初识 Redis
在企业信息化进程中,数据处理性能常常成为业务系统的瓶颈。例如,当需要对包含姓名、邮箱、地理位置、电话号码等字段的客户数据进行高效检索时,传统的关系型数据库(如 SQL 数据库)虽然具备丰富的数据结构和强大的查询能力,但在面对数万乃至数十万级别的数据量及复杂多条件搜索时,往往存在查询延迟高、扩展受限的问题——一次典型的多表联合查询甚至可能耗时 10-15 秒,这对于高并发、高实时性场景来说是难以接受的。
针对上述业务痛点,Redis 以其丰富的数据结构(如哈希表、集合、有序集合等)和极致的内存存储性能,能够帮助我们构建响应更迅速、更具扩展性的搜索引擎。例如,针对同样 6 万条客户数据的多字段检索,通过 Redis 的优化设计,响应时间可以缩短至 50 毫秒以内,整体性能提升显著,可达到 200 倍以上。
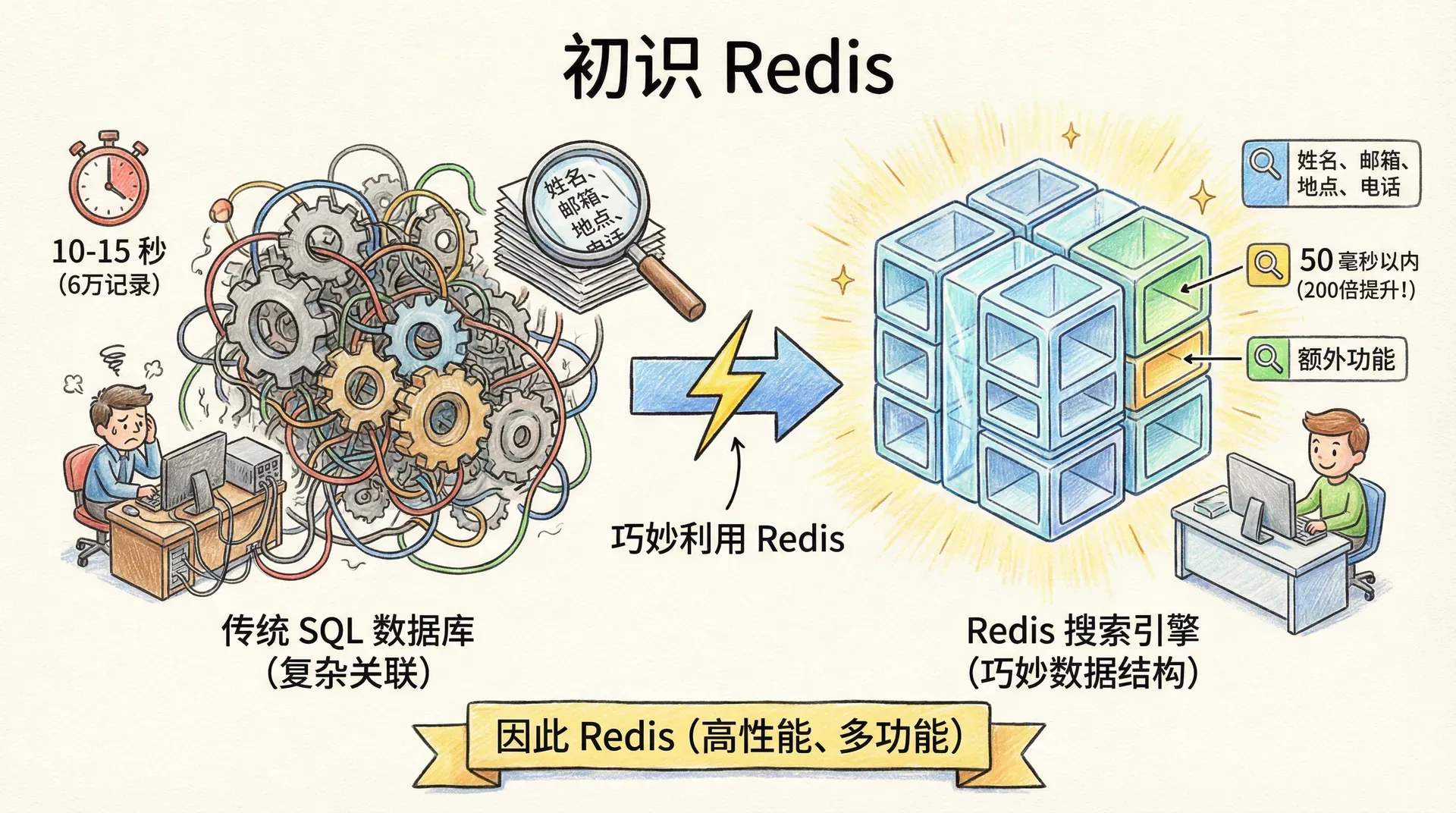
因此,Redis 不仅是一个高性能的键值数据库,更是支撑复杂、实时数据处理和现代化架构的核心技术组件之一。
Redis 是什么
如果将 Redis 简单地归类为一个数据库,其实只是触及了表面。事实上,Redis 是一款高性能的内存型非关系数据库系统,它的核心在于通过键值对方式管理多达五种类型的数据结构。 Redis 支持数据在内存中的高效操作,同时提供了多样化的持久化机制,能够确保数据安全。此外,借助主从复制功能可以横向扩展读取能力,分片部署则能应对写入压力。 因此,不论是面向小型原型开发,还是应对数百 GB 数据量、极高并发的企业级应用,Redis 都具备极其突出的适用性与弹性。
Redis 与其他数据库系统的差异
在日常的软件开发中,我们经常会面临这样一个抉择:到底选用哪种数据库来存储和管理数据?传统关系型数据库,例如 MySQL 或 PostgreSQL,强调的是结构化的数据管理和复杂的关系约束。它们的数据层就像一个有序且规范的系统,各种表与表之间通过外键、索引等方式彼此关联,非常适合高度结构化、查询需求复杂的业务场景。每一条数据都“井井有条”地安放在特定的位置。
而 Redis 则代表了另一种思路。作为内存型的 NoSQL 数据库,Redis 并没有表的概念,也无需预先设计繁琐的结构。所有数据都围绕着「键」进行组织,通过灵活的数据结构(如字符串、列表、集合、哈希、有序集合等)来满足各种实时处理的需求。这种方式极大地降低了应用层的耦合,尤其适合数据模型频繁变化、不必强调表间关系的场合,比如实时排行榜、分布式计数器、消息队列及会话缓存等。对于需要极低延迟、极高并发的数据访问,Redis 在业界一直有口皆碑。
