贪心算法:把局部选择变成可证明的全局最优
一间会议室从早到晚有许多预约。每个预约都想独占会议室一段时间,我们希望尽量多地接受预约。你会先选最早开始的、持续时间最短的,还是最早结束的?
这类问题最容易让人凭直觉写出一个排序规则。真正困难的地方不是“选谁”,而是回答:这一步做完以后,是否还保留了得到全局最优解的机会?
贪心算法在每一步固定一个当前最有利的选择,不撤销,也不并行保留其他方案。它通常只有排序、扫描、堆操作几行核心代码,却附带一项严格的证明义务。只要安全性证明缺了一环,程序就只是一个运行很快的猜测。
学完本章,你应该能完成四件事:提出候选贪心规则;用交换论证证明规则安全;用小反例推翻错误规则;识别拟阵这类能稳定支持贪心的结构。
1
判断一个贪心规则是否正确,最关键的依据是什么?
从“看起来最好”到“可以放心选”
设一个优化问题的候选集合为 ,可行解族为 ,目标是在可行解中最大化或最小化某个值。一个完整的贪心设计至少要说清四个对象:
- 当前有哪些候选元素;
- 怎样判断加入一个元素后仍然可行;
- 用什么排序键或优先级定义“当前最好”;
- 选择后剩下的是哪个更小的同类问题。
只写“每次取最大”还不是算法。最大的是价值、价值密度、剩余空间,还是最早结束时间,会导向完全不同的结果。
贪心选择性质
贪心选择性质并不要求每个最优解都包含贪心元素。它只要求:至少存在一个最优解包含当前贪心选择。
这个量词很重要。证明时,我们可以先拿任意一个最优解。如果它没有采用贪心选择,就在不损失质量的前提下改造它,得到另一个包含贪心选择的最优解。
最优子结构
