢弃,至少应在别处检查和记录退出状态,否则真正的故障会变成“什么都没发生”。
&> 和 &>> 是 Bash 语法;需要照顾较老或不同的 Shell 时,用 >file 2>&1 和 >>file 2>&1 更容易移植。
10
哪些写法会让 stdout 和 stderr 共享同一个已打开连接,并写入 all.log?
2>&1 是从左到右的连接快照
这两条命令不能互换:
bash
report >all.log 2>&1
report 2>&1 >out.log第一条的接线过程是:
>all.log让 fd 1 指向文件。2>&1让 fd 2 复制 fd 1 此刻的连接。- stdout 与 stderr 都指向
all.log。
第二条则是:
2>&1先让 fd 2 复制 fd 1 当时的终端连接。>out.log再把 fd 1 移到文件。- stdout 进
out.log,stderr 仍沿原终端连接输出。
2>&1 中的 &1 表示“文件描述符 1”,不是名为 1 的文件。复制完成后,两条描述符各自持有连接;以后再修改 fd 1,不会让 fd 2 追着变化。
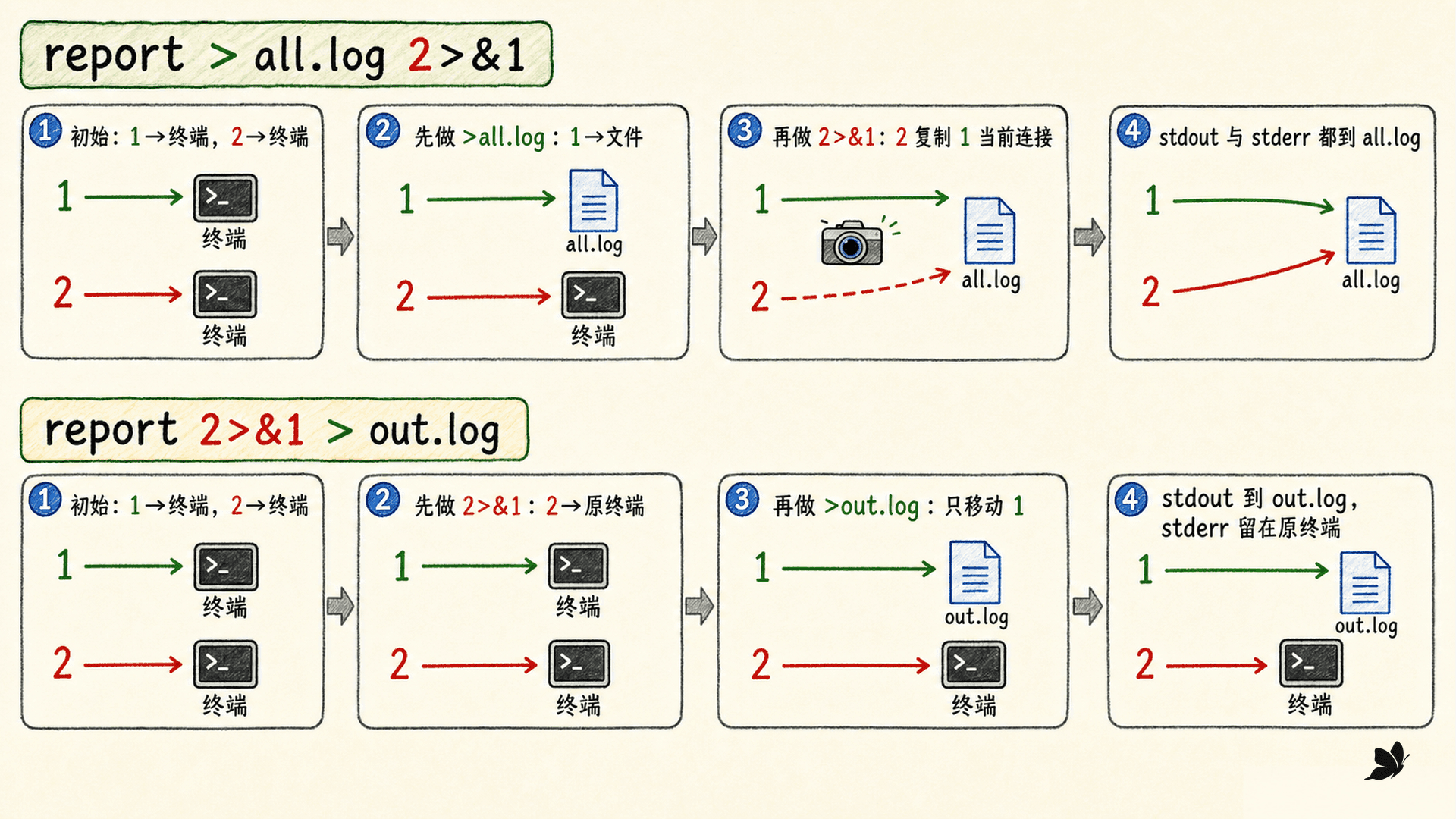
图:先改 fd 1 再复制可以合流;先复制再改 fd 1 会继续分流。
11
report 2>&1 >out.log 执行后,stderr 通常去哪里?
