更深入的响应式编程
在掌握了响应式编程的基础之后,我们需要深入理解响应式编程的高级特性和最佳实践。实际项目中的响应式编程远比简单的Mono和Flux操作复杂,你需要处理背压、超时、重试、缓存、性能优化等实际问题。
响应式编程的优势在于它能够以少量线程处理大量并发请求,但这种优势的实现需要深入理解响应式流的执行机制。 操作符的选择和组合会影响性能,不当的使用可能导致内存泄漏、线程阻塞、背压处理不当等问题。理解这些底层机制,掌握高级操作符的使用技巧,学会性能调优和问题诊断,这些都是构建生产级响应式应用所必需的技能。
这节课我们将深入学习响应式编程的高级特性,包括背压处理的高级技巧、操作符的组合和优化、性能调优、复杂场景的处理、响应式编程的最佳实践等内容。通过这些知识的学习,你将能够构建出真正高性能、高可靠性的响应式应用。
深入理解背压机制
背压是响应式编程中的核心概念,它允许消费者控制数据流的速度,防止生产者产生数据的速度超过消费者处理数据的速度。理解背压机制的工作原理对于编写高效的响应式代码至关重要。
当数据生产者的速度超过消费者的处理速度时,响应式流会通过背压信号来通知生产者减慢速度。Project Reactor提供了多种背压策略来处理这种情况,包括BUFFER、DROP、LATEST、ERROR等。默认情况下,如果消费者无法跟上生产者的速度,流会抛出BufferOverflowException。
让我们通过一个例子来理解背压的处理。创建一个背压处理的示例服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建BackpressureService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import reactor.util.retry.Retry;
import java.time.Duration;
import java.util.concurrent.atomic.AtomicLong;
@Service
public class BackpressureService {
public Flux<Long> generateFastData() {
return Flux.range(1, 1000000)
.map(i -> (long) i)
.delayElements(Duration.ofMillis(1))
.onBackpressureBuffer(1000)
.doOnNext(value -> {
System.out.println("Processing: " + value);
});
}
public Flux<Long> generateWithDropStrategy() {
return Flux.range(1, 1000000)
.map(i -> (long) i)
.delayElements(Duration.ofMillis(1))
.onBackpressureDrop(dropped -> {
System.out.println("Dropped: " + dropped);
})
.onBackpressureLatest();
}
public Flux<Long> generateWithErrorStrategy() {
return Flux.range(1, 1000000)
.map(i -> (long) i)
.delayElements(Duration.ofMillis(1))
.onBackpressureError();
}
public Flux<Long> generateWithRateLimit() {
return Flux.range(1, 1000000)
.map(i -> (long) i)
.limitRate(100)
.delayElements(Duration.ofMillis(10));
}
}onBackpressureBuffer(1000)使用缓冲策略,当缓冲区满时(1000个元素),如果消费者仍然无法跟上,会抛出异常。onBackpressureDrop()使用丢弃策略,当背压发生时,直接丢弃无法处理的数据,并调用回调函数通知。onBackpressureLatest()保留最新的数据,丢弃旧数据。onBackpressureError()在背压发生时立即抛出异常。limitRate(100)限制数据产生的速率,每秒最多产生100个元素。
选择合适的背压策略取决于你的业务场景。对于不能丢失数据的场景,应该使用缓冲策略,但要设置合理的缓冲区大小。对于可以容忍数据丢失的场景(如实时监控数据),可以使用丢弃策略。对于需要最新数据的场景,可以使用LATEST策略。
操作符的组合和优化
响应式编程的强大之处在于操作符的组合,你可以通过链式调用多个操作符来实现复杂的数据转换逻辑。然而,操作符的选择和顺序会影响性能,不当的组合可能导致不必要的开销。
理解操作符的执行顺序对于优化性能非常重要。操作符按照订阅时的顺序执行,上游操作符的结果会传递给下游操作符。某些操作符会改变执行上下文(如publishOn、subscribeOn),这会影响线程的切换。频繁的线程切换会增加开销,应该尽量减少不必要的线程切换。
让我们创建一个操作符组合优化的示例。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建OperatorOptimizationService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import java.time.Duration;
import java.util.List;
@Service
public class OperatorOptimizationService {
public Flux<String> optimizedProcessing(List<Integer> data) {
return Flux.fromIterable(data)
.
