存储
在计算机系统中,数据的持久化存储依赖于二级存储(Secondary Storage)或大容量存储(Mass Storage)设备。这些非易失性存储介质能够在断电后长期保存数据,构成了现代计算系统存储层次结构中的关键组成部分。
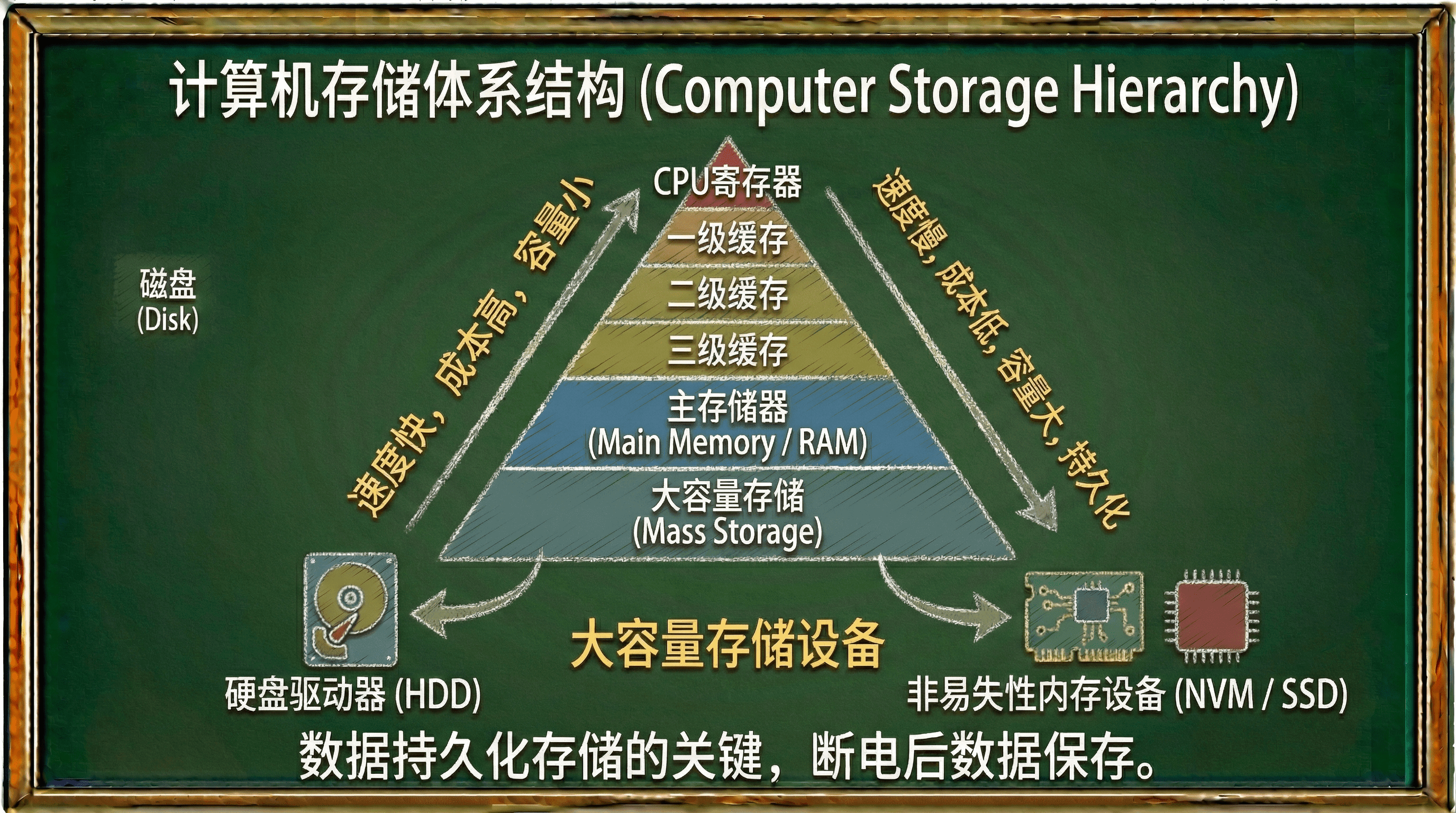
根据存储层次结构理论,计算机系统通常采用多级存储架构:一级存储(L1 Cache)、二级存储(L2 Cache)、三级存储(L3 Cache)、主存储器(RAM)以及大容量存储设备。大容量存储设备位于存储层次的最底层,虽然访问速度相对较慢,但具有容量大、成本低、数据持久化的特点。
在现代计算机系统中,最重要的两种大容量存储设备是硬盘驱动器(Hard Disk Drive, HDD)和非易失性内存设备(Non-Volatile Memory, NVM)。这两种设备在存储介质、访问机制、性能特征等方面存在显著差异,我们将在后续学习中再来详细探讨它们的技术原理和应用场景。
硬盘驱动器
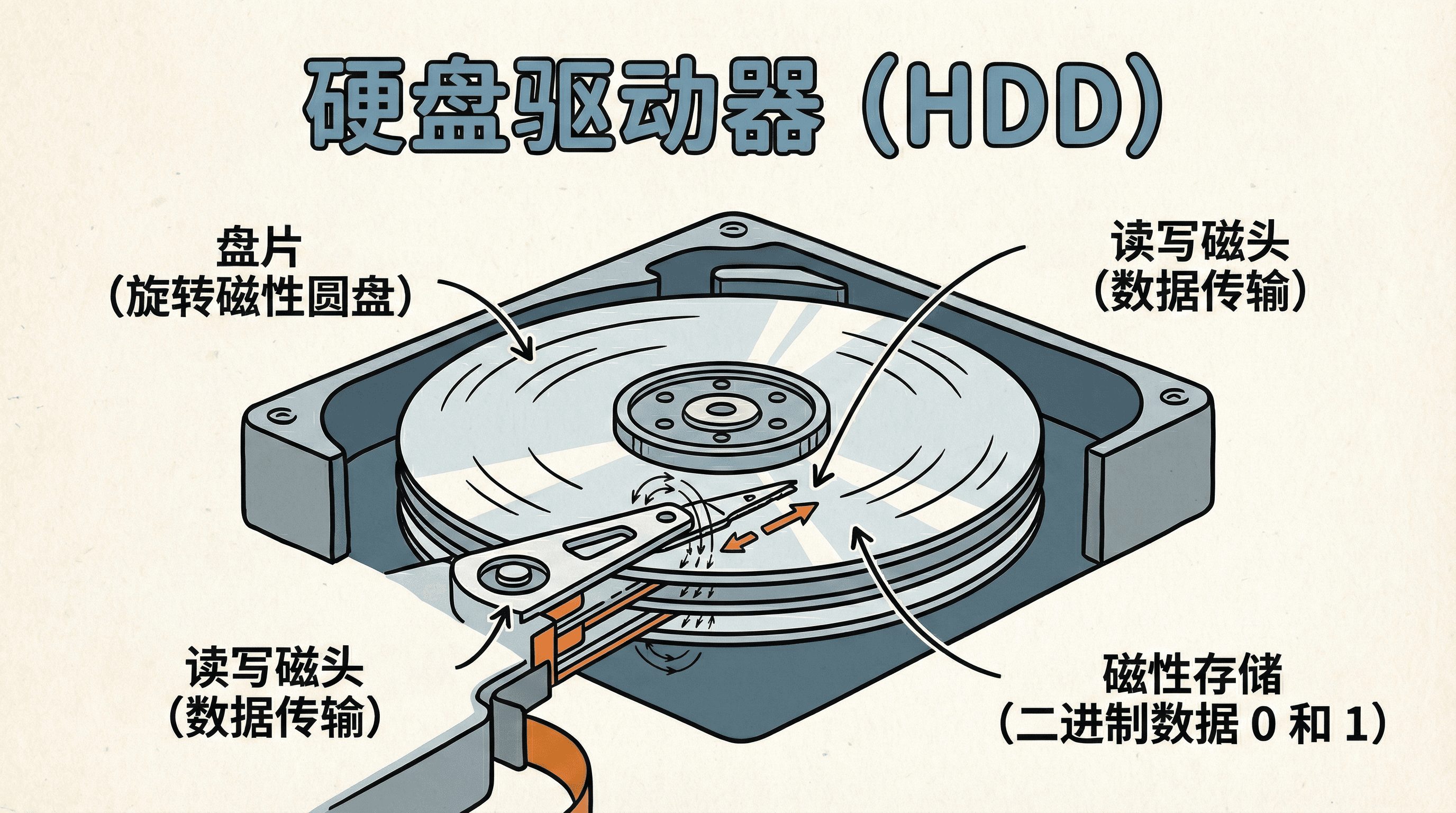
硬盘驱动器(Hard Disk Drive, HDD)是一种基于磁性存储技术的机械式存储设备。它利用磁记录原理,通过改变盘片表面磁性材料的磁化方向来存储二进制数据。HDD的核心工作原理是:在高速旋转的盘片表面,通过磁头产生的磁场改变磁性材料的磁化状态,实现数据的写入;通过检测磁性材料的磁化方向,实现数据的读取。
硬盘的内部构造
HDD的物理结构由多个关键组件构成。盘片(Platter)是存储数据的核心介质,通常由铝合金或玻璃基板制成,表面涂覆有磁性材料薄膜。现代HDD通常包含1到5个盘片,每个盘片有上下两个存储面。磁头(Head)是读写数据的执行部件,每个存储面都配备一个磁头,所有磁头通过音圈电机(Voice Coil Motor)驱动的磁头臂(Actuator Arm)实现同步移动。
盘片以恒定角速度(Constant Angular Velocity, CAV)旋转,转速通常为5400 RPM、7200 RPM、10000 RPM或15000 RPM。数据以同心圆的形式记录在盘片上,这些同心圆称为磁道(Track)。每个磁道被划分为若干个扇区(Sector),扇区是磁盘I/O操作的最小单位。传统扇区大小为512字节,现代高级格式化(Advanced Format)硬盘采用4KB扇区,以提高存储密度和纠错能力。所有盘片上相同半径的磁道组成一个柱面(Cylinder),柱面是数据组织的重要概念。
数据访问采用CHS寻址(Cylinder-Head-Sector Addressing)或LBA寻址(Logical Block Addressing)。CHS寻址通过柱面号、磁头号和扇区号唯一标识一个扇区;LBA则将整个磁盘视为连续的逻辑块序列,每个逻辑块对应一个唯一的线性地址。现代操作系统主要使用LBA寻址,由磁盘控制器负责LBA到CHS的转换。
硬盘的性能特点
HDD的性能主要受三个时间因素影响:寻道时间(Seek Time)、旋转延迟(Rotational Latency)和传输时间(Transfer Time)。寻道时间是指磁头从当前位置移动到目标磁道所需的时间,典型值在3-15毫秒之间,取决于磁头移动距离。旋转延迟是指等待目标扇区旋转到磁头下方所需的时间,平均旋转延迟等于盘片旋转半圈所需的时间,对于7200 RPM的硬盘约为4.17毫秒。传输时间是指实际读写数据所需的时间,取决于数据量和传输速率。
总访问时间(Total Access Time)可以表示为:
由于机械运动的限制,HDD的随机访问性能远低于顺序访问性能。随机I/O的IOPS(Input/Output Operations Per Second)通常在100-200之间,而顺序I/O的吞吐量可达100-200 MB/s。
硬盘最严重的故障是磁头碰撞(Head Crash),即磁头与盘片表面发生物理接触。这通常由剧烈震动、电源故障或制造缺陷引起,会导致盘片表面划伤、磁性材料脱落,造成数据永久性丢失。现代HDD采用自动磁头停放(Automatic Head Parking)技术,在断电或检测到异常时自动将磁头移动到安全区域,降低碰撞风险。
非易失性存储设备的革新
