初识文件系统
文件系统是操作系统提供的抽象层,用于管理存储设备上的数据组织、存储和访问。它为用户和应用程序提供了统一的接口,屏蔽了底层存储设备的物理特性差异,使得数据可以按照逻辑结构进行组织和管理。
文件是文件系统中的基本存储单元,是命名数据的逻辑集合。从操作系统的角度来看,文件是字节序列的抽象表示,这些字节序列存储在物理存储介质上,如硬盘、固态硬盘或可移动存储设备。文件系统通过文件名和路径来标识和定位文件,使得用户和程序可以通过逻辑名称访问物理存储上的数据。
文件这个概念非常灵活,它可以是任何形式的数据:程序代码、文本文档、图片、音频,甚至是系统配置信息。操作系统并不关心文件里面具体是什么内容,它只负责提供统一的存储和管理机制。

文件
每个文件都包含一组元数据(metadata),这些元数据描述了文件的各种属性和特征。文件系统通过维护这些元数据来实现对文件的管理和控制。常见的文件属性包括:
文件名是用户可见的文件标识符,通常由主文件名和扩展名组成,扩展名用于指示文件类型。唯一标识符是文件系统内部使用的数字标识,在类Unix系统中通常称为inode号,操作系统通过这个标识符来唯一区分文件系统中的每个文件。文件位置信息记录了文件数据在存储设备上的物理位置,可能包括起始块号、块分配表等。文件大小属性记录了文件占用的字节数,这是文件系统进行空间分配和管理的依据。保护信息定义了文件的访问控制权限,包括读取、写入和执行权限,以及文件所有者、所属组和其他用户的权限设置。时间戳包括文件的创建时间、最后修改时间和最后访问时间,这些信息用于文件版本管理和缓存策略。
这些元数据共同构成了文件的完整描述,使得文件系统能够高效地管理、定位和保护文件。
文件的常见操作
文件系统提供了一组标准的文件操作原语,这些操作通过系统调用接口提供给应用程序。基本的文件操作包括创建文件、打开文件、读取文件、写入文件、关闭文件和删除文件。创建文件操作会在存储设备上分配必要的存储空间,并在目录结构中创建相应的目录项,同时初始化文件的元数据。打开文件操作会验证文件的存在性和访问权限,如果验证通过,系统会分配一个文件描述符(file descriptor)或文件句柄(file handle)返回给调用进程,这个描述符用于后续的文件操作。
读取文件操作通过文件描述符从存储设备读取数据到内存缓冲区,系统会根据文件指针的当前位置确定读取的起始位置。写入操作则将内存缓冲区中的数据写入到存储设备,同样基于文件指针的位置。关闭文件操作会释放文件描述符,刷新缓冲区,并更新文件的元数据,如最后修改时间。
文件操作中有一个重要的概念叫"文件指针"(file pointer)或"文件偏移量"(file offset)。文件指针是一个整数,表示当前读写操作在文件中的位置,以字节为单位从文件开头计算。每次读取或写入操作后,文件指针会自动向前移动相应的字节数。应用程序可以通过系统调用(如lseek)显式地修改文件指针的位置,实现随机访问。
下面是一个简单的文件操作流程图:
在实际编程中,文件操作通过系统调用接口完成。标准C库提供了文件操作的封装函数,底层最终会调用操作系统的系统调用。下面的示例展示了基本的文件操作流程:
c
#include <stdio.h>
