URL
在Web的世界里,URL(Uniform Resource Locator,统一资源定位符)就像现实世界中的地址一样,为我们提供了定位和访问网络资源的方式。每一个网页、每一张图片、每一个API端点,都通过URL来标识和访问。理解URL的结构、语法和特性,对于Web后端开发来说具有基础性的重要意义。URL不仅仅是简单的字符串,它们承载着丰富的语义信息,反映了Web资源的组织方式和访问机制。
URL的概念可以追溯到Web的早期发展阶段。在Tim Berners-Lee设计万维网时,他需要一种机制来唯一标识网络上的资源,这就是URL的起源。URL的设计目标是在全球范围内唯一地标识资源,同时提供足够的信息来访问这些资源。这个看似简单的需求实际上涉及了多个复杂的问题,包括命名空间的管理、协议的扩展、字符编码的处理、相对路径的解析等。
从技术规范的角度来看,URL是URI(Uniform Resource Identifier,统一资源标识符)的一个子集。URI是一个更广泛的概念,包括URL和URN(Uniform Resource Name,统一资源名称)。URL通过位置来标识资源,而URN通过名称来标识资源。在实际的Web开发中,我们几乎总是使用URL,因为我们需要知道如何访问资源,而不仅仅是标识资源。RFC 3986是当前定义URI(包括URL)语法的国际标准,它详细规定了URL的各个组成部分和解析规则。
URL的设计哲学体现了Web的开放性和扩展性。URL不仅仅是一个地址,它还是一个抽象的资源标识符,可以指向任何类型的资源,无论是静态文件、动态内容、API端点还是其他类型的资源。这种设计使得Web可以支持各种不同的应用场景,从简单的静态网站到复杂的Web应用,都可以使用相同的URL机制来标识和访问资源。
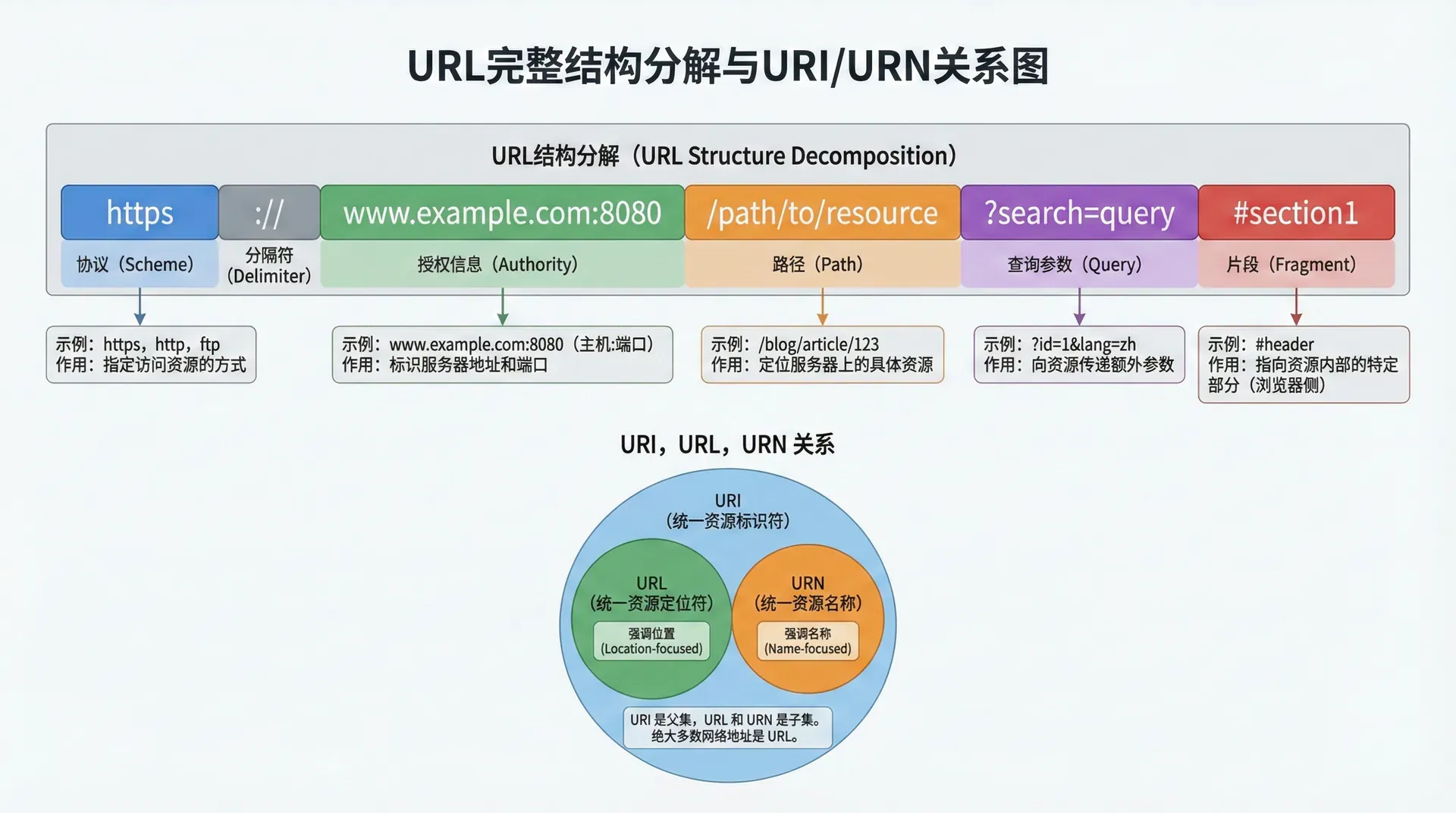
URL结构
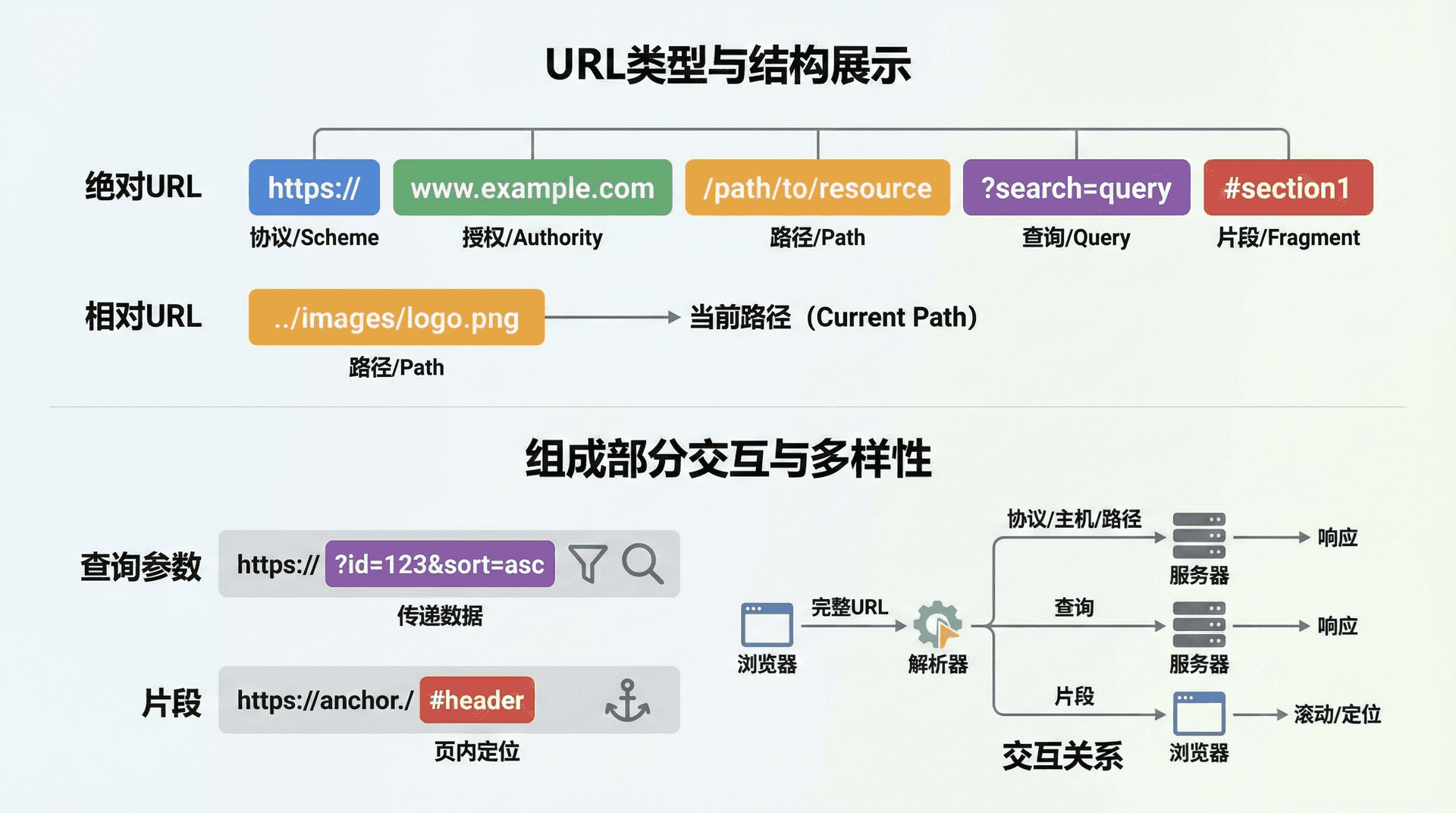
URL的结构看似简单,实际上包含了多个层次的信息。一个完整的URL可以被分解为几个主要部分:方案(Scheme)、授权部分(Authority)、路径(Path)、查询字符串(Query)和片段(Fragment)。
方案部分的设计与扩展
方案部分指定了访问资源所使用的协议。最常见的方案是http和https,分别表示使用HTTP协议和安全的HTTP协议(即HTTPS)。除此之外,还有ftp(文件传输协议)、file(本地文件系统)、mailto(电子邮件)、data(数据URI)等多种方案。方案部分不仅指定了协议类型,还隐含地指定了默认端口号。例如,http方案的默认端口是80,https方案的默认端口是443。这种设计使得URL更加简洁,因为大多数情况下我们不需要显式指定端口号。
URL方案部分的设计体现了Web协议的扩展性。虽然HTTP和HTTPS是最常用的方案,但Web标准还定义了其他多种方案,如ftp、file、mailto、data等。这种设计使得URL可以用于各种不同的场景,不仅仅是Web浏览。理解不同方案的特点和用途,对于构建功能丰富的Web应用非常重要。
常见URL方案的特点
不同的URL方案具有不同的特点和用途。HTTP和HTTPS方案用于访问Web资源,它们是最常用的方案。FTP方案用于文件传输,虽然现在使用较少,但在某些场景中仍然有用。File方案用于访问本地文件系统,主要用于开发和测试场景。Mailto方案用于创建电子邮件链接,当用户点击时会打开邮件客户端。Data方案允许将数据直接嵌入URL中,这对于小图片、内联样式等场景很有用。理解这些不同方案的特点,可以帮助我们选择最合适的方案来满足特定的需求。
自定义方案的可能性
虽然标准定义了许多URL方案,但应用程序也可以定义自己的自定义方案。自定义方案通常以应用程序的名称开头,如myapp://。自定义方案在移动应用开发中特别常见,用于实现深度链接(Deep Linking)功能。然而,自定义方案的使用需要谨慎,因为它们可能不被所有系统支持,也可能带来安全风险。在使用自定义方案时,应该确保它们不会与标准方案冲突,并且有适当的错误处理机制。
授权部分的复杂性
