非平稳数据分析
现代经济学中,大多数核心经济变量——如GDP、消费、价格水平、汇率、货币供应、进出口等——都表现出长期上升或下降的趋势。在中国,1978年以来,GDP和居民收入持续高速增长,CPI等物价和股票指数也长期呈现不可逆的趋势。这种非平稳性根植于诸如技术进步、人口变化、制度演化、资本积累等推动力,它们不断驱动经济变量远离短期均衡,让数据轨迹展现出“记忆效应”与路径依赖,没有固定均值方差。
事实上,非平稳数据是宏观与金融经济分析的常态而非特例。无论是利率、债券、国际商品价格,还是各类金融资产指数、财政收支,几乎都存在趋势或结构性变动。因为这些变量不满足传统平稳性假设,我们称之为“非平稳数据”或“集成过程”(integrated process),分析建模也需借助专门的方法。
值得注意的是,直接用传统回归分析非平稳变量很容易产生“虚假回归”(spurious regression):即使两个毫无实际关联的变量,只要各自具有趋势,也容易回归出高度显著的关系(高R²、回归系数显著),导致误判经济内在联系。例如,两个独立但带趋势的序列经过回归也常能得出“显著”结果,掩盖实证分析的逻辑陷阱。
因此,处理非平稳数据的分析不仅是计量经济学的技术难题,更是从根本上影响宏观经济理论、政策制定与金融实证的基础问题。准确识别和建模这些变量的非平稳特征,是获得有经济意义、能够指导实际决策的研究结论的前提条件。
单位根过程与积分概念
单位根过程是理解非平稳数据与经济变量长期趋势的核心基础。其主要特征在于:任何一次冲击都会对未来产生永久性影响,而非如平稳序列那样渐次消散。用数学术语表述,单位根过程是一类自回归系数绝对值为 1 的时间序列过程。这类过程在宏观和金融经济中屡见不鲜,中国的GDP、CPI和一线城市房价等核心指标均表现出显著的单位根和非平稳性特征。
随机游走过程的基本特征
以中国CPI月度数据为例,其演化可以抽象为带漂移的随机游走模型:
其中,是漂移项(反映长期趋势),为白噪声扰动。通过反复代入,可得到:
这一式揭示以下两大特征:
- 确定性趋势: 使得序列呈现持续性线性趋势(如中国30年CPI和GDP长期上涨)。
- 随机趋势: 累积所有历史冲击,反映“记忆效应”,其影响不能被均值回归所消解。
方差发散性
随机游走过程的方差递推关系为:
意味着方差随时间线性增长,样本越长,变量波动越大。China的房价、货币供应量等序列也常显示这一特性。这是经典的非平稳性征象。
积分阶数(I(d))的概念
积分过程定义
在计量经济学中,如果一个序列需要差分次之后才变为平稳序列,则称为阶积分过程,记为。例如,中国名义GDP的对数约为,说明其一阶差分(即增长率)为平稳序列。常见变量的积分阶数如下表:
ARIMA模型的含义
积分概念产生了著名的ARIMA(p,d,q)模型:
其中为次差分算子,为滞后算子。ARIMA已广泛应用于中国CPI、GDP等宏观变量的实证建模与预测。