固定第一步以后,原问题必须缩小成同类问题。若贪心选择为 ,剩余实例为 ,常见的证明目标是:
最大化“元素个数”时,;霍夫曼编码中,固定一次合并增加的是两个节点的频率之和。
交换论证的四步模板
取一个全局最优解 ,并指出贪心选择 。如果 ,第一步已经安全。
如果 ,找到 中可被替换的元素 ,构造 。
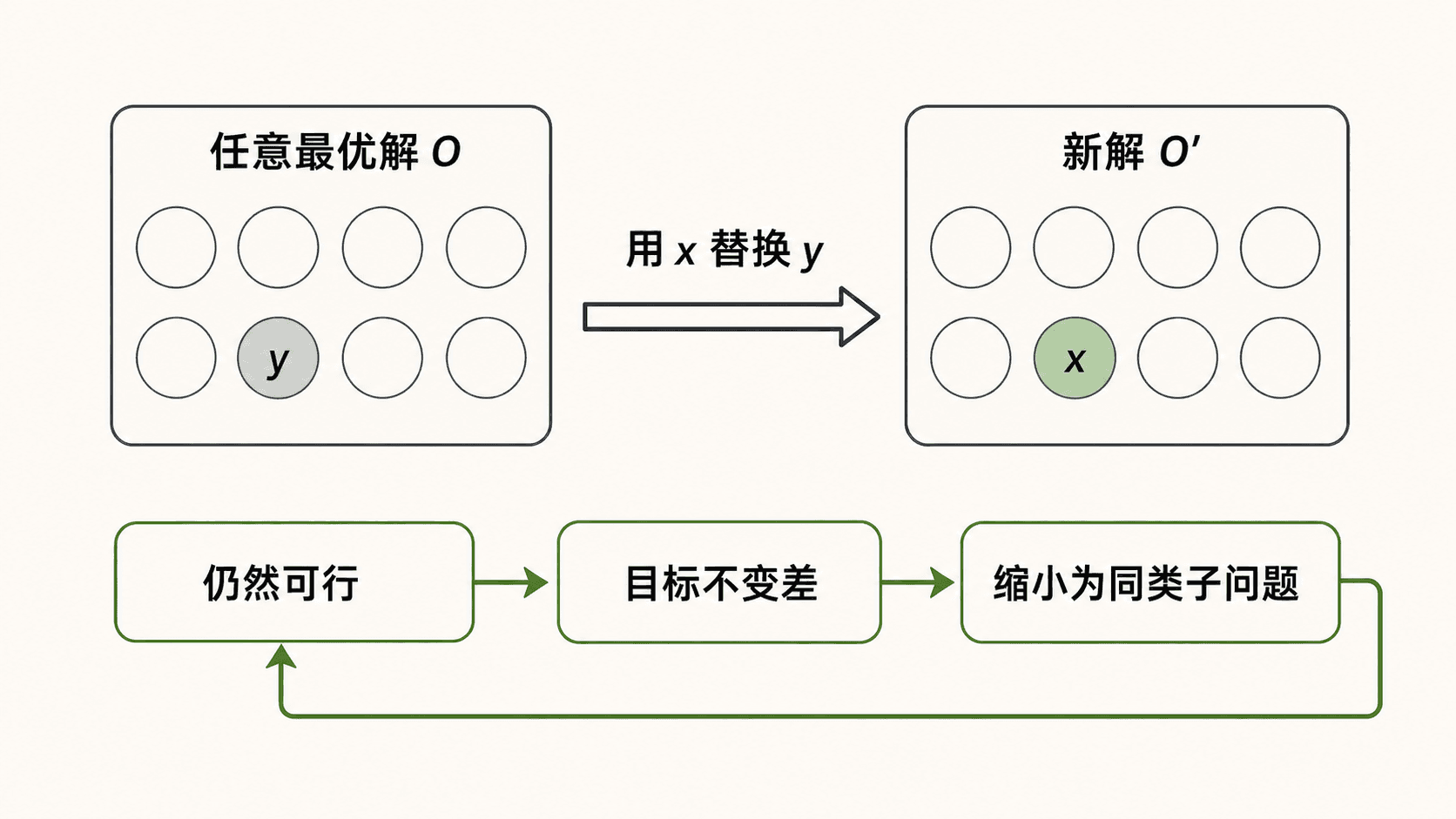
“我总能把贪心选择换进去”必须说明换掉谁、为什么仍可行、目标值为何不变差。省略任何一项,交换论证都没有闭合。
2
某证明说:把最优解中的元素 x 换成更高价值的 g,所以新解更优或相同。这个论证还必须补充哪些内容?
活动选择:为什么要选最早结束的预约
每个活动 占用半开时间区间 。半开区间允许一个活动在时刻 结束,另一个活动恰好在 开始。两个活动兼容,当且仅当它们的区间不重叠。目标是选出数量最多的两两兼容活动。
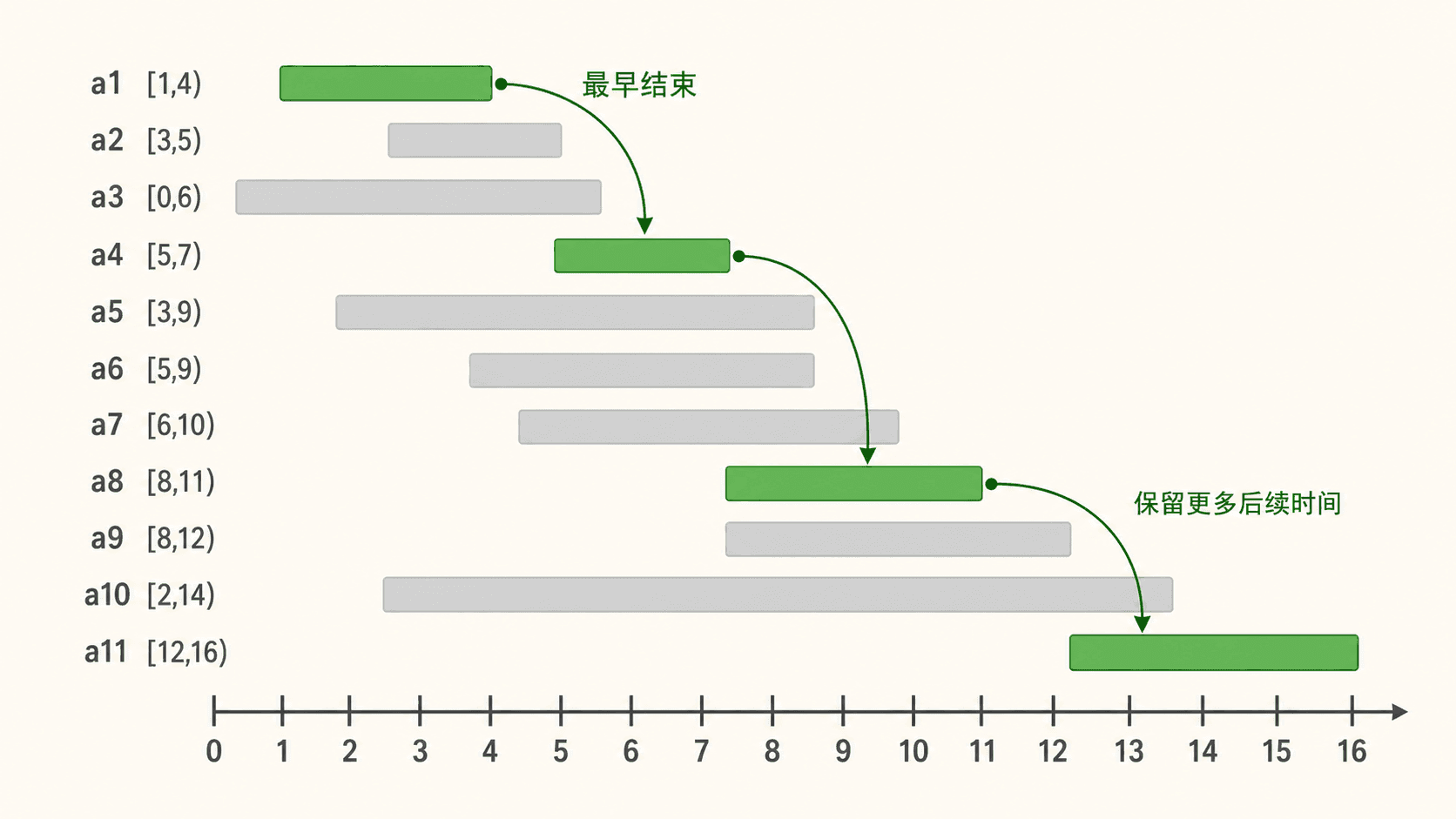
考虑下面的 11 个活动:
规则与算法
先按结束时间升序排列,然后从左到右扫描。只要当前活动的开始时间不早于最近已选活动的结束时间,就接受它。
js
function selectActivities(activities) {
const sorted = [...activities].sort((a, b) => a.finish - b.finish);
const selected = [];
let lastFinish = -Infinity;
for (const activity of sorted) {