optimizedProcessing方法展示了优化的操作符组合,所有的过滤和映射操作在同一个线程上执行,只在最后需要I/O操作时才切换到并行调度器。unoptimizedProcessing方法展示了不优化的组合,每个操作都切换线程,这会带来不必要的开销。
collectOptimized方法展示了如何使用buffer和flatMap来批量处理数据,这比逐个处理更高效。windowAndProcess方法使用window操作符将数据流分成多个窗口,然后并行处理每个窗口,flatMap的第二个参数(10)限制了并发窗口的数量,防止创建过多的线程。
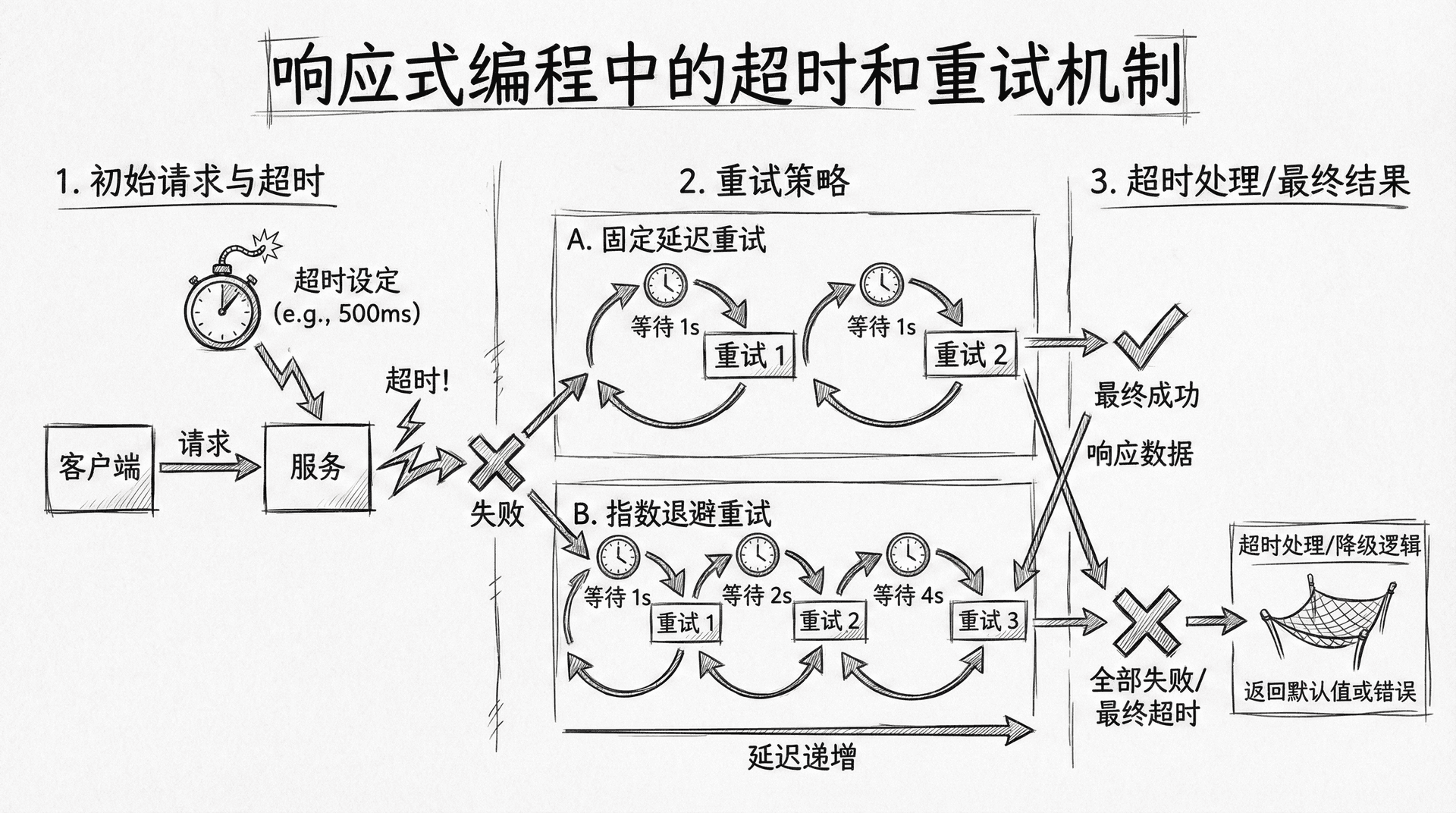
处理超时和重试
在实际应用中,网络请求、数据库查询等操作可能会超时或失败。响应式编程提供了丰富的超时和重试机制来处理这些情况,确保应用的健壮性。
超时处理是响应式编程中的重要特性。当操作超过指定时间未完成时,应该取消操作并返回错误或默认值。Project Reactor提供了timeout操作符来处理超时,你可以指定超时时间、超时时的回退值等。
重试机制允许在操作失败时自动重试。Project Reactor 3.4.0引入了新的重试API(reactor.util.retry.Retry),它提供了更灵活的重试策略,包括固定延迟重试、指数退避重试、带抖动重试等。
创建一个处理超时和重试的服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建TimeoutRetryService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.util.retry.Retry;
import java.time.Duration;
import java.util.concurrent.TimeoutException;
@Service
public class TimeoutRetryService {
public Mono<String> fetchWithTimeout(Mono<String> source) {
return source
.timeout(Duration.
timeout(Duration.ofSeconds(5))设置5秒超时,如果操作在5秒内未完成,会抛出TimeoutException。onErrorResume用于处理超时异常,返回默认值。timeout操作符可以链式调用,每个timeout都会创建一个新的超时检查点。
retryWhen(Retry.fixedDelay(3, Duration.ofSeconds(1)))使用固定延迟重试,最多重试3次,每次重试间隔1秒。filter用于过滤需要重试的异常类型,只有RuntimeException才会重试。doBeforeRetry在每次重试前执行,可以用于记录日志。
Retry.backoff(3, Duration.ofSeconds(1))使用指数退避重试,初始延迟1秒,每次重试延迟时间会指数增长。maxBackoff设置最大退避时间,jitter添加随机抖动,避免多个请求同时重试造成的"雷群效应"。