把文件或多行文本接到标准输入
输入重定向以 < 开头,省略编号时默认操作 fd 0。它让命令从指定连接读数据,因此很适合那些以 stdin 为通用接口的过滤器。与输出重定向一样,输入目标也由 Shell 在命令开始前打开;文件不存在或不可读时,命令不会正常启动。
12
command <input.txt 会把字符串 '<input.txt' 作为参数交给 command。
< 适合连接 stdin 接口
最小形式是:
bash
tr '[:lower:]' '[:upper:]' <names.txt可以同时安排输入和输出:
bash
tr '[:lower:]' '[:upper:]' <names.txt >upper-names.txt这一行出现两个重定向,但它们操作不同描述符:<names.txt 改 fd 0,>upper-names.txt 改 fd 1。对于这两个彼此独立的打开操作,交换书写位置通常不改变结果;一旦出现 2>&1 这类描述符复制,顺序就可能改变连接关系。
连续写多个输入重定向没有“把多个文件串起来”的效果:
bash
command <first.txt <second.txtShell 从左到右处理,后一个 <second.txt 会替换 fd 0 的前一连接。要合并多个文件,应使用支持多文件参数的工具或显式管道,例如 cat first.txt second.txt | command。
13
command <first.txt <second.txt 最终从哪个文件读取 stdin?
Here-document 的 delimiter 决定展开边界
Here-document 用脚本内的多行文本提供输入:
bash
course='输入输出重定向'
cat <<EOF
课程:$course
时间:$(date +%F)
算术:$((2 + 3))
EOF<<EOF 告诉 Shell 继续读取后续行,直到遇到只包含 EOF 的一行。结束标记可以换成其他字符串,大写只是便于辨认的惯例。结束行必须独立出现,不能带额外文字;普通 << 下,前后空白也不能随意增加。
未引用 delimiter 时,正文会进行参数展开、命令替换和算术展开。若正文应按字面交给命令,就引用 delimiter:
bash
cat <<'EOF'
课程:$course
时间:$(date +%F)
算术:$((2 + 3))
EOF引号控制的是正文是否展开,引号本身不会成为结束标记的一部分。上例实际仍以独立的 EOF 结束。
<<-EOF 还有一个适合脚本排版的规则:Shell 会剥离正文和结束标记前的 Tab。它不会剥离普通空格,因此用编辑器自动把 Tab 转为空格后,缩进仍会进入数据,结束标记也可能无法匹配。
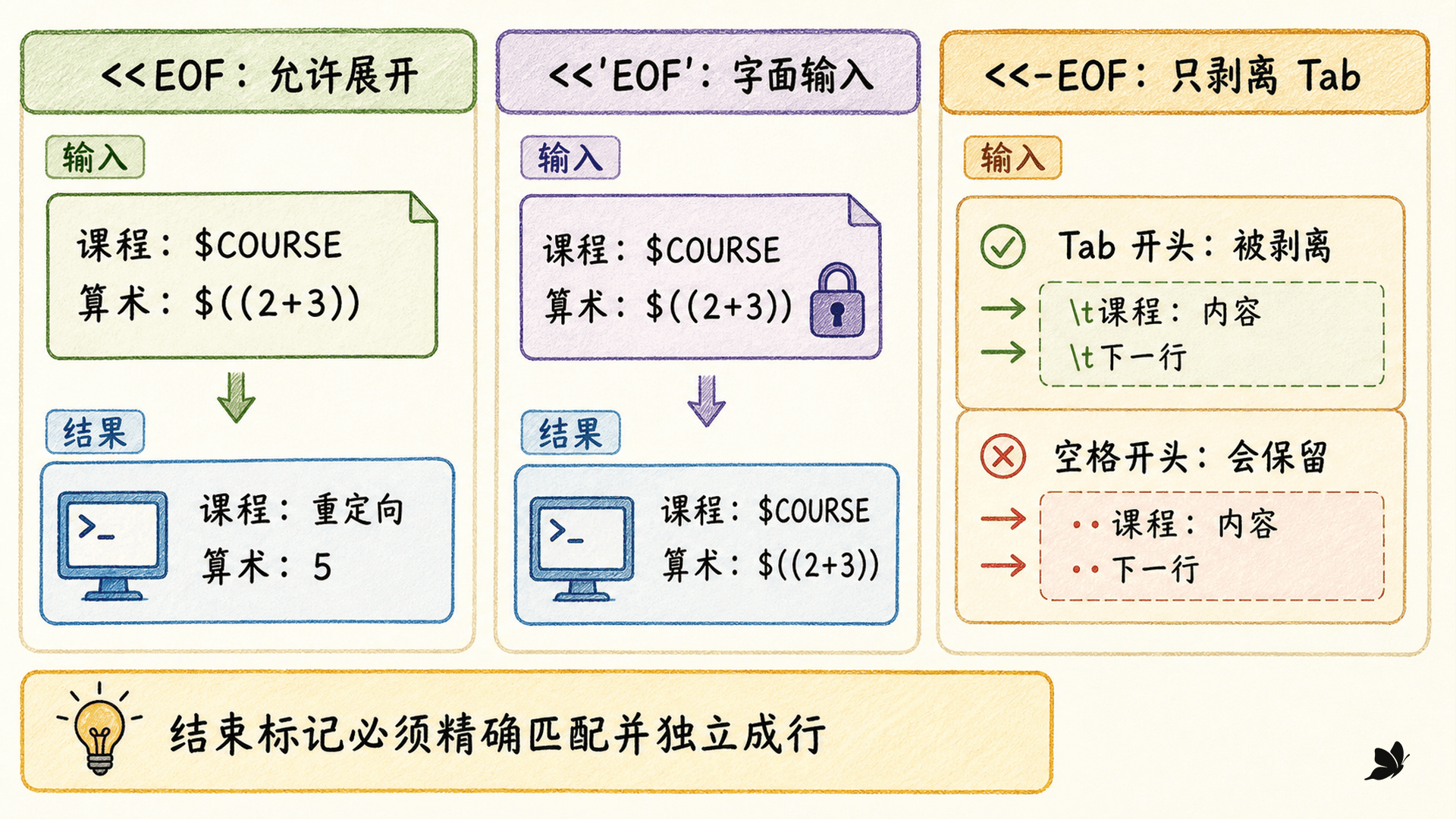
