子查询
子查询(Subquery)是指嵌套在其他SQL语句(如SELECT、INSERT、UPDATE、DELETE等)内部的查询语句。它本质上是一个“查询中的查询”,用于为主查询(Outer Query)动态提供数据或条件。子查询通常被圆括号括起来,作为表达式、条件或临时结果集参与主查询的逻辑。 根据SQL标准,子查询的执行顺序通常优先于主查询,但在实际执行计划中,数据库优化器可能会对其进行重写以提升性能。
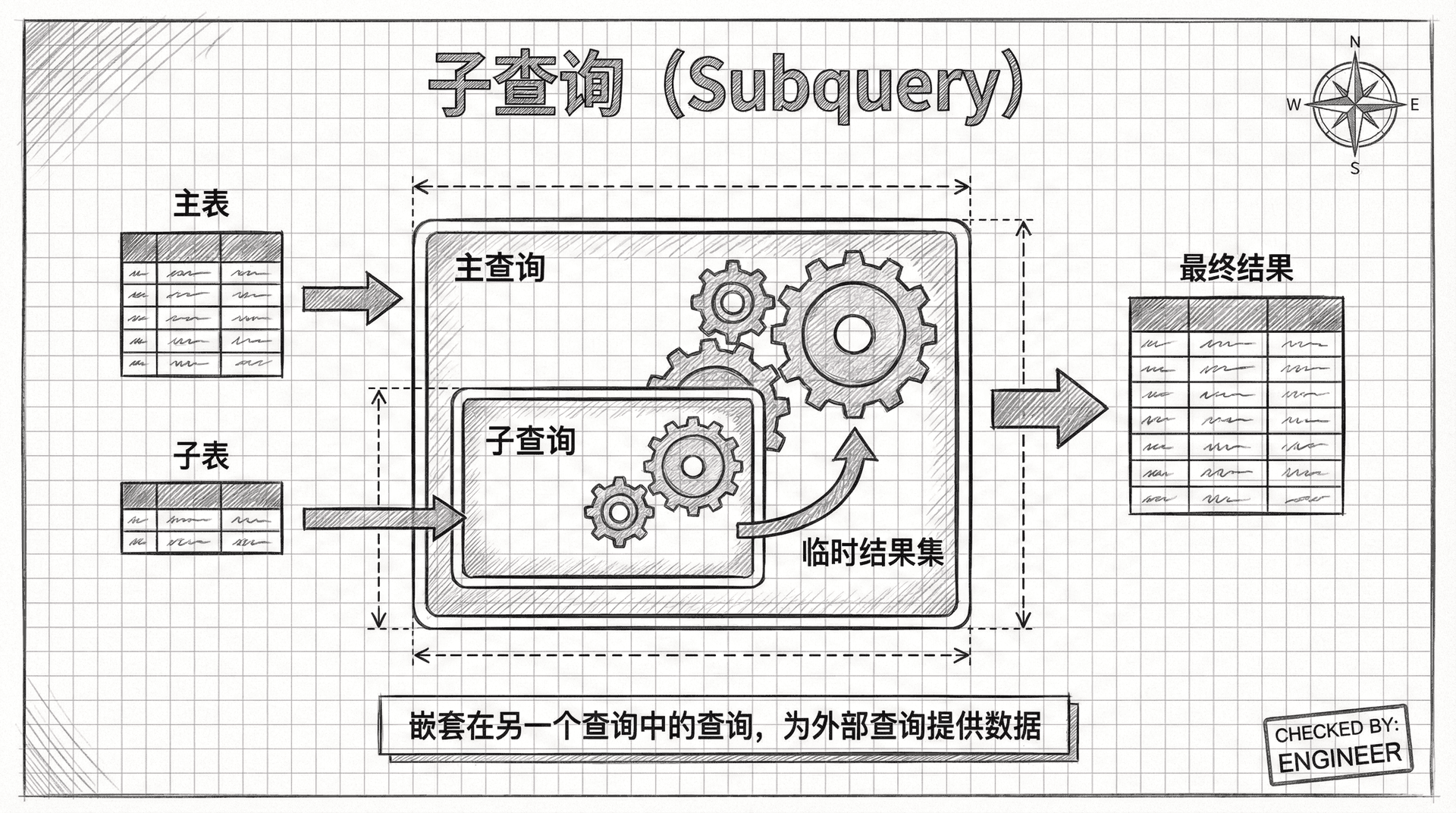
从返回结果的结构来看,子查询可以分为以下三类:
- 单行单列子查询(Scalar Subquery):返回唯一的一个值(单个标量),常用于需要一个具体数值或字符串的场景。例如:
SELECT ... WHERE salary > (SELECT AVG(salary) FROM employees); - 多行单列子查询(Column Subquery):返回一列多行数据,常用于IN、ANY、ALL等操作符的集合比较。例如:
SELECT ... WHERE dept_id IN (SELECT dept_id FROM departments WHERE location = '北京'); - 多行多列子查询(Table Subquery):返回多行多列的结果集,通常作为临时表参与主查询的JOIN或FROM子句。例如:
SELECT ... FROM (SELECT ... FROM ...) AS temp_table;
让我们看一个简单的例子。假设我们有一个学生成绩表,想要找出成绩最高的学生信息:
sql
SELECT student_name, subject, score
FROM grades
WHERE score = (SELECT MAX(score) FROM grades);在这个例子中,(SELECT MAX(score) FROM grades) 就是一个子查询。它首先计算出所有成绩中的最高分,然后主查询利用这个结果来找出获得最高分的学生。
子查询的执行结果就像一个临时表,只在当前SQL语句执行期间存在。当整个查询完成后,子查询的结果会被丢弃,释放内存空间。
非相关子查询
标量子查询
标量子查询(Scalar Subquery)是指返回恰好一行一列结果的子查询。由于其结果是单一的标量值,因此可以像普通常量或字段一样,直接参与各种比较、赋值和运算操作。标量子查询广泛应用于WHERE、SELECT、HAVING等子句中,用于动态获取聚合值、计算结果或外部依赖数据。
在实际应用中,标量子查询常用于以下场景:
- 作为比较条件:与主查询的字段进行大小、等值等比较,实现动态筛选。
- 作为计算列:在
SELECT子句中生成动态计算结果,为每一行提供额外信息。 - 作为赋值来源:在
UPDATE、INSERT等语句中为字段赋予动态值。
标量子查询的优势在于能够将复杂的业务逻辑内嵌到SQL语句中,实现高度动态化和自动化的数据处理,是SQL开发中极为重要和常用的子查询类型。
sql
-- 查找工资高于公司平均工资的员工
