Redis搜索应用 | 自在学Redis搜索应用
在当今信息爆炸的时代,快速准确地搜索和筛选数据已经成为每个应用的核心需求。无论是电商平台的商品搜索、内容管理系统的文章检索,还是广告定向系统的精准投放,都离不开高效的搜索技术。Redis作为内存数据库,其丰富的数据结构为我们提供了构建高性能搜索系统的强大工具。
所以这节课我们探讨如何利用Redis的SET和ZSET数据结构来解决各种搜索型问题。我们将从最基础的倒排索引开始,逐步构建完整的搜索系统,最终实现广告定向和职位匹配等复杂应用场景。
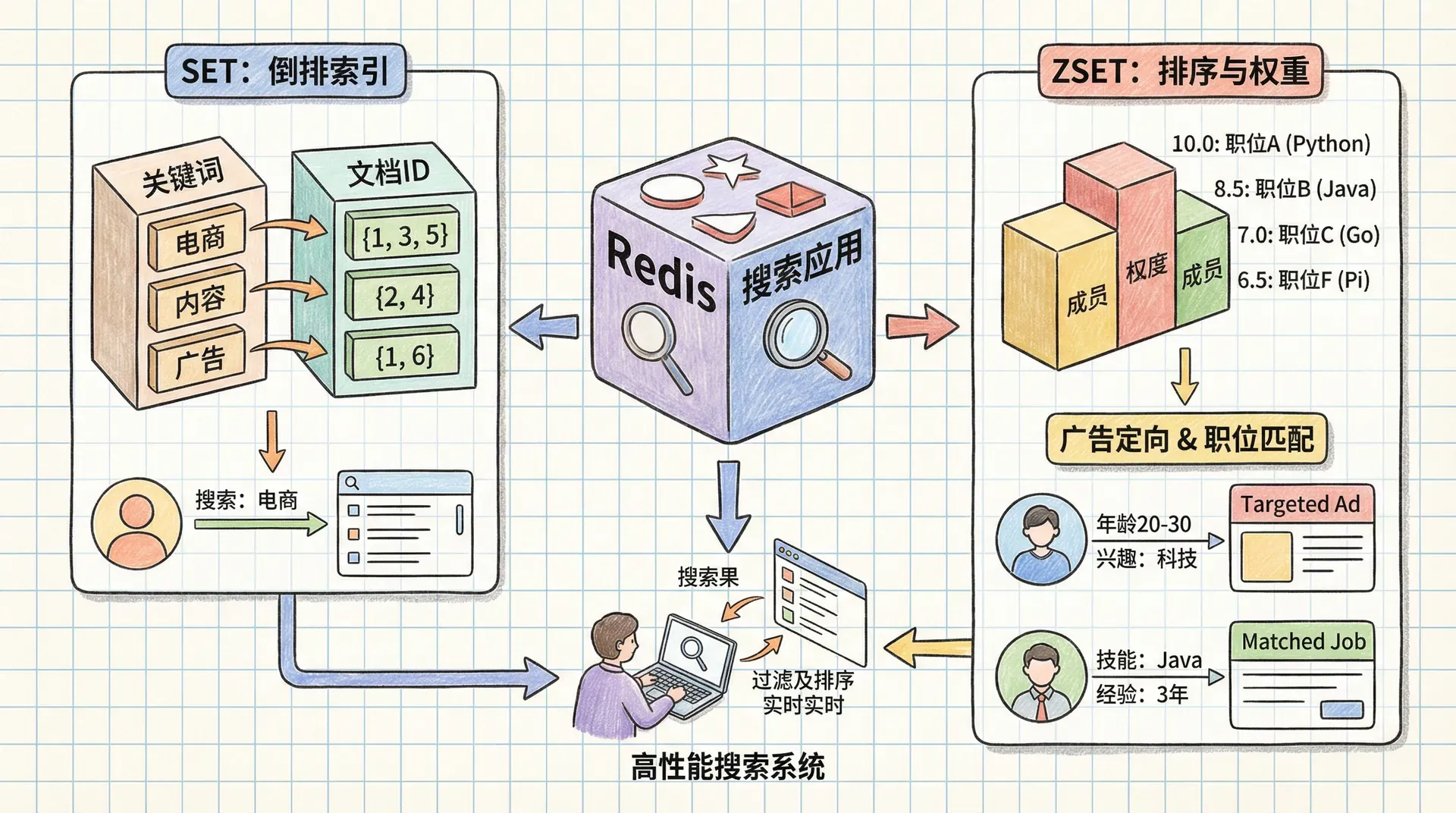
利用 Redis 实现高效搜索引擎
在大规模数据检索场景下,优化查询效率是搜索系统的核心目标。传统做法如线性遍历文档集合(例如在“小李学习平台”手动查找包含“Redis缓存优化”的教程),不仅效率低下,而且无法应对数据量快速增长带来的性能挑战。
专业的搜索引擎通过预处理与索引机制,将原始文档内容转化为结构化的数据索引,实现毫秒级数据检索。典型代表就是“倒排索引”(Inverted Index),它预先维护了“词汇到文档ID”的映射关系,有效规避了全量扫描的问题。
倒排索引是一种反向映射结构:以词条为主键,记录其出现的全部文档ID。当用户发起关键词检索时,系统可直接基于索引查找相关文档集合,极大提升查询性能。
倒排索引原理
让我们用一个具体的例子来理解倒排索引的工作原理。假设我们有一个技术博客平台"小李学习",目前只有三篇教程:
- 《Redis缓存策略详解》- 内容包含:redis、缓存、策略、优化
- 《Python数据分析实战》- 内容包含:python、数据、分析、实战、redis
- 《MySQL性能调优指南》- 内容包含:mysql、性能、调优、数据库、优化`
传统的正向索引是这样的:每篇教程记录自己包含哪些词。而倒排索引则是反向的:每个词记录自己出现在哪些教程中。
这种反向思维带来了巨大的性能优势。当用户搜索"redis"时,系统不需要扫描所有三篇教程,而是直接查询"redis"对应的教程列表,立即得到教程1和教程2。如果用户搜索"redis 优化",系统只需要对两个词对应的教程列表求交集,就能快速找到同时包含这两个词的教程。
Redis的SET数据结构天然适合存储这种倒排索引。每个词对应一个SET,SET的成员就是包含该词的教程ID。当我们需要查找包含多个词的教程时,可以使用Redis的SINTER命令对多个SET求交集。
分词与停用词
在构建倒排索引之前,我们需要对教程内容进行"分词"处理。分词就是将连续的文本切分成一个个独立的词汇单元。这个过程看似简单,实际上涉及很多细节处理。
首先,我们需要定义什么是"词"。在中文环境中,我们通常按照字符或词语来分词;在英文环境中,我们通常按照空格和标点符号来分词。为了简化示例,我们以中文为例,定义词为有意义的词汇单元。
import re
# 定义停用词集合 - 这些词出现频率太高,对搜索意义不大
STOP_WORDS = {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要',
停用词的处理很重要。像“的、了、在”这样的词在几乎所有文档中都会出现,如果不对它们进行过滤,会导致索引过于庞大,搜索效率降低。同时,这些词对搜索结果的相关性判断也没有太大帮助。
分词完成后,我们就可以开始构建倒排索引了。这个过程就是将每篇教程的词汇添加到对应的SET中:
def index_tutorial(conn, tutorial_id, content):
"""
为教程建立倒排索引
参数:
conn - Redis连接对象
tutorial_id - 教程唯一标识
content - 教程内容
返回: 添加到索引中的词汇数量
"""
# 对教程内容进行分词
words = tokenize_chinese(content)
# 使用管道批量执行Redis命令,提高性能
pipeline = conn.pipeline(True)
# 将教程ID添加到每个词对应的SET中
for word in words:
pipeline.sadd(f'idx:{word}'
通过这种方式,我们为每篇教程建立了倒排索引。当用户搜索“redis”时,Redis会返回包含tutorial_001和tutorial_002的SET;当用户搜索“redis 优化”时,我们可以对两个SET求交集,得到同时包含这两个词的教程。
这种基于倒排索引的搜索方式具有几个显著优势:搜索速度与文档数量无关,只与查询词的数量相关;可以轻松支持复杂的布尔查询(AND、OR、NOT);索引结构简单,易于理解和维护。
实现基础搜索
现在我们已经理解了倒排索引的原理,接下来学习如何在Redis中实现各种搜索操作。Redis的SET数据结构提供了丰富的集合运算命令,这些命令正是我们构建搜索引擎的核心工具。
让我们先了解三种基本的集合操作:交集(SINTER)、并集(SUNION)和差集(SDIFF)。这些操作对应了搜索中的不同逻辑需求。
为了便于使用这些操作,我们创建一些辅助函数来封装Redis的SET命令:
import uuid
def _set_common(conn, method, names, ttl=30, execute=True):
"""
执行SET操作的通用辅助函数
参数:
conn - Redis连接对象
method - SET操作方法名(sinterstore, sunionstore, sdiffstore)
names - 要操作的SET名称列表
ttl - 结果SET的过期时间(秒)
execute - 是否立即执行命令
返回: 结果SET的ID
"""
# 生成唯一的临时SET标识符
result_id = str(uuid.uuid4())
# 设置管道,确保操作的原子性
pipeline = conn.pipeline(True) if
高级搜索查询处理
在实际的搜索应用中,用户往往需要更复杂的查询功能。比如搜索“缓存”时,可能希望同时匹配“缓存”、“缓存策略”、“缓存优化”等同义词;或者搜索“数据库”时,希望排除包含“nosql”的教程。
为了实现这些高级功能,我们需要设计一个查询解析器,能够理解用户的搜索意图并转换为相应的Redis操作。
import re
# 查询解析的正则表达式:匹配带前缀的词
QUERY_RE = re.compile(r"[+-]?[\u4e00-\u9fff]+")
def parse_query(query):
"""
解析搜索查询,支持同义词和排除词
参数: query - 用户输入的搜索查询
返回: (同义词组列表, 排除词列表)
查询语法说明:
- 普通词: 必须包含的词
- +词: 同义词(与前面的词是同义词)
- -词: 排除词(不包含的词)
示例: "缓存 +缓存策略 +缓存优化 数据库 -nosql"
"""
unwanted = set() # 排除词集合
all_groups
通过这种查询解析方式,我们可以支持非常灵活的搜索语法。用户可以自然地表达复杂的搜索需求,系统会自动将其转换为高效的Redis SET操作。这种设计既保持了搜索功能的强大性,又确保了良好的用户体验。
搜索结果的智能排序
搜索功能只是解决了“找到相关内容”的问题,但用户真正需要的是“找到最相关的内容”。当搜索“Redis”时,可能有数百篇教程都包含这个关键词,但用户最想看到的可能是最新发布的、最受欢迎的,或者最权威的教程。这就需要对搜索结果进行智能排序。
使用SORT命令排序
Redis的SORT命令是一个非常强大的工具,它可以对LIST或SET中的元素进行排序,并且可以引用外部数据进行排序。这个特性正好满足我们对搜索结果排序的需求。
让我们以技术教程网站为例,假设每篇教程都有以下属性:标题、创建时间、最后更新时间、作者ID、点赞数等。我们可以将这些信息存储在Redis的HASH结构中,然后使用SORT命令按照不同的标准对搜索结果进行排序。
def search_and_sort(conn, query, result_id=None, ttl=300, sort="-updated", start=0, num=20):
"""
搜索并排序结果
参数:
conn - Redis连接对象
query - 搜索查询
result_id - 之前的搜索结果ID(用于分页)
ttl - 结果缓存时间
sort - 排序字段(-updated表示按更新时间降序)
start - 起始位置(分页)
num - 返回数量
返回: (总数量, 结果列表, 结果ID)
"""
# 判断是否降序排序
desc = sort.startswith('-')
SORT命令的强大之处在于它支持分页和缓存。我们可以先执行一次搜索,然后将结果ID保存起来,后续可以对这个结果进行不同的排序操作,而不需要重新搜索。这对于用户体验和系统性能都非常重要。
ZSET复合排序
虽然SORT命令功能强大,但它有一个限制:每次只能按照一个字段进行排序。在实际应用中,我们往往需要综合考虑多个因素。比如,我们希望教程既要有较高的点赞数,又要相对较新,还要考虑作者的权威性。
这时候,ZSET就派上用场了。我们可以将多个评分因素组合成一个综合分数,然后使用ZSET来存储和排序。Redis的ZINTERSTORE和ZUNIONSTORE命令支持权重参数,让我们可以灵活地调整不同因素的权重。
让我们实现一个支持复合排序的搜索系统:
def search_and_zsort(conn, query, result_id=None, ttl=300,
like_weight=1, time_weight=0, author_weight=0,
start=0, num=20, desc=True):
"""
使用ZSET进行复合排序搜索
参数:
conn - Redis连接对象
query - 搜索查询
result_id - 之前的搜索结果ID
ttl - 结果缓存时间
like_weight - 点赞数权重
time_weight - 时间权重
ZSET复合排序的优势在于我们可以动态调整不同因素的权重,而不需要修改代码。比如在技术教程网站中,我们可以根据时间段调整时间权重:在教程刚发布时,时间权重较高;在教程发布几天后,内容质量权重逐渐增加。这种灵活性让我们的排序系统能够适应不同的业务需求。
字符串数据排序
在实际应用中,我们不仅需要对数值进行排序,还需要对字符串进行排序。比如按教程标题的字母顺序排序,或者按作者名的字母顺序排序。Redis的ZSET虽然只能存储数值分数,但我们可以通过巧妙的方法将字符串转换为数值,从而实现字符串排序。
字符串转数值的核心思想是:将字符串的每个字符转换为ASCII码值,然后按照一定的规则组合成一个数值。这样,字符串的比较就变成了数值的比较。
def string_to_score(string, ignore_case=False):
"""
将字符串转换为数值分数,用于ZSET排序
参数:
string - 要转换的字符串
ignore_case - 是否忽略大小写
返回: 转换后的数值分数
"""
if ignore_case:
string = string.lower()
# 只取前6个字符,避免数值过大
pieces = list(map(ord, string[:6]))
# 如果字符串不足6个字符,用-1填充
while len(pieces) < 6
字符串转数值的方法虽然有效,但有一些限制。由于我们只使用前6个字符,对于超过6个字符的字符串,排序可能不够精确。在实际应用中,我们需要根据具体的业务需求来调整这个限制,或者考虑使用其他排序方法。
通过以上三种排序方法,我们可以构建一个功能完整的搜索排序系统。SORT命令适合简单的单字段排序,ZSET复合排序适合复杂的多因素排序,字符串转数值适合字符串排序。这些技术的组合使用,让我们能够为用户提供精准、灵活的搜索结果排序功能。
构建广告定向系统
搜索和排序技术不仅适用于内容检索,在广告定向系统中同样发挥着重要作用。现代互联网广告系统需要在毫秒级时间内,从成千上万的广告中选择最合适的广告展示给用户,同时确保广告主获得最大的投资回报。这背后离不开高效的搜索和排序算法。
广告系统基础
广告定向系统的核心挑战在于如何快速找到“最赚钱”的广告。这里的“赚钱”不仅仅指广告主愿意支付的费用,还包括用户点击广告的概率。一个愿意支付高额费用但用户从不点击的广告,其实际价值可能远低于一个费用适中但点击率很高的广告。
为了统一衡量不同广告的价值,广告行业引入了eCPM(estimated Cost Per Mille)概念,即每千次展示的预估收入。eCPM将不同类型的广告(按展示付费、按点击付费、按行动付费)统一到同一个价值体系中。
让我们实现eCPM的计算逻辑:
def cpc_to_ecpm(views, clicks, cpc):
"""
将CPC广告转换为eCPM
参数:
views - 广告展示次数
clicks - 广告点击次数
cpc - 每次点击的费用
返回: eCPM值
"""
if views == 0:
return 0
return 1000.0 * cpc * clicks / views
def cpa_to_ecpm(views, actions, cpa):
"""
将CPA广告转换为eCPM
参数:
views - 广告展示次数
actions - 用户行动次数
cpa - 每次行动的费用
eCPM的计算基于历史数据,对于新广告,我们需要使用行业平均值或类似广告的数据来估算。随着广告展示次数的增加,我们可以根据实际表现不断调整eCPM值,使广告定向越来越精准。
广告索引设计
广告定向系统的关键在于如何让每一条广告都能被“精准”地投放给合适的用户。这就需要我们为每条广告建立一个高效的“广告索引”,类似于图书馆给每本书贴标签,让后续查找更容易。
与单纯的内容搜索不同,广告定向要同时满足两类需求:
- 必须满足的条件:这些条件广告必须满足才能被展示,比如用户所在的地理位置,只有“北京”的广告才能展示给北京的用户。
- 可选的条件:这些条件可以提高广告与用户的相关性,但不是必须的,比如广告的内容与用户正在浏览的页面内容相匹配。
我们可以把这些条件想象成“门槛”和“加分项”:
- 门槛(必须条件)决定广告能不能被初步“筛选出来”。
- 加分项(可选条件)决定在一堆被筛选出来的广告中,哪些广告更相关、更合适,排序会靠前。
下面以本地商家(比如咖啡店)投放广告为例,说明如何一步步为广告建立索引,让系统能快速而精准地找到合适的广告。
def index_ad(conn, ad_id, locations, content, ad_type, value):
"""
为广告建立索引
参数:
conn - Redis连接对象
ad_id - 广告唯一标识
locations - 目标地理位置列表
content - 广告内容描述
ad_type - 广告类型(cpm, cpc, cpa)
value - 广告价值(费用或出价)
"""
pipeline = conn.pipeline(True)
# 为每个地理位置建立索引
for location in locations:
pipeline.sadd(f'req:{location}', ad_id)
# 对广告内容进行分词
智能定向算法
要实现广告定向,其实就是要让不同的用户在不同的页面和位置,看到最可能对他们有用、同时给平台带来最大收益的广告。这个算法背后的流程其实很好理解。
首先,系统会根据用户的地理位置,比如城市、商圈等,筛选出在这些区域投放的所有广告,只有这些广告才有资格“参赛”。
平台随后会结合用户正在浏览的页面内容,分析其中的关键词,再和候选广告的内容相关性进行比对。如果某个广告的内容和当前页面特别契合,它的分数就会高一些。
最后系统会综合考虑广告主为这些广告愿意支付的金额(eCPM),以及内容匹配获得的加分,把所有候选广告的分数都算出来,然后找出得分最高的那个。
让我们实现这个定向算法:
def target_ads(conn, locations, content):
"""
广告定向主函数
参数:
conn - Redis连接对象
locations - 用户地理位置
content - 页面内容
返回: (目标ID, 广告ID)
"""
pipeline = conn.pipeline(True)
# 第一步:位置匹配
matched_ads, base_ecpm = match_location(pipeline, locations)
