国际化
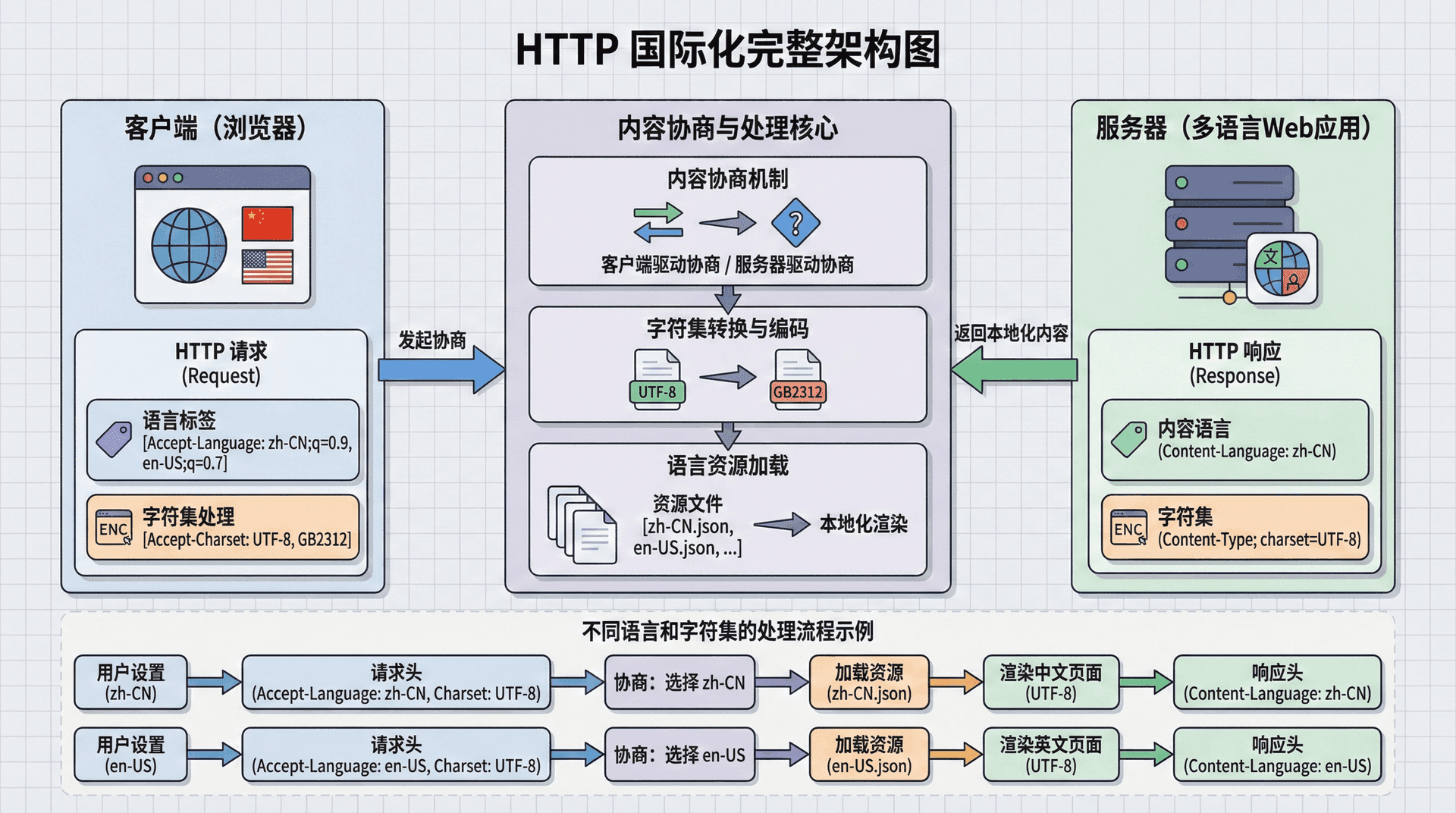
HTTP国际化(Internationalization,i18n)是Web应用支持多语言、多地区、多字符集的重要机制。国际化不仅仅是简单的翻译,它涉及字符编码、文本方向、日期格式、数字格式、货币格式等多个方面。
Web的国际化需求源于互联网的全球性特征。不同地区的用户使用不同的语言、字符集、文化习惯,Web应用需要能够适应这些差异,提供本地化的用户体验。HTTP协议提供了多种机制来支持国际化,包括字符集声明、语言标签、内容协商等。
字符集(Character Set)是国际化的基础。不同的语言使用不同的字符集,如英语使用ASCII,中文使用GB2312或UTF-8,日文使用Shift-JIS等。HTTP协议需要能够正确处理各种字符集,确保文本内容能够正确显示和传输。
语言标签(Language Tag)用于标识内容使用的语言和地区。HTTP协议使用BCP 47标准来定义语言标签,如en-US表示美式英语,zh-CN表示简体中文,ja-JP表示日文等。语言标签可以用于内容协商,服务器根据客户端的语言偏好返回相应语言的内容。
内容协商(Content Negotiation)是HTTP协议中用于根据客户端偏好选择最合适内容表示的机制。内容协商可以基于多种因素,如语言、字符集、内容类型等。
现代Web应用的国际化还需要考虑多个方面,包括字符编码的统一、语言标签的标准化、内容协商的优化等。
字符集