SELECT emp_name, department, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);需要注意的是,标量子查询必须保证只返回一行一列,否则数据库会抛出“子查询返回多行”或“子查询返回多列”的错误。因此,在设计标量子查询时,通常会结合聚合函数(如AVG、MAX、MIN等)或唯一性约束,确保结果的唯一性。
我们看下下面这个错误例子:
sql
-- 错误示例:子查询返回多行
SELECT product_name, price
FROM products
WHERE category_id = (
SELECT category_id
FROM categories
WHERE category_name LIKE '%电子%'
);假设有多个包含「电子」的分类,这个查询就会报错,因为一个值不能等于多个值。
当使用等号(=)、不等号(!=)或其他比较操作符时,确保子查询只返回一行数据。否则数据库会抛出错误。
多行单列子查询
当子查询返回多行(但通常只包含一列)结果时,不能直接用等号(=)等比较操作符进行判断。此时,必须借助专门用于集合比较的操作符来处理这些结果集。 常用的集合操作符包括 IN、NOT IN、ANY、ALL 等,它们能够让主查询的某个字段与子查询返回的多个值进行灵活的匹配和比较,从而实现更复杂的数据筛选和业务逻辑。
IN 和 NOT IN 操作符
IN 操作符(IN Operator)用于判断某个字段的取值是否包含在子查询返回的结果集中。其本质是将主查询中的某个值与子查询返回的所有值进行集合匹配,只要存在任意一个匹配项,条件即为真。
该操作符常用于需要判断某个实体是否属于一组动态生成的数据集合的场景,极大提升了查询的灵活性和表达能力。
使用 IN 操作符时,子查询通常返回单列多行结果,主查询会依次将字段值与子查询结果集进行比较。例如,可以用来筛选出那些在某些特定条件下出现过的记录,或实现复杂的交叉筛选逻辑。
需要注意的是,IN 操作符的子查询结果集必须与主查询字段的数据类型兼容,否则会导致类型不匹配错误。 此外,IN 操作符在处理大规模数据时,数据库会自动优化为高效的集合查找,通常性能较好,但在极大数据量下仍需关注执行效率。
sql
-- 查找购买过电子产品的顾客
SELECT customer_name, phone
FROM customers
WHERE customer_id IN (
SELECT DISTINCT customer_id
FROM orders o
JOIN products p ON o.product_id = p.product_id
WHERE p.category = '电子产品'
);NOT IN 操作符的作用与 IN 相反,用于查找那些其字段值不在子查询结果集中的记录。也就是说,主查询会返回所有不属于子查询返回集合的行。 例如,可以用来筛选那些从未发生过某种行为的对象,比如从未下过订单的顾客。需要注意的是,如果子查询结果中包含 NULL 值,NOT IN 的判断可能会导致整个条件无法正确匹配,因此实际使用时应确保子查询结果不包含 NULL。
sql
-- 查找从未下过订单的顾客
SELECT customer_name, email
FROM customers
WHERE customer_id NOT IN (
SELECT DISTINCT customer_id
FROM orders
