数据探索
当我们面对一张陌生的数据表时,第一个问题往往是"这张表里到底有什么?"。数据探索(Data Exploration)就像是探险家在未知领域中的第一次探索,我们需要仔细观察、仔细分析,才能发现数据中隐藏的规律和价值。 这一节课,我们将学习如何系统地探索数据,从单列的基本统计到多列之间的关系,从SQL查询到Excel可视化,逐步建立起对数据的全面理解。
数据探索是数据分析的第一步,也是最重要的一步。在开始任何深入的分析之前,我们都需要先了解数据的基本情况。这就像是在做菜之前,我们需要先看看冰箱里有什么食材,了解它们的品质和特点,才能决定做什么菜、怎么做。
数据探索的目的不仅仅是了解数据的基本信息,更重要的是发现数据中的异常、识别数据质量问题、理解数据的分布特征,以及初步发现数据中可能存在的规律。这些发现将指导我们后续的分析方向,帮助我们避免在错误的方向上浪费时间。
数据探索不是一次性的工作,而是一个迭代的过程。随着我们对数据的理解不断深入,我们可能会发现新的问题,需要回到探索阶段重新审视数据。
在实际工作中,数据探索往往能够揭示一些意想不到的发现。比如,我们可能会发现某些字段中存在大量的缺失值,某些数值明显超出了合理范围,或者某些类别字段的分布极不均匀。这些发现虽然看起来像是"问题",但实际上它们本身就是有价值的信息,能够帮助我们更好地理解业务现状。
从SQL开始:探索列的基本信息
在开始使用Excel进行可视化之前,我们先用SQL来获取数据的基本信息。SQL查询能够快速告诉我们数据的规模、结构以及基本的统计特征。
测试数据如下:
-- 创建订单表
CREATE TABLE 订单表 (
订单ID SERIAL PRIMARY KEY,
订单金额 DECIMAL(10, 2) NOT NULL,
订单状态 VARCHAR(20) NOT NULL,
商品数量 INTEGER NOT NULL,
产品类别 VARCHAR(50) NOT NULL,
客户ID INTEGER NOT NULL,
订单日期 DATE NOT NULL,
地区 VARCHAR(20) NOT NULL,
客户姓名 VARCHAR(50) NOT NULL
);
-- 插入100条测试数据
INSERT INTO 订单表 (订单金额, 订单状态, 商品数量, 产品类别, 客户ID, 订单日期, 地区, 客户姓名) VALUES
(125.50, '已完成', 2, '电子产品', 1001, '2024-01-15', '华东', '张三'),
(89.00, '已完成', 1, '服装', 1002, '2024-01-16', '华南', '李四'),
(256.80, '待处理', 3, '电子产品', 1003, '2024-01-17', '华北', '王五'),
(45.90, '已完成', 1, '食品', 1004, '2024-01-18', '华东', '赵六'),
(678.50, '已完成', 5, '电子产品', 1005, '2024-01-19', '华南', '钱七'),
(234.20, '已取消', 2, '服装', 1006, '2024-01-20', '华北', '孙八'),
(156.30, '已完成', 1, '食品', 1007, '2024-01-21', '华东', '周九'),
(89.50, '待处理', 1, '服装', 1008, '2024-01-22', '华南', '吴十'),
(345.60, '已完成', 3, '电子产品', 1009, '2024-01-23', '华北', '郑一'),
(67.80, '已完成', 1, '食品', 1010, '2024-01-24', '华东', '王二'),
(1234.90, '已完成', 8, '电子产品', 1011, '2024-01-25', '华南', '李三'),
(189.40, '待处理', 2, '服装', 1012, '2024-01-26', '华北', '张四'),