int main() {
// 调用fopen打开文件,底层会执行open系统调用
// "r"模式表示以只读方式打开文件
FILE *file = fopen("example.txt", "r");
if (file == NULL) {
printf("无法打开文件\n");
return 1;
}
// 使用fgets按行读取文件内容
// 每次读取会更新文件指针的位置
char buffer[100];
文件的类型
文件类型可以通过多种方式识别。文件扩展名是用户层面的类型标识,如".txt"表示文本文件,".jpg"表示JPEG图像文件,但扩展名可以被任意修改,因此不是可靠的类型判断依据。文件内容结构因类型而异,文本文件包含可读的字符序列,而可执行文件遵循特定的二进制格式规范,如ELF(Executable and Linkable Format)或PE(Portable Executable)格式。
更可靠的文件类型识别方法是检查文件的魔数(magic number),这是存储在文件开头的特定字节序列,用于标识文件格式。操作系统和应用程序可以通过读取文件的前几个字节来判断文件的实际类型,这种方法比依赖文件扩展名更加准确和可靠。
文件的内部结构
在物理存储设备上,文件数据被组织成固定大小的块(block)或簇(cluster)进行存储。文件系统负责管理这些存储块的分配和映射关系。一个文件可能占据多个不连续的存储块,文件系统通过维护块分配表或使用链表结构来记录文件的所有块的位置,从而将分散的存储块逻辑上组织成连续的文件。
文件系统抽象层隐藏了这种物理存储的分散性,向用户和应用程序呈现的是逻辑上连续的文件视图。当应用程序读取文件时,文件系统会根据文件指针和块映射关系,自动定位并读取相应的物理块,这个过程对上层应用是透明的。
访问方法
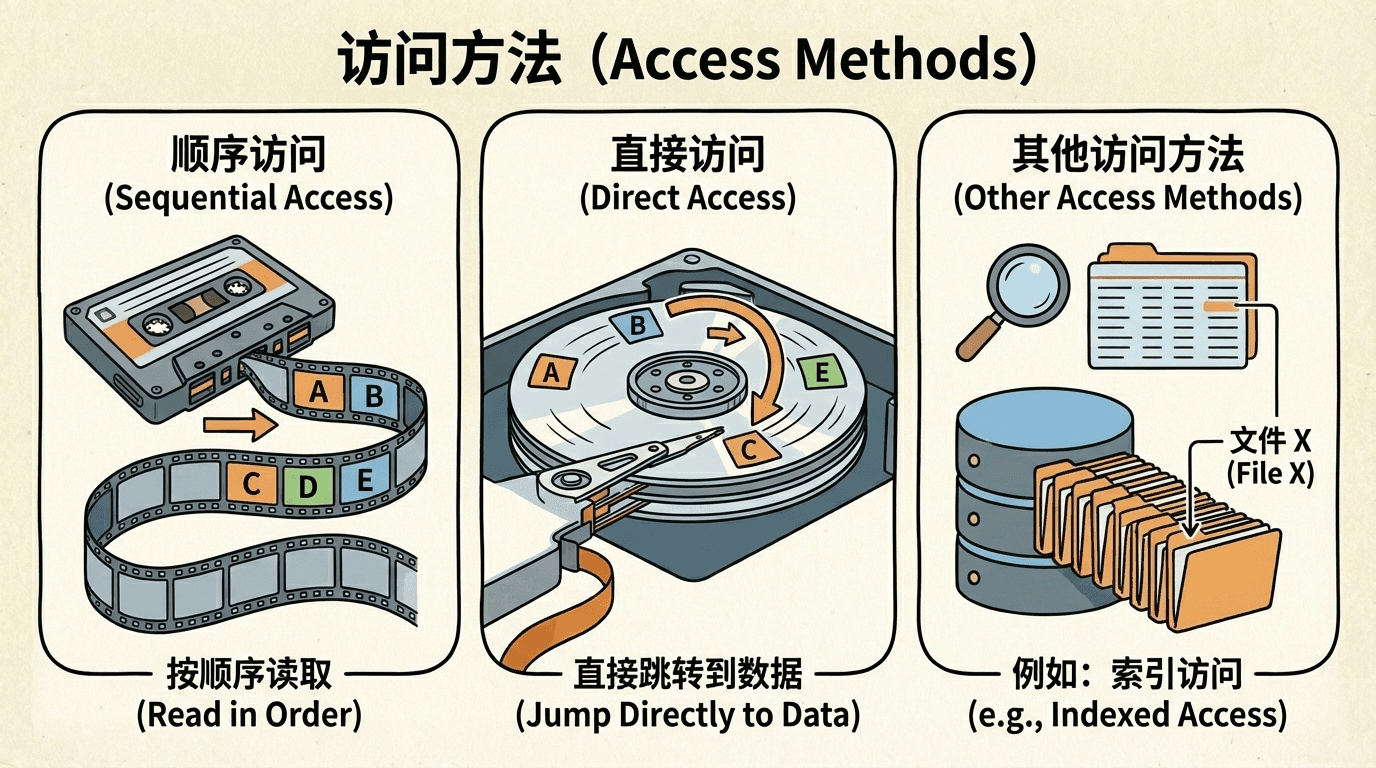
顺序访问
顺序访问(sequential access)是一种线性的文件访问模式,数据必须按照存储顺序依次读取或写入,不能直接跳转到文件的任意位置。在这种模式下,文件指针只能向前移动,每次读写操作都会自动更新文件指针的位置。顺序访问的实现简单高效,特别适合流式数据处理场景,如文本编辑器、日志文件处理等应用。
顺序访问的文件系统通常使用链表结构来组织存储块,每个块包含指向下一个块的指针。这种结构使得顺序读取非常高效,但随机访问需要从头遍历到目标位置,性能较差。
直接访问
直接访问(direct access)或随机访问(random access)允许程序直接跳转到文件的任意位置进行读写操作,而不需要从文件开头顺序遍历。文件被视为固定大小的逻辑记录序列,每个记录可以通过记录号直接定位。直接访问通过计算目标位置的偏移量,然后使用文件指针定位操作来实现。
直接访问文件系统通常使用索引结构或计算方式来确定存储块的位置,使得随机访问的时间复杂度可以达到O(1)或O(log n)。数据库管理系统、文件系统索引等应用广泛使用直接访问模式,因为它们需要快速定位和修改文件中的特定数据块。
其他访问方法
