位置决定价值
在商业分析中,地理位置往往是一个被忽视但却极其重要的维度。不同的地区有着不同的消费习惯、经济水平和市场特征,理解这些地域差异能够帮助我们制定更精准的营销策略、优化门店布局、识别潜在市场。 这节课,我们将学习如何处理和分析地理位置数据,使用SQL进行地域聚合分析,并通过Excel创建直观的地域可视化图表,发现隐藏在位置背后的商业价值。
位置分析在商业中的重要性
位置分析在商业决策中扮演着至关重要的角色。无论是零售企业的门店选址,还是电商平台的区域营销策略,都需要深入理解地理位置对业务的影响。位置不仅仅是数据表中的一个字段,它承载着丰富的信息:经济水平、人口密度、消费习惯、竞争环境等。
门店选址
对于零售企业来说,门店选址是决定成败的关键因素之一。一个好的位置能够带来稳定的客流和可观的销售额,而一个差的位置即使产品再好、服务再优,也可能面临经营困难。通过分析现有门店的位置数据和业绩数据,我们能够发现哪些区域更适合开设新店,哪些区域可能存在过度竞争。
比如,我们可以分析不同区域的销售额、客流量、客户满意度等指标,找出表现最好的区域特征。这些特征可能包括:人口密度、平均收入水平、交通便利程度、周边竞争情况等。掌握了这些规律,我们就能够在选址时更有针对性地寻找符合这些特征的位置。
客户地域分布的价值
了解客户的地域分布同样重要。不同地区的客户可能有不同的消费偏好、购买能力和忠诚度。通过分析客户的地域分布,我们能够:
识别高价值客户集中的区域,在这些区域加大营销投入;发现潜在市场,在客户密度较低但消费能力较强的区域开展推广活动;优化物流配送,根据客户分布调整仓储和配送策略;制定差异化策略,针对不同地区的客户特点提供个性化的产品和服务。
位置分析不仅仅是看数据,更重要的是理解地理位置背后的经济、社会和文化因素。这些因素共同决定了该地区的商业特征。
区域营销策略的制定
在制定营销策略时,一刀切的方法往往效果不佳。不同地区的市场环境、竞争态势和客户需求可能存在显著差异。通过位置分析,我们能够识别这些差异,制定更有针对性的区域营销策略。
比如,在一线城市,客户可能更注重产品的品质和品牌,价格敏感度相对较低;而在三四线城市,客户可能更关注性价比,对促销活动更敏感。了解这些差异,我们就能够在不同地区采用不同的营销策略,提高营销效果和投资回报率。
处理地理位置数据
在开始地域分析之前,我们需要先处理好地理位置数据。地理位置数据可能以多种形式存在:详细的地址、邮政编码、城市名称、省份名称、经纬度坐标等。不同的数据格式需要不同的处理方法。
准备测试数据
让我们先创建一个简单的测试数据集,帮助我们理解分析过程。假设我们有一个客户表,包含以下字段:
-- 创建客户测试表
CREATE TABLE 客户表 (
