Redis 内存优化
在计算机的世界里,内存就是最宝贵的资源。假如你是一家大型电商平台的架构师,每天要应对数千万用户的购物车、浏览记录和个人偏好。如果每个用户数据都占用太多内存,服务器很快就会吃不消,系统变慢不说,用户体验也会大打折扣。
所以,我们有必要深入掌握Redis的内存优化技巧。通过合理选择数据结构、巧妙设计分片策略,以及灵活运用位运算,我们能够把原本需要70GB内存的数据压缩到3GB以下。这种优化方式不仅能大幅降低硬件成本,还能提升系统整体性能。
接下来,我们会介绍三种核心的内存优化方法:短结构优化、分片结构设计和位字节打包技术。这些方法不仅帮你节省宝贵内存,还能让Redis在快照、AOF重写、主从同步等场景下表现更加高效。
短结构优化
当我们谈论Redis的“短结构”时,实际上是在讨论一种非常聪明的存储策略。Redis为LIST、HASH、ZSET和SET这些数据结构提供了特殊的紧凑存储方式,当数据量较小时,Redis会自动选择更加节省空间的编码方式。
让我们从一个电商平台的商品推荐系统开始理解这个概念。假设我们有一个用户最近浏览的商品列表,传统的双向链表存储方式会为每个商品ID创建一个节点,每个节点包含指向前一个和后一个节点的指针,以及指向实际数据的指针。在32位系统上,仅仅为了存储一个3字节的商品ID"123",我们就需要21字节的额外开销。
ziplist
Redis的ziplist编码就像是一个精心设计的压缩算法。它将多个数据项连续存储在一个内存块中,每个数据项只包含必要的长度信息和实际数据,大大减少了指针和元数据的开销。
继续我们的电商例子,如果用户浏览了“手机”、“电脑”、“耳机”这三个商品,ziplist会将它们存储为:长度1、长度2、“手机”、长度1、长度2、“电脑”、长度1、长度2、“耳机”。每个商品只需要2字节的额外开销,相比传统方式的21字节,节省了90%以上的空间。
ziplist的“zip”并不是指压缩算法,而是指这种存储方式像拉链一样紧凑,数据项一个接一个地排列,没有空隙。
配置ziplist的使用条件
Redis提供了六个配置选项来控制何时使用ziplist编码:
这些配置的含义很简单:只有当数据结构中的条目数量不超过“最大条目数”,且每个条目的字节数不超过“最大条目值”时,Redis才会使用ziplist编码。一旦超出这些限制,Redis就会自动转换为标准的存储方式。 让我们通过一个实际的例子来验证这个机制。假设我们正在构建一个在线教育平台的课程章节列表:
python
# 创建课程章节列表
conn.rpush('course_chapters', '第一章:基础概念', '第二章:数据类型', '第三章:高级特性')
print(conn.debug_object('course_chapters'))输出结果会显示这个列表使用了ziplist编码,因为章节数量少于512个,且每个章节名称少于64字节。
intset
SET数据结构也有自己的紧凑存储方式,叫做intset。当SET中的所有成员都可以解释为整数,且SET的大小不超过配置限制时,Redis会将SET存储为一个排序的整数数组。
想象一下,我们正在为一家连锁餐厅构建会员积分系统。每个会员都有一个唯一的积分ID,这些ID都是整数。如果我们使用普通的SET来存储活跃会员的积分ID,Redis会自动选择intset编码,因为所有成员都是整数,且数量在合理范围内。
python
# 添加会员积分ID到活跃会员集合
conn.sadd('active_members', 1001, 1002, 1003, 1004, 1005)