非易失性内存(Non-Volatile Memory, NVM)设备采用纯电子存储技术,不包含任何机械运动部件。最常见的NVM设备是固态硬盘(Solid State Drive, SSD),它基于NAND闪存技术实现数据存储。与HDD的磁性存储不同,NVM设备通过控制半导体器件中的电荷状态来存储数据,实现了更高的访问速度和更低的功耗。
NVM的工作原理
NAND闪存的核心存储单元是浮栅晶体管(Floating Gate Transistor)。每个存储单元包含一个控制栅(Control Gate)和一个浮栅(Floating Gate),浮栅被绝缘层包围,能够长期保持电荷。 数据存储通过Fowler-Nordheim隧穿效应或热电子注入将电子注入浮栅,或通过量子隧穿效应将电子从浮栅中移除,从而改变晶体管的阈值电压,实现不同数据状态的表示。
NAND闪存采用页(Page)和块(Block)的组织结构。页是读写操作的最小单位,通常为4KB、8KB或16KB;块是擦除操作的最小单位,通常包含64、128或256个页。 这种组织结构导致了写入放大(Write Amplification)问题:要更新一个页的数据,必须先擦除整个块,然后将有效数据和新数据一起写回。
NVM设备的性能优势主要体现在访问延迟上。由于没有机械运动,随机访问延迟可低至几十微秒,比HDD快两个数量级。顺序读取速度可达500-3500 MB/s,顺序写入速度可达300-3000 MB/s,随机读写IOPS可达数万到数十万。 这使得NVM设备特别适合需要低延迟、高IOPS的应用场景,如数据库、虚拟化、高性能计算等。
NVM设备面临的主要技术挑战包括:
- 写入前擦除限制(Erase-Before-Write),即不能直接覆盖数据,必须先擦除整个块;
- 磨损均衡(Wear Leveling),需要均匀分布擦写操作,避免某些块过早失效;
- 垃圾回收(Garbage Collection),需要定期整理数据,回收无效数据占用的空间;
- 写入放大,实际写入的数据量可能远大于逻辑写入量;
- 数据保持(Data Retention),电荷泄漏可能导致数据丢失,特别是在高温环境下;
存储设备的逻辑抽象
操作系统通过块设备接口(Block Device Interface)将各种存储设备的复杂物理结构抽象为统一的逻辑模型。这种抽象将存储设备视为一个连续的逻辑块数组(Logical Block Array), 每个逻辑块(Logical Block)具有固定大小(通常为512字节或4KB),并通过逻辑块地址(Logical Block Address, LBA)进行唯一标识。LBA是一个从0开始的线性地址空间,操作系统通过LBA访问数据,无需了解底层物理实现细节。
这种抽象设计的核心优势在于设备独立性(Device Independence)。应用程序和文件系统只需要与统一的块设备接口交互,无需关心底层是HDD的CHS寻址、NVM的页块结构,还是其他存储技术。 存储控制器负责将LBA映射到物理地址:对于HDD,控制器执行LBA到CHS的转换;对于NVM设备,闪存转换层(Flash Translation Layer, FTL)负责LBA到物理页地址的映射,同时处理磨损均衡、垃圾回收等复杂操作。
这种分层抽象架构实现了存储系统的 可移植性 和 可扩展性 。文件系统可以运行在任何支持块设备接口的存储设备上,而存储设备制造商可以在不影响上层软件的情况下优化底层实现。同时,这种抽象也带来了性能开销:每次I/O操作都需要经过多层转换,但现代存储控制器通过硬件加速和缓存技术将这种开销降至最低。
存储设备的抽象设计体现了计算机系统设计的核心原则:通过分层抽象隐藏复杂性,上层只需关注逻辑功能,下层负责物理实现。这种设计使得存储系统具有良好的可维护性和可扩展性,新的存储技术可以无缝集成到现有系统中。
硬盘调度算法
在多任务操作系统中,多个进程可能同时发起磁盘I/O请求,这些请求会进入操作系统的I/O请求队列(I/O Request Queue)。如果简单地按照请求到达的先后顺序(FIFO)处理,可能导致磁头频繁大幅度移动,显著降低磁盘性能。磁盘调度算法(Disk Scheduling Algorithm)通过优化I/O请求的处理顺序,最小化磁头移动距离和寻道时间,从而提高整体I/O吞吐量和系统响应速度。
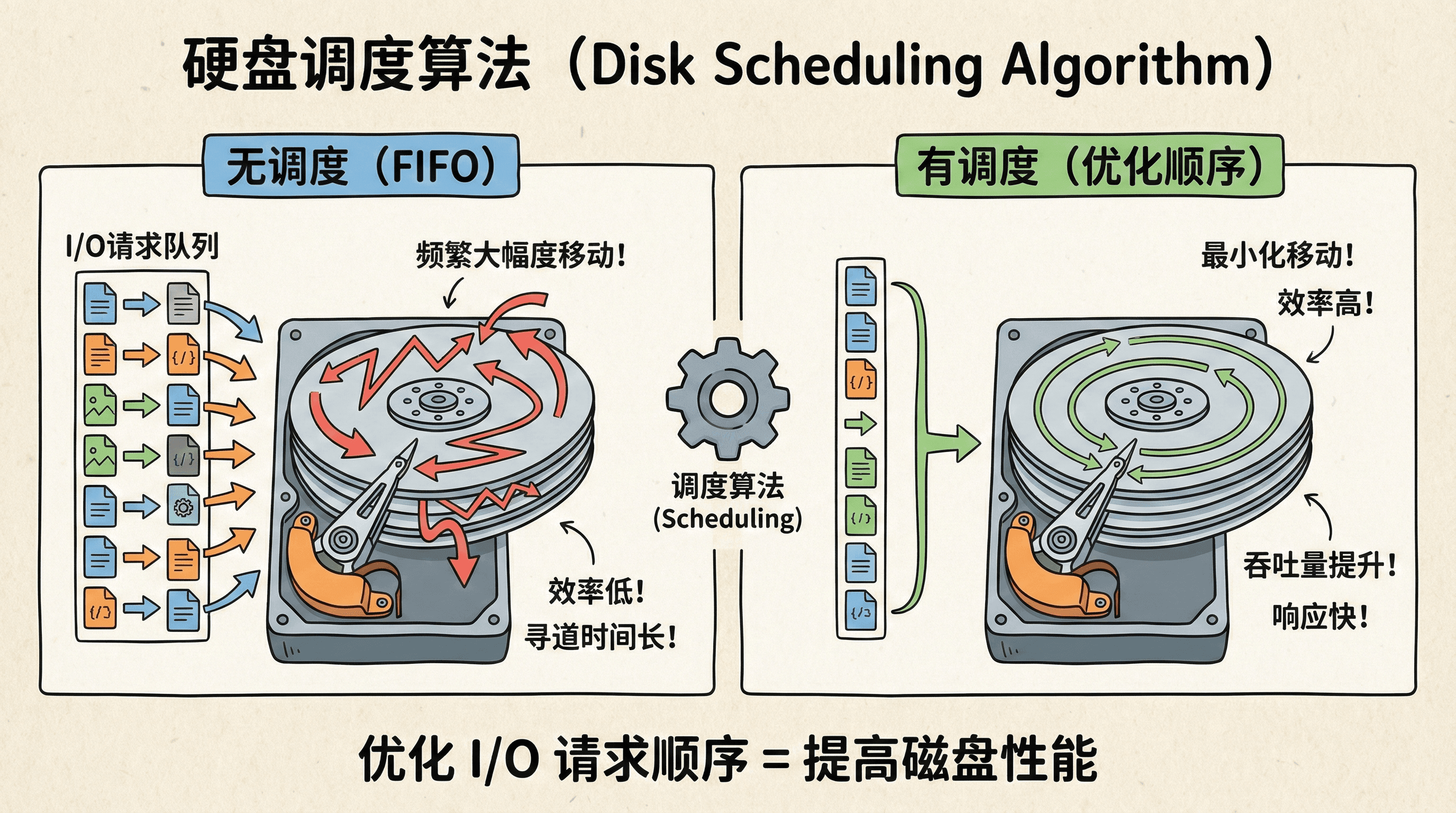
为什么需要调度算法?
