找出关键特征
在上节课我们学习了如何分析客户的留存情况。但仅仅知道客户留存率是不够的,更重要的是理解为什么某些客户留存率高,某些客户留存率低。因此这一堂课,我们将通过实际的测试数据,逐步探索影响客户留存的各种因素,学习如何识别关键特征,并构建简单的预测模型来识别流失风险客户。
理解客户特征与留存的关系
要找出影响客户留存的因素,我们首先需要理解客户特征与留存之间的关系。不同的客户有着不同的特征:注册渠道、首次购买金额、购买频率、产品偏好等。这些特征可能与客户的留存表现有关。
准备测试数据
让我们先创建一个简单的测试数据集,帮助我们理解分析过程。假设我们有一个客户表,包含以下字段:
-- 创建测试数据示例
CREATE TABLE 客户测试表 (
客户ID INT,
注册日期 DATE,
注册渠道 VARCHAR(20),
首次购买金额 DECIMAL(10,2),
所在城市 VARCHAR(20),
是否流失 INT -- 1表示流失,0表示未流失
);
-- 插入一些测试数据
INSERT INTO 客户测试表 VALUES
(1, '2024-01-15', '线上广告', 299.00, '北京', 0),
(2, '2024-01-20', '朋友推荐', 599.00, '上海', 0),
(3, '2024-02-01', '搜索引擎', 199.00, '广州', 1),
(4, '2024-02-10', '朋友推荐', 899.00, '深圳', 0),
(5, '2024-02-15', '线上广告', 149.00, '北京', 1),
(6, '2024-03-01', '社交媒体', 399.00, '上海', 0),
(7, '2024-03-10', '朋友推荐', 699.00, '杭州', 0),
(8, '2024-03-20', '搜索引擎', 249.00, '成都', 1);这个测试数据包含了8个客户的基本信息和流失状态。虽然数据量很小,但足够我们理解分析过程。在实际工作中,我们会使用更大的数据集,但分析方法是一样的。
观察不同特征的留存率
现在让我们看看不同注册渠道的客户留存率有什么不同:
SELECT
注册渠道,
COUNT(*) AS 客户总数,
SUM(是否流失) AS 流失客户数,
COUNT(*) - SUM(是否流失) AS 留存客户数,
ROUND((COUNT(*) - SUM(是否流失)) * 100.0 / COUNT(*), 2) AS
这个查询会返回类似这样的结果:
+--------------+--------------+-----------------+-----------------+-----------+
| 注册渠道 | 客户总数 | 流失客户数 | 留存客户数 | 留存率 |
+--------------+--------------+-----------------+-----------------+-----------+
| 朋友推荐 | 3 | 0 | 3 | 100.00 |
| 社交媒体 | 1 | 0 | 1 | 100.00 |
| 线上广告 | 2
从这个结果可以看出,通过"朋友推荐"和"社交媒体"注册的客户留存率最高,而通过"搜索引擎"注册的客户留存率最低。这可能说明朋友推荐的客户对产品更有信任,而搜索引擎来的客户可能只是临时搜索,兴趣不高。
虽然测试数据量很小,但已经能够展示分析思路。在实际工作中,我们需要更大的样本量才能得出可靠的结论。
分析首次购买金额的影响
让我们看看首次购买金额是否影响客户留存:
SELECT
CASE
WHEN 首次购买金额 < 200 THEN '低金额(<200)'
