序列相关性

在经济学研究中,时间序列数据占据着极其重要的地位。无论是GDP增长率、通货膨胀率、利率,还是金融市场中的股票和债券价格,这些变量都随着时间变化而记录下来,并构成了丰富且复杂的数据集。时间序列数据有一个显著特征:序列内部各期之间往往不是完全独立的,而是表现出一定的相关结构。这种沿时间推移所体现出来的依赖性,被称为序列相关性(serial correlation),也叫自相关性(autocorrelation)。
这种现象在现实经济生活中广泛存在。比如,一国季度GDP增长通常会受到上几个季度经济活动的持续影响,通胀率或失业率往往也会表现出缓慢的动态调整过程。序列相关性的本质是:过去的事件或冲击会对当前甚至未来产生影响,使得时间序列呈现“记忆”特征。
序列相关性的存在会对传统的回归分析产生深远影响。在经典的回归假设(如高斯-马尔可夫定理)中,误差项应当是相互独立的。然而,在时间序列分析中,这一条件往往难以满足。当我们使用普通最小二乘法(OLS)分析时间序列数据时,如果忽略了序列相关性,不仅可能导致参数估计不再是最有效的,还会使标准误、t统计量等推断结果严重失真,进而误导经济解释和政策建议。例如,过高估计变量的显著性,错误判断模型的拟合优度,甚至对变量之间的因果关系产生误判。因此,识别和正确处理序列相关性,是经济建模不可或缺的重要步骤,也是提升实证分析严谨性的基础。
时间序列数据的理论基础
时间序列数据与横截面数据在本质上的差异十分关键。这不仅表现在数据结构上,更深远地体现在统计推断的理论根基。时间序列分析要求我们针对序列内部的“记忆性”与依赖性,发展出和横截面数据迥异的方法体系。
时间序列过程的基本概念
时间序列模型通常用于描述变量在时间轴上的演化。最常见的线性表达式为:
其中,为外生解释变量,引入了动态依赖项,为误差项。需要注意,时间序列是一个随机过程的单次实现(realization)。例如,中国1978年至2022年的GDP增长序列,是中国经济增长过程在这一历史区间的一个实现序列。
时间序列的独特性
与横截面数据可以通过重复性实验或抽样获得独立份额不同,时间序列过程(如中国GDP、CPI或PM2.5等)的历史演变无法“再来一次”。每一份实际历史数据都是独一无二的,这对后续推断产生重要影响。
观测的相关性
时间序列数据最核心的特征是:与、等存在显著统计相关性。比如中国CPI季度同比变动,往往连续数季呈现持续高位或低位,这种现象便反映了数据随时间的“自相关性”。此时,传统的独立同分布(i.i.d.)假设已不再适用,我们需要采用更一般的理论——如平稳性、遍历性等——来保障合理推断。
平稳性的重要概念
平稳性是时间序列建模和推断的基石。只有平稳过程才可能得到稳定、可重复的估计结果。
强平稳性
若时间序列过程中任意个观测值联合分布与时间起点无关,则称为“强平稳”:
也就是说,该过程的统计结构不会随时间推移发生本质性演变。
弱平稳性(协方差平稳性)
大多数实际分析以“弱平稳”为主,包括:
- ,均值不随变动;
- 对任意,,仅依赖于时间差,与本身无关。
例如,上海1990年以来的季节性PM2.5读数序列,若扣除季节性和趋势后,剩余扰动序列(即残差)近似弱平稳。
