从问题到可验证的算法
一批配送单按承诺时间排队。数据只有几百条时,手动整理似乎也能完成;到了几十万条,同样的做法可能让系统等上很久。更麻烦的是,如果排序过程漏掉一张单据,即使结果看起来整齐,也仍然是错误的。
算法讨论的核心因此有两层:先把问题写成可以执行和验证的步骤,再判断这些步骤会消耗多少资源。本章用插入排序与归并排序贯穿这两层,并把“为什么正确”和“为什么够快”分别说清。

先写清输入、输出与约束
算法是一段有限、明确的计算过程。它接收满足前置条件的输入,经过一系列可执行步骤,最后给出满足后置条件的输出。只描述“把数组排好”还不够,排序问题至少要写成下面这样:
- 输入:含有 个可比较元素的数组 。
- 输出:数组 ,其中元素按非降序排列。
- 元素守恒: 与 含有完全相同的元素及重复次数。
- 终止:过程必须在有限步内结束。
“有序”和“元素守恒”缺一不可。把 [3, 1, 2] 变成 [1, 2] 虽然有序,却丢了元素;把它变成 [1, 2, 3] 才满足完整的输出条件。
伪代码用接近程序的形式表达步骤,但允许省略与核心思路无关的工程细节。本章统一使用 0 起始下标,区间 A[left..right] 包含两端。
判断一个过程是不是完整算法时,先检查输入域、输出要求、每一步是否明确,以及过程能否终止。运行速度是后续问题。
1
排序算法返回 [1, 2, 3]。要确认结果正确,还必须检查什么?
插入排序:把局部有序向右推进
设左侧已经排好,接下来只处理一个新元素。把这个元素暂存为 key,从已排序区的右端向左比较:比 key 大的元素右移一格,直到出现不大于 key 的元素,再把 key 放进空位。
