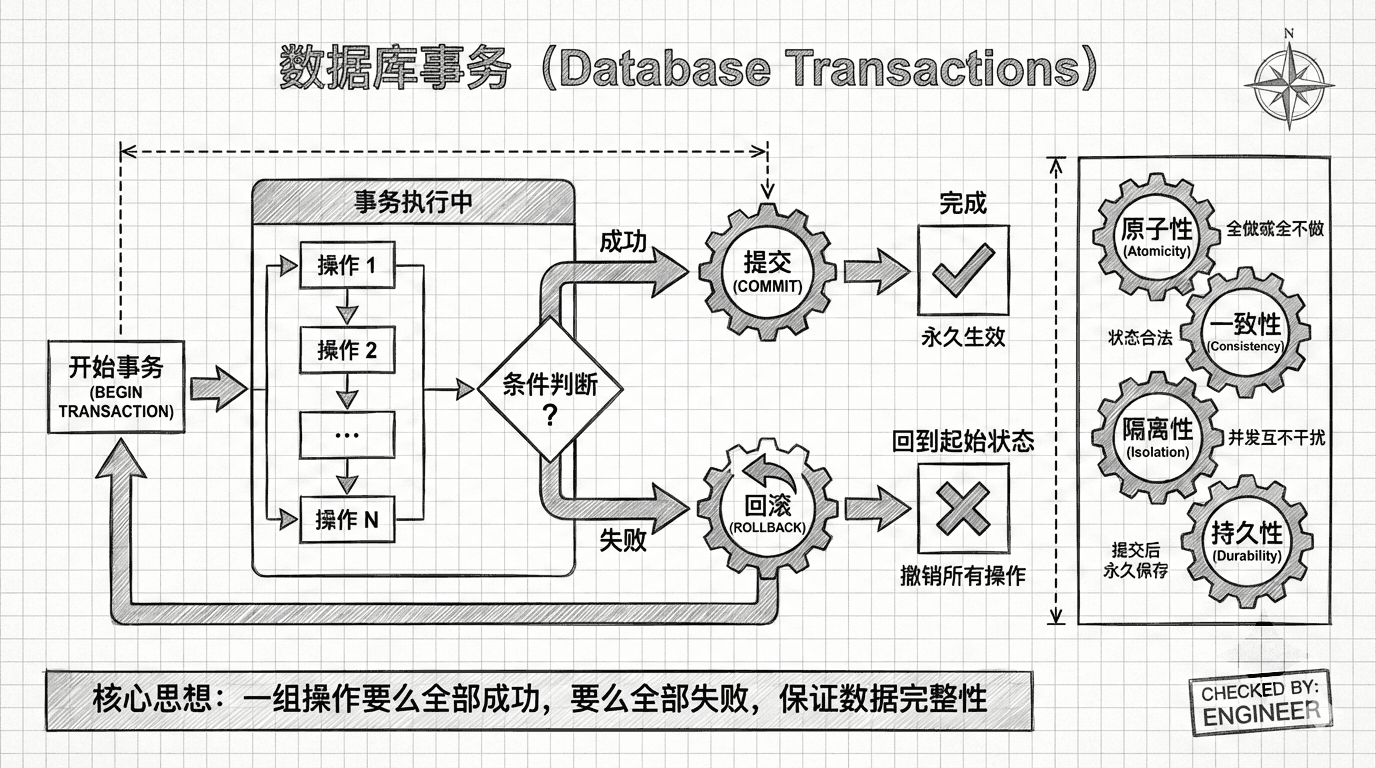
数据库事务
在前面的学习中,我们学习的都是单独执行的SQL语句。但在实际的应用开发中,我们经常需要将多个相关的SQL操作组合在一起执行,就像是一个不可分割的整体。 这就是我们今天要学习的“事务”概念。
我们来看一个手机银行转账的场景:从你的储蓄账户转500元到你的支票账户。 这个看似简单的操作,实际上在数据库层面需要执行两个步骤:先从储蓄账户减去500元,再向支票账户增加500元。 如果在这两个步骤之间出现了任何问题(比如系统崩溃、网络中断等),你肯定不希望钱从储蓄账户扣了,但没有到达支票账户。
事务就是将多个相关的数据库操作绑定在一起,确保它们要么全部成功执行,要么全部不执行,绝不会出现执行一半的情况。
多用户环境下的挑战
现代的数据库系统都需要支持多个用户同时访问和操作数据。当只有查询操作时,这通常不会造成问题。但当有用户在修改数据时,情况就复杂了。
让我们来看一个具体的例子。假设你是一家银行分行的经理,正在生成一份显示所有支票账户余额的报表。就在你的报表运行期间,银行里同时发生着这些事情:
一位柜员正在为客户办理存款业务,一位客户正在ATM机上取款,银行的月末批处理程序正在为账户计算利息。
这时候一个问题出现了:你的报表应该显示什么数据?是报表开始运行时的账户余额,还是报表运行过程中实时变化的余额? 这个问题的答案取决于数据库如何处理“锁定”机制。
在这个时间线中,我们可以看到多个操作同时进行。数据库需要决定报表应该看到哪个时间点的数据状态。
锁定机制
为了解决多用户同时访问数据的问题,数据库系统引入了“锁定”机制,就像交通信号灯一样管理着数据的访问权限。 当数据库的某部分被锁定时,其他想要修改(甚至可能是读取)这部分数据的用户就必须等待,直到锁被释放。
目前主流的数据库系统采用两种不同的锁定策略:
读写锁策略
这种策略要求用户在操作数据前必须获得相应的锁。想要修改数据的用户需要获得“写锁”,想要查询数据的用户需要获得“读锁”。 多个用户可以同时获得读锁来查询同一份数据,但写锁一次只能分配给一个用户,而且在有写锁的情况下,其他读锁请求也会被阻塞。
这就像图书馆的规则:多个人可以同时阅读同一本书的复印本(读锁),但如果有人要修改这本书的内容(写锁),其他人就不能同时阅读或修改。
版本控制策略
这种策略下,写操作仍然需要获得写锁,但读操作不需要任何锁。数据库通过维护数据的多个版本来确保读操作看到的是一致的数据快照。 即使在读操作进行期间有其他用户在修改数据,读操作看到的仍然是开始时刻的数据状态。
这就像你在看一张照片:不管现实中的场景如何变化,照片中的内容始终保持拍摄时的样子。
微软SQL Server使用读写锁策略,Oracle数据库使用版本控制策略,而MySQL则根据存储引擎的选择支持两种策略。
锁定粒度
数据库系统在决定锁定范围时,可以采用不同的粒度级别:
下表总结了三种主流数据库系统的锁定特性:
事务的本质
现在让我们回到开头提到的转账问题。在理想的世界里,数据库服务器永远不会宕机,用户永远不会中途取消操作,应用程序也永远不会遇到致命错误。 但现实是残酷的,这些情况都可能发生。