if (activity.start >= lastFinish) {
selected.
这组数据的真实运行结果是:
console
activity greedy: a1,a4,a8,a11 (4)
activity brute: a1,a4,a8,a11 (4)暴力枚举只是对这一个有限输入做校验;一般性的正确性来自下面的交换论证。
为什么第一步安全
在当前可选活动中,设 的结束时间最早。再取一个最大兼容活动集合 ,把 中最早结束的活动记为 。
如果 ,这个最优解已经包含贪心选择。否则有:
把 中的 换成 。原来排在 后面的活动,开始时间都不早于 ,当然也不早于 ,所以替换后仍然兼容。集合大小没有变化,于是新的集合仍然最优,而且包含 。
选定 后,只需保留所有满足 的活动。剩余任务仍然是一个活动选择问题,最优子结构成立。
三个很像正确答案的错误规则
最早开始。 活动 最早开始,但会挡住 、、 等许多活动。
持续时间最短。 中间的短活动可能同时挡住左、右两个可兼容活动。例如选 会排除 与 ,而后两者可以同时选择。
与其他活动冲突最少。 冲突数量只统计当前图上的邻接关系,没有反映选择后剩余时间轴的结构;局部最小冲突也可能破坏更好的组合。
复杂度与循环不变量
若输入已按结束时间排好,扫描是 ;否则排序使总时间为 。扫描过程中可以维护这个不变量:在已经检查过的活动中,selected 是某个最优解的前缀,lastFinish 是该前缀最后一个活动的结束时间。
3
已选活动在时刻 7 结束。采用半开区间 [s,f) 时,下列哪个活动可以紧接着选择?