WHERE customer_id IS NOT NULL
);使用 NOT IN 时要特别小心 NULL 值。如果子查询结果中包含 NULL,整个 NOT IN 条件可能返回意想不到的结果。建议在子查询中添加 WHERE column IS NOT NULL 来排除 NULL 值。
ALL 操作符
ALL 操作符(ALL Operator)用于将主查询中的某个字段与子查询返回的所有值逐一进行比较,只有当该字段与子查询结果集中的每一个值都满足指定的比较条件时,整个条件才为真。
换句话说,ALL 要求主查询的字段在与子查询返回的所有值进行比较时,无一例外地全部成立。常见的用法包括 > ALL(大于所有值)、< ALL(小于所有值)等。
例如,salary > ALL (子查询) 表示“工资比子查询返回的所有工资都高”。需要注意的是,如果子查询结果为空,ALL 条件总是为真;如果子查询结果中包含 NULL,则比较结果为 UNKNOWN(在 WHERE 子句中等同于假)。
sql
-- 查找比所有管理员工资都高的员工
SELECT emp_name, salary, department
FROM employees
WHERE salary > ALL (
SELECT salary
FROM employees
WHERE position = '管理员'
AND salary IS NOT NULL
);上面的查询语句相当于说:「找出工资比最高管理员工资还要高的员工」。
ANY 操作符
ANY 操作符(ANY Operator)用于将主查询中的某个字段与子查询返回的所有值逐一进行比较,只要有任意一个值满足指定的比较条件,整个条件就为真。
换句话说,ANY 只要主查询的字段和子查询结果集中的至少一个值比较成立,条件就成立。常见的用法包括 > ANY(大于任意一个值)、< ANY(小于任意一个值)、= ANY(等价于 IN 操作符)等。
举例来说,salary > ANY (子查询) 表示“工资比子查询返回的至少一个工资高”。如果子查询结果中有多个值,只要有一个值让比较条件成立,主查询的这行数据就会被选中。
需要注意的是,如果子查询结果为空,ANY 条件总是为假;如果子查询结果中包含 NULL,只有与非 NULL 值的比较成立时才会返回结果,NULL 不会影响其他值的判断。
sql
-- 查找工资比任何一个销售员都高的员工
SELECT emp_name, salary, department
FROM employees
WHERE salary > ANY (
SELECT salary
FROM employees
WHERE department = '销售部'
AND salary IS NOT NULL
);上面的查询语句相当于说:「找出工资比最低销售员工资高的员工」。
操作符对比表
多列子查询
在实际的数据库查询中,业务需求常常要求我们对多列数据进行联合比较。所谓多列子查询(Multi-column Subquery),是指子查询一次性返回多列结果,主查询则可以将自身的多列字段与子查询结果集中的多列进行逐行组合匹配。 这种方式通常用于需要同时满足多个字段联合条件的场景,例如判断某组(如城市与员工ID)的组合是否存在于另一张表的结果集中。