中国CPI的自相关示例分析
我们以中国CPI(月度对数)为例,比较其不同差分阶数下的自相关函数:
图中可见,原序列自相关系数几乎恒为1,典型的非平稳过程特征;而经过一次、二次差分后,自相关系数明显下降,数据向平稳序列转换。
虚假回归的严重问题
非平稳数据直接回归极易产生“镜花水月”式的虚假回归。例如,若用中国M2与上证指数(两个单位根过程)做OLS回归,即使两者经济上毫无联系,结果仍可能出现高值与,看似显著。这是因为各自的趋势项导致回归残差序列也带趋势,统计推断失效。
Granger-Newbold及Phillips的发现
Granger和Newbold通过模拟研究发现,当传统临界值(如)用于检验这些变量时,虚假显著比例极高。他们建议统计量的临界值应提高到才能降低第一类错误。
Phillips在理论上严密证明了上述现象,并提出标准化统计量应为 ,其中为样本容量。例如,时,合适的临界值已接近15。这一发现对中国金融数据滥用回归也有重要警示意义。
三种基本的非平稳过程举例
理解不同非平稳类型对选择模型和实证推断极为关键。以中国数据类比说明:
-
纯随机游走
如90年代人民币汇率每日波动,具有随机性但无明显趋势。
-
带漂移的随机游走
中国主要经济变量的积分特征与政策含义
中国实际数据中,不同变量积分阶数如下:
如中国GDP为过程,则一次性的财政或货币宽松将永久提升产出水平,而非仅短期推动。这一发现也为经济治理与制度设计带来深刻启示。判断变量的积分阶数不仅事关统计推断,更影响政策含义和经济解释。误判积分阶数,易导致对政策长期效力的误解。
单位根检验方法

准确识别时间序列是否包含单位根(unit root)是非平稳数据分析中的关键第一步。如果对序列平稳性判断失误,后续的模型设定和推断将存在根本性缺陷。因此,研究者必需使用专门为单位根设计的统计检验方法。
Dickey-Fuller检验的理论基础
Dickey-Fuller(DF)检验的核心思想是判断自回归一阶过程(AR(1))的系数是否等于 ,即:
- 原假设():(序列存在单位根,非平稳)
- 备择假设():(序列平稳)
DF检验通过估计 并判断其是否显著小于 来决定序列平稳性。
标准推断的失效
在单位根假设下(),传统 检验已失效。Dickey和Fuller通过理论和数值模拟发现:
- 估计量的偏误: 在有限样本下存在向下偏差;
- 收敛速度异常: 的方差为 ,显著慢于通常的 ;
因此,不能直接借用常规回归的t检验和临界值。
特殊的临界值
单位根检验需要查表获取专门的临界值。下表比较了DF统计量与传统 分布的临界值:
可以看到,单位根检验的临界值绝对值通常比 分布更大,说明单位根显著性判断更为严格。拒绝 (认为序列平稳)需要更强的证据。
三种基本的DF检验形式
根据时间序列的特征,可以采用不同的DF检验形式:
形式1:无截距的纯随机游走
其中 ,检验 。适用于均值无漂移的序列。