很多开发者可能也用过 memcached。确实,memcached 在缓存领域性能很高,但它只能存储简单的键值对,一旦服务重启或者断电,缓存中的数据就会全部丢失。Redis 则进一步提升了实用性——不仅保持了高速访问的特性,还提供了数据持久化机制,保证重要数据在异常重启后依然能够恢复。除此之外,Redis 的数据结构远比简单的“键-值”映射丰富和强大,这也让它能够胜任更复杂的任务。
Redis 在实际项目中可以有多种定位。例如,它可以单独承担核心业务的数据管理工作,也可以在 “冷热数据分层” 的架构下,成为关系型数据库的强力加速层,缓解后端数据库的压力,实现业务的高可用和高弹性。在数据量指数级增长时,Redis 并非银弹;我们通常会采用数据库分层或数据分片等策略,结合多种存储方案,使系统既能保证性能,又能实现高可靠性。
为了让你对这些主流数据库的定位和适合场景有直观认识,下表做了简单对比:
Redis 的核心特性
谈到 Redis,许多人最关心的还是数据的安全性。作为一款内存数据库,Redis 在数据持久化上有着独特的思路。其实,Redis 提供了双重保障机制:一方面,它可以定时将数据快照保存到磁盘上,确保在特定条件下自动留存一份“定格”的备份。 另一方面,Redis 还支持操作日志追记(AOF),也就是把每一次数据变更的动作记录下来。你可以灵活配置这套机制,比如每秒落盘、每次操作都写入,或者追求性能时选择异步处理。这样一来,即便遭遇断电、重启等突发情况,也能最大程度减少数据损失。
在扩展性方面,Redis 也有成熟的解决方案。如果你的业务量不断上涨,访问压力越来越大,只靠一台服务器自然难以满足需求。这个时候,Redis 的主从复制功能就显示出了它的威力。 你可以搭建一组一主多从的架构,每台从节点都会同步主节点的数据副本。这样一来,读请求可以分摊到多台服务器,大幅提升系统吞吐能力。而如果主系统出现异常,从节点还能快速顶上,最大限度保证业务连续性。
Redis 并不仅仅以“快”见长,在可靠性和可扩展性方面同样具备企业级水准。无论是数据安全,还是系统弹性,从底层设计到上层运维都考虑得非常周到。
Redis 的独特优势在哪里?