平稳过程隐含了一种经济体长期均衡回归的假设,即变量可能短期偏离均衡,但长期表现出中心回归的倾向,这对于预测与政策模拟尤为重要。
遍历性定理
遍历性(Ergodicity)是时间序列理论中又一基石,为基于一条序列的样本均值近似总体均值提供理论保障。
遍历性意味着:时间上足够分隔远的观测值,彼此趋于独立。比如中国GDP增速1978年与2022年,虽然同属于一个序列,但相隔多年后,其相关性极低。
遍历定理表明,如果时间序列既是强平稳的又具有遍历性,并且,那么
即样本均值几乎必然收敛于总体均值。这使得我们能够使用现实历史数据,推断“理论”经济统计量。
AR(1)过程的详细分析
一阶自回归模型(AR(1))代表最基础、最常用的序列相关模型,广泛应用于中国经济增长、CPI、M2等时间序列数据。
其中是白噪声:,当。
AR(1)过程的性质推导
迭代代换得:
说明当前扰动是过去所有冲击的加权和,越大“记忆”越长。
平稳性条件
为使有限,必须。此时:
自协方差为:
自相关系数为:
该图展示了正负不同下的自相关函数:时自相关缓慢递减,时则正负交替衰减。
模型设定错误导致的自相关
以房地产价格为例,假如最初模型仅以“房价与收入”解释房价变动,但忽略金融政策、人口流动等变量,常会发现残差高自相关。随着对模型不断扩展,比如加入二手房交易量、贷款利率、限购限售政策等变量,残差序列的序列相关性会显著减弱。以下是一个类似的递进分析:
模型演进的效果(中国房地产市场举例)
可见,模型设定的完整性大幅影响残差序列的自相关性,关键经济变量或结构变革没有捕捉时,自相关性尤其明显。
结构变化的重要性
如2016年中国多地限购限售政策、2020年以来的“稳房价、稳地价”调控等,均可视为经济结构的大转折点。将这些因素纳入模型后,残差序列的自相关性通常会趋近于消失。说明:
- 历史事件的持久影响:重大政策或经济事件可改变变量关系的结构
- 模型的时间稳定性:经济关系在不同历史时期可能存在参数漂移或突变
- 诊断分析的必要性:残差自相关性不只是统计问题,更是模型设定是否充分的信号
序列相关性通常意味着“模型还有遗漏的重要经济信息”。与其简单做统计修正,不如先深思经济机制、补足变量与结构建模。
序列相关性的两种观点
关于如何处理序列相关性,理论和实践中存在两种主要方法:
实用主义观点
认为序列相关性是一个“技术问题”,可借助统计修正如GLS(广义最小二乘)、FGLS等优化估计方法来提升参数效率和推断的可靠性。
方法论观点
则认为序列相关反映了模型设定不完善,主张通过扩充模型变量、引入政策冲击、结构变化等经济学思路解决根本原因,而不应仅仅依赖统计修正。
实践中的平衡思路
实际应用中,通常按照如下步骤:
- 优先完善经济模型:检视是否有关键变量遗漏、结构变革未涵盖
- 对剩余自相关进行统计修正:如剩余的微弱自相关,可采用统计技术修正
- 稳健性检验:尝试不同处理方式,确保主要结论不因技术选择而剧变
这种“理论—统计—稳健”的综合方式,可兼顾经济解释的说服力与统计推断的准确性。
扰动过程的特征分析

理解扰动过程的特性是深入处理和识别序列相关性的核心。不同类型的扰动(误差)过程反映着不同的经济学机制,因此采用的分析与建模方法也各不相同。
自协方差与自相关的严格定义
在时间序列回归等分析中,通常假定扰动项满足同方差但存在序列相关性,即:
其中, 是 的协方差矩阵,通常是某种结构化的特殊矩阵。
自协方差函数(Autocovariance Function)
设 为滞后期数,第 阶自协方差定义为:
对于弱平稳(或严格平稳)过程, 仅依赖于 ,与具体时间 无关。
自相关函数(Autocorrelation Function, ACF)
第 阶自相关系数定义为:
其中, 为扰动项的方差。自相关函数刻画了序列依赖的强弱及衰减特性。
AR(1) 过程的数学推导与特性
一阶自回归(AR(1))过程是序列相关性分析中最为基础也最为重要的模型之一。其形式为:
其中 保证平稳性, 为白噪声过程(, )。
方差与自协方差的递推与求解
利用平稳性条件 ,有:
递推解得:
阶自协方差:
对应自相关系数为:
AR(1) 协方差矩阵的特殊结构
AR(1) 的协方差矩阵具有 Toeplitz 结构,即:
该矩阵充分体现了“记忆逐级衰减”特征——期距越远,自协方差越弱。
其他常见扰动过程数学描述
移动平均过程(MA(1))
移动平均过程捕捉“仅短期扰动相关”:
相关特性为:
高阶自回归过程(AR(p))
可呈现“周期性”、“振荡”等复杂相关结构。
自回归滑动平均过程(ARMA)
结合自回归与移动平均:
ARMA 过程能够极为灵活地拟合各类实际观测到的自相关特征。
中国经济数据中的实际序列相关性
以中国主要宏观变量为例,实际数据显示其误差项自相关性极显著:
GDP增长率的自相关性
CPI通胀率的自相关性
这些数据反映出中国宏观经济变量的自相关性和“粘性调整”结构,与经济理论一致。
序列相关性的经济学机制
许多经济变量之所以存在显著的自相关性,主要源于三个方面:
-
惯性和调整成本。无论是企业生产、居民消费还是政府政策,现实中往往难以实现即时调整,而是受到资金、技术、管理等多重约束,必须经历渐进的变化过程。
-
“适应性预期”,即经济主体决策时不仅参考当前信息,还深受历史经验与过往观测的影响——如通胀预期、投资决策和政策制定都普遍依赖历史数据修正。
-
外部冲击的持续和传导效应。重大国际事件、政策变动、市场情绪等会通过复杂机制在经济系统内部产生连锁反应,效果常常滞后并持续较长时期。
因此,经济变量往往表现为“粘性调整”和对历史状态的长期依赖,这正是自相关性在统计建模中的根本来源。
扰动过程类型的识别与建模建议
在实际的时间序列建模中,准确判断并合理建模扰动项的自相关结构,是获得可靠估计和科学推断的基础。建模流程通常需要“理论-诊断-选择-验证”相结合,以下是常见经验总结与实践建议。
典型自相关结构与建模指引
详细诊断与模型识别工具
- 自相关函数(ACF)图:直观检查不同滞后下的相关系数,可辅助判别衰减类型。例如,缓慢指数型衰减多为AR;突然截断通常提示MA结构。
- 偏自相关函数(PACF)图:用于决定AR项的具体阶数。PACF在p阶后骤降至零,说明可选AR(p)。
- 信息准则(AIC、BIC等):比较不同阶数组合的模型,选择平衡拟合优度与复杂度的最优结构。通常逐步递增阶数并对比AIC/BIC值最小的模型。
- 残差分析与Ljung-Box检验:对拟合模型后的残差进行自相关检验,确保残差“白噪声”假设成立,若残差仍有自相关则需调整模型结构。