(56.70, '已完成', 1, '食品', 1013, '2024-01-27', '华东', '赵五'),
(456.30, '已完成', 4, '电子产品', 1014, '2024-01-28', '华南', '钱六'),
(78.90, '已取消', 1, '服装', 1015, '2024-01-29', '华北', '孙七'),
(234.50, '已完成', 2, '食品', 1016, '2024-01-30', '华东', '周八'),
(567.80, '已完成', 5, '电子产品', 1017, '2024-02-01', '华南', '吴九'),
(123.40, '待处理', 1, '服装', 1018, '2024-02-02', '华北', '郑十'),
(345.20, '已完成', 3, '食品', 1019, '2024-02-03', '华东', '王一'),
(89.60, '已完成', 1, '电子产品', 1020, '2024-02-04', '华南', '李二'),
(678.90, '已完成', 6, '电子产品', 1021, '2024-02-05', '华北', '张三'),
(156.70, '待处理', 2, '服装', 1022, '2024-02-06', '华东', '李四'),
(45.30, '已完成', 1, '食品', 1023, '2024-02-07', '华南', '王五'),
(1234.50, '已完成', 9, '电子产品', 1024, '2024-02-08', '华北', '赵六'),
(234.80, '已取消', 2, '服装', 1025, '2024-02-09', '华东', '钱七'),
(567.40, '已完成', 4, '食品', 1026, '2024-02-10', '华南', '孙八'),
(89.20, '已完成', 1, '电子产品', 1027, '2024-02-11', '华北', '周九'),
(345.60, '待处理', 3, '服装', 1028, '2024-02-12', '华东', '吴十'),
(156.90, '已完成', 2, '食品', 1029, '2024-02-13', '华南', '郑一'),
(456.70, '已完成', 4, '电子产品', 1030, '2024-02-14', '华北', '王二'),
(78.50, '已完成', 1, '服装', 1031, '2024-02-15', '华东', '李三'),
(234.30, '待处理', 2, '食品', 1032, '2024-02-16', '华南', '张四'),
(1234.80, '已完成', 10, '电子产品', 1033, '2024-02-17', '华北', '赵五'),
(567.20, '已完成', 5, '电子产品', 1034, '2024-02-18', '华东', '钱六'),
(89.40, '已取消', 1, '服装', 1035, '2024-02-19', '华南', '孙七'),
(345.80, '已完成', 3, '食品', 1036, '2024-02-20', '华北', '周八'),
(156.50, '已完成', 1, '电子产品', 1037, '2024-02-21', '华东', '吴九'),
(678.30, '已完成', 6, '电子产品', 1038, '2024-02-22', '华南', '郑十'),
(234.70, '待处理', 2, '服装', 1039, '2024-02-23', '华北', '王一'),
(456.40, '已完成', 4, '食品', 1040, '2024-02-24', '华东', '李二'),
(123.60, '已完成', 1, '电子产品', 1041, '2024-02-25', '华南', '张三'),