print(conn.debug_object('active_members'))这个SET会被存储为intset,占用更少的内存空间,同时保持所有SET操作的快速执行。 虽然紧凑存储能够显著减少内存使用,但我们也要理解其中的性能权衡。当ziplist或intset变得很长时,读取和更新操作可能会变慢,因为Redis需要解码整个结构或移动内存中的数据。
让我们通过一个性能测试和实际输出示例来理解这个问题。假设我们有一个电商平台的商品标签系统,每个商品可能有多个标签:
python
import time
def test_ziplist_performance(conn, key, length, operations):
"""测试不同长度ziplist的性能"""
conn.delete(key)
# 创建指定长度的列表
conn.rpush(key, *range(length))
start_time = time.time()
# 执行指定次数的操作
for _ in range(operations):
conn.rpoplpush(key, key) # 将右端元素移到左端
end_time = time.time()
return operations / (end_time - start_time)
# 测试不同长度的性能
shell
长度 100: 60976 操作/秒
长度 1000: 51282 操作/秒
长度 5000: 32051 操作/秒
长度 10000: 23801 操作/秒
长度 50000: 17240 操作/秒测试结果显示,当列表长度在1000以下时,性能保持在50000操作/秒以上。但当长度达到50000时,性能会下降到约17000操作/秒。进一步,如果列表长度达到100000,性能可能急剧下降到每秒500操作左右。
在实际应用中,建议将ziplist的最大条目数控制在500-2000之间,最大条目值控制在128字节以下,这样既能获得内存优化的好处,又能保持良好的性能。
键名优化的细节
除了数据结构本身的优化,我们还可以通过优化键名来节省内存。在大型系统中,键名的长度累积起来可能会占用相当可观的内存空间。
比如,在用户管理系统中,使用“user:1001”比“user_profile:1001”更节省空间,使用“order:20231201:1001”比“daily_order_record:20231201:user_1001”更高效。虽然单个键名的差异很小,但在处理数百万或数十亿条记录时,这些微小的优化会带来显著的内存节省。
分片结构
当我们面对海量数据时,单个数据结构可能会变得过于庞大,无法享受短结构的优化。这时,分片技术就派上用场了。分片就像是将一本厚厚的字典分成多个小册子,每个小册子只包含特定字母开头的词汇,这样查找起来更加高效。
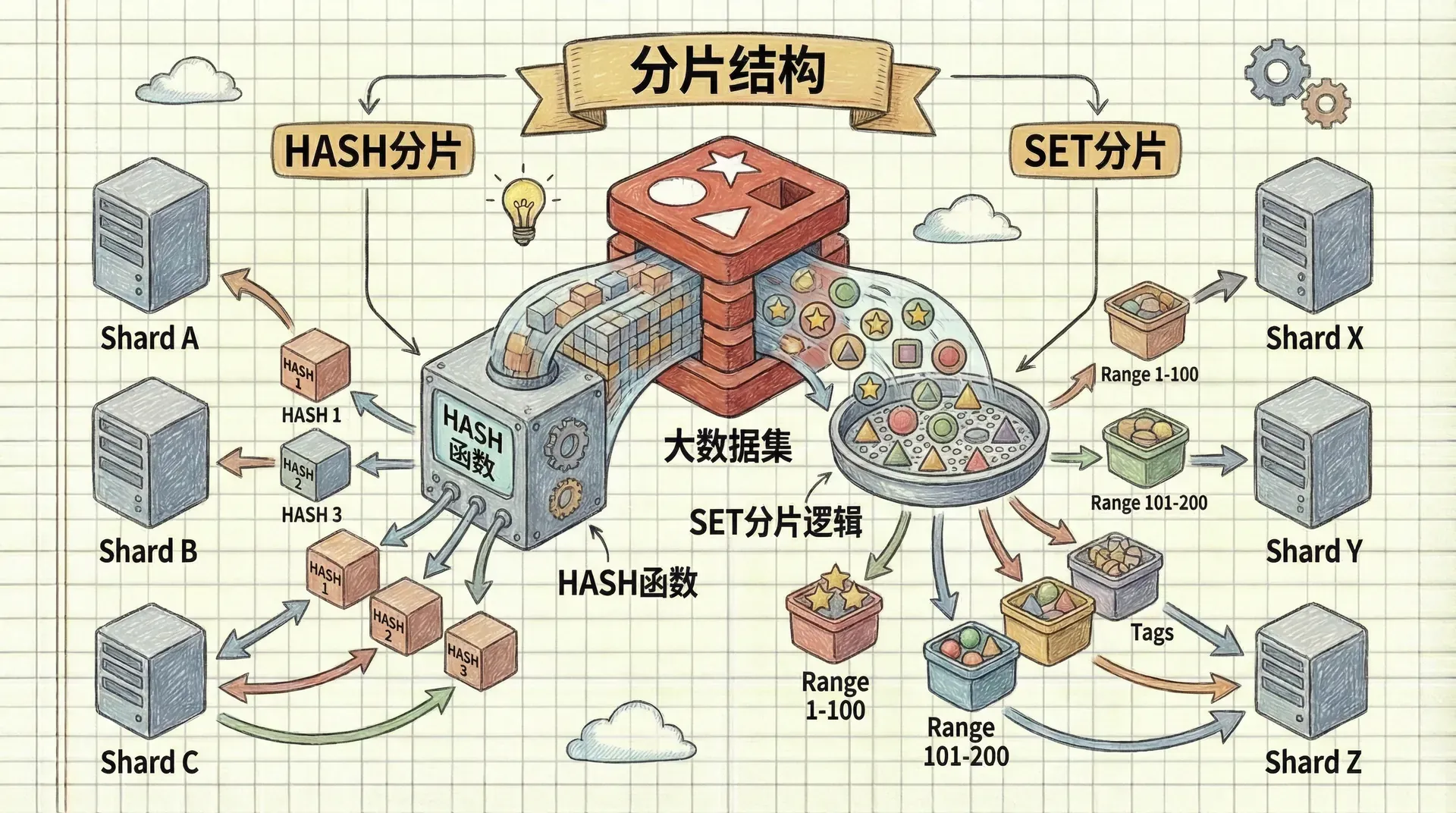
在Redis中,分片意味着我们将一个大数据结构拆分成多个小的数据结构,每个小结构都能享受ziplist或intset的优化。比如,原本存储100万个用户信息的单个HASH,我们可以分成1000个小的HASH,每个HASH只存储1000个用户的信息。
HASH分片
让我们通过一个实际的例子来理解HASH分片。假设我们正在构建一个社交平台的用户资料系统,需要存储数百万用户的详细信息。 传统的做法是将所有用户资料存储在一个大的HASH中:
python