形式2:带漂移的随机游走
包含常数项 ,适用于均值具有长期趋势的序列。
形式3:带趋势的平稳过程
包含时间趋势 ,用于区分确定性趋势与随机趋势。
选择哪种形式,应结合数据特性(如绘制序列图、理论预期等)判断。
增强Dickey-Fuller (ADF) 检验
ADF检验的必要性
标准DF检验假定误差项 为白噪声。但实际宏观数据中,误差常存在自相关、异方差等问题,导致一阶DF检验失效。ADF(Augmented Dickey-Fuller)检验通过引入滞后差分修正误差相关性:
其中 为滞后阶数,通过引入 控制高阶相关性,有效提升检验的适用性和可靠性。
滞后阶数的选择
的选取直接影响检验结果,常见方法有:
常见补充:ADF结果需结合残差的自相关检查,以防误判。
宏观变量的单位根检验实证
以中国1990–2020年主要宏观数据为例,单位根(ADF)检验核心结果如下:
经济学解释:
- 大部分核心变量具有单位根特性:中国实际GDP、CPI、M2和汇率原始序列均为非平稳过程,说明它们对外部冲击的影响具有持久性,不易恢复到均值水平。
- 利率相对平稳:SHIBOR等货币市场短期利率表现为平稳过程,更好地反映了货币市场的短期均衡机制。
- 经济含义:非平稳变量说明政策、外部冲击“记忆”悠久,增长性变量建模与预测需采用差分或协整技术,不能直接进行OLS回归,否则可能出现虚假回归。
Phillips-Perron (PP) 检验
PP检验是DF检验的扩展,同样适用于中国数据,允许更复杂的误差结构(如序列相关性和异方差)。主要优势包括:
- 误差项更一般:允许 存在各种自相关和异方差形态,常见于经济数据。
- 非参数修正:利用Newey-West等方法修正统计量,结果对误差结构更稳健。
- 宽松分布假设:避免对误差白噪声的严格要求,更适合实际经济序列。
PP检验的主统计量类似于修正的DF型:
其中为长期方差估计,为当期方差,和涉及误差项的方差结构。
KPSS检验
检验逻辑的反向设定
KPSS(Kwiatkowski–Phillips–Schmidt–Shin)检验与DF/ADF正好相反,原假设为:“序列平稳”,备择为:“单位根过程”:
- 原假设::序列平稳
- 备择假设::序列非平稳(单位根)
统计量公式:
其中 ,为回归残差,为残差的方差估计。
互补检验的常规用法
实务中,DF/ADF和KPSS双重结合可以有效判别单位根,具体判别框架如下:
单位根检验的推断结果直接关系到中国宏观数据建模路径。如果将变量误当成平稳,或反之,会导致经济判断和政策分析出现严重偏差。
中国宏观数据的单位根分析
应用于中国1990–2020年宏观数据,主要变量单位根检验如下:
一阶差分后的平稳性检验
这些数据再次验证:中国主要宏观变量在原始序列上基本都是过程,但一阶差分均为平稳过程,这为后续协整建模奠定基础。
结构变化对单位根检验的影响
结构断点的重要性