授权部分包含了访问资源所需的主机信息。在HTTP和HTTPS方案中,授权部分通常包括主机名(Hostname)和可选的端口号(Port)。主机名可以是域名(如www.example.com)或IP地址(如192.168.1.1)。域名需要通过DNS解析转换为IP地址,这个过程虽然对用户透明,但在性能优化和故障诊断中非常重要。端口号指定了服务器上监听请求的端口,如果省略,则使用方案的默认端口。
主机名的解析机制
主机名的解析是URL处理中的一个重要步骤。域名需要通过DNS解析转换为IP地址,这个过程可能涉及多个DNS服务器的查询。DNS解析的性能直接影响URL访问的速度,特别是在高延迟的网络环境中。现代浏览器和操作系统通常会缓存DNS查询结果,以减少重复查询的开销。DNS缓存的有效期由DNS记录的TTL(Time To Live)值决定,通常为几分钟到几小时。理解DNS解析的机制,对于优化Web应用的性能非常重要。
用户信息的安全考虑
授权部分还可以包含用户信息(User Information),格式为"用户名:密码@主机名"。这种格式在FTP协议中比较常见,但在HTTP协议中已经不再推荐使用,因为密码会以明文形式出现在URL中,存在安全风险。现代Web应用通常使用其他认证机制,如HTTP基本认证、OAuth、JWT等,这些机制不会在URL中暴露敏感信息。
在URL中包含用户信息(如用户名和密码)是一个严重的安全风险。密码会以明文形式出现在URL中,可能被记录在浏览器历史、服务器日志、引用页面等地方。攻击者可能通过分析这些信息来获取用户的凭证。因此,应该避免在URL中包含敏感信息,而是使用更安全的认证机制,如OAuth、JWT等。
路径部分的语义设计
路径部分指定了资源在服务器上的位置。路径由一系列由斜杠(/)分隔的段(Segment)组成,类似于文件系统中的路径。路径的第一段通常表示应用程序的根目录或上下文路径,后续的段表示资源的层级结构。例如,在URL "https://www.example.com/products/electronics/phones" 中,路径 "/products/electronics/phones" 表示资源位于products目录下的electronics子目录中的phones资源。
RESTful架构中的路径设计
路径的设计反映了RESTful架构的原则。在RESTful API中,路径通常用来表示资源的层级关系,而HTTP方法(GET、POST、PUT、DELETE等)用来表示对资源的操作。这种设计使得URL具有自描述性,开发者可以通过URL直观地理解资源的结构和关系。例如,URL "/users/123/posts/456" 表示用户123的帖子456,这种层级结构使得API更加直观和易于理解。
RESTful架构中的路径设计应该遵循资源导向的原则,路径应该表示资源而不是操作。例如,应该使用 "/users/123" 而不是 "/getUser?id=123",应该使用 "/users/123/posts" 而不是 "/getUserPosts?userId=123"。这种设计使得URL更加语义化,也使得API更加易于理解和维护。
路径段的编码要求
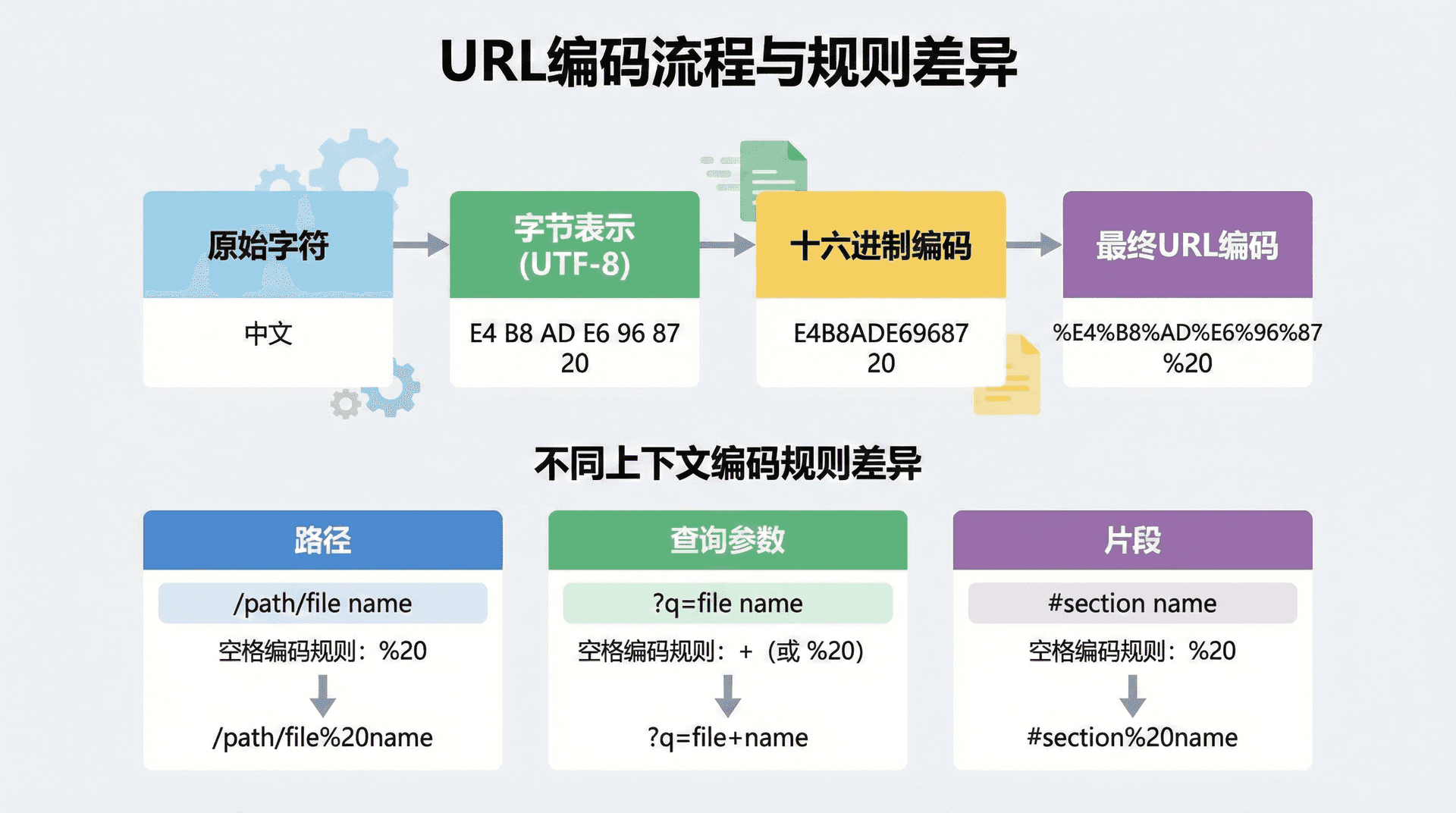
路径段中的特殊字符需要进行URL编码,以确保它们不会与路径分隔符冲突。例如,如果路径段中包含空格,应该编码为%20。如果路径段中包含中文字符,应该使用UTF-8编码后再进行URL编码。路径段的编码需要仔细处理,因为错误的编码可能导致资源无法访问。现代编程语言通常提供了URL编码和解码的函数,但在使用时需要注意编码的上下文,确保在正确的位置进行编码。
查询字符串的参数传递
查询字符串部分以问号(?)开头,包含一系列键值对,用于向服务器传递额外的参数。查询字符串的格式为“键=值”,多个键值对之间用&符号分隔。例如,在URL https://www.example.com/search?q=keyword&page=1 中,查询字符串包含两个参数:q(值为keyword)和page(值为1)。查询字符串中的特殊字符需要进行URL编码(Percent Encoding),以确保它们不会与URL的其他部分冲突。