WHEN 首次购买金额 < 500 THEN '中金额(200-500)'
ELSE '高金额(>500)'
END AS 首次购买金额区间,
COUNT(*) AS 客户总数,
SUM(是否流失) AS 流失客户数,
ROUND((COUNT(*) - SUM(是否流失))
+--------------------------+--------------+-----------------+-----------+
| 首次购买金额区间 | 客户总数 | 流失客户数 | 留存率 |
+--------------------------+--------------+-----------------+-----------+
| 高金额(>500) | 3 | 0 | 100.00 |
| 中金额(200-500) | 3 | 1 | 66.67 |
| 低金额(<200) | 2 |
这个查询将首次购买金额分成三个区间,然后计算每个区间的留存率。从结果中,我们可能会发现首次购买金额越高的客户,留存率也越高。这可能是因为高金额购买表示客户对产品更认可,或者客户本身消费能力更强。
构建客户特征表
要进行更深入的分析,我们需要构建一个包含各种客户特征的表。这个表应该包括客户的基本信息、购买行为、互动情况等。
扩展测试数据
让我们创建一个更完整的测试数据集,包含更多的客户特征:
-- 创建更完整的客户特征表
CREATE TABLE 客户特征表 (
客户ID INT,
注册日期 DATE,
注册渠道 VARCHAR(20),
首次购买金额 DECIMAL(10,2),
所在城市 VARCHAR(20),
总订单数 INT,
总消费金额 DECIMAL(10,2),
平均订单金额 DECIMAL
这个扩展的数据表包含了更多的客户特征:总订单数、总消费金额、平均订单金额、最后购买日期等。这些特征可能都与客户留存有关。
分析多个特征
现在我们可以同时分析多个特征对留存的影响。比如,我们想看看不同注册渠道和不同首次购买金额区间的组合,留存率有什么不同:
SELECT
注册渠道,
CASE
WHEN 首次购买金额 < 300 THEN '低金额'
WHEN 首次购买金额 < 600 THEN '中金额'
ELSE '高金额'
END AS 首次购买金额区间,
COUNT(*) AS 客户数,
SUM(是否流失) AS 流失数,
ROUND((COUNT(*) - SUM
+--------------+--------------------------+-----------+-----------+-----------+
| 注册渠道 | 首次购买金额区间 | 客户数 | 流失数 | 留存率 |
+--------------+--------------------------+-----------+-----------+-----------+
| 搜索引擎 | 低金额 | 2 | 2 | 0.00 |
| 朋友推荐 | 中金额 | 1 | 0 | 100.00 |
| 朋友推荐 | 高金额
这个查询会展示不同注册渠道和首次购买金额区间的组合留存率。通过这种交叉分析,我们可能会发现某些组合的留存率特别高或特别低,这些发现能够帮助我们更好地理解客户行为。
分析购买行为特征
购买行为特征,如总订单数、总消费金额、平均订单金额等,也可能影响客户留存。让我们分析一下:
SELECT
CASE
WHEN 总订单数 = 1 THEN '仅1单'
WHEN 总订单数 <= 3 THEN '2-3单'
WHEN 总订单数 <= 5 THEN '4-5单'