经济数据常常面临重大制度、政策或突发事件的结构变动。这些“断点”会导致序列表现为非线性趋势叠加,若单位根检验时忽视结构变化,则容易做出错误结论。例如:
- 中国1978年改革开放
- 1992年市场经济体制确立
- 2001年加入WTO
上述事件均可能影响宏观序列的时间趋势。
考虑结构变化的单位根检验(Perron方法)
Perron等人发展了考虑结构突变的单位根检验,一般模型如下:
其中:
- :趋势断点虚拟变量(通常在断点后递增)
- :水平断点虚拟变量(断点后取1,前为0)
如果检验模型考虑断点后,显著小于0,则表明变量环绕断点趋势平稳。“伪单位根”问题在中国宏观数据中常见(如改革开放影响GDP系列)。
结构变化型单位根检验有助于正确揭示变量的长期趋势本质,加强实证经济分析的解释力和严谨性。
协整理论与长期均衡关系
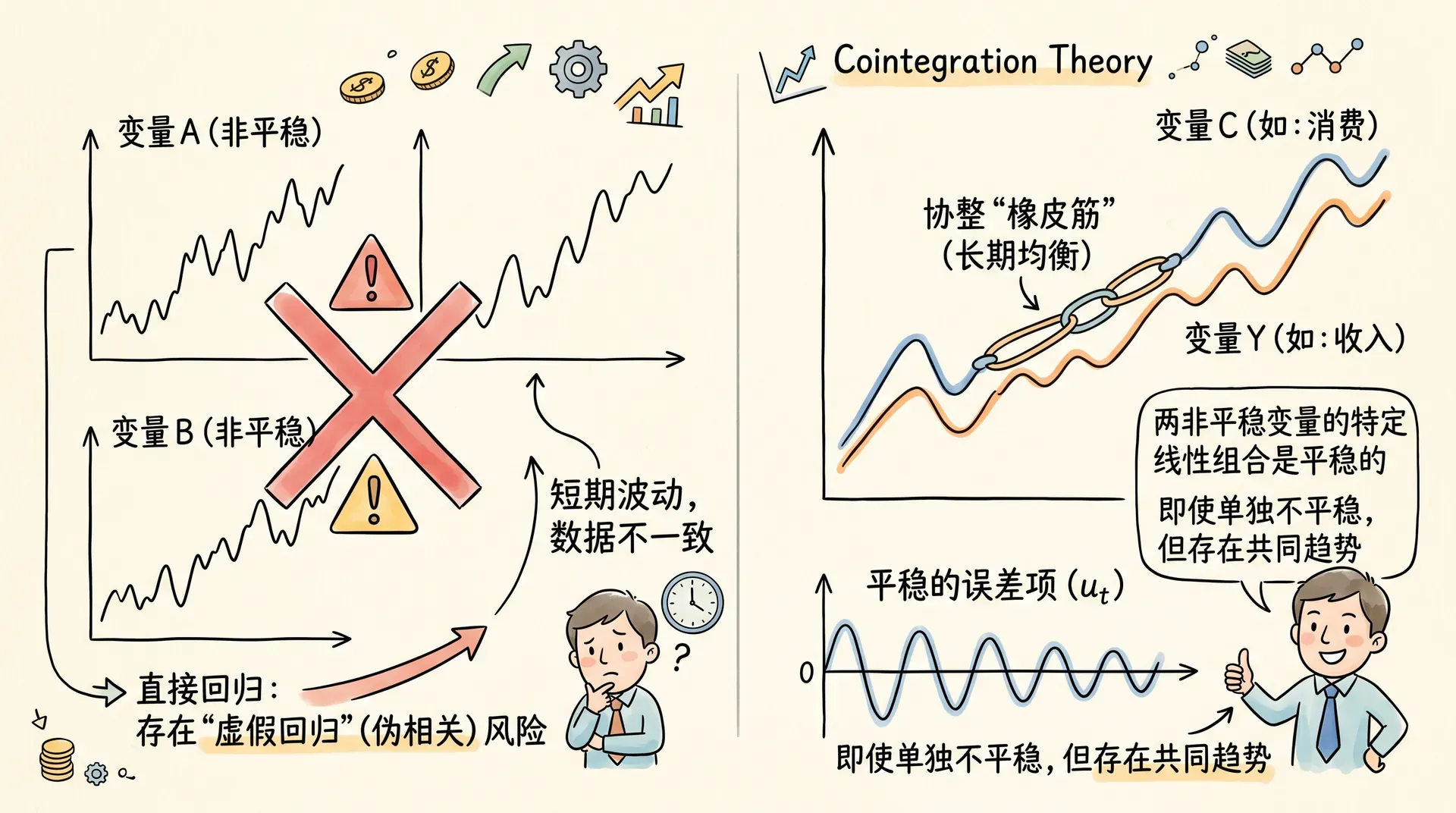
协整理论是处理非平稳时间序列数据的核心理论之一。它回答了一个重要问题:如何在非平稳变量之间寻找稳定且有意义的长期关系,并有效避免“虚假回归”的统计陷阱。协整分析已成为宏观经济学、金融学等领域的重要实证工具。
协整的基本概念
在宏观经济中,许多重要变量(如GDP、M2、CPI等)表面上呈现明显的随机趋势,即为非平稳。而实际经济理论往往假定这些变量存在某种长期均衡约束。例如,中国的实际GDP和社会消费品零售总额(消费)都随时间上升,但两者的比例长期来看较为稳定。如果两个或多个非平稳变量之间存在这种“同步变动”,并且它们的某种线性组合消除了趋势、变得平稳,则称这些变量协整。
假设与都是过程,如果存在常数,使得
即与的线性组合是平稳的,则称与协整,为协整向量。
协整关系刻画了经济变量之间的长期均衡机制。即使短期内因为冲击等因素发生偏离,长期来看变量会有“拉回”均衡的趋势,这一现象称为“均衡回归”或“误差修正”。
中国收入与消费的协整案例分析
以中国近年来城镇居民人均可支配收入()和社会消费品零售总额()为例,这两个变量都呈明显的上升趋势,被证实是过程。但二者间是否存在稳定的收入-消费长期关系?
协整检验过程示例
-
单位根检验
对和序列做ADF检验,均无法拒绝单位根假设,即序列为。
-
长期协整回归关系
用OLS估计如下关系:
图中可以明显看到,消费和收入的对数序列呈现长期高度同步的变动轨迹,两者不仅趋势方向一致,波动也高度协调。通过协整分析,实证结果进一步表明二者之间存在稳定且显著的长期均衡关系,说明收入的长期增长能够持续带动消费的上升,符合经典经济理论关于收入决定消费的预期。这为政策分析和消费预测提供了坚实的计量基础。
误差修正模型(ECM)
误差修正模型(ECM)把短期动态与长期均衡机制结合,有以下通用表达式:
其中,为的一阶差分,为滞后一期的长期均衡误差,为误差修正参数。
经济含义举例
当越大时,偏离均衡后的调整速度越快。当,说明系统没有误差修正过程。
