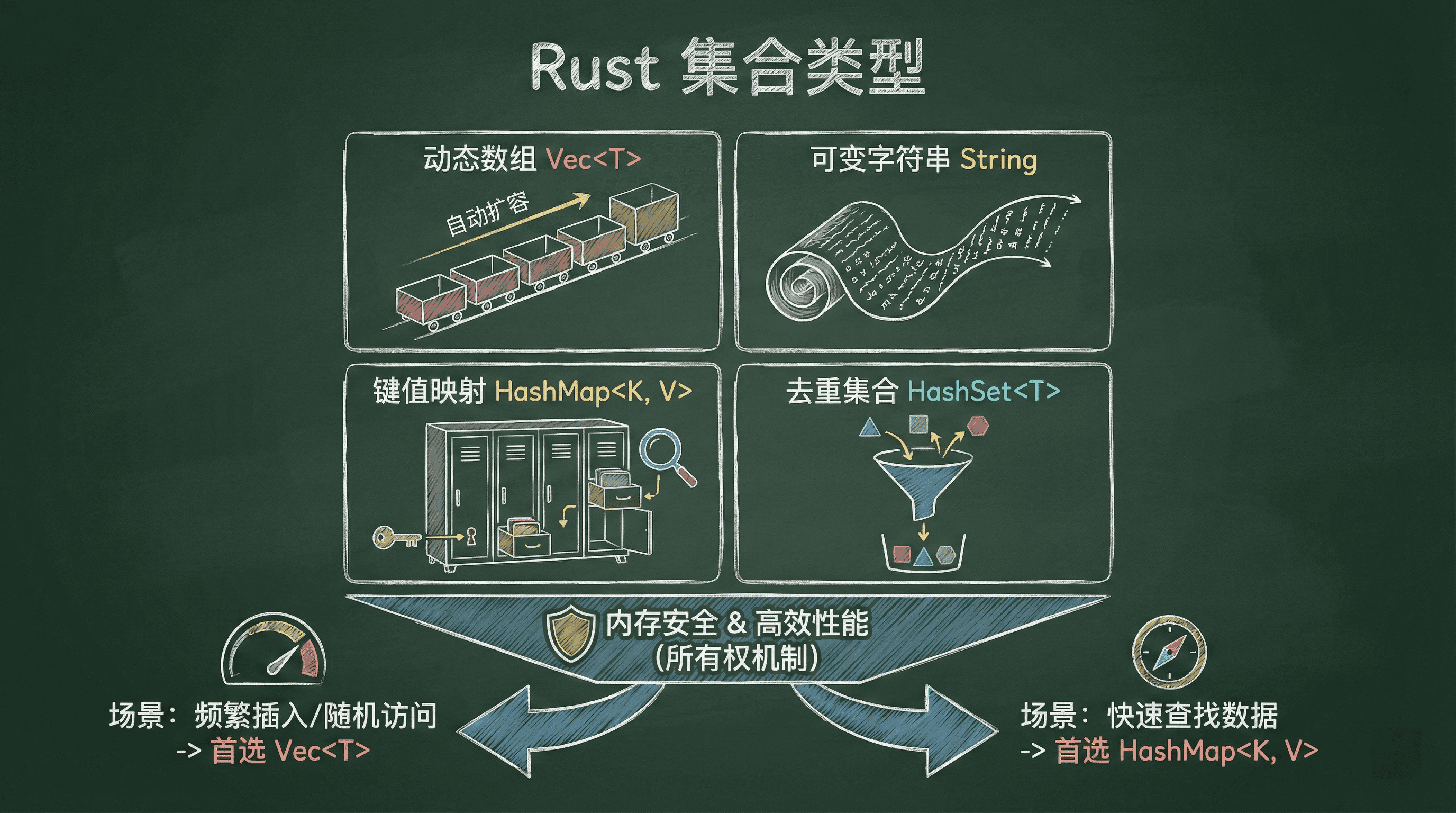
集合类型
在实际开发中,很多时候我们并不能提前确定数据的数量和边界,这时集合类型就显得尤为重要。Rust 标准库为我们准备了多种常用集合,比如动态数组 Vec<T>、可变字符串 String、键值映射 HashMap<K, V>
以及去重集合 HashSet<T> 等。这些集合不仅能灵活应对数据规模的变化,还能在 Rust 的所有权和借用机制下保证内存安全和高效性能。
我们在使用这些集合时,需要理解它们的扩容策略(比如如何自动增长容量)、元素访问方式(如索引、迭代器等)、遍历和修改的语义(比如可变借用与不可变借用的区别),以及它们在内存中的布局特点。
掌握这些知识后,我们就能根据实际需求选择合适的集合类型,写出既安全又高效的 Rust 代码。例如,面对需要频繁插入和随机访问的场景,Vec<T> 往往是首选;而需要根据键快速查找数据时,HashMap<K, V> 则更为合适。
Vec<T>:可增长的连续存储
Vec<T> 是 Rust 中最常用、最灵活的动态数组类型。它在内存中以一块连续区域存放元素,支持高效的随机访问和批量追加。我们可以随时向 Vec 末尾插入新元素,Rust 会自动帮我们扩容,
无需手动管理内存。Vec<T> 与切片 &[T] 之间可以方便地相互转换:比如我们可以把 Vec 的一部分借用为切片进行只读操作,也可以把整个 Vec 通过 into_iter 消费掉,获得所有权。
这样既保证了灵活性,也充分利用了 Rust 的所有权和借用机制,既安全又高效。无论是批量收集数据、动态生成内容,还是需要高性能的遍历和查找,Vec<T> 都是我们的首选工具。
rust
fn main() {
let mut numbers = Vec::new();
numbers.push(10);
numbers.push(20);
numbers.extend([30, 40]);
println!("len={}, last={:?}", numbers.len(), numbers.last());
// 切片视图,不转移所有权
let head = &numbers[..2];
println!("head={:?}", head);
// into_iter 消费所有权,collect 回收为 Vec
let doubled: Vec<_> = numbers.into_iter().map(|x| x * 2).collect();
println!("{:?}", doubled);
}text
len=4, last=Some(40)
head=[10, 20]
[20, 40, 60, 80]下面是一些vec的常见的操作:
rust
fn main() {
let mut v = vec![10, 20, 30];
// 1) 下标访问(越界会 panic)
println!("{}", v[1]);
// 2) 安全访问(返回 Option)
println!("{:?}", v.get(100)); // None
// 3) 修改某个位置的值
if let Some(x) = v.get_mut(