磁盘调度算法的核心目标是优化寻道时间(Seek Time),因为寻道时间是HDD访问延迟的主要组成部分。假设磁头当前位于磁道100,待处理的请求分别位于磁道50、120和150。如果采用FIFO策略,处理顺序为50→120→150,磁头移动距离为|100-50|+|50-120|+|120-150|=50+70+30=150个磁道。如果优化为50→120→150的顺序(实际上与FIFO相同),或者采用其他策略如120→150→50,可以进一步减少磁头移动距离。
现代操作系统的I/O调度器(如Linux的CFQ、Deadline、Noop调度器)不仅考虑寻道优化,还兼顾公平性(Fairness)、延迟保证(Latency Guarantee)和吞吐量(Throughput)等多个目标。调度算法的选择需要根据工作负载特征进行权衡:顺序I/O密集型应用优先考虑吞吐量,随机I/O密集型应用优先考虑延迟,多用户环境需要保证公平性。
常见的调度算法
先来先服务(FCFS)
先来先服务(First-Come, First-Served, FCFS)是最简单的磁盘调度算法,它按照I/O请求到达的顺序依次处理,不进行任何优化。FCFS算法的时间复杂度为 ,实现开销极低,所有请求被公平对待,不会出现饥饿(Starvation)现象。
然而,FCFS算法忽略了磁头的当前位置,可能导致磁头抖动(Head Thrashing)。例如,如果请求序列为磁道98、183、37、122、14、124、65、67,磁头从53开始,总寻道距离为640个磁道。FCFS算法的平均寻道时间取决于请求序列的分布,在随机访问模式下性能较差。因此,FCFS主要用于请求到达率低、顺序访问占主导的场景,或者作为其他复杂算法的基准。
电梯算法(SCAN)
SCAN算法(也称为电梯算法,Elevator Algorithm)模拟电梯的运行方式:磁头从磁盘一端开始,沿一个方向移动,沿途处理所有请求,直到到达磁盘另一端,然后反向移动继续处理。SCAN算法将磁头移动限制在一个方向上,避免了磁头的频繁来回移动,显著减少了平均寻道时间。
SCAN算法的平均寻道时间约为磁盘总磁道数的三分之一,性能优于FCFS。然而,SCAN算法存在边缘请求延迟(Edge Request Latency)问题:位于磁盘边缘的请求可能需要等待磁头完成整个扫描周期才能被处理,最大等待时间可能达到两个完整的扫描周期。
C-SCAN算法(Circular SCAN)是SCAN的改进版本,解决了边缘延迟问题。C-SCAN算法在到达磁盘一端后,不立即反向,而是快速返回到起点,然后重新开始同方向扫描。这样,所有请求的最大等待时间被限制在一个扫描周期内,等待时间更加均匀。C-SCAN算法特别适合请求分布均匀、对延迟敏感的应用场景。
假设磁头当前位于磁道100,待处理请求为30、70、110、150、180。SCAN算法(假设向外圈移动)的处理顺序为110→150→180→70→30,总寻道距离为 个磁道。C-SCAN算法的处理顺序为110→150→180→30→70(快速返回后),总寻道距离可能略高,但等待时间更均匀。
调度算法实验
其他硬盘调度算法
最短寻道时间优先(Shortest Seek Time First, SSTF)算法每次选择距离当前磁头位置最近的请求,贪心地最小化每次寻道距离。SSTF算法的平均寻道时间优于FCFS,但存在严重的饥饿问题(Starvation Problem):如果不断有靠近磁头当前位置的新请求到达,距离较远的请求可能长期得不到服务。SSTF算法的时间复杂度为 ,需要维护请求队列并按距离排序。
LOOK算法和C-LOOK算法是对SCAN和C-SCAN的优化。LOOK算法不会移动到磁盘的最边缘,而是在有请求的最远磁道处立即反向,避免了无意义的边缘移动。C-LOOK算法在LOOK的基础上,处理完一个方向的所有请求后,直接跳回到最小请求位置,而不是返回到磁盘起点。这些优化进一步减少了无效的磁头移动,提高了调度效率。
现代操作系统的I/O调度器通常采用混合策略,结合多种算法的优点。例如,Linux的CFQ调度器(Completely Fair Queuing)为每个进程维护独立的请求队列,使用时间片轮转保证公平性,同时在每个队列内部使用SCAN算法优化寻道。Deadline调度器为每个请求设置截止时间,优先处理即将超时的请求,兼顾延迟和吞吐量。Noop调度器采用简单的FIFO策略,适用于NVM设备或上层已优化的场景。
不同的调度算法在不同的负载情况下表现不同。电梯算法在高负载时表现最好,而在低负载时可能不如简单算法。
NVM设备的调度特点
NVM设备与HDD在调度策略上存在根本性差异。由于NVM设备没有机械运动部件,不存在寻道时间和旋转延迟,因此不需要复杂的磁头移动优化算法。NVM设备的访问延迟主要由电子电路延迟(Electronic Circuit Latency)决定,通常在几十到几百微秒之间,比HDD的毫秒级延迟快两个数量级。
然而,NVM设备的调度并非简单的FCFS策略。现代NVM设备(特别是基于NVMe协议的SSD)具有独特的硬件特性,需要专门的调度优化:
- 读写性能不对称是NVM设备的重要特征。NAND闪存的读取延迟通常为25-100微秒,而写入延迟可达200-1500微秒,擦除延迟更是高达1-3毫秒。因此,调度器通常采用读取优先策略(Read Priority),优先处理读取请求以提升整体响应速度。同时,通过写入合并(Write Coalescing)将多个小写入请求合并为更大的写入操作,减少擦除次数,降低写入放大。
- 写入放大(Write Amplification, WA)是指实际写入闪存的数据量与逻辑写入数据量的比值。由于NAND闪存的擦除前写入限制,更新数据需要先擦除整个块,然后写入有效数据和新数据,导致WA通常大于1。垃圾回收(Garbage Collection, GC)是FTL的重要后台操作,负责回收无效数据占用的块。调度器需要平衡用户I/O和GC操作,避免GC影响前台性能。现代SSD控制器采用预留空间(Over-Provisioning)和后台GC策略,在空闲时进行垃圾回收,减少对用户I/O的影响。
- 磨损均衡(Wear Leveling)确保所有存储单元被均匀使用,避免某些块过早达到擦写次数上限(通常为3000-10000次,取决于NAND类型)。FTL通过动态磨损均衡(Dynamic Wear Leveling)和静态磨损均衡(Static Wear Leveling)算法,将写入操作分散到所有块,并定期迁移冷数据,实现均匀磨损。
- 多队列并发是现代NVMe SSD的核心特性。NVMe协议支持多达65535个I/O队列,每个队列深度可达65535,远超SATA的单队列32深度限制。调度器需要合理分配I/O请求到不同队列,充分利用SSD的并行处理能力。Linux的多队列块I/O(Multi-Queue Block I/O, blk-mq)框架为NVMe设备提供了高效的队列管理机制。
这张表对比了HDD和NVM设备在调度策略上的差异。HDD需要复杂的算法来优化机械移动,而NVM更注重读写特性的平衡。
错误检测和纠正
在存储系统中,数据在写入、存储和读取过程中可能因各种原因发生错误,包括位翻转(Bit Flip)、位丢失(Bit Loss)或位插入(Bit Insertion)。 这些错误可能由物理因素(如电磁干扰、温度变化、辐射)、介质老化(如磁性材料退化、NAND单元电荷泄漏)、制造缺陷(如坏块、弱块)或传输噪声(如信号衰减、串扰)引起。
数据错误的后果可能是灾难性的:单个关键位的错误可能导致程序崩溃、数据损坏或安全漏洞。因此,存储系统必须实现错误检测(Error Detection)和错误纠正(Error Correction)机制,确保数据的完整性(Integrity)和可靠性(Reliability)。
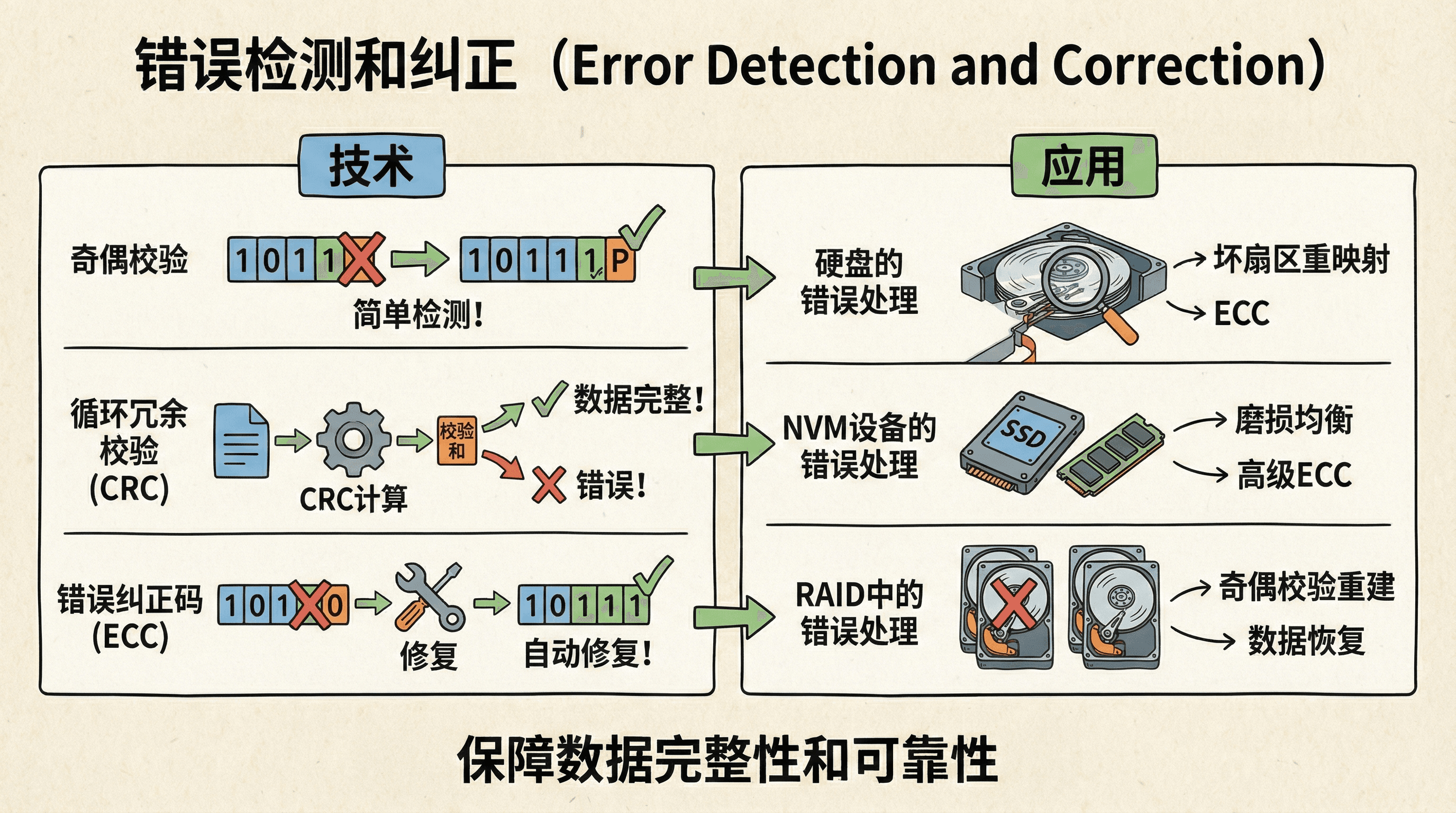
错误检测机制能够识别数据是否发生错误,但无法修复错误;错误纠正机制不仅能检测错误,还能自动修复部分错误。 现代存储系统通常采用多层错误保护(Multi-Layer Error Protection)策略:在硬件层面使用错误纠正码(Error Correction Code, ECC),在软件层面使用校验和(Checksum)或哈希值(Hash),在应用层面使用冗余存储(如RAID、备份)。 这种分层保护机制大大提高了数据可靠性,现代存储设备的不可恢复错误率(Unrecoverable Error Rate, UER)已降至 到 级别。
奇偶校验
奇偶校验(Parity Check)是最简单的错误检测方法。它通过计算数据中1的个数,添加一个奇偶校验位(Parity Bit)使总1的个数为奇数(奇校验)或偶数(偶校验)。 奇偶校验的数学原理是:对于数据位 ,奇校验位 ,其中 表示异或运算。