图:delimiter 是否引用决定展开,<<- 只处理前导 Tab。
14
关于 here-document,哪些说法正确?
Here-string 是 Bash 的单字符串输入简写
Bash 还支持 <<<:
bash
text='alpha beta'
wc -w <<<"$text"Shell 展开 word 后,把结果作为一个字符串送到 stdin,并在末尾补一个换行。因此 wc -c <<<"abc" 通常得到 4,而不是 3。
Here-string 不是 POSIX sh 语法。需要更广的脚本兼容范围时,可以用:
bash
printf '%s\n' "$text" | wc -w无论选哪种形式,变量都应按预期引用。<<<"$text" 能明确保留字符串内部空格;不要把 here-string 当成无需考虑展开和引号的特殊安全区。
15
在 Bash 中执行 wc -c <<<"abc",常见结果是 ____。
用额外文件描述符保留独立通道
fd 0、1、2 足以覆盖大多数命令行操作,但长脚本有时希望持续打开一个独立日志,而不反复打开文件,也不永久改动标准输出。Bash 可以让 Shell 分配一个额外描述符,并把编号存到变量中。
这类通道要按生命周期管理:打开、使用、关闭。忘记关闭会让后续命令意外继承连接,长时间运行的进程还可能耗尽可用描述符。
16
额外文件描述符一旦打开,脚本结束前永远不能关闭。
exec {fd}>file 的打开、写入与关闭
下面是一套完整用法:
bash
exec {audit_fd}>audit.log
printf '任务开始\n' >&"$audit_fd"
do_work
status=$?
printf '任务结束 status=%s\n' "$status" >&"$audit_fd"
exec {audit_fd}>&-第一行没有提供要替换 Shell 的命令,因此 exec 只把重定向应用到当前 Bash。{audit_fd} 让 Bash 选择一个可用的较高编号,并把编号写入变量。两次 printf 复制该描述符的连接,写进同一个已打开文件;最后一行用 >&- 关闭输出描述符。
如果只写固定编号,也能看到类似形式,例如 exec 3>audit.log、printf ... >&3、exec 3>&-。动态编号更不容易撞上脚本或 Shell 已使用的描述符,但 {变量} 形式属于 Bash 扩展。无论使用哪一种,都不要随意占用 fd 0、1、2,也不要假设一个未知程序不会使用其他固定编号。
在隔离测试中,Bash 为变量分配了 fd 10。打开后 /proc/$$/fd/10 存在,关闭后链接消失,已写入的文件内容仍然保留。这说明关闭的是进程连接,不是删除文件。
17
exec {logfd}>run.log 的主要效果是什么?