客户ID INT,
客户姓名 VARCHAR(50),
地址 VARCHAR(200),
邮政编码 VARCHAR(10),
注册日期 DATE
);
-- 插入测试数据
INSERT INTO 客户表 VALUES
(1, '张三', '北京市朝阳区建国路88号', '100020', '2024-01-15'),
(2, '李四', '上海市浦东新区陆家嘴环路1000号', '200120', '2024-01-20'),
(3, '王五', '广东省广州市天河区天河路123号', '510000', '2024-02-01'),
(4, '赵六', '深圳市南山区科技园南路2000号', '518057', '2024-02-10'),
(5, '钱七', '北京市海淀区中关村大街1号', '100080', '2024-02-15'),
(6, '孙八', '上海市黄浦区南京东路100号', '200001', '2024-03-01'),
(7, '周九', '杭州市西湖区文三路259号', '310012', '2024-03-10'),
(8, '吴十', '成都市锦江区春熙路123号', '610021', '2024-03-20');这个测试数据包含了8个客户的基本信息和地理位置数据。虽然数据量很小,但足够我们理解分析过程。在实际工作中,我们会使用更大的数据集,但分析方法是一样的。
地址数据的标准化
地址数据往往是最复杂的地理位置数据。同一个地点可能有多种不同的表示方式,比如"北京市朝阳区"、"北京朝阳"、"北京市朝阳区建国路"等。这些不同的表示方式会给分析带来困难,因此我们需要对地址进行标准化处理。
在SQL中,我们可以使用字符串函数来处理地址数据。比如,我们可以提取省份、城市、区县等信息:
SELECT
客户ID,
地址,
CASE
WHEN 地址 LIKE '%北京%' THEN '北京'
WHEN 地址 LIKE '%上海%' THEN '上海'
WHEN 地址 LIKE '%广州%' THEN '广州'
WHEN 地址 LIKE '%深圳%' THEN '深圳'
WHEN 地址 LIKE '%杭州%' THEN '杭州'
WHEN 地址 LIKE '%成都%'
这个查询会返回类似这样的结果:
这个查询使用CASE语句和LIKE操作符来识别城市。虽然这种方法比较简单,但对于标准化的地址数据已经足够。如果地址数据比较复杂,我们可能需要使用更高级的字符串处理函数,或者考虑使用专门的地理编码服务。
提取地理位置维度
从地址中提取地理位置维度(省份、城市、区县等)是地域分析的基础。我们可以创建一个查询来系统地提取这些信息:
SELECT
客户ID,
地址,
