应用层:从进程通信到内容分发
当你在地址栏输入一个网址,屏幕上的一次点击会迅速展开成一串协作:域名先被解析成地址,客户端选择合适的传输服务,HTTP 请求穿过套接字到达服务器,缓存判断资源是否仍然新鲜,页面中的视频又可能从更近的 CDN 节点分片下载。应用层的任务,就是为这些“有意义的数据交换”规定消息格式、交互顺序和处理动作。
这一层最贴近产品功能,却并不等于“界面层”。它运行在网络边缘的端系统中,利用传输层提供的通信能力,把网页、邮件、域名、文件块和视频分片组织成可互操作的协议。下面从应用设计的共同原则出发,逐步走进 HTTP、电子邮件、DNS、P2P、流媒体和套接字编程。
网络应用的设计原则
网络应用的程序通常运行在手机、电脑、服务器等端系统上,而不是运行在沿途的路由器和交换机中。浏览器和 Web 服务端是两个不同的程序;视频客户端与内容平台的服务端也是两个不同的程序。它们各自在端系统中执行,通过网络交换消息。
这种“把创新留在边缘”的安排很重要:开发者只需更新客户端或服务器,就能部署新的应用逻辑,不必先改造互联网中的每一台转发设备。
应用架构:谁为谁服务
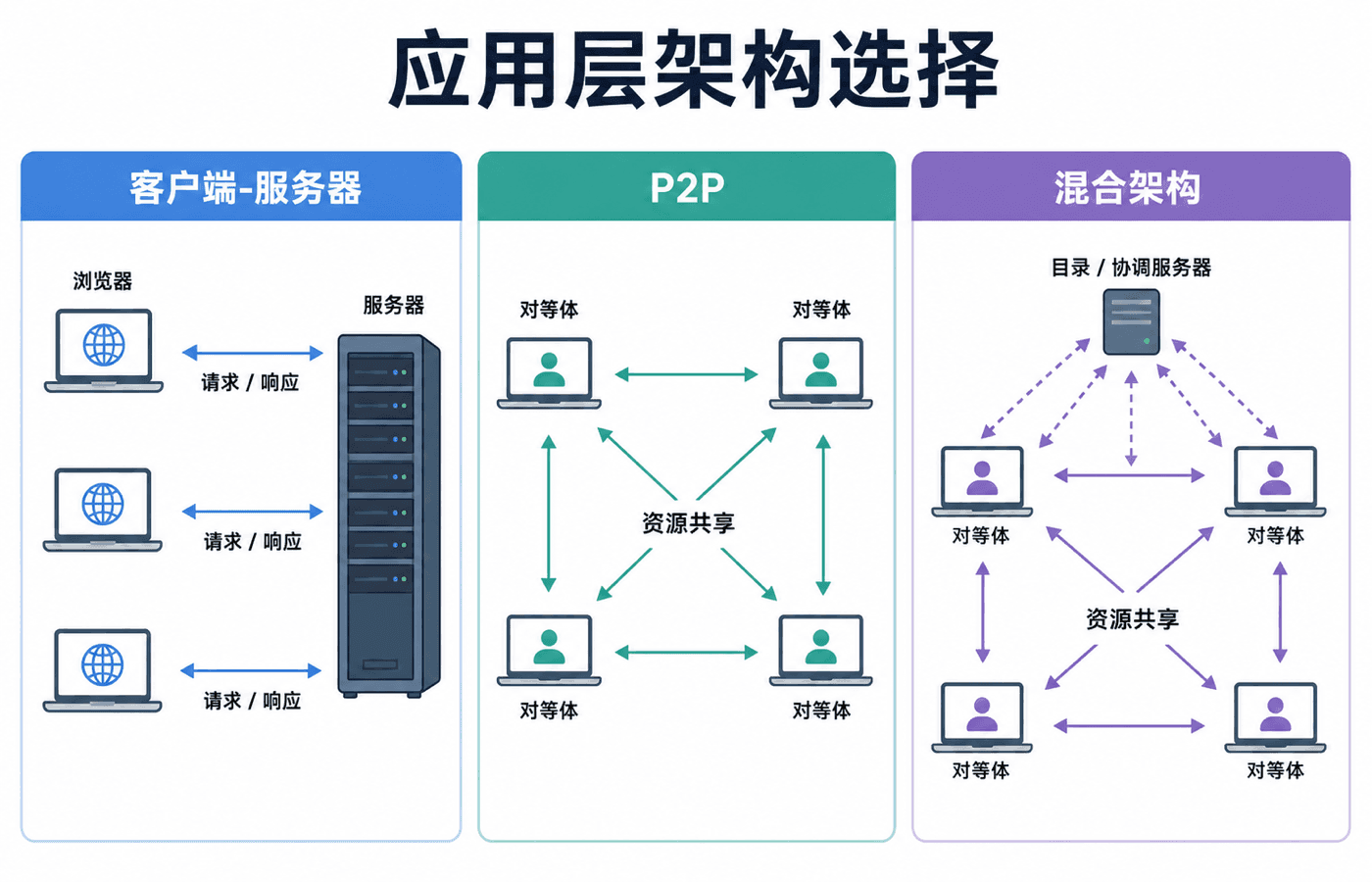
应用架构描述程序如何分布在不同端系统上,它与由路由器、链路和协议栈组成的网络架构不是一回事。常见的组织方式有两种。
大型客户端-服务器系统很少只靠一台物理主机。它通常把大量主机组织成数据中心,对外呈现为一个服务,并用负载均衡、复制和故障转移维持可用性。P2P 系统也不意味着完全没有中心节点:实际产品常用服务器完成登录、发现和协调,让大数据传输尽可能发生在对等体之间。
真正通信的是进程
程序是静态的代码,进程是正在运行的程序实例。同一台主机上的进程可以使用操作系统提供的进程间通信机制;不同主机上的进程,则通过网络发送和接收消息。
在一段具体会话中,先发起联系的一方称为客户端进程,等待联系的一方称为服务器进程。这个角色按“会话”判断,而不是按“机器”永久固定。P2P 节点下载某个分块时是客户端,随后向别人上传该分块时又成为服务器。