管道连接进程,不经过中间文件
command1 | command2 让 Shell 创建一条管道,把前一命令的 stdout 接到后一命令的 stdin。两段通常并发运行:前段写入,后段读取;数据不必先完整落到一个普通文件里。
bash
printf 'pear\napple\npear\n' | sort | uniq -c这里 printf 的 stdout 进入 sort 的 stdin,sort 的 stdout 再进入 uniq。最后一段的 stdout 仍沿原连接显示,除非继续重定向。
18
在 producer | consumer 中,默认被管道连接的是哪两端?
普通 | 不接 stderr,|& 会在最后合流
下面的诊断不会进入 grep:
bash
report | grep '成功'普通 | 只连接 stdout。如果希望 Bash 把前一段 stdout 和 stderr 一起送进下一段,可以写:
bash
report |& grep '关键字'在 Bash 中,|& 可以理解成对前一段应用 2>&1 |,而且隐式的 2>&1 在前一段显式重定向之后处理。这会带来一个容易漏掉的次序边界:
bash
report 2>side.log |& consumerShell 先创建 side.log 并让 fd 2 指向它,随后 |& 的隐式 2>&1 又把 fd 2 改到管道。因此 side.log 可能被创建却为空,stdout 与 stderr 都进入 consumer。如果目标是“stderr 留文件、stdout 进管道”,应使用普通 |:
bash
report 2>side.log | consumer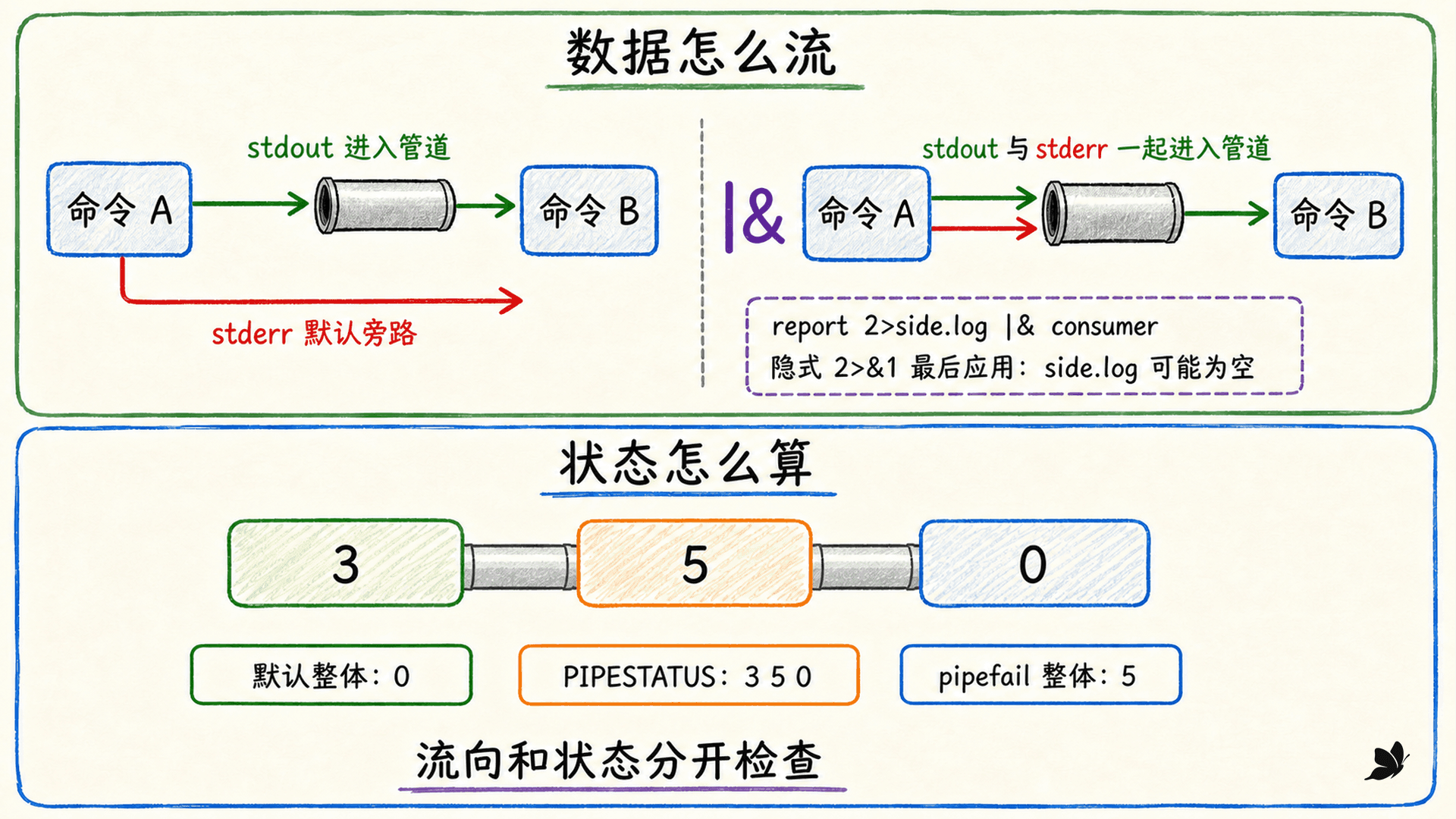
图:数据流向与退出状态是两套问题,先确认接了哪条流。
19
在 Bash 中,report 2>side.log |& consumer 一定会把 stderr 留在 side.log。
默认状态、PIPESTATUS 与 pipefail
