动态规划:把重复的选择变成一张可回溯的表
一家金属加工店收到一根长度为 4 的钢条。整根卖出值 9 元;切成 1+3 值 9 元;切成 2+2 却能卖 10 元。只看眼前的一刀,很难保证最后最好。若把长度换成 40,逐一枚举所有切法又会迅速失控。
动态规划处理的正是这类问题:一个决策会留下规模更小、结构相同的后续问题,而许多决策又会抵达同一个后续状态。我们先给这些状态准确命名,再把已经求过的答案保存起来。最后得到的不只是一个数,还可以沿着记录的选择还原具体方案。
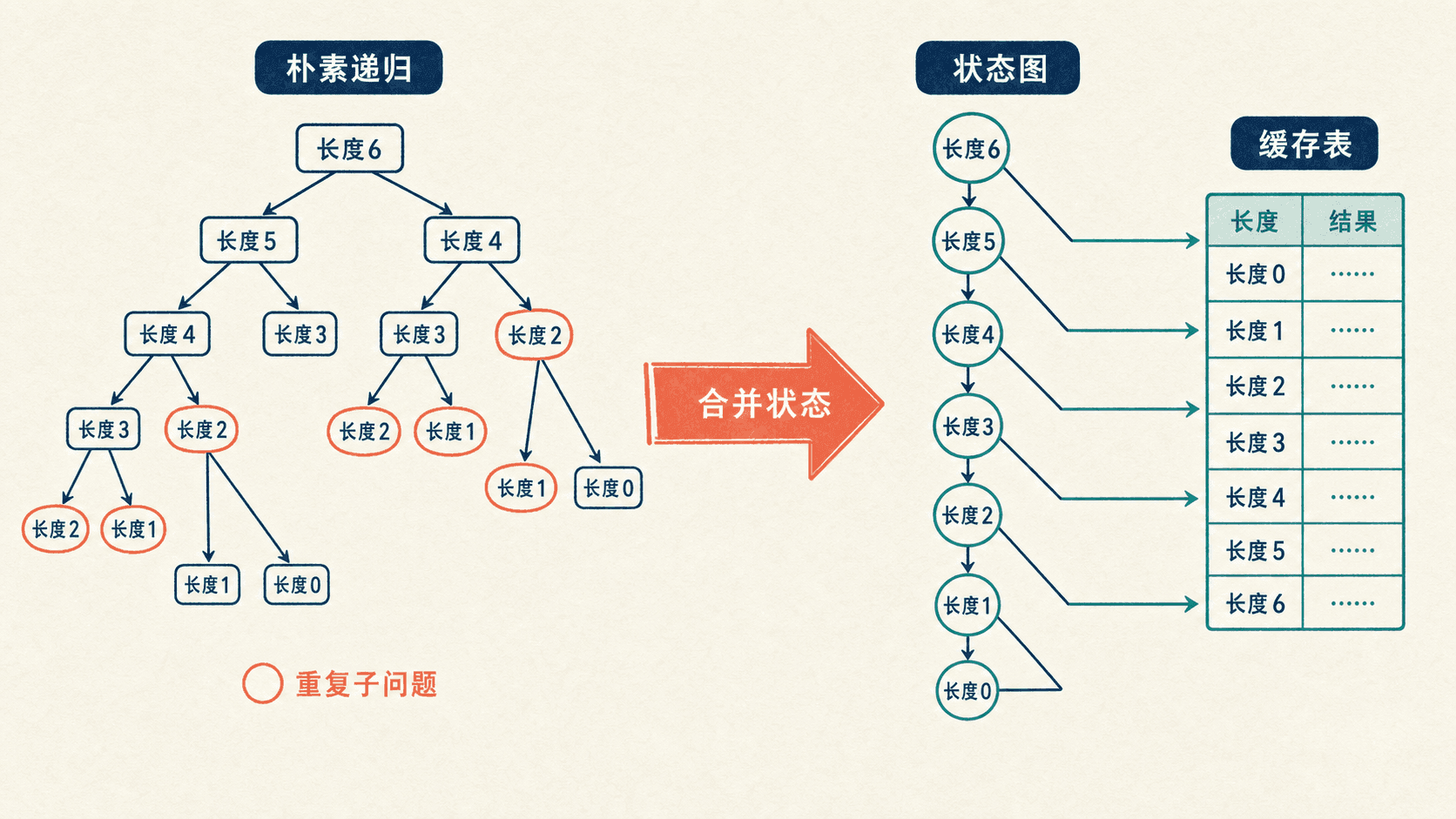
这一章围绕三类模型展开:钢条切割是一维最优化,矩阵链乘法是区间动态规划,最长公共子序列是二维序列动态规划。它们的表格形状不同,设计过程却共享同一套逻辑。
先判断问题是否适合动态规划
动态规划和分治都会把大问题拆成小问题。区别在于子问题之间的关系。归并排序的左右两半互不重叠,分别求解即可;钢条切割的许多递归分支却会反复询问“长度为 2 的钢条最多值多少”。若不保存答案,同一个状态会在递归树中出现多次。
最优子结构
最优子结构表示:一个整体最优方案中,做完某个选择后留下的子方案,也必须是对应子问题的最优方案。
以钢条切割为例。假设最优方案先切下长度 i,剩余长度为 n-i。若剩余部分采用的切法不是长度 n-i 的最大收益方案,我们就能用更高收益的切法替换它,使总收益继续上升。这与原方案已经最优矛盾。
这种“假设子方案不最优,再用更优子方案替换”的论证叫剪切—粘贴。写出转移式之前,最好先完成这段论证;否则一个看似合理的局部转移,可能根本拼不成合法的整体方案。
重叠子问题
最优子结构说明“可以拆”,重叠子问题说明“值得存”。若不同递归分支会抵达相同状态,状态总数通常远少于递归树节点数。动态规划让每个不同状态只被完整求解一次。