SUBSTRING_INDEX(地址, '省', 1) AS 省份,
CASE
WHEN 地址 LIKE '%市%' THEN
SUBSTRING_INDEX(SUBSTRING_INDEX(地址, '市', 1), '省', -1)
ELSE NULL
END AS 城市
FROM 客户表;这个查询尝试从地址中提取省份和城市信息。SUBSTRING_INDEX函数根据指定的分隔符提取子字符串。不过,这种方法依赖于地址格式的一致性,如果地址格式不统一,可能需要更复杂的处理逻辑。
使用邮政编码进行地域分析
邮政编码是另一种常见的地理位置标识。虽然邮政编码不能直接告诉我们具体的地理位置,但它能够帮助我们进行地域分组和聚合分析。
为了演示邮政编码分析,我们需要一个包含订单数据的表。让我们创建一个订单测试表:
-- 创建订单测试表
CREATE TABLE 订单表 (
订单ID INT,
客户ID INT,
订单日期 DATE,
订单金额 DECIMAL(10,2),
省份 VARCHAR(20),
城市 VARCHAR(20)
);
-- 插入测试数据
INSERT INTO 订单表 VALUES
(1,
现在我们可以使用邮政编码和订单数据进行分析:
SELECT
LEFT(c.邮政编码, 2) AS 省份代码,
LEFT(c.邮政编码, 4) AS 城市代码,
COUNT(DISTINCT c.客户ID) AS 客户数,
COUNT(o.订单ID) AS 订单数,
ROUND(AVG(
这个查询会返回类似这样的结果:
这个查询使用LEFT函数提取邮政编码的前几位,用于标识省份和城市。通过这种方式,我们能够快速进行地域分组,分析不同地区的客户特征。
经纬度坐标的处理
如果数据中包含经纬度坐标,我们就能够进行更精确的地理位置分析。经纬度坐标允许我们计算两点之间的距离,识别特定半径范围内的客户或门店,甚至进行热力图分析。
让我们创建一个包含经纬度信息的门店测试表:
-- 创建门店测试表
CREATE TABLE 门店表 (
门店ID INT,
门店名称 VARCHAR(50),
所在城市 VARCHAR(20),
纬度 DECIMAL(10,6),
经度 DECIMAL(10,6),
月销售额 DECIMAL(10,2)
);
在SQL中,我们可以使用距离计算公式来计算两点之间的距离。最常用的是Haversine公式,它能够计算地球表面两点之间的大圆距离:
SELECT
门店1.门店名称 AS 门店1,
门店2.门店名称 AS 门店2,
ROUND(6371 * ACOS(
COS(RADIANS(门店1.纬度)) *
COS(RADIANS(门店2.纬度)) *
COS(RADIANS(