# 第二步:内容匹配和eCPM计算
words, targeted_ads = finish_scoring(
pipeline, matched_ads, base_ecpm, content
)
# 记录广告展示
pipeline.incr('ads:served:'
这个广告定向系统的巧妙之处在于它将位置匹配(必须条件)和内容匹配(可选条件)分开处理。位置匹配使用SET操作快速筛选候选广告,内容匹配使用ZSET操作计算加分,最后通过权重组合得到最终的eCPM排序。这种设计既保证了定向的准确性,又确保了系统的响应速度。
通过以上设计,我们构建了一个完整的广告定向系统。系统能够根据用户的地理位置和浏览内容,快速找到最合适的广告,同时为广告主提供最大的投资回报。
从用户行为中学习
一个优秀的广告定向系统不仅要能够快速找到合适的广告,更要能够从用户的行为中学习,不断优化定向的准确性。当用户点击广告时,系统应该记录这次成功的匹配,并调整相关词汇的权重;当用户忽略广告时,系统也应该从中学习,降低相关因素的权重。
这种学习机制的核心是点击率(CTR)的追踪和优化。通过分析哪些词汇、哪些位置、哪些时间段更容易产生点击,系统可以动态调整广告的eCPM计算,让定向越来越精准。
让我们实现这个学习系统:
def record_targeting_result(conn, target_id, ad_id, words):
"""
记录广告定向结果,用于学习优化
参数:
conn - Redis连接对象
target_id - 定向ID
ad_id - 广告ID
words - 匹配的词汇
"""
pipeline = conn.pipeline(True)
# 获取广告的所有词汇
ad_terms = conn.smembers(f'terms:{ad_id}')
# 找出实际匹配的词汇
matched_words = list(words & ad_terms)
这个学习系统的好处在于它能够从每次用户交互中提取价值。无论是点击、忽略还是转化,系统都能从中学习并调整定向策略。随着数据的积累,系统会变得越来越智能,广告定向的准确性也会不断提高。
通过以上设计,我们构建了一个完整的智能广告定向系统。系统不仅能够快速找到合适的广告,还能够从用户行为中学习,不断优化定向的准确性。这种自学习的能力让广告系统能够适应不断变化的用户偏好和市场环境。
职位技能匹配
搜索技术的应用远不止内容检索和广告定向。在人力资源领域,如何快速找到符合职位要求的候选人,或者为求职者推荐合适的职位,同样是一个典型的搜索问题。让我们以在线招聘平台为例,探索如何使用Redis的SET和ZSET数据结构来解决技能匹配问题。
需求分析
在传统的职位匹配系统中,我们可能会为每个职位创建一个SET,存储该职位需要的所有技能。当求职者搜索职位时,系统会逐一检查每个职位的技能要求,判断求职者是否具备所有必需的技能。
这种方法虽然直观,但存在明显的性能问题:随着职位数量的增加,检查时间会线性增长。当平台有数万个职位时,每次搜索都需要检查所有职位,响应时间会变得不可接受。
不难想到更好的方法是采用“反向思维”:为每个技能创建一个SET,存储需要该技能的所有职位。这样,当求职者搜索时,我们可以快速找到包含其技能的职位,然后通过SET操作判断哪些职位完全匹配。
反向思维建模
让我们重新设计职位匹配系统。我们将为每个技能创建一个SET,存储需要该技能的职位ID;同时创建一个ZSET,记录每个职位需要的技能总数。
这种设计的优势在于:我们可以使用SET的交集操作快速找到同时包含多个技能的职位,然后使用ZSET操作判断求职者是否具备所有必需的技能。
def index_job(conn, job_id, required_skills):
"""
为职位建立技能索引
参数:
conn - Redis连接对象
job_id - 职位唯一标识
required_skills - 必需技能列表
"""
pipeline = conn.pipeline(True)
# 为每个技能建立索引
for skill in required_skills:
pipeline.sadd(f'idx:skill:{skill}', job_id)
# 记录职位需要的技能总数
pipeline.zadd('idx:jobs:req', {job_id: len(
这个职位匹配系统的巧妙之处在于它使用了“技能差距”的概念。通过计算职位要求的技能数量减去求职者具备的技能数量,我们可以快速找到差距为0的职位,即完全匹配的职位。这种方法避免了逐一检查每个职位的繁琐过程。
实现技能搜索
接下来,我们来丰富这个职位匹配系统,让它变得更加实用和贴心。比如:不仅可以找出“完全匹配”的职位,还可以把“部分匹配但也很合适”的职位推荐给求职者;再比如结合地理位置帮大家筛选附近的工作机会。
def find_partial_matches(conn, candidate_skills, min_match_ratio=0.5):
"""
找到部分匹配的职位
参数:
conn - Redis连接对象
candidate_skills - 求职者技能列表
min_match_ratio - 最小匹配比例
返回: [(职位ID, 匹配比例), ...]
"""
# 构建技能权重字典
skills = {}
for skill in set(candidate_skills):
skills[f'skill:{skill}'] = 1
# 计算求职者具备的技能数量
job_scores
通过这种设计,我们可以构建一个功能完整的职位匹配系统。系统不仅能够找到完全匹配的职位,还能够推荐部分匹配的职位,帮助求职者发现更多机会。同时,地理位置筛选功能让求职者能够找到符合自己期望的工作地点。
小结
通过本部分的学习,我们了解了Redis在搜索型应用中的强大能力。从最基础的倒排索引开始,我们逐步构建了完整的搜索系统,并将其应用到了广告定向和职位匹配等实际场景中。
虽然我们在这里介绍的技术已经能够解决很多实际问题,但还有很多扩展的可能性。比如,我们可以引入机器学习算法来优化搜索结果排序,可以使用更复杂的文本分析技术来理解用户意图,可以结合用户画像来提供个性化推荐。
Redis的丰富数据结构为我们提供了无限的可能性。SET和ZSET只是开始,LIST、HASH、Stream等数据结构同样可以应用到搜索系统中,创造出更多创新的解决方案。
搜索技术的核心在于理解问题的本质。无论是内容搜索、广告定向还是职位匹配,本质上都是“找到最相关的内容”的问题。掌握了这个本质,我们就能够灵活运用Redis的各种数据结构,构建出高效、智能的搜索系统。
'去'
,
'你'
,
'会'
,
'着'
,
'没有'
,
'看'
,
'好'
,
'自己'
,
'这'
}
# 中文分词的正则表达式:匹配中文字符
CHINESE_WORDS_RE = re.compile(r'[\u4e00-\u9fff]+')
def tokenize_chinese(content):
"""
将中文文档内容分词,去除停用词
参数: content - 原始文档内容
返回: 去重后的词汇集合
"""
words = set()
# 使用正则表达式提取中文词汇
for match in CHINESE_WORDS_RE.finditer(content):
word = match.group()
# 只保留长度至少为2的词
if len(word) >= 2:
words.add(word)
# 返回去除停用词后的词汇集合
return words - STOP_WORDS
# 测试中文分词功能
tutorial_content = "Redis缓存优化策略详解,提升系统性能的关键技术"
tokens = tokenize_chinese(tutorial_content)
print(f"分词结果: {tokens}")
# 输出: {'redis', '缓存', '优化', '策略', '详解', '提升', '系统', '性能', '关键', '技术'}
, tutorial_id)
# 执行所有命令并返回添加的词汇数量
return len(pipeline.execute())