text
20
None
v=[15, 30], last=Some(40)容量管理与几何扩容
在 Rust 中,Vec 的扩容机制是自动的,背后采用的是类似倍增的几何增长策略。每当我们往 Vec 里添加元素且容量不足时,系统会自动分配一块更大的内存空间,
把原有元素搬过去,这样可以显著减少频繁分配带来的性能损耗。我们可以通过 with_capacity 方法提前为 Vec 分配一块足够大的空间,这样在后续多次插入时就不需要频繁扩容了,从而提升效率。
当数据减少后,如果觉得 Vec 占用的内存太多,还可以调用 shrink_to_fit 方法来尝试让 Vec 释放多余的内存,不过这个操作并不保证一定会收缩到最小,只是尽量减少浪费。
rust
fn main() {
let mut v: Vec<u8> = Vec::with_capacity(2);
for i in 0..8 { v.push(i); println!("len={} cap={}", v.len(), v.capacity()); }
}排序、去重与切片
rust
fn main() {
let mut v = vec![3, 1, 2, 2, 1];
v.sort(); // [1,1,2,2,3]
v.dedup(); // 相邻相同元素合并 -> [1,2,3]
let mid = &v[1..]; // 切片,不拷贝
println!("v={:?}, mid={:?}", v, mid);
}String:文本的可增长容器
String 类型其实是对 Vec<u8> 的进一步封装,但它专门用来存储和处理有效的 UTF-8 编码文本。
我们在操作 String 时,必须确保所有的切片操作都严格落在字符的合法边界上,否则会导致程序 panic。比如,直接用字节下标切片时,
如果不小心把一个多字节字符切断,就会出错。因此,遍历字符串内容时,推荐用 chars() 方法按字符逐个处理,这样可以正确地支持所有 Unicode 字符。
String 既能灵活追加、插入和删除内容,又能和切片 &str 之间高效转换,非常适合动态构建和处理文本数据。
rust
fn main() {
let mut s = String::from("Rust");
s.push(' 🦀');
s.push_str(" + 嗨");
let part = &s[0..4]; // 按字节切片,需谨慎
println!("s={s}; part={part}");
}text
s=Rust 🦀 + 嗨; part=Rust假设我们有一段文本,需要把它拆分成单词并统计单词数量。可以使用 split_whitespace 方法:
rust
fn main() {
let s = "hi rust rustaceans";
let words: Vec<_> = s.split_whitespace().collect();
let replaced = s.replacen("rust", "Rust", 1);
println!("{:?} | {}", words, replaced);
}下面是一些string的常见的操作:
rust