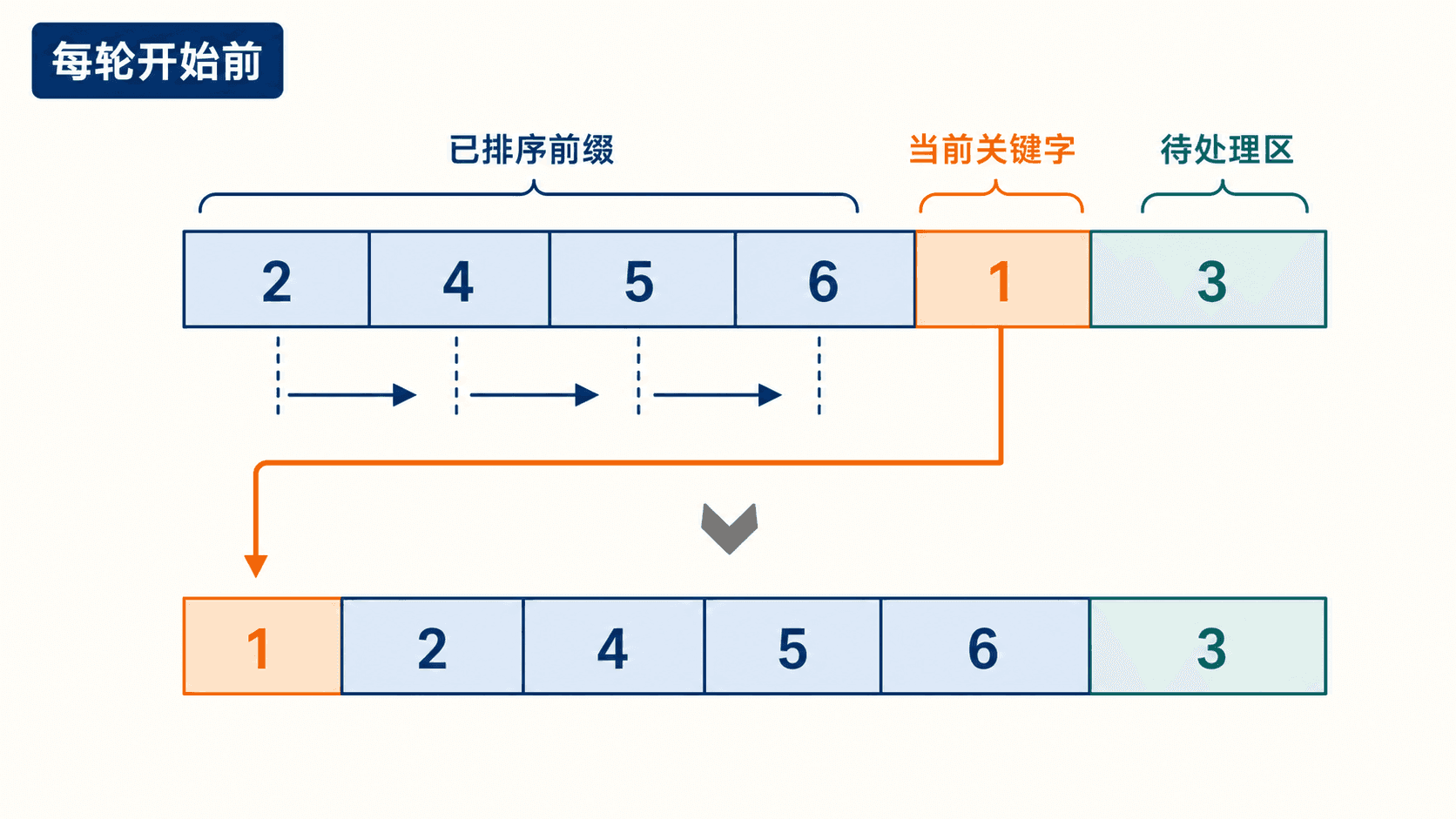
text
INSERTION-SORT(A)
for j = 1 to A.length - 1
key = A[j]
i = j - 1
while i >= 0 and A[i] > key
A[i + 1] = A[i]
i = i - 1
A[i + 1] = key数组 [5, 2, 4, 6, 1, 3] 的前几轮很能说明这个过程:第一轮把 2 插到 5 前,得到 [2, 5, 4, 6, 1, 3];下一轮把 4 插进 [2, 5],得到 [2, 4, 5, 6, 1, 3]。算法没有另建一份同规模数组,只用 key、i、j 等常数个临时位置,因此额外空间为 。
2
处理 key 时,为什么要把较大元素右移,而不是直接覆盖插入位置?
循环不变式:把“看起来能行”变成证明
一次示例运行不能证明所有合法输入都正确。循环不变式提供了可复用的证明结构:找出一个在每轮开始前都成立的陈述,再依次证明初始化、保持与终止。
插入排序外层循环的不变式是:每轮开始、准备处理下标 j 时,A[0..j-1] 已按非降序排列,而且恰好包含输入原前缀中的全部元素。
初始化时 j = 1,前缀只有 A[0]。单个元素天然有序,它也显然没有被替换,所以不变式成立。
假设一轮开始前不变式成立。内层循环只把大于 key 的元素向右搬移,随后把 key 写入空位;处理后的 A[0..j] 有序,且元素及重复次数不变。下一轮开始时,不变式继续成立。