# 示例:为小李学习平台的教程建立索引
def build_tutorial_index():
tutorials = {
'tutorial_001': 'Redis缓存策略详解,提升系统性能的关键技术',
'tutorial_002': 'Python数据分析实战,从入门到精通的完整指南',
'tutorial_003': 'MySQL性能调优指南,数据库优化的最佳实践'
}
# 假设conn是Redis连接对象
for tutorial_id, content in tutorials.items():
word_count = index_tutorial(conn, tutorial_id, content)
print(f"为教程 {tutorial_id} 添加了 {word_count} 个词汇到索引")
execute
else
conn
# 为所有SET名称添加'idx:'前缀
prefixed_names = [f'idx:{name}' for name in names]
# 调用相应的SET操作方法
getattr(pipeline, method)(f'idx:{result_id}', *prefixed_names)
# 设置结果SET的过期时间
pipeline.expire(f'idx:{result_id}', ttl)
if execute:
pipeline.execute()
return result_id
def intersect(conn, items, ttl=30, _execute=True):
"""
计算多个SET的交集
返回同时包含所有指定词的教程
"""
return _set_common(conn, 'sinterstore', items, ttl, _execute)
def union(conn, items, ttl=30, _execute=True):
"""
计算多个SET的并集
返回包含任意一个指定词的教程
"""
return _set_common(conn, 'sunionstore', items, ttl, _execute)
def difference(conn, items, ttl=30, _execute=True):
"""
计算多个SET的差集
返回包含第一个词但不包含其他词的教程
"""
return _set_common(conn, 'sdiffstore', items, ttl, _execute)
# 示例:在小李学习平台中搜索教程
def search_tutorials_example():
"""
演示如何使用SET操作进行教程搜索
"""
# 假设我们已经为小李学习平台的教程建立了倒排索引
# idx:redis 包含所有提到"redis"的教程
# idx:python 包含所有提到"python"的教程
# idx:优化 包含所有提到"优化"的教程
# 搜索同时包含"redis"和"优化"的教程
redis_optimization_tutorials = intersect(conn, ['redis', '优化'])
print(f"同时包含redis和优化的教程: {redis_optimization_tutorials}")
# 搜索包含"python"或"mysql"的教程
python_or_mysql_tutorials = union(conn, ['python', 'mysql'])
print(f"包含python或mysql的教程: {python_or_mysql_tutorials}")
# 搜索包含"数据"但不包含"分析"的教程
data_not_analysis_tutorials = difference(conn, ['数据', '分析'])
print(f"包含数据但不包含分析的教程: {data_not_analysis_tutorials}")
=
[]
# 所有同义词组
current_group = set() # 当前同义词组
# 遍历查询中的所有词
for match in QUERY_RE.finditer(query):
word = match.group()
prefix = word[:1] # 获取前缀(+ 或 -)
# 处理带前缀的词
if prefix in '+-':
word = word[1:] # 去掉前缀
else:
prefix = None
# 跳过太短的词和停用词
if len(word) < 2 or word in STOP_WORDS:
continue
# 处理排除词
if prefix == '-':
unwanted.add(word)
continue
# 如果当前词没有+前缀,且已有同义词组,则开始新的组
if current_group and not prefix:
all_groups.append(list(current_group))
current_group = set()
# 将词添加到当前同义词组
current_group.add(word)
# 添加最后一个同义词组
if current_group:
all_groups.append(list(current_group))
return all_groups, list(unwanted)
def parse_and_search(conn, query, ttl=30):
"""
解析查询并执行搜索
参数:
conn - Redis连接对象
query - 搜索查询字符串
ttl - 临时结果SET的过期时间
返回: 搜索结果SET的ID
"""
# 解析查询
synonym_groups, unwanted_words = parse_query(query)
if not synonym_groups:
return None
# 处理每个同义词组
to_intersect = []
for synonym_group in synonym_groups:
if len(synonym_group) > 1:
# 多个同义词,使用并集操作
group_result = union(conn, synonym_group, ttl=ttl)
to_intersect.append(group_result)
else:
# 单个词,直接使用
to_intersect.append(synonym_group[0])
# 对所有同义词组求交集
if len(to_intersect) > 1:
intersect_result = intersect(conn, to_intersect, ttl=ttl)
else:
intersect_result = to_intersect[0]
# 如果有排除词,从结果中移除
if unwanted_words:
unwanted_words.insert(0, intersect_result)
return difference(conn, unwanted_words, ttl=ttl)
return intersect_result
# 示例:复杂的搜索查询
def advanced_search_example():
"""
演示高级搜索功能
"""
# 搜索缓存相关教程,但排除nosql相关内容
query = "缓存 +缓存策略 +缓存优化 数据库 -nosql"
result_id = parse_and_search(conn, query)
if result_id:
# 获取搜索结果
results = conn.smembers(f'idx:{result_id}')
print(f"搜索结果: {results}")
# 解析过程演示
groups, unwanted = parse_query(query)
print(f"同义词组: {groups}")
print(f"排除词: {unwanted}")
# 输出:
# 同义词组: [['缓存', '缓存策略', '缓存优化'], ['数据库']]
# 排除词: ['nosql']
sort_field = sort.lstrip('-')
# 构建排序引用路径
by_field = f"tutorial:*->{sort_field}"