查询字符串的安全限制
查询字符串的使用需要谨慎,因为它们在浏览器历史记录、服务器日志、引用页面等地方都会出现,可能会暴露敏感信息。对于包含敏感数据的请求,应该使用POST方法将数据放在请求体中,而不是放在查询字符串中。此外,查询字符串的长度也有限制,虽然HTTP协议没有明确规定,但大多数浏览器和服务器都有实际限制(通常为2048字符左右)。
查询字符串中的参数会出现在浏览器历史、服务器日志、引用页面等多个地方,这可能导致敏感信息泄露。因此,不应该在查询字符串中包含密码、API密钥、会话令牌等敏感信息。对于包含敏感数据的请求,应该使用POST方法将数据放在请求体中,并使用HTTPS来加密传输。
查询字符串的编码规则
查询字符串中的特殊字符需要进行URL编码,但编码规则与路径段略有不同。在查询字符串中,空格通常编码为+或%20,加号(+)需要编码为%2B,等号(=)和&符号需要编码为%3D和%26。不同的编程语言和框架可能有不同的编码规则,在使用时需要注意这些差异。现代Web框架通常会自动处理查询字符串的编码和解码,但在某些场景中,可能需要手动处理编码。
片段部分的客户端特性
片段部分以井号(#)开头,用于标识资源内部的特定位置。片段不会发送给服务器,它只在客户端使用,通常用于在HTML文档中定位到特定的锚点(Anchor)。例如,在URL https://www.example.com/page#section1 中,片段“section1”告诉浏览器在加载页面后滚动到id为"section1"的元素。在现代单页应用(SPA)中,片段也被用于客户端路由,实现无需页面刷新的导航。
片段在单页应用中的应用
在现代单页应用中,片段被广泛用于实现客户端路由。单页应用使用JavaScript来动态更新页面内容,而不需要重新加载整个页面。片段路由(Hash Routing)是一种常见的实现方式,它使用URL的片段部分来标识不同的页面状态。例如,URL https://app.example.com/#/users/123 中的片段 "/users/123" 被JavaScript解析,用于显示用户123的详细信息。这种方式的优点是兼容性好,不需要服务器端的特殊配置,但缺点是URL不够美观,也不利于SEO。
HTML5 History API的替代方案
HTML5 History API提供了另一种实现客户端路由的方式,它使用pushState和replaceState方法来修改URL的路径部分,而不需要重新加载页面。这种方式使得URL更加美观,也利于SEO,但需要服务器端的支持,因为服务器需要能够处理所有的路径请求。现代单页应用框架如React Router、Vue Router等都支持这两种路由方式,开发者可以根据具体需求选择合适的方式。
URL各部分之间的交互
URL的各个部分之间有着复杂的交互关系。例如,路径和查询字符串的组合可以表示复杂的资源定位和参数传递需求。授权部分和路径的组合可以表示跨域资源的访问。方案和授权部分的组合可以表示不同协议和不同服务器上的资源。
URL 语法规则
URL的语法规则由RFC 3986详细规定,这些规则确保了URL在全球范围内的唯一性和可解析性。
字符集和编码规则
URL的字符集基于ASCII字符集,但并不是所有ASCII字符都可以直接使用。RFC 3986将字符分为几类:未保留字符(Unreserved Characters)、保留字符(Reserved Characters)和需要编码的字符。未保留字符包括大小写字母、数字以及一些特殊字符(-、.、_、~),这些字符可以直接在URL中使用。保留字符包括一些在URL中有特殊意义的字符,如:、/、?、#、[、]、@等,这些字符只有在用于其特殊目的时才能直接使用,否则需要进行编码。
URL编码的机制
URL编码(Percent Encoding)是处理特殊字符的机制。URL编码将特殊字符转换为百分号(%)后跟两个十六进制数字的形式。例如,空格字符编码为%20,中文字符"你"在UTF-8编码下会编码为%E4%BD%A0。URL编码确保了URL可以安全地传输任何字符,但同时也使得URL的可读性降低。在实际开发中,我们需要在URL构建时进行编码,在URL解析时进行解码。