递归式不等于动态规划。若所有子问题互不相同,缓存几乎没有复用价值;若子问题的最优方案不能合法拼成整体方案,保存再多结果也得不到正确转移。
用状态图检查依赖
可以把每个子问题看成一个顶点,把“状态 A 需要状态 B”画成一条从 A 指向 B 的边。适合动态规划的依赖图应当没有环,并且多个顶点可能指向同一个更小状态。备忘录法从目标状态沿边向下访问,自底向上法按依赖的逆序填表。
1
下列哪些现象支持使用动态规划?
用四步把想法写成算法
动态规划最难的地方通常不是填表,而是决定表格中的一格究竟表示什么。下面四步应按顺序完成。
定义状态
先写一句完整的话解释状态。例如:
txt
r[j] = 长度恰好为 j 的钢条能够取得的最大收益“长度恰好为 j”给出子问题边界,“最大收益”给出返回值。若一句话中还藏着未说明的条件,状态往往定义得太粗;若加入了以后不会影响决策的信息,状态又可能过细。
写出转移和边界
列出当前状态的最后一个选择或第一个选择,再写出每种选择留下的子问题。转移必须覆盖所有合法方案,又不能重复引入不合法方案。边界状态则负责让递推停止,例如空钢条的收益为 0。
安排计算顺序
求当前状态之前,它依赖的状态必须已经有值。一维前缀状态通常从小到大;区间状态通常按区间长度从短到长;二维前缀状态通常从左上向右下。
记录选择并重构
最优值只回答“最多多少”或“最少多少”。若还要输出切法、括号或序列,就要在更新最优值时同步记录产生该值的选择。之后从目标状态沿选择反向移动,直到边界。
并列最优很常见。选择表只记录一个候选,就会重构出一个最优方案;若题目要求所有最优方案,则必须保存所有并列选择,并在回溯阶段分叉。
2
若题目既要最小代价,又要输出具体决策序列,四步中哪一项不能省略?