# 判断是否为字母排序(非数字字段)
alpha = sort_field not in ('updated', 'id', 'created', 'likes')
# 如果提供了之前的搜索结果ID,尝试延长其过期时间
if result_id and not conn.expire(result_id, ttl):
result_id = None
# 如果没有有效的搜索结果,执行新的搜索
if not result_id:
result_id = parse_and_search(conn, query, ttl=ttl)
# 使用管道批量执行命令
pipeline = conn.pipeline(True)
# 获取搜索结果总数
pipeline.scard(f'idx:{result_id}')
# 对结果进行排序并分页
pipeline.sort(
f'idx:{result_id}',
by=by_field,
alpha=alpha,
desc=desc,
start=start,
num=num
)
# 执行命令并返回结果
results = pipeline.execute()
return results[0], results[1], result_id
# 示例:技术教程搜索和排序
def tutorial_search_example():
"""
演示技术教程的搜索和排序功能
"""
# 搜索"Redis"相关的教程
query = "Redis"
# 按更新时间排序,获取前10篇
total_count, tutorials, result_id = search_and_sort(
conn, query, sort="-updated", start=0, num=10
)
print(f"找到 {total_count} 篇相关教程")
print(f"按更新时间排序的前10篇: {tutorials}")
# 使用相同的结果ID,按创建时间排序
_, tutorials_by_created, _ = search_and_sort(
conn, query, result_id=result_id, sort="-created", start=0, num=5
)
print(f"按创建时间排序的前5篇: {tutorials_by_created}")
# 按标题字母顺序排序
_, tutorials_by_title, _ = search_and_sort(
conn, query, result_id=result_id, sort="title", start=0, num=5
)
print(f"按标题排序的前5篇: {tutorials_by_title}")
author_weight - 作者权威性权重
start - 起始位置
num - 返回数量
desc - 是否降序
返回: (总数量, 结果列表, 结果ID)
"""
# 如果提供了之前的搜索结果ID,尝试延长过期时间
if result_id and not conn.expire(result_id, ttl):
result_id = None
# 如果没有有效的搜索结果,执行新的搜索
if not result_id:
result_id = parse_and_search(conn, query, ttl=ttl)
# 构建评分权重字典
scored_search = {
result_id: 0, # 搜索结果本身不参与权重计算
'sort:likes': like_weight,
'sort:time': time_weight,
'sort:author': author_weight
}
# 使用ZINTERSTORE计算综合评分
final_result_id = zintersect(conn, scored_search, ttl)
# 使用管道获取结果
pipeline = conn.pipeline(True)
pipeline.zcard(f'idx:{final_result_id}')
# 根据排序方向获取结果
if desc:
pipeline.zrevrange(f'idx:{final_result_id}', start, start + num - 1)
else:
pipeline.zrange(f'idx:{final_result_id}', start, start + num - 1)
results = pipeline.execute()
return results[0], results[1], final_result_id
def zintersect(conn, items, ttl=30, **kwargs):
"""
ZSET交集操作的辅助函数
参数:
conn - Redis连接对象
items - 权重字典 {zset_id: weight}
ttl - 结果过期时间
**kwargs - 其他ZINTERSTORE参数
返回: 结果ZSET的ID
"""
result_id = str(uuid.uuid4())
execute = kwargs.pop('_execute', True)
pipeline = conn.pipeline(True) if execute else conn
# 为所有ZSET添加'idx:'前缀
prefixed_items = {}
for key, weight in items.items():
prefixed_items[f'idx:{key}'] = weight
# 执行ZINTERSTORE操作
pipeline.zinterstore(f'idx:{result_id}', prefixed_items, **kwargs)
pipeline.expire(f'idx:{result_id}', ttl)
if execute:
pipeline.execute()
return result_id
# 示例:技术教程的复合排序
def composite_sorting_example():
"""
演示复合排序功能
"""
query = "Redis教程"
# 主要按点赞数排序,时间作为次要因素
total_count, tutorials_by_likes, result_id = search_and_zsort(
conn, query, like_weight=1.0, time_weight=0.2, start=0, num=10
)
print(f"按点赞数+时间排序: {tutorials_by_likes}")
# 主要按时间排序,点赞数作为次要因素
_, tutorials_by_time, _ = search_and_zsort(
conn, query, result_id=result_id,
like_weight=0.3, time_weight=1.0, start=0, num=10
)
print(f"按时间+点赞数排序: {tutorials_by_time}")
# 平衡考虑点赞数、时间和作者权威性
_, tutorials_balanced, _ = search_and_zsort(
conn, query, result_id=result_id,
like_weight=0.5, time_weight=0.3, author_weight=0.2, start=0, num=10
)
print(f"平衡排序: {tutorials_balanced}")
:
pieces.append(-1)
# 将字符值组合成数值
score = 0
for piece in pieces:
score = score * 257 + piece + 1
# 如果字符串超过6个字符,添加额外位
return score * 2 + (len(string) > 6)
def create_string_sorted_index(conn, items):
"""
创建字符串排序索引
参数:
conn - Redis连接对象
items - 要排序的项目列表 [(id, string), ...]