在实际开发中,Redis 的灵活性和强大功能带来了极大的便利。比如,你在做一个电商项目,想要高效管理每个用户的购物车。传统方案往往要将整个购物车内容编码成一个大字符串存储,每次增删查改都需要整体读写,既繁琐又低效。 而 Redis 内建的哈希表让这件事变得轻松无比:添加商品、查询信息、移除商品都可以独立操作,每一步都简洁高效。
再比如,如果要做实时排行榜,传统数据库常常力不从心,因为每一次排名统计都要全表扫描和排序。而 Redis 的有序集合恰好“天生”适合这个场景:给用户计分、取前几名、查个人名次,这些只需几个命令,在内存中即刻响应。
还有网站访问量统计,采用传统数据库经常会遇到并发写入的性能瓶颈。Redis 的 INCR 操作本身就是“原子级”自增,不需要锁定或等待,多用户同时访问也完全不会混乱,数据统计既准确又极快。
通过这些具体案例可以看到,Redis 不只是数据操作速度远超绝大部分数据库,它还通过独有的数据结构和原子操作,把许多棘手的编程场景变得简单明了。开发者只需聚焦业务本身,不用为底层实现绞尽脑汁,同时也让代码更加易读易维护。
Redis 的数据结构世界
Redis 最引人入胜的地方,就是它对数据结构的支持极为丰富和有趣。与一般只支持“键-值”的键值库不同,Redis 提供了五大核心数据结构,每一种都有着清晰的用途和完善的操作命令。