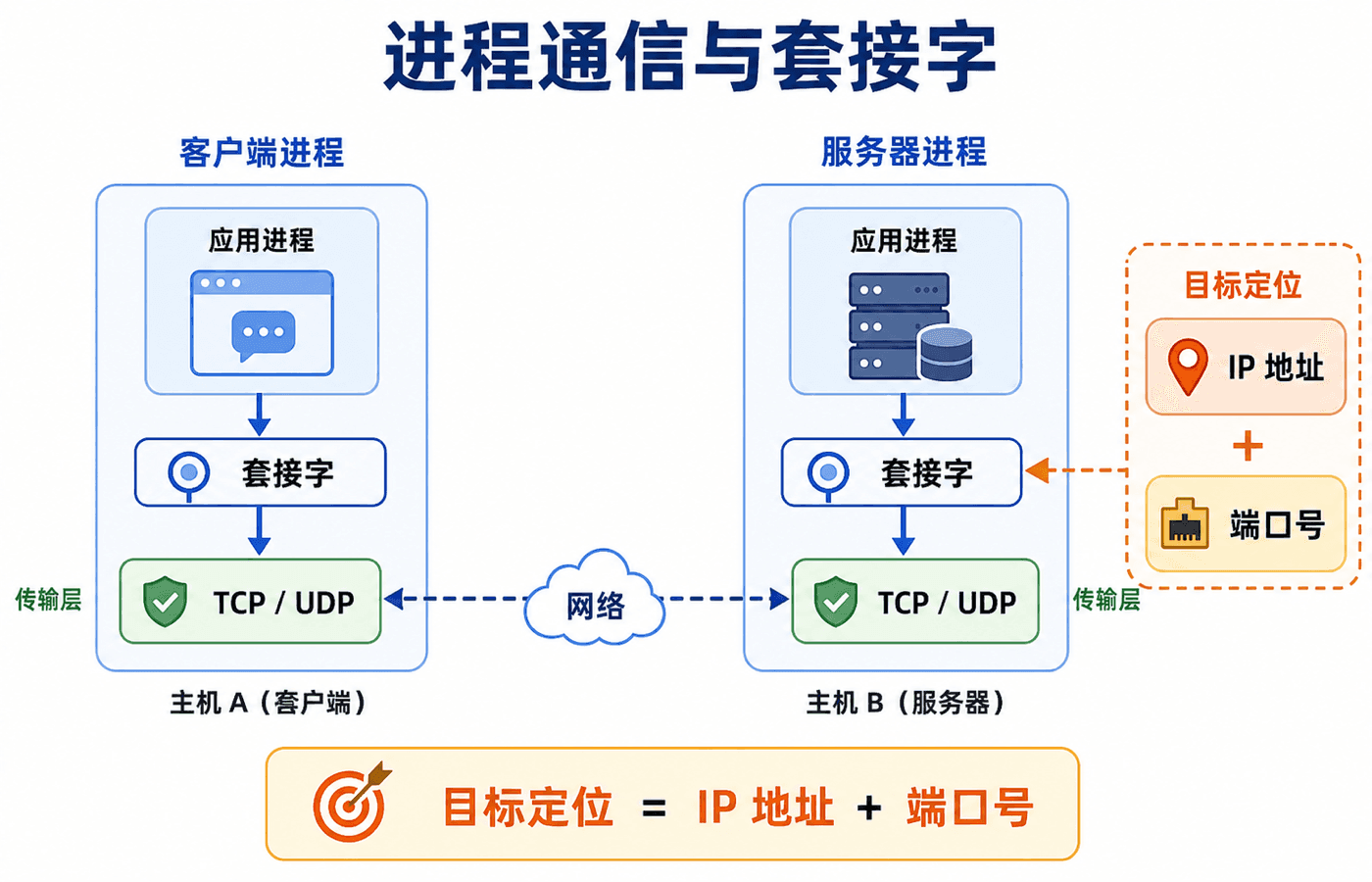
进程通过套接字(socket)与传输层交接数据。应用开发者控制套接字之上的消息内容和处理逻辑,也能选择传输协议、调整少量参数;可靠传输、拥塞控制和实际分段等工作则由操作系统中的传输层实现。
要把消息送到正确进程,只有目标主机的 IP 地址还不够,还必须给出端口号。IP 地址定位主机,端口号定位该主机上的接收进程。203.0.113.8:443 因而表达了“目标主机 + 目标服务入口”。
应用如何挑选传输服务
设计者通常从四个维度评估传输服务:
- 可靠性:文件、邮件和交易记录不能容忍缺字节;实时语音可以容忍少量丢失。
- 吞吐量:视频需要持续达到最低码率;弹性应用则可根据可用带宽快慢完成。
- 时延:互动游戏、语音和远程控制关心低时延;离线下载更关心完整性。
- 安全性:机密性、完整性和身份认证往往由 TLS 等安全协议补充。
TCP 提供面向连接、可靠、有序的字节流,并带有流量控制和拥塞控制,但不承诺固定时延或最低吞吐量。UDP 不建立连接,不保证到达和顺序,应用却能更直接地控制发送时机、报文边界与重试策略。现代应用还可能使用基于 UDP 实现的 QUIC,在应用可演进的空间中结合可靠流、加密和快速建连。
应用层协议究竟规定什么
一个可互操作的应用层协议至少需要说明:
- 有哪些消息类型,例如请求、响应、查询和回答;
- 每种消息由哪些字段组成,字段如何分隔或编码;
- 字段的含义,例如方法、状态码和资源标识代表什么;
- 发送或接收某类消息后应采取什么动作;
- 超时、无效输入和服务失败如何处理。
开放协议允许不同实现互相通信;私有协议则由单一组织控制。无论是否公开,只要双方要协作,就必须在消息语法和行为上形成一致约定。
1
在一段 P2P 文件传输会话中,应该如何区分客户端进程与服务器进程?
