图数据库
在现实世界中,事物之间普遍存在各种复杂的关联关系。例如,社交网络中的点赞、评论,商品推荐系统中的用户行为,以及人际关系网络的纵横交错,这些场景都离不开对数据间关联的高效建模和查询。图数据库正是在此背景下应运而生,为强关联、高连接度数据的存储与分析提供了专业解决方案。
图数据库最大的优势在于关系是预先存储的,而不是查询时才计算出来的。这意味着遍历复杂的关系网络时,性能远超传统关系数据库。
图数据库的核心概念
节点与属性
每个节点代表着一个现实世界中的专业实体。在专业的电商系统建模中,用户、商品、订单等均作为节点加以抽象。下面以一个实际例子进行说明:
javascript
// 创建用户节点
const user = {
id: 'user_001',
name: '张小明',
age: 28,
city: '北京',
registered: '2023-01-15'
}
// 创建商品节点
const product = {
id: 'product_888',
name: 'MacBook Pro',
price: 15999,
category: '电子产品'
}关系的方向性
关系在图数据库中不仅仅起到连接节点的作用,更蕴含着丰富的业务语义。例如,「购买」这种关系通常是有方向的,表示用户对商品进行操作;而「朋友」关系则通常是双向的,表示用户之间存在互惠的社交联系。在建模时,必须根据实际业务需求区分关系的方向性与属性,以保证数据表达的准确性和高效性。
javascript
// 购买关系(单向)
{
from: 'user_001',
to: 'product_888',
type: '购买',
properties: {
购买时间: '2024-03-15',
数量: 1,