索引访问(indexed access)是一种基于索引结构的访问方法,通过维护额外的索引表来加速数据定位。索引表将逻辑键(如学号、主键)映射到文件中的物理位置,类似于数据库的B树或哈希索引结构。当需要访问特定记录时,系统首先在索引表中查找对应的物理位置,然后直接定位到该位置进行读写操作。
索引访问在需要频繁按非顺序键值查找数据的场景中非常有效,如学生信息管理系统、商品目录等应用。虽然索引访问需要额外的存储空间和维护开销,但它显著提高了查找效率,将平均查找时间从O(n)降低到O(log n)或O(1)。
目录结构
目录(directory)是文件系统中用于组织文件的逻辑容器,它本身也是一种特殊的文件,包含指向其他文件或子目录的目录项(directory entry)。目录结构提供了层次化的文件组织方式,使得文件可以通过路径名(pathname)进行唯一标识和访问。没有目录结构,所有文件将处于同一命名空间,在多用户环境中会导致文件名冲突和管理困难。
单级目录
单级目录结构是最简单的目录组织形式,所有文件都位于同一个根目录下,没有子目录层次。这种结构的实现简单,文件查找直接,但存在明显的局限性:在多用户环境中,不同用户可能使用相同的文件名,导致命名冲突;随着文件数量增加,目录项列表会变得很长,影响查找效率;无法按逻辑关系组织文件,缺乏分类管理能力。
两级目录
两级目录结构引入了主文件目录(Master File Directory, MFD)和用户文件目录(User File Directory, UFD)的层次。MFD为每个用户维护一个指向其UFD的条目,每个用户的文件都存储在自己的UFD中。这种结构解决了单级目录中的文件名冲突问题,每个用户拥有独立的命名空间,可以在自己的目录中使用任意文件名而不与其他用户冲突。
两级目录结构在多用户操作系统中提供了基本的用户隔离,但灵活性仍然有限,用户无法创建子目录来进一步组织文件。
树形目录
树形目录结构允许创建任意深度的目录层次,形成树状的目录组织。每个目录可以包含文件和子目录,子目录又可以包含自己的文件和子目录,形成递归的层次结构。在树形目录中,从根目录到任意文件或目录的路径是唯一的,通过绝对路径(从根目录开始)或相对路径(从当前工作目录开始)可以唯一标识任何文件。
树形目录结构提供了最大的组织灵活性,用户可以根据项目、类型、时间等维度创建目录层次来组织文件。现代操作系统如Unix、Linux、Windows都采用树形目录结构,其中Unix/Linux系统使用单一的根目录"/",而Windows系统为每个存储设备分配一个根目录(如C:\、D:\)。
图结构目录
图结构目录允许文件和目录在目录树中的多个位置出现,通过硬链接(hard link)或符号链接(symbolic link)实现。硬链接是文件系统中指向同一inode的多个目录项,所有硬链接共享相同的文件数据和元数据,删除一个硬链接不会影响文件本身,只有当所有硬链接都被删除时,文件才会被真正删除。符号链接是包含目标路径的特殊文件,当访问符号链接时,系统会重定向到目标路径。
图结构目录提供了文件共享和灵活组织的机制,但增加了管理复杂性。文件系统需要维护引用计数来跟踪指向同一文件的链接数量,确保文件在所有引用被删除前不会被错误释放。循环引用检测也是图结构目录需要处理的重要问题。