fn main() {
let mut s = String::from("abc");
s.push('d'); // 追加单个字符
s.push_str("ef"); // 追加字符串切片
s.insert(0, 'X'); // 指定位置插入(按字节边界)
s.replace_range(1..3,
text
X--cdef | X--CDEF
pos=Some(3)
<hi rust and rustaceans> 容量与内存
rust
fn main() {
let mut s = String::with_capacity(5);
s.push_str("hello world");
println!("len={} cap={}", s.len(), s.capacity());
s.shrink_to_fit();
println!("after shrink cap={}", s.capacity());
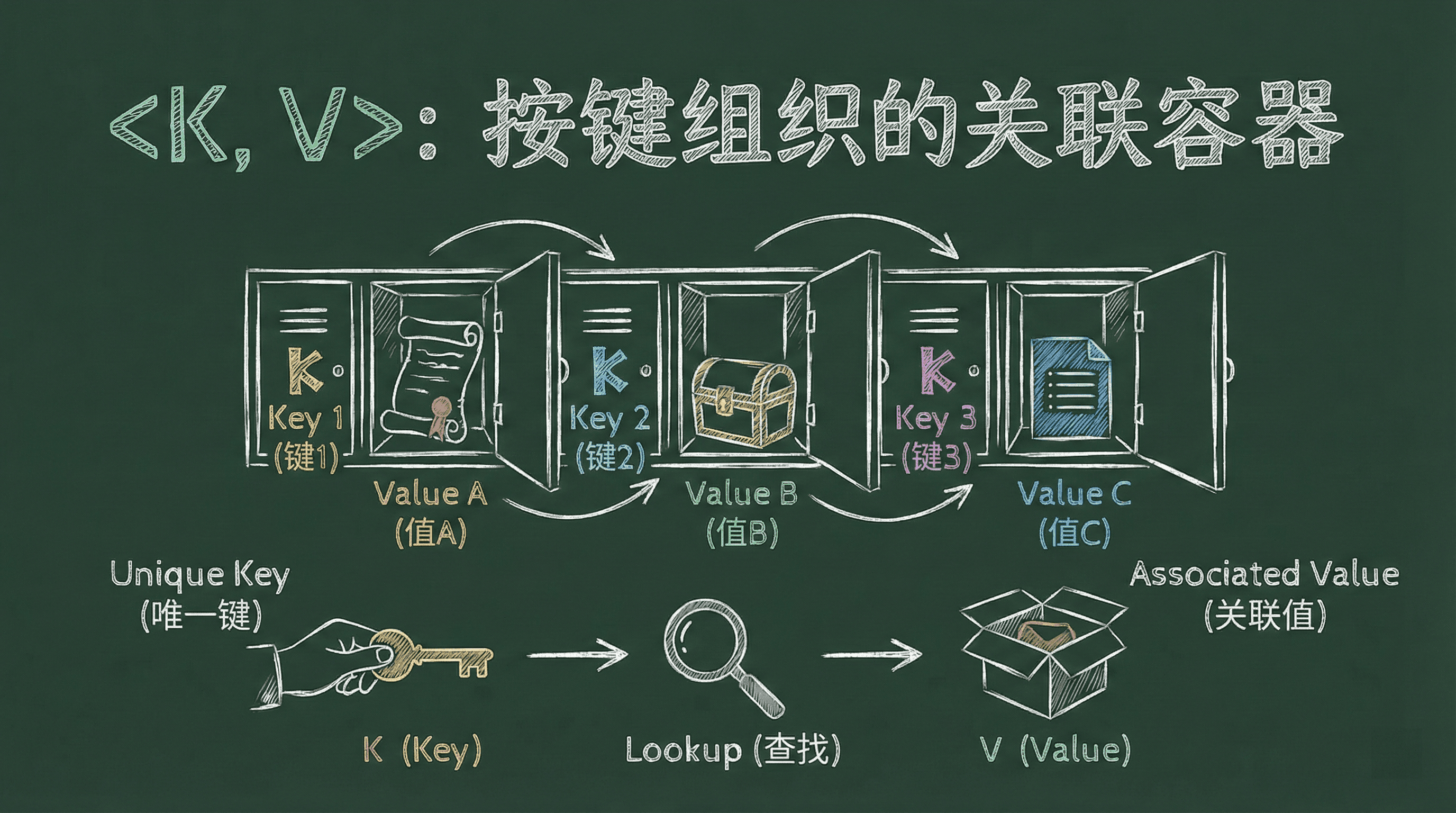
}HashMap<K, V>:按键组织的关联容器
在 Rust 里,HashMap 是一种非常适合用来根据“键”快速查找、存储和更新数据的容器。
我们只要给定一个键,就能高效地获取或修改对应的值。要作为键的类型,必须实现 Eq 和 Hash 这两个 trait,通常我们用 #[derive(Eq, Hash)] 就能自动搞定。
实际开发中,entry 方法特别实用,它允许我们在不需要提前判断键是否存在的情况下,直接对某个键进行插入或更新操作,这样既省去了多余的查找,也让代码更简洁高效。
比如我们要统计每个人的分数,只需用 entry 结合 or_insert 或 and_modify,就能轻松实现“有就更新、没有就插入”的逻辑。
rust
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
for (name, s) in [("A", 90), ("B", 75), ("A", 95)] {
*scores.entry(name).or_insert(0)
text
{"A": 95, "B": 75}
{"A": 95, "B": 80}在 Rust 的标准库中,HashMap 默认采用 RandomState 作为哈希算法实现,这种设计既能保证哈希表在面对恶意输入时的安全性,也能提供不错的性能表现。
实际开发中,如果我们对性能有极致的追求,比如在数据量很大、哈希表操作频繁的场景下,也可以选择第三方的哈希算法实现,比如 fxhash 或 ahash。
这些哈希器通常能带来更快的插入和查找速度,但相应地,抗攻击能力会有所下降,因此在选择时要结合实际需求权衡安全性和性能。
如果我们的应用场景对安全性要求不高,追求极致速度,可以尝试这些替代方案;
但如果程序可能暴露在不可信输入下,还是建议坚持使用默认的 RandomState,以免遭遇哈希碰撞攻击带来的性能退化。
rust
use std::collections::HashMap;
fn main() {
let mut map: HashMap<String, i32> = HashMap::new();