奇偶校验只能检测奇数个位错误,对于偶数个位错误无法检测。例如,如果两个位同时翻转,1的个数的奇偶性不变,错误无法被发现。 奇偶校验的汉明距离(Hamming Distance)为2,意味着需要至少2个位错误才能将一个有效码字转换为另一个有效码字。奇偶校验广泛应用于内存条(如DDR内存的ECC)、串行通信(如UART)等场景,其计算开销极低,适合实时性要求高的应用。
循环冗余校验
循环冗余校验(Cyclic Redundancy Check, CRC)是一种基于多项式除法的错误检测方法,能够检测多种类型的错误,包括单比特错误、双比特错误、奇数个错误、突发错误等。CRC的检测能力取决于生成多项式(Generator Polynomial)的选择和CRC的位数。
CRC算法的数学原理是:将数据视为一个二进制多项式M(x),用预定义的生成多项式G(x)对M(x)进行模2除法运算,得到的余数R(x)即为CRC校验码。发送方将数据和CRC校验码一起传输;接收方用同样的生成多项式对接收到的数据计算CRC,如果计算结果与接收到的CRC不一致,则检测到错误。
常用的CRC标准包括CRC-8、CRC-16、CRC-32、CRC-64等,其中CRC-32广泛应用于以太网、ZIP文件、PNG图像等。CRC-32的生成多项式为0x04C11DB7(标准形式)或0xEDB88320(反向形式),能够检测所有单比特和双比特错误、所有奇数个错误、所有长度不超过32位的突发错误,以及99.9969%的更长突发错误。
CRC算法的计算可以通过查表法(Lookup Table)实现,将计算复杂度从 降低到 ,适合硬件实现。现代存储设备(如硬盘、SSD)在扇区或页级别使用CRC进行错误检测,CRC校验失败会触发重试或错误纠正机制。
错误纠正码
- 错误纠正码(Error Correction Code, ECC)不仅能检测错误,还能自动纠正部分错误。ECC通过在原始数据中添加冗余校验位(Redundant Check Bits),根据编码理论构造具有纠错能力的码字。当读取数据时,系统通过译码算法(Decoding Algorithm)检测错误并定位错误位置,然后自动纠正。
- 海明码(Hamming Code)是最经典的单比特纠错码。对于 位数据,海明码需要添加 位校验位,满足 。海明码的校验位位于2的幂次位置(1, 2, 4, 8, ...),每个校验位负责检查特定位置的位。例如,对于4位数据,需要3位校验位,组成7位海明码。海明码的最小汉明距离为3,能够检测2个错误或纠正1个错误。
- 里德-所罗门码(Reed-Solomon Code, RS码)是一种强大的多比特纠错码,广泛应用于存储系统。RS码基于有限域(Finite Field)理论,能够纠正多个符号错误。对于 RS码,其中 为码字长度, 为数据长度,可以纠正最多 个符号错误。RS码在RAID 6、CD/DVD、QR码等场景中广泛应用。
现代存储设备通常采用BCH码(Bose-Chaudhuri-Hocquenghem Code)或LDPC码(Low-Density Parity-Check Code)作为ECC。BCH码是海明码的推广, 能够纠正多个比特错误;LDPC码是一种迭代译码(Iterative Decoding)码,具有接近香农极限(Shannon Limit)的性能,现代SSD广泛采用LDPC码实现高密度存储下的可靠纠错。 存储设备的ECC通常能够纠正每512字节数据中的多个比特错误,原始误比特率(Raw Bit Error Rate, RBER)可达 到 ,经过ECC纠错后,不可恢复误比特率(Unrecoverable Bit Error Rate, UBER)降至 以下。
存储设备中的错误处理
硬盘的错误处理
现代HDD在每个扇区存储512字节数据和50-100字节的ECC校验码。读取时,控制器重新计算ECC并与存储的ECC比较。如果检测到错误,控制器首先尝试软错误恢复(Soft Error Recovery),通过调整读取参数(如读取电压、时序)重试。如果软错误恢复失败,ECC会尝试纠正错误;如果错误超出ECC的纠错能力,控制器会报告不可恢复错误(Unrecoverable Error)。
HDD采用扇区重映射(Sector Remapping)技术处理坏扇区。当某个扇区反复出现错误时,控制器将其标记为坏扇区(Bad Sector),并将数据重映射到备用扇区(Spare Sector)。备用扇区通常占磁盘容量的1-5%,分布在各个区域。现代HDD还采用扇区滑动(Sector Slipping)技术,动态调整扇区分配,避免使用已知的弱扇区。这些技术由SMART(Self-Monitoring, Analysis and Reporting Technology)系统监控和管理。
NVM设备的错误处理
NVM设备(特别是NAND闪存)的错误处理更为复杂。由于电荷泄漏(Charge Leakage)和单元老化(Cell Aging),NAND闪存的错误率随时间和擦写次数增加而上升。现代SSD采用多层错误保护:在页级别使用BCH码或LDPC码进行纠错,在块级别使用RAID-like冗余保护,在设备级别使用预留空间(Over-Provisioning)提供备用块。
当某个块的错误率超过阈值或达到最大擦写次数时,FTL会将其标记为坏块(Bad Block),并将数据迁移到备用块。现代SSD通常预留7-28%的容量作为备用空间,用于坏块替换和磨损均衡。读取干扰(Read Disturb)和写入干扰(Write Disturb)是NAND闪存特有的问题,FTL通过读取刷新(Read Refresh)和写入验证(Write Verify)机制进行缓解。
RAID中的错误处理
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)系统通过数据冗余和校验码实现错误检测和纠正。RAID 5采用分布式奇偶校验(Distributed Parity),将数据和奇偶校验信息(通过异或运算计算)分散存储在多块磁盘上。 奇偶校验的计算公式为:
其中 为数据块, 为奇偶校验块。当一块磁盘故障时,系统可以通过剩余磁盘的数据和奇偶校验块重构丢失的数据:
RAID 6采用双重分布式校验(Double Distributed Parity),使用两个独立的校验算法:P校验(通过异或运算)和Q校验(通过里德-所罗门编码或伽罗华域运算)。RAID 6可以同时容忍两块磁盘故障,其Q校验的计算基于有限域 的运算。RAID 6的容错能力使其特别适合大容量、高可靠性要求的场景,如企业级存储系统、云存储等。
这张流程图展示了错误检测和纠正的工作过程。从写入到读取,每一步都有校验码的保护。
错误检测和纠正技术让存储设备变得更加可靠。现在的硬盘和NVM设备出错率已经非常低了,这都要归功于这些储存技术的进步。
存储设备的管理
存储设备管理是操作系统将物理存储设备组织成可用存储空间的过程,包括格式化(Formatting)、分区(Partitioning)、卷管理(Volume Management)和文件系统创建(File System Creation)等步骤。 这些步骤将原始的存储介质转换为操作系统和应用程序可以使用的逻辑存储空间。
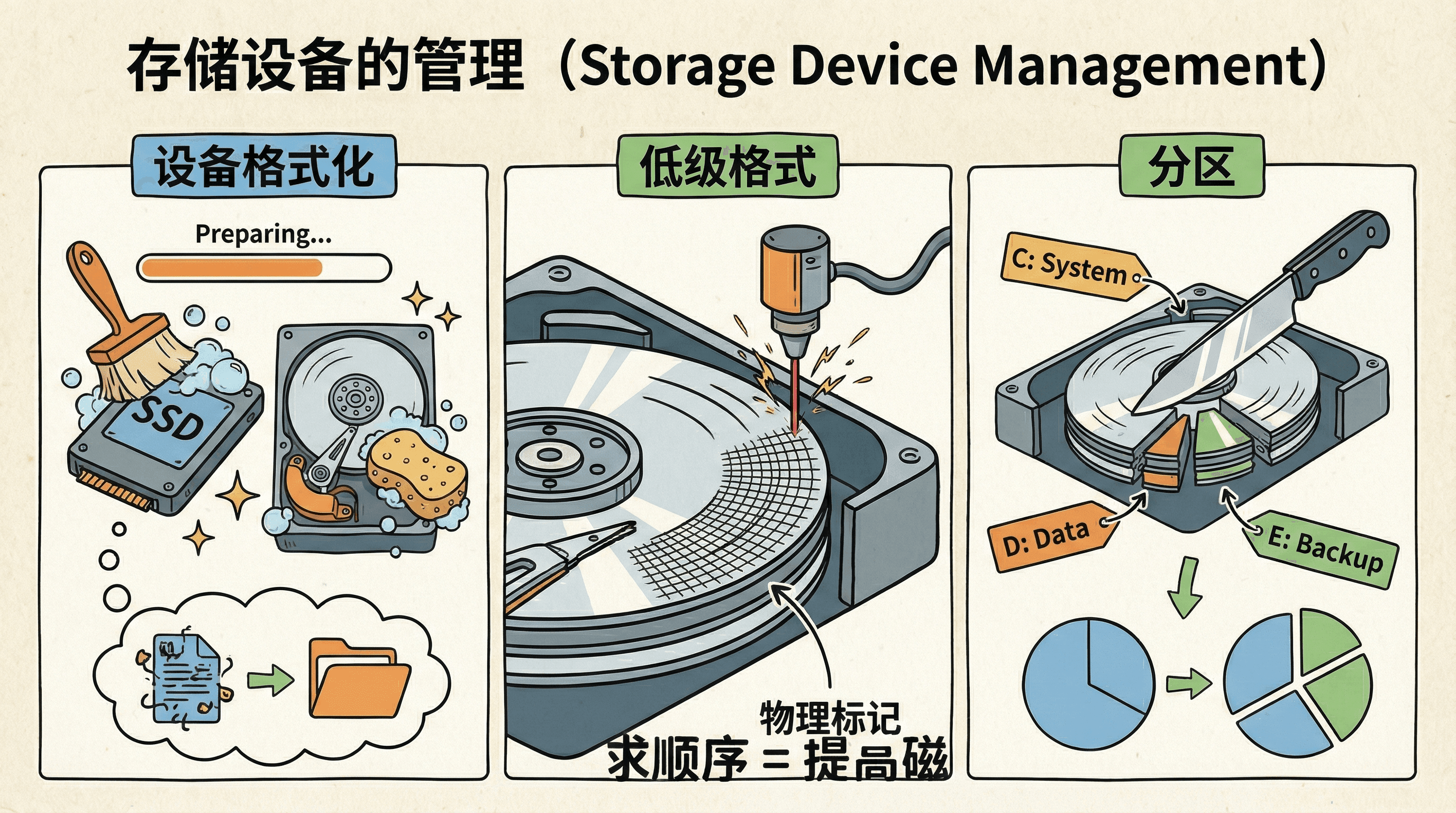
设备格式化
格式化是在存储设备上创建数据结构的过程,使操作系统能够识别、访问和管理存储空间。格式化分为低级格式化(Low-Level Formatting)和高级格式化(High-Level Formatting)两个层次。
低级格式
低级格式化(也称为物理格式化,Physical Formatting)在工厂制造时完成,或在特殊维护场景下使用专业工具执行。对于HDD,低级格式化在每个扇区写入扇区标识(Sector ID)、同步字段(Sync Field)、地址标记(Address Mark)、数据区域(Data Area)和ECC校验码。扇区的物理结构包括:前导码(Preamble,用于同步)、扇区标记(Sector Marker)、数据字段(512或4096字节)和后置码(Postamble,包含ECC)。
对于NVM设备,低级格式化初始化闪存转换层(Flash Translation Layer, FTL)的数据结构,包括地址映射表(Address Mapping Table)、磨损均衡表(Wear Leveling Table)、坏块表(Bad Block Table)等。FTL负责将逻辑块地址(LBA)映射到物理页地址(PPA),处理磨损均衡、垃圾回收、坏块管理等复杂操作。现代SSD的FTL通常由控制器固件实现,对上层透明。
分区