URL编码是Web开发中的一个基础概念,它确保了URL可以安全地传输任何字符,包括非ASCII字符。理解URL编码的机制对于正确处理用户输入、构建API端点、实现URL重写等功能非常重要。现代编程语言通常提供了URL编码和解码的函数,但在使用时需要注意编码的上下文,确保在正确的位置进行编码。
编码上下文的重要性
URL编码的规则在不同的上下文中可能略有不同。在路径段中,某些字符的编码规则可能与查询字符串中的编码规则不同。例如,在路径段中,空格通常编码为%20,而在查询字符串中,空格可以编码为+或%20。这种差异可能导致解析问题,特别是在手动构建URL时。因此,应该使用编程语言提供的URL编码函数,而不是手动进行编码,这样可以确保编码的正确性。
URL解析的复杂性
URL的解析是一个看似简单但实际上相当复杂的过程。解析器需要能够处理各种边界情况,如缺失的部分、格式错误的字符、编码错误等。解析器还需要能够区分绝对URL和相对URL,因为它们的解析规则不同。现代编程语言通常提供了URL解析库,但理解解析的原理对于正确使用这些库和诊断问题仍然很重要。
解析器的健壮性要求
URL解析器需要具有足够的健壮性,能够处理各种边界情况和错误情况。例如,解析器应该能够处理格式错误的URL,至少不能因为格式错误而导致系统崩溃。解析器还应该能够处理各种编码错误,如无效的百分号编码、不完整的UTF-8序列等。这些健壮性要求使得URL解析器的实现变得复杂,需要大量的测试和错误处理代码。
相对URL解析的特殊性
相对URL的解析比绝对URL的解析更加复杂,因为它需要基于基础URL进行解析。解析器需要正确识别相对URL的类型(网络路径相对、绝对路径相对、相对路径),然后根据基础URL的各个部分来构建最终的绝对URL。这个过程涉及多个步骤,包括路径段的合并、特殊路径段的处理(.和..)、查询字符串和片段的处理等。理解这些步骤对于正确实现URL解析器非常重要。
URL长度限制的考虑
URL的长度限制是另一个需要考虑的问题。虽然HTTP协议没有明确规定URL的最大长度,但实际中存在各种限制。浏览器的地址栏通常有长度限制(通常为2000字符左右),服务器也可能有URL长度限制。过长的URL不仅难以处理,还可能暴露在日志、错误消息等地方,带来安全风险。对于需要传递大量数据的场景,应该使用POST方法将数据放在请求体中,而不是放在URL中。
不同系统的长度限制
不同的系统和组件对URL长度有不同的限制。浏览器的地址栏通常限制在2000字符左右,但实际限制可能因浏览器而异。Web服务器如Apache和Nginx也有URL长度限制,通常可以通过配置调整。代理服务器和负载均衡器也可能有URL长度限制。这些限制可能导致长URL无法正常访问,因此在设计API和构建URL时,应该考虑这些限制。
长URL的替代方案
对于需要传递大量数据的场景,应该使用POST方法将数据放在请求体中,而不是放在URL中。POST请求的请求体大小限制通常比URL长度限制大得多,可以传递更多的数据。此外,POST请求的数据不会出现在URL中,也不会被记录在浏览器历史中,这提供了更好的安全性。对于文件上传等场景,应该使用multipart/form-data编码,而不是将文件内容编码到URL中。
URL规范化的必要性
URL的规范化(Normalization)是一个重要的处理步骤。URL规范化包括多个方面:将主机名转换为小写(因为域名不区分大小写)、移除默认端口号、移除多余的斜杠、解码不必要的编码字符等。规范化确保了相同的资源总是有相同的URL表示,这对于缓存、链接去重、SEO等场景都很重要。然而,规范化也需要谨慎,因为某些情况下,看似相同的URL实际上指向不同的资源(例如,某些服务器可能区分URL中的大小写)。
URL规范化是Web开发中的一个重要实践,它确保了相同的资源总是有相同的URL表示。这对于缓存、链接去重、SEO等场景非常重要。然而,规范化需要谨慎进行,因为某些服务器可能区分URL中的大小写,过度规范化可能导致资源无法访问。在实现URL规范化时,应该参考RFC 3986的规范,确保规范化的正确性。