在图结构目录中,同一个文件可以通过多个路径名访问。对于硬链接,删除一个目录项只是减少了文件的引用计数,文件的实际数据仍然存在,直到所有硬链接都被删除且引用计数降为零时,文件系统才会回收存储空间。对于符号链接,删除符号链接文件本身不会影响目标文件,但如果删除目标文件,符号链接就会变成悬空引用(dangling reference)。
文件保护
在多用户操作系统中,文件保护机制确保只有授权用户才能访问和修改文件,防止未授权的访问、修改或删除操作。文件保护通过访问控制机制实现,包括访问控制列表、权限位、能力列表等多种方式。
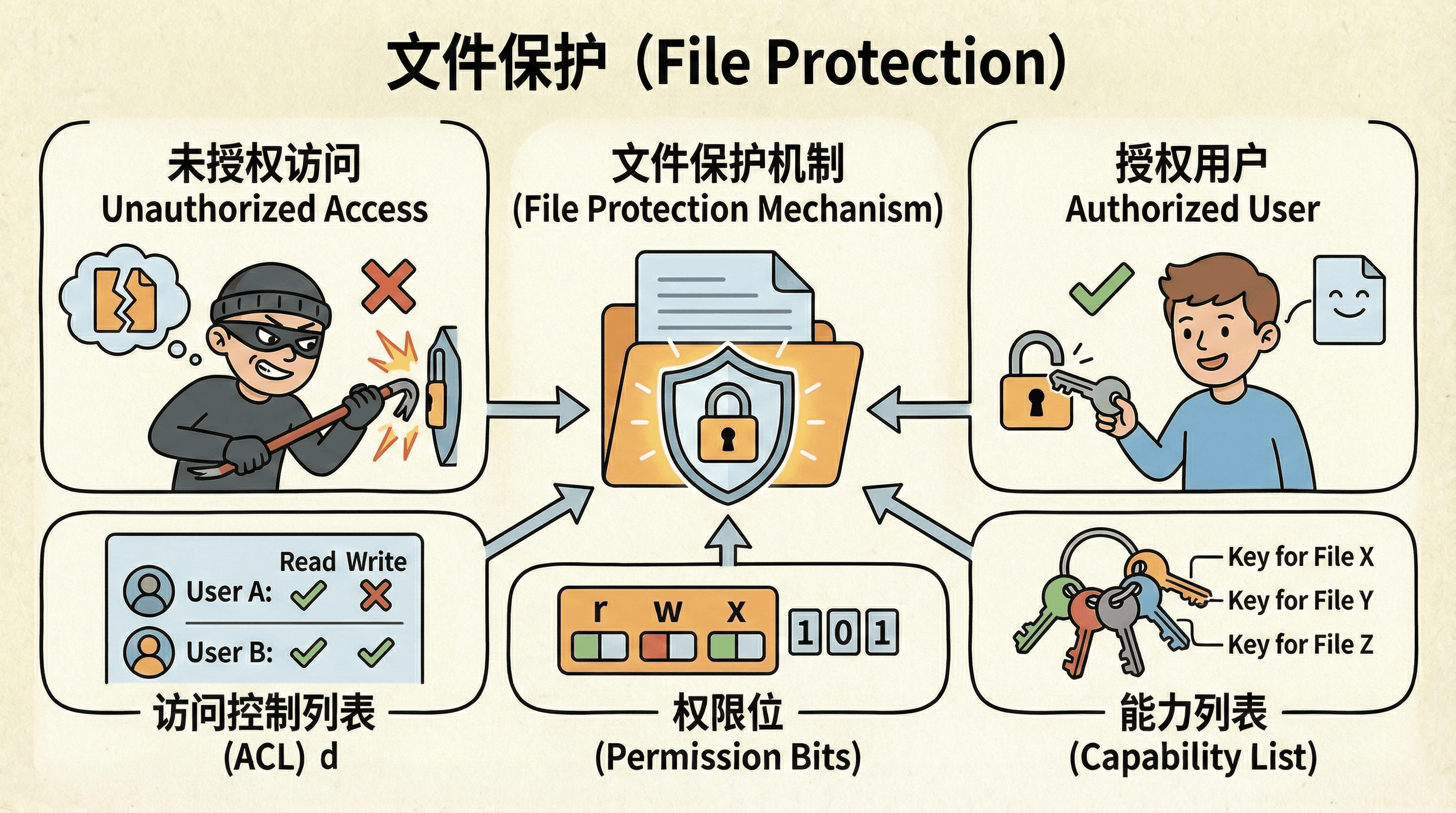
访问控制
访问控制列表(Access Control List, ACL)是最常见的文件保护机制。每个文件维护一个ACL,其中记录了用户或用户组对该文件的访问权限。权限通常包括读取(read)、写入(write)和执行(execute)三种基本权限。当进程请求访问文件时,操作系统会检查进程的有效用户ID和组ID,查找ACL中对应的权限条目,只有权限检查通过才允许执行相应的操作。
在UNIX/Linux系统中,文件权限采用简化的访问控制模型,使用9位权限位(permission bits)来表示三类用户(所有者owner、所属组group、其他用户others)的三种权限(读取read、写入write、执行execute)。权限位可以用三组rwx字符表示,也可以用八进制数字表示(如755表示rwxr-xr-x)。
下面是一个查看文件权限的Linux命令示例:
shell
$ ls -l myfile.txt
-rw-r--r-- 1 user group 1024 Jan 15 10:30 myfile.txt命令输出解析:第一个字符-表示文件类型(-为普通文件,d为目录,l为符号链接);接下来的9个字符rw-r--r--表示权限位,分为三组,每组三位;数字1表示硬链接计数;user是文件所有者的用户名;group是文件所属组的组名;1024是文件大小(字节);Jan 15 10:30是最后修改时间戳;myfile.txt是文件名。
其他保护方法
除了基于ACL的访问控制,文件系统还支持其他保护机制。文件级加密可以对文件内容进行加密存储,即使攻击者获得了文件访问权限,没有解密密钥也无法读取文件内容。现代文件系统如NTFS、ext4等支持透明加密功能,可以在文件系统层面自动加密和解密文件。
能力列表(capability list)是另一种访问控制模型,它将权限与进程关联而不是与文件关联,进程持有访问特定资源的"能力",只有具备相应能力的进程才能访问文件。这种模型提供了更细粒度的访问控制,但实现和管理复杂度较高。在实际系统中,通常结合多种保护机制来提供分层的安全防护。
文件保护机制涵盖了机密性(防止未授权访问)、完整性(防止未授权修改)和可用性(确保授权用户能够访问)三个安全目标。现代操作系统通常采用纵深防御策略,结合访问控制、加密、审计日志、备份恢复等多种机制来构建完整的文件系统安全体系。
内存映射文件