# 传统方式:所有用户资料存储在一个HASH中
conn.hset('user_profiles', 'user_1001', json.dumps({
'name': '张三',
'age': 25,
'city': '北京',
'occupation': '软件工程师'
}))这种方式的问题在于,当用户数量达到几十万时,这个HASH会变得非常大,无法使用ziplist优化。 分片的方式是将用户资料分散到多个小的HASH中:
python
def shard_key(base, key, total_elements, shard_size):
"""计算分片键"""
if isinstance(key, (int, long)) or key.isdigit():
# 对于数字键,使用数值分片
shard_id = int(str(key), 10) // shard_size
else:
# 对于字符串键,使用哈希分片
shards = 2 * total_elements // shard_size
shard_id = binascii.crc32(key) % shards
return
这种分片方式的优势在于,每个小的HASH都能使用ziplist编码,从而显著减少内存使用。在我们的测试中,原本需要44MB内存的用户资料数据,通过分片后只需要12MB,节省了70%的内存空间。
SET分片
SET分片在独立访客统计场景中特别有用。假设我们正在为一家电商平台统计每日的独立访客数量。 传统的做法是使用一个大的SET来存储所有访客的会话ID:
python
# 传统方式:所有访客会话ID存储在一个SET中
conn.sadd('daily_visitors:20231201', 'session_uuid_1', 'session_uuid_2', ...)这种方式的问题在于,UUID通常很长(36个字符),而且单个SET无法享受intset优化。 我们可以通过提取UUID的前15个十六进制数字来优化存储:
python
def shard_sadd(conn, base, member, total_elements, shard_size):
"""分片SET的ADD操作"""
shard = shard_key(base, 'x' + str(member), total_elements, shard_size)
return conn.sadd(shard, member)
def count_visit(conn, session_id):
"""统计访客访问"""
today = date.today()
key = f'unique:{today.isoformat()}'
expected = get_expected_visitors(conn, key, today)
# 提取UUID的前15个十六进制数字
visitor_id = int(session_id.replace(
这种方法的巧妙之处在于,我们将128位的UUID压缩为56位的整数,既节省了存储空间,又能使用intset优化。 根据生日悖论的计算,在250万独立访客以内,碰撞概率不到1%,这对于大多数应用场景来说是完全可接受的。
在使用分片技术时,我们必须保持分片参数的一致性。total_elements和shard_size这两个参数决定了数据如何分布到不同的分片中,一旦改变这些参数,数据的分片位置就会发生变化。
这就是为什么我们需要在系统设计初期就确定这些参数,或者建立完善的数据迁移机制来处理参数变更的情况。
位和字节打包