"""
pipeline = conn.pipeline(True)
for item_id, string_value in items:
score = string_to_score(string_value)
pipeline.zadd('idx:string_sorted', {item_id: score})
pipeline.execute()
# 示例:作者名的自动补全
def author_autocomplete_example():
"""
演示基于字符串排序的作者名自动补全
"""
# 假设我们有一些作者名
authors = [
('author_001', '张三'),
('author_002', '李四'),
('author_003', '王五'),
('author_004', '赵六'),
('author_005', '钱七'),
('author_006', '孙八')
]
# 创建排序索引
create_string_sorted_index(conn, authors)
# 查找以"张"开头的作者名
def find_prefix_range(prefix):
"""查找前缀范围"""
start_score = string_to_score(prefix)
end_score = string_to_score(prefix + chr(255))
return start_score, end_score
def autocomplete_authors(prefix, limit=10):
"""自动补全作者名"""
start_score, end_score = find_prefix_range(prefix)
# 使用ZRANGEBYSCORE获取范围内的作者名
results = conn.zrangebyscore(
'idx:string_sorted', start_score, end_score,
start=0, num=limit
)
return results
# 测试自动补全功能
prefix = "张"
matches = autocomplete_authors(prefix)
print(f"以'{prefix}'开头的作者: {matches}")
# 输出: ['author_001']
prefix = "李"
matches = autocomplete_authors(prefix)
print(f"以'{prefix}'开头的作者: {matches}")
# 输出: ['author_002']
# 示例:教程标题排序
def tutorial_title_sorting_example():
"""
演示教程标题的排序功能
"""
tutorials = [
('tutorial_001', 'Redis缓存优化策略'),
('tutorial_002', 'Python数据分析实战'),
('tutorial_003', 'MySQL性能调优指南'),
('tutorial_004', 'Docker容器化部署'),
('tutorial_005', 'Kubernetes集群管理')
]
# 创建标题排序索引
create_string_sorted_index(conn, tutorials)
# 按标题字母顺序获取教程
sorted_tutorials = conn.zrange('idx:string_sorted', 0, -1)
print(f"按标题排序的教程: {sorted_tutorials}")
# 输出: ['tutorial_003', 'tutorial_004', 'tutorial_005', 'tutorial_002', 'tutorial_001']
返回: eCPM值
"""
if views == 0:
return 0
return 1000.0 * cpa * actions / views
def cpm_to_ecpm(cpm):
"""
将CPM广告转换为eCPM(直接返回)
参数:
cpm - 每千次展示费用
返回: eCPM值
"""
return cpm
# 广告类型转换字典
TO_ECPM = {
'cpc': cpc_to_ecpm,
'cpa': cpa_to_ecpm,
'cpm': cpm_to_ecpm,
}
# 示例:计算不同类型广告的eCPM
def calculate_ad_ecpm_example():
"""
演示如何计算不同类型广告的eCPM
"""
# CPM广告示例
cpm_ad = {
'type': 'cpm',
'cost': 50.0, # ¥50 per 1000 views
'views': 1000,
'clicks': 0
}
cpm_ecpm = TO_ECPM[cpm_ad['type']](cpm_ad['views'], cpm_ad['clicks'], cpm_ad['cost'])
print(f"CPM广告eCPM: ¥{cpm_ecpm:.2f}")
# CPC广告示例
cpc_ad = {
'type': 'cpc',
'cost': 5.0, # ¥5 per click
'views': 1000,
'clicks': 20 # 2% CTR
}
cpc_ecpm = TO_ECPM[cpc_ad['type']](cpc_ad['views'], cpc_ad['clicks'], cpc_ad['cost'])
print(f"CPC广告eCPM: ¥{cpc_ecpm:.2f}")
# CPA广告示例
cpa_ad = {
'type': 'cpa',
'cost': 100.0, # ¥100 per action
'views': 1000,
'actions': 1 # 0.1% conversion rate
}
cpa_ecpm = TO_ECPM[cpa_ad['type']](cpa_ad['views'], cpa_ad['actions'], cpa_ad['cost'])
print(f"CPA广告eCPM: ¥{cpa_ecpm:.2f}")
words = tokenize_chinese(content)
# 为每个词建立可选匹配索引
for word in words:
pipeline.zadd(f'idx:{word}', {ad_id: 0}) # 初始权重为0
# 计算广告的eCPM
# 使用行业平均CTR/转化率进行估算
AVERAGE_PER_1K = {'cpc': 20, 'cpa': 1} # 每1000次展示的点击/行动数
estimated_ecpm = TO_ECPM[ad_type](
1000, AVERAGE_PER_1K.get(ad_type, 1), value
)
# 存储广告元数据
pipeline.hset('ad:type:', ad_id, ad_type)
pipeline.zadd('idx:ad:value:', {ad_id: estimated_ecpm})
pipeline.zadd('ad:base_value:', {ad_id: value})
pipeline.sadd(f'terms:{ad_id}', *list(words))
pipeline.execute()
# 示例:为本地商家广告建立索引
def local_business_ad_example():
"""
演示本地商家广告的索引建立
"""
# 一家咖啡店的广告
coffee_shop_ad = {
'ad_id': 'coffee_001',
'locations': ['北京', '朝阳区', '三里屯'],
'content': '三里屯最佳咖啡店,新鲜烘焙豆子,温馨氛围',
'type': 'cpc',
'value': 20.0 # ¥20 per click
}
index_ad(
conn,
coffee_shop_ad['ad_id'],
coffee_shop_ad['locations'],
coffee_shop_ad['content'],
coffee_shop_ad['type'],
coffee_shop_ad['value']
)
# 一家餐厅的广告
restaurant_ad = {
'ad_id': 'restaurant_001',
'locations': ['北京', '海淀区', '中关村'],
'content': '正宗川菜,麻辣火锅,家庭聚餐首选',
'type': 'cpa',
'value': 150.0 # ¥150 per reservation
}
index_ad(
conn,
restaurant_ad['ad_id'],
restaurant_ad['locations'],
restaurant_ad['content'],
restaurant_ad['type'],
restaurant_ad['value']
)
print("本地商家广告索引建立完成")
)
# 获取eCPM最高的广告
pipeline.zrevrange(f'idx:{targeted_ads}', 0, 0)
target_id, targeted_ad = pipeline.execute()[-2:]
if not targeted_ad:
return None, None
ad_id = targeted_ad[0]
# 记录定向结果,用于后续学习
record_targeting_result(conn, target_id, ad_id, words)
return target_id, ad_id
def match_location(pipeline, locations):
"""
匹配地理位置
参数:
pipeline - Redis管道对象
locations - 地理位置列表
返回: (匹配的广告SET ID, 基础eCPM ZSET ID)
"""
# 构建位置查询键
required_locations = [f'req:{loc}' for loc in locations]
# 对位置SET求并集,找到所有匹配的广告
matched_ads = union(pipeline, required_locations, ttl=300, _execute=False)