Web 与 HTTP
Web 页面通常由一个基础 HTML 文档和若干被引用对象组成,例如图片、样式表、脚本、字体或视频片段。每个对象由 URL 标识。浏览器实现 HTTP 客户端,Web 服务实现 HTTP 服务器,两者通过 HTTP 请求与响应交换对象。
HTTP 把传输可靠性委托给下层。经典 HTTP/1.1 和 HTTP/2 常运行在 TCP 上;HTTPS 在其间加入 TLS;HTTP/3 则运行在 QUIC 之上。无论底层如何变化,应用仍围绕方法、资源、头字段、状态码和表示进行交互。
无状态,不等于没有登录态
HTTP 的核心语义是无状态的:服务器不必记住客户端此前的每一次请求,便能解释当前请求。这有利于扩展和故障转移,因为下一次请求可以交给另一个服务实例。
网站仍可借助 Cookie 和后端会话保存状态。服务器在响应中用 Set-Cookie 交给浏览器一个标识,浏览器以后在匹配域名和路径的请求中带上 Cookie。这个标识再与服务端数据库中的账户或购物车状态关联。Cookie 还应合理设置 Secure、HttpOnly、SameSite、有效期和作用域,以降低泄露或跨站滥用风险。
非持续连接与持续连接
如果每传一个对象就新建一条 TCP 连接,称为非持续连接。完成握手需要约一个往返时间,发送请求到收到响应首字节还需要约一个往返时间,再加对象传输时间;页面对象很多时,重复建连的成本非常明显。
持续连接允许多个请求和响应复用同一条连接,减少握手、慢启动和系统资源开销。HTTP/1.1 默认采用持续连接,但一个连接上的响应仍可能发生排队。HTTP/2 进一步把消息拆成帧,让多个流在一条连接上交错传输,并对头字段压缩;它缓解了应用层的队头阻塞,不过 TCP 层丢失一个字节时,后续字节仍要等待恢复。HTTP/3 借助 QUIC 的独立流减少了这种跨流影响。
请求报文与响应报文
一个典型请求由请求行、若干头字段、空行和可选正文组成:
http
GET /courses/network/chapter-2 HTTP/1.1
Host: learn.example.edu
Accept: text/html
If-None-Match: "lesson-v7"GET 获取资源,HEAD 只取与 GET 类似的响应头而不取正文,POST 常提交由服务端处理的数据,PUT 常用于把给定表示写到指定资源位置。方法的真正语义由协议约定和服务端实现共同落实,不能只看名字猜测。
响应以状态行开头:
http
HTTP/1.1 304 Not Modified
Date: Mon, 13 Jul 2026 09:00:00 GMT
ETag: "lesson-v7"
Cache-Control: max-age=120状态码按首位分组:2xx 表示成功,3xx 表示重定向或缓存协商,4xx 表示客户端请求存在问题,5xx 表示服务器未能完成有效请求。常见的 200、301、304、400、404 与 505 只表达处理结果,不应被当成完整的业务错误说明。
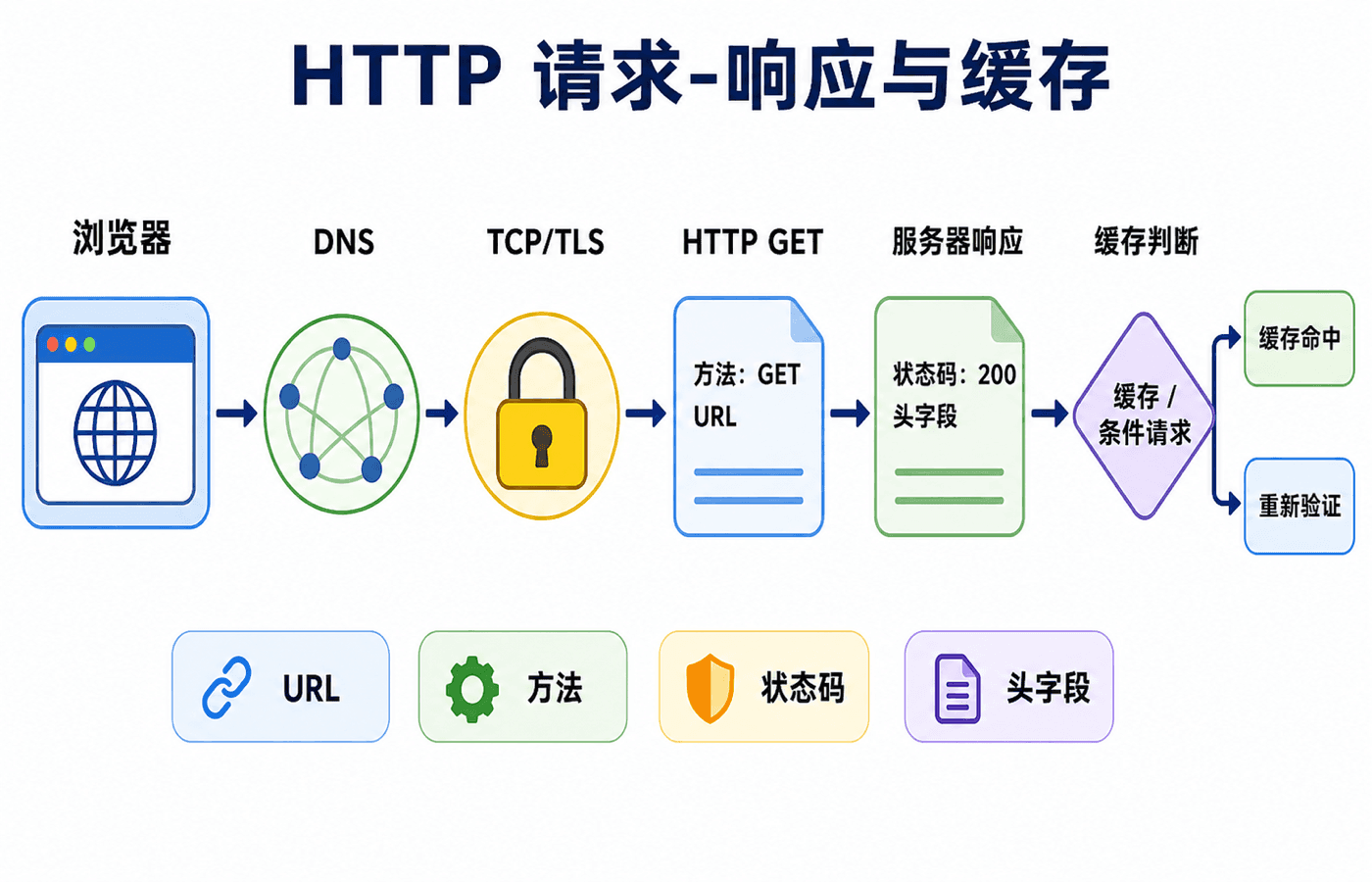
Web 缓存与条件请求
缓存既可以在浏览器内部,也可以部署为组织网络中的代理缓存。命中缓存时,客户端不必再次跨越远端链路获取完整对象,于是用户等待更短、接入链路压力更小、源服务器负载也更低。
缓存不能无限期相信旧副本。Cache-Control: max-age=120 可声明新鲜期;过期后,缓存可用 If-None-Match 携带先前的 ETag 做条件请求。若对象未变化,服务器返回 304 Not Modified,不发送新的表示正文;若对象已变化,则返回 200 OK 和新正文。Last-Modified 与 If-Modified-Since 也能做时间条件验证,但 ETag 更适合表达精确版本。
2
关于 HTTP 缓存验证,下列说法哪些正确?