ELSE '6单以上'
END AS 订单数区间,
COUNT(*) AS 客户数,
SUM(是否流失) AS 流失数,
ROUND((COUNT
+-----------------+-----------+-----------+-----------+-----------------+
| 订单数区间 | 客户数 | 流失数 | 留存率 | 平均总消费 |
+-----------------+-----------+-----------+-----------+-----------------+
| 4-5单 | 1 | 0 | 100.00 | 1500.00 |
| 6单以上 | 4 | 0 | 100.00 | 6250.00 |
| 仅1单 | 2
从结果中,我们很可能会发现订单数越多的客户,留存率越高。这很直观:如果一个客户只买了一次就不再买了,他很可能已经流失了;而如果一个客户多次购买,说明他对产品满意,更可能继续购买。
识别关键影响因素
通过上面的分析,我们已经看到了一些可能影响客户留存的因素。现在我们需要更系统地识别哪些因素最重要,哪些因素影响较小。
计算特征与留存的相关性
虽然SQL不是专门的统计分析工具,但我们可以通过一些简单的方法来评估特征与留存的关系。一个简单的方法是计算不同特征值下的留存率差异:
-- 分析注册渠道的影响
SELECT
注册渠道,
COUNT(*) AS 客户数,
ROUND(AVG(是否流失), 2) AS 流失率,
ROUND(1 - AVG(是否流失), 2) AS 留存率,
ROUND(AVG(总消费金额), 2) AS 平均总消费
FROM 客户特征表
GROUP BY 注册渠道
ORDER BY+--------------+-----------+-----------+-----------+-----------------+
| 注册渠道 | 客户数 | 流失率 | 留存率 | 平均总消费 |
+--------------+-----------+-----------+-----------+-----------------+
| 朋友推荐 | 3 | 0.00 | 1.00 | 7533.33 |
| 社交媒体 | 1 | 0.00 | 1.00 | 2400.00 |
| 线上广告 | 2 |
这个查询计算每个注册渠道的流失率、留存率和平均总消费。流失率越低、留存率越高,说明这个渠道带来的客户质量越好。
对比分析:找出差异最大的特征
为了系统地找出哪些特征对留存最有影响,我们可以使用对比分析的方法,分别计算和比较不同特征分组下的留存率差异。例如,可以把客户按照“总消费金额”分成高消费、中消费和低消费三组,统计每组的留存率和人数。如果发现高消费客户的留存率显著高于低消费客户,就说明“总消费金额”这个特征对留存很关键。
同理,我们还可以对比其它特征,如注册渠道、首购金额、订单数等,把客户分别按照这些特征分组,对比各组的留存率。例如,统计“通过朋友推荐注册”的客户和“通过广告注册”的客户各自的留存率,或者把订单数分区间(如1单、2-3单、4-5单、6单以上),对比每个区间的留存表现,进而评估这些特征对客户留存的影响强弱。
SELECT
CASE
WHEN 总消费金额 < 1000 THEN '低消费(<1000)'
WHEN 总消费金额 < 5000 THEN '中消费(1000-5000)'
ELSE '高消费(>5000)'
END AS 消费区间,
COUNT(*) AS 客户数,
ROUND(AVG(是否流失), 2) AS 流失率,
ROUND(1 - AVG