这就是为什么我们需要“事务”这个概念。事务是一种将多个SQL语句组合在一起的机制,确保它们要么全部成功执行,要么全部不执行。这种特性被称为“原子性”。
还是假设你要从储蓄账户向支票账户转账500元。如果储蓄账户的钱被成功扣除,但支票账户却没有收到这笔钱,你肯定会非常愤怒。 无论是什么原因导致的失败(服务器维护关机、页面锁请求超时等),你都希望你的500元能够安然无恙。
为了防止这种情况发生,处理转账请求的程序会首先开始一个事务,然后执行将钱从储蓄账户转移到支票账户所需的SQL语句。 如果一切顺利,程序会发出“提交”命令来结束事务。但如果发生意外,程序会发出“回滚”命令,指示服务器撤销自事务开始以来的所有更改。
让我们看一个具体的转账事务示例:
sql
-- 开始事务
START TRANSACTION;
-- 从储蓄账户扣款,确保余额充足
UPDATE account
SET available_balance = available_balance - 500
WHERE account_id = '6228481234567890'
AND available_balance >= 500;
-- 检查是否成功更新了一行
-- 如果是,继续向支票账户存款
UPDATE account
SET available_balance = available_balance + 500
WHERE account_id = '6228481234567891';
-- 如果两个操作都成功,提交事务
通过使用事务,程序确保你的500元要么留在储蓄账户中,要么转移到支票账户中,绝不会凭空消失或重复出现。
当事务完成时,无论是通过提交还是回滚,事务执行期间获得的所有资源(如写锁)都会被释放。
事务的持久性保证
即使程序成功完成了两个更新语句并且发出了提交命令,但如果服务器在更改应用到永久存储之前就关机了(即修改的数据还在内存中,没有刷新到磁盘),数据库服务器在重启时必须重新应用你事务中的更改。这种特性被称为“持久性”。
相反,如果你的程序完成了一个事务并发出了提交命令,但服务器在提交或回滚执行之前就关机了,那么数据库服务器必须在上线之前找到所有未完成的事务并将其回滚。
这个流程图清楚地展示了事务的执行逻辑:只有当所有操作都成功时,事务才会被提交;任何一个操作失败都会导致整个事务回滚。
事务的生命周期管理
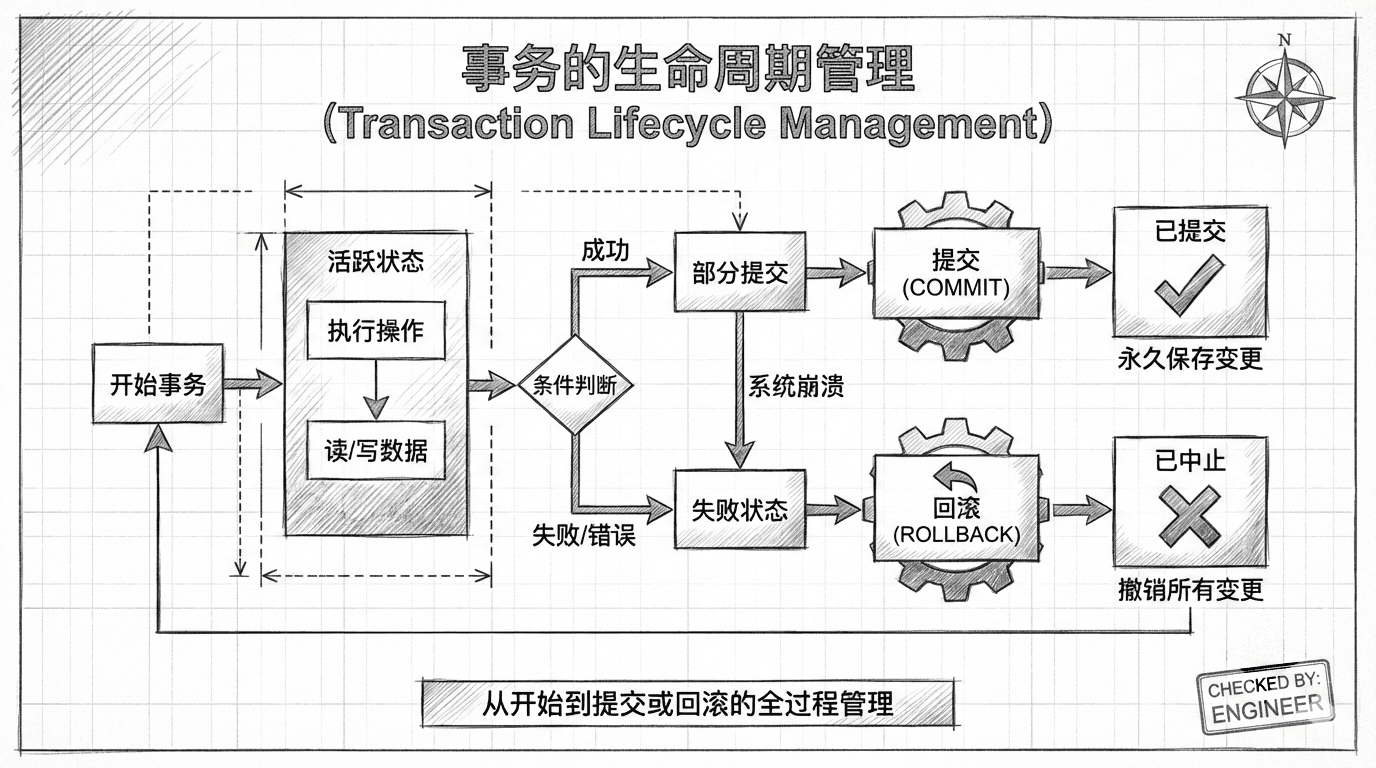
不同数据库的事务创建方式
各大数据库系统在处理事务创建时采用了不同的策略:
- Oracle数据库的方式:在Oracle中,每个数据库会话始终有一个活跃的事务,你无需(也无法)显式地开始一个事务。当当前事务结束时,服务器会自动为你的会话开始一个新的事务。这种方式的好处是,即使你只执行一个SQL语句,如果发现结果不符合预期,你仍然可以撤销更改。
- MySQL和SQL Server的方式:这两个数据库系统默认采用"自动提交"模式,除非你显式开始一个事务,否则每个SQL语句都会被自动提交。要开始一个事务,你需要发出相应的命令。
在MySQL中,你可以使用标准的SQL语法:
sql
START TRANSACTION;
-- 你的SQL语句
COMMIT;在SQL Server中,命令略有不同:
sql
BEGIN TRANSACTION;
-- 你的SQL语句
COMMIT;关闭自动提交模式
如果你希望像Oracle那样工作,可以关闭自动提交模式。在SQL Server中:
sql
SET IMPLICIT_TRANSACTIONS ON;在MySQL中:
sql
SET AUTOCOMMIT = 0;建议每次登录数据库时都关闭自动提交模式,并养成在事务中运行所有SQL语句的习惯。这样可以避免意外删除或修改重要数据时无法恢复的尴尬。
事务的结束方式
事务的结束方式多种多样,既包括用户主动发起的操作,也包括由数据库系统自动触发的情形:
正常结束
当你确认所有操作都按预期执行时,使用COMMIT命令让更改永久生效:
sql
COMMIT;如果你想要撤销事务中的所有更改,使用ROLLBACK命令:
sql
ROLLBACK;异常结束
除了主动提交或回滚,事务还可能在以下情况下被强制结束:
- 服务器关闭:如果数据库服务器意外关闭,所有未完成的事务会在服务器重启时自动回滚。
- 模式变更操作:当你执行表结构修改命令(如
ALTER TABLE)时,数据库会自动提交当前事务,然后执行模式变更操作,最后开始新事务。这是因为结构变更无法回滚,必须在事务之外执行。 - 开始新事务:如果你在当前事务未结束时再次发出
START TRANSACTION命令,前一个事务会被自动提交。 - 死锁检测:当数据库检测到死锁时,会选择其中一个事务进行回滚,以解除僵局。
死锁
死锁是一种特殊情况,当两个或多个事务互相等待对方释放资源时就会发生。
假设有这样一个场景:事务A刚刚更新了账户表,现在正在等待交易表的写锁,而事务B刚刚向交易表插入了一行,现在正在等待账户表的写锁。 如果两个事务恰好操作的是同一页或同一行数据,它们就会永远等待下去,形成死锁。
数据库系统必须时刻监控这种情况,以防止系统吞吐量陷入停滞。当检测到死锁时,系统会选择其中一个事务进行回滚,让另一个事务得以继续执行。
在MySQL中,被选中回滚的事务会收到这样的错误信息:
shell
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction如错误信息所建议的,重新执行被回滚的事务通常是一个合理的做法。但如果死锁频繁发生,你可能需要重新设计应用程序的数据访问模式,确保不同的事务以相同的顺序访问数据资源。
事务保存点
在某些情况下,你可能会在事务执行过程中遇到问题,需要回滚部分操作,但又不想撤销事务中已经成功完成的所有工作。这时候“保存点”就派上用场了。 保存点允许你在事务中设置多个检查点,然后选择性地回滚到任何一个检查点,而不必回滚到事务的开始。
保存点的使用方法
创建一个保存点非常简单,你只需要给它起一个名字:
sql
SAVEPOINT sp_更新产品;当你想要回滚到某个保存点时,使用以下语法:
sql
ROLLBACK TO SAVEPOINT sp_更新产品;让我们看一个实际的例子。假设你正在更新一个电商系统的产品数据,需要先停用某个产品,然后关闭所有使用该产品的账户:
sql
START TRANSACTION;
-- 第一步:停用产品
UPDATE product
SET retirement_date = CURRENT_TIMESTAMP()
WHERE product_code = 'MOBILE_PLAN_001';
-- 设置保存点
SAVEPOINT sp_关闭账户前;
-- 第二步:关闭相关账户
UPDATE account
SET status = 'CLOSED',
close_date = CURRENT_TIMESTAMP(),
last_activity_date = CURRENT_TIMESTAMP()
WHERE product_code = 'MOBILE_PLAN_001'
在这个例子中,最终的结果是产品被成功停用,但相关账户没有被关闭。
保存点只是在事务中设置的回滚目标,它本身不会保存任何数据。你仍然需要执行COMMIT命令才能让事务中的更改永久生效。
使用保存点的注意事项
在使用保存点时,有几个重要的原则需要记住:
如果你执行不带保存点名称的ROLLBACK命令,事务中的所有保存点都会被忽略,整个事务都将被撤销。
在SQL Server中,保存点的语法略有不同,你需要使用:
sql
SAVE TRANSACTION sp_保存点名称;
ROLLBACK TRANSACTION sp_保存点名称;MySQL存储引擎
与Oracle和SQL Server不同,MySQL采用了独特的模块化设计,允许你为不同的表选择不同的存储引擎。 这种设计给了你更大的灵活性,但也需要你了解各种存储引擎的特点。
主要存储引擎介绍
查看和设置存储引擎
要查看某个表使用的存储引擎,可以使用以下命令:
sql
SHOW TABLE STATUS LIKE 'user_account' \G输出结果会包含类似这样的信息:
shell
Name: user_account
Engine: InnoDB
Version: 10
Rows: 15420
Avg_row_length: 892
...如果你需要将某个表改为使用InnoDB引擎,可以执行:
sql
ALTER TABLE user_account ENGINE = InnoDB;对于需要参与事务的表,务必选择InnoDB存储引擎。MyISAM等不支持事务的引擎无法提供数据一致性保证。
实战演练
习题1:银行转账事务
假设有一个银行账户表 account,包含以下字段:
account_id(VARCHAR): 账户IDaccount_type(VARCHAR): 账户类型 ('SAVINGS' 或 'CHECKING')customer_id(INT): 客户IDavailable_balance(DECIMAL): 可用余额pending_balance(DECIMAL): 待处理余额
请编写一个完整的事务,实现从储蓄账户(A001)向支票账户(A002)转账1000元的功能。需要确保:
- 储蓄账户余额充足
- 两个账户都属于同一客户(customer_id = 1)
- 如果转账成功则提交,否则回滚