价格: 15999
}
}
// 朋友关系(可能双向)
{
from: 'user_001',
to: 'user_002',
图遍历
这正体现了图数据库在关系和连接查询方面的强大能力。例如,若需分析所有曾购买MacBook Pro的用户的朋友还购买过哪些其他商品,传统关系型数据库往往需要多次复杂的表关联(JOIN)操作,而在图数据库中,可以通过关系遍历(Graph Traversal)自然且高效地实现跨节点与关系的深度查询。
图数据库的特性
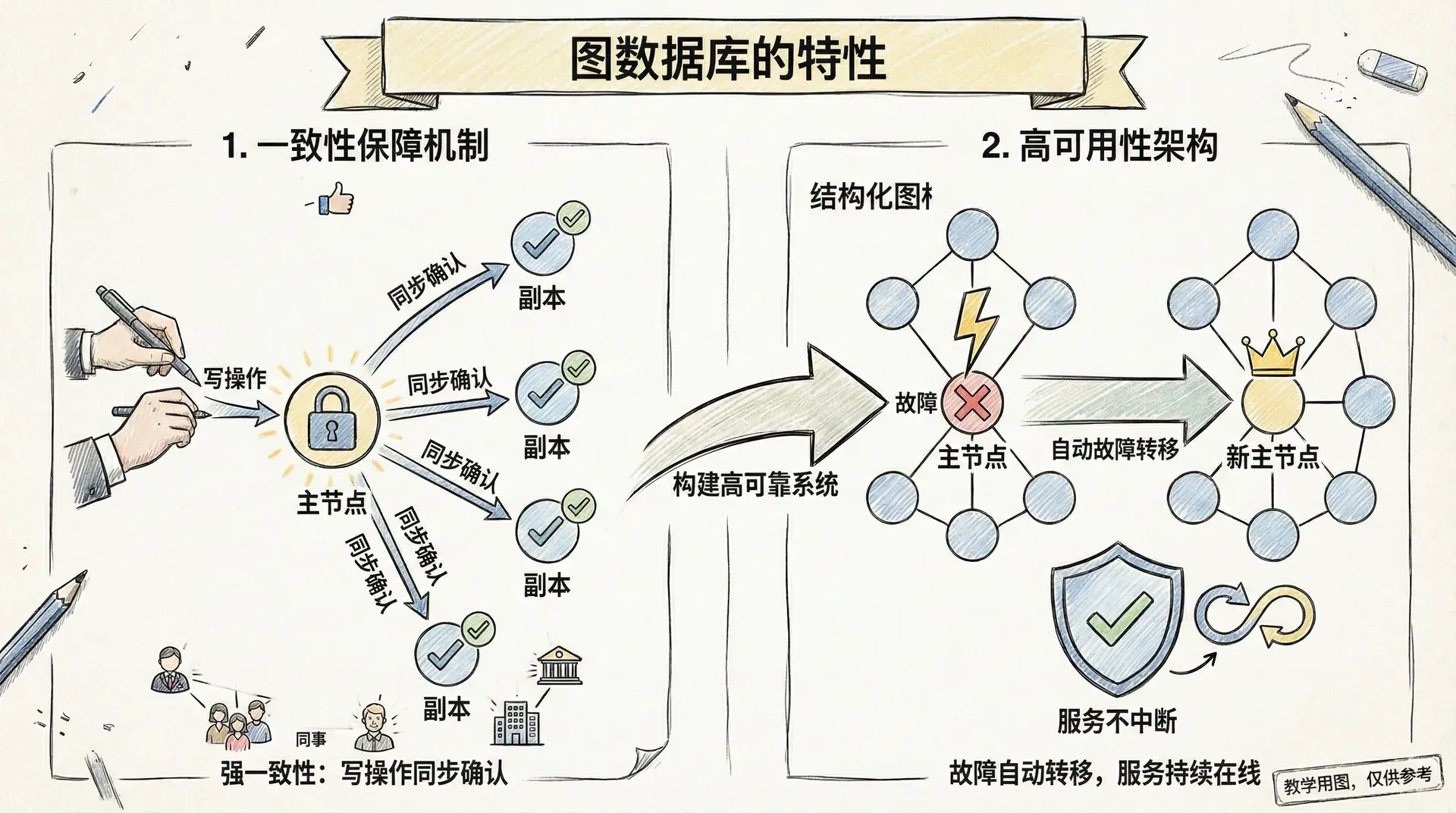
一致性保障机制
图数据库对数据一致性和完整性具有严格的保障机制。所有边(关系)均要求其起始节点(起点)和目标节点(终点)真实存在,杜绝「悬挂」关系,从结构上保障了数据的有效性和准确性。
以 Neo4j 为代表的主流图数据库,所有写入与更新操作都在 ACID 事务(原子性、一致性、隔离性、持久性)包裹下执行,确保整个操作过程中要么全部成功提交,要么在发生异常时完全回滚,从而避免任何中间状态导致的数据不一致问题。
javascript
// Neo4j事务示例
const session = driver.session();
const transaction = session.beginTransaction();
try {
// 创建用户节点
const userResult = await transaction.run(`
CREATE (u:用户 {
姓名: $name,
邮箱: $email,
注册时间: datetime()
})
RETURN u
`, { name: '李明', email: 'liming@example.com' });
高可用性架构
