SQL中的数据挖掘模型
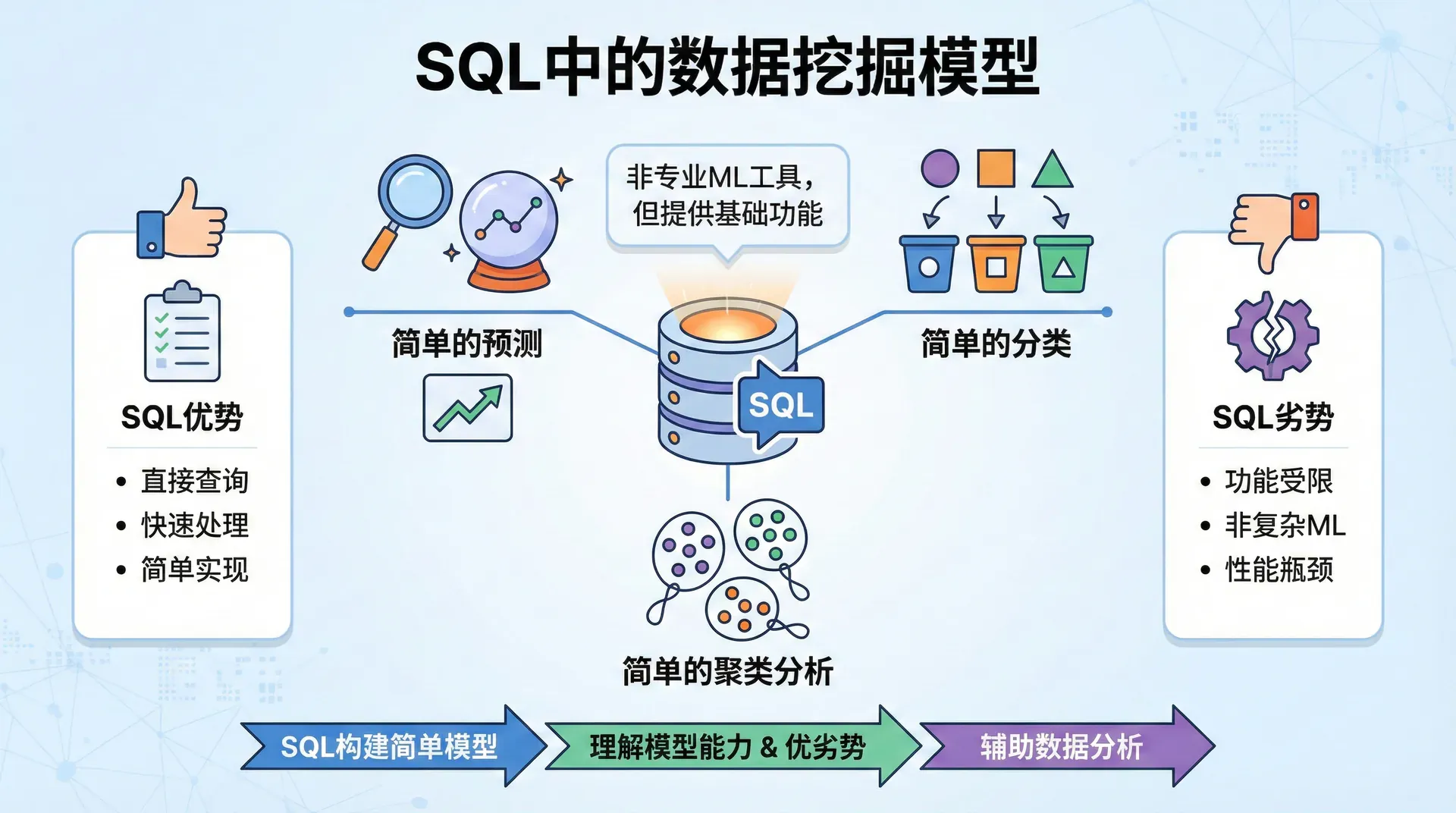
SQL虽然主要是用于数据查询的语言,但在某些情况下,我们也可以使用SQL来构建简单的数据挖掘模型。虽然SQL不能替代专业的机器学习工具,但它提供了一些基础功能,能够帮助我们进行简单的预测、分类和聚类分析。 这节课我们将探索SQL在数据挖掘中的能力,学习如何在SQL中构建简单的模型,并理解SQL的优劣势。
简单的分类模型
虽然SQL不能实现复杂的分类算法,但我们可以使用一些简单的规则来构建分类模型。这些模型虽然简单,但在某些场景下已经足够用了。
让我们先创建一些测试数据,帮助我们理解分类模型的构建过程:
-- 创建客户测试表
CREATE TABLE 客户分类测试表 (
客户ID INT,
年龄 INT,
年收入 DECIMAL(10,2),
购买次数 INT,
总消费金额 DECIMAL(10,2),
是否高价值客户 INT -- 1表示高价值,0表示普通客户
);
-- 插入测试数据
INSERT INTO 客户分类测试表 VALUES
(1, 25, 50000, 3, 1500, 0),
(2, 35, 80000, 8, 4800, 1),
(3, 28, 45000, 2, 800, 0),
(4, 42, 120000, 12, 12000, 1),
(5, 30, 60000, 5, 3000, 1),
(6, 22, 35000, 1, 500, 0),
(7, 38, 95000, 10, 9500, 1),
(8, 26, 48000, 2, 960, 0);这个测试数据包含了8个客户的信息,包括年龄、年收入、购买次数、总消费金额,以及是否高价值客户的标签。我们可以基于这些特征来构建分类模型。
基于规则的分类
最简单的分类方法是基于规则。我们可以根据一些简单的条件来判断客户是否高价值。比如,我们可以定义:如果年收入大于80000且购买次数大于5,则为高价值客户。
SELECT
客户ID,
年龄,
年收入,
购买次数,
总消费金额,
CASE
WHEN 年收入 >= 80000 AND 购买次数 >= 5 THEN 1
WHEN 年收入 >= 60000 AND 购买次数 >= 3 THEN 1
ELSE 0
END AS 预测高价值,
是否高价值客户 AS 实际高价值,
CASE
+----------+--------+-----------+--------------+-----------------+-----------------+-----------------+--------------+
| 客户ID | 年龄 | 年收入 | 购买次数 | 总消费金额 | 预测高价值 | 实际高价值 | 预测正确 |
+----------+--------+-----------+--------------+-----------------+-----------------+-----------------+--------------+
| 1 | 25 | 50000.00 | 3 | 1500.00 | 0 | 0 | 1 |
| 2
这个查询使用CASE语句来构建分类规则,并计算预测准确性。从结果中,我们能够看到哪些客户被正确分类,哪些被错误分类,从而评估模型效果。
评估分类模型
要评估分类模型的效果,我们可以计算准确率、精确率、召回率等指标:
WITH 分类结果 AS (
SELECT
客户ID,
CASE
WHEN 年收入 >= 80000 AND 购买次数 >= 5 THEN 1
WHEN 年收入 >= 60000 AND 购买次数 >= 3 THEN 1
ELSE 0
END AS 预测值,
是否高价值客户 AS 实际值
FROM 客户分类测试表
+-----------+-----------+-----------+-----------+--------+-----------+-----------+-----------+
| 真正例 | 假正例 | 假负例 | 真负例 | 总数 | 准确率 | 精确率 | 召回率 |
+-----------+-----------+-----------+-----------+--------+-----------+-----------+-----------+
| 4 | 0 | 0 | 4 | 8 | 100.00 | 100.00 | 100.00 |
+-----------+-----------+-----------+-----------+--------+-----------+-----------+-----------+这个查询计算分类模型的评估指标。准确率表示所有预测中正确的比例,精确率表示预测为正例中实际为正例的比例,召回率表示实际为正例中被正确预测的比例。这些指标帮助我们理解模型的性能。
简单的聚类分析
聚类分析是将相似的数据点分组的过程。虽然SQL不能实现复杂的聚类算法(如K-means),但我们可以使用一些简单的方法来进行基础的聚类。
基于阈值的聚类
最简单的方法是使用阈值来划分数据。比如,我们可以根据总消费金额将客户分为高消费、中消费、低消费三个群体:
SELECT
客户ID,
总消费金额,
CASE
WHEN 总消费金额 >= 5000 THEN '高消费'
WHEN 总消费金额 >= 2000 THEN '中消费'
ELSE '低消费'
END AS 消费群体,
COUNT(*) OVER (PARTITION BY
CASE
WHEN 总消费金额 >= 5000 THEN
+----------+-----------------+--------------+-----------------+
| 客户ID | 总消费金额 | 消费群体 | 群体客户数 |
+----------+-----------------+--------------+-----------------+
| 4 | 12000.00 | 高消费 | 2 |
| 7 | 9500.00 | 高消费 | 2 |
| 2 | 4800.00 | 中消费 | 2 |
|
这个查询使用CASE语句和窗口函数来进行简单的聚类。虽然这种方法很简单,但在某些场景下已经足够用了。
基于多特征的聚类
我们可以同时考虑多个特征来进行聚类。比如,我们可以根据年收入和购买次数来划分客户:
SELECT
客户ID,
年收入,
购买次数,
CASE
WHEN 年收入 >= 80000 AND 购买次数 >= 5 THEN '高价值高活跃'
WHEN 年收入 >= 80000 AND 购买次数 < 5 THEN '高价值低活跃'
WHEN 年收入 < 80000 AND 购买次数 >= 5 THEN '低价值高活跃'
ELSE '低价值低活跃'
END