规范化的具体步骤
URL规范化的具体步骤包括多个方面。首先,将方案部分转换为小写,因为URL方案是不区分大小写的。其次,将主机名转换为小写,因为域名也是不区分大小写的。第三,移除默认端口号,因为默认端口号是冗余的。第四,移除路径中的多余斜杠,但保留根路径的斜杠。第五,解码不必要的编码字符,但保留必要的编码字符。这些步骤的组合可以确保URL的规范化,但需要注意某些特殊情况。
URL安全性的重要考虑
URL的安全性是一个不容忽视的问题。URL可能包含敏感信息,如用户ID、会话令牌、API密钥等。这些信息如果出现在URL中,可能会在浏览器历史记录、服务器日志、引用页面等地方暴露。攻击者可能通过分析URL来获取敏感信息,或者通过修改URL来尝试未授权的访问。因此,敏感信息应该放在请求头或请求体中,而不是URL中。对于已经包含敏感信息的URL,应该使用HTTPS来加密传输,防止中间人攻击。
敏感信息的保护策略
保护URL中的敏感信息需要多层次的策略。首先,应该避免在URL中包含敏感信息,如密码、API密钥、会话令牌等。如果必须使用URL传递标识符,应该使用不可预测的随机标识符,而不是可预测的序列号。其次,应该使用HTTPS来加密URL传输,防止中间人攻击。第三,应该定期清理服务器日志,避免敏感信息长期保存。第四,应该使用安全的会话管理机制,如HttpOnly Cookie、Secure Cookie等。
URL注入攻击的防护
URL注入攻击是一种常见的安全威胁,攻击者通过在URL中注入恶意代码来攻击应用程序。常见的URL注入攻击包括SQL注入、XSS攻击、路径遍历攻击等。防护URL注入攻击需要多层次的防护策略,包括输入验证、输出编码、参数化查询等。输入验证应该检查URL的格式和内容,拒绝不符合规范的URL。输出编码应该确保URL中的特殊字符被正确编码,防止被解释为控制字符。参数化查询应该使用预编译的SQL语句,防止SQL注入攻击。
相对URL
相对URL是URL系统中的一个重要特性,它允许我们使用相对于当前文档位置的URL,而不需要指定完整的绝对URL。相对URL的使用使得文档集合可以更容易地移动和部署,因为它们不依赖于特定的服务器地址或协议。
相对URL的基本概念
相对URL的概念源于文件系统的相对路径概念。在文件系统中,我们可以使用"./file.txt"来表示当前目录下的文件,使用"../parent/file.txt"来表示父目录下的文件。相对URL采用了类似的概念,但需要考虑更多的因素,如协议、主机名、端口号、路径等。相对URL的解析基于一个基础URL(Base URL),基础URL通常是当前文档的URL,或者由HTML文档中的 <base> 标签指定。
基础URL的确定
基础URL的确定是相对URL解析的第一步,也是最关键的一步。在HTML文档中,基础URL通常是当前文档的URL,即浏览器地址栏中显示的URL。但是,HTML文档中的 <base> 标签可以覆盖这个默认值,指定一个不同的基础URL。这个特性在某些场景中很有用,比如当HTML文档是通过其他方式(如data URI)加载时,可以使用 <base> 标签指定正确的基础URL。理解基础URL的确定规则对于正确使用相对URL非常重要。
相对URL的类型
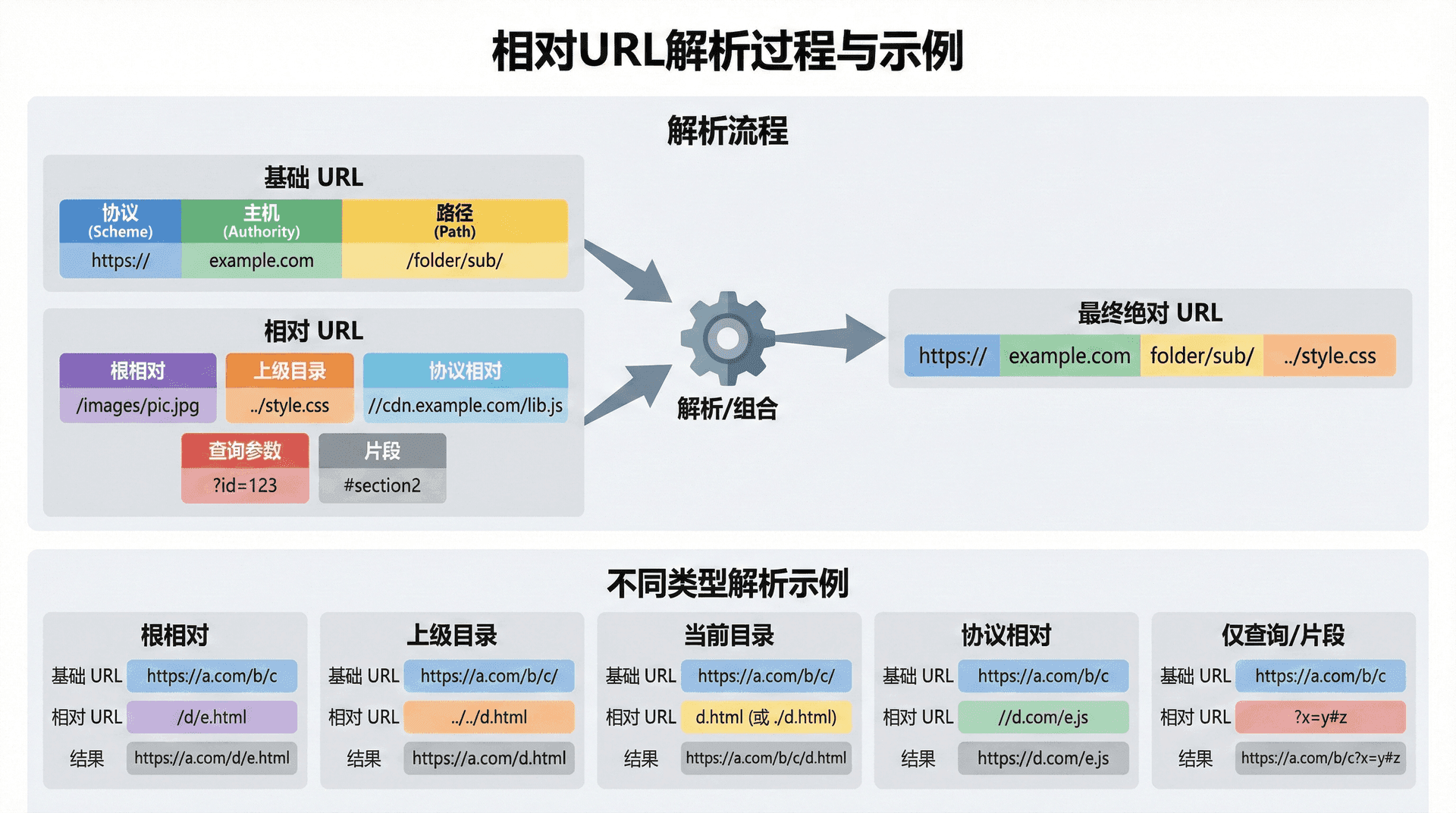
相对URL可以根据其格式分为几种类型。网络路径相对URL以"//"开头,只包含主机名和后续部分,继承基础URL的方案。绝对路径相对URL以"/"开头,只包含路径部分,继承基础URL的方案和授权部分。相对路径URL不以"/"开头,相对于基础URL的路径进行解析。理解这些不同类型的相对URL,对于正确构建和解析URL非常重要。
相对URL的解析规则
相对URL的解析规则由RFC 3986详细规定。解析过程包括几个步骤:首先确定基础URL,然后根据相对URL的类型(网络路径相对、绝对路径相对、相对路径)进行不同的处理。网络路径相对URL以"//"开头,只包含主机名和后续部分,继承基础URL的方案。绝对路径相对URL以"/"开头,只包含路径部分,继承基础URL的方案和授权部分。相对路径URL不以"/"开头,相对于基础URL的路径进行解析。