多列子查询的典型写法是:在主查询的 WHERE 子句中使用类似 (col1, col2) IN (SELECT colA, colB FROM ...) 的语法结构。这样,只有当主查询的 col1 和 col2 的组合与子查询结果集中的某一行 colA 和 colB 完全一致时,该行才会被选中。
需要注意以下几点专业细节:
- 多列子查询的列数和主查询用于比较的列数必须严格一致,且顺序对应。
- 多列比较通常依赖于数据库对元组(tuple)比较的支持,主流的关系型数据库(如 PostgreSQL、MySQL、Oracle)均支持此语法。
- 多列子查询不仅可以用于 IN 操作符,还可以与 EXISTS、NOT IN 等结合,实现更复杂的业务逻辑。
- 在大数据量场景下,建议关注执行计划,合理利用索引,避免因多列匹配导致的性能瓶颈。
下面是一个简单的例子:
sql
-- 查找在特定城市由特定销售员开设的账户
SELECT account_id, customer_id, account_type
FROM accounts
WHERE (branch_city, sales_emp_id) IN (
SELECT b.city, e.emp_id
FROM branches b
JOIN employees e ON b.branch_id = e.branch_id
WHERE b.city = '上海'
AND e.position = '高级销售'
在这个例子中,我们同时比较了分支城市和销售员ID两个条件。主查询的 (branch_city, sales_emp_id) 必须与子查询返回的某一行的 (city, emp_id) 完全匹配。
相关子查询
与非相关子查询不同,相关子查询的执行过程会依赖于主查询(外部查询)当前处理的那一行数据。也就是说,子查询内部会引用主查询的某些字段,每当主查询处理一行数据时,子查询就会根据这行数据的具体值动态生成查询条件,并执行一次。
这种执行方式类似于嵌套循环(Nested Loop):主查询每处理一行,都会触发子查询重新运行一次,子查询的结果会根据主查询当前行的字段而变化。这样,相关子查询可以实现对主查询每一行的动态判断、比较或聚合,非常适合需要行级别逻辑处理的复杂业务场景。 例如,判断某个员工的工资是否为其部门最高,或者某个订单是否满足特定的客户条件等。
需要注意的是,由于相关子查询会被多次执行(每一行一次),在数据量较大时可能会带来性能压力。因此,在实际应用中要权衡其灵活性与性能影响,合理设计查询结构。
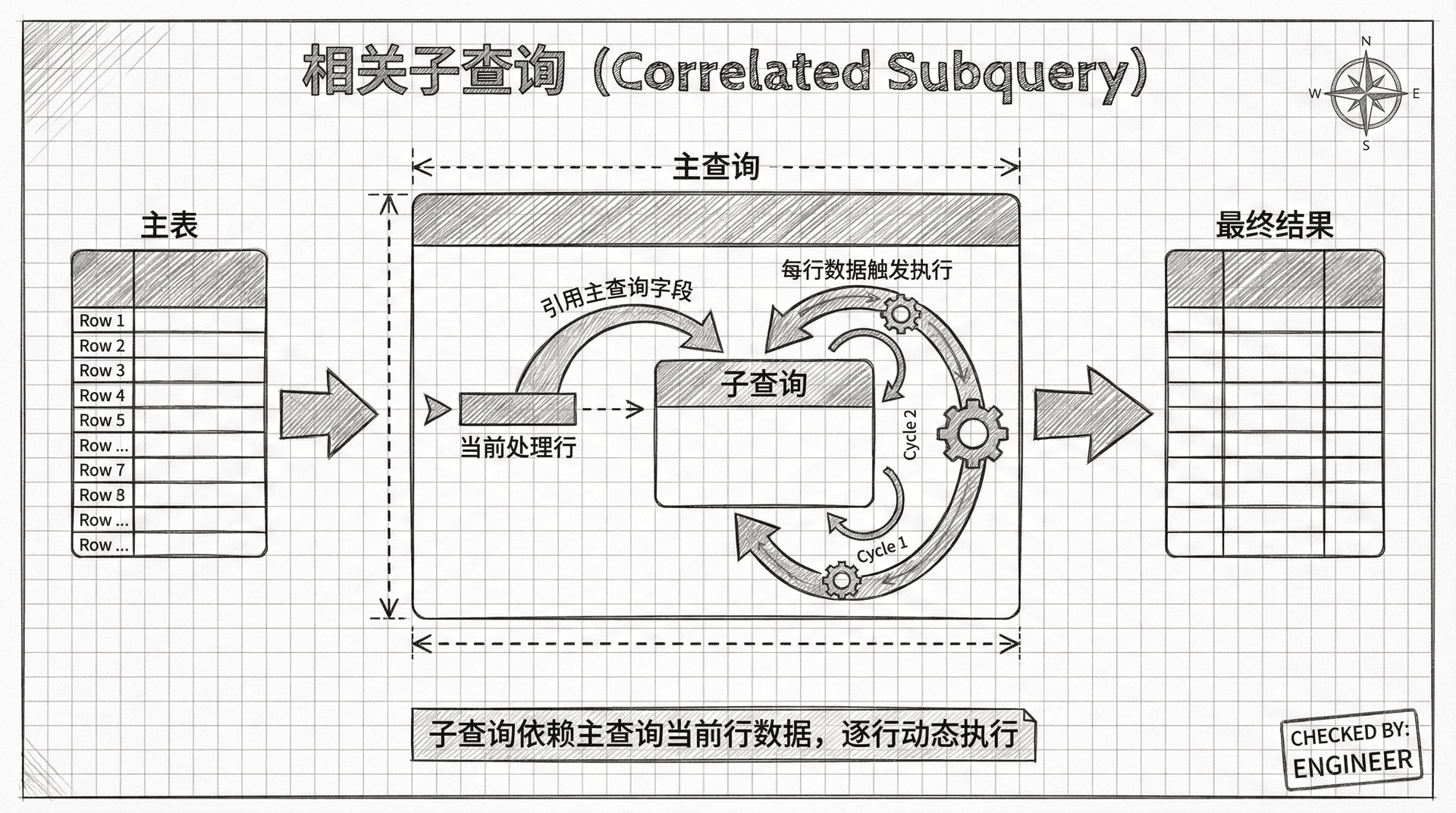
相关子查询的执行原理
让我们通过一个具体例子来理解相关子查询的执行过程:
sql
-- 查找每个部门中工资最高的员工
SELECT e1.emp_name, e1.department, e1.salary
FROM employees e1
WHERE e1.salary = (
SELECT MAX(e2.salary)
FROM employees e2
WHERE e2.department = e1.department
);这个查询的执行流程是这样的:
相关子查询为主查询的每一行都执行一次,这使得它能够进行行级别的动态比较,但也意味着执行效率相对较低。