# 计算这些广告的基础eCPM
base_ecpm = zintersect(
pipeline,
{matched_ads: 0, 'ad:value:': 1},
_execute=False
)
return matched_ads, base_ecpm
def finish_scoring(pipeline, matched_ads, base_ecpm, content):
"""
完成eCPM计算,包括内容匹配加分
参数:
pipeline - Redis管道对象
matched_ads - 位置匹配的广告SET ID
base_ecpm - 基础eCPM ZSET ID
content - 页面内容
返回: (匹配的词汇, 最终eCPM ZSET ID)
"""
bonus_ecpm = {}
words = tokenize_chinese(content)
# 为每个匹配的词计算加分
for word in words:
word_bonus = zintersect(
pipeline,
{matched_ads: 0, word: 1},
_execute=False
)
bonus_ecpm[word_bonus] = 1
if bonus_ecpm:
# 计算最小和最大加分
minimum = zunion(
pipeline, bonus_ecpm, aggregate='MIN', _execute=False
)
maximum = zunion(
pipeline, bonus_ecpm, aggregate='MAX', _execute=False
)
# 使用最小值和最大值的平均值作为最终加分
return words, zunion(
pipeline,
{base_ecpm: 1, minimum: 0.5, maximum: 0.5},
_execute=False
)
return words, base_ecpm
# 示例:广告定向演示
def ad_targeting_example():
"""
演示广告定向功能
"""
# 用户在北京朝阳区浏览美食页面
user_location = ['北京', '朝阳区']
page_content = "北京最佳餐厅推荐,川菜美食,火锅推荐"
# 执行广告定向
target_id, ad_id = target_ads(conn, user_location, page_content)
if ad_id:
print(f"定向成功!目标ID: {target_id}, 广告ID: {ad_id}")
# 获取广告详细信息
ad_type = conn.hget('ad:type:', ad_id)
base_value = conn.zscore('ad:base_value:', ad_id)
print(f"广告类型: {ad_type}")
print(f"基础价值: ¥{base_value}")
else:
print("未找到合适的广告")
if matched_words:
# 记录匹配的词汇,保存15分钟用于后续点击追踪
matched_key = f'terms:matched:{target_id}'
pipeline.sadd(matched_key, *matched_words)
pipeline.expire(matched_key, 900)
# 获取广告类型
ad_type = conn.hget('ad:type:', ad_id)
# 记录该类型广告的展示次数
pipeline.incr(f'type:{ad_type}:views:')
# 记录每个匹配词汇的展示次数
for word in matched_words:
pipeline.zincrby(f'views:{ad_id}', word, 1)
# 记录广告总展示次数
pipeline.zincrby(f'views:{ad_id}', '', 1)
# 每100次展示更新一次eCPM
pipeline.execute()
if pipeline.execute()[-1] % 100 == 0:
update_cpms(conn, ad_id)
def record_click(conn, target_id, ad_id, action=False):
"""
记录广告点击或用户行动
参数:
conn - Redis连接对象
target_id - 定向ID
ad_id - 广告ID
action - 是否为用户行动(而非点击)
"""
pipeline = conn.pipeline(True)
# 获取广告类型
ad_type = conn.hget('ad:type:', ad_id)
# 获取匹配的词汇
match_key = f'terms:matched:{target_id}'
matched_words = list(conn.smembers(match_key))
# 对于CPA广告,如果是行动,延长匹配词汇的保存时间
if ad_type == 'cpa':
pipeline.expire(match_key, 900)
# 确定记录类型
if action and ad_type == 'cpa':
click_key = f'actions:{ad_id}'
pipeline.incr(f'type:{ad_type}:actions:')
else:
click_key = f'clicks:{ad_id}'
# 记录该类型广告的点击/行动次数
pipeline.incr(f'type:{ad_type}:clicks:')
# 记录每个匹配词汇的点击/行动次数
matched_words.append('') # 添加空字符串表示广告整体
for word in matched_words:
pipeline.zincrby(click_key, word, 1)
pipeline.execute()
# 每次点击/行动都更新eCPM
update_cpms(conn, ad_id)
def update_cpms(conn, ad_id):
"""
更新广告和词汇的eCPM值
参数:
conn - Redis连接对象
ad_id - 广告ID
"""
pipeline = conn.pipeline(True)
# 获取广告基本信息
pipeline.hget('ad:type:', ad_id)
pipeline.zscore('ad:base_value:', ad_id)
pipeline.smembers(f'terms:{ad_id}')
ad_type, base_value, words = pipeline.execute()
# 确定使用点击还是行动数据
which = 'clicks'
if ad_type == 'cpa':
which = 'actions'
# 获取全局统计数据
pipeline.get(f'type:{ad_type}:views:')
pipeline.get(f'type:{ad_type}:{which}:')
type_views, type_clicks = pipeline.execute()
# 更新全局平均CTR/转化率
if type_views and type_clicks:
AVERAGE_PER_1K[ad_type] = (
1000.0 * int(type_clicks) / int(type_views)
)
# CPM广告不需要更新eCPM
if ad_type == 'cpm':
return
# 计算广告的eCPM
view_key = f'views:{ad_id}'
click_key = f'{which}:{ad_id}'
pipeline.zscore(view_key, '')
pipeline.zscore(click_key, '')
ad_views, ad_clicks = pipeline.execute()
if (ad_clicks or 0) < 1:
# 没有点击,使用现有eCPM
ad_ecpm = conn.zscore('idx:ad:value:', ad_id)
else:
# 根据实际表现计算eCPM
ad_ecpm = TO_ECPM[ad_type](ad_views or 1, ad_clicks or 0, base_value)
# 更新广告的eCPM
pipeline.zadd('idx:ad:value:', {ad_id: ad_ecpm})
# 更新每个词汇的eCPM加分
for word in words:
pipeline.zscore(view_key, word)
pipeline.zscore(click_key, word)
word_views, word_clicks = pipeline.execute()[-2:]
if (word_clicks or 0) < 1:
continue
# 计算词汇的eCPM
word_ecpm = TO_ECPM[ad_type](word_views or 1, word_clicks or 0, base_value)
# 计算词汇的加分(词汇eCPM - 广告eCPM)
bonus = word_ecpm - ad_ecpm
# 更新词汇的加分
pipeline.zadd(f'idx:{word}', {ad_id: bonus})
pipeline.execute()
# 示例:广告学习系统演示
def ad_learning_example():
"""
演示广告学习系统的工作流程
"""
# 模拟广告展示
target_id, ad_id = target_ads(
conn,
['北京', '朝阳区'],
"北京最佳咖啡店推荐,新鲜烘焙豆子"
)
if ad_id:
print(f"广告 {ad_id} 已展示给用户")
# 记录展示
record_targeting_result(conn, target_id, ad_id, {'咖啡', '北京'})
# 模拟用户点击
import random
if random.random() < 0.05: # 5% 点击率
print("用户点击了广告!")