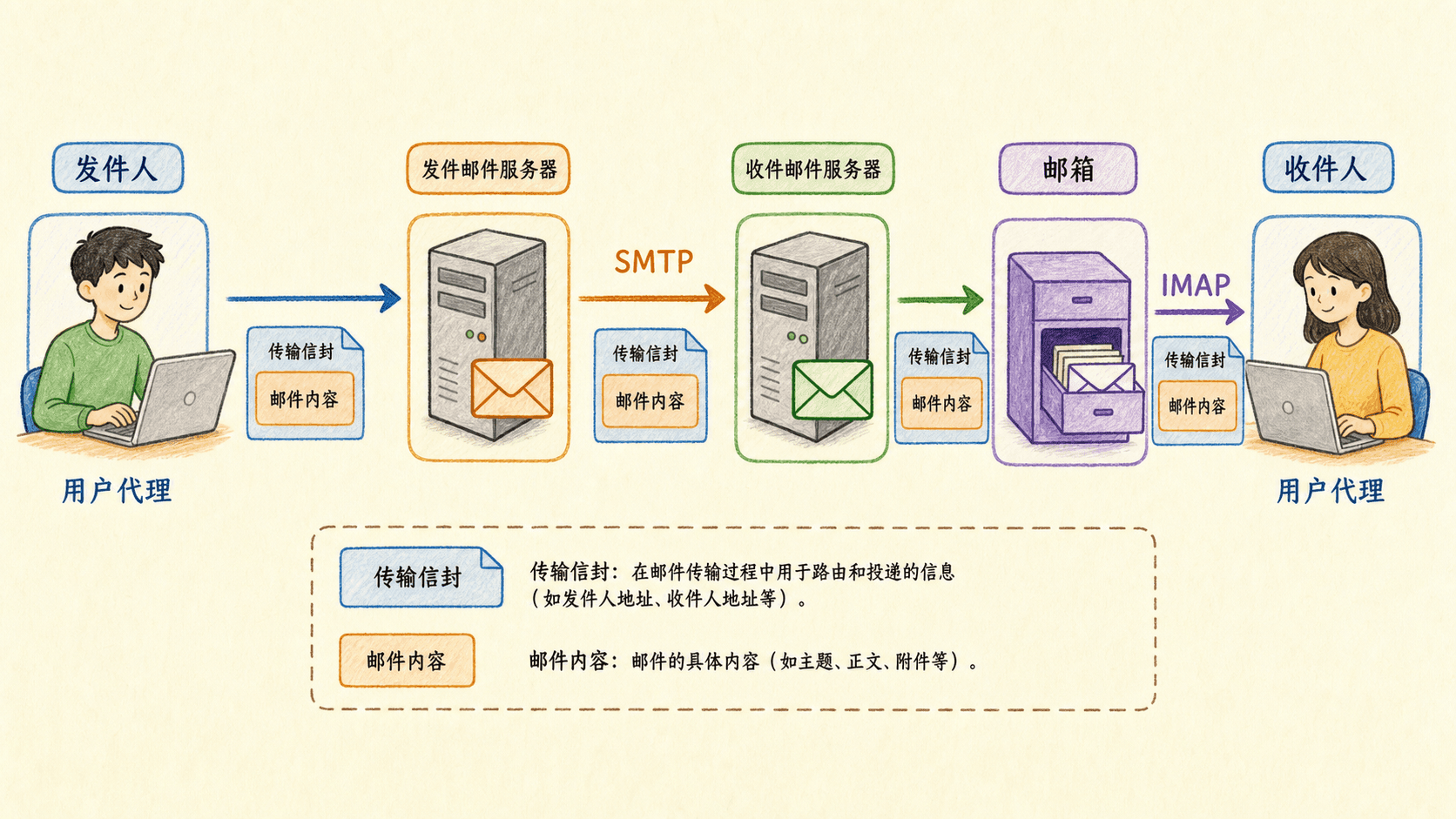
互联网电子邮件
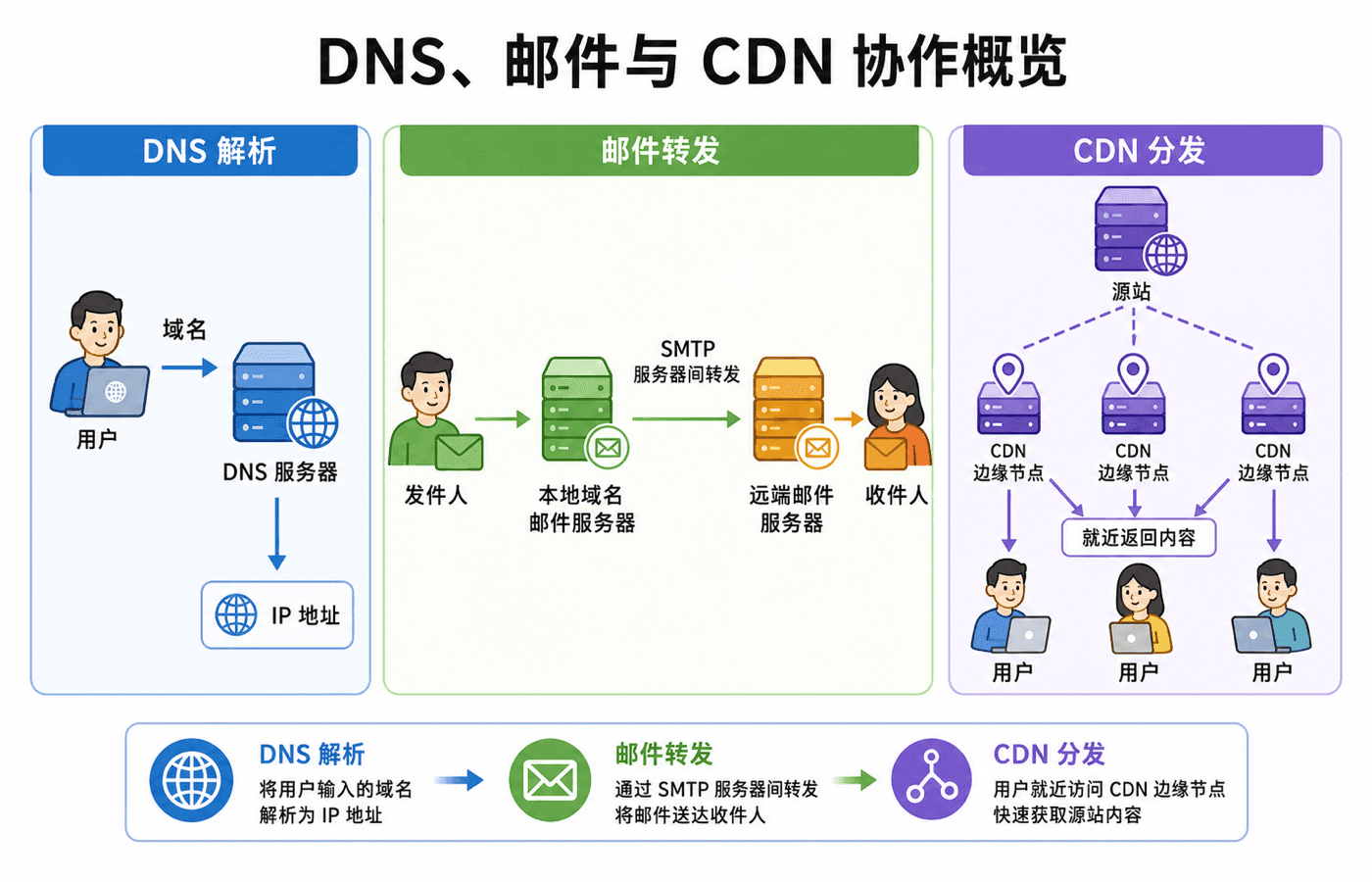
电子邮件系统由三类核心组件组成:用户代理负责撰写和阅读,邮件服务器保存邮箱并维护待发送队列,SMTP 负责在邮件服务器之间传送消息。收件人不在线时,邮件仍能先进入其邮件服务器,稍后再由用户代理访问。
一次典型投递可以这样展开:
- 发件人的用户代理把邮件提交到发件方邮件服务器;
- 发件方服务器查询收件域名的 MX 记录,找到接收邮件的服务器;
- 发件方 SMTP 客户端与接收方 SMTP 服务器建立 TCP 连接;
- 双方完成问候,客户端依次说明发件人、收件人并传送邮件内容;
- 接收服务器把邮件放入收件人的邮箱;
- 收件人通过 Web 邮件或 IMAP 等方式查看邮件。
SMTP 的推送过程
SMTP 使用持续 TCP 连接可靠地传送邮件,服务器间通常直接建立连接,而不是把消息逐站交给一串中间邮件服务器。协议交互以命令和三位数字回复组成,例如 HELO/EHLO、MAIL FROM、RCPT TO、DATA 与 QUIT。一条连接可以连续投递多封邮件,失败的消息进入队列并按策略重试。
SMTP 是“推”协议:发送方把消息推给接收服务器。Web 的 HTTP 常是“拉”协议:客户端主动请求对象。邮件附件和非 ASCII 内容需要通过 MIME 相关头字段声明媒体类型和传输编码,接收端才能正确还原。
邮件正文格式与访问方式
邮件消息由头部、空行和正文构成。From、To、Subject 属于消息自身的头部,和 SMTP 传输过程中的 MAIL FROM、RCPT TO 并不是同一层信息:前者供收件人和客户端展示,后者决定本次传输的信封路径。
邮件到达接收服务器后,用户可以通过三种常见方式访问:
现代邮件系统还会执行垃圾邮件过滤、病毒扫描、身份验证和加密传输。可靠的 TCP 只能保证字节交付,并不能自动证明发件人身份,也不能阻止恶意内容。