分区(Partitioning)是将物理存储设备划分为多个逻辑分区(Logical Partition)的过程,每个分区可以独立格式化和管理。分区的主要目的包括:数据隔离(Data Isolation),将系统文件、用户数据和应用程序分离,提高安全性和可维护性;多系统支持(Multi-OS Support),允许在同一设备上安装多个操作系统;性能优化(Performance Optimization),为不同用途(如系统、数据、交换空间)分配合适的存储空间;故障隔离(Fault Isolation),单个分区的损坏不会影响其他分区。
分区信息存储在分区表(Partition Table)中。MBR(Master Boot Record)是传统的分区方案,位于磁盘的第一个扇区(LBA 0),包含446字节的引导代码、64字节的分区表(最多4个主分区)和2字节的引导签名(0x55AA)。MBR使用32位LBA地址,最大支持2TB磁盘。GPT(GUID Partition Table)是UEFI标准的分区方案,支持更大的磁盘容量(使用64位LBA,理论最大8ZB),支持128个主分区,并在分区表末尾存储备份,提高可靠性。GPT还支持分区类型GUID(Partition Type GUID),可以标识不同操作系统的分区。
卷管理
卷(Volume)是比分区更灵活的存储抽象,它通过逻辑卷管理器(Logical Volume Manager, LVM)将物理存储资源抽象为逻辑存储单元。卷管理突破了物理设备的限制,可以将多个物理硬盘、多个分区甚至不同类型的存储设备组合成统一的逻辑卷,实现存储虚拟化(Storage Virtualization)。
Linux LVM(Logical Volume Manager)是典型的卷管理实现,采用三层架构:物理卷(Physical Volume, PV)是物理存储设备或分区;卷组(Volume Group, VG)由一个或多个物理卷组成,是存储池;逻辑卷(Logical Volume, LV)是从卷组中分配的逻辑存储单元,可以像普通分区一样格式化和挂载。LVM支持在线扩容(Online Resizing)、快照(Snapshot)、条带化(Striping)、镜像(Mirroring)等高级功能。
Windows动态磁盘(Dynamic Disk)提供类似的卷管理功能,支持简单卷(Simple Volume,对应单个分区)、跨区卷(Spanned Volume,跨越多个磁盘)、条带卷(Striped Volume,RAID 0)、镜像卷(Mirrored Volume,RAID 1)和RAID-5卷(RAID 5)。卷管理实现了存储资源的动态分配(Dynamic Allocation)和灵活管理(Flexible Management),是现代存储系统的重要特性。
卷管理就像是乐高积木:你可以把不同的积木块(硬盘分区)组合成各种形状(卷),创造出你需要的存储结构。
文件系统创建
高级格式化(High-Level Formatting)是在分区或卷上创建文件系统(File System)的过程。文件系统定义了数据在存储设备上的组织方式,包括元数据结构(Metadata Structure)、目录结构(Directory Structure)、文件分配方法(File Allocation Method)和空间管理策略(Space Management Strategy)。
文件系统的核心功能包括:文件组织(File Organization),将文件数据存储在磁盘块中,并维护文件名到数据块的映射;目录管理(Directory Management),维护文件名的层次结构,通常采用B+树或哈希表实现快速查找;空间分配(Space Allocation),跟踪空闲块,为新文件分配存储空间,常用方法包括连续分配(Contiguous Allocation)、链接分配(Linked Allocation)和索引分配(Indexed Allocation);元数据管理(Metadata Management),存储文件的属性信息(如大小、权限、时间戳)和文件系统的全局信息(如超级块、inode表)。
常见的文件系统包括:FAT32(File Allocation Table 32),采用文件分配表管理文件,兼容性好但性能有限;NTFS(New Technology File System),采用主文件表(Master File Table, MFT)和B+树索引,支持大文件、权限控制和日志;ext4(Fourth Extended File System),采用extent分配和多块分配(Multi-Block Allocation),支持大文件系统和日志;ZFS(Zettabyte File System),采用写时复制(Copy-on-Write)和校验和(Checksum),提供数据完整性保护和快照功能。
shell
# Linux中查看分区信息
$ fdisk -l /dev/sda
# 创建文件系统
$ mkfs.ext4 /dev/sda1
# 挂载文件系统
$ mount /dev/sda1 /mnt/data引导块
引导块(Boot Block)是存储设备上的特殊区域,包含引导程序(Bootloader)代码,负责启动操作系统。引导过程是一个多阶段的过程,涉及固件、引导程序和操作系统的协同工作。
在传统BIOS系统中,主引导记录(Master Boot Record, MBR)位于磁盘的第一个扇区(LBA 0),包含446字节的引导代码、64字节的分区表和2字节的引导签名(0x55AA)。BIOS在POST(Power-On Self-Test)完成后,按照启动顺序(Boot Order)查找可引导设备,读取MBR的引导代码到内存地址0x7C00,并跳转执行。MBR引导代码通常很小,只能加载第二阶段引导程序(如GRUB、Windows Boot Manager),后者再加载操作系统内核。
在UEFI(Unified Extensible Firmware Interface)系统中,引导过程更加灵活。UEFI固件直接读取EFI系统分区(EFI System Partition, ESP),该分区采用FAT32文件系统,包含EFI引导程序(.efi文件)。UEFI支持安全启动(Secure Boot),通过数字签名验证引导程序的完整性,防止恶意软件篡改引导过程。UEFI还支持GPT分区表和大于2TB的磁盘,提供了比传统BIOS更强的功能和安全性。
现代操作系统的引导过程通常包括:第一阶段引导程序(First-Stage Bootloader,如MBR或UEFI Boot Manager)负责初始化硬件和加载第二阶段引导程序;第二阶段引导程序(Second-Stage Bootloader,如GRUB、Windows Boot Manager)提供多系统选择、内核参数配置等功能;操作系统内核(OS Kernel)负责初始化硬件驱动、挂载根文件系统、启动系统服务,最终完成系统启动。
坏块处理
存储设备在长期使用过程中,某些区域(如磁盘的扇区或块)可能会因为物理磨损、制造缺陷或意外断电等原因发生损坏,这些损坏的区域被称为“坏块”或“坏扇区”。 如果操作系统不加以处理,数据可能会写入这些损坏的区域,导致文件丢失或系统崩溃。 为此,操作系统和硬盘控制器会协同工作,检测并标记这些坏块,避免继续使用它们。 同时,系统会采取措施(如使用备用扇区或扇区滑动技术)来替换或绕过坏块,确保数据的完整性和存储设备的正常运行。
存储管理的层次结构
存储管理是一个多层次的过程,每一层都有特定的职责,它们相互协作,为应用程序提供可靠的存储服务。
存储管理的层次结构体现了分层抽象(Layered Abstraction)的设计原则。应用程序层通过系统调用(System Call)与文件系统交互,无需了解底层存储细节;文件系统层将文件操作转换为块I/O请求,管理文件的逻辑组织和元数据;卷管理层提供逻辑卷抽象,支持跨设备的存储池管理;分区层管理物理设备的分区布局,维护分区表信息;驱动层实现与具体硬件的通信协议(如SATA、NVMe),执行实际的I/O操作;硬件层是物理存储介质,执行数据的实际读写。
这种分层设计实现了关注点分离(Separation of Concerns):上层关注逻辑功能,下层处理物理实现。每一层为上层提供简洁的接口,隐藏下层的复杂性,使得系统具有良好的可维护性(Maintainability)、可扩展性(Extensibility)和可移植性(Portability)。
存储设备的管理虽然复杂,但正是这些管理机制让我们的数据存储变得安全、有序和高效。
换页空间管理
换页(Paging)或交换(Swapping)是操作系统将物理内存中的页面(Page)暂时存储到辅助存储设备(通常是硬盘)的技术,用于实现虚拟内存(Virtual Memory)系统。 换页使得系统能够运行比物理内存更大的程序,通过按需分页(Demand Paging)和页面置换(Page Replacement)机制,在物理内存和交换空间之间动态调度页面。