现代图数据库通常采用主从(主备)复制架构以实现高可用性。主节点(Master)负责所有写操作的处理与数据一致性保证,从节点(Slave/Replica)承担只读负载并实时同步主节点数据。当主节点发生故障时,系统会通过分布式选举算法自动切换新的主节点,保障集群的业务连续性与对外服务的高可用。
强大的查询能力
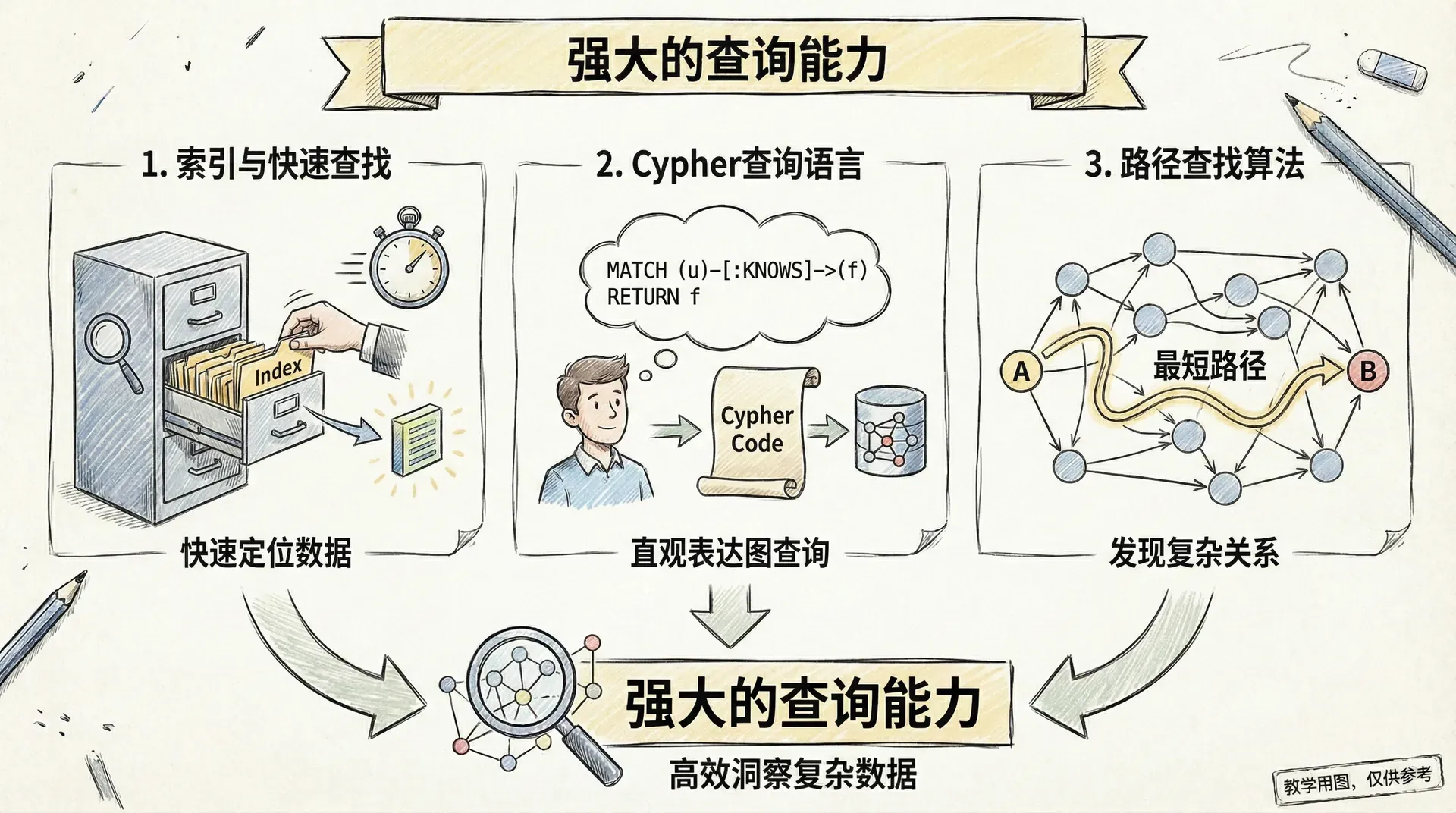
索引与快速查找
图数据库具备高效的索引机制,可显著提升节点和关系的检索速度。通过为关键属性(如唯一标识、姓名、邮箱等)建立索引,能够在大规模数据集中实现毫秒级的定位与访问,极大优化查询性能与系统吞吐能力。
javascript
// 为用户节点创建索引
await session.run('CREATE INDEX ON :用户(姓名)');
await session.run('CREATE INDEX ON :用户(邮箱)');
// 通过索引快速查找用户
const result = await session.run(`
MATCH (u:用户 {姓名: '张小明'})
RETURN u
`);Cypher查询语言
Cypher 是 Neo4j 所采用的声明式图查询语言,其语法设计高度贴合图结构的数据建模方式,使得复杂的关系型查询表达简洁明了,具有极强的可读性与可维护性。以下展示若干典型使用场景:
cypher
-- 找到张小明的所有朋友
MATCH (张小明:用户 {姓名: '张小明'})-[:朋友]->(朋友:用户)
RETURN 朋友.姓名
-- 找到张小明朋友的朋友(二度人脉)
MATCH (张小明:用户 {姓名: '张小明'})-[:朋友*2]->(朋友的朋友:用户)
WHERE 朋友的朋友 <> 张小明