实现响应式缓存
缓存是提高应用性能的重要手段,它能够减少重复计算和网络请求。在响应式编程中,缓存的使用需要特别小心,因为响应式流是延迟执行的,缓存的时机和方式会影响缓存的效果。
Project Reactor提供了cache操作符来实现响应式流的缓存。cache操作符会缓存流的元素,当有新的订阅者订阅时,会直接返回缓存的数据,而不需要重新执行上游操作。这对于昂贵的操作(如数据库查询、外部API调用)特别有用。
然而,cache操作符会缓存所有元素,对于无限流或大流,这可能导致内存问题。cache(Duration)可以设置缓存的过期时间,超过时间后缓存会失效。cache(Duration, Scheduler)可以指定用于计算过期时间的调度器。
创建一个响应式缓存服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建ReactiveCacheService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import java.time.Duration;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
@Service
public class ReactiveCacheService {
private final ConcurrentMap<String, Mono<String>> cache = new ConcurrentHashMap<>();
public Mono<
fetchWithCache方法使用ConcurrentHashMap来存储缓存的Mono,computeIfAbsent确保每个key只创建一次Mono。缓存的Mono使用cache(Duration.ofMinutes(5))设置5分钟过期时间。这种方式适合缓存单个值的情况。
fetchWithTimeBasedCache方法直接在Mono上使用cache,设置过期时间和调度器。这种方式更简单,但无法手动失效缓存。
对于流(Flux)的缓存,cache操作符会缓存所有元素,这对于有限流是可行的,但对于无限流或大流,应该使用其他策略,如share()操作符,它允许多个订阅者共享同一个订阅,但不会缓存数据。
性能调优和监控
响应式编程的性能优势来自于非阻塞I/O和事件循环机制,但要充分发挥这种优势,需要进行适当的调优和监控。理解响应式流的执行机制、线程模型、内存使用等对于性能调优非常重要。
Project Reactor提供了丰富的操作符来帮助监控和调试响应式流。doOnNext、doOnError、doOnComplete、doOnSubscribe、doOnCancel等操作符可以用于在流的各个阶段执行副作用操作,如记录日志、更新指标等。
线程模型的选择对性能有重要影响。Schedulers.immediate()在当前线程执行,没有线程切换开销。Schedulers.parallel()使用固定大小的线程池,适合CPU密集型任务。Schedulers.boundedElastic()使用可扩展的线程池,适合I/O密集型任务。Schedulers.single()使用单线程,适合需要顺序执行的任务。