Granger表示定理
Granger表示定理奠定了协整与误差修正模型(ECM)的对应关系。定理要点如下:
- 如果两个变量存在协整关系,则一定存在ECM表示。
- 反之,若一个系统存在有效的ECM形式表示,则说明原始变量协整。
向量自回归(VAR)模型在存在协整时可以重写为向量误差修正模型(VECM):
其中,矩阵内蕴含协整向量等长期信息,其秩等于独立协整关系个数。
多变量协整系统
在个变量的系统中,协整秩最多为,即最多可存在个独立的协整向量。例如,中国“三大需求”(消费、投资、出口)长期增长趋势虽有波动,但可以检验出一至两个协整向量。
当协整秩时,协整向量只在某种线性组合下被唯一确定,这时需要引入经济理论、结构假设等外生约束实现识别。否则定量结果可能缺乏独特性。
购买力平价的协整实证
以人民币兑美元汇率与中美价格水平为例,分析多变量协整:
其中为人民币对美元汇率,、分别为中国、美国价格指数。
实证检验
实际对、和构造如下协整回归关系:
当发现残差平稳时,视为三变量存在协整、购买力平价部分成立。
中国1994年汇改后长期数据通常支持“弱形式”购买力平价,即、基本接近1,但常有显著偏离。这说明现实中受到贸易壁垒、资本管制、外汇政策等多种因素影响。
协整分析的结论极为依赖样本期与数据特征。宏观制度突变(如人民币汇率形成机制改革、资本账户开放等)极易改变协整结构,因此分析时应区分不同政策阶段,并进行稳健性检验。
Johansen协整检验方法
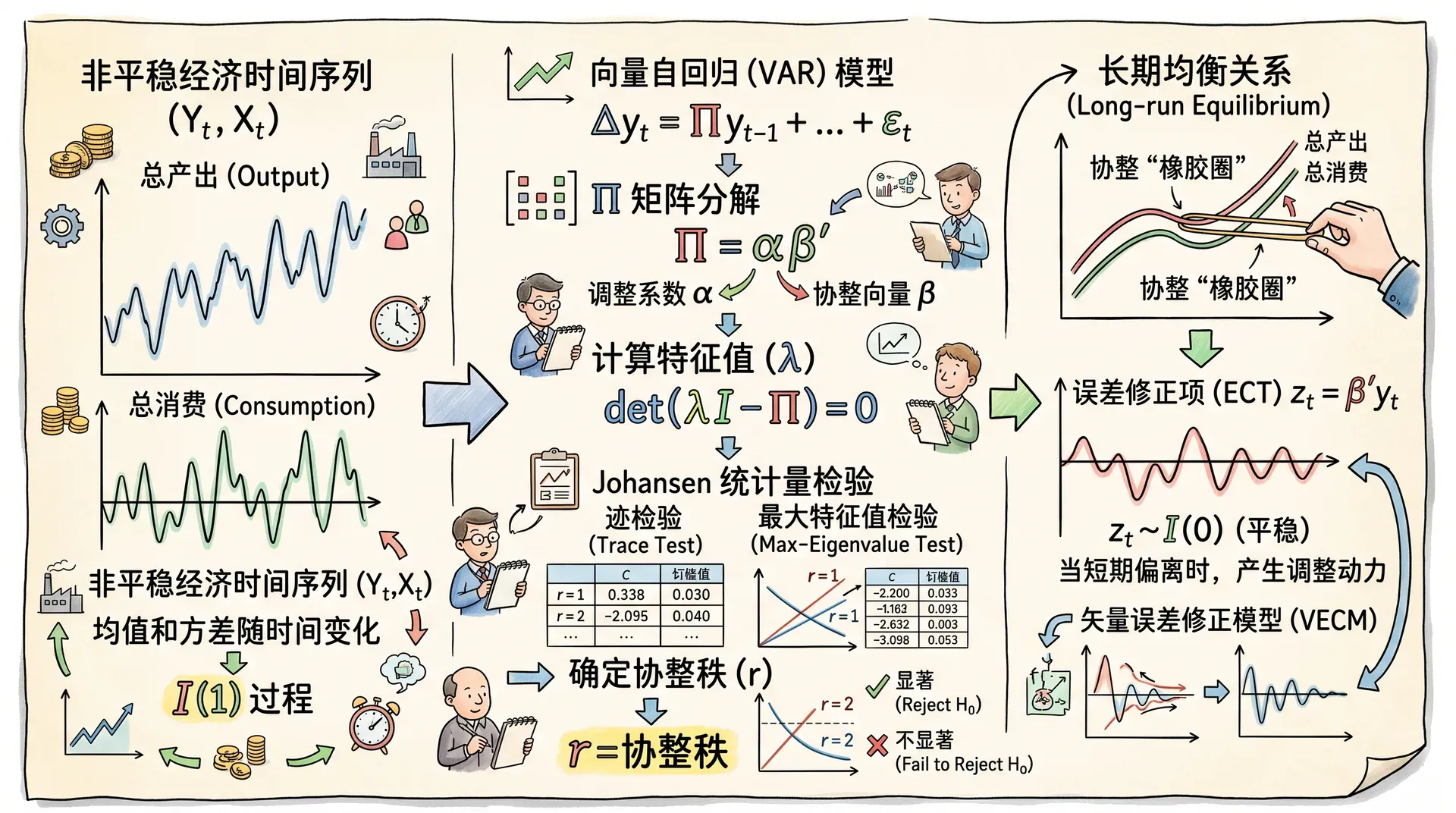
当系统包含多个变量时,需要使用更系统的方法来检验协整关系的存在和确定协整秩。Johansen方法是目前多变量协整检验中最为核心和广泛应用的方法之一,在宏观计量、金融建模等领域都具有重要应用价值。
Johansen方法的理论基础
向量自回归VAR模型的起点
Johansen方法基于向量自回归(VAR)模型。假设有个变量构成的系统,则VAR()模型可写为:
通过矩阵变换(差分化和重参数化),将其改写为向量误差修正模型(VECM):
其中,。
协整的矩阵分解与秩判别
Johansen方法的核心在于矩阵的秩(rank)分析:
- 如果,说明 所有变量均为,不存在协整问题。
- 如果,则系统无协整关系,每个变量均包含单位根随机趋势。
在有协整时,可分解为,其中为的协整向量矩阵,定义长期均衡关系;为调整系数矩阵,反映各变量偏离均衡后的回归速度。
协整秩的迹检验和最大特征值检验
迹检验 (Trace test)
用于检验原假设“协整向量个数”:
其中为样本容量,为样本特征根。
最大特征值检验 (Maximum Eigenvalue test)
检验原假设“协整秩为”对“协整秩为”:
实际操作中,常常结合两种检验结果共同判断协整关系数。
中国货币需求的协整实证分析
以中国货币需求为例,介绍Johansen方法在实际经济研究中的应用。