- 理论与实际结合:结合经济变量特性和专业领域知识判断,利用经济学常识(如周期性、惯性、冲击来源等)辅助模型初筛。
综合应用上述方法与诊断工具,有助于构建适配数据特性的扰动项过程模型,为后续参数估计、预测与经济解释提供可靠基础。
序列相关性的检验方法

在实际的时间序列分析中,检验序列相关性的存在是一个不可或缺的关键步骤。如果误差项(扰动项)存在序列相关性(自相关)而我们却忽略了这一点,通常会导致估计量失去有效性,统计推断(如置信区间和假设检验)也会出现偏误,严重时甚至使结论完全失效。因此,在建模初期就应当对扰动项的自相关性进行严格检验。
检验的基本思路
序列相关性检验的基本思路是:如果真实扰动项存在自相关性,这种特征可以从最小二乘残差的自相关性中得到线索。最常见的是检验一阶自相关,即:
其中为残差,代表一阶自相关系数。如果显著不为零,即统计检验表明,则说明存在一阶序列相关性。
Durbin-Watson检验
Durbin-Watson检验(简称检验)是最早且最为经典的序列相关性检验方法之一,目前在应用经济、金融等多个领域依然被广泛采纳。
检验统计量公式:
当样本容量较大时,与残差的一阶自相关系数大致满足关系:
其中,。
判别规则:
其中,和分别为下、上界,具体数值查表获取,与样本量和解释变量数有关。
DW检验局限性:
- 不确定区间:当落入不确定区间,不能唯一判断自相关是否存在。
- 仅检验一阶自相关:没法发现高阶()自相关。
- 滞后因变量问题:模型包含滞后因变量(如等)时,DW检验失效。
Breusch-Godfrey LM检验
Breusch-Godfrey LM检验(又称通用拉格朗日乘数法)是更为一般和强大的序列相关性检验方法,可检测任意阶的自相关,适用于包含滞后因变量的模型。
检验步骤:
用估计原始回归,获得残差。
其中为辅助回归的判定系数,为检验的最大滞后阶数。显著性检验拒绝则认为存在自相关。
LM检验优势对比:
Box-Pierce 和 Ljung-Box 检验
这两类检验直接用残差的自相关系数判断是否有自相关,特别适合ARMA模型残差的诊断。
Box-Pierce Q统计量:
其中是残差的阶自相关系数,为样本容量。
Ljung-Box修正Q统计量:
在有限样本下性质更优。对于残差无自相关的检验,两者都广泛使用。
中国CPI同比增速的检验实例
以中国CPI(月度同比增速)的回归残差为例,采用四种主流检验方法,统计结果如下:
四种检验均一致拒绝无序列相关性的原假设,表明CPI回归模型的残差具有显著的序列自相关性。
残差自相关系数表:
可以看到,主要存在显著的一阶自相关,因此AR(1)模型较为适用。
含滞后因变量时的检验策略
当回归方程中含有滞后依赖项(如),传统DW检验会高估无自相关的概率,易忽略序列相关性。
Durbin 检验
为此,Durbin提出了检验,检验统计量为:
其中为残差的一阶自相关系数,为滞后因变量回归系数的方差估计,为样本容量。统计量近似服从标准正态分布。
修正型LM检验
针对这种模型,还可以在辅助回归中纳入原始解释变量和滞后因变量:
然后联合检验。
在包含滞后因变量的模型中,若误差项存在序列相关性,则估计量将不再一致(即即使样本足够大也偏离真实值),这比效率损失更为严重。因此,必须准确检测序列相关,并根据检验结果采用如GLS、FGLS等更稳健的估计方法,保障模型可靠性。