+----------------------+-----------+-----------+-----------+
| 消费区间 | 客户数 | 流失率 | 留存率 |
+----------------------+-----------+-----------+-----------+
| 中消费(1000-5000) | 3 | 0.00 | 1.00 |
| 高消费(>5000) | 2 | 0.00 | 1.00 |
| 低消费(<1000) | 3 | 1.00
如果高消费客户的留存率明显高于低消费客户,说明总消费金额是一个重要的影响因素。我们可以用类似的方法分析其他特征,找出影响最大的几个因素。
组合特征分析
有时候,单个特征的影响可能不明显,但多个特征组合起来影响就很大。比如,单独看注册渠道或首次购买金额,可能差异不大,但"朋友推荐 + 高首次购买金额"的组合,留存率可能特别高。
SELECT
CASE
WHEN 注册渠道 = '朋友推荐' AND 首次购买金额 >= 500 THEN '朋友推荐+高金额'
WHEN 注册渠道 = '朋友推荐' THEN '朋友推荐+其他'
WHEN 首次购买金额 >= 500 THEN '其他渠道+高金额'
ELSE '其他'
END AS 特征组合,
COUNT(*) AS 客户数,
ROUND(AVG
+------------------------+-----------+-----------+-----------+
| 特征组合 | 客户数 | 流失率 | 留存率 |
+------------------------+-----------+-----------+-----------+
| 朋友推荐+高金额 | 3 | 0.00 | 1.00 |
| 其他 | 5 | 0.60 | 0.40 |
+------------------------+-----------+-----------+-----------+这个查询分析不同特征组合的留存率。通过这种分析,我们能够发现哪些特征组合最有利于客户留存,从而在营销和客户服务中重点关注这些组合。
构建简单的流失预测模型
基于我们识别出的关键特征,我们可以构建一个简单的流失预测模型。虽然SQL不是机器学习工具,但我们可以使用一些简单的规则来预测客户流失风险。
创建流失风险评分
我们可以根据客户的特征,给每个客户计算一个流失风险分数。分数越高,流失风险越大。比如,我们可以这样设计评分规则:
SELECT
客户ID,
注册渠道,
首次购买金额,
总订单数,
总消费金额,
距最后购买天数,
-- 计算流失风险分数(分数越高,风险越大)
CASE WHEN 注册渠道 = '搜索引擎' THEN 3 ELSE 0 END +
CASE WHEN 首次购买金额 < 200 THEN 2 ELSE 0 END +
CASE WHEN 总订单数 = 1 THEN 3 ELSE
+----------+--------------+--------------------+--------------+-----------------+-----------------------+--------------------+--------------+
| 客户ID | 注册渠道 | 首次购买金额 | 总订单数 | 总消费金额 | 距最后购买天数 | 流失风险分数 | 是否流失 |
+----------+--------------+--------------------+--------------+-----------------+-----------------------+--------------------+--------------+