创建一个性能监控和调优的服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建PerformanceMonitoringService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import reactor.util.context.Context;
import java.time.Duration;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAdder;
@Service
public class PerformanceMonitoringService {
private final LongAdder requestCount = new LongAdder();
private final
processWithMonitoring方法展示了如何使用各种doOn*操作符来监控流的执行。doOnSubscribe在订阅时执行,doOnNext在每个元素发出时执行,doOnError在错误时执行,doOnCancel在取消时执行,doOnFinally在流完成(无论成功还是失败)时执行。
processStreamWithMetrics方法展示了如何监控流式处理的指标,如处理元素的数量、完成状态、错误信息等。
processWithContext方法展示了如何使用Context来传递请求ID等上下文信息,这对于分布式追踪和日志关联非常有用。
processWithBackpressureMonitoring方法展示了如何监控背压,doOnRequest在订阅者请求元素时执行,可以用于监控请求速率。
processWithThreadMonitoring方法展示了如何监控线程切换,这对于理解响应式流的执行路径和性能调优非常重要。
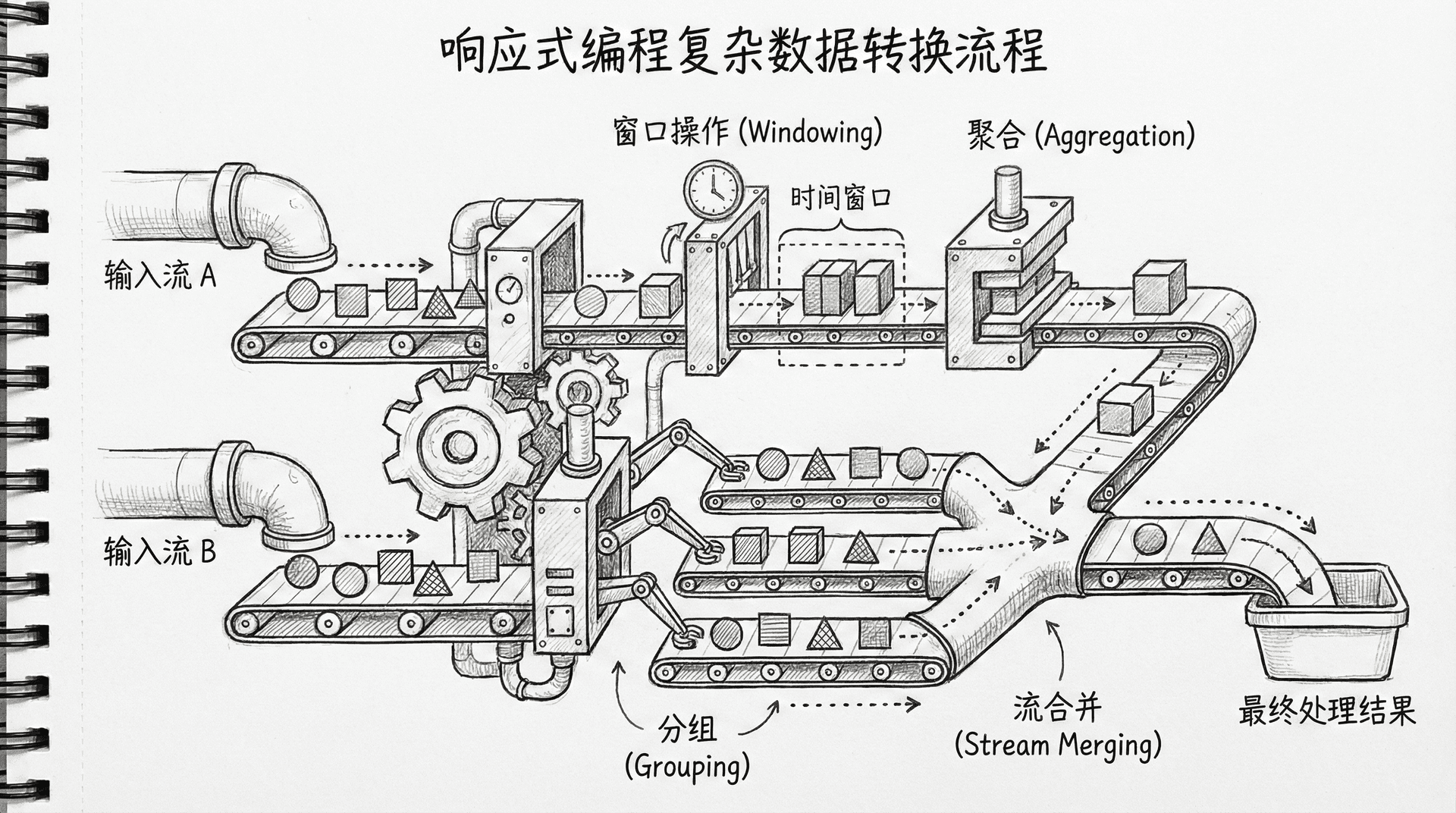
处理复杂的数据转换场景
在实际应用中,你经常需要处理复杂的数据转换场景,如数据聚合、分组、窗口操作、合并多个流等。Project Reactor提供了丰富的操作符来处理这些场景。
数据聚合是常见的需求,你需要将多个元素聚合成单个值。reduce操作符可以用于聚合,它接受一个累加器函数,将流中的元素逐个累加。scan操作符类似于reduce,但它会发出每个中间结果,而不是只发出最终结果。
分组操作将流中的元素按照某个条件分组。groupBy操作符可以用于分组,它返回一个GroupedFlux,每个组是一个独立的Flux。窗口操作将流分成多个窗口,每个窗口是一个Flux。window操作符可以用于窗口操作,它支持按数量、按时间、按条件等来创建窗口。
现在让我们来创建一个处理复杂数据转换的服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建ComplexTransformationService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.time.Duration;
import java.util.Map;