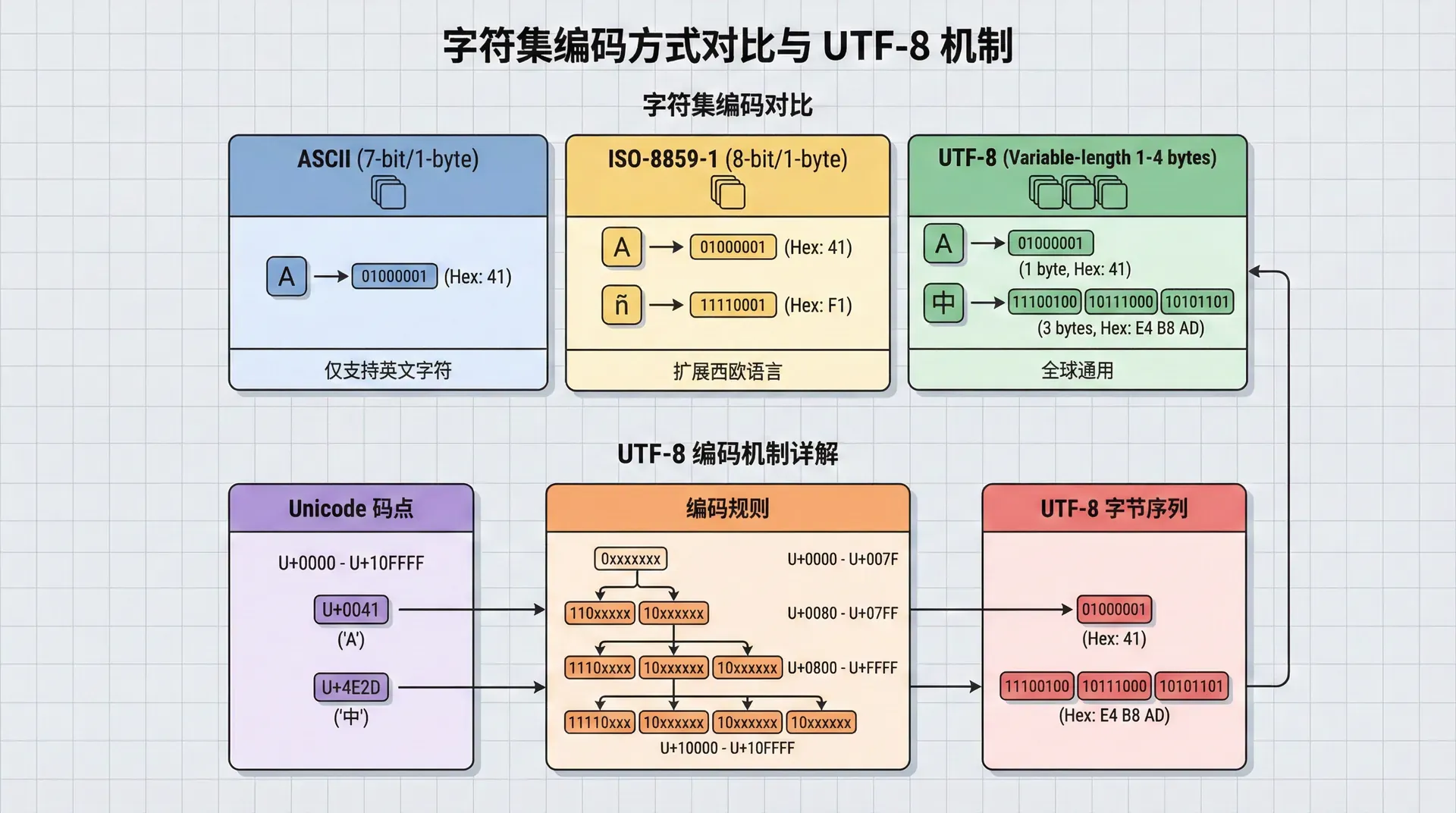
字符集是国际化的基础,它定义了如何将字节序列映射到字符。不同的字符集使用不同的编码方式,相同的字节序列在不同的字符集中可能表示不同的字符。
ASCII字符集的局限性
ASCII是最早的字符集,它使用7位编码,可以表示128个字符,包括英文字母、数字、标点符号等。ASCII虽然简单,但只能表示英语字符,无法表示其他语言的字符。为了支持更多语言,出现了各种扩展字符集,如ISO-8859系列、Windows代码页等。
扩展字符集的发展
各种扩展字符集试图解决ASCII的局限性,但它们之间存在兼容性问题。不同的扩展字符集使用相同的字节值表示不同的字符,这可能导致字符显示错误。这种不兼容性是国际化中的一个重要问题,直到Unicode的出现才得到解决。
Unicode的统一标准
Unicode是一个统一的字符集,它试图包含世界上所有语言的字符。Unicode使用代码点(Code Point)来标识每个字符,代码点是一个数字,范围从0到0x10FFFF。Unicode本身不定义如何编码这些代码点,而是由各种编码方案来实现,如UTF-8、UTF-16、UTF-32等。
UTF-8编码的优势
UTF-8是Unicode最常用的编码方案,它使用可变长度编码,英文字符占用1个字节,中文字符占用3个字节。UTF-8的优势在于它向后兼容ASCII,ASCII字符的UTF-8编码与ASCII编码相同。UTF-8还具有良好的网络传输特性,因为它不包含字节序标记,可以在不同字节序的系统之间传输。