RETURN DISTINCT 朋友的朋友.姓名
路径查找算法
路径查询是图数据库的核心优势之一。无论是社交网络中的「六度分隔理论」分析,还是交通与导航中的最短路径计算,图数据库均可高效、准确地完成相关查询与路径推断任务,展现出优异的性能与可扩展性。
javascript
// 找到两个用户之间的最短关系路径
const pathResult = await session.run(`
MATCH path = shortestPath((a:用户 {姓名: '张小明'})-[:朋友*..6]-(b:用户 {姓名: '李小华'}))
RETURN path, length(path) as 路径长度
`);
// 找到所有可能的路径
const allPathsResult = await session.run(`
MATCH path = (a:用户 {姓名: '张小明'})-[:朋友*..3]-(b:用户 {姓名: '李小华'})
RETURN path
ORDER BY length(path)
`);扩展性挑战与解决方案
由于图结构高度互联,节点和关系的分布特性导致传统的水平分片方法难以直接应用。节点间频繁的跨分片遍历将显著增加网络通信与查询延迟,严重影响整体系统性能及可扩展性。
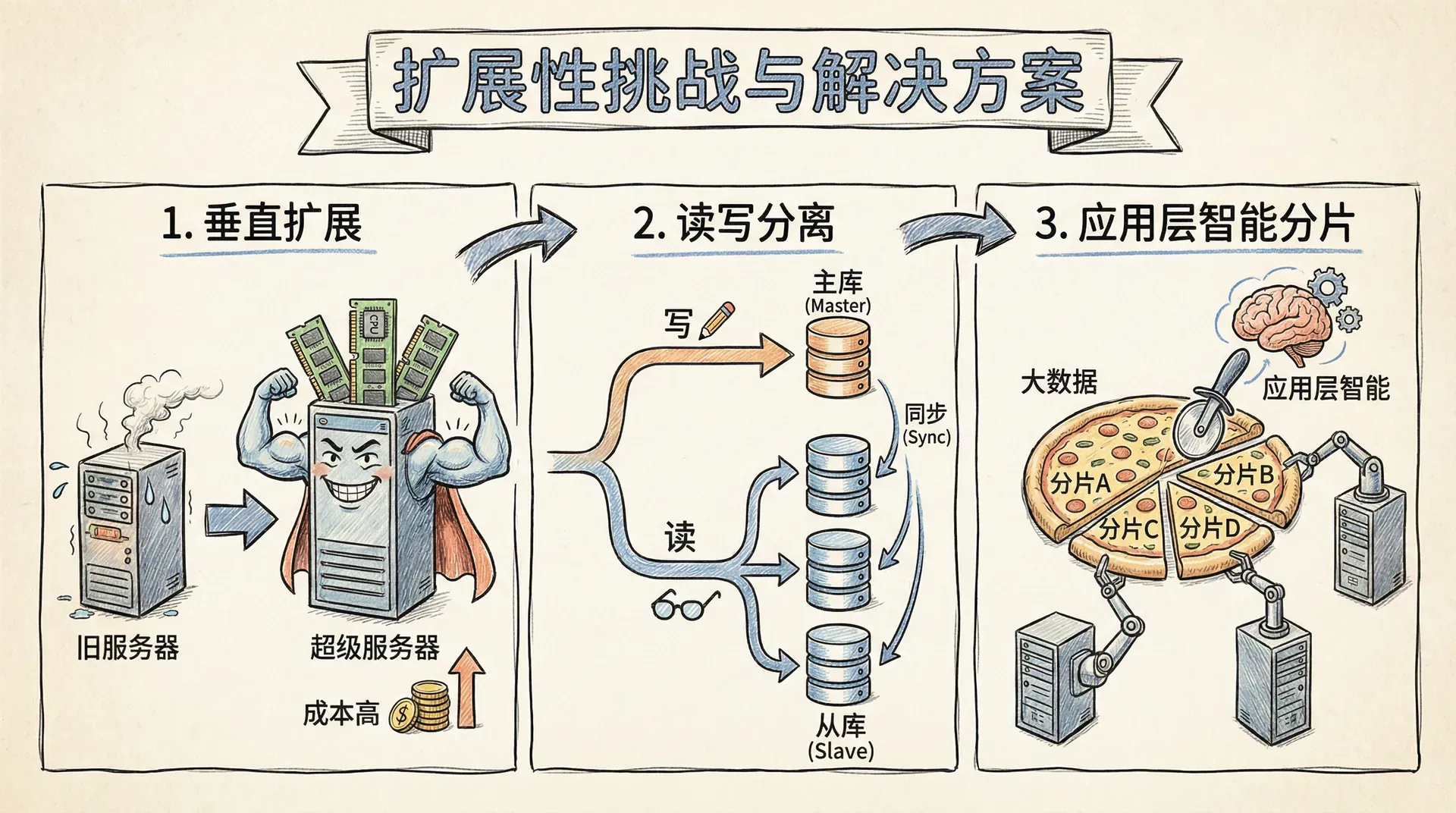
垂直扩展
一种可行的扩展策略是提升单台服务器的硬件配置,尤其是内存容量。现代高性能服务器支持数百GB至TB级别内存,从而能够将整个图数据集载入内存,实现毫秒级的高性能图查询。但此种方式受限于单机硬件的天花板,适合于中小规模到中大型的数据场景。
读写分离
