计算机网络安全:从密码学到纵深防御
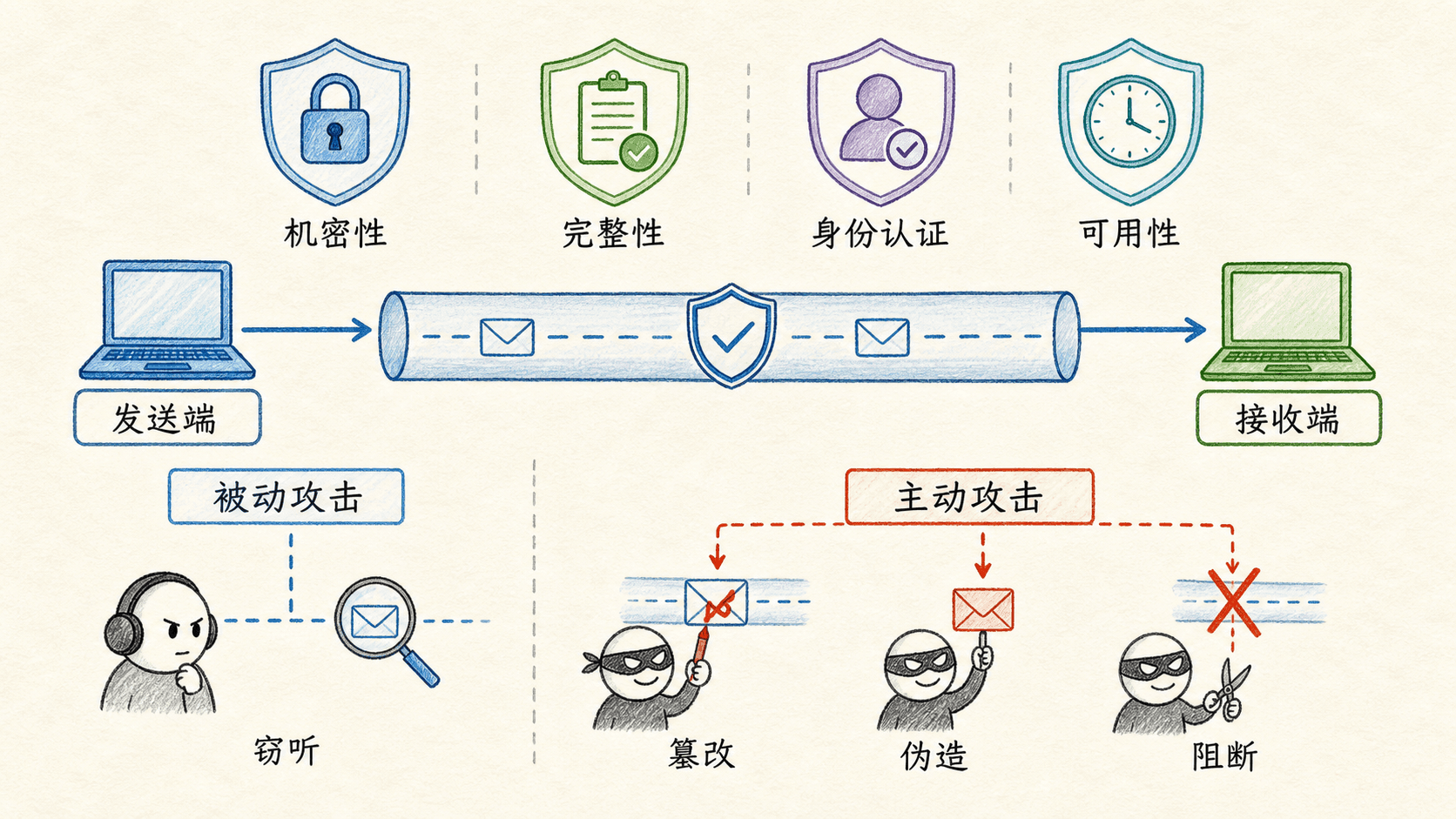
网络把彼此不认识的设备连接起来,也把通信暴露在窃听、伪造、篡改和阻断之下。所谓“安全通信”,并不是简单地给报文加密,而是让接收方能够回答四个问题:内容是否只有预期对象能读懂?数据是否保持原样?对端是否真是它所声称的身份?服务能否持续向合法用户开放?