UTF-8是现代Web应用的标准字符编码,它向后兼容ASCII,支持所有Unicode字符,具有良好的网络传输特性。现代Web应用应该始终使用UTF-8编码,这可以避免字符编码问题,简化国际化实现。
HTTP协议中的字符集声明
HTTP协议中,字符集通过Content-Type头的charset参数来指定,如Content-Type: text/html; charset=utf-8。客户端和服务器都需要正确设置和解析charset参数,以确保文本内容能够正确显示。如果charset参数缺失或错误,可能导致文本显示乱码。
字符集检测的挑战
字符集的检测也是一个重要问题。在某些情况下,Content-Type头可能没有指定charset,或者指定的charset不正确。客户端需要能够检测字符集,通常通过分析内容本身、使用默认字符集、或者提示用户选择字符集等方式。
字符集转换的复杂性
字符集的转换也是国际化中的一个重要方面。在某些场景中,内容可能需要从一种字符集转换为另一种字符集。字符集转换需要仔细处理,因为某些字符可能在一个字符集中存在,但在另一个字符集中不存在。字符集转换还可能导致信息丢失,特别是在从较大的字符集转换为较小的字符集时。
Language Tags
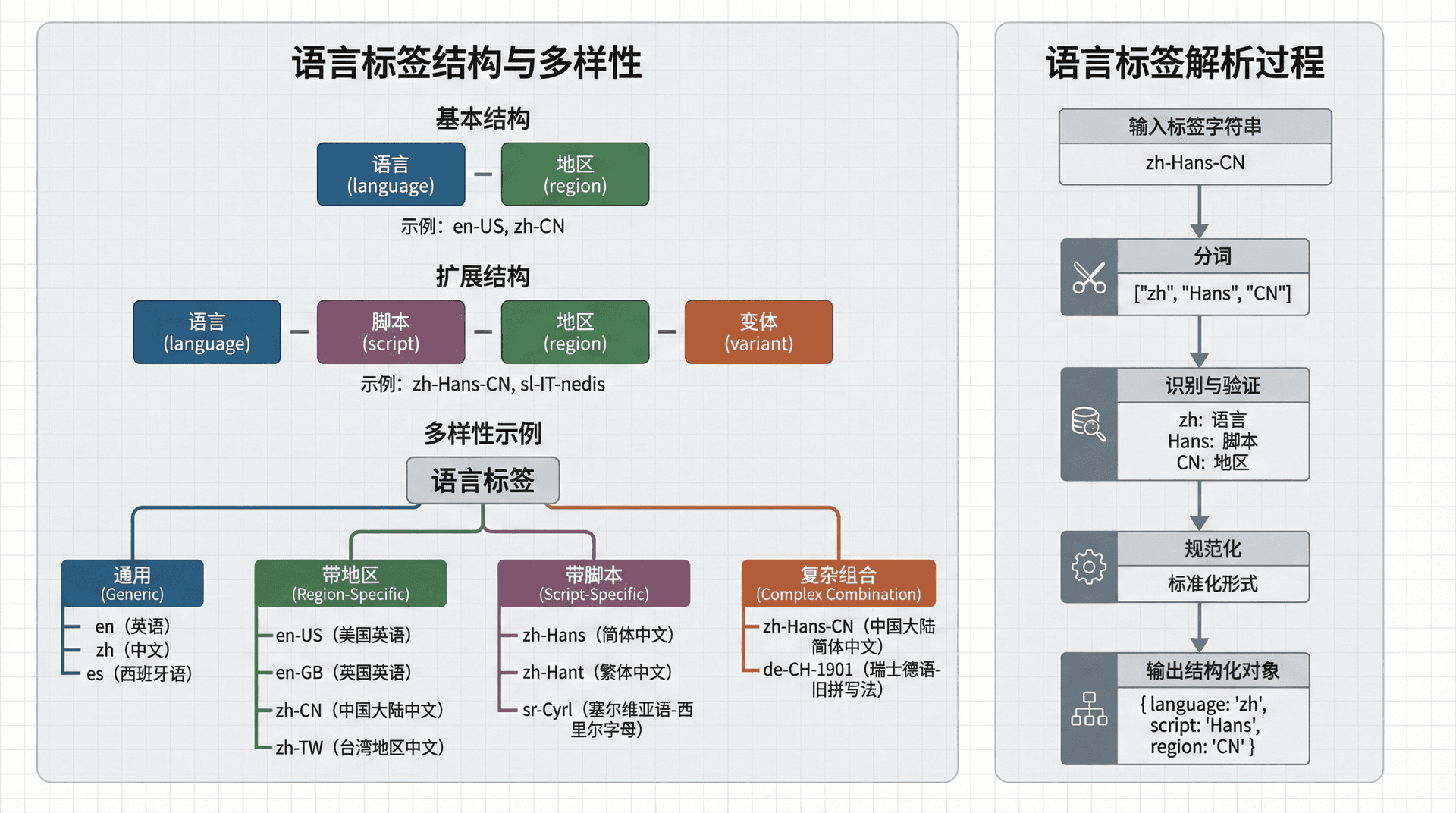
语言标签用于标识内容使用的语言和地区。HTTP协议使用BCP 47标准来定义语言标签,这是一个基于ISO 639语言代码和ISO 3166地区代码的标准。