@Service
public class ComplexTransformationService {
public Mono<Integer> aggregateSum(Flux<Integer> source) {
return source
.reduce(0, Integer::
aggregateSum方法使用reduce来求和,aggregateWithScan方法使用scan来发出每个中间结果。
groupAndCount方法使用groupBy按首字母分组,然后统计每组的数量,最后收集成Map。
windowByTime和windowByCount方法分别按时间和数量创建窗口,窗口本身是Flux,可以进一步处理。
mergeMultipleStreams方法使用merge来合并多个流,元素按照到达时间交错发出。concatMultipleStreams方法使用concat来连接多个流,先发出第一个流的所有元素,再发出第二个流的所有元素。zipMultipleStreams方法使用zip来组合多个流,每次从每个流中取一个元素进行组合。combineLatest方法使用combineLatest来组合多个流,每当任何一个流发出新元素时,就与所有流的最新元素进行组合。
flatMapWithConcurrency方法使用flatMap来转换每个元素,第二个参数(10)限制了并发数。switchMap方法类似于flatMap,但当新元素到达时,会取消之前未完成的转换,只处理最新的元素。concatMap方法类似于flatMap,但会顺序执行转换,不会并发。
响应式编程的最佳实践
响应式编程虽然强大,但也有一些陷阱需要注意。理解这些陷阱并遵循最佳实践,能够帮助你编写出高效、可靠的响应式代码。
避免阻塞操作是响应式编程的基本原则。在响应式流中执行阻塞操作(如Thread.sleep、同步I/O)会阻塞线程,破坏响应式编程的优势。应该使用非阻塞的替代方案,如Mono.delay、异步I/O等。如果必须使用阻塞操作,应该使用subscribeOn(Schedulers.boundedElastic())将其调度到专门的线程池。
避免在响应式流中抛出异常,应该使用onErrorReturn、onErrorResume等操作符来处理错误。未处理的异常会导致流终止,可能影响其他订阅者。对于可恢复的错误,应该使用重试机制。对于不可恢复的错误,应该提供合理的错误响应。
合理使用subscribeOn和publishOn。subscribeOn影响整个链的执行线程,应该只调用一次,通常放在链的开头。publishOn影响后续操作的执行线程,可以在链中多次调用,用于在不同阶段切换线程。
避免内存泄漏。响应式流是延迟执行的,只有当有订阅者订阅时才会执行。如果你创建了流但没有订阅,或者订阅后没有正确处理,可能导致资源泄漏。确保所有订阅都有适当的生命周期管理,使用doFinally来清理资源。
现在让我们来创建一个展示最佳实践的服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建BestPracticesService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import java.time.Duration;