序列相关性下的估计方法

当我们确认残差存在序列相关性后,需要采取合适的估计方法,以获得有效的参数估计和可靠的统计推断。此时,普通最小二乘(OLS)估计会导致标准误低估、系数偏误甚至不一致,必须采用能够修正序列相关性的推断手段。下面介绍几种主要方法。
广义最小二乘法(GLS)
如果残差协方差矩阵 已知,广义最小二乘(GLS)估计量为
该估计量具有最优的渐近性质:无偏、一致,并且在同类线性无偏估计中方差最小(BLUE)。
AR(1) 序列相关下的GLS变换方法
对于满足一阶自回归(AR(1))结构的误差项模型,,可以通过如下变换消除序列相关:
变换后的模型满足高斯-马尔可夫假设,可以直接应用OLS:
可行广义最小二乘法(FGLS)
实际中, 通常未知,需要先对 等参数作出估计,这就引出了FGLS。思路是:先用OLS得到残差,再利用残差估计自相关系数,最后按上述GLS变换。
Prais-Winsten估计步骤
用OLS估计原始回归,得到残差 。
估计自相关系数:
该方法保留首期观测,不损失样本信息。
Cochrane-Orcutt估计量
与Prais-Winsten类似,但第一步将观测舍弃:
该算法实现简单,但损失一个观测值,长期序列效果更接近Prais-Winsten。经验中,Prais-Winsten具有一定优势。
最大似然估计(MLE)
当误差为AR(1)过程时,对数似然函数为:
其中
最大似然估计可联合估计等参数。
中国汽油市场的实例分析
为了直观呈现不同方法的效果,以下以中国汽油消费建模为例:
拟合模型形式为
不同估计方法结果对比:
主要结论:
- 价格弹性校正: 当修正序列相关性后,价格弹性从提升到约,更符合理论预期。
- 收入弹性变化: 收入弹性自OLS的1.625跌至0.47-0.75,说明序列相关会显著高估OLS下的收入效应。
- 高度自相关性: 达到,表明残差高度正自相关,采用GLS/FGLS是极为必要的。
工具变量与动态模型的自相关修正
若回归中含有滞后因变量,例如,则残差存在自相关会使OLS估计量不一致,此时必须采用工具变量(Instruments, IV)方法。
Hatanaka两步估计法
- 用工具变量法估计含滞后因变量的回归系数(常见工具包括及其线性组合)。
- 用IV残差估计自相关参数,然后进行FGLS变换。
常见工具变量的选择:
- 及其滞后;
- 在上的拟合值;
该方法在动态面板和动态时间序列建模中也极为常用。
稳健标准误的估算(Newey-West调整)
即便采用OLS估计,也可通过稳健标准误修正序列相关性错误带来的推断偏差。Newey-West标准误是其中的主流方法。
其协方差矩阵估计为:
其中,,为滞后阶数,通常选择。
实际应用举例:
以货币需求的回归为例,修正前后的标准误如下:
可以看出,修正后的标准误更大,检验显著性略有下降,反映了序列相关性对假设检验的重要影响。
Newey-West估计量的显著优势在于其对序列相关类型无须假定具体结构,能够对各种自相关形式提供稳健性修正。因此在宏观经济、金融、微观面板数据等应用场景中被广泛采纳,是现代实证研究的重要基础工具之一。
ARCH与GARCH模型详解