record_click(conn, target_id, ad_id)
else:
print("用户未点击广告")
# 查看学习结果
ad_ecpm = conn.zscore('idx:ad:value:', ad_id)
print(f"广告当前eCPM: ¥{ad_ecpm:.2f}")
# 查看词汇加分
coffee_bonus = conn.zscore('idx:咖啡', ad_id)
beijing_bonus = conn.zscore('idx:北京', ad_id)
print(f"'咖啡'词汇加分: ¥{coffee_bonus:.2f}")
print(f"'北京'词汇加分: ¥{beijing_bonus:.2f}")
set
(required_skills))})
pipeline.execute()
def find_jobs(conn, candidate_skills):
"""
为求职者找到匹配的职位
参数:
conn - Redis连接对象
candidate_skills - 求职者技能列表
返回: 匹配的职位ID列表
"""
# 构建技能权重字典
skills = {}
for skill in set(candidate_skills):
skills[f'skill:{skill}'] = 1
# 计算求职者具备的技能数量
job_scores = zunion(conn, skills)
# 计算技能差距(职位要求 - 求职者具备)
final_result = zintersect(
conn,
{job_scores: -1, 'jobs:req': 1}
)
# 返回技能差距为0的职位(完全匹配)
return conn.zrangebyscore(f'idx:{final_result}', 0, 0)
# 示例:在线招聘平台的职位匹配
def job_matching_example():
"""
演示职位技能匹配功能
"""
# 建立职位索引
jobs = [
('job_001', ['Python', 'Redis', '机器学习']),
('job_002', ['Python', 'Django', 'PostgreSQL']),
('job_003', ['Java', 'Spring', 'MySQL']),
('job_004', ['Python', 'Flask', 'MongoDB']),
('job_005', ['JavaScript', 'React', 'Node.js'])
]
for job_id, skills in jobs:
index_job(conn, job_id, skills)
print("职位索引建立完成")
# 求职者A:具备Python、Redis、机器学习技能
candidate_a_skills = ['Python', 'Redis', '机器学习']
matching_jobs_a = find_jobs(conn, candidate_a_skills)
print(f"求职者A匹配的职位: {matching_jobs_a}")
# 输出: ['job_001']
# 求职者B:具备Python、Django技能
candidate_b_skills = ['Python', 'Django']
matching_jobs_b = find_jobs(conn, candidate_b_skills)
print(f"求职者B匹配的职位: {matching_jobs_b}")
# 输出: ['job_002']
# 求职者C:具备Python、Flask、MongoDB技能
candidate_c_skills = ['Python', 'Flask', 'MongoDB']
matching_jobs_c = find_jobs(conn, candidate_c_skills)
print(f"求职者C匹配的职位: {matching_jobs_c}")
# 输出: ['job_004']
=
zunion(conn, skills)
# 计算技能差距
skill_gap = zintersect(
conn,
{job_scores: -1, 'jobs:req': 1}
)
# 获取所有职位的技能差距
all_jobs = conn.zrangebyscore(f'idx:{skill_gap}', '-inf', '+inf', withscores=True)
# 计算匹配比例
matches = []
for job_id, gap in all_jobs:
required_skills = conn.zscore('idx:jobs:req', job_id)
if required_skills > 0:
match_ratio = (required_skills - gap) / required_skills
if match_ratio >= min_match_ratio:
matches.append((job_id, match_ratio))
# 按匹配比例排序
matches.sort(key=lambda x: x[1], reverse=True)
return matches
def find_jobs_by_location(conn, candidate_skills, locations):
"""
根据地理位置筛选职位
参数:
conn - Redis连接对象
candidate_skills - 求职者技能列表
locations - 目标地理位置列表
返回: 匹配的职位ID列表
"""
# 先找到技能匹配的职位
skill_matches = find_jobs(conn, candidate_skills)
if not skill_matches:
return []
# 构建位置查询
location_sets = [f'location:{loc}' for loc in locations]
# 找到位置匹配的职位
location_matches = union(conn, location_sets, ttl=300)
# 求交集,找到既技能匹配又位置匹配的职位
final_matches = intersect(conn, [
f'idx:{location_matches}',
*[f'job:{job_id}' for job_id in skill_matches]
], ttl=300)
return list(conn.smembers(f'idx:{final_matches}'))
# 示例:高级职位搜索功能
def advanced_job_search_example():
"""
演示高级职位搜索功能
"""
# 建立位置索引
job_locations = {
'job_001': ['北京', '朝阳区'],
'job_002': ['上海', '浦东'],
'job_003': ['北京', '海淀区'],
'job_004': ['广州', '天河区'],
'job_005': ['深圳', '福田区']
}
for job_id, locations in job_locations.items():
for location in locations:
conn.sadd(f'location:{location}', job_id)
# 求职者搜索:Python技能,北京地区
candidate_skills = ['Python', 'Redis']
target_locations = ['北京']
# 完全匹配的职位
perfect_matches = find_jobs(conn, candidate_skills)
print(f"完全匹配的职位: {perfect_matches}")
# 部分匹配的职位(至少50%技能匹配)
partial_matches = find_partial_matches(conn, candidate_skills, 0.5)
print(f"部分匹配的职位: {partial_matches}")
# 地理位置筛选
location_matches = find_jobs_by_location(conn, candidate_skills, target_locations)
print(f"北京地区的匹配职位: {location_matches}")