此外,Redis 的这些数据结构都支持一套基础命令,比如删除键、查询数据类型、重命名等,方便统一管理。每个结构还有自己专门的命令集,能够针对业务需求实现高效、精准的操作。 等你亲自摸索下去,一定会体验到这些数据结构带来的“降维打击”——原本难啃的问题,用对结构和命令就能轻松解决。
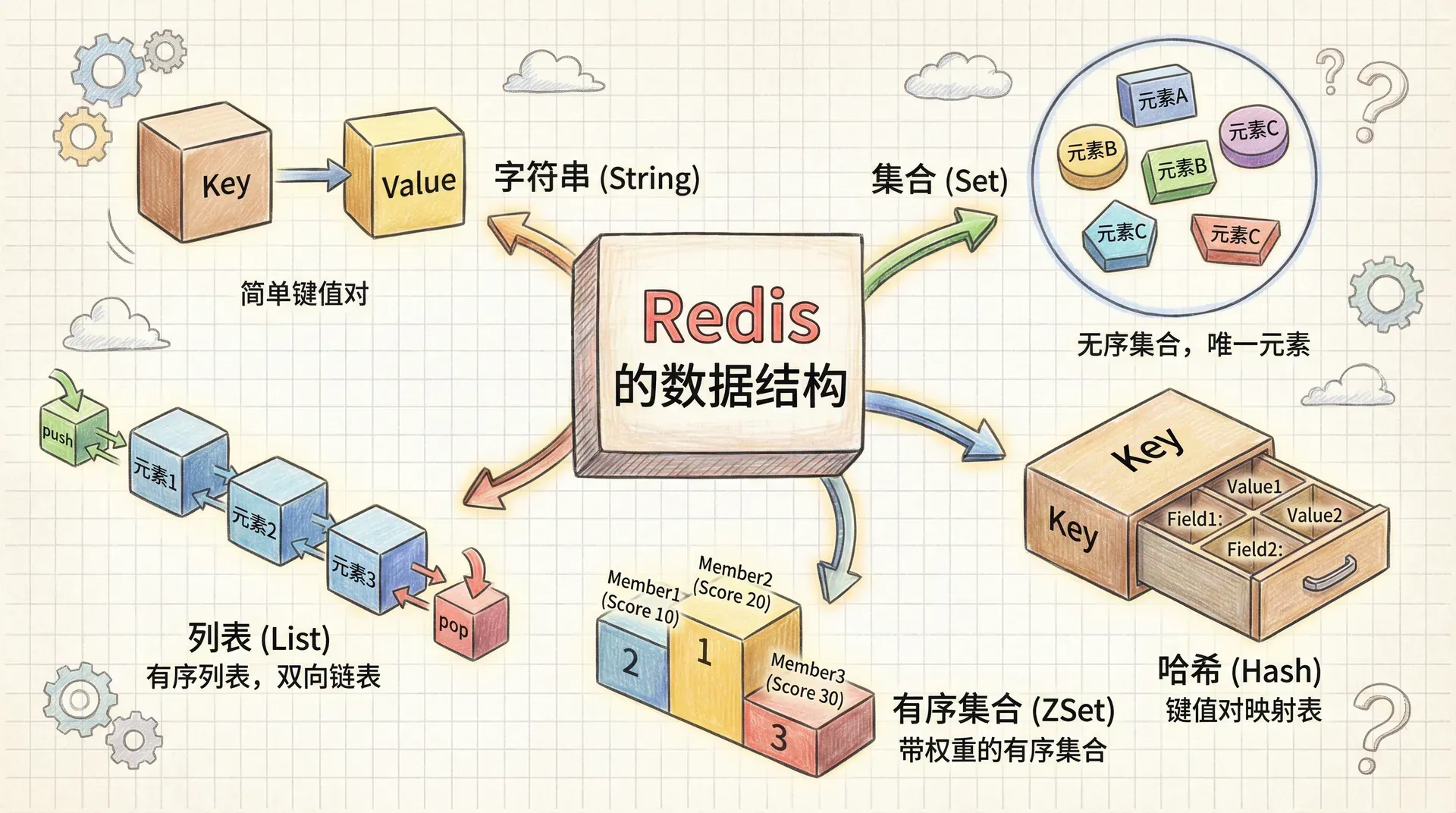
下表展示了 Redis 五种数据结构之间的关系:
在接下来的 Redis 学习中,我们将采用命令行与代码相结合的方式,深入理解每一种核心数据结构的原理和应用。为了便于展示思路和操作,我们会使用 redis-cli 讲解每个命令的直接效果,并辅以适量的 Python 示例,帮助大家用代码实现实际功能。 即使你平时主要使用 Java、Go 或其他语言,也完全不必担心——Redis 的核心命令和主要操作在各主流编程环境中都高度一致,底层思想是相通的。
我们的目标是让你不仅知其然,更知其所以然。通过边用边学,你能体会到 Redis 数据结构在解决实际业务问题时的效率与优雅。无论是命令行的直观反馈,还是脚本代码的灵活扩展,这堂课都会一步步带你掌握 Redis 的真正价值。
现在,就让我们从最基础、也是 Redis 应用场景最多的 STRING(字符串)类型开始,探索它在实际开发中如何大展身手吧!