循环在 j = n 时结束。此时不变式中的前缀变成 A[0..n-1],正好覆盖整个数组,因此整个数组有序且元素守恒。
终止部分不能只写“循环结束,所以正确”。真正发挥作用的是“不变式 + 退出条件”:退出条件告诉我们已排序前缀已经扩展到整个输入。
3
证明初始化和保持后,就可以不看循环的退出条件,直接得到算法最终正确。
用统一成本模型分析运行时间
墙上时钟测到的秒数会受处理器、编译器、缓存和系统负载影响。为了先比较算法本身,我们采用一个简化的随机访问机模型:程序在单处理器上顺序执行;算术、比较、赋值和一次内存访问等常见原子操作按常数成本计算。
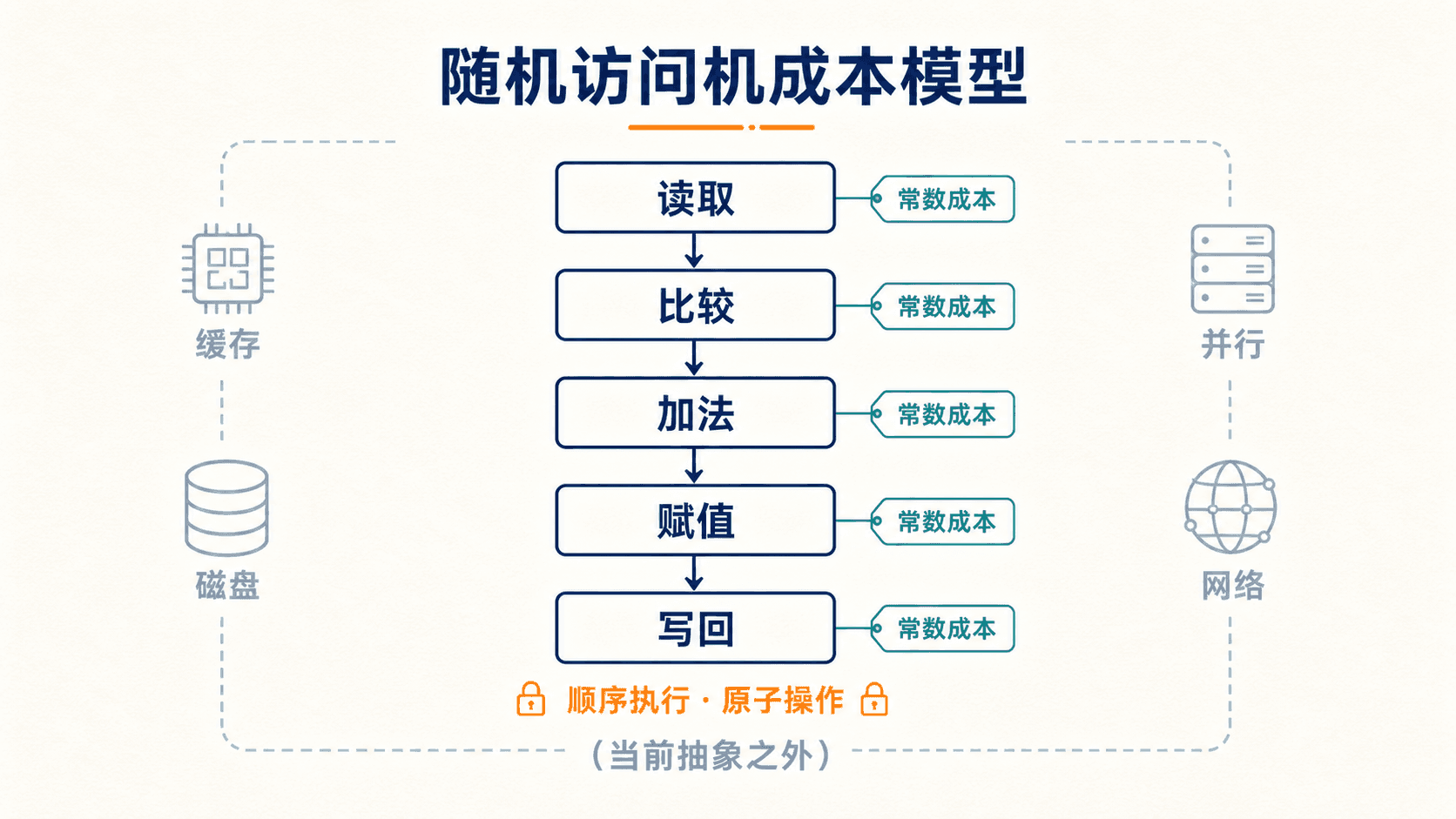
这个模型是一套记账规则,不是对真实机器的完整复刻。它不会把“排序整个数组”当成一条原子指令,也暂时不细分缓存命中、磁盘访问、网络通信或并行执行。统一口径让我们可以在硬件未知时比较增长趋势,工程落地时再补充实测。
输入规模也不能一律理解成“输入了几个参数”。排序通常用元素个数 ;大整数乘法更关心总比特数;图算法常同时使用顶点数 与边数 。
插入排序的内层比较次数依赖数据排列。记第 j 轮检查条件的次数为 ,总成本可以写成各语句单次成本与执行次数的乘积之和。精确式子很长,但两种边界输入很清楚:
- 已经有序:每轮第一次比较就停止,总工作量随 线性增长,即 。
- 完全逆序:第
j轮要跨过前面的 个元素,移动总数为
因此最坏情况为 。随机排列下,当前元素平均需要检查已排序前缀的大约一半,量级仍为 。
4
关于算法分析中的输入规模,哪些说法正确?