数据能流到最后,不代表每一段都成功。Bash 默认用最后一段的状态作为整条管道的 $?:
bash
set +o pipefail
false | true
printf '整体=%s,各段=%s\n' "$?" "${PIPESTATUS[*]}"
# 整体=0,各段=1 0最后的 true 成功,所以整体是 0;PIPESTATUS 数组才揭示第一段返回 1。这个数组会被下一条简单命令刷新,必须紧跟管道读取或复制。
开启 pipefail 后,整体状态取最右侧非 0;如果每段都成功才为 0:
bash
set -o pipefail
bash -c 'exit 3' | bash -c 'exit 5' | true
printf '整体=%s,各段=%s\n' "$?" "${PIPESTATUS[*]}"
# 整体=5,各段=3 5 0为什么取“最右侧非 0”?它既保留失败,又尽量反映沿管道向后推进时最后遇到的失败。pipefail 不会阻止各段运行,也不会自动打印诊断;它只改变整条管道如何计算退出状态。
POSIX.1-2024 已把 pipefail 纳入标准,但较老的 /bin/sh 实现和旧环境仍可能不支持。PIPESTATUS 则是 Bash 数组,脚本若依赖它,应明确使用 Bash。
20
执行 false | true 后,哪些说法正确?
用 tee 一边继续处理,一边保存副本
普通 > 会把 stdout 从原去向移到文件,后面的终端或管道收不到这份数据。tee 是一个普通命令:它从 stdin 读取,把每份数据同时写到自己的 stdout 和指定文件。因此它像管道中的三通,而不是一种 Shell 重定向符号。
bash
generate_report | tee raw-report.txt | grep 'ERROR'raw-report.txt 保存到达 tee 的完整 stdout,grep 同时继续处理同一份流。tee 默认覆盖目标,tee -a 才追加:
bash