在这最后一部分,我们会先建立安全目标与攻击模型,再逐步搭起密码学工具箱。随后,我们会把这些工具放回真实网络协议:安全电子邮件、TLS、IPsec、无线接入和蜂窝网络。最后回到组织网络的边界,理解防火墙与入侵检测系统为何必须协同工作。
安全机制必须与威胁对应。加密可以隐藏内容,却不会自动阻止重放;散列可以发现偶然变化,却不能单独证明发送者身份;防火墙能缩小入口,却不能替代端到端认证。可靠的方案总是把若干机制按明确顺序组合起来。
安全通信的目标与攻击面
四个目标不是同一件事
机密性要求只有发送方和预期接收方能理解消息。开放网络上的攻击者即使记录了全部报文,也只能得到不可读的密文。机密性通常由加密提供,但能否保密还取决于密钥是否安全、随机数是否正确使用,以及实现是否泄漏信息。
消息完整性要求接收方能够发现内容是否在途中被改变。改变可能来自恶意攻击,也可能来自传输错误。普通校验和擅长发现随机差错,却不能防御能重新计算校验值的攻击者;安全协议需要把秘密密钥或签名私钥纳入验证过程。
端点认证要求通信的一方证明自己的身份。网络地址不是可靠身份证明,因为源地址可能伪造,报文也可能从旧会话中复制。有效认证通常依赖口令、共享密钥、私钥或受信任机构签发的凭据,并通过挑战—响应证明对方此刻在线。
运营安全关注组织网络能否持续抵御恶意软件、扫描、入侵和拒绝服务。它不仅包含技术设备,还包含策略、日志、更新、隔离和响应流程。防火墙负责执行访问规则,IDS 负责发现可疑模式,两者解决的问题不同。
设计安全协议时,先画出发送方、接收方、信道和攻击者。然后明确攻击者能看到什么、能改变什么、是否能控制端点。如果攻击者已经控制了终端,链路加密无法阻止它读取解密后的内容;如果攻击者只能监听信道,正确实现的加密则非常有效。威胁模型决定了安全边界。
1
攻击者截获并原样重放一条已经通过完整性验证的转账指令,最直接缺失的机制是什么?
密码学基础:明文、密文与密钥