(345.90, '已完成', 3, '服装', 1042, '2024-02-26', '华北', '李四'),
(567.50, '已完成', 5, '食品', 1043, '2024-02-27', '华东', '王五'),
(89.70, '待处理', 1, '电子产品', 1044, '2024-02-28', '华南', '赵六'),
(1234.40, '已完成', 8, '电子产品', 1045, '2024-03-01', '华北', '钱七'),
(234.60, '已完成', 2, '服装', 1046, '2024-03-02', '华东', '孙八'),
(156.80, '已取消', 1, '食品', 1047, '2024-03-03', '华南', '周九'),
(678.60, '已完成', 6, '电子产品', 1048, '2024-03-04', '华北', '吴十'),
(456.80, '已完成', 4, '电子产品', 1049, '2024-03-05', '华东', '郑一'),
(345.40, '待处理', 3, '服装', 1050, '2024-03-06', '华南', '王二'),
(123.80, '已完成', 1, '食品', 1051, '2024-03-07', '华北', '李三'),
(567.60, '已完成', 5, '电子产品', 1052, '2024-03-08', '华东', '张四'),
(89.90, '已完成', 1, '服装', 1053, '2024-03-09', '华南', '赵五'),
(234.40, '已完成', 2, '食品', 1054, '2024-03-10', '华北', '钱六'),
(1234.60, '已完成', 9, '电子产品', 1055, '2024-03-11', '华东', '孙七'),
(156.20, '待处理', 1, '电子产品', 1056, '2024-03-12', '华南', '周八'),
(678.40, '已完成', 6, '电子产品', 1057, '2024-03-13', '华北', '吴九'),
(345.70, '已完成', 3, '服装', 1058, '2024-03-14', '华东', '郑十'),
(456.20, '已取消', 4, '食品', 1059, '2024-03-15', '华南', '王一'),
(567.80, '已完成', 5, '电子产品', 1060, '2024-03-16', '华北', '李二'),
(123.20, '已完成', 1, '服装', 1061, '2024-03-17', '华东', '张三'),
(234.90, '待处理', 2, '食品', 1062, '2024-03-18', '华南', '李四'),
(89.30, '已完成', 1, '电子产品', 1063, '2024-03-19', '华北', '王五'),
(1234.70, '已完成', 10, '电子产品', 1064, '2024-03-20', '华东', '赵六'),
(345.50, '已完成', 3, '服装', 1065, '2024-03-21', '华南', '钱七'),
(678.20, '已完成', 6, '食品', 1066, '2024-03-22', '华北', '孙八'),
(156.40, '已完成', 1, '电子产品', 1067, '2024-03-23', '华东', '周九'),
(456.60, '待处理', 4, '电子产品', 1068, '2024-03-24', '华南', '吴十'),
(567.40, '已完成', 5, '服装', 1069, '2024-03-25', '华北', '郑一'),
(234.20, '已完成', 2, '食品', 1070, '2024-03-26', '华东', '王二'),
(89.60, '已取消', 1, '电子产品', 1071, '2024-03-27', '华南', '李三'),