generate_report | tee -a history.log | summarizestderr 默认仍不会进入 tee。若确实要连同诊断一起保存,可以先显式合流,但下游也会收到混合数据:
bash
generate_report 2>&1 | tee all.log | summarize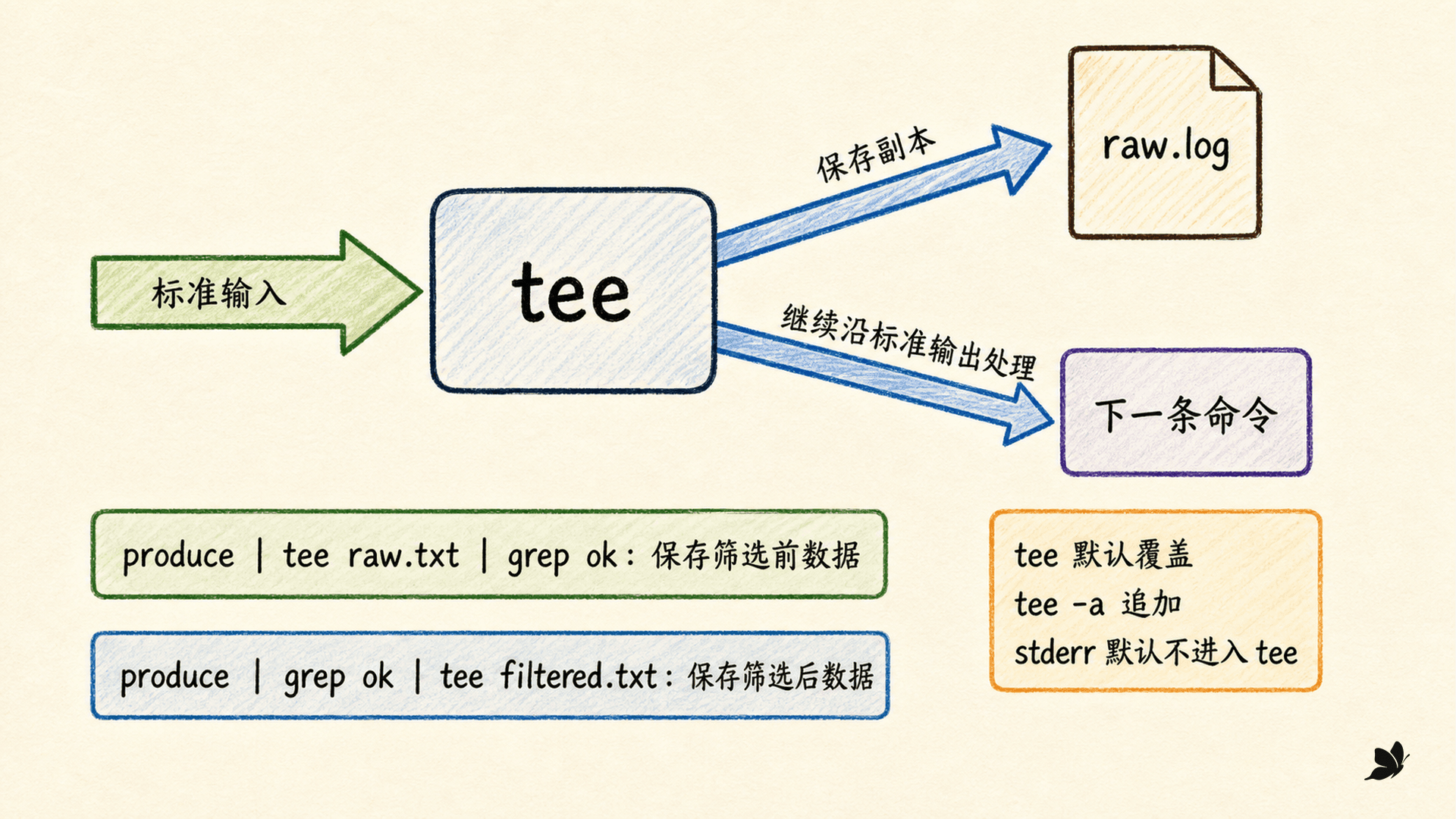
图:tee 保存的是到达它的流,放在管道不同位置会得到不同阶段的数据。
21
哪条命令会把数据追加到 history.log,同时继续交给 summarize?
tee 放在哪里,就保存哪个阶段
比较两条流水线:
bash
produce | tee raw.txt | grep 'ok' >filtered.txt
produce | grep 'ok' | tee filtered.txt第一条的 raw.txt 保存 produce 的全部 stdout,filtered.txt 只保存筛选结果。第二条的 filtered.txt 只保存经过 grep 的内容,tee 的 stdout 还会继续显示。
当 tee 后面的消费者提前退出时,tee 可能遇到断开的管道。处理长数据或多个输出时,要检查整条流水线状态;GNU tee -p 还能调整输出错误处理方式。入门阶段先掌握一个判断:tee 只复制自己实际读到的 stdin,既不会回看上游 stderr,也不会猜测你想保存哪个阶段。
22
produce | grep ok | tee filtered.txt 会让 filtered.txt 保存 grep 之前的全部原始输出。
在一次性 Debian 环境完成整套实操
下面的练习把写入限制在容器的 /tmp/welearn-ch06。--rm 让容器退出后自动移除,脚本仍会显式删除实验目录并输出清理证据。这样做的重点不是“为了测试而测试”,而是让每个现象都能对应到一条描述符规则,并确保练习不会污染后续环境。
23
隔离练习同时使用 --rm 和脚本内显式 rm -rf,主要为了什么?