特殊路径段的处理
相对URL中的特殊路径段"."和".."具有特殊含义。"."表示当前目录,在路径解析时通常被忽略或移除。".."表示父目录,在路径解析时会移除路径中的最后一个段。这些特殊段使得相对URL可以表示复杂的路径关系,但同时也增加了解析的复杂性。解析器需要正确处理这些特殊段,确保解析结果的正确性。例如,路径 "/a/b/../c" 应该解析为 "/a/c",而不是 "/a/b/c"。
路径段的合并规则
路径段的合并是相对URL解析中的一个重要步骤。当相对URL的路径不以"/"开头时,它需要与基础URL的路径进行合并。合并规则包括移除基础URL路径的最后一个段(如果它不是以"/"结尾),然后附加相对URL的路径。如果相对URL的路径以"/"开头,它直接替换基础URL的路径。理解这些合并规则对于正确实现URL解析器非常重要。
相对URL的优势与挑战
相对URL的使用带来了许多好处。首先,它使得文档集合可以更容易地移动。如果所有链接都使用相对URL,那么整个文档树可以移动到不同的服务器或目录,而不需要修改链接。其次,相对URL使得文档可以在不同的协议下工作。例如,同一个文档可以在HTTP和HTTPS下工作,也可以在本地文件系统(file://)下工作。最后,相对URL使得URL更加简洁和可读,特别是在同一站点内的链接中。
相对URL的维护优势
相对URL的一个主要优势是它们使得网站更容易维护。当网站需要移动到新的域名或目录时,如果所有链接都使用相对URL,只需要修改基础URL(如通过<base>标签),而不需要修改每个链接。这种特性对于大型网站特别有用,因为可以大大减少维护工作量。此外,相对URL还使得网站可以在不同的环境中(如开发、测试、生产)使用相同的代码,只需要修改基础URL即可。
相对URL的使用可以大大简化网站的维护工作。当网站需要移动或重构时,如果所有链接都使用相对URL,只需要修改基础URL即可,而不需要修改每个链接。这种特性对于大型网站特别有用,可以大大减少维护工作量。此外,相对URL还使得网站可以在不同的环境中使用相同的代码,提高了代码的可移植性。
相对URL的解析挑战
然而,相对URL的使用也带来了一些挑战。相对URL的解析依赖于基础URL,如果基础URL不正确或缺失,解析结果就会错误。在某些场景中,如电子邮件、RSS订阅、API响应等,基础URL可能不明确,这时应该使用绝对URL。此外,相对URL的解析规则虽然由标准规定,但不同的实现可能有细微的差异,这可能导致兼容性问题。
现代Web开发中的相对URL
在现代Web开发中,相对URL的使用场景有所变化。在传统的多页应用中,相对URL是常见的选择,因为它们使得站点更容易维护。在单页应用(SPA)中,客户端路由通常使用相对路径,但基础URL的概念仍然重要。在API开发中,通常使用绝对URL,因为API端点需要明确的标识。
单页应用中的相对URL
在单页应用中,相对URL主要用于客户端路由。单页应用使用JavaScript来动态更新页面内容,URL的路径部分用于标识不同的页面状态。相对URL的使用使得路由更加灵活,可以适应不同的部署环境。例如,如果应用部署在子目录中(如 /app/),相对URL可以自动适应这个子目录,而不需要修改路由配置。这种特性使得单页应用可以在不同的环境中使用相同的代码。
API开发中的绝对URL
在API开发中,通常使用绝对URL,因为API端点需要明确的标识。API客户端需要知道完整的URL才能发送请求,相对URL在这种情况下没有意义。此外,API端点通常需要跨域访问,相对URL无法表示跨域的URL。因此,API开发中应该使用绝对URL,并在API文档中明确说明每个端点的完整URL。
URL 快捷方式
URL快捷方式(Shortcuts)是URL系统中的一些特殊形式和约定,它们提供了更简洁或更方便的方式来指定URL。这些快捷方式包括协议相对URL、数据URI、javascript:协议、mailto:协议等。
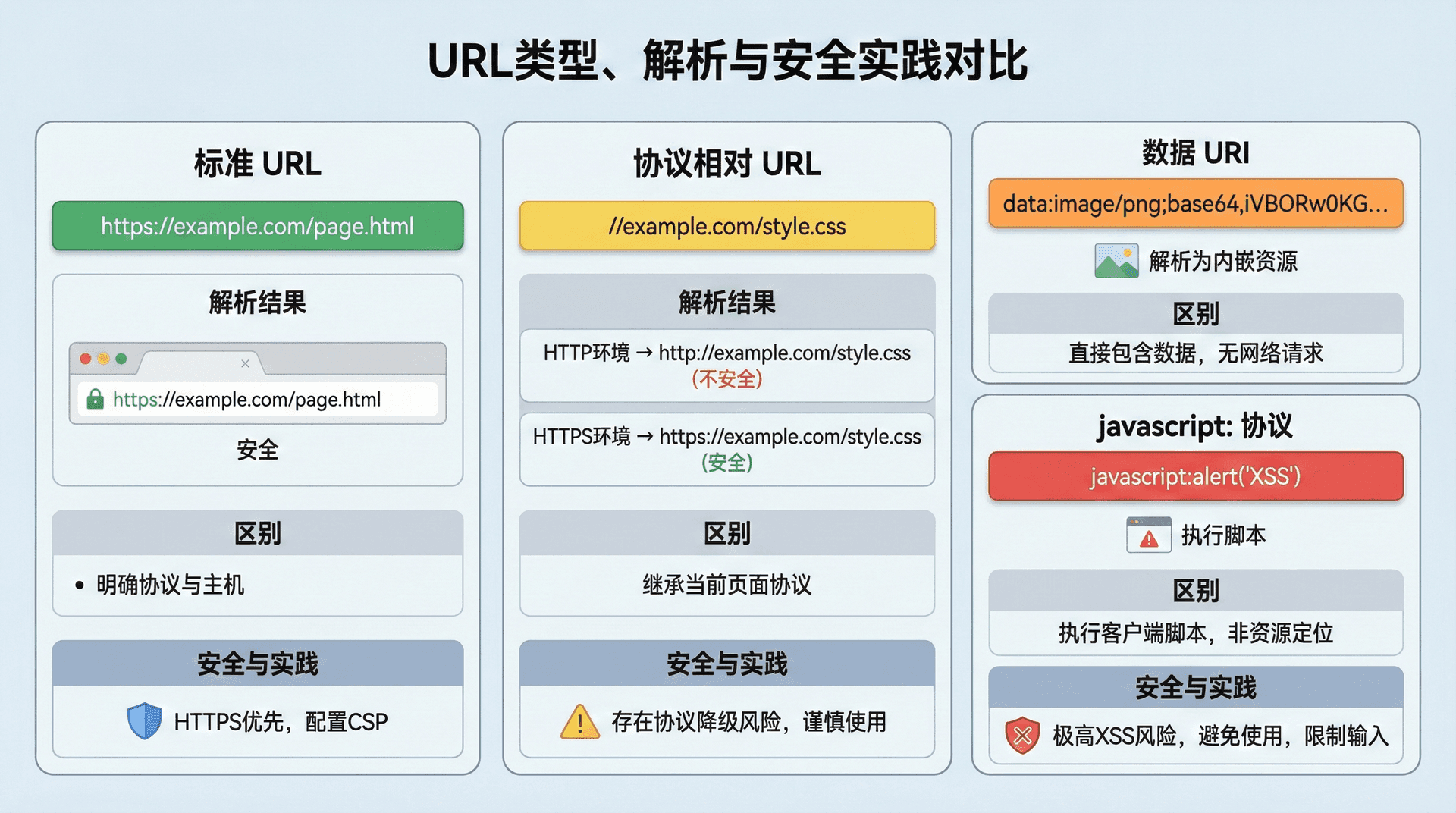
协议相对URL的现代应用