加密算法把明文 m 与加密密钥 K 映射为密文 c,解密算法再用相应密钥恢复明文。现代系统通常公开算法,把安全性放在密钥上。这样算法可以被广泛分析、标准化和改进,攻击者即使知道每一步计算,也不能在没有密钥的情况下有效恢复数据。
对称密钥加密
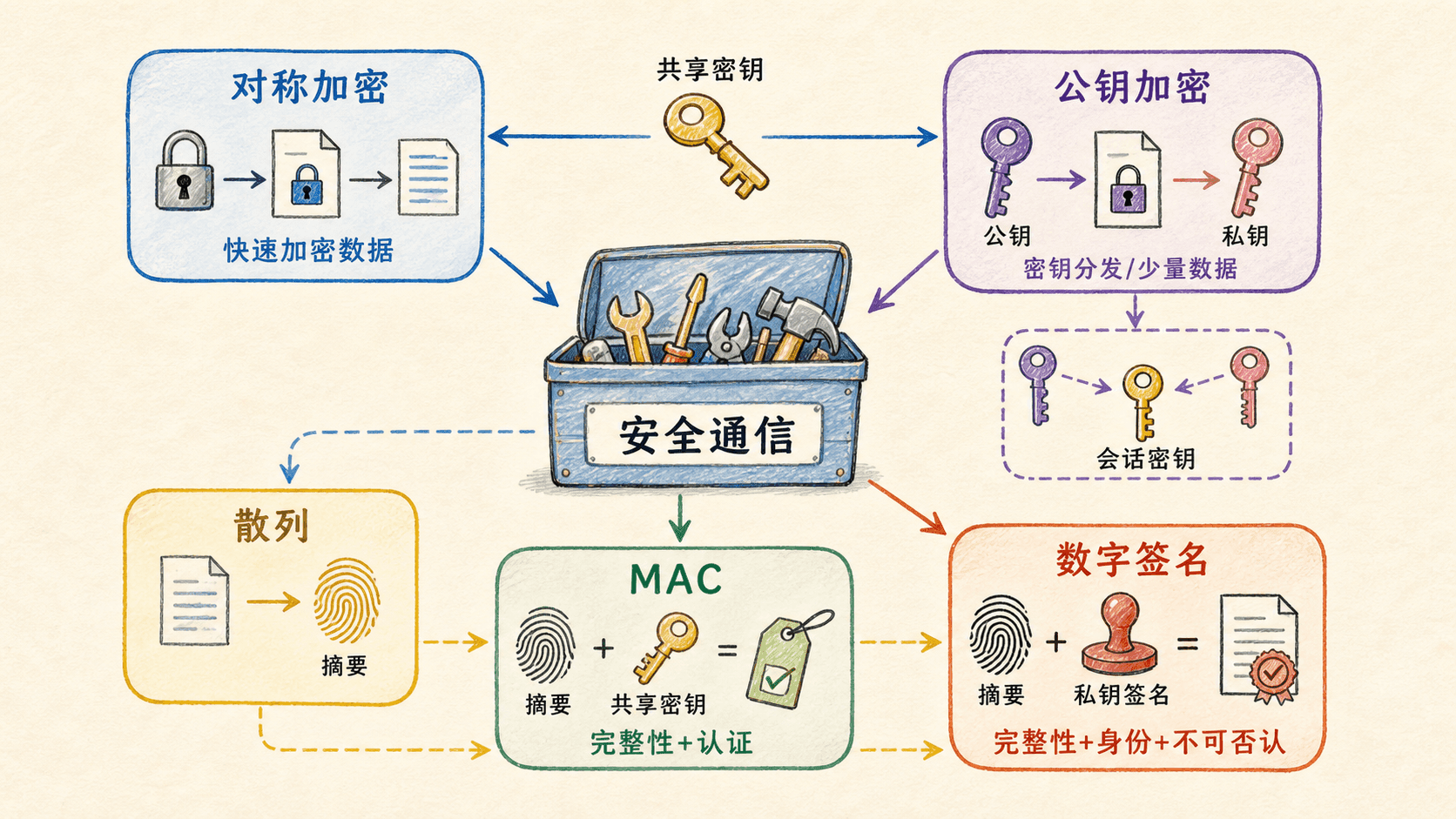
对称加密中,双方持有同一秘密密钥。早期替换密码把字母按固定规则替换,密钥空间小或会泄漏语言频率,因而不适合现代网络。现代分组密码把固定长度的比特块映射到等长密文块。AES 使用 128 位数据块,并支持多种密钥长度;只要模式和密钥管理正确,它可以高效保护大量数据。
仅把每个相同明文块独立加密会暴露重复模式,因此分组密码需要工作模式。以密码块链接思想为例,第一个明文块先与随机初始向量结合,之后每个明文块再与前一密文块关联。这样,相同明文块出现在不同位置时通常得到不同密文。初始向量不一定保密,但必须满足对应模式的不可预测或唯一性要求。
实际协议通常更偏爱认证加密:它同时产生密文与认证标签,把机密性和完整性放在一个受严格定义的结构里。无论使用何种模式,都必须避免在同一密钥下错误复用 nonce 或初始向量,否则重复模式、明文关系乃至密钥信息都可能泄漏。
公钥密码与混合加密
公钥体系为每个主体准备一对密钥:公钥可以公开,私钥必须独占。用接收方公钥加密的数据只能由对应私钥解开;用私钥生成的签名可以由公钥验证。公钥方法解决了“未预先共享秘密的双方怎样开始安全通信”的难题,但计算成本高,不适合直接处理长消息。
RSA 的核心是模运算。密钥生成从两个大素数出发,得到公开参数与私有参数;其安全性依赖于对大整数分解的困难。教学中的小整数例子能够说明运算关系,却完全没有实际安全性。实际使用还必须采用经过验证的填充方案,不能直接对裸消息做简单幂模运算。
因此,网络协议常用混合加密:公钥技术负责认证或建立一次性的会话秘密,对称加密负责后续大流量。会话结束后丢弃临时密钥,可以限制单个密钥泄漏的影响范围。密钥派生函数还会从同一主秘密导出不同方向、不同用途的密钥,避免“一把钥匙到处用”。
2
关于现代加密系统,下列哪些说法正确?