3
邮件头中的 From 字段与 SMTP 传输阶段的 MAIL FROM 命令承担完全相同的作用。
DNS:把名字连接到网络
人们更容易记住域名,网络转发却需要 IP 地址。DNS 是由分层服务器和分布式数据库共同实现的应用层系统,负责把主机名解析成地址,也提供主机别名、邮件服务器定位与负载分配等服务。
DNS 提供的服务
- 主机名到地址的转换:A 记录给出 IPv4 地址,AAAA 记录给出 IPv6 地址。
- 主机别名:CNAME 把易记别名指向规范主机名。
- 邮件服务器定位:MX 指明负责接收某个域邮件的服务器。
- 服务分布:同一名称可以返回多个地址,解析系统还可按位置或策略改变返回顺序。
DNS 不采用单台全球服务器,因为那会形成单点故障、巨大流量瓶颈、遥远访问时延和难以维护的集中数据库。它把命名空间按层级委派,让不同组织分别管理自己的权威数据。
分层查询过程
主机通常先把查询交给本地递归解析器。若没有可用缓存,解析器从根 DNS 获得顶级域服务器的线索,再从顶级域服务器获得权威服务器的线索,最后向权威服务器取得目标记录。
在递归查询中,被询问的服务器负责继续查询并返回最终结果;在迭代查询中,被询问的服务器返回自己所知的最佳下一站。实践中,终端到本地解析器常表现为递归请求,而解析器在 DNS 层级之间执行迭代查询。
缓存是 DNS 可扩展性的关键。解析器会按记录的 TTL 暂存回答,在有效期内直接复用。短 TTL 便于快速切换地址,却增加查询量;长 TTL 降低负载,却让变更传播更慢。负回答也可能被缓存,所以刚修正配置时仍可能暂时看到旧结果。
资源记录与报文
DNS 资源记录可抽象为 (Name, Value, Type, TTL):
DNS 查询与响应使用相同的基本报文结构,通过标志位区分角色。报文包含首部、问题区、回答区、权威区和附加区。事务标识符帮助客户端把响应与查询配对;标志位还描述是否权威、是否期望递归以及是否发生错误。