完整命令、预期结果与逐步解释
复制下面的命令即可运行。脚本不需要管理权限,所有目标都在临时目录中:
bash
docker run -i --rm --name welearn-linux-ch06-lab \
debian:bookworm-slim bash -s <<'LAB'
set -u
lab=/tmp/welearn-ch06
mkdir -p "$lab"
trap 'rm -rf -- "$lab"' EXIT
cd "$lab"
emit_pair() {
printf 'OUT:%s\n' "$1"
printf 'ERR:%s\n' "$1" >&2
}
# 1. 分开 stdout 与 stderr
emit_pair split >stdout.txt 2>stderr.txt
printf 'stdout=<%s> stderr=<%s>\n' \
"$(tr '\n' '|' <stdout.txt)" \
"$(tr '\n' '|' <stderr.txt)"
# 2. 比较 2>&1 的左右顺序
emit_pair both >both.txt 2>&1
printf 'both=<%s>\n' "$(tr '\n' '|' <both.txt)"
emit_pair copied_first 2>&1 >only-out.txt
printf 'only-out=<%s>\n' "$(tr '\n' '|' <only-out.txt)"
# 3. 开启覆盖保护,再对单个文件明确强制覆盖
printf '保留\n' >protected.txt
set -C
printf '误覆盖\n' >protected.txt
printf 'blocked=%s content=<%s>\n' \
"$?" "$(tr '\n' '|' <protected.txt)"
printf '强制覆盖\n' >|protected.txt
set +C
# 4. 比较未引用和引用的 here-document
topic='重定向'
cat <<EOF >expanded.txt
主题:$topic
算术:$((2 + 3))
EOF
cat <<'EOF' >literal.txt
主题:$topic
算术:$((2 + 3))
EOF
printf 'expanded=<%s> literal=<%s>\n' \
"$(tr '\n' '|' <expanded.txt)" \
"$(tr '\n' '|' <literal.txt)"
# 5. 查看管道各段状态和 pipefail
set +o pipefail
false | true
printf 'default=%s parts=<%s>\n' "$?" "${PIPESTATUS[*]}"
set -o pipefail
bash -c 'exit 3' | bash -c 'exit 5' | true
printf 'pipefail=%s parts=<%s>\n' "$?" "${PIPESTATUS[*]}"
set +o pipefail
# 6. tee 同时保存并继续输出
printf 'alpha\nbeta\n' | tee copy.txt | sed 's/^/next:/'
printf 'copy=<%s>\n' "$(tr '\n' '|' <copy.txt)"
cd /
rm -rf -- "$lab"
if test ! -e "$lab"; then
printf '/tmp/welearn-ch06 已删除\n'
trap - EXIT
else
printf '清理失败\n' >&2
exit 1
fi
LAB关键输出应包含:
text
stdout=<OUT:split|> stderr=<ERR:split|>
both=<OUT:both|ERR:both|>
ERR:copied_first
only-out=<OUT:copied_first|>
bash: protected.txt: cannot overwrite existing file
blocked=1 content=<保留|>
expanded=<主题:重定向|算术:5|>
literal=<主题:$topic|算术:$((2 + 3))|>
default=0 parts=<1 0>
pipefail=5 parts=<3 5 0>
next:alpha
next:beta
copy=<alpha|beta|>
/tmp/welearn-ch06 已删除逐步看原因:
emit_pair split >stdout.txt 2>stderr.txt 分别改 fd 1 和 fd 2,所以两个文件各含一条流。这先证明“同屏显示”不等于“同一连接”。
>both.txt 2>&1 先移动 fd 1 再复制给 fd 2,因此文件有两行;2>&1 >only-out.txt 先复制旧连接,故 ERR 仍出现在外部终端,文件只含 OUT。
set -C 让第二次常规覆盖在重定向阶段返回 1,printf 没有得到运行机会,旧内容保留;>| 才明确强制覆盖。随后立即 set +C,避免选项影响后面的步骤。
未引用的 EOF 允许变量和算术展开,引用的 'EOF' 则把正文按字面交给 cat。结束标记仍然是没有引号的 EOF。
默认管道只取最后一个 true 的状态,所以整体为 0;PIPESTATUS 仍显示 1 0。开启 pipefail 后,三段里的最右侧非 0 是 5,整体随之变成 5。
tee copy.txt 把 alpha、beta 写入文件,也从 stdout 继续交给 sed。最后切出临时目录、删除它并用 test ! -e 检查,输出明确的清理证据。
实操有几条失败边界要提前知道:Docker 服务不可用时,容器不会启动;同名容器仍在运行时,名称会冲突;镜像首次使用可能需要拉取。脚本中的 noclobber 故意触发一次错误,因此不能简单加全局 set -e,否则练习会在预期失败处提前退出。若自行改动路径,务必保持清理目标和创建目标使用同一个已引用变量。
这套行为已在 Debian bookworm-slim、Bash 5.2.15 的一次性容器中验证,内核标识为 6.10.14-linuxkit。容器退出后,同名容器列表为空。
24
实操中 default=0 parts=<1 0> 能说明什么?