语言标签的基本格式
语言标签的基本格式为"语言-地区",如en-US表示美式英语,zh-CN表示简体中文,fr-FR表示法式法语等。语言部分使用ISO 639代码,通常是两个字母,如en表示英语,zh表示中文,fr表示法语等。地区部分使用ISO 3166代码,通常是两个字母,如US表示美国,CN表示中国,FR表示法国等。
扩展格式的支持
语言标签还可以包含更多信息,如脚本、变体等。例如,zh-Hans-CN表示简体中文(中国大陆),其中Hans表示简体中文脚本。语言标签的解析需要遵循BCP 47的规则,正确处理各种格式和变体。
HTTP协议中的语言标签使用
语言标签在HTTP协议中通过多个头来使用。Accept-Language头用于客户端声明它接受的语言,服务器可以根据这个信息进行内容协商。Content-Language头用于服务器声明内容使用的语言,客户端可以根据这个信息来正确显示内容。
语言标签的匹配算法
语言标签的匹配是一个复杂的过程。客户端可能声明多个语言偏好,每个偏好都有一个质量值(q值),表示偏好的程度。服务器需要根据这些偏好选择最合适的语言。语言匹配需要考虑语言代码、地区代码、脚本等多个因素,还需要处理部分匹配、回退等情况。
语言标签的匹配是一个复杂的过程,需要考虑语言代码、地区代码、脚本等多个因素。服务器应该实现智能的匹配算法,能够处理部分匹配、回退等情况,确保用户能够获得最合适的内容。同时,应该提供合理的默认内容,确保即使没有匹配的偏好,也能提供可用的内容。