EXISTS 操作符
EXISTS 操作符(EXISTS Operator)是 SQL 中专门用于配合相关子查询的高效存在性判断工具。其核心作用在于判断子查询是否能够返回至少一行数据,而并不关心子查询实际返回的内容或列值。
在执行过程中,数据库会针对主查询的每一行,动态运行子查询,一旦子查询返回任意一行结果,EXISTS 条件即为真,主查询当前行即被选中;如果子查询结果为空,则条件为假。
EXISTS 的实现机制通常非常高效:数据库在检测到子查询有一行满足条件时就会立即停止子查询的进一步扫描(即“短路”机制),无需遍历全部结果集。 这使得 EXISTS 特别适合用于大数据量下的存在性检查、去重、过滤等场景,尤其是在需要判断某一外部实体是否与主表存在关联关系时。
需要注意的是,EXISTS 子查询内部通常会引用主查询的字段(形成相关子查询),从而实现基于主查询当前行的动态条件判断。
sql
-- 查找有订单记录的顾客
SELECT c.customer_name, c.email, c.city
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);使用 EXISTS 时,子查询的 SELECT 列表并不重要,通常我们写作 SELECT 1 或 SELECT *。数据库只关心子查询是否返回行,而不关心返回的具体内容。
NOT EXISTS 操作符的作用与 EXISTS 相反,用于查找那些其字段值不在子查询结果集中的记录。也就是说,主查询会返回所有不属于子查询返回集合的行。 例如,可以用来筛选那些从未发生过某种行为的对象,比如从未下过订单的顾客。需要注意的是,如果子查询结果中包含 NULL,NOT EXISTS 的判断可能会导致整个条件无法正确匹配,因此实际使用时应确保子查询结果不包含 NULL。
sql
-- 查找从未下过订单的顾客
SELECT c.customer_name, c.email
FROM customers c
WHERE NOT EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);在数据操作中使用相关子查询
相关子查询不仅局限于 SELECT 查询语句,在实际数据库开发中,它们同样广泛应用于 UPDATE 和 DELETE 等数据操作语句中。 通过在这些语句的 SET、WHERE 等子句中嵌入相关子查询,可以实现基于主表当前行动态条件的复杂数据更新与删除操作。 例如,利用相关子查询可以为每一行计算并赋予与之关联的最新、最大、最小等聚合值,或根据外部表的存在性、匹配关系精准筛选需要被修改或删除的数据行。 这种用法极大增强了 SQL 语句的灵活性和表达能力,是实现复杂业务逻辑和数据一致性的重要手段。
UPDATE 语句中的相关子查询
sql
-- 更新每个顾客的最后订单日期
UPDATE customers c
SET c.last_order_date = (
SELECT MAX(o.order_date)
FROM orders o
WHERE o.customer_id = c.customer_id
)
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.