完整性、MAC 与数字签名
密码学散列函数
散列函数把任意长度消息映射为固定长度摘要 H(m)。安全散列需要具备三个直观性质:由摘要反推输入应不可行;给定一条消息,找到另一条同摘要消息应不可行;寻找任意一对碰撞消息也应不可行。摘要对输入变化高度敏感,一位改变通常会让输出看起来完全不同。
散列函数本身不含秘密。若发送方只发送 m 与 H(m),主动攻击者可以把二者一起替换。因此,散列适合做指纹和签名的预处理,却不能独立证明网络消息来自谁。
消息认证码
消息认证码(MAC)把消息和共享认证密钥一起计算。接收方用同一密钥重新计算并比较结果:若标签一致,可以认为消息未被改变,并且生成者掌握共享秘密。HMAC 是把散列函数以规定结构与秘密密钥组合的常用方案。
MAC 的限制在于双方都能生成相同标签。它适合两方协议中的来源认证,却不能向第三方证明究竟是哪一方生成了消息。共享密钥的分发与轮换也必须有安全渠道。
数字签名与证书
数字签名先计算消息摘要,再用签名者私钥对摘要执行签名算法。验证者用公钥检查签名。签名同时保护来源与内容:消息变化会让摘要变化,错误公钥也无法通过验证。对摘要签名而非直接签整个长文档,可以显著减少公钥运算量。
公钥只有在身份绑定可靠时才有意义。攻击者若能把自己的公钥冒充为某人的公钥,就能同时伪造消息与签名。认证机构先核验主体身份,再签发包含主体信息、公钥、有效期、序列号和签名算法等字段的证书。验证者用认证机构的公钥检查证书签名,再从证书中取得主体公钥。
3
为什么把普通散列值直接附在消息后面不能抵御主动篡改?
端点认证:证明“是我,而且是现在”
网络认证比当面辨认困难,因为通信双方看不到彼此,报文还可能被记录和复制。仅发送用户名毫无证明力;把源 IP 地址当身份也不可靠;直接发送明文口令会被窃听。即使把固定口令加密后发送,攻击者仍可能原样重放那段密文。
nonce 与挑战—响应
nonce 是只使用一次的随机数。验证方生成一个新的 nonce 作为挑战,声称身份的一方用共享密钥或私钥对它进行规定的密码运算并返回。验证方检查结果,即可同时确认两件事:对方掌握正确密钥,而且它刚刚处理了本次挑战,而不是重放旧会话。
一个基于共享密钥的简化流程如下:
申请方声明身份,验证方创建不可预测且不重复的 nonce。
验证方发送 nonce;申请方用双方共享秘密计算响应。
验证方独立计算预期结果并比较。匹配说明申请方掌握秘密并在线。
认证成功后再建立会话密钥,并把身份结果绑定到后续连接,避免认证与数据通道被调包。
使用公钥时,申请方可以用私钥签署挑战,验证方用证书中的公钥检查。但必须先验证证书,否则中间人可以把自己的公钥替换进去,分别与两端建立会话。认证协议的困难常常不在密码算法,而在消息顺序、身份绑定、错误处理和新鲜性细节。
4
只要固定口令经过加密后再发送,认证协议就天然能够抵御重放攻击。
安全电子邮件:签名、加密与密钥封装
电子邮件的特殊之处在于发送者和接收者不必同时在线,消息还会经过并存放在多个邮件服务器中。安全邮件通常在应用层直接保护消息本体,使内容离开发送者设备后仍保持机密和完整。
只要求机密性
发送方随机生成一次性对称会话密钥,用它加密邮件正文;再用接收方公钥加密会话密钥。邮件携带“加密正文 + 加密会话密钥”。接收方先用私钥恢复会话密钥,再用对称算法解密正文。这样既保留公钥分发的便利,也避免用公钥算法处理整封长邮件。
同时要求来源与完整性
发送方先对正文计算摘要,再用自己的私钥签名摘要,把正文与签名一起发送。接收方取得发送者的可信公钥,重新计算摘要并验证签名。若还需要机密性,则把“正文 + 签名”作为整体,再按混合加密流程保护。
PGP 展示了这种组合方式:用户拥有公私钥对,私钥通常以口令保护;消息可以只签名、只加密,也可以先签名后加密。公钥可信度可以由他人签名背书,形成分散的信任关系。关键不是具体软件名称,而是理解四步次序:摘要、签名、对称加密、会话密钥封装。
加密邮件正文并不等于隐藏全部通信信息。发件人、收件人、时间和路由等元数据仍可能暴露;终端一旦被恶意软件控制,解密后的内容也可能泄漏。
5
安全邮件为何常用随机会话密钥加密正文,再用接收方公钥加密会话密钥?