换页空间(Swap Space)是辅助存储设备上专门用于存储换出页面的区域。当物理内存不足时,操作系统将最近最少使用(Least Recently Used)或不活跃(Inactive)的页面换出到交换空间,释放物理内存供其他进程使用。 当需要访问已换出的页面时,操作系统会触发缺页异常(Page Fault),将页面从交换空间换入物理内存。
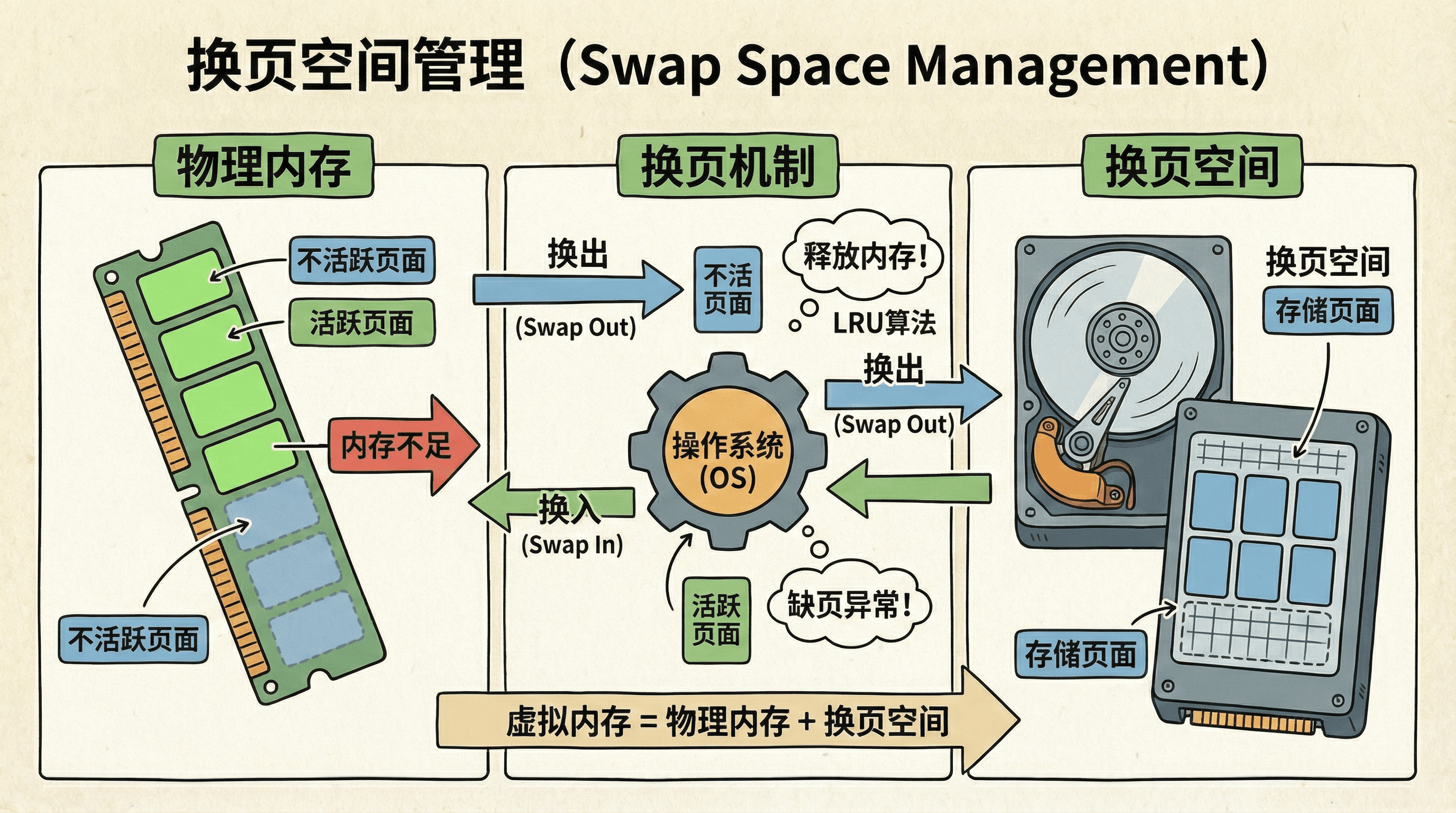
为什么需要换页空间?
换页空间的主要作用包括:扩展虚拟地址空间(Extending Virtual Address Space),允许进程使用比物理内存更大的地址空间,支持大型应用程序和数据集;多任务支持(Multitasking Support),在物理内存有限的情况下,通过换页实现多个进程的并发执行,操作系统将不活跃进程的页面换出,为活跃进程腾出内存;内存碎片整理(Memory Defragmentation),通过换出部分页面,操作系统可以整理出更大的连续内存区域,满足大块内存分配需求;工作集管理(Working Set Management),根据局部性原理(Principle of Locality),只将活跃的工作集(Working Set)保留在内存中,将不活跃的页面换出。
换页的性能开销主要来自磁盘I/O延迟。HDD的随机访问延迟为几毫秒,而内存访问延迟为纳秒级,相差6个数量级。因此,频繁换页会导致严重的性能下降,称为抖动(Thrashing)。现代系统通过预取(Prefetching)、页面聚类(Page Clustering)和交换优先级(Swap Priority)等优化技术减少换页开销。
换页频率是系统内存压力的重要指标。如果系统频繁换页(swap in/out速率高),说明物理内存不足,应该考虑增加物理内存或优化内存使用。现代系统通常建议交换空间大小为物理内存的1-2倍,但对于SSD系统,可以适当减少。
换页空间的类型
专用交换分区
专用交换分区(Dedicated Swap Partition)是在存储设备上专门划分的独立分区,完全由操作系统管理,不经过文件系统。交换分区采用原始块设备访问(Raw Block Device Access),操作系统直接通过块设备接口读写数据,避免了文件系统的元数据管理、目录查找、空间分配等开销。
交换分区的优势包括:零文件系统开销(Zero Filesystem Overhead),直接块访问消除了文件系统层的延迟,提高了I/O效率;连续存储布局(Contiguous Storage Layout),分区通常是连续分配的,对于HDD可以减少磁头寻道时间,对于SSD可以提高顺序写入性能;高可靠性(High Reliability),不受文件系统损坏影响,即使根文件系统出现问题,交换分区仍可正常工作;性能可预测(Predictable Performance),没有文件系统碎片化问题,性能稳定。
交换分区的主要缺点是灵活性不足(Limited Flexibility):分区大小在创建时确定,调整需要重新分区,操作复杂且风险较高。现代系统更倾向于使用交换文件,除非对性能有极高要求或需要确保交换空间不被文件系统占用。
交换文件
交换文件(Swap File)是在现有文件系统中创建的普通文件,通过特殊标记和权限设置,被操作系统识别为交换空间。现代Linux系统(内核2.6+)和Windows系统都支持交换文件,它已成为主流的交换空间实现方式。
交换文件的优势包括:动态大小调整(Dynamic Resizing),可以在系统运行时动态创建、删除或调整交换文件大小,无需重新分区;灵活的存储管理(Flexible Storage Management),不需要预留专门分区,可以充分利用磁盘空间,支持多个交换文件分布在不同的磁盘或分区上;易于管理(Easy Management),交换文件可以像普通文件一样备份、移动或删除,操作简单;适合虚拟化环境(Virtualization-Friendly),在虚拟机或云环境中,调整分区通常困难,但可以轻松管理交换文件。
交换文件的潜在问题包括:文件系统碎片化(Filesystem Fragmentation),如果文件系统碎片化严重,交换文件可能不连续,影响性能(现代文件系统通过预分配(Preallocation)和连续分配(Contiguous Allocation)缓解此问题);文件系统依赖(Filesystem Dependency),交换文件依赖于文件系统的正常运行,如果文件系统损坏,交换文件可能无法使用。对于大多数场景,交换文件的灵活性和易用性优势明显,性能差异可以忽略不计。
内存盘
内存盘(RAM Disk)或tmpfs(Temporary File System)是在物理内存中创建的虚拟文件系统,将RAM模拟为块设备。将交换空间放在内存盘上在逻辑上是矛盾的:交换的目的是将内存内容转移到辅助存储,而内存盘本身就是内存,无法真正"释放"内存。
实际上,内存盘通常用于临时文件存储(Temporary File Storage)或缓存(Caching),而不是作为交换空间。Linux的tmpfs文件系统将内存作为临时存储,数据在内存中,访问速度极快,但断电后丢失。tmpfs常用于/tmp、/var/run等目录,提供快速的临时文件访问。
使用内存作为"交换空间"的唯一场景是压缩交换(Zswap)技术:Linux内核的zswap功能将部分交换页面压缩后存储在内存中,只有压缩后的数据才写入磁盘交换空间。这样可以减少磁盘I/O,提高交换性能,但本质上仍然是内存到磁盘的交换,只是增加了压缩层。
换页空间的使用策略
操作系统在管理换页空间时采用不同的分配策略(Allocation Strategy)。按需分配(On-Demand Allocation)策略只在页面需要换出时才在交换空间中分配位置,节省磁盘空间,但在内存紧张、频繁换页时,分配操作本身可能成为瓶颈。预分配(Preallocation)策略在进程启动或页面首次分配时就预留交换空间,避免了换出时的分配延迟,提高了性能,但可能浪费磁盘空间(如果页面从未被换出)。
现代操作系统通常采用混合策略(Hybrid Strategy):为部分页面预分配交换空间(如匿名页面(Anonymous Pages)),其他页面采用按需分配。Linux系统还支持交换预留(Swap Reservation),通过mlock()系统调用将页面锁定在内存中,防止被换出,这对于实时应用和关键数据非常重要。
页面置换算法
LRU(最近最少使用)
LRU算法(Least Recently Used)基于时间局部性原理(Temporal Locality Principle):最近访问过的页面很可能在不久的将来再次被访问。LRU算法维护页面的访问顺序,每次换出最久未访问(Least Recently Used)的页面。
精确LRU的实现需要为每个页面维护访问时间戳(Access Timestamp)或使用双向链表(Doubly Linked List)记录访问顺序,每次页面访问都需要更新时间戳或移动链表节点,时间复杂度为 ,但需要硬件支持(如访问位(Access Bit))或软件开销。精确LRU的缺页率(Page Fault Rate)接近理论最优,但实现复杂。
实际系统中通常采用近似LRU(Approximate LRU)算法,如时钟算法(Clock Algorithm)或二次机会算法(Second Chance Algorithm),通过硬件提供的引用位(Reference Bit)近似实现LRU,在性能和效果之间取得平衡。LRU算法的时间复杂度为 (如果使用链表)或 (如果需要搜索),空间复杂度为 ,其中 为页面数。
FIFO(先进先出)
FIFO算法(First-In, First-Out)按照页面进入内存的时间顺序进行置换,最早进入的页面最先被换出。FIFO算法使用队列(Queue)数据结构,新页面加入队尾,换出时从队头移除,实现简单,时间复杂度为 ,空间复杂度为 。
FIFO算法的主要问题是不考虑页面访问频率(Ignoring Access Frequency),可能将热点页面(Hot Pages)提前换出,导致缺页率上升。FIFO算法还存在Belady异常(Belady's Anomaly):在某些情况下,增加物理内存反而导致缺页率上升。这是因为FIFO算法没有利用访问局部性(Access Locality),无法识别哪些页面应该保留在内存中。
尽管存在这些问题,FIFO算法由于实现简单、开销低,仍被用于某些场景,或作为其他算法的基础。现代操作系统很少单独使用FIFO,而是将其与其他策略结合,或用于特定类型的页面(如文件缓存页面(File Cache Pages))。
时钟算法