内存映射文件(memory-mapped file)是一种将文件内容映射到进程虚拟地址空间的技术,使得文件数据可以直接通过内存访问指令进行读写,而不需要显式的read/write系统调用。当进程访问映射的内存区域时,操作系统通过虚拟内存管理机制和页错误(page fault)处理,按需将文件块加载到物理内存中。
内存映射文件利用了操作系统的虚拟内存系统和按需分页(demand paging)机制。文件被映射到进程的虚拟地址空间后,文件数据与虚拟内存页面建立对应关系。当进程访问某个虚拟地址时,如果对应的页面尚未加载到内存,处理器会触发页错误,操作系统捕获该错误后,从文件中读取相应的数据块到物理内存,然后更新页表,最后恢复进程执行。这种延迟加载(lazy loading)策略使得大文件的映射不会立即消耗大量内存,只有实际访问的部分才会被加载。
内存映射文件特别适合需要频繁随机访问文件内容的应用场景。数据库管理系统使用内存映射来高效访问数据文件和索引文件,避免了频繁的系统调用开销。多媒体播放器通过内存映射来流式读取大型媒体文件,操作系统会自动管理内存缓存,提供平滑的播放体验。内存映射还支持写时复制(copy-on-write)机制,多个进程可以共享只读映射,提高内存利用效率。
在Java中,我们可以使用NIO(New I/O)包提供的FileChannel和MappedByteBuffer来实现内存映射文件:
java
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
public class MemoryMappedFileExample {
public static void main(String[] args) throws IOException {
// 创建RandomAccessFile以支持读写模式
RandomAccessFile file = new RandomAccessFile("largefile.dat", "rw");
// 获取文件通道,用于底层文件操作
FileChannel channel
在Windows API中,内存映射文件通过CreateFileMapping和MapViewOfFile函数实现:
c
#include <windows.h>
#include <stdio.h>
int main() {
HANDLE hFile, hMapFile;
LPVOID lpMapAddress;
// CreateFile打开或创建文件,返回文件句柄
// GENERIC_READ | GENERIC_WRITE指定读写权限
// OPEN_ALWAYS表示文件不存在时创建,存在时打开
hFile = CreateFile("data.bin", GENERIC_READ | GENERIC_WRITE, 0, NULL,
OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
// CreateFileMapping创建文件映射对象
// PAGE_READWRITE指定页面保护属性为可读写
// 参数0,0表示映射整个文件(使用文件当前大小)
hMapFile = CreateFileMapping(hFile,