TLS:给 TCP 应用建立安全通道
TLS 位于应用与 TCP 之间。应用通过类似安全套接字的接口读写数据,而 TLS 负责握手、密钥派生、分段、加密和完整性验证。它可保护任何基于 TCP 的应用,HTTPS 只是最常见的组合。
握手解决三个问题
第一,协商双方支持的密码算法。第二,认证服务器身份,必要时也认证客户端。第三,在可能被监听和篡改的网络上建立只有双方掌握的主秘密。握手结束后,双方从主秘密派生多个密钥,分别服务于客户端到服务器、服务器到客户端,以及不同保护用途。
一个便于理解的流程是:客户端发起问候;服务器返回证书和参数;客户端验证证书中的身份与公钥;双方完成密钥建立;最后用新密钥验证握手记录。最后一步把此前的协商内容一起纳入校验,防止攻击者悄悄降级算法或替换参数。
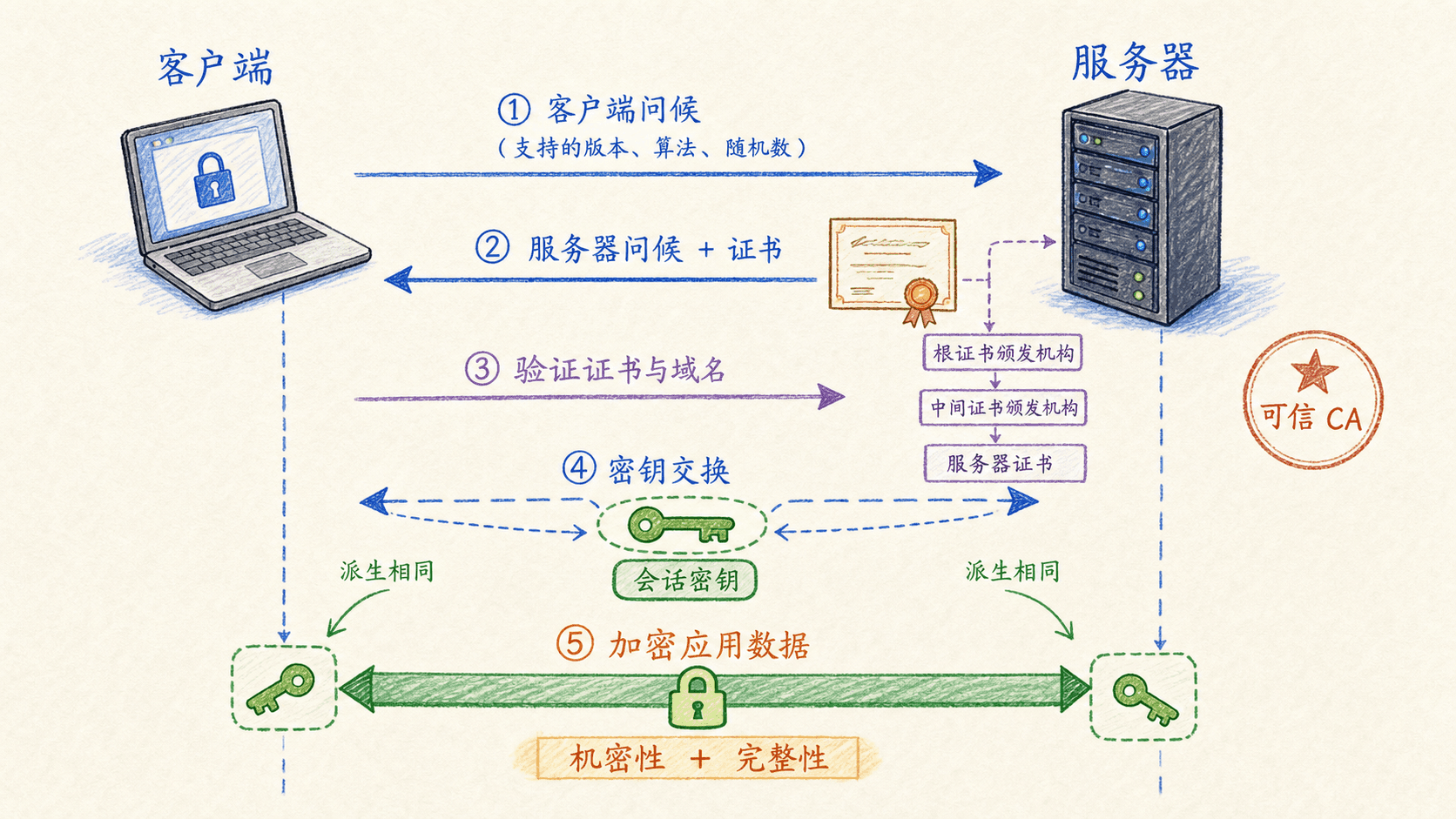
记录层为何还需要序号
TCP 提供字节流,不保留应用消息边界。TLS 把数据切成记录,每条记录带有完整性保护。若只给每条记录做 MAC,攻击者还可能删除、交换或重放完整记录。因此协议把隐式序号纳入完整性计算。接收方维护自己的期望序号,缺失、乱序或重复都能被发现。
关闭连接也要被认证。若攻击者简单截断 TCP 连接,接收方可能误以为应用数据已完整到达。受保护的关闭通知让双方区分“正常结束”和“未经确认的中断”。
6
TLS 握手和记录层分别承担哪些任务?