基础数据结构
Redis 中的字符串
在 Redis 里,字符串(STRING)类型的用法其实非常直接,可以把它理解为一个带名字的小盒子,里面保存着某个值。你存进去什么,它就一字不差地还给你。不论你熟悉的是 Java、Python 还是其他编程语言,这里的字符串体验都十分贴合直觉。 举个例子,假如我们有个名字叫 user:nickname 的键,把内容设为 小明,就相当于给某人贴了标签并写上备注,随时想查、想改、甚至丢弃都很方便:
shell
键名: user:nickname
类型: string
值: 小明在 Redis 中,字符串类型的最典型用法就是存储简单的数据,比如某个用户的昵称。假设我们要保存用户“小明”的昵称为 user:nickname,只需几行命令即可实现增删查操作:
shell
$ redis-cli
redis 127.0.0.1:6379> set user:nickname 小明
OK
redis 127.0.0.1:6379> get user:nickname
"小明"
redis 127.0.0.1:6379> del user:nickname
(integer) 1
redis 127.0.0.1:6379> get user:nickname
(nil)在上面的示例中,我们通过 redis-cli 依次演示了字符串的增、查、删操作。首先用 SET 命令把 user:nickname 这个键指定为“小明”,服务端返回 OK,表示设置成功。接下来使用 GET 查询,Redis 会原样返回你刚存进去的值。 通过 DEL 命令删除之后,再次尝试获取数据时,Redis 返回 nil,说明这个键已经被清理干净。整个过程非常直接,无论是日常开发还是批量处理配置与缓存,这样的字符串操作都十分高效可靠。
除了前面介绍的获取、设置和删除字符串操作外,Redis 的 STRING 类型还支持更多灵活的用法。例如,你可以只读写字符串中的某一部分,或者把字符串值直接当作数字进行累加和递减。这些高级命令我们留到后面再来学习。现在先让我们简单的了解一下Redis。
Redis 中的列表
Redis 的列表(List)类型,是一种有序、可重复的字符串序列,非常适合处理消息队列、任务列表、聊天消息等业务场景。在实际开发中,如果你需要存储一串有顺序的内容,比如一个用户的签到记录、或者一条聊天消息流,Redis 的列表结构就能发挥巨大优势。 我们不妨举个更贴近生活的例子:假如你在做一个社交网站,需要记录某位用户“张三”的最近五条搜索历史。每次用户搜索内容,都把关键词放入列表末尾。
比如说,用户“张三”分别搜索“Redis 指南”、“美食推荐”、“美食推荐”,我们通过如下方式存储:
shell
键名: user:zhangsan:search_history
类型: list
值:
- Redis指南
- 美食推荐
- 美食推荐你可能会发现,列表里的内容不强制唯一,比如用户重复搜索“美食推荐”,依然会被记录下来。这一点非常灵活。 那怎么操作这些内容呢?Redis 给我们提供了丰富的命令。例如,我们可以用 RPUSH 往列表右侧不断添加新记录,让搜索历史不断累积;用 LPOP 可以弹出最旧的记录,控制列表长度保证只保留最近 N 条;用 LRANGE 可以一次性查看用户的全部历史。 看看实际的操作过程:
shell
redis 127.0.0.1:6379> rpush user:zhangsan:search_history "Redis 指南"
(integer) 1
redis 127.0.0.1:6379> rpush user:zhangsan:search_history "美食推荐"
(integer) 2
redis 127.0.0.1:6379> rpush user:zhangsan:search_history "美食推荐"
(integer) 3
redis 127.0.0.1:6379> lrange user:zhangsan:search_history 0 -1
1) "Redis指南"
这里,我们三次 rpush,相当于不断将搜索关键词添加到历史记录。lrange 帮我们一次查看全部历史,lindex 按位置取关键词,lpop 删除最早的记录。通过这些命令,我们就能灵活地维护一个有序、可扩展的搜索历史列表。
其实,光用这些常见的 LIST 操作,Redis 已经可以应对大量实际需求了。事实上,LIST 还支持更多强大的操作,比如从任意位置插入或删除元素,或者按照业务需求对列表进行裁剪,灵活地保留特定范围的数据。接下来,让我们把目光转向集合(SET),看它会带来哪些独特的能力。