备忘录与自底向上只是两种求值顺序
同一个递推式通常有两种实现。它们计算的是同一组数学状态,区别在于谁先被访问。
自顶向下备忘录
备忘录法保留自然递归。函数进入一个状态时先查表:若已有答案便直接返回;否则递归求依赖,保存后再返回。
js
function solve(state) {
if (memo.has(state)) return memo.get(state);
const answer = combine(smallerStates(state));
memo.set(state, answer);
return answer;
}它只计算从目标状态真正可达的子问题,适合状态图稀疏、边界分支较多的情况。代价是递归调用开销和调用栈深度。
自底向上填表
自底向上法从边界开始,按状态依赖的拓扑顺序逐格填表。它没有递归栈,内存访问也常更连续。若最终所有状态都必须计算,自底向上通常更直接。
两种实现的时间复杂度都可以用同一个式子估计:
3
同一递推式改写成备忘录后,一定比自底向上更快。
钢条切割:从指数枚举到平方时间
设 p[i] 是长度为 i 的钢条售价,r[j] 是长度为 j 时的最大收益。把一个方案统一描述为“先取长度 i 的第一段,再最优处理剩余长度 j-i”。当 i=j 时,剩余为 0,正好表示不切。
边界与转移为:
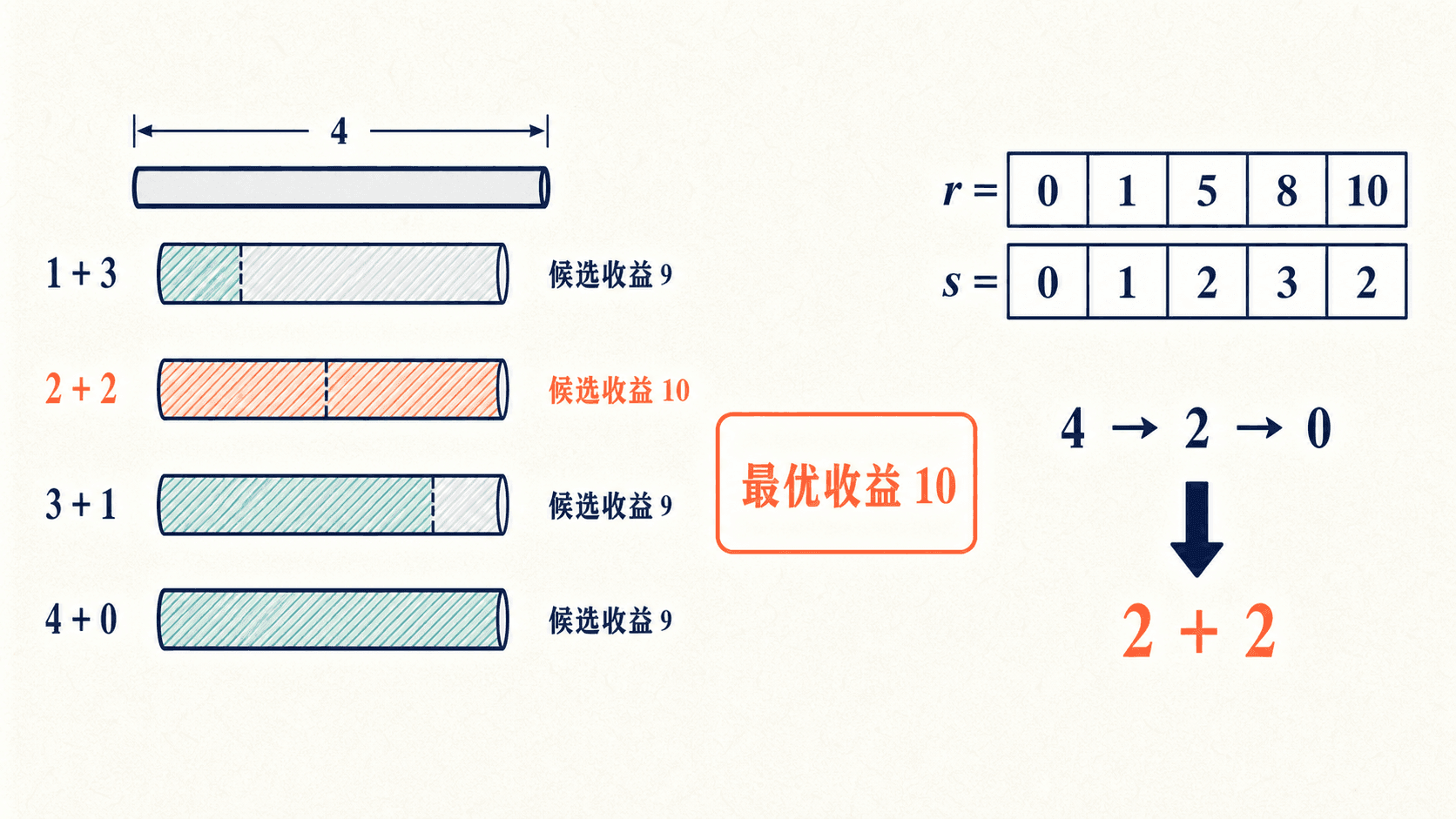