语言标签的标准化
语言标签的标准化也很重要。虽然BCP 47定义了标准格式,但在实际应用中,可能存在各种变体和扩展。服务器和客户端需要能够正确处理这些变体,同时也要遵循标准,确保互操作性。
内容协商
内容协商是HTTP协议中用于根据客户端偏好选择最合适内容表示的机制。内容协商可以基于多种因素,如语言、字符集、内容类型等。
内容协商的基本方式
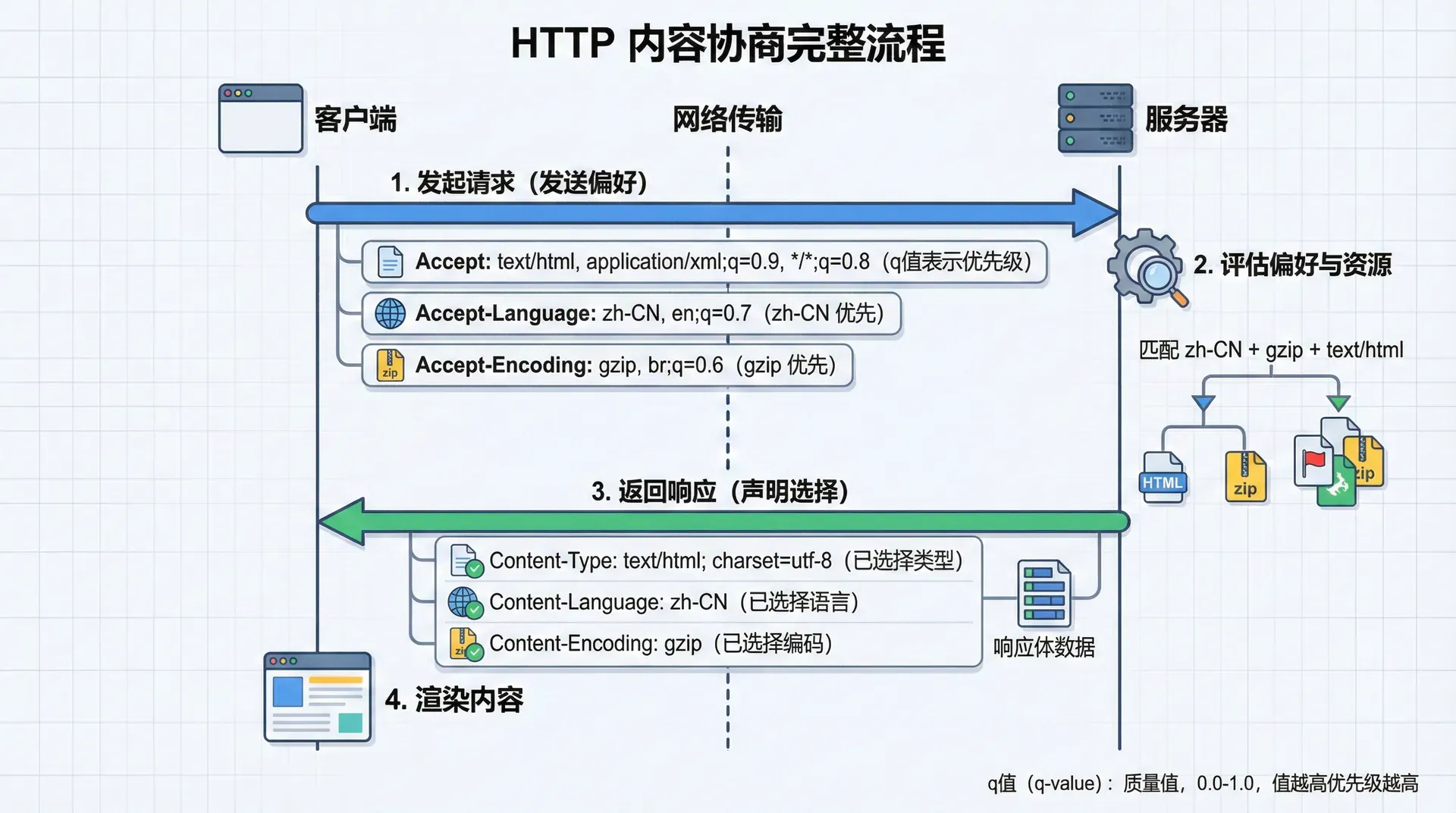
内容协商有两种基本方式:服务器驱动协商和客户端驱动协商。服务器驱动协商是服务器根据客户端的请求头(如Accept-Language、Accept-Charset、Accept等)来选择最合适的内容。客户端驱动协商是服务器返回多个选项,客户端选择最合适的内容。
服务器驱动协商的实现
服务器驱动协商是HTTP协议中最常用的方式。客户端在请求头中声明它的偏好,服务器根据这些偏好选择最合适的内容,并在响应头中声明选择的内容。例如,客户端发送Accept-Language: en-US, en;q=0.9, zh-CN;q=0.8,表示优先选择美式英语,其次是英语,再次是简体中文。服务器根据可用的内容选择最匹配的语言,并在Content-Language头中声明。
内容协商的算法
内容协商的算法需要考虑多个因素。首先是质量值(q值),它表示偏好的程度,范围从0到1,1表示最高偏好。服务器应该选择质量值最高的可用内容。其次是部分匹配,如果完全匹配不可用,服务器可以选择部分匹配的内容,如语言匹配但地区不匹配。再次是回退机制,如果没有任何匹配,服务器可以使用默认内容。