IPsec 与虚拟专用网
TLS 由应用主动使用,IPsec 则在网络层保护 IP 数据报。它可以让应用无感地获得加密与完整性服务,尤其适合把两个地点的内部网络通过公共互联网连接成虚拟专用网(VPN)。
隧道模式与 ESP
站点到站点 VPN 常由两端安全网关完成。发送端把原始内部 IP 数据报作为载荷封装,外面再加新的 IP 首部,使公共网络只看到两个网关之间的流量。ESP 可以对载荷加密、提供来源认证和完整性,并通过序号抵御重放。接收网关验证后解封装,把原始数据报送入目标内网。
AH 提供认证与完整性但不提供机密性;ESP 可以同时提供加密与认证,因而更常见。无论使用哪种协议,网络层保护都不会自动修复不安全的端点或错误授权策略。
安全关联、SAD 与 SPD
IPsec 的安全关联(SA)是单向的。双向安全通信至少需要两个 SA,每个 SA 记录安全参数索引 SPI、算法、密钥、源/目的地址和序号状态。到达报文可依据 SPI 和地址定位正确 SA。
安全策略数据库 SPD 决定一类流量应绕过、丢弃还是交给 IPsec;安全关联数据库 SAD 则保存具体 SA 的算法与密钥。可以把 SPD 理解为“对什么流量做什么”,把 SAD 理解为“具体怎样做”。
小规模环境可以手工配置 SA,大规模 VPN 则需要 IKE 自动认证对端、协商算法并建立密钥。IKE 先建立受保护的管理通道,再为实际 IPsec 流量创建方向明确的 SA,使密钥更新与扩展成为可能。
7
为什么一条双向 IPsec 通信通常至少需要两个安全关联?
无线局域网与 4G/5G 接入安全
无线信号会在覆盖范围内传播,攻击者无需接入网线就能监听帧。因此,无线接入必须同时解决移动设备与网络的认证、会话密钥生成和空口加密。
802.11:设备、接入点与认证服务器
企业无线网络通常包含移动设备、接入点和认证服务器。移动设备与认证服务器预先拥有凭据,接入点在无线侧转发认证消息。认证成功后,设备与网络得到共享会话密钥,接入点再用该密钥保护无线帧。
EAP 定义可承载多种认证方法的消息框架。无线链路上的 EAP 消息封装在 EAPoL 中;接入点再把认证内容通过 AAA 协议送往认证服务器。这里的关键是把接入设备与真正作出认证决定的服务器分开,同时把认证结果安全地绑定到该无线会话。
早期无线安全方案的根本问题包括短初始向量、密钥复用和不可靠的完整性机制,导致攻击者能够收集流量后推断密钥或修改帧。安全升级不能只换一个更长口令,还必须更换协议设计和加密模式。