归并排序:拆开之后有序地合并
插入排序每次把已解范围扩展一个元素。归并排序选择分治:把区间分成左右两半,递归排好两半,再把两个有序序列合成一个。
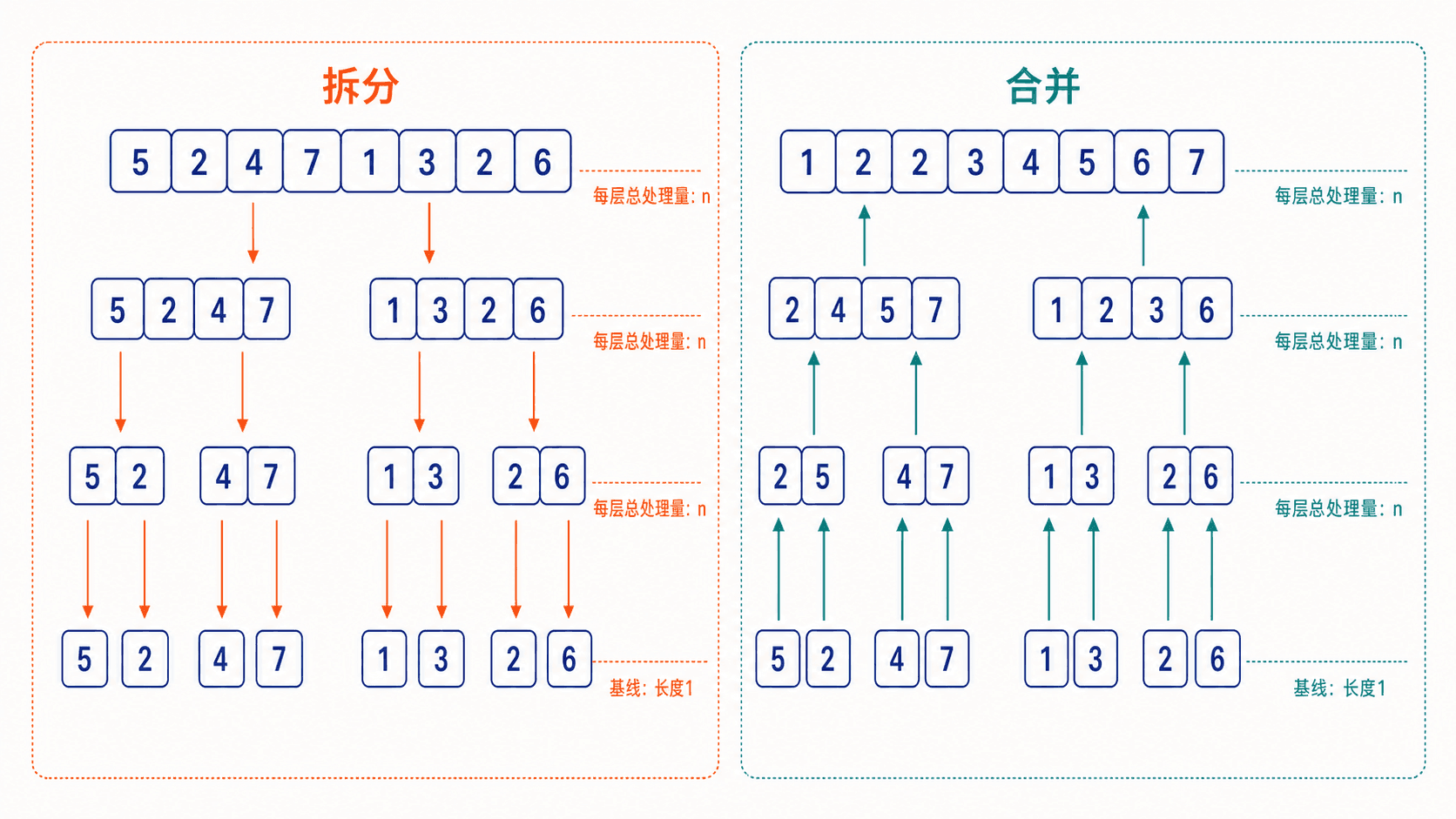
javascript
function mergeSort(input) {
if (input.length <= 1) return [...input];
const middle = Math.floor(input.length / 2);
const left = mergeSort(input.slice(0, middle));
const right = mergeSort(input.slice(middle));
const result = [];
let i = 0;
let j = 0;
while (i < left.length && j < right.length) {
if (left[i] <= right[j]) result.push(left[i++]);
else result.push(right[j++]);
}
return result.concat(left.slice(i), right.slice(j));
}合并过程有自己的不变式:每次比较前,result 已经按序包含左右两边所有“已取出元素”,并且这些元素就是尚未输出前的最小一批。每次从两个当前首元素中选择较小者,就能保持这个事实;某一边耗尽后,另一边剩余元素本来就有序,可以整体接到末尾。
5
合并两个有序数组时,为什么只比较它们当前未处理的首元素?
从递推式读出归并排序的成本
长度为 1 的数组不需要继续拆分,成本为常数。长度为 时产生两个规模约为 的子问题,合并阶段扫描全部 个元素。因此:
把递归过程画成树:第 0 层合并总量是 ;第 1 层有两个规模为 的合并,总量仍是 ;此后每层同样是 。规模每次减半,约经过 层到达长度 1,所以
普通归并排序还需要 的辅助空间来存放合并结果。与插入排序相比,它用额外内存换取更稳定的最坏情况时间。
渐进量级不等于任何规模下的实测排名。常数成本、内存局部性和数据状态会影响交叉点;这也是实际排序实现常在大区间用高效算法、在很小的子区间切换到插入排序的原因。