这个查询会返回类似这样的结果:
这个查询计算所有门店对之间的距离。6371是地球的平均半径(单位:公里),Haversine公式使用经纬度坐标计算大圆距离。通过这个查询,我们能够识别哪些门店距离太近可能存在竞争(如北京的两家店距离只有12.5公里),哪些区域门店覆盖不足(如广州和深圳之间距离较远)。
使用SQL进行地域聚合分析
一旦我们处理好了地理位置数据,就可以开始进行地域聚合分析了。SQL的聚合功能非常适合这种分析,它能够快速计算不同地区的各种统计指标。
按地区统计销售额
最基本的地域分析是按地区统计销售额。这能够帮助我们了解哪些地区是主要的收入来源:
SELECT
省份,
城市,
COUNT(*) AS 订单数,
SUM(订单金额) AS 总销售额,
ROUND(AVG(订单金额), 2) AS 平均订单金额,
COUNT(DISTINCT 客户ID) AS 客户数
FROM 订单表
GROUP BY 省份, 城市
ORDER BY 总销售额 DESC;这个查询会返回类似这样的结果:
这个查询按照省份和城市分组,统计每个地区的订单数、总销售额、平均订单金额和客户数。通过查看总销售额,我们能够快速识别表现最好和最差的地区。从结果可以看出,深圳和上海是销售额最高的两个城市,而成都的销售额相对较低。
计算地区占比和排名
仅仅知道绝对数值还不够,我们还需要了解各地区在整体中的相对地位。我们可以计算占比和排名:
WITH 地区销售 AS (
SELECT
省份,
城市,
SUM(订单金额) AS 地区销售额
FROM 订单表
GROUP BY 省份, 城市
),
总计 AS (
SELECT SUM(地区销售额) AS 总销售额
FROM 地区销售
)
SELECT
r.省份,
r.城市,
这个查询会返回类似这样的结果:
这个查询使用CTE来计算每个地区的销售额占比和排名。RANK()窗口函数按照销售额降序排列,为每个地区分配排名。通过查看占比和排名,我们能够更清楚地了解各地区的相对重要性。从结果可以看出,上海和深圳合计占据了超过50%的销售额,是核心市场区域。
地区增长趋势分析
除了静态的销售额统计,我们还可以分析各地区销售额的增长趋势。这能够帮助我们识别快速增长的地区和可能面临下滑的地区。
为了演示增长趋势分析,我们需要更多时间跨度的数据。让我们扩展订单数据:
-- 添加更多月份的订单数据
INSERT INTO 订单表 VALUES
(13, 1, '2024-05-01', 299.00, '北京', '北京'),
(14, 2, '2024-05-02', 599.00, '上海', '上海'),
(15, 4, '2024-05-04', 899.
现在我们可以分析增长趋势:
WITH 月度地区销售 AS (
SELECT
省份,
城市,
DATE_FORMAT(订单日期, '%Y-%m') AS 月份,
SUM(订单金额) AS 月度销售额
FROM 订单表
GROUP BY 省份, 城市, DATE_FORMAT(订单日期, '%Y-%m')
),
月度对比 AS (
SELECT
省份,
城市,
月份,
月度销售额,
LAG
这个查询会返回类似这样的结果:
这个查询使用窗口函数LAG来获取上个月的销售额,然后计算环比增长率。通过分析增长率,我们能够识别哪些地区在快速增长(如北京增长了249.83%),哪些地区增长较慢(如上海增长了23.04%)。
地区客户特征分析
不同地区的客户可能有不同的特征。我们可以分析各地区客户的购买行为、偏好和忠诚度:
SELECT
省份,
城市,
COUNT(DISTINCT 客户ID) AS 客户数,
ROUND(AVG(订单金额), 2) AS 平均订单金额,
ROUND(AVG(订单频率), 2) AS 平均订单频率,
ROUND(AVG(客户生命周期价值), 2) AS 平均客户价值
FROM (
SELECT
o.
这个查询会返回类似这样的结果:
这个查询分析各地区客户的购买行为特征。通过比较不同地区的平均订单金额、订单频率和客户生命周期价值,我们能够发现哪些地区的客户更有价值,哪些地区可能需要改进客户体验。从结果可以看出,深圳的客户平均价值最高(1498.00),平均订单金额也最大(749.00),说明深圳市场的客户质量较高。
使用Excel进行地域可视化
SQL查询能够帮助我们获取地域分析的数据,但要将这些数据转化为直观的洞察,可视化是必不可少的。Excel提供了多种工具来创建地域可视化,包括地图图表、热力图、气泡图等。
准备数据:从SQL到Excel
在开始可视化之前,我们需要先将SQL查询的结果导出到Excel。大多数数据库管理工具都支持将查询结果导出为Excel格式。导出时,我们要确保数据格式正确,特别是地理位置字段,这样Excel才能正确识别并用于地图可视化。
下面提供了可以直接复制粘贴到Excel的测试数据。在Excel中,我们只需要选中这些数据,复制,然后粘贴到工作表中即可。
地区销售额数据(用于地图图表和汇总表)
将以下数据复制到Excel的A1单元格开始的位置:
省份 城市 总销售额 订单数 客户数
广东 深圳 1498.00 2 1
上海 上海 1597.00 3 2
北京 北京 1046.00 4 2
广东 广州 399.00 1 1
浙江 杭州 399.00 1 1
四川 成都 249.00 1 1粘贴后,Excel会自动识别制表符分隔的数据,将每列数据正确分配到对应的列中。
创建地区汇总表