4G/5G:归属网络参与认证
蜂窝网络中,终端的 SIM/USIM 与归属网络共享长期秘密。终端接入访问网络时,归属网络参与认证向量和会话密钥的生成。挑战—响应让网络验证终端,终端也检查网络返回的信息,从而降低接入伪基站的风险。派生出的密钥分别供无线链路和核心网不同功能使用。
5G 延续相互认证与密钥派生,并进一步减少永久身份在空口明文暴露的机会。终端可能通过非归属接入网络连接服务,但最终认证决定仍须与归属网络的可信信息关联。无论 WiFi 还是蜂窝网络,基本构件仍是 nonce、对称密码、消息完整性和可信认证服务器。
8
无线接入只要加密空口数据,就不再需要认证接入网络的身份。
运营安全:防火墙、DMZ 与访问策略
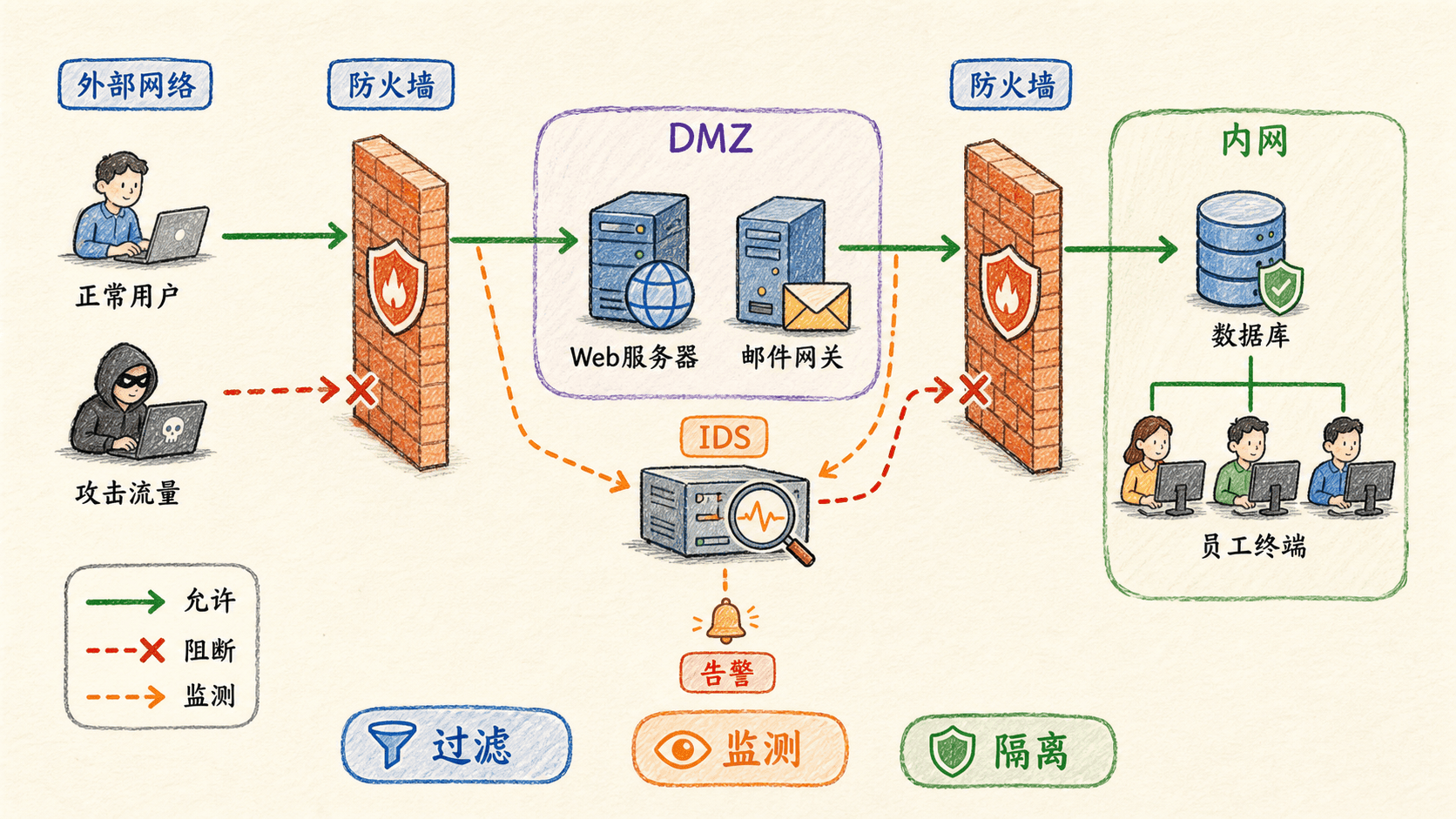
防火墙位于内部网络与外部网络之间,按照组织策略放行或丢弃流量。一个合理边界至少满足三个条件:内外流量必须经过控制点;只有策略允许的流量能够通过;控制设备本身必须经过加固。
传统包过滤
传统包过滤器逐个检查数据报,不记忆之前发生过什么。规则可以使用源/目的 IP、源/目的端口、协议、TCP 标志和方向。例如,可以拒绝从外部发起的管理端口连接,允许内部用户访问外部 Web 服务,并允许必要的 DNS 流量。
包过滤的优点是速度快、位置透明;缺点是规则容易变复杂,而且单个报文的首部信息不足以表达“它是否属于合法会话”。把某个源端口写成允许条件,并不能证明报文真的来自对应应用。
状态过滤与应用网关
状态防火墙观察 TCP 连接建立和结束,维护连接表。外部返回报文只有与表中已建立连接匹配时才被放行。它比只看 ACK 位或端口可靠,因为攻击者伪造一个首部字段并不能凭空创造合法连接状态。
应用网关理解具体应用协议,可以根据用户身份、命令和内容做更细粒度控制。代价是每种应用都需要相应逻辑,网关还会增加处理开销并成为需要重点保护的节点。
DMZ 与分区
必须让公网访问的服务器不应与高价值内网处于同一信任区。DMZ 把公开服务放在相对低信任区域,内网再由额外规则和应用网关保护。即使公开服务器被攻陷,攻击者仍要跨越另一层控制才能进入核心网络。多层防火墙与分布式控制的目的,是减少一次边界失守造成的横向扩散。
9
状态防火墙相对传统包过滤最关键的新增能力是什么?
入侵检测与纵深防御
防火墙回答“按策略能不能通过”,IDS 回答“流量是否像一次攻击”。许多攻击必须查看应用载荷或连续多条报文才能识别,例如端口扫描、恶意输入、协议异常和拒绝服务征兆。深度包检查能够分析首部之外的内容与跨报文关系。