通常的短查询使用 UDP 以减少建连开销;响应过大、发生截断或执行区域传送时可使用 TCP。仅凭 UDP 的轻量并不意味着 DNS 可以忽略安全:缓存投毒防护、随机事务标识、源端口随机化、DNSSEC 验证,以及面向客户端的加密 DNS 都是在不同位置解决风险。
4
在 DNS 资源记录中,用于指出某个域的邮件接收服务器的记录类型是 ____。
P2P 文件分发
集中式文件分发要求服务器向每个接收者上传一份完整文件。设文件大小为 F 位、接收者数量为 N、服务器上传速率为 u_s,最慢客户端下载速率为 d_min。无论怎样调度,服务器至少要上传 NF 位,最慢客户端至少要下载一份文件,因此集中式分发时间满足:
text
D_cs ≥ max(NF / u_s, F / d_min)随着 N 增大,NF/u_s 线性增长,服务器上行很快成为瓶颈。
P2P 中,服务器至少要注入一份完整文件,每个节点仍要下载一份文件,而系统总共要上传 NF 位。若第 i 个节点上传速率为 u_i,则分发时间下界为:
text
D_p2p ≥ max(F / u_s, F / d_min, NF / (u_s + Σu_i))当新节点加入时,它既产生一份下载需求,也带来上传能力,因此总容量会随群体增长。这就是 P2P 的自扩展性来源。不过,上式只是理想下界;实际时间还受节点离线、分块稀缺、协议开销和接入网络策略影响。
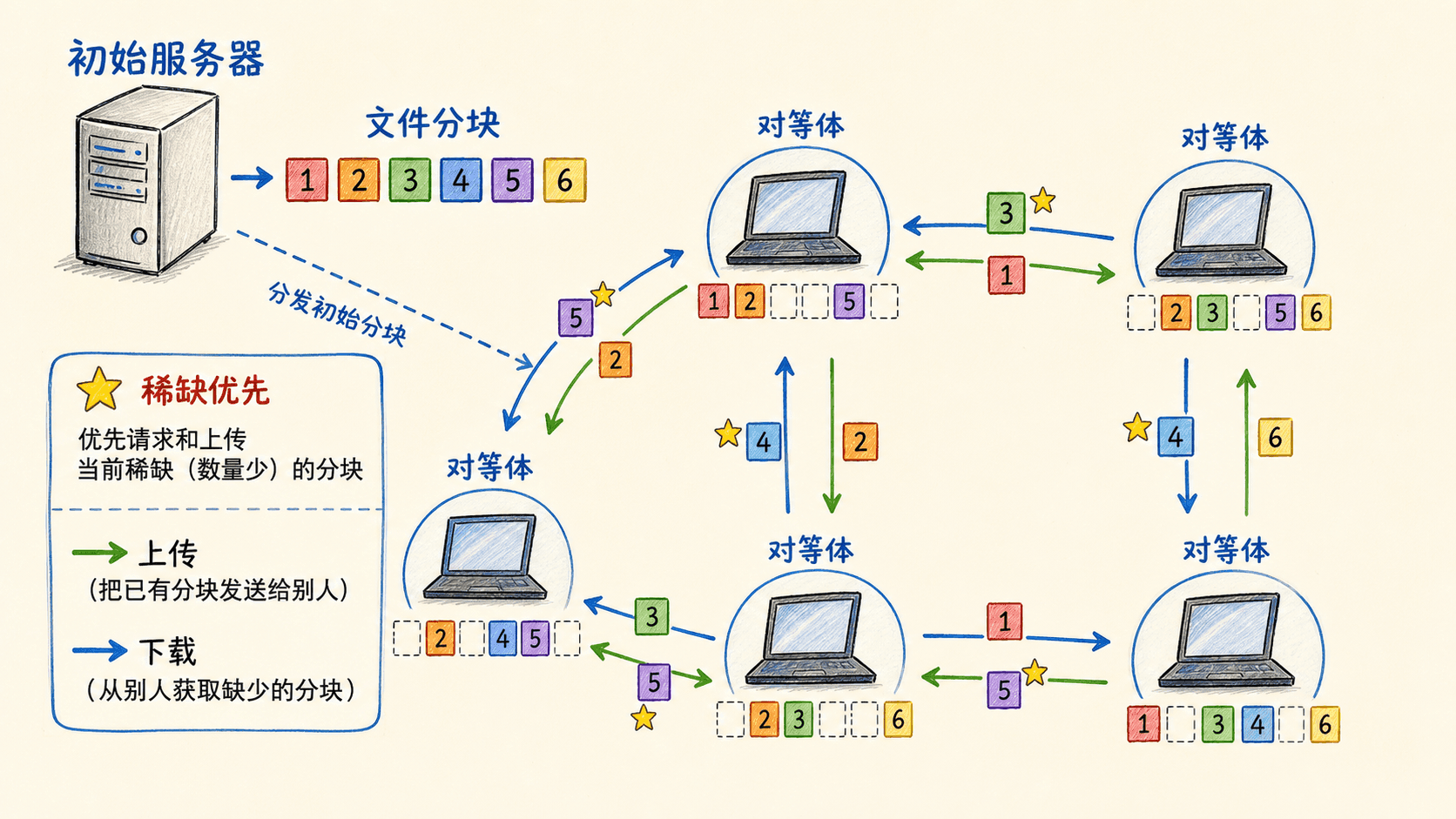
BitTorrent 式分块协作
大文件会被切成许多固定大小的分块。同一文件的一组交换节点可视为一个群体;协调服务帮助新节点发现可连接的邻居。节点周期性询问邻居拥有哪些分块,并优先请求群体中较稀缺的分块,使稀缺数据更快复制,降低“大家都缺同一块”的风险。
上传资源也需要调度。节点倾向于优先服务近期向自己提供数据较快的邻居,同时周期性尝试一个新的邻居,避免群体关系永久固化。这样的互惠机制鼓励上传,但仍需处理搭便车、恶意分块、NAT 穿透与隐私暴露等问题。
5
为什么 P2P 文件分发在节点增多时具有自扩展潜力?