协议相对URL(Protocol-Relative URL)是一种特殊的相对URL,它以"//"开头,只包含主机名和后续部分。协议相对URL会继承当前文档的协议(http或https),这使得同一个URL可以在HTTP和HTTPS环境下工作。例如,URL "//cdn.example.com/style.css" 在HTTP页面中会解析为 "http://cdn.example.com/style.css",在HTTPS页面中会解析为 "https://cdn.example.com/style.css"。这种特性在混合内容(Mixed Content)的场景中很有用,但需要注意的是,现代浏览器对混合内容有严格的安全限制。
协议相对URL的安全考虑
虽然协议相对URL在某些场景中很有用,但它们也带来了一些安全风险。当页面从HTTP升级到HTTPS时,协议相对URL仍然会使用HTTP协议,这可能导致混合内容问题。现代浏览器会阻止HTTP资源在HTTPS页面中加载,这可能导致资源无法加载。因此,现代Web开发中应该避免使用协议相对URL,而是明确指定协议(https://),确保资源始终通过安全连接加载。
协议相对URL在现代Web开发中应该避免使用,因为它们可能导致混合内容问题。当页面从HTTP升级到HTTPS时,协议相对URL仍然会使用HTTP协议,现代浏览器会阻止这些资源加载。因此,应该明确指定协议(https://),确保资源始终通过安全连接加载。
数据URI的实用场景
数据URI(Data URI)是一种特殊的URL方案,它允许将数据直接嵌入URL中,而不需要外部资源。数据URI的格式为 "data:[mediatype][;base64],data",其中mediatype指定数据的MIME类型,base64是可选的编码方式,data是实际的数据内容。数据URI常用于嵌入小图片、图标、内联样式等,可以减少HTTP请求的数量,提高页面加载速度。然而,数据URI也有一些限制,如长度限制、缓存困难、可维护性差等。
数据URI的性能权衡
数据URI的使用需要在性能和可维护性之间进行权衡。数据URI可以减少HTTP请求的数量,这对于小资源特别有用,可以显著提高页面加载速度。然而,数据URI也有一些缺点。首先,数据URI会增加HTML文档的大小,可能影响首次加载时间。其次,数据URI无法被浏览器缓存,每次页面加载都需要重新下载数据。第三,数据URI使得资源难以维护,因为资源内容直接嵌入在HTML中。因此,数据URI应该只用于非常小的资源,如小图标、内联样式等。
Base64编码的影响
数据URI通常使用Base64编码来编码二进制数据,如图片。Base64编码会将数据大小增加约33%,这可能会影响页面大小。对于较大的资源,使用数据URI可能不如使用外部资源文件,因为外部资源可以被浏览器缓存,也可以被CDN加速。因此,在使用数据URI时,应该考虑资源的大小和缓存需求,选择最合适的方案。
JavaScript协议的安全风险
javascript:协议是一种特殊的URL方案,它允许在URL中嵌入JavaScript代码。当用户点击javascript:协议的链接时,浏览器会执行URL中的JavaScript代码,而不是导航到新页面。javascript:协议在某些场景中很有用,如书签工具、动态内容生成等,但它也带来了严重的安全风险。恶意网站可能使用javascript:协议来执行恶意代码,窃取用户信息或进行其他攻击。现代Web开发中,应该避免使用javascript:协议,而是使用事件处理器或其他更安全的方式。
javascript:协议是一个严重的安全风险,应该避免使用。恶意网站可能使用javascript:协议来执行恶意代码,窃取用户信息或进行其他攻击。现代Web开发中,应该使用事件处理器(如onclick)或其他更安全的方式来实现相同的功能。如果必须使用javascript:协议,应该确保代码来源可信,并实施适当的安全措施。
现代替代方案
现代Web开发提供了许多替代javascript:协议的方案。对于链接点击事件,应该使用HTML的onclick属性或JavaScript的事件监听器。对于动态内容生成,应该使用JavaScript的DOM操作API。对于书签工具,可以使用data:协议或其他更安全的方案。这些替代方案不仅更安全,也更符合现代Web开发的最佳实践。