(1234.30, '已完成', 8, '电子产品', 1072, '2024-03-28', '华北', '张四'),
(345.30, '已完成', 3, '服装', 1073, '2024-03-29', '华东', '赵五'),
(678.80, '已完成', 6, '食品', 1074, '2024-03-30', '华南', '钱六'),
(156.60, '待处理', 1, '电子产品', 1075, '2024-04-01', '华北', '孙七'),
(456.40, '已完成', 4, '电子产品', 1076, '2024-04-02', '华东', '周八'),
(567.20, '已完成', 5, '服装', 1077, '2024-04-03', '华南', '吴九'),
(123.40, '已完成', 1, '食品', 1078, '2024-04-04', '华北', '郑十'),
(234.80, '已完成', 2, '电子产品', 1079, '2024-04-05', '华东', '王一'),
(89.50, '已完成', 1, '服装', 1080, '2024-04-06', '华南', '李二'),
(1234.20, '已完成', 9, '电子产品', 1081, '2024-04-07', '华北', '张三'),
(345.60, '已完成', 3, '食品', 1082, '2024-04-08', '华东', '李四'),
(678.60, '已完成', 6, '电子产品', 1083, '2024-04-09', '华南', '王五'),
(156.80, '已完成', 1, '电子产品', 1084, '2024-04-10', '华北', '赵六'),
(456.50, '待处理', 4, '服装', 1085, '2024-04-11', '华东', '钱七'),
(567.30, '已完成', 5, '食品', 1086, '2024-04-12', '华南', '孙八'),
(234.70, '已完成', 2, '电子产品', 1087, '2024-04-13', '华北', '周九'),
(89.40, '已取消', 1, '服装', 1088, '2024-04-14', '华东', '吴十'),
(1234.40, '已完成', 8, '电子产品', 1089, '2024-04-15', '华南', '郑一'),
(345.80, '已完成', 3, '食品', 1090, '2024-04-16', '华北', '王二'),
(678.70, '已完成', 6, '电子产品', 1091, '2024-04-17', '华东', '李三'),
(156.30, '待处理', 1, '服装', 1092, '2024-04-18', '华南', '张四'),
(456.70, '已完成', 4, '电子产品', 1093, '2024-04-19', '华北', '赵五'),
(567.50, '已完成', 5, '食品', 1094, '2024-04-20', '华东', '钱六'),
(234.60, '已完成', 2, '电子产品', 1095, '2024-04-21', '华南', '孙七'),
(89.80, '已完成', 1, '服装', 1096, '2024-04-22', '华北', '周八'),
(1234.50, '已完成', 10, '电子产品', 1097, '2024-04-23', '华东', '吴九'),
(345.40, '已完成', 3, '食品', 1098, '2024-04-24', '华南', '郑十'),
(678.90, '已完成', 6, '电子产品', 1099, '2024-04-25', '华北', '王一'),
(156.50, '已完成', 1, '电子产品', 1100, '2024-04-26', '华东', '李二');了解表的整体结构