4
如果每个活动还带有不同价值,按结束时间最早选择仍一定能得到最大总价值。
贪心与动态规划:相同的子结构,不同的决策时机
贪心和动态规划都可能利用最优子结构。区别在于什么时候固定选择。
分数背包为什么可以贪心
物品 的价值为 ,重量为 。若允许切分物品,按价值密度 从高到低装入是安全的。假设某个解把一小段容量给了低密度物品,而仍有更高密度物品未装满;交换这两段容量不会超重,且总价值只会增加。
0/1 背包为什么会失败
容量为 50,有三件不可切分物品:
密度贪心先取 A、B,价值为 160,剩余 20 的容量装不下 C。最优解取 B、C,价值为 220。分数版本可以再取 C 的 ,总价值为 240。
0/1 约束制造了不可修补的离散空隙。此时我们必须同时比较“选当前物品”和“不选当前物品”两个分支,动态规划更合适。
“问题有最优子结构”不能推出“问题可以贪心”。0/1 背包既有最优子结构,也有小而明确的密度贪心反例。
如何主动寻找反例
从 2–4 个元素开始,故意让贪心第一步制造不可逆损失:占满关键容量、跨越时间轴中点、阻断两个可组合元素,或选择一个单独价值略高但总组合价值更低的元素。再用暴力枚举算出真正最优解。
5
上表的三件物品在容量 50 下,0/1 背包的最优选择是什么?
霍夫曼编码:每次合并最低频的两个节点
前缀码是一组二进制码字,其中任何码字都不是另一个码字的前缀。把字符放在二叉树叶子上,左边记 0,右边记 1,从根走到叶子的路径就是码字。由于字符只出现在叶子上,解码器读到叶子便能确定一个字符,不需要分隔符。
设字符集合为 ,字符 的频率为 ,它在树 中的深度为 。编码总成本是:
高频字符应该浅一些,但“逐个把高频字符放浅”很难保证整棵树合法。霍夫曼算法换了一个方向:从叶子向根合并。
合并算法
- 把每个字符作为一棵单节点树放进最小优先队列。