时钟算法(Clock Algorithm)或二次机会算法(Second Chance Algorithm)是LRU的近似实现,通过硬件提供的引用位(Reference Bit)或访问位(Access Bit)判断页面的访问情况。算法将所有页面组织成环形队列(Circular Queue),维护一个时钟指针(Clock Hand)循环扫描页面。
当需要置换页面时,时钟指针检查当前页面的引用位:如果引用位为0,说明页面近期未被访问,可以换出;如果引用位为1,说明页面最近被访问过,算法给页面"第二次机会"(Second Chance),将引用位清零,指针继续移动。每当页面被访问时,硬件自动将引用位设置为1。算法继续扫描,直到找到引用位为0的页面。
时钟算法的时间复杂度为 (最坏情况需要扫描所有页面),但平均情况下远小于 ,因为大多数页面引用位为1的概率较低。时钟算法的缺页率接近LRU,但实现开销远低于精确LRU,因此被广泛采用。Linux内核的页面置换机制基于时钟算法的变种,结合了多级LRU(Multi-Level LRU)和工作集检测(Working Set Detection)等优化。
当系统出现"抖动"(thrashing)现象时,CPU大部分时间都在等待页面换入换出,而不是执行有用的工作。这时我们就需要减少运行的程序数量或增加物理内存。
Linux中的换页管理
Linux在换页(swap)管理方面提供了非常灵活和细致的机制。它支持多种交换空间的配置方式,包括传统的交换分区(swap partition)和更为灵活的交换文件(swap file)。系 统管理员可以根据实际需求动态添加、删除或调整交换空间的大小,而无需重启系统。
Linux通过swapon和swapoff命令实现对交换空间的启用和禁用,支持同时存在多个交换分区或交换文件,并可以为每个交换空间设置优先级(priority),以决定页面换出时的使用顺序。
此外,Linux内核还允许通过/proc/sys/vm/swappiness参数调整内存与交换空间的使用倾向,从而优化系统性能和响应速度。
shell
# 查看当前的交换空间
$ swapon -s
# 创建交换文件
$ dd if=/dev/zero of=/swapfile bs=1M count=1024
$ mkswap /swapfile
$ swapon /swapfile
# 设置开机自动挂载
$ echo '/swapfile none swap sw 0 0' >> /etc/fstab存储连接方式
存储设备需要通过各种“桥梁”连接到计算机系统。这些桥梁就像是不同类型的道路,有的快捷有的便捷,有的适合本地使用有的适合远程访问。
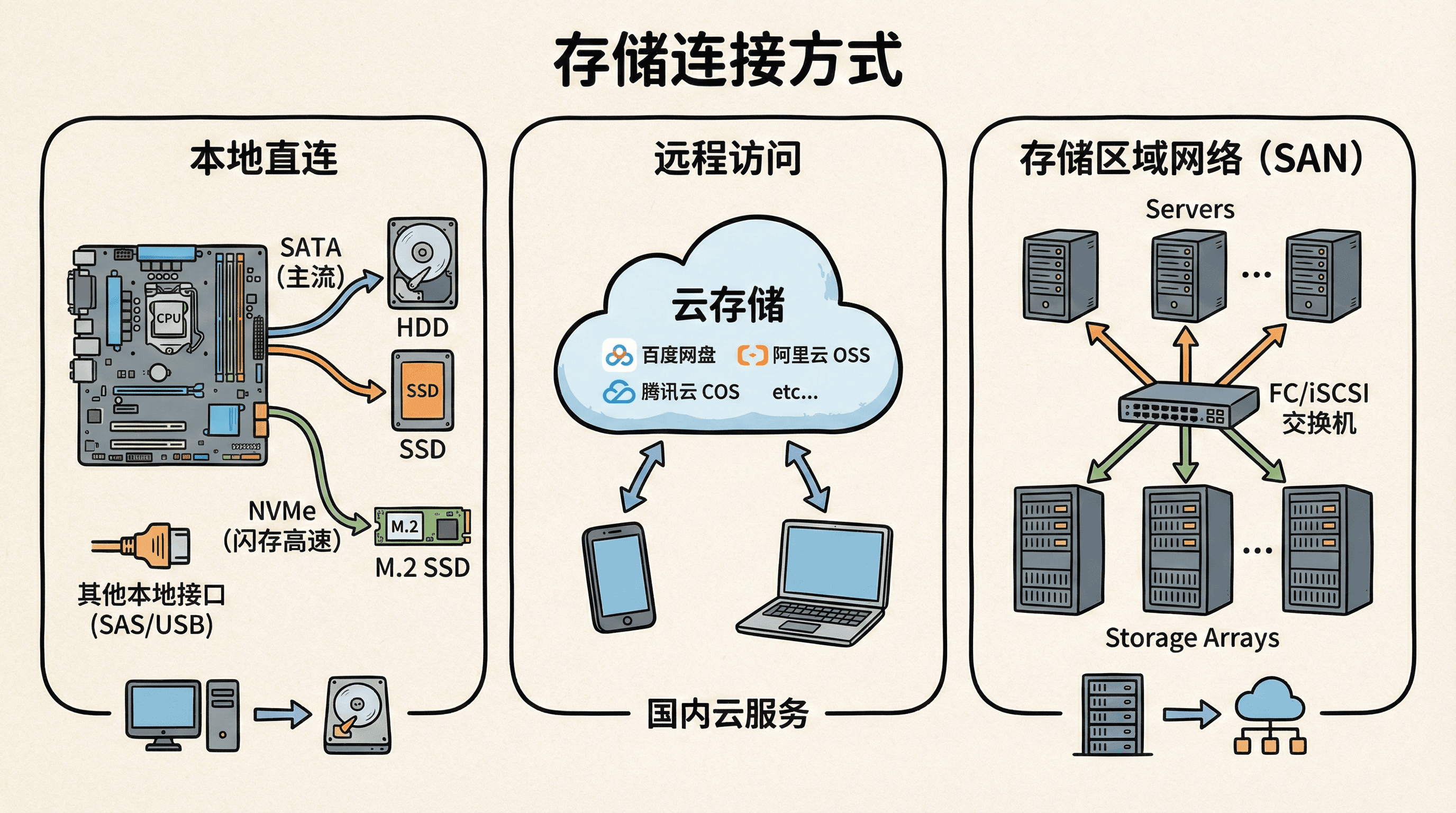
本地直连
主机附加存储(Host-Attached Storage)是最传统也是最直接的连接方式。存储设备直接连接到计算机的主板或扩展卡上。
SATA:主流的选择
SATA(Serial Advanced Technology Attachment)是并行ATA(PATA)的串行化版本,采用点对点(Point-to-Point)连接架构,每个设备独占一条链路。SATA协议经历了三代演进:SATA 1.0(1.5 Gbps,实际吞吐量约150 MB/s)、SATA 2.0(3 Gbps,实际吞吐量约300 MB/s)和SATA 3.0(6 Gbps,实际吞吐量约600 MB/s)。SATA 3.0的带宽足以满足大多数HDD和部分中低端SSD的需求。
SATA接口支持热插拔(Hot Plugging),允许在系统运行时插拔设备,这对于服务器和存储阵列的维护非常有用。SATA还支持NCQ(Native Command Queuing),允许设备接收最多32个未完成的命令,并优化执行顺序,减少寻道时间,提高多任务环境下的性能。SATA采用低电压差分信号(Low Voltage Differential Signaling, LVDS),降低了功耗和电磁干扰,同时简化了线缆设计(7针数据线+15针电源线)。
NVMe:为闪存而生
NVMe(Non-Volatile Memory Express)是专为NAND闪存设计的高速存储协议,直接基于PCIe(Peripheral Component Interconnect Express)总线,消除了SATA/SAS协议的转换开销。NVMe协议栈比AHCI(Advanced Host Controller Interface)更简洁,命令处理延迟从SATA的几微秒降低到几十纳秒。
NVMe的核心优势包括:极低延迟(Ultra-Low Latency),典型读取延迟为50-100微秒,写入延迟为10-50微秒,比SATA SSD低一个数量级;超高并发(High Concurrency),支持最多65535个I/O队列,每个队列深度65535,远超SATA的1队列32深度,充分利用多核CPU的并行处理能力;高带宽(High Bandwidth),PCIe 3.0 x4提供约4 GB/s带宽,PCIe 4.0 x4提供约8 GB/s,PCIe 5.0 x4可达16 GB/s,满足高性能应用需求;优化的命令集(Optimized Command Set),针对NAND闪存特性设计,支持多命名空间、端到端数据保护、原子写入等高级功能。
NVMe设备采用多种物理形态:M.2(22mm宽,多种长度)用于笔记本和台式机,U.2(2.5英寸)用于服务器,PCIe扩展卡用于高性能场景,EDSFF(Enterprise and Data Center SSD Form Factor)用于数据中心。NVMe已成为现代高性能SSD的标准接口,广泛应用于企业存储、云计算、高性能计算等领域。
其他本地接口
SAS(Serial Attached SCSI)是面向企业级应用的存储接口,采用双端口(Dual Port)设计,支持多路径(Multipath)和故障转移(Failover),提供高可用性。SAS协议支持12 Gbps(SAS-3)和24 Gbps(SAS-4)传输速率,具备更强的命令队列(Command Queuing)和标签命令(Tagged Command)能力。SAS硬盘通常具有更高的转速(10K、15K RPM)、更长的平均故障间隔时间(Mean Time Between Failures, MTBF)和更好的错误恢复(Error Recovery)能力,适合企业级存储阵列和关键业务应用。
USB(Universal Serial Bus)是通用的外部接口标准,广泛应用于便携式存储设备。USB 3.0(USB 3.2 Gen 1)提供5 Gbps带宽,USB 3.1(USB 3.2 Gen 2)提供10 Gbps,USB 3.2 Gen 2x2提供20 Gbps。USB接口的优势在于即插即用(Plug and Play)、热插拔(Hot Swapping)和广泛的兼容性,虽然延迟和持续性能不及SATA/NVMe,但便携性和易用性使其成为消费级外部存储的首选。
Thunderbolt是Intel和Apple联合开发的高速接口,Thunderbolt 3/4采用USB-C物理接口,提供40 Gbps双向带宽(PCIe 3.0 x4 + DisplayPort)。Thunderbolt支持菊花链(Daisy Chaining),可串联多个设备,同时支持数据传输、视频输出和供电(最高100W),适合专业用户和创意工作者。Thunderbolt 4进一步提升了安全性和兼容性,支持USB4兼容模式。
远程访问
网络附加存储(Network-Attached Storage,简称NAS)是一种通过网络将存储设备与多台计算机连接起来的技术。 与传统的本地直连存储不同,NAS设备通常是一个独立的存储服务器,内置专用的操作系统和管理软件。 它通过以太网等局域网与多台计算机相连,所有用户都可以像访问本地硬盘一样,通过网络访问NAS上的文件和数据。
NAS的核心作用是为局域网内的多台计算机提供集中式的文件存储和共享服务。 比如在公司、学校或家庭环境中,大家可以把重要的文档、照片、视频等统一存放在NAS设备上,任何授权用户都能随时通过网络读取、编辑或备份这些数据。 NAS支持多种文件访问协议(如NFS、SMB/CIFS、AFP等),可以兼容不同操作系统(Windows、macOS、Linux等)的客户端。
此外,NAS设备通常具备数据冗余(如RAID)、自动备份、权限管理、远程访问等功能,能够提升数据的安全性和管理效率。 它不仅适合家庭用户集中存储照片和影音资料,也广泛应用于企业环境,实现团队协作、数据集中管理和高效备份。
NAS虽然方便,但网络延迟和带宽限制了它的性能。如果需要高性能访问,主机附加存储仍然是最佳选择。
云存储