首先,我们需要知道表中有多少行数据,有多少列,以及每一列的数据类型。虽然不同数据库系统的语法略有不同,但基本思路是相似的。在大多数数据库中,我们可以使用以下查询来获取表的基本信息:
SELECT COUNT(*) AS 总行数 FROM 订单表;这个简单的查询告诉我们表中有多少条记录。知道数据量的大小很重要,因为它会影响我们后续分析的方法和工具选择。如果数据量很小(比如几千条),我们可以直接在Excel中处理;如果数据量很大(比如几百万条),我们可能需要先在SQL中进行预处理。
Output:
+-----------+
| 总行数 |
+-----------+
| 100 |
+-----------+接下来,我们想要了解每一列的基本情况。对于数值型列,我们通常关心最小值、最大值、平均值、中位数等统计指标;对于文本型列,我们关心有多少个不同的值,每个值出现的频率等。
探索数值列:基本统计量
假设我们有一张销售订单表,其中包含了订单金额这个数值列。我们想要了解订单金额的分布情况,可以这样查询:
SELECT
COUNT(*) AS 订单数量,
MIN(订单金额) AS 最小金额,
MAX(订单金额) AS 最大金额,
AVG(订单金额) AS 平均金额,
SUM(订单金额) AS 总金额
FROM 订单表;Output:
+--------------+--------------+--------------+--------------+-----------+
| 订单数量 | 最小金额 | 最大金额 | 平均金额 | 总金额 |
+--------------+--------------+--------------+--------------+-----------+
| 100 | 45.30 | 1234.90 | 402.341000 | 40234.10 |
+--------------+--------------+--------------+--------------+-----------+这个查询一次性返回了订单金额的几个关键统计指标。COUNT(*)统计订单总数,MIN()和MAX()告诉我们订单金额的范围,AVG()计算平均值,SUM()计算总和。这些基本统计量能够快速给我们一个数据分布的概览。
但是,仅仅知道平均值和最大值、最小值还不够。如果最大值特别大,而平均值相对较小,说明数据可能存在极端值(异常值)。为了更好地理解数据分布,我们还需要查看中位数和分位数。
使用分位数理解数据分布
分位数能够帮助我们更好地理解数据的分布特征。比如,中位数(50%分位数)能够告诉我们有一半的数据小于这个值,一半的数据大于这个值。如果平均值和中位数相差很大,说明数据分布可能偏斜。
在SQL中,我们可以使用窗口函数来计算分位数。不过,更直接的方法是使用数据库系统提供的分位数函数。比如,在PostgreSQL中:
SELECT
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY 订单金额) AS 中位数,
PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY 订单金额) AS 第一四分位数,
PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY 订单金额) AS 第三四分位数
FROMOutput:
CREATE TABLE
INSERT 0 100
中位数 | 第一四分位数 | 第三四分位数
--------+--------------+--------------
345.25 | 156.275 | 567.425
(1 row)这些分位数能够帮助我们理解数据的分布情况。如果第一四分位数、中位数和第三四分位数比较接近,说明大部分数据都集中在一个较小的范围内;如果它们相差很大,说明数据分布比较分散。
探索类别列:频率统计