在Excel中,我们可以先创建一个地区汇总表,包含省份、城市、销售额、订单数等关键指标。这个表格可以作为后续可视化的数据源。
我们可以使用Excel的数据透视表功能来快速创建这样的汇总表。将省份和城市拖到行区域,将销售额和订单数拖到值区域,Excel会自动生成汇总表。如果数据量很大,我们也可以先在SQL中进行聚合,然后只导出汇总后的数据。
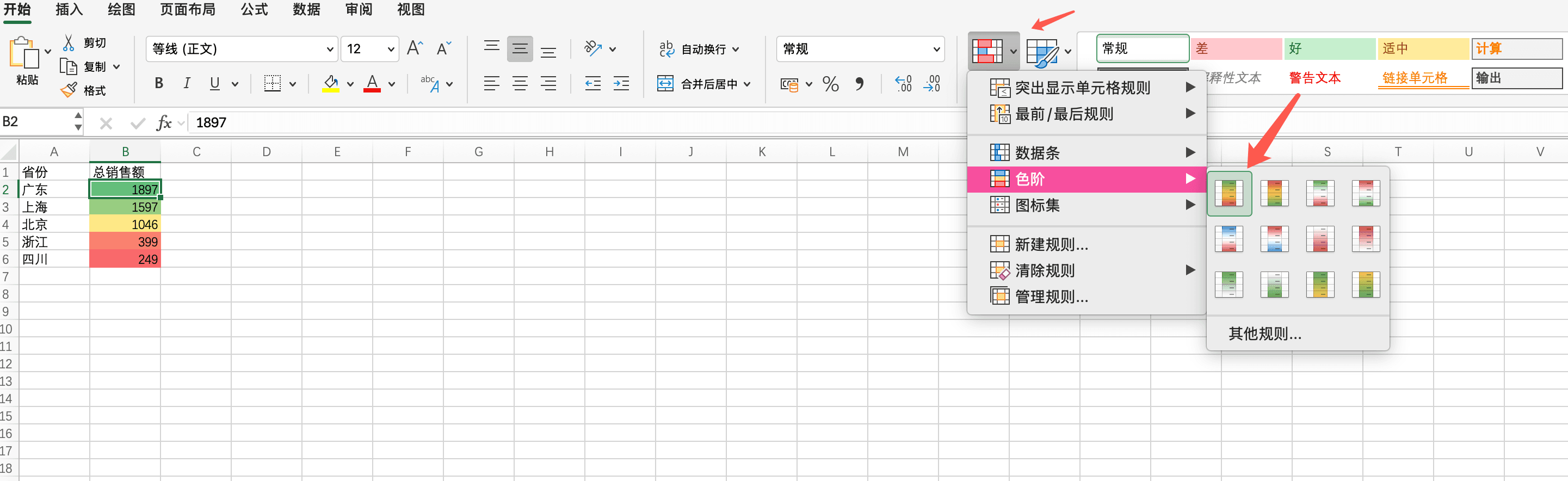
使用条件格式创建热力图
Excel的条件格式功能可以创建简单的热力图,用颜色深浅来表示数值大小。这对于快速识别高值和低值区域非常有用。
省份销售额数据(用于热力图)
将以下数据复制到Excel的新工作表中,从A1单元格开始:
省份 总销售额
广东 1897.00
上海 1597.00
北京 1046.00
浙江 399.00
四川 249.00粘贴数据后,选中B2到B6单元格(销售额列),然后在"开始"选项卡中选择"条件格式",选择"色阶"。Excel会自动根据数值大小应用不同的颜色,数值越大,颜色越深(或越暖)。我们一眼就能看出哪些省份的销售额最高(广东和上海),哪些省份可能需要关注(四川)。
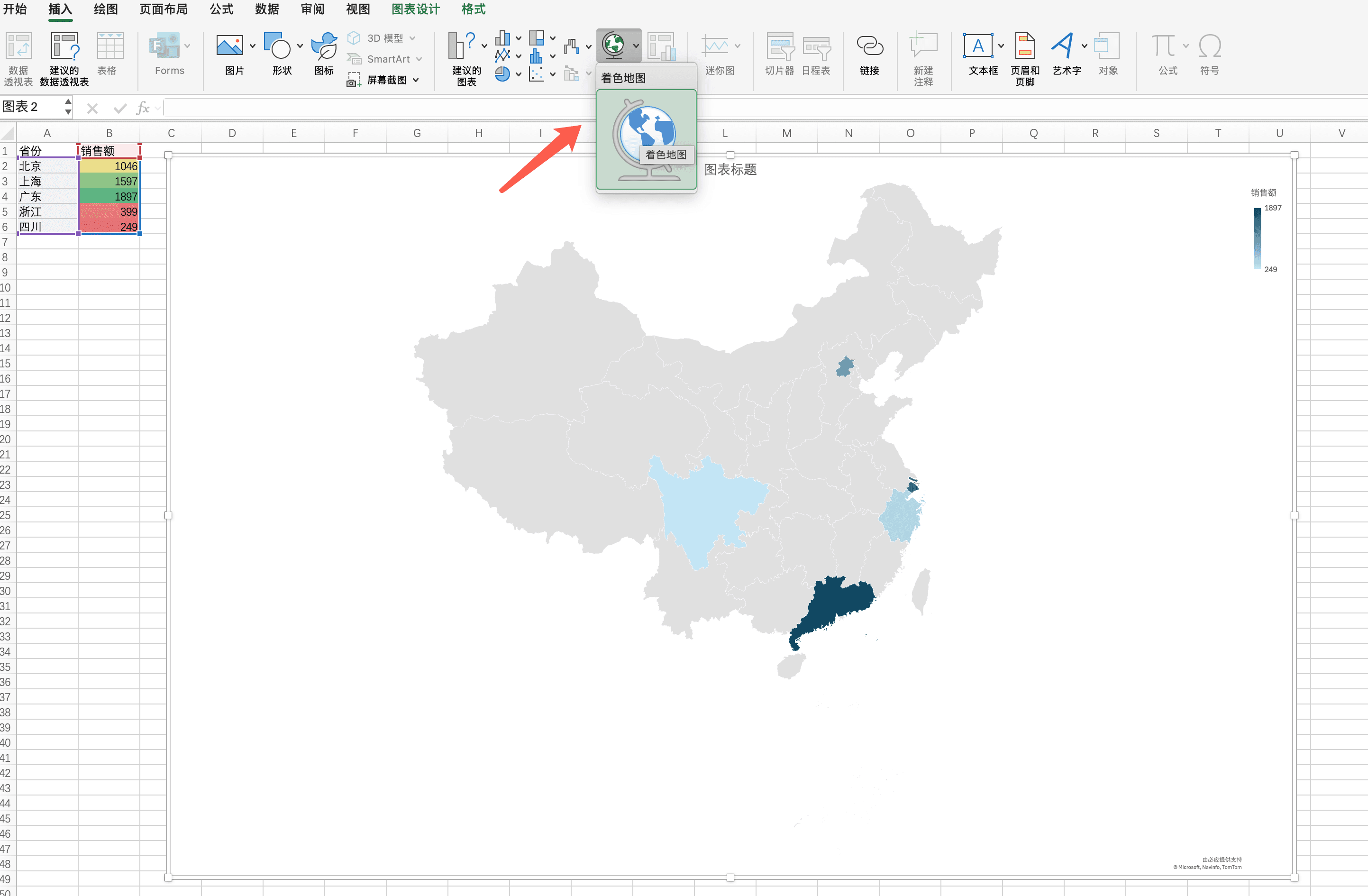
创建地图图表
Excel 2016及更高版本支持地图图表(Map Chart),可以直接在地图上显示数据。要创建地图图表,我们需要确保数据中包含地理位置信息(如省份名称、城市名称等),然后选中数据区域,在"插入"选项卡中选择"地图"。
地图图表数据
将以下数据复制到Excel的新工作表中,从A1单元格开始:
省份 销售额
北京 1046.00
上海 1597.00
广东 1897.00
浙江 399.00
四川 249.00粘贴数据后,选中A1到B6单元格(包括表头),然后在"插入"选项卡中选择"地图"。地图图表会自动识别地理位置,并将数据值映射到地图上。数值越大,颜色越深,或者气泡越大。这样,我们就能直观地看到数据在地理空间上的分布。
地图图表功能需要Excel 2016或更高版本,并且需要网络连接来加载地图数据。如果无法使用地图图表,我们可以考虑使用其他可视化方法,如条形图、饼图等。
使用散点图展示地区分布
如果数据中包含经纬度坐标,我们可以使用散点图来展示地区分布。将经度作为横轴,纬度作为纵轴,每个点代表一个地区,点的大小或颜色可以表示该地区的销售额或其他指标。
门店经纬度数据(用于散点图)
将以下数据复制到Excel的新工作表中,从A1单元格开始:
门店名称 所在城市 经度 纬度 月销售额
北京朝阳店 北京 116.4074 39.9042 150000
北京海淀店 北京 116.2984 39.9593 120000