| 3 | 搜索引擎 | 199.00 | 1 | 199.00 | 130 | 12 | 1 |
|
这个查询根据多个特征计算流失风险分数。每个特征根据其对流失的影响程度分配不同的分数,然后相加得到总分。从结果中,我们可以看到风险分数高的客户,是否真的流失了,从而验证评分规则是否有效。
验证模型效果
要验证模型效果,我们可以看看风险分数和实际流失情况的关系:
SELECT
CASE
WHEN 流失风险分数 >= 7 THEN '高风险'
WHEN 流失风险分数 >= 4 THEN '中风险'
ELSE '低风险'
END AS 风险等级,
COUNT(*) AS 客户数,
SUM(是否流失) AS 实际流失数,
ROUND(AVG(是否流失) * 100, 2) AS
+--------------+-----------+-----------------+-----------------+
| 风险等级 | 客户数 | 实际流失数 | 实际流失率 |
+--------------+-----------+-----------------+-----------------+
| 高风险 | 2 | 2 | 100.00 |
| 中风险 | 1 | 1 | 100.00 |
| 低风险 | 5 | 0 | 0.00 |
+--------------+-----------+-----------------+-----------------+这个查询将客户按照风险等级分组,然后计算每个风险等级的实际流失率。如果高风险客户的流失率明显高于低风险客户,说明我们的模型是有效的。
优化评分规则
如果模型效果不理想,我们可以调整评分规则。比如,如果发现某个特征的影响比预期大,我们可以增加它的权重;如果某个特征影响不大,我们可以减少它的权重或者移除它。
在实际工作中,我们可以使用Excel来帮助优化评分规则。我们可以将SQL查询结果导出到Excel,然后尝试不同的权重组合,看看哪种组合的预测效果最好。
使用Excel进行特征分析
Excel提供了强大的功能来帮助我们进行特征分析和模型构建。虽然Excel不是专门的机器学习工具,但对于简单的预测模型,Excel已经足够用了。
准备分析数据
首先,我们将SQL查询结果导出到Excel。数据应该包括客户的各种特征和是否流失的标签。在Excel中,我们可以更方便地进行各种分析和可视化。
下面是一组可以直接复制粘贴到Excel中进行测试的客户数据。我们打开Excel,新建一个工作表,然后将以下数据复制粘贴到A1单元格开始的位置:
客户ID 注册日期 注册渠道 首次购买金额 总订单数 总消费金额 距最后购买天数 所在城市 是否流失
1001 2023-01-15 线上广告 299.00 3 1250.00 15 北京 0
1002 2023-01-20 朋友推荐 599.00 8 4560.00 5 上海 0
1003 2023-02-01 搜索引擎 199.00 1 199.00 75 广州 1
1004 2023-02-10 朋友推荐 899.00 12 7890.00 8 深圳 0
1005 2023-02-15 线上广告 149.00 1 149.00 82 北京 1
1006 2023-03-01 社交媒体 399.00 5 2150.00 12 上海 0
1007 2023-03-10 朋友推荐 699.00 9 5620.00 6 杭州 0
1008 2023-03-20 搜索引擎 249.00 1 249.00 68 成都 1
1009 2023-04-05 线上广告 459.00 4 1890.00 25 北京 0