对于类别型数据(比如订单状态、产品类别等),我们通常关心每个类别出现的频率。这能够帮助我们了解数据的分布是否均匀,是否存在某些类别占主导地位的情况。
SELECT 订单状态, COUNT(*) AS 数量,
ROUND(COUNT(*) * 100.0 / (SELECT COUNT(*) FROM 订单表), 2) AS 百分比
FROM 订单表
GROUP BY 订单状态
ORDER BY 数量 DESC;这个查询按照订单状态分组,统计每个状态的订单数量和占比。GROUP BY将数据按照订单状态分组,COUNT(*)统计每组中的记录数,子查询计算总数用于计算百分比。通过查看百分比,我们能够快速了解各个类别的相对重要性。
Output:
+--------------+--------+-----------+
| 订单状态 | 数量 | 百分比 |
+--------------+--------+-----------+
| 已完成 | 76 | 76.00 |
| 待处理 | 16 | 16.00 |
| 已取消 | 8 | 8.00 |
+--------------+--------+-----------+探索字符串列:发现隐藏的模式
字符串列往往包含丰富的信息,但也更容易出现数据质量问题。探索字符串列需要我们特别仔细,因为字符串的格式可能不统一,可能存在拼写错误、多余的空格、不一致的大小写等问题。
检查字符串长度分布
首先,我们可以检查字符串列的长度分布,这能够帮助我们发现异常值。比如,如果某个字段应该是固定长度的(比如身份证号),但实际数据中长度不一致,说明可能存在数据质量问题。
SELECT
LENGTH(客户姓名) AS 姓名长度,
COUNT(*) AS 数量
FROM 客户表
GROUP BY LENGTH(客户姓名)
ORDER BY 姓名长度;这个查询统计了不同长度的客户姓名的数量。如果发现某些长度明显异常(比如特别短或特别长),我们就需要进一步检查这些数据。
查找重复和相似值
字符串列中可能存在重复值或相似值,这些可能是数据录入错误导致的。我们可以使用一些简单的查询来发现这些问题:
SELECT 客户姓名, COUNT(*) AS 出现次数
FROM 客户表
GROUP BY 客户姓名
HAVING COUNT(*) > 1
ORDER BY 出现次数 DESC;这个查询找出所有出现多次的客户姓名。如果同一个姓名出现了多次,可能是重复数据,也可能是不同的客户恰好同名。我们需要根据业务逻辑来判断。
检查字符串格式
有时候,我们需要检查字符串是否符合特定的格式。比如,邮箱地址应该包含"@"符号,电话号码应该符合特定的格式等。我们可以使用SQL的字符串函数来进行这些检查:
SELECT
COUNT(*) AS 总记录数,
SUM(CASE WHEN 邮箱 LIKE '%@%' THEN 1 ELSE 0 END) AS 有效邮箱数,
SUM(CASE WHEN 邮箱 NOT LIKE '%@%' THEN 1 ELSE 0 END) AS 无效邮箱数
FROM 客户表;这个查询使用LIKE操作符和CASE WHEN语句来检查邮箱格式。LIKE '%@%'匹配包含"@"符号的字符串,我们统计有效和无效邮箱的数量,从而了解数据质量。
探索列之间的关系
数据探索不仅仅是了解每一列的情况,更重要的是理解列与列之间的关系。这些关系可能是因果关系,也可能是相关关系,发现这些关系能够帮助我们更好地理解业务逻辑。
数值列之间的相关性
假设我们想要了解订单金额和订单商品数量之间的关系。我们可以先计算一些基本的统计量:
SELECT
AVG(订单金额) AS 平均金额,
AVG(商品数量) AS 平均数量,
COUNT(*) AS 订单数
FROM 订单表;但是,仅仅知道平均值还不够。我们想要更详细地了解这两个变量之间的关系,可以按照商品数量分组,查看不同数量下的平均订单金额:
SELECT
商品数量,
COUNT(*) AS 订单数,
AVG(订单金额) AS 平均金额,
MIN(订单金额) AS 最小金额,
MAX(订单金额) AS 最大金额