- 取出频率最小的两棵树 。
- 新建父节点 ,令 ,再把 放回队列。
txt
HUFFMAN(C)
Q = 由 C 建成的最小堆
while Q.size > 1
x = Q.extractMin()
y = Q.extractMin()
z = Node(freq = x.freq + y.freq, left = x, right = y)
Q.insert(z)
return Q.extractMin()对频率 a:45, b:13, c:12, d:16, e:9, f:5,真实执行得到:
console
huffman merges: 5+9=14 | 12+13=25 | 14+16=30 | 25+30=55 | 45+55=100
huffman cost: 224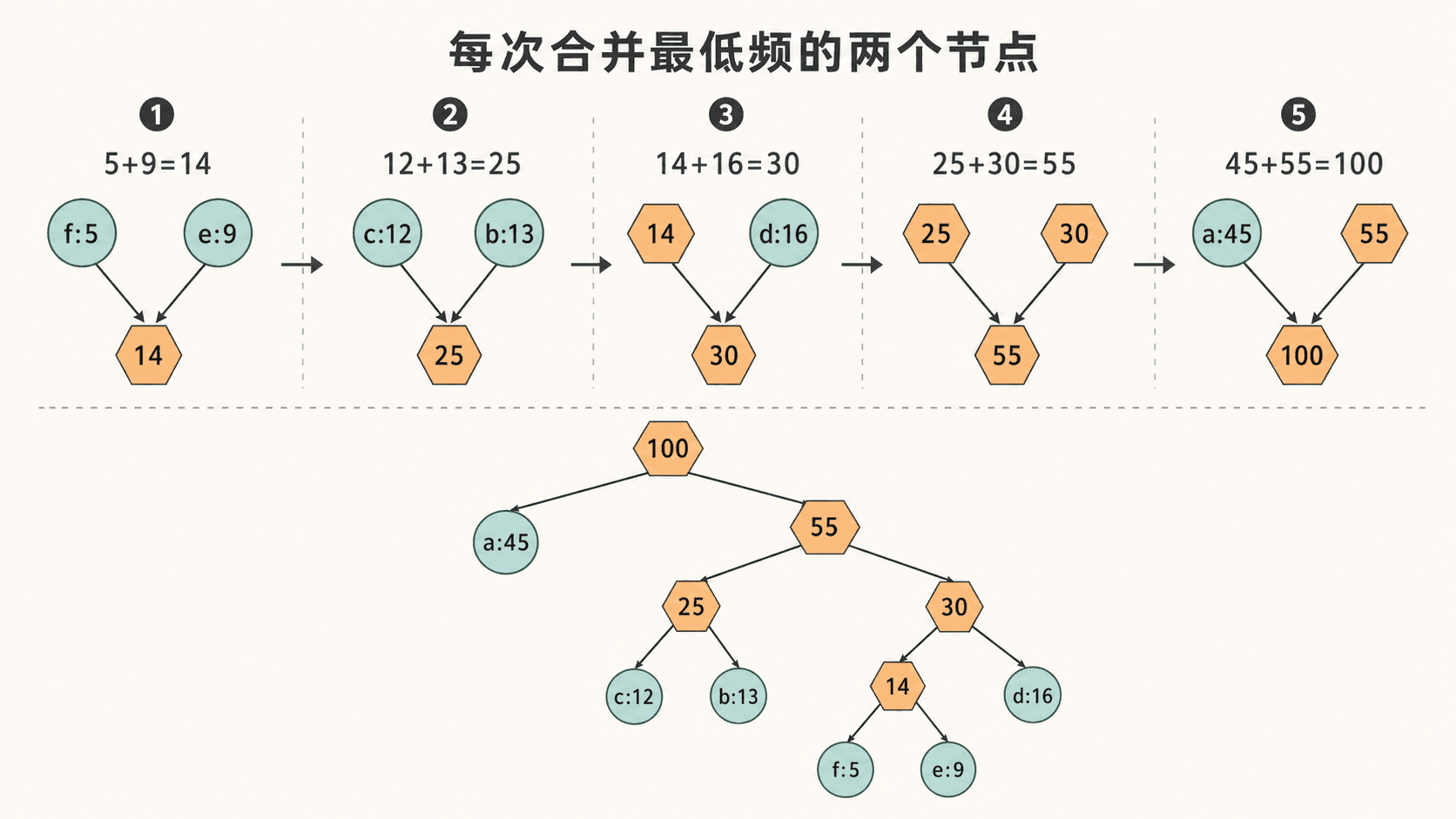
最低频的两个字符为什么可以先合并
在一棵最优的满二叉树中,取最深处的一对兄弟叶。设它们是 ,而全体字符中最低频的两个字符是 。
把 与 的位置交换。交换引起的成本差可以整理为:
的频率不大于 ,而 的深度不小于 ,所以把低频字符放到更深处不会增加成本。同理可把 换到另一个兄弟位置。于是存在一棵最优树,让 成为最深处的兄弟。
现在把 收缩成频率为 的复合字符 。若缩小后的树不是剩余字母表上的最优树,就能换成更优的小树,再把 展开为 ,从而得到比原最优树更好的编码,产生矛盾。这证明了最优子结构。
两个容易混淆的细节
- 左右孩子可以互换。具体 0/1 串会变化,但每个字符的码长和总成本不变。
- 频率相同会产生多棵不同的最优树。霍夫曼编码不保证输出唯一,只保证成本最优。
使用二叉最小堆时,建立堆是 , 轮合并各做常数次 堆操作,总时间为 ,空间为 。
6
关于霍夫曼树,下列哪些说法正确?