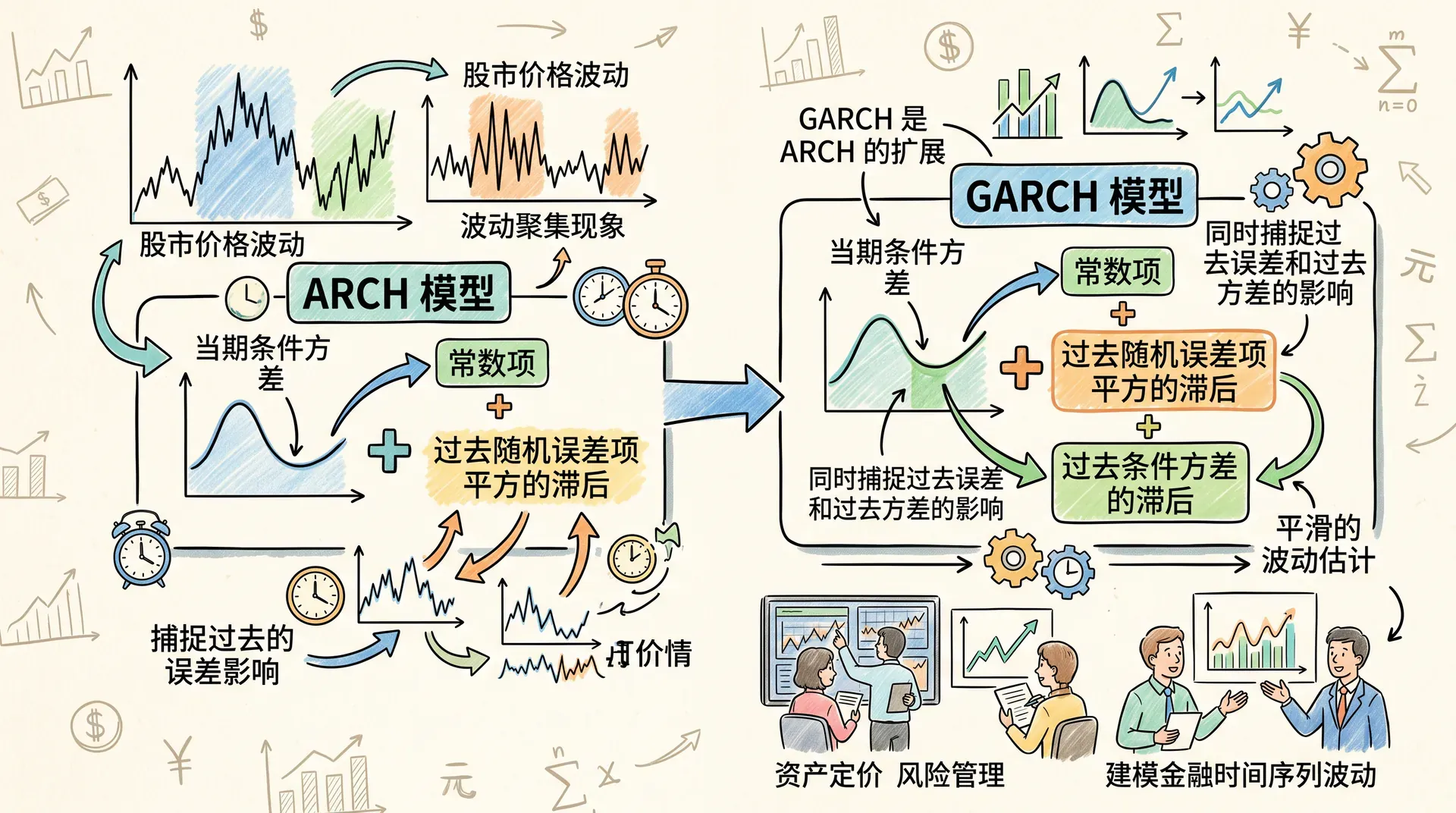
在金融及经济时间序列分析中,常出现“波动聚集”(volatility clustering)现象:大的收益率变动往往紧跟着大变动,小变动后又多为小变动。这种现象表明条件异方差存在,即序列的方差随时间变化,而传统的同方差(Homoscedasticity)假设难以解释这些波动。为此,需要采用ARCH类模型加以建模。
ARCH模型基本原理
ARCH(自回归条件异方差)模型由Robert Engle在1982年提出,其核心思想是误差项的条件方差取决于以往的扰动。最简单的ARCH(1)模型为:
其中 ,且 。
此模型意味着:
A股某科技龙头股票收益率波动
以下以“中证500指数某成分股”日收益率作为案例(如),展示ARCH效应,替换原有例子。
实证数据显示,在某些时段(如50-90与330-390日),收益率剧烈波动,而其他时段明显趋于平稳,符合ARCH过程的“波动聚集”特性。
GARCH模型与进一步推广
Bollerslev于1986年提出GARCH(广义ARCH)模型,更灵活地描述条件方差的动态性质:
(这里以GARCH(1,1)为例)
GARCH模型的主要特征比较:
GARCH平稳性条件:
无条件方差(长期均值)为:
ARCH-M模型及应用场景
现实中“高风险高收益”现象突出,ARCH-M(ARCH-in-Mean)模型将条件方差直接纳入均值方程:
其中衡量风险溢价的显著性。若,说明风险上升带来更高预期收益。
全球主要股票市场ARCH-M估计
注:星号表示统计显著性
GARCH模型的估计方法
GARCH参数主要通过极大似然(MLE)估计。其对数似然形式为:
其中,为上述递归方程。
常见估计流程:
- 初值设定:用OLS残差估及,小正数初步设定,
GARCH(1,1)在“中证500成分股”收益率上的估计结果(假设样本分析):
解释:
- 显著,ARCH效应成立
- 较大,波动有明显持久性
- ,满足平稳性
ARCH效应的识别与检验
在GARCH建模前,应先鉴别序列是否有ARCH效应,常用Lagrange Multiplier(LM)检验,步骤如下:
用OLS拟合,获得残差
示例检验(“中证500成分股”,滞后期):
- LM = 46.7,
- 明显拒绝无ARCH效应原假设
ARCH/GARCH模型广泛应用于金融风险管理、波动率预测等领域。例如它们可准确估算风险价值(VaR),帮助机构对冲市场风险、提高稳健性,是现代资产管理、风险控制的基础工具。
总结
序列相关性分析是时间序列计量经济学的核心内容,为理解和建模经济变量的动态行为提供了强大工具。
序列相关性的本质特征
序列相关性分析作为现代计量经济学的重要组成部分,为我们理解经济变量的时间演化提供了强大工具。从简单的自回归模型到复杂的GARCH规范,这些方法帮助我们更好地理解经济系统的动态特征。
在数据驱动决策日益重要的今天,掌握这些方法对于政策制定者、金融分析师和经济研究者都具有重要意义。通过适当运用这些工具,我们能够更准确地预测经济走势,更有效地管理金融风险,更科学地评估政策效果。
统计模型只是理解现实的工具,而不是现实本身。成功的分析需要将严谨的统计方法与深入的经济学洞察相结合,这样才能产生既有科学价值又有实践意义的研究成果。