// 1) 插入(移动所有权进来)
map.insert("Alice".into(), 90);
map.insert("Bob".into
text
Some(90)
Alice -> 95
Bob -> 85
remove=Some(70)- 若键来自外部输入且需要持久保存,建议
HashMap<String, V>,把字符串所有权放进表里。 - 若键是程序内的短生命周期引用(如解析中的临时切片),可用
HashMap<&str, V>,但要确保被引用的数据活得足够久。 - 访问顺序不保证稳定,如需有序映射可考虑
BTreeMap(按键排序,代价是稍高的对数时间)。
HashSet<T>:去重集合
HashSet<T> 是 Rust 标准库提供的集合类型,它专注于解决"某个元素是否存在"这一核心问题。与 HashMap 不同,HashSet 只存储值而不存储键值对,每个值在集合中最多只能出现一次,这使得它天然具备去重功能。
HashSet 的主要优势在于它提供了丰富的集合运算方法,比如求并集(union)、交集(intersection)、差集(difference)和对称差集(symmetric_difference)。这些操作在处理数据分析、用户权限管理、标签系统等场景时特别有用。
比如在一个在线学习平台中,我们可能需要找出同时选修了"数学"和"物理"课程的学生,或者找出只选修了"数学"但没选修"物理"的学生,这时候集合运算就能派上用场。
HashSet 的插入、删除和查找操作平均时间复杂度都是 O(1),这让它在处理大量数据时依然能保持高效。与 HashMap 类似,要作为 HashSet 元素的类型也必须实现 Eq 和 Hash trait。
rust
use std::collections::HashSet;
fn main() {
let a: HashSet<_> = [1, 2, 3].into_iter().collect();
let b: HashSet<_> = [3, 4].into_iter().collect
text
union={1, 2, 3, 4}, inter={3}下面是一些hashset的常见的操作:
rust
use std::collections::HashSet;
use std::hash::{Hash};
#[derive(Debug, Hash, PartialEq, Eq)]
struct User { id: u32, name: &'static str }
fn main() {
let mut s =
所有权、借用与集合
当我们向集合插入数据时,需要特别注意所有权的转移规则。如果插入的是"拥有值"(owned value),那么这个值的所有权就会从原来的位置移动到集合中,原来的变量将不再可用。 这种移动语义是 Rust 内存安全机制的核心组成部分,它确保了同一时刻只有一个所有者能够访问和修改数据。
在实际开发中,我们经常会遇到这样的情况:既想把数据放入集合,又希望在其他地方继续使用这些数据。这时候就需要根据具体场景来选择合适的策略。 如果我们只是想让集合引用已有的值,而不是获得这些值的所有权,那么应该考虑使用借用的方式,也就是存储对这些值的引用。 这种方法的优点是避免了不必要的内存拷贝,但缺点是需要处理生命周期的约束,确保被引用的数据在集合使用期间始终有效。