7
频率为 5 和 9 的两个最低频节点第一次合并后,新节点频率是 ____。
拟阵:什么时候“按权重排序,能加就加”必然正确
许多贪心问题都能写成:从有限集合 中选一个满足独立性约束的子集,并让总权重最大。拟阵给出了一组足以保证权重贪心正确的结构条件。
一个拟阵写作 ,其中 是独立集族,并满足:
- 是有限集合, 非空;
- 遗传性:若 且 ,则 ;
- 交换性质:若 且 ,则存在 ,使 。
遗传性保证“删掉元素不会突然违规”。交换性质更强:一个较小的独立集总能从较大的独立集中吸收至少一个元素,而不失去独立性。
图拟阵的直觉
对无向图,把边集作为 ,把“不含环的边集”作为独立集。森林删边仍是森林,所以有遗传性。若森林 的边比森林 多, 的连通分量就更少;总能在 中找到一条边,连接 的两个不同分量,把它加入 不会成环。这就是交换性质。
通用权重贪心
txt
WEIGHTED-MATROID-GREEDY(S, I, w)
A = 空集
按权重从大到小排列 S
for x in S
if A ∪ {x} 属于 I
A = A ∪ {x}
return A证明仍然是交换。设 是当前最重且可加入的元素,取一个不含 的最优独立集 。交换性质允许从 中移除某个元素 并加入 ;又因为 ,新集合权重不差,所以存在一个包含 的最优解。
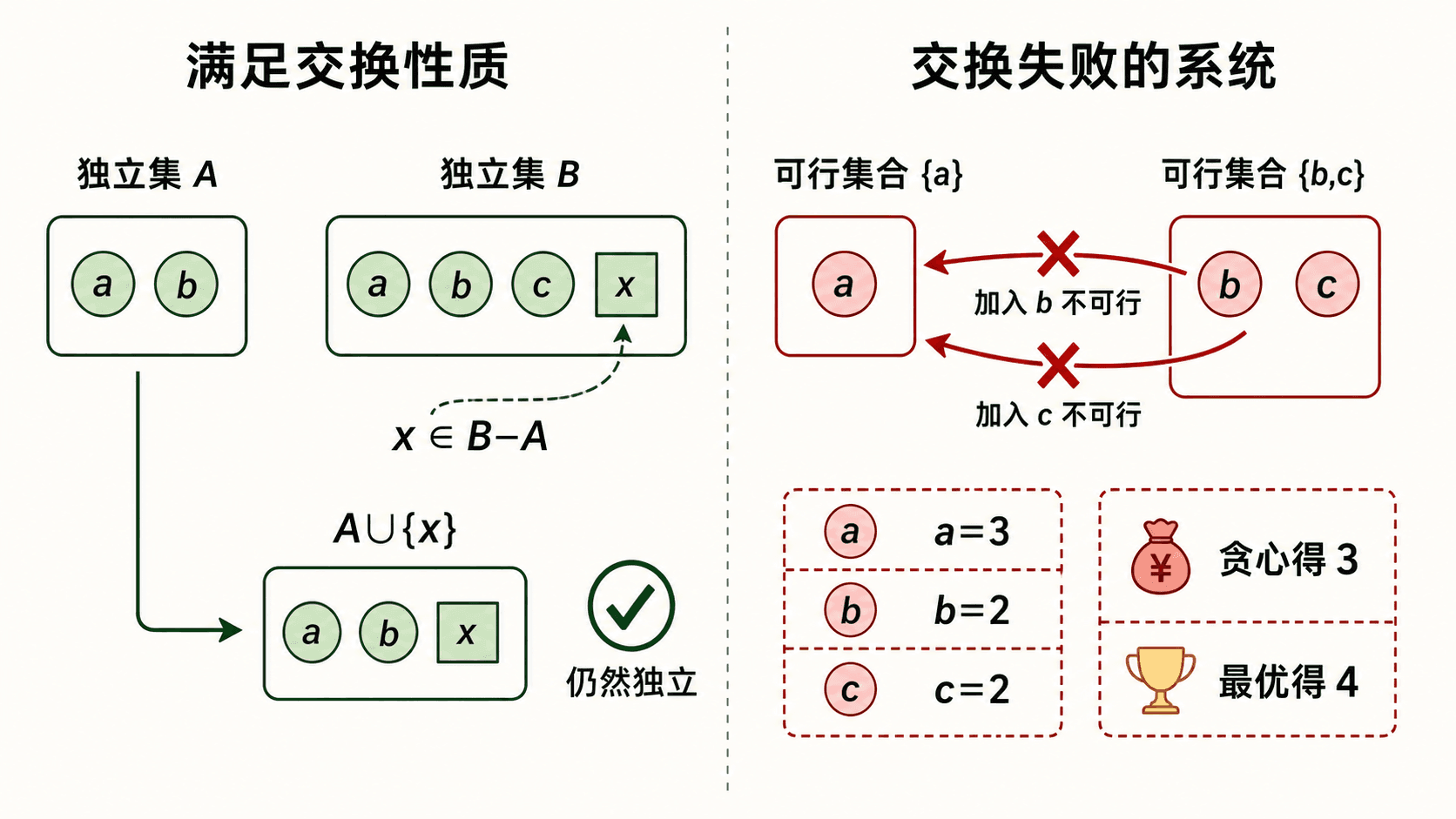
没有交换性质时,权重贪心怎样失败
考虑独立集族:
它有遗传性,但没有交换性质: 比 小,却无法从后者拿一个元素加入前者。令 ,。按权重排序会先选 ,之后不能再加任何元素,得到 3;真正最优的 权重为 4。
真实执行输出为:
console
non-matroid greedy: a=3; optimum: bc=4拟阵是贪心正确的一类充分结构,不是所有贪心问题的统一外壳。活动选择和霍夫曼编码可以直接用各自的交换论证,无需强行改写成拟阵。
极大不等于最大
极大独立集表示“已经无法再添加元素”,最大独立集表示“基数达到全局最大”。在拟阵中,所有极大独立集的基数相同;在一般独立系统中,这件事可能不成立。最大权独立集还要进一步比较权重。
8
只要一个可行集合族满足遗传性,按权重从大到小、能加就加一定最优。
9
无向图中,不含环的边集为什么满足遗传性?