手算长度 4
价格表前四项是 p=[1,5,8,9]。候选分别为:
因此 r[4]=10,第一段选择为 2。继续查看 r[2] 的第一段仍为 2,得到切法 2+2。
自底向上实现
js
function cutRod(prices, n) {
const revenue = Array(n + 1).fill(0);
const first = Array(n + 1).fill(0);
for (let length = 1; length <= n; length += 1) {
let
在 Node.js v25.2.1 中用价格表 [1,5,8,9,10,17,17,20,24,30] 运行,实际输出为:
console
revenue = [0,1,5,8,10,13,17,18,22,25,30]
first = [0,1,2,3,2,2,6,1,2,3,10]
plan for length 10 = [10]长度 10 的最优收益是 30,其中一个最优方案是不切。算法共有 n 个状态,每个状态枚举至多 n 个第一段长度,所以时间复杂度为 O(n^2),两个数组与回溯结果占 O(n) 空间。
4
对价格 p[1..4]=[1,5,8,9],长度 4 的最大收益是 ____。
矩阵链乘法:状态是一个区间
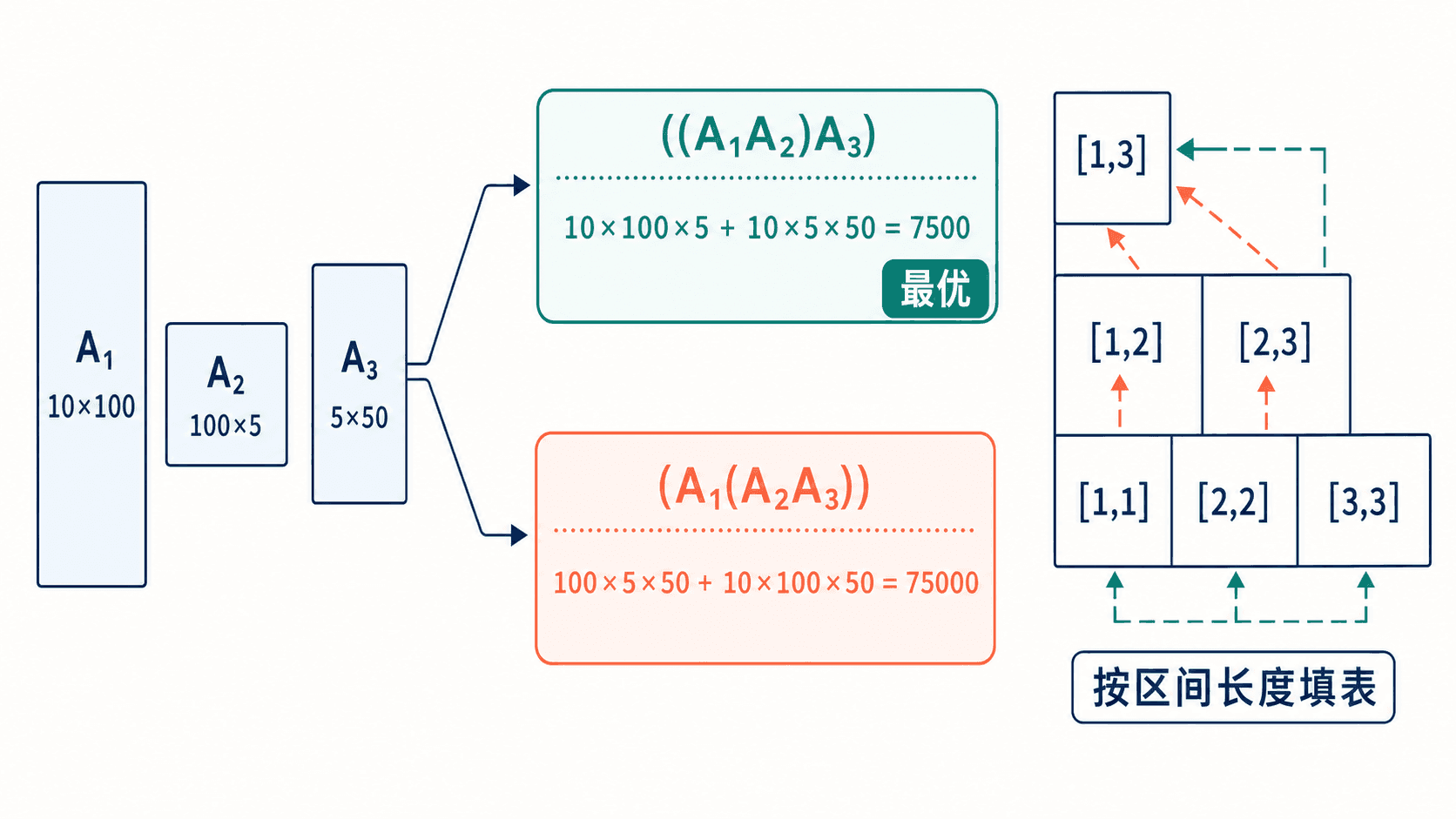