上海浦东店 上海 121.4737 31.2304 180000
上海黄浦店 上海 121.4737 31.2304 160000
广州天河店 广州 113.2644 23.1291 100000
深圳南山店 深圳 114.0579 22.5431 130000注意:在散点图中,我们通常将经度作为X轴(横轴),纬度作为Y轴(纵轴),这样能够正确显示地理位置。
粘贴数据后,选中C列(经度)和D列(纬度),然后在"插入"选项卡中选择"散点图"。Excel会自动生成散点图,我们还可以调整点的大小和颜色,使其更加直观。 要使用月销售额来设置点的大小,我们需要在图表中选择数据系列,然后设置"大小"选项,选择E列(月销售额)作为大小依据。这样我们就能在地理空间上看到哪些区域的门店业绩更好。
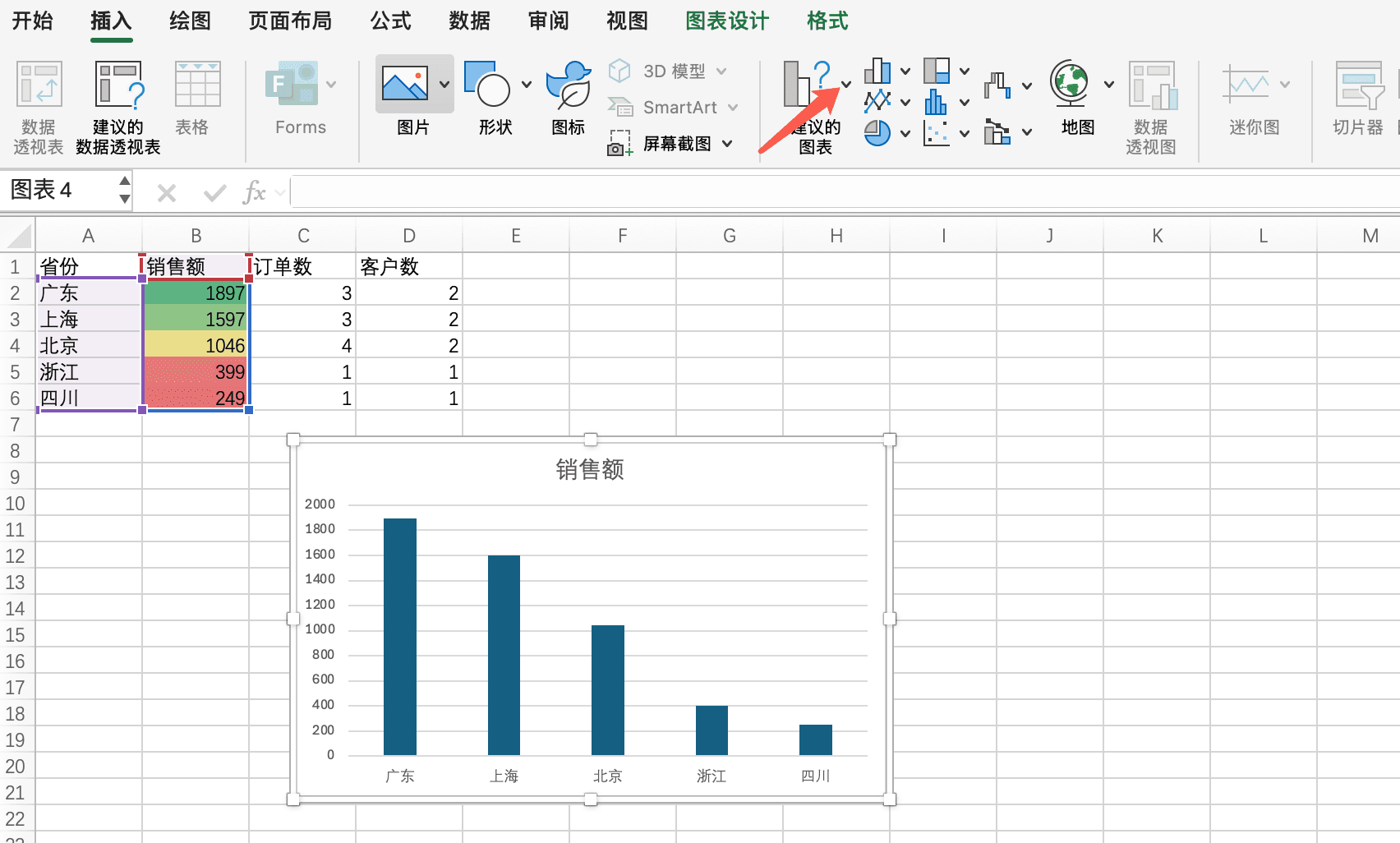
创建地区对比图表
除了地图可视化,我们还可以创建传统的图表来对比不同地区的表现。柱状图适合对比不同地区的销售额,折线图适合展示地区销售额随时间的变化趋势。
省份对比数据(用于柱状图)
将以下数据复制到Excel的新工作表中,从A1单元格开始:
省份 销售额 订单数 客户数
广东 1897.00 3 2
上海 1597.00 3 2
北京 1046.00 4 2
浙江 399.00 1 1
四川 249.00 1 1粘贴数据后,选中A1到B6单元格(省份和销售额),然后在"插入"选项卡中选择"柱状图"。Excel会自动生成柱状图,横轴是省份名称,纵轴是销售额。这样,我们就能清楚地看到哪些省份表现最好(广东和上海),哪些省份需要改进(四川)。
组合图表数据(多指标对比)
如果我们要展示多个指标(如销售额、订单数、客户数),可以使用组合图表。将上面的数据粘贴后,选中A1到D6单元格(包括所有列),然后在"插入"选项卡中选择"推荐的图表",选择"组合图"。我们可以用柱状图表示销售额,用折线图表示订单数和客户数,这样就能在一个图表中同时展示多个维度的信息。
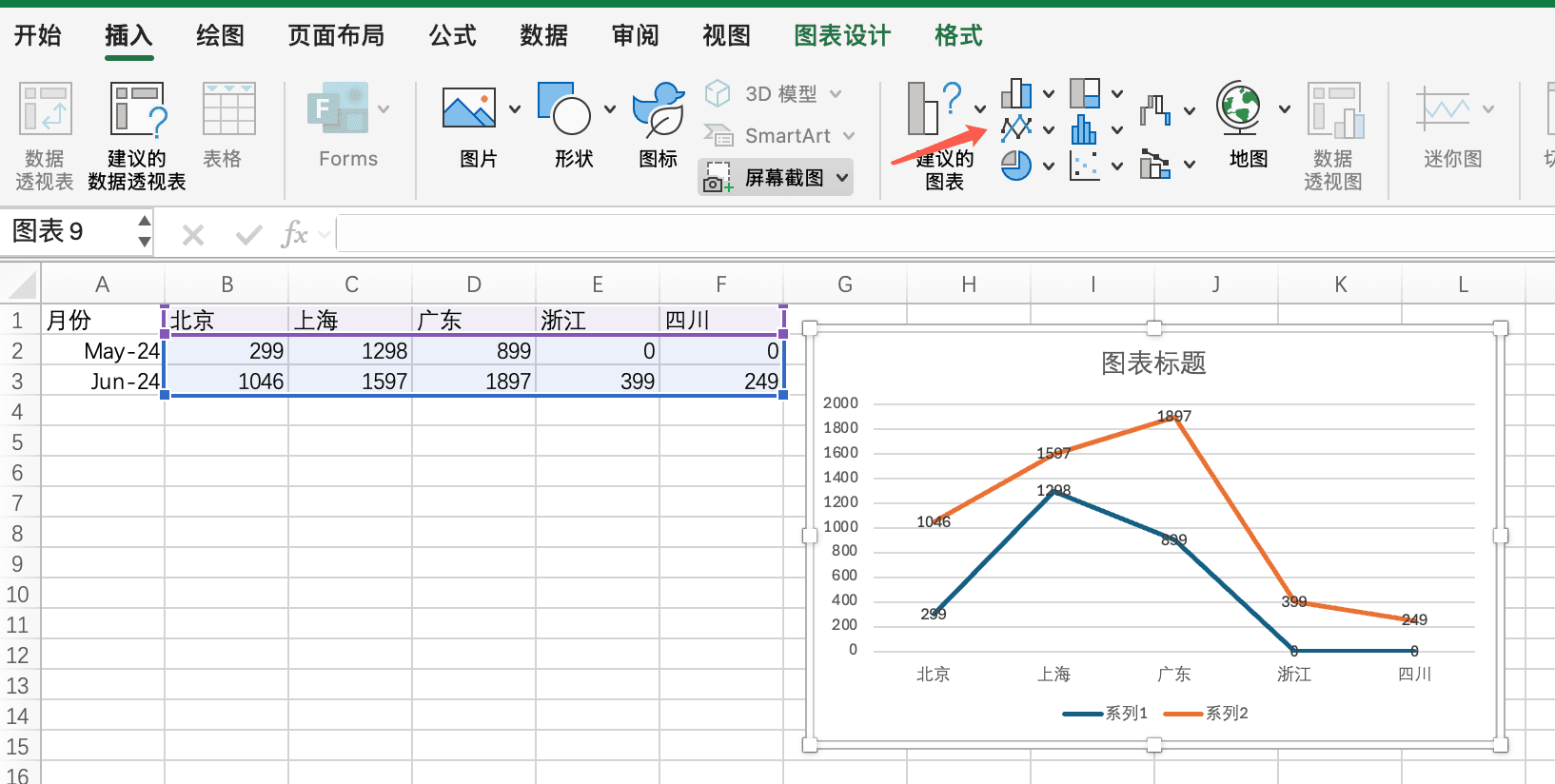
时间序列数据(用于折线图展示趋势)
如果我们要展示地区销售额随时间的变化趋势,可以使用以下数据:
月份 北京 上海 广东 浙江 四川
2024-05 299.00 1298.00 899.00 0.00 0.00
2024-06 1046.00 1597.00 1897.00 399.00 249.00将数据复制到Excel后,选中整个数据区域,然后在"插入"选项卡中选择"折线图"。这样我们就能看到不同地区销售额随时间的变化趋势,识别哪些地区在增长,哪些地区在下降。