import java.util.concurrent.atomic.AtomicBoolean;
@Service
public class BestPracticesService {
public Mono<String> avoidBlockingOperation() {
return Mono.fromCallable(() -> {
return "Result from blocking operation"
avoidBlockingOperation方法展示了如何正确处理阻塞操作,使用subscribeOn(Schedulers.boundedElastic())将阻塞操作调度到专门的线程池,并设置超时。
handleErrorsProperly方法展示了如何正确处理错误,使用onErrorResume来处理不同类型的异常,提供合理的回退值或转换错误。
properThreadUsage方法展示了如何正确使用线程,subscribeOn放在链的开头,publishOn用于在需要时切换线程。
resourceCleanup方法展示了如何清理资源,使用doFinally确保资源在任何情况下都能被清理。
avoidMemoryLeak方法展示了如何避免内存泄漏,使用take来限制元素数量,使用doOnCancel和doFinally来管理流的生命周期。
properSubscriberContext方法展示了如何正确使用Context来传递上下文信息。
响应式编程与命令式编程的混合
在实际项目中,你可能会遇到需要在响应式代码中调用命令式代码,或者在命令式代码中调用响应式代码的情况。理解如何正确地混合使用这两种编程模型非常重要。
从命令式代码调用响应式代码时,应该使用block()方法(不推荐,但有时是必要的)或者将响应式代码转换为CompletableFuture。block()会阻塞当前线程,应该只在必要时使用,比如在测试中或者在应用启动时的初始化代码中。
从响应式代码调用命令式代码时,应该使用Mono.fromCallable()或Flux.fromIterable()等操作符,并使用subscribeOn将命令式代码调度到适当的线程池。
创建一个展示混合使用的服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建HybridProgrammingService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import java.util.List;
import java.util.concurrent.CompletableFuture;
@Service
public class HybridProgrammingService {
public String callReactiveFromImperative() {
Mono<String> reactiveResult = fetchDataReactive();
return reactiveResult.block(Duration.