选择的变量包括:(实际广义货币余额,如M2/CPI)、(实际GDP或收入)、(短期利率,如一年期定存利率)、(长期利率,如10年期国债收益率)、(通胀率,常用CPI同比增速)。理论上的长期货币需求关系可表示为:
Johansen协整检验结果举例(假定面板)
结论:存在唯一协整关系()。
经Johansen方法估计得到的协整向量(系数标准化,假设样本):
实证结果显示实际货币需求随收入增加而增加,与通胀和利率(尤其是长期利率)负相关,基本符合货币需求理论。时间趋势项系数极小,说明有微弱的宏观环境长期趋势成分。
共同趋势与Stock-Watson分解
协整理论强调共同趋势。如果有个变量存在个协整关系,则系统可拆解为组平稳协整关系与个非平稳共同趋势:
中国经济中的共同趋势示例
这类分解不仅有助于理解中国宏观经济变量长期联动与同步上升背后的动力机制,还能揭示各变量“共同趋势”来源。例如,技术进步、人口城镇化、金融深化等深层次因素,会同时推动GDP、货币供应、房价等多个重要宏观指标长期上升。通过分离平稳协整关系与非平稳共同趋势,研究者能够更准确地区分短期波动与长期增长,从而为政策分析和结构性改革提供理论支持。
中国消费与收入的协整实证分析
改革开放以来,中国居民消费与收入快速增长。二者是否存在稳定的长期协整关系,对于检验消费平滑假说、设计收入分配与刺激消费的宏观政策具有重要意义。
以1980-2020年年度数据为例:
基于协整关系建立误差修正模型(ECM):
经济意义扩展说明
- 长期消费倾向:,表明在长期内消费随收入增加而增加,但弹性略低于1,符合“永久收入假说”与储蓄倾向的现实。
- 短期调整特征:系数低于长期弹性,说明消费增长对收入波动有一定缓冲与平滑效应。
- 误差修正项:为调整系数,表示偏离长期均衡时,消费变量会以每期18%的幅度回归均衡(半衰期约3.5年),说明长期均衡关系对短期动态具有重要约束。
协整向量识别的实际操作
当协整秩大于1,即存在多个协整关系时,我们只能借助统计推断获得线性空间。实际经济分析需要从中识别具体具有经济学意义的协整向量组合,这需要引入理论假设或额外参数限制。
识别方法举例扩展
货币需求系统多协整关系识别
如同一系统既含“货币需求关系”
又含“费雪关系”
理论限定可帮助区分和唯一化多个协整向量,为实证结果赋予经济含义。
协整分析的成功不仅取决于严密的统计方法,更需要坚实的经济理论指导。经济学解释与实证分析的结合,才保证协整分析具有生动且有用的结论。
协整检验的实际注意事项与扩展
样本量要求
协整或Johansen多变量检验法均需要较大样本量支持,以保证检验权力和结果稳定性。实际推荐:
- 单方程协整(如Engle-Granger回归)不少于30-50期观测
- Johansen检验不少于50-100期观测
- 高维系统:观测期数应为变量数的倍
结构突变什么情况下影响协整关系?