多因素内容协商
内容协商还可以基于其他因素,如内容类型、字符集、编码方式等。Accept头用于内容类型协商,Accept-Charset头用于字符集协商,Accept-Encoding头用于编码方式协商。这些协商机制可以组合使用,提供更精细的内容选择。
内容协商的性能和缓存
内容协商的实现需要考虑性能和缓存。内容协商可能增加服务器的处理负担,因为服务器需要为每个请求选择内容。内容协商还可能影响缓存,因为不同的客户端可能获得不同的内容,缓存需要考虑这些差异。Vary头用于声明响应可能因为某些请求头而不同,这对于正确缓存很重要。
内容协商可能影响缓存,因为不同的客户端可能获得不同的内容。服务器应该使用Vary头来声明响应可能因为哪些请求头而不同,这有助于缓存正确工作。同时,应该考虑内容协商的性能影响,避免过于复杂的协商逻辑。
小结
想要让你的Web应用真正服务全球用户,HTTP国际化是不可或缺的关键一步。国际化绝不是“把内容翻译一下”这么简单,它包含了字符编码、语言标签、内容协商、文本方向、日期、数字和货币格式等方方面面。这些细节哪怕只忽略一项,都可能对用户体验和业务拓展带来很大影响。
很多开发者在实际工作中可能会误用或者忽略某些国际化的细节,所以深入理解它们、正确地实现各项技术非常重要。只有把字符编码做统一、语言标签按标准来设置、内容协商合理运用、本地化细致落地,才有可能搭建一个真正适合全球用户的Web系统。