1010 2023-04-12 朋友推荐 799.00 11 6890.00 10 上海 0
1011 2023-04-18 搜索引擎 179.00 1 179.00 95 广州 1
1012 2023-05-02 社交媒体 549.00 6 3240.00 18 深圳 0
1013 2023-05-15 线上广告 329.00 2 680.00 45 杭州 0
1014 2023-05-20 朋友推荐 999.00 15 12350.00 3 北京 0
1015 2023-06-01 搜索引擎 229.00 1 229.00 88 上海 1
1016 2023-06-10 线上广告 379.00 3 1120.00 32 成都 0
1017 2023-06-18 朋友推荐 649.00 10 7120.00 7 广州 0
1018 2023-07-05 社交媒体 479.00 7 3890.00 14 深圳 0
1019 2023-07-12 搜索引擎 159.00 1 159.00 102 杭州 1
1020 2023-07-20 线上广告 429.00 4 1680.00 28 北京 0创建特征对比表
在Excel中,我们可以创建一个表格,对比不同特征值下的留存率。这个表格可以帮助我们直观地看出哪些特征对留存影响最大。
我们可以使用数据透视表来快速创建这样的对比表。首先,我们选中包含所有数据的区域(A1:I21),然后在"插入"选项卡中选择"数据透视表"。在弹出的对话框中,选择"新工作表",点击确定。
在数据透视表字段列表中,我们将"注册渠道"字段拖到"行"区域,将"是否流失"字段拖到"值"区域。默认情况下,Excel会对"是否流失"求和,我们需要修改计算方式。我们点击"值"区域中的"是否流失"下拉菜单,选择"值字段设置",将计算方式改为"平均值"。这样,我们就能看到每个注册渠道对应的平均流失率(也就是流失率),1减去这个值就是留存率。
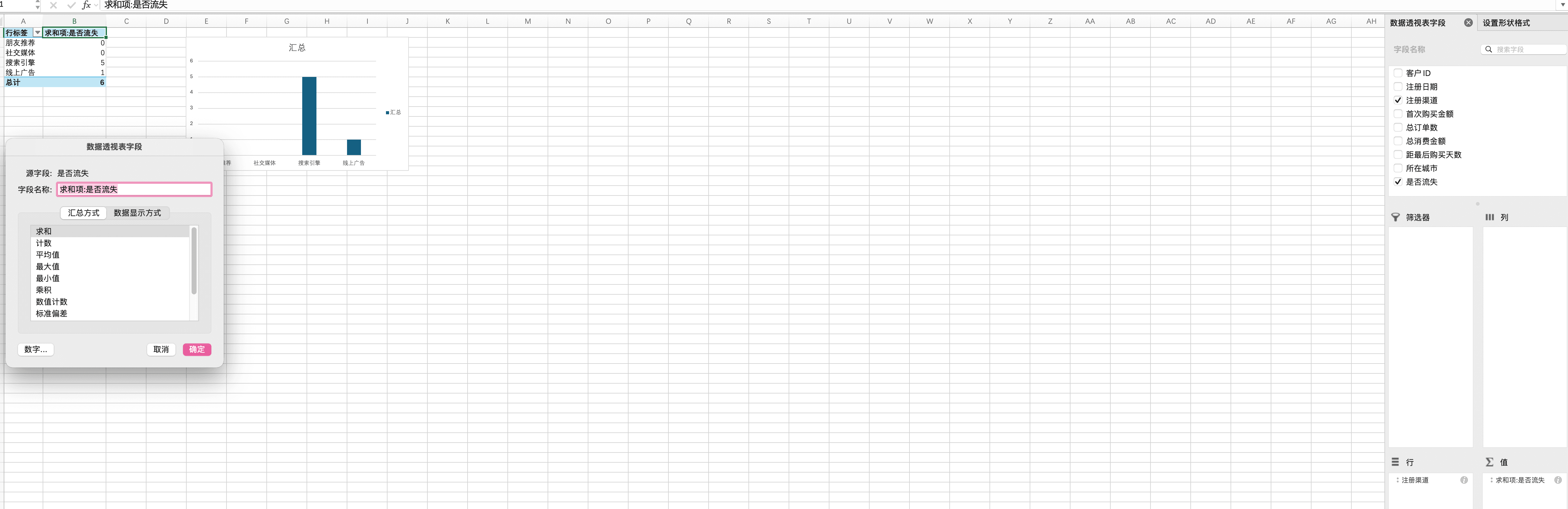
我们还可以创建多个数据透视表来分析不同的特征。比如,我们可以创建一个按"首次购买金额区间"分组的透视表。首先,我们需要在J列添加一个辅助列,使用以下公式来划分金额区间:
=IF(D2<200, "低金额(<200)", IF(D2<500, "中金额(200-500)", "高金额(>500)"))然后将这个公式向下拖动到所有数据行。这样,我们就可以创建一个新的数据透视表,将"首次购买金额区间"拖到行区域,将"是否流失"拖到值区域,同样设置为平均值。通过对比不同特征值下的留存率,我们能够识别出哪些特征对客户留存影响最大。
创建散点图分析
散点图可以帮助我们观察两个特征之间的关系,以及它们与留存的关系。比如,我们可以创建一个散点图,横轴是总消费金额,纵轴是总订单数,点的颜色表示是否流失。
在Excel中创建散点图很简单。我们选中包含总消费金额(F列)和总订单数(E列)的数据列,然后在"插入"选项卡中选择"散点图"。Excel会创建一个基础的散点图。
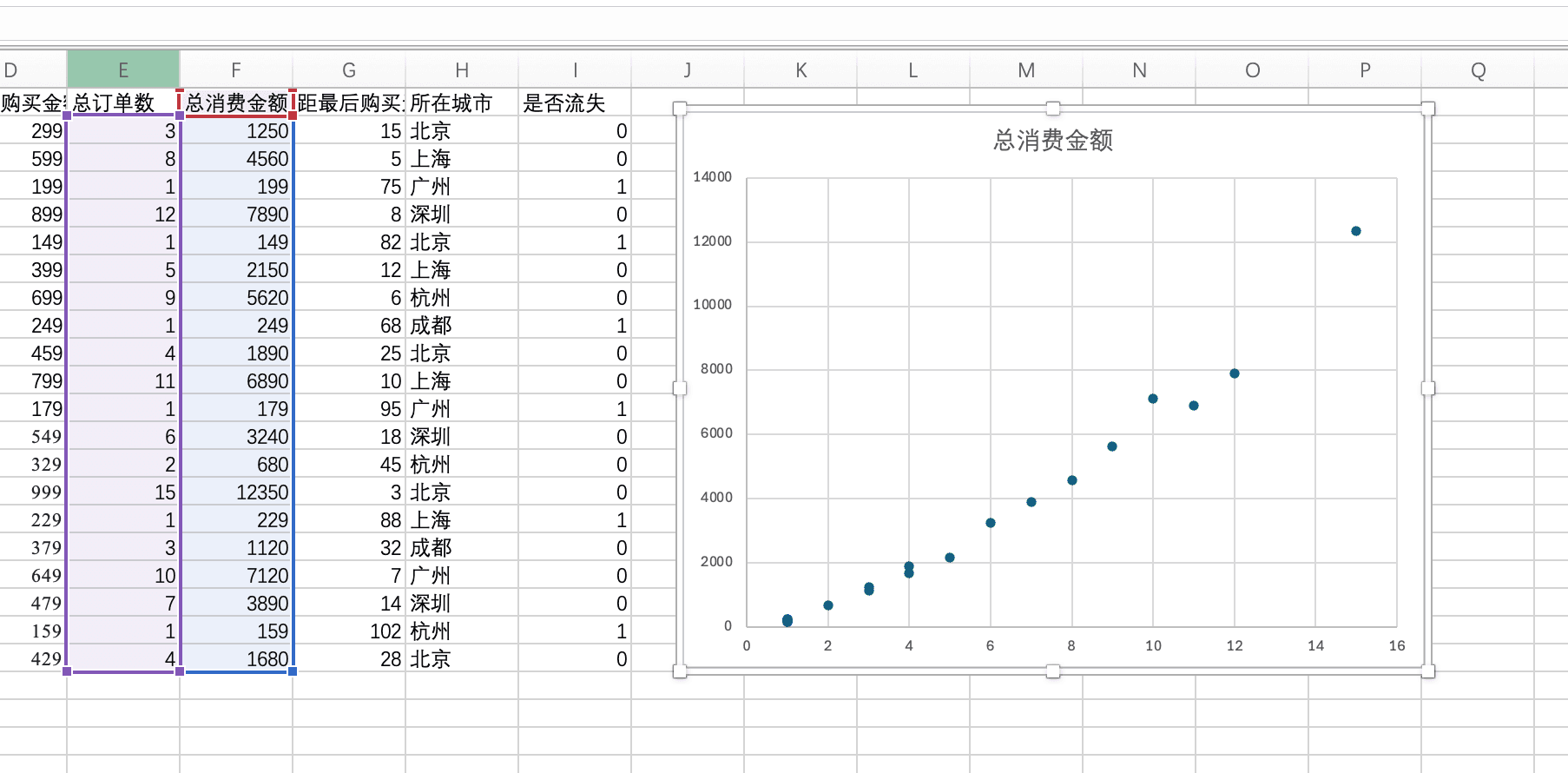
为了根据是否流失来设置不同的颜色,我们需要将数据分成两组:流失客户和留存客户。我们可以先筛选数据,只显示流失客户(是否流失=1),选中这些点的总消费金额和总订单数,创建散点图,并将这些点设置为红色。然后,我们再添加留存客户的数据系列(是否流失=0),将这些点设置为蓝色。
更简单的方法是使用筛选功能。我们选中数据区域,在"数据"选项卡中选择"筛选"。然后点击"是否流失"列的下拉箭头,先选择"1",选中所有流失客户的数据,创建散点图并设置为红色。接着取消筛选,选择"0",选中所有留存客户的数据,添加到图表中并设置为蓝色。