矩阵乘法满足结合律,改变括号不会改变结果矩阵,但会改变标量乘法次数。若三个矩阵维度依次为 10×100、100×5、5×50:
只是改变括号,工作量就相差 10 倍。
状态与转移
设矩阵 A_i 的维度为 p[i-1]×p[i]。定义:
txt
m[i][j] = 计算连续矩阵 A_i...A_j 所需的最少标量乘法次数当 i=j 时只有一个矩阵,不需要乘法,所以 m[i][i]=0。若最后一次乘法在 k 处分开,左侧代价是 m[i][k],右侧代价是 m[k+1][j],合并两个结果矩阵还需 p[i-1]p[k]p[j] 次标量乘法:
为什么按区间长度填表
状态 [i,j] 依赖两个更短区间 [i,k] 与 [k+1,j]。因此先填长度 1 的主对角线,再填长度 2、3,直到长度 n。简单地从第一行扫到最后一行,不能保证依赖已经完成。
保存最优分割点 s[i][j]=k 后,可以递归打印左右括号。对维度数组 [30,35,15,5,10,20,25],真实运行得到:
console
minimum scalar multiplications = 15125
parenthesization = ((A1(A2A3))((A4A5)A6))区间共有 O(n^2) 个,每格最多枚举 O(n) 个分割点,所以时间复杂度为 O(n^3),代价表和选择表占 O(n^2) 空间。
5
矩阵链状态 m[i][j] 为什么应按区间长度从短到长计算?