Redis 中的集合
在 Redis 里,集合(SET)是一种很有意思的数据结构。它和列表(LIST)一样能存储多个字符串,但有一个显著区别:集合里的元素是“无序的”并且“不可重复”。举个实际业务中常见的例子——你想统计用户“张三”某天看过的所有独立商品,避免重复记录。这个需求用 SET 就非常合适,因为即使你反复添加同一个商品,最终集合里只有一份。 比如,张三在某天浏览了手机、耳机、鼠标,又无意间点了两次“耳机”这个商品。我们在 Redis 中可以这样存储:
text
键名: user:zhangsan:products_20240612
类型: set
内容(无序且唯一):
- 手机
- 耳机
- 鼠标
你可能注意到了,SET 不关心元素的顺序,只关心“有没有、唯一不唯一”。无论加多少次某个商品,集合里始终只出现一次。常用操作非常直观,比如 SADD 可以给集合加新元素,SREM 删除指定元素,SISMEMBER 检查某个商品张三到底看没看过,SMEMBERS 可以一次拉取所有商品。 来看实际操作:
shell
redis 127.0.0.1:6379> sadd user:zhangsan:products_20240612 手机
(integer) 1
redis 127.0.0.1:6379> sadd user:zhangsan:products_20240612 耳机
(integer) 1
redis 127.0.0.1:6379> sadd user:zhangsan:products_20240612 鼠标
(integer) 1
redis 127.0.0.1:6379> sadd user:zhangsan:products_20240612 耳机
(integer) 0
redis
在这个例子里,每当我们 SADD 一个新商品,结果是 1,代表“真的新加入了”;如果商品之前已经看过了,再加一次就返回 0。用 SMEMBERS 查询,得到的所有元素顺序是随机的但无重复。SISMEMBER 用来判断某个商品是否浏览过,SREM 删除指定商品,从集合剔除。 通过这些命令,你可以非常轻松地在实际项目中实现用户足迹去重、兴趣标签管理等功能,既高效又简洁。
其实,刚才展示的 SET 命令只是冰山一角。SET 在 Redis 中不仅可以添加和删除元素,还具备很强的集合运算能力,比如可以求多个集合的交集(SINTER)、并集(SUNION)和差集(SDIFF)。 遇到实际复杂业务时,你会发现 SET 的强大几乎能解决一大半“去重”“标签”“兴趣”相关的高效问题。现在我们暂时不展开,后面还有两种常用结构等着大家继续探索。接下来,一起看看 Redis 的哈希结构(HASH),看看它又能带来哪些独特的功能。
高级数据结构
Redis 中的哈希
相较于 LIST 和 SET 这种只关心一串值的结构,Redis 的 HASH 更像是一个“小型的对象”,它可以让你为同一个键组织多个属性。简单来说,HASH 就是一组字段到字段值的映射,可以非常高效地管理类似“用户信息”“订单数据”这样的结构化数据。
比如说,我们想要在 Redis 里保存一个用户的资料,可以这样设计:
shell
# 创建一个用户信息哈希
redis 127.0.0.1:6379> hset user:10086 name "张三"
(integer) 1
redis 127.0.0.1:6379> hset user:10086 age 28
(integer) 1
redis 127.0.0.1:6379> hset user:10086 city "北京"
(integer) 1
# 再次插入相同字段不会增加新字段
redis 127.0.0.1:6379> hset user:10086 age
你会发现,哈希结构支持非常灵活的属性管理:增加和更新某个字段非常省资源;查询所有字段用 hgetall,单独查某个属性用 hget,删除字段用 hdel。每次执行 hset 或 hdel,返回值数字代表字段是新插入(或真的删除)还是原来就有(或者根本没有、未发生改变)。
对熟悉 MongoDB 文档或 MySQL 行的开发者来说,Redis 的 HASH 有点类似于一条“用户记录”,唯一键(比如 user:10086)下可以存储多组键值对属性,调用命令即可高效实现增删查改。比如像“用户资料、商品详情、会话状态”这类结构化信息,用 HASH 存储会比 STRING 更直观和节约空间。
到这里,我们已经掌握了 STRING、LIST、SET、HASH 四种结构的基本用法。下一个要登场的是 Redis 非常有特色的数据结构——有序集合(ZSET),继续往下看吧!