+----------+-----------+--------------+--------------------+--------------------+
| 客户ID | 年收入 | 购买次数 | 客户群体 | 群体平均消费 |
+----------+-----------+--------------+--------------------+--------------------+
| 4 | 120000.00 | 12 | 高价值高活跃 | 8766.666667 |
| 7 | 95000.00 | 10 | 高价值高活跃 | 8766.666667 |
| 2 | 80000.00
这个查询根据年收入和购买次数将客户分为四个群体。通过分析每个群体的特征,我们能够更好地理解不同类型的客户。
SQL数据挖掘模型的优劣势
通过上面的例子,我们可以看到SQL在数据挖掘中的一些能力和局限。让我们系统地总结一下SQL数据挖掘模型的优劣势。
SQL的优势
SQL在数据挖掘中有几个明显的优势。首先,SQL可以直接在数据库中操作数据,不需要将数据导出到其他工具,这对于大数据场景特别有用。数据不需要移动,减少了数据传输的开销和风险。
其次,SQL的语法相对简单,学习曲线平缓。大多数数据分析师都熟悉SQL,不需要学习新的工具或语言。这使得SQL模型更容易被团队理解和维护。
最后,SQL查询的结果可以直接用于后续的分析和可视化。我们可以将SQL查询的结果导出到Excel,或者直接在BI工具中使用,流程非常顺畅。
SQL的局限性
但SQL也有明显的局限性。首先,SQL不是为机器学习设计的,它缺乏专门的机器学习算法和工具。复杂的模型(如神经网络、随机森林、支持向量机等)无法在SQL中实现。
其次,即使是一些简单的模型,在SQL中实现也可能非常复杂,代码难以维护。比如,要实现一个简单的决策树,可能需要写很多嵌套的CASE语句,代码可读性很差。
最后,SQL模型的性能可能不如专门的机器学习工具。虽然SQL在处理大数据时有一定优势,但在模型训练和优化方面,专门的机器学习工具通常更高效。
SQL适合构建简单的、基于规则的模型,但不适合构建复杂的机器学习模型。在实际工作中,我们应该根据具体需求选择合适的工具。
SQL适合构建简单的、基于规则的模型。比如,我们可以使用SQL来:
- 基于阈值的分类(如高价值客户识别)
- 简单的聚类(如客户分群)
- 基于历史平均值的预测(如销售预测)
- 基于规则的推荐(如产品推荐)
这些场景的共同特点是:模型逻辑简单,不需要复杂的算法,主要依赖业务规则和统计方法。
对于复杂的模型,我们应该使用专门的机器学习工具,如Python的scikit-learn、R、或者云平台的机器学习服务。这些工具提供了丰富的算法和工具,能够构建更复杂、更准确的模型。
比如,如果我们需要构建一个复杂的客户流失预测模型,涉及多个特征和复杂的非线性关系,使用Python或R会更合适。这些工具提供了决策树、随机森林、神经网络等算法,能够处理更复杂的问题。
课程小结
通过本节课的学习,我们了解了SQL在数据挖掘中的应用及其局限。SQL虽不是专门的机器学习工具,但可以用来实现如基于规则的分类、简单聚类、历史平均值预测等基础模型,优势在于直接操作库内数据、语法简单、结果对接分析流程十分便捷。
在实践中建议:先从简单方法尝试,若效果良好无需引入复杂工具,同时要清楚SQL的边界,避免其承担所有模型任务。在下一节课中,我们将学习线性回归模型,深入探索线性回归的理论和实现。