当我们面对大量固定长度的数据时,传统的键值存储方式可能会造成巨大的内存浪费。这时,Redis的位操作命令就展现出了它们的威力。
Redis提供了四个关键的位操作命令:GETRANGE、SETRANGE、GETBIT和SETBIT。这些命令让我们能够像操作数组一样操作Redis的STRING类型,实现极致的空间压缩。
让我们从一个地理位置存储的例子开始。假设我们正在为一家外卖平台构建用户地理位置系统,需要存储数百万用户的省市信息。
地理位置数据的紧凑存储
我们可以将省市信息编码为2字节的数据:第一个字节表示国家/地区代码,第二个字节表示省份/州代码。
python
# 中国省份代码表
PROVINCES = {
'BJ': 1, 'TJ': 2, 'HE': 3, 'SX': 4, 'NM': 5, 'LN': 6, 'JL': 7, 'HL': 8,
'SH': 9, 'JS': 10, 'ZJ'
这种存储方式的优势在于,每个用户的地理位置信息只需要2字节,相比传统的键值存储方式,可以节省90%以上的内存空间。
聚合统计的高效实现
有了紧凑的地理位置存储,我们就可以高效地进行各种聚合统计。比如,统计某个省份有多少用户,或者分析用户的地理分布情况。
python
def aggregate_locations(conn):
"""聚合所有用户的地理位置统计"""
provinces = defaultdict(int)
max_id = int(conn.zscore('location:max', 'max'))
max_shard = max_id // (2**20)
for shard_id in range(max_shard + 1):
# 读取整个分片的数据
data = conn.get(f'location:
除了地理位置存储,位操作还可以用于实现各种高效的统计功能。比如,我们可以使用SETBIT和GETBIT来实现用户行为标记系统。
python
def mark_user_action(conn, user_id, action_type):
"""标记用户执行了某种行为"""
# 将用户ID和行为类型组合成位偏移
bit_offset = user_id * 10 + action_type # 假设有10种行为类型
shard_id = bit_offset // (8 * 1024 * 1024) # 每个分片8MB
local_offset = bit_offset % (8 * 1024 * 1024)
conn.setbit(f'user_actions:{
这种位操作方式的优势在于,每个用户的行为标记只需要1个位,相比传统的布尔值存储,可以节省87.5%的内存空间。
小结
这堂课我们学习了三种核心的Redis内存优化方法,它们能够显著降低内存消耗并提升系统性能。首先,短结构优化借助ziplist和intset等智能编码方式,在保持良好操作性能的同时,将内存使用量大幅压缩,关键在于合理配置编码触发条件,实现内存与性能的平衡。 其次,分片结构技术通过将大型数据结构拆分为多个小结构,使每个分片都能享受短结构的优化优势,不论是HASH还是SET都能通过合适的分片策略提升效率。 最后,位和字节打包则展现了内存压缩的极致可能,通过对STRING类型的直接位操作,能够极为高效地存储固定长度数据。
在实际应用中,这三种方法往往需要结合使用。我们可以先用分片技术将大结构拆分成小结构,然后通过短结构优化减少每个小结构的内存使用,最后通过位操作进一步压缩固定长度的数据。