最长公共子序列:在二维表中保留相对顺序
子序列从原序列中删除若干元素得到,剩余元素的相对顺序不变,但不要求连续。例如 BCBA 是 ABCBDAB 的子序列。公共子序列同时出现在两个序列中,最长公共子序列(LCS)要求长度最大,答案可能不唯一。
令:
txt
c[i][j] = X 的前 i 个字符与 Y 的前 j 个字符的 LCS 长度若两个前缀的末字符相同,可以把该字符接到更短前缀的 LCS 后;若末字符不同,当前 LCS 至少会跳过其中一个末字符:
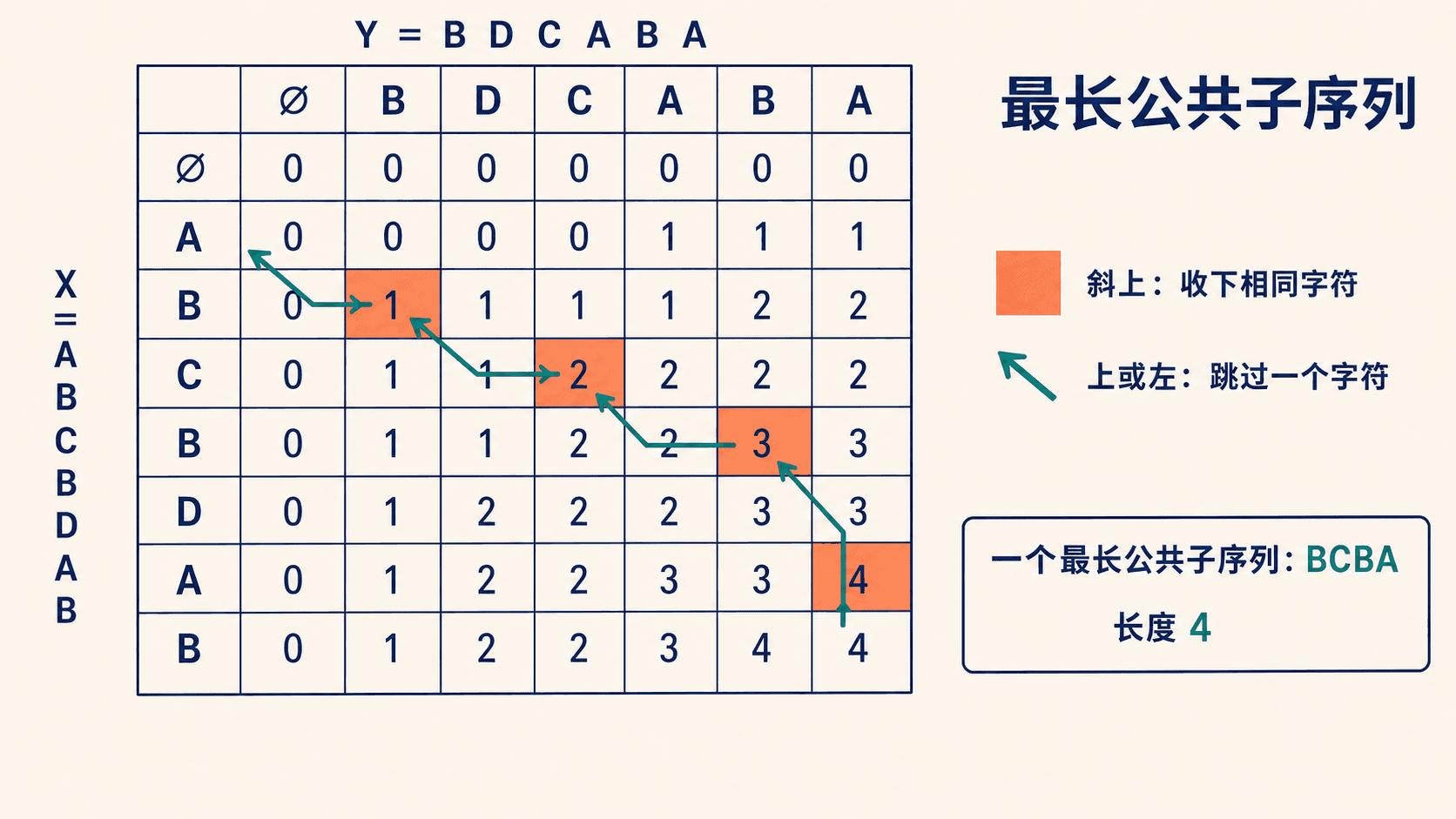
从长度表回溯序列
从右下角开始:
- 若
x_i=y_j,该字符属于当前答案,斜向左上移动。 - 若不相等,向数值较大的上方或左方移动。
- 若两边相等,任选一边都能得到一个最长解;不同选择可能产生不同 LCS。
js
function lcs(x, y) {
const dp = Array.from(
{ length: x.length + 1 },
() => Array(y.length + 1).fill(0),
);
for (let i = 1; i <= x.length; i += 1
在 Node.js v25.2.1 中运行 lcs("ABCBDAB", "BDCABA"),实际输出为:
console
{ length: 4, sequence: 'BCBA' }共有 m×n 个非边界状态,每格只做常数次比较,所以时间和完整表空间都是 O(mn)。
6
最长公共子序列中的字符必须在原序列中连续出现。
空间压缩与常见误区
完整表格有两个作用:提供以后计算所需的旧状态,以及保留回溯所需的信息。空间压缩只能删除以后不再需要的部分。
只求 LCS 长度
计算 LCS 的第 i 行时只依赖第 i-1 行和当前行左侧,因此只求长度时可以保留两行,把空间从 O(mn) 降到 O(n)。若让较短序列作为列,还能写成 O(min(m,n))。