FROM 订单表
GROUP BY 商品数量
ORDER BY 商品数量;这个查询能够帮助我们发现商品数量和订单金额之间是否存在某种关系。如果随着商品数量的增加,平均订单金额也增加,说明这两个变量之间存在正相关关系。
类别列和数值列的关系
我们经常需要分析不同类别下的数值分布。比如,我们想要了解不同产品类别的平均销售额:
SELECT
产品类别,
COUNT(*) AS 订单数,
AVG(订单金额) AS 平均金额,
SUM(订单金额) AS 总金额
FROM 订单表
GROUP BY 产品类别
ORDER BY 总金额 DESC;这个查询按照产品类别分组,统计每个类别的订单数、平均金额和总金额。通过比较不同类别的这些指标,我们能够发现哪些类别表现更好,哪些类别可能需要关注。
交叉分析:多维度探索
有时候,我们需要同时考虑多个维度。比如,我们想要了解不同地区和不同产品类别的销售情况:
SELECT
地区,
产品类别,
COUNT(*) AS 订单数,
AVG(订单金额) AS 平均金额,
SUM(订单金额) AS 总金额
FROM 订单表
GROUP BY 地区, 产品类别
ORDER BY 地区, 总金额 DESC;这个查询按照地区和产品类别两个维度进行分组,能够帮助我们发现不同地区对不同产品类别的偏好。这种交叉分析往往能够揭示一些单维度分析无法发现的规律。
使用Excel进行数据可视化
SQL查询能够帮助我们获取数据的统计信息,但有时候数字本身不够直观。Excel的可视化功能能够将数据转化为图表,让我们更直观地理解数据的特征和规律。
准备数据:从SQL到Excel
在开始Excel可视化之前,我们需要先将SQL查询的结果导出到Excel。大多数数据库管理工具都提供了导出功能,我们可以直接将查询结果保存为CSV或Excel格式。
在导出数据时,要注意数据量的大小。如果数据量太大,可能会影响Excel的性能。在这种情况下,我们应该先在SQL中进行聚合,只导出汇总后的数据。
创建基本图表:柱状图和折线图
Excel提供了丰富的图表类型,我们可以根据数据的特征和分析目的选择合适的图表。对于类别数据,柱状图是一个很好的选择。
假设我们已经将产品类别的销售数据导入到Excel中。要创建柱状图,我们首先选中数据区域,包括类别名称和对应的销售额。然后,在"插入"选项卡中选择"柱状图",Excel会自动生成图表。
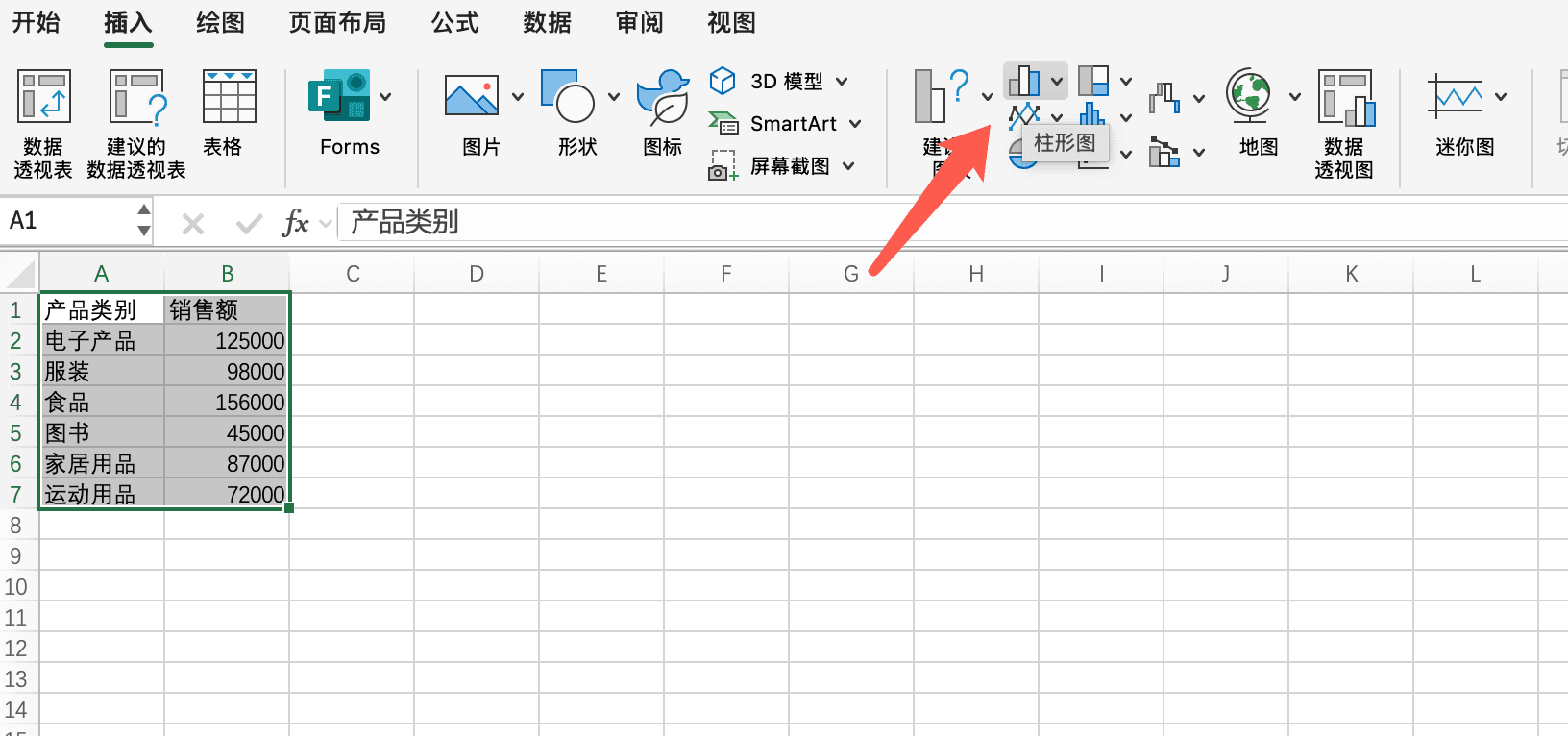
柱状图能够直观地比较不同类别的数值大小。如果某个类别的柱子特别高,说明这个类别的销售额特别大;如果某个类别的柱子特别低,说明这个类别可能需要关注。
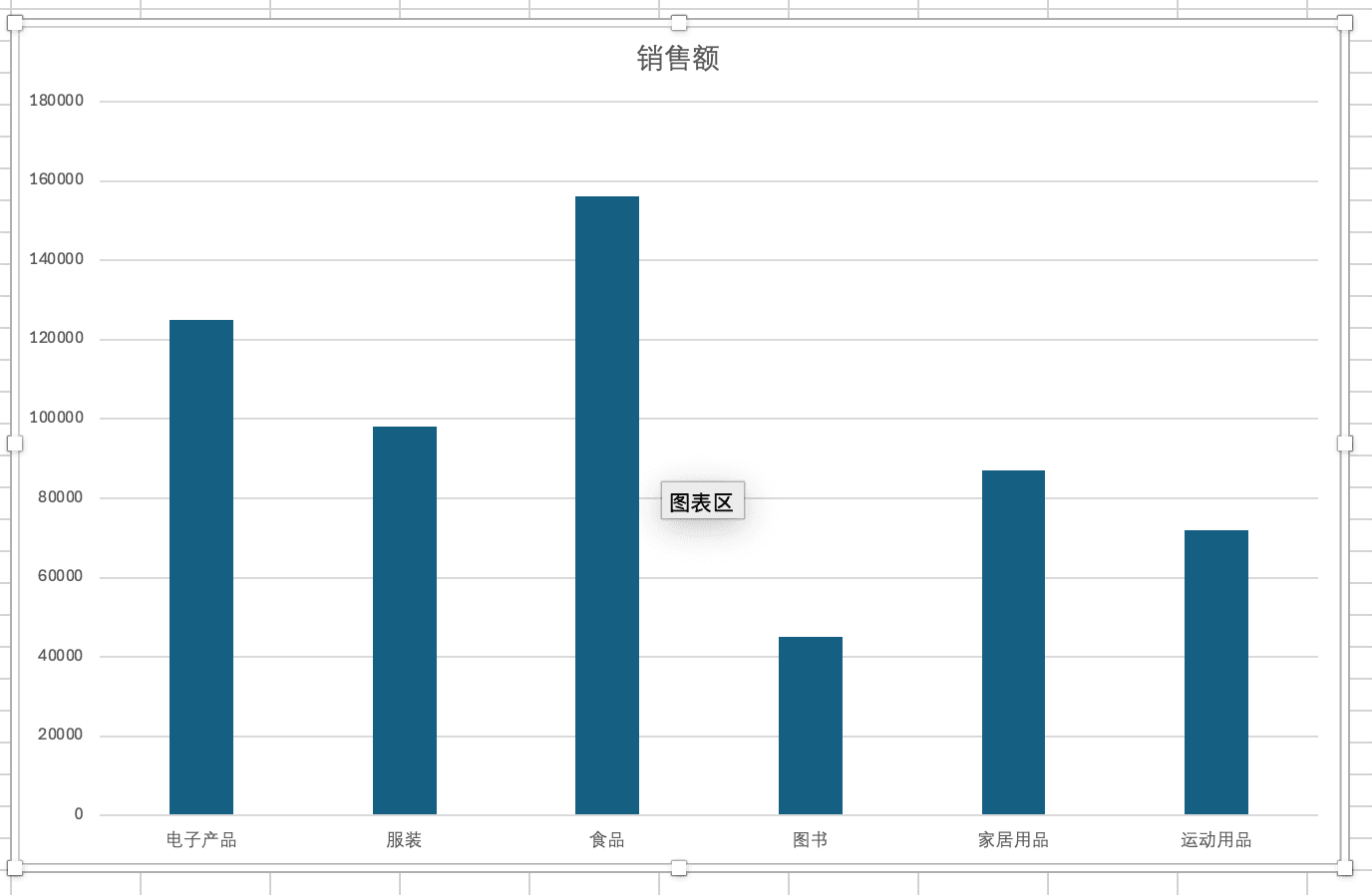
对于时间序列数据,折线图更加合适。折线图能够清晰地展示数据随时间变化的趋势。比如,我们可以用折线图来展示每个月的销售额变化,这样能够很容易地看出销售额是上升、下降还是保持稳定。
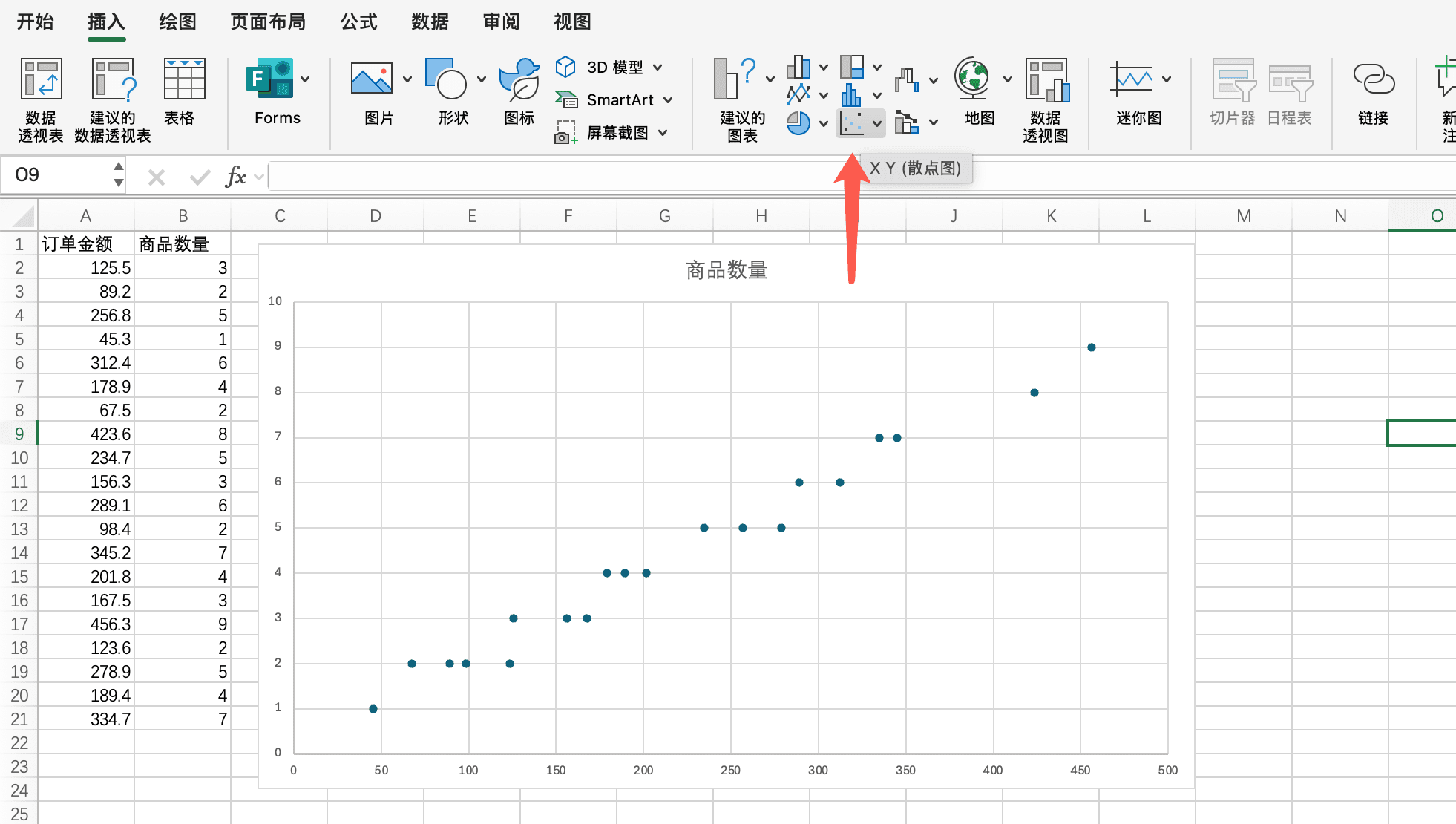
使用散点图探索变量关系
当我们想要探索两个数值变量之间的关系时,散点图是最佳选择。散点图将每个数据点绘制在二维坐标系中,横轴和纵轴分别代表两个变量。
比如,我们想要探索订单金额和商品数量之间的关系。我们可以将订单金额作为横轴,商品数量作为纵轴,每个订单对应一个点。如果这些点大致形成一条向上的直线,说明订单金额和商品数量之间存在正相关关系;如果点分布比较随机,说明两者之间可能没有明显的关系。
在Excel中创建散点图很简单。我们选中包含两个数值列的数据区域,然后在"插入"选项卡中选择"散点图"。Excel会自动生成散点图,我们还可以添加趋势线来更清晰地展示变量之间的关系。
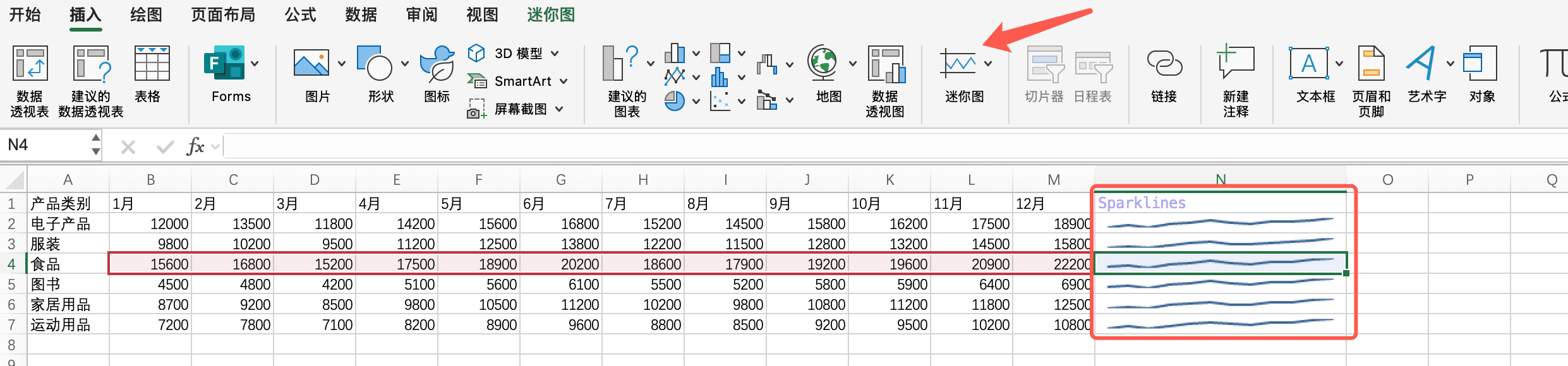
Sparklines:单元格内的迷你图表
Sparklines是Excel中一个非常有用的功能,它能够在单个单元格内显示迷你图表。这对于在表格中同时展示数据和趋势非常有用。