习题2:电商订单处理事务
假设有商品表 product 和订单表 order_table,表结构如下:
product表:
product_id(INT): 商品IDproduct_name(VARCHAR): 商品名称stock_quantity(INT): 库存数量unit_price(DECIMAL): 单价
order_table表:
order_id(INT): 订单IDcustomer_id(INT): 客户IDproduct_id(INT): 商品IDorder_quantity(INT): 订单数量order_date(DATETIME): 下单时间order_status(VARCHAR): 订单状态 ('PENDING', 'CONFIRMED', 'CANCELLED')
请编写事务处理逻辑:客户购买商品ID为1的商品,购买数量为2。需要:
- 检查商品库存是否充足
- 创建订单记录
- 减少商品库存
- 如果一切正常则提交,否则回滚
习题3:使用保存点的员工信息更新
假设有员工表 employee,包含以下字段:
employee_id(INT): 员工IDfirst_name(VARCHAR): 名last_name(VARCHAR): 姓department_id(INT): 部门IDsalary(DECIMAL): 薪资hire_date(DATE): 入职日期status(VARCHAR): 状态 ('ACTIVE', 'INACTIVE')
请编写使用保存点的事务:更新员工ID为1的信息,包括:
- 更新基本信息
- 设置保存点
- 调整薪资
- 如果薪资调整有问题,回滚到保存点
- 提交基本信息更新
习题4:库存管理系统并发控制
假设有库存表 inventory,包含以下字段:
product_id(INT): 商品IDwarehouse_id(INT): 仓库IDquantity(INT): 当前数量reserved_quantity(INT): 预留数量last_updated(DATETIME): 最后更新时间
请编写事务处理两个并发操作:
- 订单预留库存(增加reserved_quantity)
- 实际出库(减少quantity和reserved_quantity)
需要确保数据一致性,避免出现负库存。
习题5:多表关联的事务处理
假设有用户表 user 和积分表 points,表结构如下:
user表:
user_id(INT): 用户IDusername(VARCHAR): 用户名email(VARCHAR): 邮箱status(VARCHAR): 状态 ('ACTIVE', 'SUSPENDED')
points表:
user_id(INT): 用户IDtotal_points(INT): 总积分available_points(INT): 可用积分last_transaction_date(DATETIME): 最后交易时间
请编写事务:为用户(username='john_doe')增加100积分。需要:
- 检查用户状态为ACTIVE
- 更新积分表
- 如果用户不存在,需要先创建积分记录
- 确保数据一致性