这样,我们就能直观地看出流失客户和留存客户在特征空间中的分布。通常,我们会发现流失客户集中在总消费金额较低、总订单数较少的区域,而留存客户则分布在总消费金额较高、总订单数较多的区域。
构建简单的预测模型
在Excel中,我们可以使用IF函数和多个条件来构建简单的预测模型。我们在J列(或任意空白列)添加"流失风险预测"列,然后在J2单元格中输入以下公式:
=IF(AND(C2="搜索引擎", E2=1, G2>60), "高风险",
IF(OR(E2=1, G2>90), "中风险", "低风险"))这个公式根据多个条件来判断客户的风险等级。第一个条件检查是否是搜索引擎渠道、总订单数为1、且距最后购买天数超过60天,如果满足则判断为"高风险"。第二个条件检查总订单数为1或距最后购买天数超过90天,如果满足则判断为"中风险"。其他情况判断为"低风险"。
我们将这个公式向下拖动到所有数据行(J2:J21),这样就能为每个客户预测流失风险。虽然这个模型很简单,但对于初步的流失预测已经足够用了。
我们还可以根据实际数据调整阈值。比如,如果我们发现总订单数少于3的客户流失率很高,我们可以修改公式:
=IF(AND(C2="搜索引擎", E2=1, G2>60), "高风险",
IF(OR(E2<=2, G2>90), "中风险", "低风险"))这样,总订单数少于等于2的客户也会被判断为“中风险”。
验证模型准确性
在Excel中,我们可以很容易地计算模型的准确性。我们在K列添加"预测是否流失"列,在L列添加"预测是否正确"列,在M列添加"准确率统计"。
首先,我们需要将预测的风险等级转换为是否流失的预测。在K2单元格中输入以下公式,将"高风险"预测转为1(预测流失),其他为0(预测不流失):
=IF(J2="高风险", 1, 0)然后将这个公式向下拖动到所有数据行(K2:K21)。
接下来,我们在L2单元格中输入以下公式,比较预测值和实际值:
=IF(K2=I2, 1, 0)这个公式检查预测值(K列)是否等于实际值(I列的"是否流失"),如果相等则返回1(预测正确),否则返回0(预测错误)。我们将这个公式向下拖动到所有数据行(L2:L21)。
最后,我们在M2单元格中输入以下公式来计算准确率:
=AVERAGE(L2:L21)这个公式计算所有预测正确的比例。如果结果是0.85,说明模型的准确率是85%,也就是说在20个客户中,有17个客户的流失预测是正确的。
我们还可以计算更详细的指标。比如,我们在M4单元格计算高风险客户的流失率:
=SUMIF(J2:J21, "高风险", I2:I21) / COUNTIF(J2:J21, "高风险")这个公式计算被预测为"高风险"的客户中,实际流失的比例。如果这个比例很高(比如超过80%),说明我们的高风险预测是有效的。
通过这种方式,我们能够评估模型的效果,并根据结果调整模型。如果准确率不够高,我们可以调整公式中的阈值,或者添加更多的判断条件。
课程小结
这节课我们介绍了如何系统性地分析各类客户特征与客户留存的关系。构建客户特征表作为分析基础,配合规则和评分方法,即使不依赖复杂的机器学习工具,也可以初步筛查和预测高风险客户,提升我们的数据洞察力和实践能力。
进行特征分析时,建议从单一特征、简单规则入手,逐步扩展到多特征组合和更复杂的分析,同时关注样本量的充足性,确保结论的可靠性。 在下一节课中,我们将学习“客户购买和其他重复事件”,探索如何分析客户的重复购买行为。这将帮助我们理解客户的购买模式,识别忠诚客户,并优化产品推荐和营销策略。