云存储是一种通过互联网提供的远程存储服务,用户无需自建和维护本地存储设备,只需通过网络即可随时随地访问和管理数据。 云存储平台通常由大型数据中心支撑,具备高可靠性和弹性扩展能力。用户可以根据实际需求灵活调整存储容量,按实际使用量付费,无需一次性投入大量硬件成本。 云存储不仅支持文件的上传、下载和共享,还提供数据备份、版本管理、权限控制等多种功能,广泛应用于个人数据同步、企业文件管理、网站内容分发、数据归档等场景。
常见的国内云存储服务
存储区域网络
存储区域网络(Storage Area Network,简称SAN)是一种专门为大型企业和数据中心设计的高性能存储解决方案。 SAN通过专用的高速网络(如光纤通道FC或iSCSI协议)将多台服务器与集中式存储设备(如磁盘阵列、磁带库等)连接起来,实现服务器与存储资源的分离。 与传统的直接附加存储(DAS)或网络附加存储(NAS)相比,SAN能够提供更高的数据传输速率、更低的延迟和更强的扩展性。 它允许多台服务器灵活访问同一组存储资源,支持关键业务的高可用性、数据备份、容灾和大规模并发访问,是企业级数据库、虚拟化平台和大数据应用的理想选择。
SAN的架构
RAID结构
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个物理磁盘组合成逻辑存储单元的技术,通过数据冗余(Data Redundancy)和数据分布(Data Distribution)实现高可用性(High Availability)和高性能(High Performance)。
RAID的基本技术包括:镜像(Mirroring),将数据复制到多个磁盘,提供冗余保护;条带化(Striping),将数据分散到多个磁盘,提高并行访问性能;奇偶校验(Parity),通过校验信息实现数据恢复,在性能和容量之间取得平衡。RAID系统通过RAID控制器(RAID Controller)管理磁盘阵列,可以是硬件RAID(Hardware RAID,专用控制器)或软件RAID(Software RAID,操作系统实现)。
RAID的主要目标包括:提高可靠性(Improving Reliability),通过冗余容忍磁盘故障;提高性能(Improving Performance),通过并行访问提高I/O吞吐量;提高容量(Improving Capacity),通过组合多个磁盘提供更大的存储空间;降低成本(Reducing Cost),通过使用多个廉价磁盘替代昂贵的高可靠性磁盘。
RAID级别详解
RAID 0:纯条带化
RAID 0采用条带化(Striping)技术,将数据按条带大小(Stripe Size)分散存储到多个磁盘,不提供任何冗余。对于 个磁盘,RAID 0的理论读取性能可提升 倍(理想情况),写入性能也可提升 倍。总容量为单个磁盘容量乘以磁盘数量,即:
RAID 0的可靠性(Reliability)显著降低:单个磁盘故障会导致整个阵列数据丢失。对于 个磁盘,每个磁盘的平均故障间隔时间(MTBF)为 ,RAID 0的MTBF为:
可靠性下降 倍。RAID 0适用于对性能要求极高、数据可重建或可丢失的场景,如临时数据、缓存、高性能计算等。
RAID 0不提供任何数据保护,单个磁盘故障会导致整个阵列数据丢失。只在对性能要求极高且能容忍数据丢失的环境中使用,如临时存储、缓存或通过其他方式(如备份)保护数据的场景。
RAID 1:镜像
RAID 1采用镜像(Mirroring)技术,将数据同时写入多个磁盘(通常为2个),每个磁盘存储完整的数据副本。RAID 1的读取性能可以提升(可以从任意磁盘读取),写入性能不变(需要写入所有磁盘)。总容量为单个磁盘容量,即 (对于2磁盘镜像)。
RAID 1的可靠性显著提高:对于2磁盘镜像,可以容忍1个磁盘故障。RAID 1的数据可用性(Data Availability)为:
其中 为单个磁盘的可用性。RAID 1适用于对可靠性要求极高的场景,如系统盘、关键数据库、金融系统等。RAID 1还可以扩展到多磁盘镜像(如3磁盘或4磁盘),提供更高的可靠性,但容量效率进一步降低。
RAID 5:分布式奇偶校验
RAID 5采用分布式奇偶校验(Distributed Parity),将数据和奇偶校验信息分散存储到所有磁盘。对于 个磁盘,RAID 5使用 个磁盘存储数据,1个磁盘等效容量存储奇偶校验。奇偶校验通过异或运算(XOR)计算:
其中 为数据块, 为奇偶校验块。奇偶校验块分布在所有磁盘上,避免单点故障。
RAID 5的读取性能接近RAID 0(可以从 个磁盘并行读取),写入性能较低(需要读取旧数据和旧校验,计算新校验,写入新数据和新校验,即读-修改-写(Read-Modify-Write)操作)。总容量为:
RAID 5可以容忍1个磁盘故障,通过剩余磁盘的数据和奇偶校验重构丢失的数据。RAID 5适用于平衡性能、容量和可靠性的场景,如文件服务器、Web服务器、中小型数据库等。
RAID 6:双重分布式奇偶校验
RAID 6在RAID 5的基础上增加第二重奇偶校验(Second Parity),使用两个独立的校验算法:P校验(通过异或运算)和Q校验(通过里德-所罗门编码或伽罗华域运算)。对于 个磁盘,RAID 6使用 个磁盘存储数据,2个磁盘等效容量存储校验。Q校验的计算基于有限域 的运算,比P校验更复杂,但提供了额外的纠错能力。
RAID 6可以同时容忍2个磁盘故障,通过剩余磁盘的数据和两种校验信息重构丢失的数据。RAID 6的读取性能接近RAID 5,写入性能更低(需要计算和写入两种校验)。总容量为:
RAID 6特别适合大容量磁盘阵列,因为重建时间(Rebuild Time)随磁盘容量增加而延长,在重建期间发生第二个磁盘故障的风险增加。RAID 6广泛应用于企业级存储、备份系统、归档存储等对可靠性要求极高的场景。
RAID 10:条带化镜像
RAID 10(也称为RAID 1+0)是镜像和条带化的组合:先将磁盘分成多个镜像对(Mirror Pairs),然后在镜像对之间进行条带化。对于 个磁盘( 为偶数),RAID 10形成 个镜像对,数据在镜像对之间条带化。总容量为:
RAID 10的读取性能接近RAID 0(可以从多个镜像对并行读取),写入性能略低于RAID 0(需要写入每个镜像对的两个磁盘)。RAID 10可以容忍多个磁盘故障,只要每个镜像对至少有一个磁盘正常。在最坏情况下(每个镜像对各故障一个磁盘),RAID 10仍可正常工作;但如果某个镜像对的两个磁盘都故障,数据将丢失。RAID 10适用于对性能和可靠性都有高要求的场景,如数据库服务器、虚拟化平台、高性能计算等。
RAID级别的比较
当RAID阵列中的硬盘出现故障时,系统会自动开始重建过程。在重建过程中,阵列的容错能力会降低。如果另一个硬盘在这时也出现故障,数据可能会丢失。因此,重建期间应该特别小心。
RAID的应用场景
存储系统的完整生态
我们已经探索了大容量存储系统的方方面面。从物理设备到软件管理,从性能优化到数据保护,这是一个庞大而精密的系统。让我们用一张思维导图来总结一下这些核心概念:
存储技术的发展日新月异,但基本原理却一直保持相对稳定。掌握了这些基础概念,你就能更好地理解和应用各种存储技术。
小练习
硬盘驱动器(HDD)的性能主要受哪些时间因素影响?
关于非易失性存储设备(NVM),以下哪个描述是正确的?
关于SCAN(电梯)算法,以下哪个描述是正确的?
关于奇偶校验,以下哪个描述是正确的?
关于RAID 0,以下哪个描述是正确的?
关于RAID 5,以下哪个描述是正确的?
关于NVMe接口,以下哪个描述是正确的?
关于换页空间,以下哪个描述是正确的?
1. 磁盘访问时间计算
假设一个7200 RPM的硬盘,平均寻道时间为8毫秒,传输速率为100 MB/s。请计算:
- 平均旋转延迟是多少?
- 读取一个4KB扇区需要多少传输时间?
- 读取一个4KB扇区的总访问时间是多少?
2. SCAN算法磁头移动距离计算
假设磁头当前位于磁道100,待处理的请求按到达顺序为:30、70、110、150、180。请计算:
- 使用FCFS算法,磁头移动的总距离是多少?
- 使用SCAN算法(假设磁头先向外圈移动),磁头移动的总距离是多少?
- 比较两种算法的效率
3. RAID容量和性能计算
假设有4块1TB的硬盘,请计算:
- 使用RAID 0,总容量和容错能力是多少?
- 使用RAID 1(2块镜像),总容量和容错能力是多少?
- 使用RAID 5,总容量和容错能力是多少?
- 使用RAID 6,总容量和容错能力是多少?
- 使用RAID 10,总容量和容错能力是多少?
4. 奇偶校验计算
假设有4个数据块:D1 = 1010、D2 = 1100、D3 = 0111、D4 = 1001。请计算:
- 使用异或运算计算奇偶校验块P
- 如果D2损坏变为1111,如何通过奇偶校验检测错误?
- 如何通过奇偶校验恢复D2的原始值?