Redis 中的有序集合
在 Redis 的核心数据结构中,有序集合(ZSET)非常有特色。它既像哈希表那样允许你用唯一的“成员”作为标识,又为每个成员加上了一个“分数”——一个可以排序的浮点数。ZSET 的优势在于,它自动帮你维护了成员的有序性,可以根据分数快速查询排名、区间,特别适合排行榜、积分榜、按优先级处理任务等场景。
假设你想记录公司销售团队每个人的当月业绩,用 ZSET 保存员工姓名及其销售额。比如:
console
键名: sales:202406
类型: zset
内容(按业绩排序):
王伟: 80000
张婷: 95000
李强: 67000这样,你就可以很轻松地统计“谁的业绩最高”“前五名都有谁”“低于6万元的员工有哪些”等等。 下面是使用 Redis 有序集合进行操作的命令流程,并配有详细的注释说明:
shell
# 添加成员及分数,王伟本月销售80000元
redis 127.0.0.1:6379> zadd sales:202406 80000 王伟
(integer) 1
# 张婷销售95000元
redis 127.0.0.1:6379> zadd sales:202406 95000 张婷
(integer) 1
# 李强销售67000元
redis 127.0.0.1:6379> zadd sales:202406 67000 李强
(integer) 1
# 再次添加张婷,不会重复插入
redis 127.0.0.1:6379>
可以看到,ZSET 的每个操作都既直观又高效。zadd 用来新加或更新成员和分数,zrange 可以根据分数排序并显示全员,zrangebyscore 支持区间精确查找,zrem 删除指定成员。商务中如排行榜、游戏积分榜、活动实时拉票等场景,都可以得益于 ZSET 的天然有序特性。
有序集合支持分数重复,但成员名是唯一的。如果你多次为同一成员赋值,会更新分数,而不是新增数据行。
到这里,你已经了解了 Redis 里数据结构的核心用法。接下来,我们会把 HASH 的结构化存储能力与 ZSET 的排序能力结合起来,解决一个实际场景中的经典问题。
课堂投票系统
既然你已经熟悉了 Redis 的核心数据结构,我们来做一个简单综合练习。假设在我们的 Redis 课程或者说这堂课上,很多同学都有参与课堂互动的经验,比如给老师出的思考题、某些知识点投赞成票,甚至给小组提出的技术方案现场投票。 为了让课堂气氛更活跃,老师决定现场统计和展示“最受欢迎的发言”和“热点答案榜单”,我们正好可以用 Redis 来设计这样的功能,实现高效、公平且透明的投票排行榜。
课堂发言投票功能
我们先设定场景:假设本堂课有 100 名学员,老师提出了一个开放讨论问题,鼓励大家踊跃发言。一天内可能有 50 个同学主动发言,其中部分内容被大家认为干货十足,大家可以现场投票支持。我们希望能快速展示“当日最受欢迎的 10 个发言”,每个发言通常能获得 3~20 个同学的点赞认同。暂时不考虑反对票。
投票时,为了保证公平性,每个同学只能为每条发言投一次票,并且希望当天投票榜单随时间实时变化。如果方案有新想法及时补充、后来的投票权重略低,那可以设计分数时兼顾发布时间与投票数——我们用“分数 = 发言提交时间 + 投票总数 × 权重分”简单处理。
时间我们用自 1970 年 1 月 1 日以来的 Unix 时间戳(秒),权重设为 100,即每个赞多加 100 分。这样一来,新颖但认可度高的发言容易冲到榜单前列,也能抑制老内容长期霸榜。
如何设计 Redis 存储
因为每条发言都需要保存内容、发表人、时间、当前点赞数等信息,我们最合适用 HASH:
shell
键名: speech:101
类型: hash
内容:
content: "分布式锁的本质是资源唯一性..."