IDS 发现可疑活动后发出告警,不一定阻断流量;IPS 位于转发路径,可直接丢弃可疑报文。阻断能力更主动,但误报的业务代价也更高。实际部署要在检测覆盖、处理性能和误报率之间权衡。
基于签名与基于异常
签名型 IDS 保存已知攻击特征,把观察到的报文或报文序列与规则库比较。它对已知攻击解释清晰、误报相对可控,但看不到尚无签名的新攻击,规则也必须持续更新。高速链路上的大量规则匹配会带来性能压力。
异常型 IDS 先建立正常流量基线,再寻找统计上偏离基线的行为,例如 ICMP 比例异常增长、端口探测突然增多或某主机通信模式骤变。它可能发现未知攻击,却也容易把业务高峰当成异常,需要长期调优。
传感器为什么要分散部署
单一边界传感器能看到总体流量,却可能因吞吐过大而漏检,也难以了解加密流量解密后的应用语义。把传感器放在边界、DMZ 与高安全区,可以减少每个传感器负载,并从不同位置拼出攻击路径。集中分析器再汇总告警、关联时间线和主机信息。
纵深防御不是重复堆设备,而是让各层承担不同职责:身份认证限制谁能访问,密码协议保护传输,分区限制横向移动,防火墙执行边界策略,IDS发现异常,日志与响应流程负责确认、处置和复盘。
10
关于 IDS 的说法,哪些正确?
设计安全网络的系统方法
把这部分机制放到一起,你可以得到一条可复用的设计路径。
确定资产和边界:列出要保护的数据、身份、服务和密钥,并画出信任区与跨区数据流。
建立攻击模型:区分被动窃听、主动篡改、重放、冒充、端点失陷与资源耗尽,明确每种攻击者的能力。
选择最小机制组合:机密性用加密,完整性与来源用 MAC 或签名,新鲜性用 nonce 或序号,身份绑定用证书或预共享凭据。
把密钥生命周期纳入协议:安全地产生、分发、派生、轮换和销毁密钥,不让同一密钥跨用途复用。
安全性来自完整链条,而链条的强度取决于最薄弱的一环。证书验证若跳过域名,强加密也会连接到错误对端;nonce 若重复,挑战—响应就可能被重放;防火墙若规则过宽,边界形同虚设;IDS 若无人处理告警,也无法降低风险。
11
在挑战—响应认证中,用于保证每次认证新鲜、使旧响应无法直接重放的一次性随机数称为 ____。
完成这部分内容后,你应该能从“某个算法是否安全”进一步追问:密钥怎样到达双方?身份怎样绑定到公钥?消息怎样证明新鲜?各层安全机制如何组合?异常发生后谁能看见并处理?这些问题共同构成计算机网络安全的完整视角。