这个例子展示了两个重要的技巧:
- 在 SET 子句中使用相关子查询来计算新值
- 在 WHERE 子句中使用 EXISTS 来确保只更新有订单的顾客,避免将没有订单的顾客的日期设为 NULL
DELETE 语句中的相关子查询
sql
-- 删除没有任何员工的部门
DELETE FROM departments d
WHERE NOT EXISTS (
SELECT 1
FROM employees e
WHERE e.department_id = d.department_id
);相关子查询与性能考虑
相关子查询在功能表达上极为灵活,能够实现基于主查询当前行动态条件的复杂筛选与数据处理。然而,从执行机制来看,相关子查询通常会针对主查询返回的每一行分别执行一次子查询,这种“嵌套循环”式的执行方式在数据量较大时会显著增加查询的计算成本,导致整体性能下降。 尤其是在主表数据量较大、子查询逻辑复杂或缺乏有效索引的情况下,相关子查询可能成为SQL性能瓶颈。
在实际数据库优化中,常见的做法是将部分可以等价转换的相关子查询重写为等价的连接(JOIN)操作。通过将原本在子查询中进行的条件判断转化为表之间的连接,数据库优化器能够采用更高效的执行计划(如哈希连接、合并连接等),大幅提升查询性能。 需要注意的是,JOIN 重写并不总是适用,只有在业务逻辑允许的情况下才能进行等价替换,且需关注结果集的唯一性和去重问题。
下面以典型的“EXISTS”相关子查询为例,展示如何用 JOIN 方式进行性能优化:
sql
-- 使用相关子查询(较慢)
SELECT c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
-- 使用连接重写(通常更快)
SELECT DISTINCT c.customer_name
FROM customers c
INNER JOIN orders o ON c.customer_id = o.customer_id不过,相关子查询在某些复杂场景下是不可替代的,特别是当我们需要进行行级别的条件判断时。
子查询的应用场景
子查询的应用远不止于简单的数据筛选。实际上,子查询可以嵌入到 SQL 语句的几乎所有主要部分,包括 SELECT、FROM、WHERE、HAVING、UPDATE、INSERT、DELETE 等子句中,极大地增强了 SQL 的表达能力和灵活性。 通过合理运用子查询,我们可以实现动态条件筛选、分组统计、数据转换、复杂的业务逻辑判断、临时表构建等多种高级功能。下面我们将详细介绍子查询在实际开发中的几个典型应用场景,并通过具体示例帮助你理解每种用法的原理和优势。
子查询作为数据源
在 SQL 查询中,子查询嵌入 FROM 子句作为“派生表”或“内联视图”(Derived Table / Inline View)是最具威力和灵活性的用法之一。 通过这种方式,我们可以动态构建一个仅在当前查询生命周期内存在的临时结果集,相当于创建了一张数据库中并不存在的“虚拟表”。 这种虚拟表可以包含聚合、分组、筛选、计算字段等复杂逻辑,极大地扩展了 SQL 的表达能力。
主查询随后可以像操作普通表一样,对该临时表进行 JOIN、筛选、排序等操作,实现多阶段、分层的数据处理流程。需要注意的是,FROM 子句中的子查询必须是非相关子查询(即不依赖主查询的字段),以便数据库在主查询执行前先完整生成该临时结果集。 这种技术在复杂报表、分组统计、动态数据转换等场景中尤为常见,是高级 SQL 开发不可或缺的工具。
sql
-- 先计算每个部门的员工数量,然后与部门表连接
SELECT d.dept_name, d.location, emp_count.total_employees
FROM departments d
INNER JOIN (
SELECT dept_id, COUNT(*) as total_employees
FROM employees
GROUP BY dept_id
) emp_count ON d.dept_id = emp_count.dept_id;这个查询首先通过子查询计算出每个部门的员工数量,然后将这个“临时表”与部门表连接,获得部门名称和位置信息。
在 FROM 子句中使用的子查询必须是非相关的,因为它们需要在主查询执行前就生成完整的结果集。
动态数据生成
在实际业务分析中,我们经常会遇到这样一种需求:需要对数据进行分组、分类或标签化,但这些分组规则本身并未以表的形式存储在数据库中。这时,可以借助子查询(尤其是内联视图/派生表)在查询过程中动态生成分组定义,实现灵活的数据分组与统计。
例如,假设我们希望根据客户的年收入水平,将所有客户划分为“低收入群体”、“中等收入群体”和“高收入群体”三类。由于这些分组标准是临时定义的,并不在数据库的物理表中存在,我们可以通过在 FROM 子句中嵌入一个包含分组规则的子查询(通常用 UNION ALL 拼接多行),再与客户表进行关联,实现动态分组统计。
sql
-- 首先定义收入分组规则
SELECT