经济结构变革(如制度转型、重大政策调整)及外部冲击(如危机、疫情)等,都可能导致原有协整关系失效甚至消失。协整关系的长期稳定性需与经济现实紧密结合:
- 制度变迁:如中国计划体制到市场体制过渡
- 重大政策改革:如汇率形成制度完全改造
- 外部重大冲击:如亚洲金融危机、全球疫情等带来的系统性变化
误差修正模型与动态分析
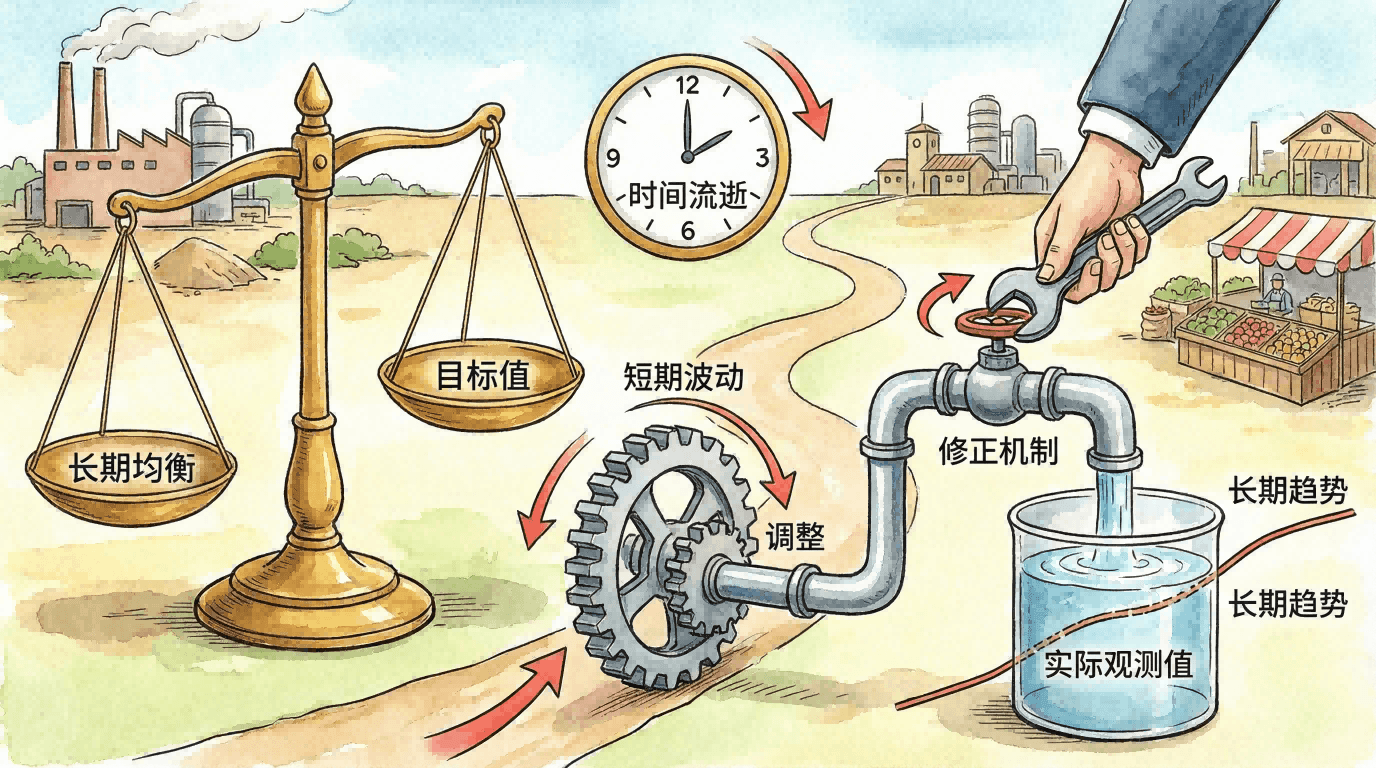
误差修正模型(ECM, Error Correction Model)是协整理论的核心应用之一。它为经济变量的短期动态与长期均衡之间的互动提供了统一且严密的计量框架。在许多宏观实证研究中,经济变量往往本身非平稳,但它们之间却存在一定的协整(长期均衡)关系。ECM不仅能捕捉变量短期波动,还能揭示它们如何渐进修正回长期均衡。
ECM的理论基础
Granger表示定理(Granger Representation Theorem)指出:如果一组经济变量之间存在协整关系,则这些变量的动态过程必然可以表示为含有“误差修正项”的向量自回归(VAR)模型。这个误差修正项反映了变量偏离长期均衡后的调整动力,同时实现短期与长期理论的统一。
设和均为过程,且存在协整关系。则双变量ECM可表达为:
其中表示一阶差分,为误差修正项,衡量调整回长期均衡的速度。若为负,表明变量发生偏离后会有均衡回归的驱动力。
当涉及多个变量、多个协整关系时,通常采用Johansen极大似然方法建立VECM(向量误差修正模型)进行分析。
人民币汇率与基本面的ECM分析
人民币实际汇率的经济解释模型
人民币汇率与一系列经济基本面变量(如生产率、贸易条件、政府支出、净对外资产)之间也可以用ECM加以刻画。
协整关系表达:
其中为实际汇率,为相对生产率,为贸易条件,为政府支出,为净对外资产。
ECM估计结果示例:
政策启示:
- 汇率调整速度,表明实际汇率对经济基本面偏离后的回归过程较慢。
- 相对生产率提升(Balassa-Samuelson效应)大幅推高长期均衡汇率。
- 政府支出扩张对汇率有贬值压力,净对外资产积累导致升值。
误差修正模型(ECM)通过引入协整误差项,有力地刻画了经济变量短期波动与长期均衡的联动。它既能刻画长期约束,又能具体量化偏离后回归均衡的速度,是宏观计量分析必不可少的工具。
ECM的诊断与检验
ECM估计后必须严格开展后验诊断,以确保结果可靠:
检验通过说明模型设定合理,反之需要重新调整变量和滞后阶数。在多变量ECM中,判断某变量是否“弱外生”十分关键。若,即某变量的方程中误差修正项系数为零,通常说明该变量不受长期约束调整,仅影响其他变量,为因果推断提供理论支撑。
总结
非平稳数据分析是现代时间序列计量经济学的核心内容,为理解经济变量的长期行为和相互关系提供了强大工具。
非平稳数据分析作为现代计量经济学的重要分支,为我们理解经济变量的长期行为提供了强大工具。从单位根检验到协整分析,从误差修正模型到面板数据扩展,这些方法帮助我们更好地理解经济系统的动态特征。
在全球经济一体化和数字化转型的背景下,掌握这些方法对于政策制定者、经济研究者和金融分析师都具有重要意义。通过适当运用这些工具,我们能够更准确地理解经济关系的本质,更科学地制定政策,更有效地管理风险。
统计方法是理解经济现象的工具,而不是目的本身。成功的分析需要将严谨的统计方法与深入的经济学洞察相结合,这样才能产生既有学术价值又有实践意义的研究成果。在面对复杂的经济现象时,保持理论的清晰性和方法的严谨性,同时关注现实问题的解决,这是非平稳数据分析的根本要求。