通过主从复制架构,将写操作集中于主节点、将读操作分发至多个只读从节点,可显著提升读取吞吐能力。此模式对于高并发、读多写少的应用场景效果显著,但写入性能仍受限于主节点,且复制延迟也需重点关注。
应用层智能分片
对于超大规模应用场景,需在应用层实现智能分片策略。以全球化社交网络为例,可依据地理区域或用户属性进行分布式数据分片,如将中国地区用户数据分配至亚洲区域集群、美国地区用户数据分配至北美区域集群,以实现地理隔离、数据本地化及跨区域负载均衡,从而提升系统的可扩展性和访问性能。
典型应用场景
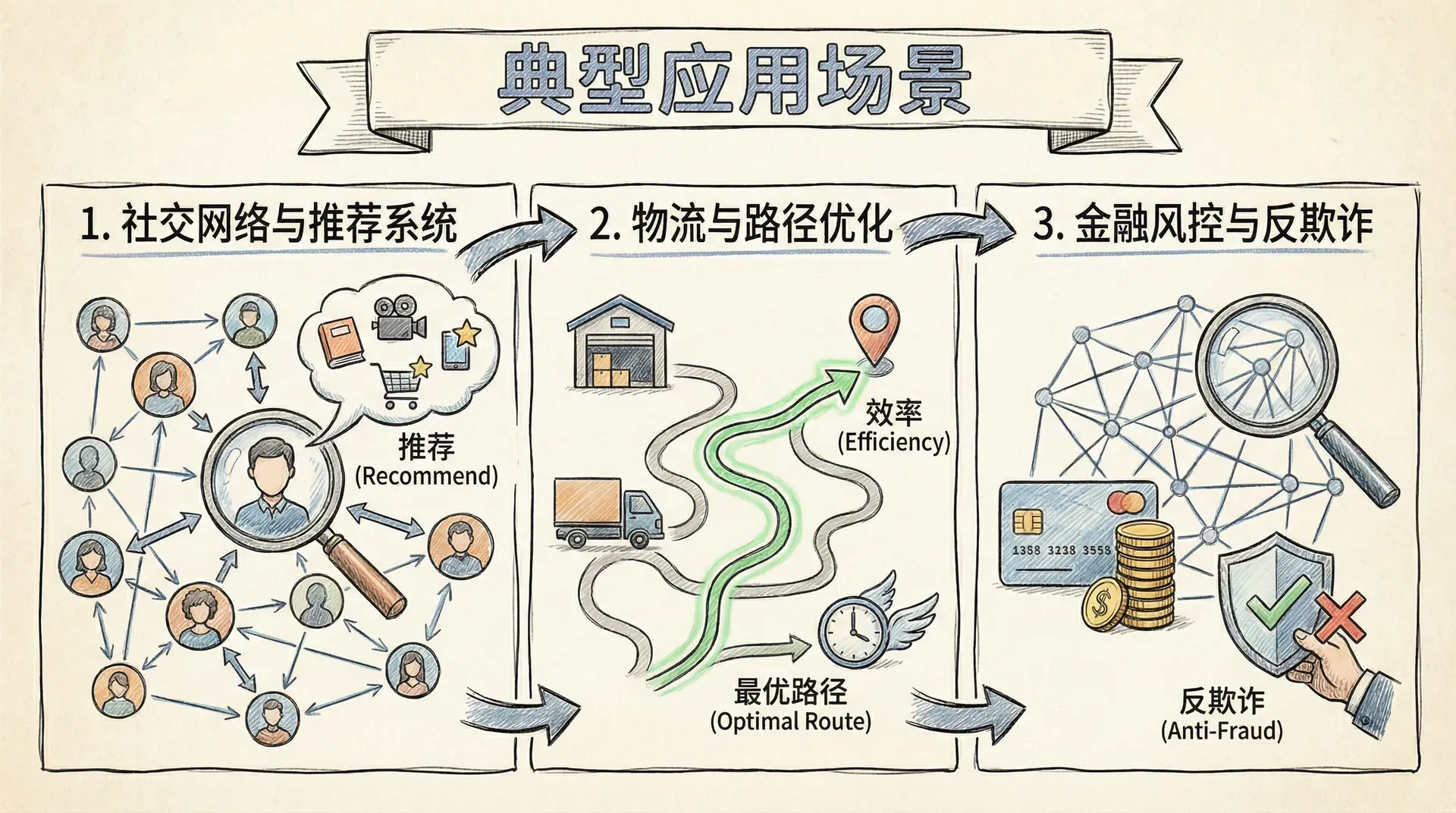
社交网络与推荐系统
社交网络与推荐系统是图数据库最具代表性的应用领域。无论是大规模用户之间的社交关系建模(如微博关注、好友点赞等),还是电商平台中基于用户行为和商品关联的推荐引擎,图数据库凭借其高效的关系遍历能力,为复杂网络结构的数据分析与实时推荐提供了核心技术支撑。
以电商推荐系统为例,我们可以采用如下的图建模与查询方式:
cypher
-- 协同过滤推荐:找到相似用户喜欢的商品
MATCH (目标用户:用户 {ID: $userId})-[:购买]->(商品:商品)<-[:购买]-(相似用户:用户)
MATCH (相似用户)-[:购买]->(推荐商品:商品)
WHERE NOT (目标用户)-[:购买]->(推荐商品)
RETURN 推荐商品.名称, COUNT(相似用户) as
物流与路径优化
在现代物流网络中,配送点建模为图中的节点,节点之间的道路以带权边的形式表示,权重可包括距离、通行时间、交通状况等多维度属性。利用图数据库,可以实现高效的路径优化、运输调度、实时路由调整等复杂物流业务需求:
cypher
-- 找到从仓库到客户的最短配送路径