income_groups.group_name,
COUNT(*) as customer_count
FROM customers c
INNER JOIN (
SELECT '低收入群体' as group_name, 0 as min_income, 30000 as max_income
UNION ALL
SELECT '中等收入群体' as group_name, 30000 as min_income, 80000 as max_income
UNION ALL
SELECT
这种方法的优势是不需要在数据库中创建额外的表来存储分组定义,所有的逻辑都包含在查询中。
任务导向的子查询
在实际的企业级报表分析和数据挖掘场景中,往往需要对原始数据进行多层次的汇总、统计和加工,然后再结合维度表或描述性信息进行丰富展示。 此时,子查询(尤其是嵌套在 FROM 子句中的派生表/内联视图)能够将复杂的业务逻辑拆解为多个有序、可读性强的步骤:首先在子查询中完成核心的聚合、分组、筛选等数据处理,生成中间结果集;
随后在主查询中通过 JOIN 关联产品、门店、员工等维度表,补充详细的业务属性,实现数据的多维度展现和分析。 这样的分层设计不仅提升了 SQL 语句的可维护性和扩展性,还能充分利用数据库的执行优化能力,提高查询性能,是数据仓库、商业智能等专业领域中常用的高级查询模式。
sql
-- 第一步:通过子查询计算核心数据
-- 第二步:连接其他表获取描述信息
SELECT
p.product_name,
b.branch_name,
e.emp_name,
sales_summary.total_amount
FROM (
-- 核心汇总逻辑
SELECT
product_id,
branch_id,
sales_emp_id,
SUM(sale_amount) as total_amount
FROM sales
WHERE sale_date >= '2024-01-01'
这种结构的好处是逻辑清晰,性能通常也更好,因为汇总操作是在较小的数据集上进行的。
子查询作为表达式
子查询不仅可以作为筛选条件出现在 WHERE、HAVING 等子句中,还可以直接嵌入到 SELECT 子句,用于为每一行动态计算衍生字段或统计指标。 这种用法通常被称为“标量子查询”或“相关子查询作为表达式”,其核心优势在于能够针对主查询的每一行,实时生成与当前行数据相关的统计值、排名、聚合结果等。 例如,可以在结果集中为每个员工动态显示其在本部门的工资排名、部门平均工资、累计销售额等业务指标。此类写法极大提升了 SQL 查询的灵活性和表达能力,是数据分析、报表开发中常用的高级技巧。
需要注意的是,嵌入 SELECT 子句的子查询通常会引用主查询的字段,因此属于相关子查询,执行时会针对主查询的每一行分别计算,可能对性能有一定影响,建议在数据量较大时结合索引优化或考虑其他实现方式。
sql
-- 在结果中显示每个员工的工资及其在部门中的排名
SELECT
emp_name,
department,
salary,
(SELECT COUNT(*) + 1
FROM employees e2
WHERE e2.department = e1.department
AND e2.salary > e1.salary) as dept_salary_rank,
(SELECT AVG(salary)
FROM employees e3
这个查询为每个员工计算了两个动态字段:在部门内的工资排名和部门平均工资。
在 INSERT 语句中使用子查询
在 INSERT 语句中,子查询同样可以发挥重要作用,尤其是在需要根据其他表的动态数据来确定插入值时。最常见的场景是为外键字段(如 customer_id、product_id 等)自动查找并填充对应的主键值,而无需提前手动查询。 通过在 VALUES 子句中嵌入标量子查询,可以实现插入时对相关表的实时数据检索和引用,从而保证数据的完整性和一致性。
这种用法不仅提升了 SQL 语句的自动化和灵活性,还能有效减少多次查询带来的代码冗余和潜在的并发问题。需要注意的是,嵌入 INSERT 的子查询必须保证只返回一行一列(即标量结果),否则会导致插入失败或数据异常。 此外,如果子查询未能查到匹配数据,插入的对应字段值将为 NULL,可能影响外键约束或数据完整性,因此建议在实际应用中结合唯一性约束和异常处理机制。
sql
-- 插入新订单时自动查找相关的ID
INSERT INTO orders (
customer_id,
product_id,
branch_id,
sales_emp_id,
order_date,
quantity
)
VALUES (
(SELECT customer_id FROM customers WHERE email = 'zhang@example.com'),
(SELECT product_id FROM products WHERE product_name = '智能手机'),