另一种常见的做法是在需要的时候进行克隆。虽然克隆会带来一定的性能开销,但它能让我们获得数据的完整副本,从而避免生命周期的复杂性。 不过,频繁的克隆操作可能会成为性能瓶颈,特别是在处理大型数据结构或者在性能敏感的代码路径中。因此,我们应该谨慎使用克隆,只在确实需要独立副本的时候才进行克隆操作。
rust
use std::collections::HashMap;
fn main() {
let names = vec!["Li", "Xue"]; // &str 字面量是 'static 引用
let mut map: HashMap<&str, usize> = HashMap::new();
for (i, &name) in names.iter
- 需要长期保存到集合中:更倾向把“拥有值”放入集合(如
String),避免外部数据被释放导致悬垂引用。 - 临时汇总/短期统计:可以存放引用,减少分配与拷贝,但要留心生命周期约束。
习题
- Rust中最常用的动态数组类型是?
- Vec中用于访问元素的方法包括?
- 在Rust中,如何为Vec预分配容量?
- Rust中的字符串类型包括?
- String中用于分割字符串的方法包括?
- Rust中的集合类型包括?
- HashMap中用于操作键值对的方法包括?
- 在Rust中,如何安全地遍历字符串的字符?
9. Vec安全取值练习
编写两个函数,实现从Vec中安全取值:
get_value_index:使用get()方法,越界时返回Noneget_value_index_panic:使用下标访问[],越界时会panic- 体会两种方式的差异:安全访问vs直接访问
10. Vec容量管理练习
观察Vec的容量变化,比较预分配和动态扩容的区别:
- 创建两个Vec:一个使用
Vec::new(),另一个使用Vec::with_capacity(100) - 每次push后,当容量发生变化时打印
len/cap - 观察两种方式的扩容次数差异
11. String空白归一化练习
编写函数,将字符串中的多个空白字符(空格、制表符、换行符等)折叠为单个空格,并去除两端空白:
- 使用
split_whitespace()方法分割字符串 - 使用
join()或collect()重新组合 - 处理包含多种空白字符的字符串
12. 按字符数安全截断字符串练习
实现函数,按字符数(不是字节数)安全地截断字符串,支持多字节Unicode字符:
- 使用
char_indices()获取字符和字节位置的对应关系 - 找到第n个字符的起始字节位置
- 使用字符串切片返回前n个字符
13. HashMap词频统计和Top-K练习
编写函数,统计字符串中每个单词的出现次数,并按频率从高到低返回前K个:
- 将字符串转换为小写(忽略大小写)
- 使用
split_whitespace()分割单词 - 使用
HashMap统计词频 - 将HashMap转换为Vec,按频率排序
- 返回前K个结果