内存映射文件还支持进程间通信(IPC)。当多个进程映射同一个文件时,它们共享相同的物理内存页面,一个进程对映射区域的修改会立即反映到其他进程的视图中,实现了高效的共享内存通信。这种机制避免了传统IPC方法(如管道、消息队列)的数据拷贝开销,特别适合需要高性能数据共享的场景,如数据库系统的共享缓冲区、多进程协作应用等。
文件锁
在多进程或多线程环境中,当多个进程同时访问同一个文件时,可能会出现竞态条件(race condition),导致数据不一致或损坏。文件锁(file locking)机制通过协调进程对文件的访问顺序来解决这个问题,确保在任意时刻只有一个进程可以对文件的特定区域进行写操作,或者多个进程可以同时进行读操作。
文件锁主要分为两种类型:共享锁(shared lock)或读锁(read lock)允许多个进程同时获取,适用于只读访问场景,多个进程可以并发读取文件而不会相互干扰;独占锁(exclusive lock)或写锁(write lock)是互斥的,同一时刻只能有一个进程持有,其他进程必须等待锁被释放,适用于需要修改文件内容的场景。
共享锁实现了多读单写(multiple readers, single writer)的并发控制模式。多个进程可以同时持有共享锁进行读取操作,提高了读操作的并发性能,但任何进程都无法在存在共享锁的情况下获取独占锁进行写入,从而保证了读取过程中数据不会被修改。独占锁实现了互斥访问,确保在写入操作期间,没有其他进程可以读取或写入文件,防止了数据竞争和不一致状态。
在Java中,我们可以使用FileChannel的文件锁功能来保护共享文件:
java
import java.io.*;
import java.nio.channels.*;
public class FileLockExample {
public static void main(String[] args) throws IOException {
// 创建RandomAccessFile以支持读写操作
RandomAccessFile file = new RandomAccessFile("shared.dat", "rw");
FileChannel channel = file.getChannel();
// lock()方法获取整个文件的独占锁
使用文件锁时需要特别小心。忘记释放锁会导致其他进程永久阻塞,形成死锁(deadlock)或活锁(livelock)情况。建议总是使用try-finally块或try-with-resources语句来确保锁能够被正确释放,即使在发生异常的情况下也能保证资源清理。另外,要注意文件锁的作用域,有些系统实现的是建议性锁(advisory lock),只对遵守锁协议的进程有效,不遵守的进程仍可能直接访问文件。
文件锁是保证数据一致性和并发控制的重要机制,特别是在多用户或多进程环境下处理共享文件时。通过合理使用文件锁,可以避免数据竞争、保证事务的原子性,并实现高效的并发文件访问。
小结
文件系统是操作系统的核心组件之一,它提供了数据存储、组织、访问和保护的完整机制。文件系统通过抽象层屏蔽了底层存储设备的物理特性,为用户和应用程序提供了统一的逻辑接口。