用症状反推是哪条连接出了问题
重定向排错不要从“再加几个符号试试”开始。先写出 fd 0、1、2 当前各指向哪里,再确认 Shell 从左到右做了哪些修改,最后看退出状态。一个很实用的诊断模板是:
bash
command >out.log 2>err.log
status=$?
printf 'status=%s out_bytes=%s err_bytes=%s\n' \
"$status" "$(wc -c <out.log)" "$(wc -c <err.log)"它把三个问题拆开:命令是否成功、正常结果有多少、诊断有多少。确认之后再决定是否合流、追加或丢弃;不要一开始就把全部内容送进 /dev/null。
25
排查命令失败时,先用 >/dev/null 2>&1 隐藏所有输出通常能提供更多证据。
四类常见症状的定位顺序
Here-document 卡住并出现次提示符时,优先检查结束标记是否完全匹配、是否独立成行、是否误用了空格代替 <<- 所需的 Tab。tee 文件内容不符合预期时,检查它位于过滤器之前还是之后,以及 stderr 是否真的被合流到它的 stdin。
最后再看环境边界:目标目录权限、磁盘空间、只读挂载、文件描述符上限和下游提前退出都可能让重定向或管道失败。重定向语法正确只代表接线意图清楚,不保证端点一定可用。
26
Here-document 一直等待输入时,最先应该检查哪一项?
把常用语法压缩成一张检查表
遇到复杂命令时,可以先在表中定位每个符号操作的描述符,再按出现顺序模拟:
不要把 2>&1 读成“把 stderr 追加到 stdout 文件”。它只复制 fd 1 在那一刻的连接;文件是否覆盖或追加,取决于前面如何打开 fd 1。
27
哪个操作符表示关闭一个输出文件描述符 n?
可移植语法和 Bash 扩展要分层使用
<、>、>|、>>、描述符复制、here-document、<<- 和普通 | 都有 POSIX Shell 语义。tee 也是标准工具。pipefail 已进入 POSIX.1-2024,但旧 Shell 可能尚未实现,部署前仍要检查目标环境。
下列形式应明确按 Bash 使用:
&>、&>>:同时处理 stdout 与 stderr 的简写。<<<:here-string。|&:把前一段 stdout 与 stderr 一起接入下一段。PIPESTATUS:保存逐段状态的 Bash 数组。exec {fd}>file:用变量接收动态分配的描述符。
脚本若使用这些语法,应以 Bash 运行并写清 shebang,例如 #!/usr/bin/env bash;不要声明 /bin/sh 后又依赖 Bash 扩展。反过来,也不必为了形式上的可移植性把清楚的 Bash 脚本改得难以维护,关键是让运行边界与语法选择一致。
28
哪些属于明确的 Bash 专用能力,而不能假设所有 POSIX sh 都支持?
继续核对语义时去哪里查
符号记住以后,最容易出错的是边界:展开顺序、描述符复制、管道状态和跨 Shell 差异。下面几份一手说明适合按问题查阅:
- GNU Bash:Redirections 列出覆盖、追加、here-document、here-string 和描述符复制的精确定义。
- GNU Bash:Pipelines 解释
|&、子进程边界和pipefail状态规则。 - GNU Bash:Bash Variables 可核对
PIPESTATUS何时更新。 - POSIX.1-2024 Shell Command Language 用来判断哪些语法属于标准 Shell,以及重定向在执行流程中的位置。
- GNU Coreutils:tee 说明覆盖、追加和输出错误处理。
- Linux man-pages:open(2) 能进一步理解截断、追加和打开文件描述之间的关系。
复盘时不妨给自己一个固定顺序:先写 fd 0、1、2 的当前端点,再从左到右应用每个重定向,最后单独计算退出状态。只要这三步分开,长命令也能逐段还原,不需要靠猜。
29
分析一条复杂重定向命令时,最稳妥的第一步是什么?