单位时间任务调度:把罚金留给最值得按时完成的任务
现在有 个任务,每个任务耗时 1。任务 的截止期为整数 ;若未在截止期前完成,就付出罚金 。最小化逾期罚金,等价于最大化按时完成任务的罚金总和,因为所有任务罚金之和是常数。
可行性的容量条件
对任务集合 ,令 表示截止期不超过 的任务数量。 能全部按时完成,当且仅当:
原因很直接:前 个时间槽最多容纳 个任务。反过来,只要每个前缀都不超容量,把任务按截止期升序排列就不会卡住。
这些可按时完成的任务集合构成拟阵,因此可以按罚金从大到小尝试加入。工程上更直观的实现是:处理一个任务时,把它安排到不晚于截止期的最晚空槽。这样为截止期更早的后续任务尽量保留前面的槽位。
示例
真实执行得到:
console
task early: a4,a2,a3,a1,a7
task late: a5,a6; penalty=50输出中的按时任务顺序对应具体时间槽。 逾期,总罚金为 。
为什么要放到最晚空槽
若任务截止期为 4,把它放在槽 1 虽然暂时可行,却可能挡住一个截止期为 1 的任务。放在槽 4 不会降低当前任务的可行性,同时保留了更紧张的早期容量。这是另一种交换视角:把截止期较晚的任务向后移动,不会让它迟到。
10
某任务集合中有 3 个任务的截止期都不超过 2。关于该集合,下列结论正确的是?
设计、证明与调试一套贪心算法
面对一个新的优化问题,可以按下面的顺序工作。
先写清目标与约束
“最多”“最少”“最大价值”必须明确。活动选择最大化数量与带权活动选择最大化价值,看起来只差一列数据,算法却完全不同。
再提出局部规则
把规则写成可执行的比较键,例如“结束时间升序”“单位价值降序”“频率最小的两个节点”,不要写“选最合适的”。同时说明平局如何处理。
用两条路线夹击它
- 证明路线:交换论证、领先一步论证、割性质或拟阵交换性质。
- 反例路线:小规模枚举、构造离散空隙、让第一步阻断两个后续元素。
只有证明闭合,规则才是算法;找到一个反例,规则就必须放弃或补充条件。
最后实现数据结构
证明决定“选什么”,数据结构决定“怎样快速找到它”。活动选择用排序加扫描;霍夫曼编码用最小堆;任务槽位可以用并查集加速查找最晚空槽。不要先沉迷实现,再回头猜正确性。
11
遇到一个新的贪心猜想,哪些做法有助于判断它是否成立?
综合练习与解析
练习一:反向活动选择
把活动按开始时间降序排列,每次选择开始时间最晚且与已选活动兼容的活动。证明该算法也能得到最多活动。
练习二:手工构造霍夫曼树
对频率 A:7, B:8, C:10, D:15, E:20, F:40 写出合并序列,并计算加权路径长度。
练习三:找出交换性质失败
设可行集合族为 。给出一对独立集,说明它不是拟阵。
练习四:判断算法边界
请分别为下列问题选择“直接贪心”或“不能仅凭该规则贪心”,并说明理由。
- 活动无权重,最大化兼容活动数量,按结束时间最早选择。
- 活动带价值,最大化总价值,仍按结束时间最早选择。
- 分数背包,按价值密度降序装入。
- 0/1 背包,按价值密度降序装入。
练习五:证明清单
你提出了“每次选代价最小的候选”这一规则。提交算法前,至少要回答哪三个问题?
贪心算法最可靠的工作习惯是:先让直觉提出规则,再让交换论证和反例共同审查它。代码只是证明通过后的最后一步。