地域分析的商业应用
掌握了地域分析的方法后,我们可以将这些方法应用到实际的商业场景中,解决具体的业务问题。
门店选址分析
对于零售企业,门店选址是至关重要的决策。我们可以通过分析现有门店的位置和业绩数据,找出成功的门店有哪些共同的地理特征,然后将这些特征应用到新店选址中。
首先,我们可以分析现有门店的业绩数据,识别表现最好和最差的门店。然后,我们可以收集这些门店周围的地理信息,如人口密度、平均收入、交通便利程度、竞争情况等。通过对比分析,我们能够发现哪些地理特征与门店成功相关。
接下来,我们可以使用这些发现来评估潜在的新店位置。对于每个候选位置,我们计算它具备的成功特征数量,优先选择具备更多成功特征的位置。
区域营销策略优化
通过地域分析,我们能够识别不同地区的市场特征和客户偏好,从而制定更有针对性的营销策略。
比如,我们可以分析不同地区的产品偏好。某些产品可能在某些地区特别受欢迎,而在其他地区销量平平。了解这些差异,我们就能够在不同地区重点推广不同的产品,提高营销效果。
我们还可以分析不同地区对促销活动的响应程度。某些地区的客户可能对折扣更敏感,而某些地区的客户可能更关注产品质量。根据这些发现,我们可以制定差异化的促销策略。
物流配送优化
地域分析还能够帮助我们优化物流配送。通过分析客户的地域分布和订单模式,我们能够确定最佳的仓储位置和配送路线。
比如,我们可以分析各地区订单的集中程度。如果某个地区的订单非常集中,我们可能需要在附近建立仓储中心,缩短配送时间。如果订单分布比较分散,我们可能需要考虑多个配送中心,或者使用更灵活的配送策略。
我们还可以分析不同地区的配送成本和时效。某些地区可能由于距离较远或交通不便,配送成本较高或时效较长。了解这些情况,我们能够制定更合理的配送策略,平衡成本和客户体验。
课程小结
这节课我们讲解了地理位置数据分析的核心流程,从清洗和标准化地址数据、利用邮政编码与经纬度等方式进行地域聚合,到基于SQL的分组聚合和Excel的多样可视化,我们已经掌握了完整的地域分析思路与常用工具。 地理位置不仅是业务分析中的重要维度,更是门店选址、区域营销和物流配送等实际决策的关键依据。理解地域差异,有助于制定更具针对性的商业策略,深入挖掘各类市场机会。
在实际操作中,务必要关注数据质量和一致性,及时清理和标准化各类地理信息。同时,还需结合经济、社会、文化等背景,以及本地市场实际,才能获得真正有价值的洞察。 地域分析是一个动态、持续优化的过程,定期复盘并根据市场和客户变化及时调整分析,将帮助企业更好地应对市场挑战,持续优化决策。
下节课我们将学习时间序列分析,探索时间序列数据分析的方法。时间维度在商业分析中同样重要,理解时间趋势能够帮助我们预测未来、识别季节性规律、优化业务节奏。