假设我们有一个包含每个月销售额的表格。我们可以在表格旁边添加一列,使用Sparklines来显示每个产品类别的销售趋势。这样,我们既能看到具体的数据,又能看到趋势,一举两得。
要创建Sparklines,我们首先选中要显示Sparklines的单元格,然后在"插入"选项卡中选择"Sparklines"。Excel会要求我们选择数据范围,我们选择对应行的数据,Sparklines就会自动生成。
数据透视表:快速汇总和分析
数据透视表是Excel中最强大的数据分析工具之一。它能够快速地对数据进行汇总、分组和分析,而且操作非常简单。
假设我们有一个包含订单详细信息的数据表,包括订单日期、产品类别、地区、订单金额等字段。我们想要快速了解不同地区、不同产品类别的销售情况,使用数据透视表是最简单的方法。
要创建数据透视表,我们首先选中数据区域,然后在"插入"选项卡中选择"数据透视表"。Excel会弹出一个对话框,让我们选择数据源和放置位置。接下来,我们将字段拖拽到相应的区域:行区域、列区域、值区域。比如,我们可以将"地区"拖到行区域,"产品类别"拖到列区域,"订单金额"拖到值区域,Excel会自动生成一个交叉汇总表。
数据透视表的优势在于它的灵活性。我们可以随时调整字段的位置,改变汇总方式(求和、平均值、计数等),添加筛选条件,而且所有的操作都是实时的,不需要重新计算。
从单列汇总到全表汇总
在实际的数据探索中,我们往往需要从多个角度、多个维度来审视数据。单列的分析只能告诉我们这一列的情况,但数据是一个整体,各个列之间可能存在复杂的相互关系。
构建全面的数据概览
我们可以创建一个综合的SQL查询,一次性获取多个列的基本统计信息。虽然这个查询可能会比较长,但它能够给我们一个全面的数据概览:
SELECT
'订单金额' AS 列名,
COUNT(*) AS 记录数,
COUNT(DISTINCT 订单金额) AS 不同值数,
MIN(订单金额) AS 最小值,
MAX(订单金额) AS 最大值,
AVG(订单金额) AS 平均值,
SUM(CASE WHEN 订单金额 IS NULL THEN 1 ELSE 0 END
这个查询使用UNION ALL将多个查询的结果合并在一起,每一行代表一个列的统计信息。通过这个查询,我们能够快速了解表中所有重要列的基本情况。
识别数据质量问题
在数据探索的过程中,我们不仅要了解数据的基本特征,还要识别数据质量问题。常见的数据质量问题包括缺失值、异常值、重复值、格式不一致等。
我们可以创建一个查询来系统地检查这些问题:
SELECT
'缺失值检查' AS 检查类型,
SUM(CASE WHEN 订单金额 IS NULL THEN 1 ELSE 0 END) AS 订单金额缺失数,
SUM(CASE WHEN 客户ID IS NULL THEN 1 ELSE 0 END) AS 客户ID缺失数,
SUM(CASE WHEN 订单日期 IS NULL THEN
这个查询帮助我们系统地检查数据质量问题。发现这些问题后,我们需要根据业务逻辑来判断这些是真正的异常,还是合理的数据,然后决定如何处理。
构建数据探索报告
数据探索的最终目的是生成一份全面的数据探索报告。这份报告应该包括数据的基本信息、数据质量评估、主要发现以及后续分析的建议。
我们可以将SQL查询的结果和Excel图表结合起来,创建一份完整的数据探索报告。报告中应该包括数据概览、各列的详细分析、列之间的关系分析、数据质量评估等内容。这份报告不仅能够帮助我们理解数据,还能够为后续的深入分析提供指导。
课程小结
本节课我们系统梳理了数据探索的核心流程和要点。从基本数据统计、异常值检测到多维关系分析,我们通过SQL高效获取数据特征,用Excel直观呈现数据分布,使得对数据全貌的理解更为清晰。 数据探索不仅是分析工作的起点,也是指导后续建模与决策的重要基石。这个过程中,持续关注数据质量、敏感捕捉数据中的隐藏信息尤为关键。
总而言之,专业的数据探索要求我们既要借助工具提升分析效率,也要保持开放、质疑和批判的思维,不断回溯和完善。