Mailto协议的使用场景
mailto:协议用于创建电子邮件链接。当用户点击mailto:协议的链接时,系统会打开默认的邮件客户端,并预填充收件人、主题、正文等信息。mailto:协议的格式为 "mailto:address?subject=Subject&body=Body",其中address是收件人地址,subject和body是可选参数。mailto:协议虽然方便,但也可能被用于垃圾邮件和钓鱼攻击,因此需要谨慎使用。
Mailto协议的安全考虑
mailto:协议虽然方便,但也带来了一些安全风险。恶意网站可能使用mailto:协议来发送垃圾邮件或进行钓鱼攻击。为了防止这些问题,应该验证mailto:链接的内容,确保它们不包含恶意代码。此外,应该教育用户识别可疑的邮件链接,避免点击不信任的mailto:链接。在某些场景中,可以使用联系表单代替mailto:链接,提供更好的用户体验和安全性。
URL国际化的复杂性
URL的国际化(Internationalization)是另一个重要的考虑因素。传统的URL只能使用ASCII字符,这对于非英语内容来说是一个限制。为了解决这个问题,引入了国际化域名(IDN,Internationalized Domain Name)和国际化资源标识符(IRI,Internationalized Resource Identifier)。IDN允许域名使用非ASCII字符(如中文、阿拉伯文等),这些字符会被转换为Punycode编码形式。IRI扩展了URI的概念,允许使用Unicode字符,这些字符在传输时会被转换为UTF-8编码并进行URL编码。
国际化域名的安全挑战
URL的国际化虽然提高了可用性,但也带来了一些挑战。国际化域名可能看起来相似但实际上不同(这被称为同形字符攻击),攻击者可能使用这种特性进行钓鱼攻击。例如,攻击者可能使用看起来像拉丁字母的西里尔字母来创建虚假的域名,欺骗用户访问恶意网站。为了防止这些问题,浏览器通常会显示Punycode编码的域名,而不是Unicode域名,帮助用户识别潜在的钓鱼攻击。
国际化域名可能被用于同形字符攻击,攻击者使用看起来相似的字符来创建虚假的域名。为了防止这些问题,浏览器通常会显示Punycode编码的域名,而不是Unicode域名。在开发支持国际化域名的应用时,应该实施适当的安全措施,如域名验证、用户教育等。
IRI的处理机制
IRI(国际化资源标识符)扩展了URI的概念,允许使用Unicode字符。IRI在传输时需要转换为URI,这个过程包括将Unicode字符转换为UTF-8编码,然后进行URL编码。在接收时,URI需要转换回IRI,这个过程包括URL解码和UTF-8解码。理解IRI的处理机制对于正确支持国际化URL非常重要。
URL技术的未来发展
URL的未来发展也在不断演进。随着Web技术的不断发展,新的URL方案和特性不断出现。例如,WebSocket协议使用ws:和wss:方案,Service Worker使用特殊的URL格式,WebAssembly模块也有特殊的URL处理方式。
新兴URL方案的应用
新兴的URL方案为Web应用提供了新的可能性。WebSocket协议使用ws:和wss:方案来建立双向通信连接,这使得实时应用成为可能。Service Worker使用特殊的URL格式来注册和更新服务工作者,这使得离线应用成为可能。WebAssembly模块使用特殊的URL处理方式来加载和执行WebAssembly代码,这使得高性能Web应用成为可能。理解这些新兴URL方案的特点和用途,对于构建现代Web应用非常重要。
小结
URL看似简单,却是Web世界不可或缺的基石。无论是结构与语法、各种快捷方式的妙用,还是背后的安全考量,理解这些细节都能帮助我们在实际开发中避免许多“坑”。 URL的灵活性让Web更加开放和强大,但也对我们提出了更高的安全和规范要求。作为Web开发者,只有真正理解和善用URL各方面的知识,才能打造出安全、可靠又易于维护的Web应用。