MATCH path = shortestPath((仓库:配送点 {名称: '北京总仓'})-[:道路*]-(目标:配送点 {名称: '朝阳区配送站'}))
RETURN path,
reduce(总距离 = 0, rel in relationships(path) | 总距离 + rel.距离) as 总配送距离金融风控与反欺诈
在金融领域,图数据库凭借其强大的关系建模与高效的关联分析能力,可用于揭示复杂金融交易网络中的隐性关联关系,及时识别潜在风险与异常行为,提升反欺诈和风控的精准性与实时性。
cypher
-- 检测可疑的资金流向网络
MATCH (可疑账户:账户)-[:转账*2..5]->(关联账户:账户)
WHERE 可疑账户.风险等级 = '高'
AND ALL(rel IN relationships(path) WHERE rel.金额 > 10000)
RETURN DISTINCT 关联账户.账号, 关联账户.持有人图数据库并非万能钥匙。在某些场景下,传统的关系数据库或其他NoSQL数据库可能是更好的选择。
小结
图数据库以其卓越的关系建模与高效的关联查询能力,为复杂关系型数据的管理与分析提供了全新技术路径。 相较于传统表格结构,图数据库将数据映射为节点和边,更加贴合现实世界中的网络关联,使路径搜索、图遍历等复杂操作得以高效实现,从而推动了数据认知范式由“表式思维”向“网络思维”的转变。
在系统选型时,应充分结合具体业务需求与场景特征。如果系统核心诉求为多元实体之间的复杂关系建模、高效路径分析或实时推荐等,则图数据库表现出明显优势。 而针对以简单数据存取、频繁批量处理为主的场景,传统关系型数据库或批处理型数据仓库可能更为合适。最终,数据架构的选择需以业务价值和可扩展性为导向,合理发挥图数据库在建模现实世界复杂关系网络中的独特价值。