但两行数组无法直接保留完整回溯路径。要输出具体 LCS,需要保留方向表、重新计算部分状态,或使用更精细的分治重构。
把状态含义写得含糊
“dp[i] 是前面的最优值”不够准确。前面是否包含 i?是长度恰好为 i,还是长度不超过 i?不同定义会改变边界与转移。实现前应把状态写成能独立核对的完整句子。
忘记把不做操作纳入候选
钢条切割允许不切,所以 i=j 必须成为候选。若只枚举真正的切口 1..j-1,就会漏掉整根售价最高的情况。
更新了最优值却没更新选择
代价表与选择表必须在同一个条件分支内更新。否则数值可能正确,回溯却沿着旧选择输出错误方案。
7
把 LCS 完整二维表压成两行后,哪些说法正确?
一张可执行的解题检查表
面对新题时,可以按下面的顺序写草稿。任何一步说不清,都先不要急着写循环。
明确输出是最优值、方案数量、可行性,还是还要给出具体方案。输出不同,状态保存的信息也不同。
写出一个状态的完整语义,并标明每个下标的范围。用两个最小输入检查这句话是否唯一确定了一个子问题。
枚举当前状态的第一步或最后一步选择,说明每个选择留下哪些更小状态,并用替换论证检查最优子结构。
写出边界和转移,检查所有合法方案都被覆盖,非法方案没有混入;再画依赖方向确定填表顺序。
8
分析一个动态规划算法时间复杂度时,最稳妥的起点是什么?
综合练习与解析
练习一:带切割成本的钢条
每发生一次真正切割要支付成本 c。请修改钢条切割转移,注意不切时不能扣费。
练习二:矩阵链的填表顺序
给定维度数组 [10,100,5,50],分别计算两种括号方式的代价,并说明最优分割点。
练习三:LCS 的并列回溯
对 X=ABCBDAB、Y=BDCABA,程序返回 BCBA。这是否说明 BCBA 是唯一答案?
练习四:识别问题边界
判断下面说法:快速排序有递归结构,所以应使用动态规划保存每个子数组的排序结果。
练习五:自行设计状态
机器人位于网格左上角,每次只能向右或向下,部分格子不可进入。请定义状态并写出方案数转移。
9
下列哪些设计能正确支持具体最优方案的重构?