callReactiveFromImperative方法展示了如何从命令式代码调用响应式代码,使用block()方法(不推荐,但有时是必要的)。
callReactiveAsFuture方法展示了如何将响应式代码转换为CompletableFuture,这样可以在命令式代码中使用。
callImperativeFromReactive方法展示了如何从响应式代码调用命令式代码,使用Mono.fromCallable()和subscribeOn。
processImperativeList方法展示了如何处理命令式集合,使用Flux.fromIterable()将其转换为响应式流。
collectReactiveToImperative方法展示了如何将响应式流收集为命令式集合,使用collectList()和blockOptional()。
在响应式代码中使用block()方法会阻塞线程,破坏响应式编程的优势。应该尽量避免使用block(),如果必须使用,应该确保在适当的上下文中(如测试、初始化代码)使用,并且设置合理的超时时间。
响应式编程的调试技巧
响应式编程的调试比命令式编程更困难,因为执行是异步的,调用栈可能不完整。Project Reactor提供了一些工具来帮助调试响应式代码。
Hooks.onOperatorDebug()可以启用操作符调试模式,它会捕获更详细的调用栈信息,帮助定位问题。但这会带来性能开销,应该只在开发环境中使用。
checkpoint()操作符可以在流中插入检查点,当错误发生时,会包含检查点的信息,帮助定位问题发生的位置。
log()操作符可以记录流的执行过程,包括订阅、元素发出、完成、错误等事件。这对于理解流的执行流程非常有用。
现在让我们来创建一个展示调试技巧的服务。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建DebuggingService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.publisher.Hooks;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
@Service
public class DebuggingService {
@PostConstruct
public void enableDebugMode() {
Hooks.onOperatorDebug();
}
@PreDestroy
public
enableDebugMode方法在应用启动时启用操作符调试模式,disableDebugMode方法在应用关闭时禁用调试模式。
debugWithCheckpoint方法展示了如何使用checkpoint来标记流中的关键位置,当错误发生时,错误信息会包含检查点的名称,帮助定位问题。
debugWithLog方法展示了如何使用log来记录流的执行过程,log操作符会记录订阅、元素发出、完成、错误等事件。
debugWithDoOn方法展示了如何使用各种doOn*操作符来调试流的执行,这些操作符不会改变流的行为,只是执行副作用操作,如记录日志。
小结
相信你已经对响应式编程的高级特性有了系统而深入的掌握。我们不仅探讨了如何优雅地处理背压、构建高效的操作符链、以及应对超时与重试场景,还学会了实现响应式缓存、性能调优与实时监控,并深入了解了复杂数据转换、最佳实践、命令式与响应式编程的协同,以及调试和排障的多种方法。这些专业技能将助力你打造高性能、高可靠性、可维护性强的响应式应用。
需要注意的是,响应式编程不仅仅是一种新技术,更代表着现代系统架构设计理念的转变。它非常适合高并发、高吞吐量、实时性要求高的应用场景。然而,最优的技术方案总是结合实际需求——对于简单的CRUD操作,经典命令式模式依然高效实用。深刻理解并权衡两种编程范式的优势与局限,能够帮助你灵活应对不同的业务挑战,做出最专业、合理的技术决策。在今后的工程实践中,愿你始终保持探索和创新的热情,将响应式思维转化为实际项目的核心竞争力。
通过这个课程的学习,你已经掌握了Spring Boot开发的完整知识体系,从基础概念到高级特性,从开发到部署,从命令式编程到响应式编程。这些知识将为你构建企业级Spring Boot应用打下坚实的基础。 继续实践和探索,将这些知识应用到实际项目中,你会不断发现新的挑战和解决方案,这正是软件开发的魅力所在!