poster: "stu:22"
time: "1717759922"
votes: "10"而为了防止刷票,我们则需要记录每位同学对每条发言的投票行为,所以用 SET,例如:
shell
键名: voted:101
类型: set
内容:
stu:12
stu:30
stu:44
…(表示学号为12、30、44的同学点过赞)
排行榜则可以用有序集合(ZSET)存储所有发言的实时分数:
shell
键名: score:speeches
类型: zset
内容:
speech:101: 1717759922+1000
speech:102: 1717759951+600
...发言榜单查询时,用 ZREVRANGE 获取前 N 条高分内容。
投票处理流程
投票操作分三步:
- 检查发言是否仍在当天(用时间戳判断)
- 用 SADD 尝试把自己的学号添加进该发言的投票 SET,判重
- 如果第一次投,ZINCRBY 增加发言 ZSET 分数(+100),同时用 HINCRBY 让 votes 字段 +1
流程简图如下:
发布与榜单查询
每当有新发言发布,老师后台用 INCR 分配自增 ID,HMSET 存储内容,用 SADD 把发言人自己自动加入投票 SET(首个赞),ZADD 将分数写入 ZSET。当天结束后可以 SETEX 设置投票 SET 自动过期,节省内存。
榜单查询时,我们使用 ZREVRANGE score:speeches 0 9 获取“当日十强发言”的 ID,然后依次查详情:
shell
redis> ZREVRANGE score:speeches 0 9
1) "speech:108" 2) "speech:105" ...
redis> HGETALL speech:108话题分组与圈子 PK
如果课堂有多个技术方向分组,我们希望展示每组最受欢迎的发言榜单。这时每个小组可用 SET 保存所有归属于该组的发言 ID:
shell
键名: group:go
类型: set
内容: speech:101, speech:103, speech:107结合总排行榜,ZINTERSTORE 可用来把“Go小组发言”与全班总分榜交集,只显示该组内的高分发言:
shell
redis> ZINTERSTORE score:go 2 group:go score:speeches AGG MAX
redis> ZREVRANGE score:go 0 4只有既在 group:go,又在 score:speeches 的发言会进榜。榜单底层可以设置自动过期,减少压力。
这样,我们在一堂课内,就能用 Redis 快速实现实时发言投票、班级榜单和小组精英 PK 赛。你也可以根据每节课实际需要,按需修改排行榜规则。如果你亲自用 redis-cli 操作这些命令,就可以更深刻理解 Redis 在互动场景下的能力!
实战练习
练习1:字符串基本操作
假设我们需要存储一个用户的昵称和年龄信息。首先,请执行以下命令设置初始数据:
shell
redis-cli set user:nickname "小明"
redis-cli set user:age "25"现在请你:
- 查询用户小明的昵称
- 将用户的年龄改为30岁
- 删除用户的年龄信息
练习2:列表操作练习
假设我们要记录一个用户的搜索历史。请先执行以下命令设置初始数据:
shell
redis-cli rpush user:search:history "Redis教程" "Python基础" "算法导论"现在请你:
- 查看用户的完整搜索历史
- 在搜索历史的开头添加"机器学习"关键词
- 从搜索历史的末尾删除一个关键词
练习3:集合操作练习
假设我们要记录用户浏览过的商品种类。请先执行以下命令设置初始数据:
shell
redis-cli sadd user:viewed:products "手机" "电脑" "耳机"现在请你:
- 查看用户浏览过的所有商品种类
- 添加一个新商品"键盘"到浏览记录中
- 检查用户是否浏览过"鼠标"
- 移除一个商品"耳机"从浏览记录中
练习4:哈希操作练习
假设我们要存储一个学生的成绩信息。请先执行以下命令设置初始数据:
shell
redis-cli hset student:001 name "张三" math "85" english "92"现在请你:
- 查看学生的所有信息
- 查询学生的数学成绩
- 为学生添加语文成绩"88"
- 删除学生的英语成绩
练习5:有序集合操作练习
假设我们要记录游戏玩家的得分排行榜。请先执行以下命令设置初始数据:
shell
redis-cli zadd game:scores 1500 "玩家A" 1200 "玩家B" 1800 "玩家C"现在请你:
- 查看所有玩家的得分(从低到高排序)
- 查看得分最高的3名玩家
- 为玩家A增加200分
- 查询玩家B的排名