6
递推式 T(n)=2T(n/2)+Θ(n) 中的 Θ(n) 表示什么?
用真实执行校对推演
下面的输出来自 Node.js v25.2.1,对输入 [8, 3, 5, 4, 7, 6, 1, 2] 实际运行。comparisons 统计元素比较,shifts 只统计已排序元素向右移动的次数。
console
pass 1: key=3, comparisons=1, shifts=1, state=[3,8,5,4,7,6,1,2]
pass 2: key=5, comparisons=2, shifts=1, state=[3,5,8,4,7,6,1,2]
pass 3: key=4, comparisons=3, shifts=2, state=[3,4,5,8,7,6,1,2]
pass 4: key=7, comparisons=2, shifts=1, state=[3,4,5,7,8,6,1,2]
pass 5: key=6, comparisons=3, shifts=2, state=[3,4,5,6,7,8,1,2]
pass 6: key=1, comparisons=6, shifts=6, state=[1,3,4,5,6,7,8,2]
pass 7: key=2, comparisons=7, shifts=6, state=[1,2,3,4,5,6,7,8]
merge=[1,2,3,4,5,6,7,8]第 2 轮有两次比较:先判断 8 > 5 并移动,再判断 3 > 5 为假后停止。比较次数因此可能比移动次数多 1。把统计口径写清,数据才可复核。
7
在上面的真实运行中,把 key=1 插入已排序前缀时发生了 ____ 次右移。
综合练习
练习一:手动跟踪与不变式
对 [9, 4, 7, 2, 6] 执行插入排序,写出每轮结束后的数组,并用一句话说明每轮开始前的不变式。
练习二:为线性查找设计不变式
线性查找从左到右寻找目标值 x。请给出能证明它正确的循环不变式,并说明找不到时为什么可以返回 null。
练习三:选择算法
有两组数据:甲只有 30 个元素且几乎有序;乙有 100 万个元素,顺序未知,内存足够。若只在插入排序和归并排序中选择,你会怎样选?
8
一份完整的算法论证通常需要包含哪些内容?