这部分我们学习了文件系统的基本概念和机制。文件作为基本的存储单元,通过元数据描述其属性和特征,支持多种访问模式包括顺序访问、直接访问和索引访问。目录结构提供了层次化的文件组织方式,从简单的单级目录到复杂的图结构目录,不同结构适用于不同的应用场景。 文件保护机制通过访问控制列表、权限位等机制确保数据的安全性和完整性。内存映射文件技术利用虚拟内存系统实现了高效的文件访问,特别适合大文件和频繁访问的场景。文件锁机制提供了并发控制能力,确保多进程环境下的数据一致性。
这些基础知识构成了理解文件系统工作原理的基础。接下来我们将学习文件系统的具体实现,包括存储空间管理、目录实现、文件分配方法等底层机制。
小练习
文件的常见属性包括哪些?
关于顺序访问,以下哪个描述是正确的?
关于树形目录结构,以下哪个描述是正确的?
关于硬链接,以下哪个描述是正确的?
关于文件权限,以下哪个描述是正确的?
关于内存映射文件,以下哪个描述是正确的?
关于文件锁,以下哪个描述是正确的?
关于索引访问,以下哪个描述是正确的?
1. 文件权限计算
假设一个文件的权限位为rwxr-xr--,请:
- 将权限位转换为八进制数字
- 说明三类用户(所有者、组、其他用户)分别拥有哪些权限
- 如果要将权限改为
rw-rw-r--,对应的八进制数字是多少?
2. 目录结构路径计算
假设一个文件系统的目录结构如下:
txt
/
├── home/
│ ├── user1/
│ │ ├── documents/
│ │ │ ├── report.txt
│ │ │ └── notes.txt
│ │ └── pictures/
│ │ └── photo.jpg
│ └── user2/
│ └── music/
│ └── song.mp3
└── etc/
└── config.conf请回答:
- 文件
report.txt的绝对路径是什么? - 如果当前工作目录是
/home/user1,访问documents/report.txt的相对路径是什么? - 如果当前工作目录是
/home/user1/documents,访问../pictures/photo.jpg的相对路径指向哪个文件? - 从
/home/user1到/home/user2/music的相对路径是什么?
3. 文件访问时间分析
假设一个文件系统使用顺序访问方式,文件被分成10个块,每个块大小为4KB。请计算:
- 如果要从文件开头顺序读取所有数据,需要多少次磁盘I/O操作?
- 如果要随机访问第5个块,需要多少次磁盘I/O操作?
- 如果使用直接访问方式,随机访问第5个块需要多少次磁盘I/O操作?
- 比较顺序访问和直接访问在随机访问场景下的效率差异
4. 内存映射文件效率分析
假设一个文件大小为100MB,系统页大小为4KB。请分析:
- 如果使用传统的read/write方式读取整个文件,需要多少次系统调用(假设每次读取1MB)?
- 如果使用内存映射文件方式,需要建立多少个虚拟页面映射?
- 如果只访问文件的前10MB,两种方式分别需要多少实际的内存占用?
- 比较两种方式在按需访问场景下的内存效率