视频流与内容分发网络
互联网视频的规模来自两个量的乘积:视频码率高,观看人数又多。一段视频会被编码为每秒固定数量比特的近似恒定码率,也可以依据画面复杂度采用可变码率。高分辨率、高帧率和更细腻的画质通常需要更高码率。
直接从单一源站向全球用户发送所有视频,会带来三个问题:跨越多条网络链路导致吞吐和时延不可控;热门内容会在相同链路上重复传送;源站和出口一旦故障,影响范围巨大。CDN 因而把内容复制或缓存到分布在不同地区的集群中,让用户从合适的边缘节点获取数据。
HTTP 流与 DASH
基础 HTTP 视频流可以把视频当作普通对象,客户端逐步接收并播放。但用户网络能力差异很大,同一固定码率无法同时照顾慢速移动网络和高速家庭宽带。
DASH 把视频编码成多个码率版本,并把每个版本切成短分片。清单文件描述可用版本、分片地址和编码信息。播放器持续估计可用吞吐量和缓冲区状态,在每次请求下一个分片时自行选择码率:带宽充裕时提高画质,带宽下降或缓冲不足时降低画质,目标是在清晰度与卡顿风险之间平衡。
CDN 如何把用户导向合适节点
CDN 通常采用两类部署思路:一种把大量小型集群深入接入网络,靠近用户;另一种在较少的关键位置建设更大的集群。前者距离短但运维点多,后者更集中却可能离部分用户较远。
当用户请求内容时,CDN 可借助 DNS 重定向或应用层清单,把请求导向某个集群。选点不能只按地理距离,还要综合网络往返时延、丢包、集群负载、ISP 路径、内容是否缓存和商业策略。边缘未命中时再向上级缓存或源站取回对象,并依据容量和热度淘汰旧内容。
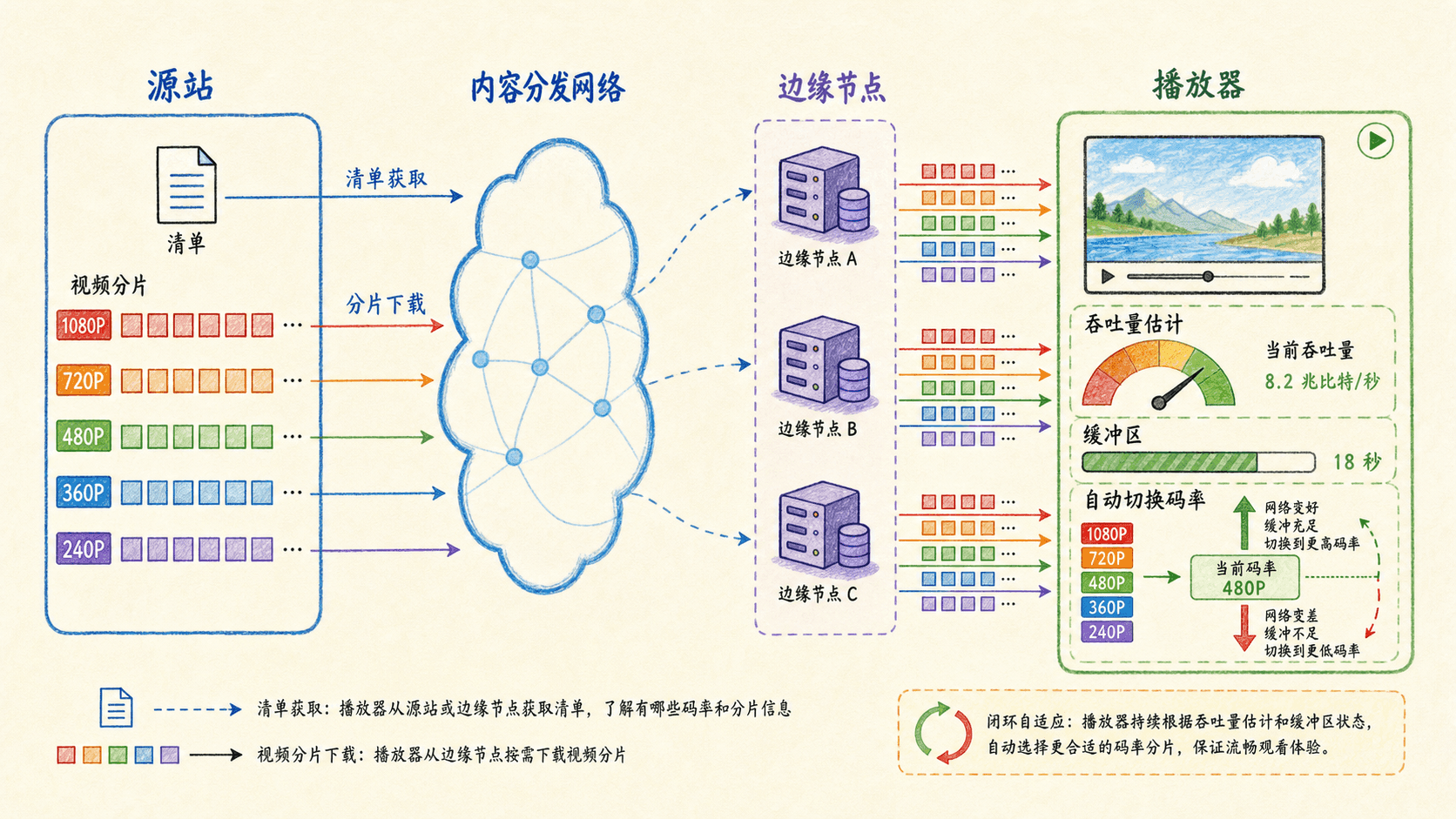
一次自适应播放的决策链
播放器先取得清单,知道每个码率版本和分片的 URL,而不是一次下载整部视频。
客户端根据最近若干分片的下载时间估计可用吞吐量,同时观察已缓冲的可播放时长。
播放器保留安全余量,选择低于估计吞吐量的版本;缓冲接近耗尽时主动降档。
客户端向选定 CDN 节点发起带有分片路径或字节范围的 HTTP 请求,下载完成后解码播放。
6
DASH 播放器选择下一个视频分片码率时,通常会考虑哪些信息?