(SELECT branch_id FROM branches WHERE
这种方法避免了需要分别查询各个ID值的麻烦,但需要注意如果任何一个子查询没有找到匹配的记录,对应的列值会被设为 NULL。
性能优化建议
使用子查询时需要考虑性能影响。当我们需要动态生成数据或分组时,子查询是很好的选择。在逻辑复杂的情况下,子查询可以显著提高代码的可读性,让复杂的查询变得更容易理解和维护。对于一次性的查询任务,比如生成报表或数据分析,子查询的便利性往往超过了性能上的小幅损失。
然而,在某些场景下需要谨慎使用子查询。相关子查询在处理大数据集时可能会显著影响性能,因为它们需要为每一行都执行一次。如果一个复杂的子查询可以用简单的JOIN来替代,通常JOIN的性能会更好。另外,在需要频繁执行的查询中,比如网站的核心业务逻辑,应该优先考虑性能,避免使用复杂的子查询。
子查询是一个强大的工具,但并不是万能的。在实际应用中,需要根据具体情况在功能需求、代码可读性和执行性能之间找到平衡。
实战练习
练习1:标量子查询 - 查找高于平均工资的员工
有一个员工表 employees,包含字段 emp_id, emp_name, salary, department。需要找出工资高于公司平均工资的所有员工。
要求:
- 使用标量子查询计算平均工资
- 显示员工姓名、部门和工资
- 按工资降序排列
练习2:IN操作符 - 查找特定类别的产品
有两个表:products (product_id, product_name, category_id, price) 和 categories (category_id, category_name)。需要找出所有“电子产品”类别的产品信息。
要求:
- 使用IN操作符和子查询
- 显示产品名称、价格和类别名称
练习3:EXISTS操作符 - 查找有订单的顾客
有两个表:customers (customer_id, customer_name, email) 和 orders (order_id, customer_id, order_date, amount)。需要找出所有曾经下过订单的顾客。
要求:
- 使用EXISTS操作符
- 显示顾客姓名和邮箱
- 按姓名排序
练习4:相关子查询作为表达式 - 计算部门排名
使用练习一中的员工表 employees,需要为每个员工显示其在部门内的工资排名。
要求:
- 使用相关子查询在SELECT子句中
- 显示员工姓名、部门、工资和部门内排名
- 排名按工资降序(工资最高为1)
练习5:ALL操作符 - 查找比所有管理员工资都高的员工
员工表中有一个 position 字段,表示员工职位。需要找出工资比所有“管理员”职位员工都高的员工。
要求:
- 使用ALL操作符
- 排除NULL值
- 显示员工信息和管理员最高工资
练习6:多列子查询 - 匹配城市和职位的组合
假设我们现有员工表 employees (emp_id, emp_name, city, position, salary) 和一个“关键岗位”表 key_positions (city, position, min_salary)。需要找出在指定城市担任指定职位且工资达到最低要求的员工。
要求:
- 使用多列子查询
- 同时匹配城市和职位
- 工资必须达到最低要求
练习7:子查询作为数据源 - 部门销售统计
假设我们现有销售表 sales (sale_id, emp_id, amount, sale_date) 和员工表 employees (emp_id, emp_name, department)。需要统计每个部门的销售总额和平均销售额。
要求:
- 使用子查询在FROM子句中生成部门销售汇总
- 与员工表连接获取部门信息
- 显示部门名称、总销售额、平均销售额和员工数量
练习8:UPDATE中的相关子查询 - 更新最后活动日期
假设我们现有顾客表 customers (customer_id, customer_name, last_order_date) 和订单表 orders (order_id, customer_id, order_date)。需要更新每个顾客的最后订单日期。
要求:
- 使用相关子查询在UPDATE语句中
- 只更新有订单的顾客
- 避免将没有订单的顾客设为NULL
练习9:性能优化 - 将相关子查询转换为JOIN
假设我们现有顾客表 customers (customer_id, customer_name, last_order_date) 和订单表 orders (order_id, customer_id, order_date)。需要查找所有有订单的顾客,使用EXISTS的相关子查询。
原查询:
sql
SELECT c.customer_name, c.email
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);要求:
- 将上面的相关子查询重写为JOIN形式
- 比较两种写法的性能差异
- 确保结果完全一致