用套接字创建网络应用
套接字编程把前面的协议原则落到代码:客户端和服务器分别创建套接字,通过操作系统把应用数据交给 UDP 或 TCP。下面使用 Python 风格的简化代码说明关键调用,重点是理解生命周期,而不是死记函数拼写。
UDP:报文边界清晰、无需建连
UDP 客户端创建数据报套接字后,用 sendto 同时给出数据和服务器地址。服务器把套接字绑定到约定端口,用 recvfrom 同时得到报文和发送方地址,再把响应发回该地址。
python
# UDP 客户端
from socket import socket, AF_INET, SOCK_DGRAM
client = socket(AF_INET, SOCK_DGRAM)
client.sendto("hello".encode(), ("server.example", 12000))
reply, server_address = client.recvfrom(2048)
client.close()python
# UDP 服务器
from socket import socket, AF_INET, SOCK_DGRAM
server = socket(AF_INET, SOCK_DGRAM)
server.bind(("", 12000))
while True:
message, client_address = server.recvfrom(2048)
server.sendto(message.decode().upper().encode(), client_address)UDP 保留一次发送对应一个数据报的边界,但数据报可能丢失、重复或乱序。生产应用还要定义超时、重试、请求标识、去重、最大报文尺寸和速率限制,否则“代码短”不等于“协议可靠”。
TCP:欢迎套接字与连接套接字
TCP 客户端先创建流式套接字,再调用 connect 建立连接。之后发送时不必给每段数据重复附加目标地址,因为连接已经由双方 IP 和端口标识。
服务器端有两类套接字容易混淆:
- 欢迎套接字绑定固定端口并监听所有新连接请求;
- 连接套接字由
accept为某个具体客户端创建,承载这位客户端的双向字节流。
python
# TCP 服务器的核心结构
from socket import socket, AF_INET, SOCK_STREAM
welcome = socket(AF_INET, SOCK_STREAM)
welcome.bind(("", 12000))
welcome.listen()
while True:
connection, client_address = welcome.accept()
data = connection.recv(2048)
connection.sendall(data.decode().upper().encode())
connection.close()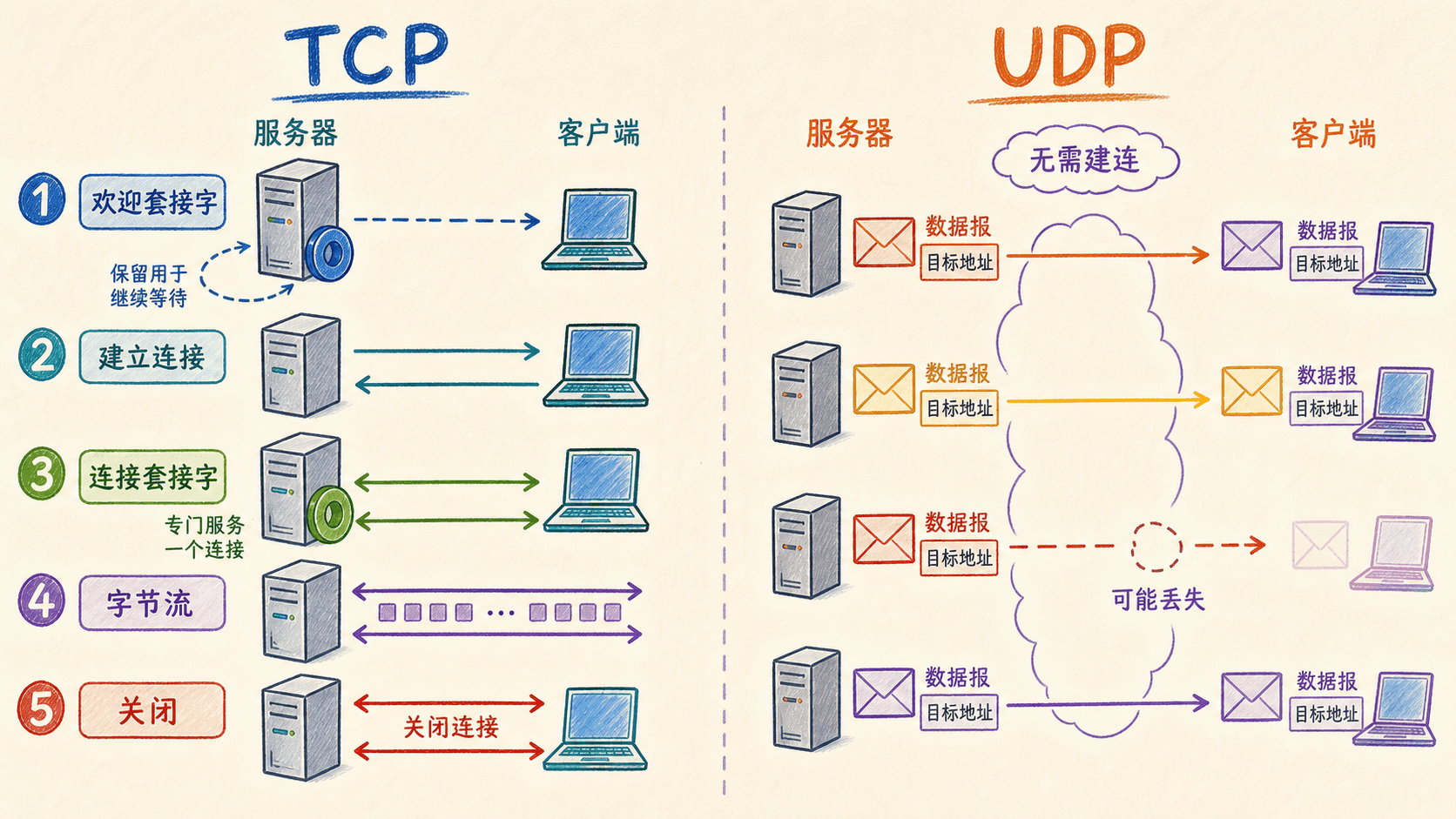
字节流中的消息边界
TCP 保证可靠、有序的字节流,却不保证一次 send 恰好对应接收端的一次 recv。接收端可能一次读到半条消息,也可能一次读到多条消息。应用协议必须自行定义边界,例如固定长度、分隔符、长度前缀,或像 HTTP 那样用头字段说明正文长度。
同时,recv 返回空字节通常表示对端已经有序关闭连接;网络调用可能阻塞或超时;服务端还需考虑并发连接、资源上限、异常清理和输入验证。正确的套接字程序不仅要“能连上”,还要在慢客户端、半包、断线和恶意输入下保持边界清晰。
TCP 的可靠性不等于应用事务只执行一次。如果客户端发送请求后在响应到达前断线,它无法仅凭连接状态判断服务器是否已经完成操作。支付、下单等接口仍需要请求唯一标识和幂等设计。
7
TCP 接收端每调用一次 recv,都会恰好取到发送端某一次 send 提交的完整消息。
把应用层知识连成一条链
现在再看一次“打开网页并播放视频”的过程,应用层的各部分就能串起来:
- 客户端依据 URL 得到主机名,并通过 DNS 查询目标地址;
- 进程利用目标 IP 与端口找到服务端进程,选择 TCP/TLS、QUIC 等通信方式;
- HTTP 请求用方法、路径、头字段和可选正文表达意图;
- 服务器或缓存以状态码、头字段和表示回应;
- Cookie 或令牌把多个无状态请求关联到应用会话;
- 视频播放器读取清单,按吞吐量与缓冲状态选择分片;
- CDN 让大对象尽量从合适的边缘节点交付;
- 若采用 P2P,终端还可以把已获得的分块继续服务给其他节点。
这些技术共享同一个核心:协议必须明确规定消息的格式、顺序、语义和处理动作。传输层解决端到端交付的通用问题,应用层则把字节变成“查询一个名字”“获取一个对象”“投递一封邮件”或“请求下一段视频”。
设计新应用时的检查表
8
要在互联网上唯一定位某台目标主机上的一个应用进程,通常需要组合目标 IP 地址与目标 ____。