哈希表:把键转换成可直接访问的位置
如果字典只需要支持插入、查找和删除,我们希望操作时间尽量不随元素数量增长。数组已经能在常数时间访问一个已知下标,哈希表做的事,就是把“键”稳定地换算成这个下标。
这句话听起来简单,真正的难点却有三个:键的可能范围通常远大于数组;不同键一定可能落到同一位置;“平均常数时间”只有在分布假设和装载因子都受控时才成立。本文从直接寻址开始,把链接法、常用哈希函数、开放寻址、删除、探查代价和静态集合的完全哈希连成一条完整路线。
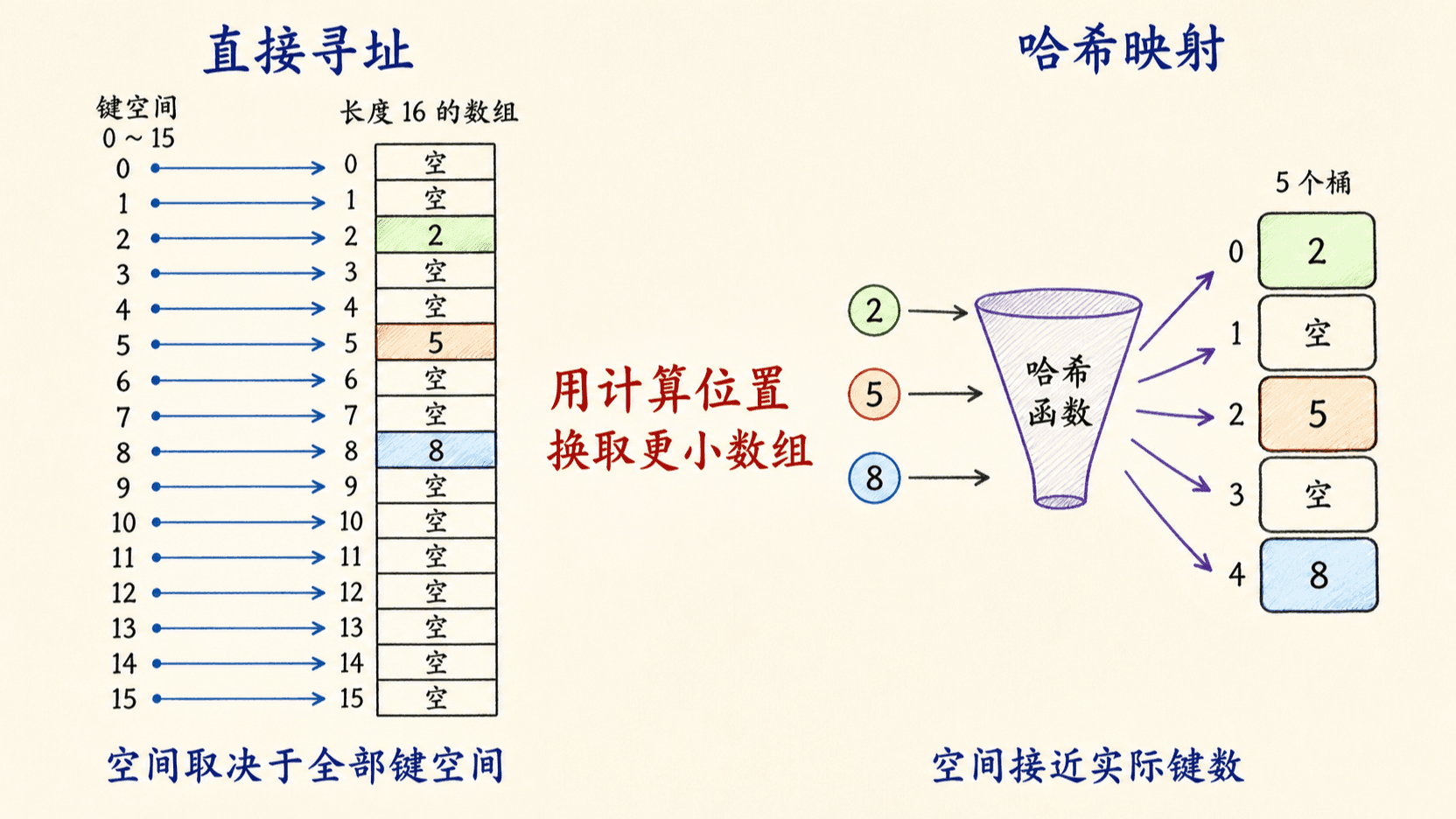
从直接寻址走到哈希表
先看一个几乎完美的字典。假设所有键都来自整数集合
而且 不大。我们分配数组 T[0..M-1],键为 的元素就放在 T[k]。空槽记为 NIL,三个操作只需一次数组访问:
text
查找(T, k):
返回 T[k]
插入(T, x):
T[x.key] = x
删除(T, x):
T[x.key] = NIL它们的最坏情况时间都是 。这里没有哈希函数,也没有冲突;数组下标本身就是键。这种表示叫直接寻址。
时间便宜,空间未必便宜
直接寻址需要 个槽。若键是八位学号,可能的键空间很大,学校实际保存的学生却只有几千人。为每个可能学号保留一个槽,会让绝大多数空间一直为空。
设实际保存的键集合为 ,元素个数为 。哈希表只分配 个桶,通常让 与 同阶,再用哈希函数
把键 映射到槽 。空间从与 相关,变成大致与实际数据量相关。
冲突不是错误,而是必处理的常态
当 时,至少有两个不同的键得到同一个哈希值。这叫冲突。无论哈希函数多巧妙,只要输入范围比桶数大,冲突就无法彻底避免。
因此,一个完整的哈希表必须同时回答两件事:
- 怎样让键尽量均匀地落到各个桶;
- 两个键落到同一桶后,怎样继续保存和查找。
常见答案有两类。链接法让一个桶容纳多个元素;开放寻址让元素全部留在数组内,发生冲突时继续探查别的槽。
装载因子是观察压力的刻度
设表中有 个元素、数组有 个槽,装载因子定义为
对链接法来说, 是每条冲突链的平均长度,可以小于、等于或大于 。对开放寻址来说,每个槽至多放一个元素,所以 ;当 时表已满。
“哈希表查找是 O(1)”不是无条件的最坏情况结论。普通链接法在所有键都落入一个桶时仍要检查 Θ(n) 个元素。常数级表现来自合适的分布假设、受控的装载因子,以及能够正确处理冲突的实现。
1
键空间有十亿种可能,但实际只存两万个键。直接寻址最突出的代价是什么?
2
哈希表有 40 个桶,当前保存 30 个元素,其装载因子 α 为 ____。
链接法:让同一桶保存一组元素
链接法把数组的每个槽看成一条链的入口。所有满足 的元素都放进桶 。桶可以用链表、动态数组或其他小型容器实现;分析时通常把它视为链表。
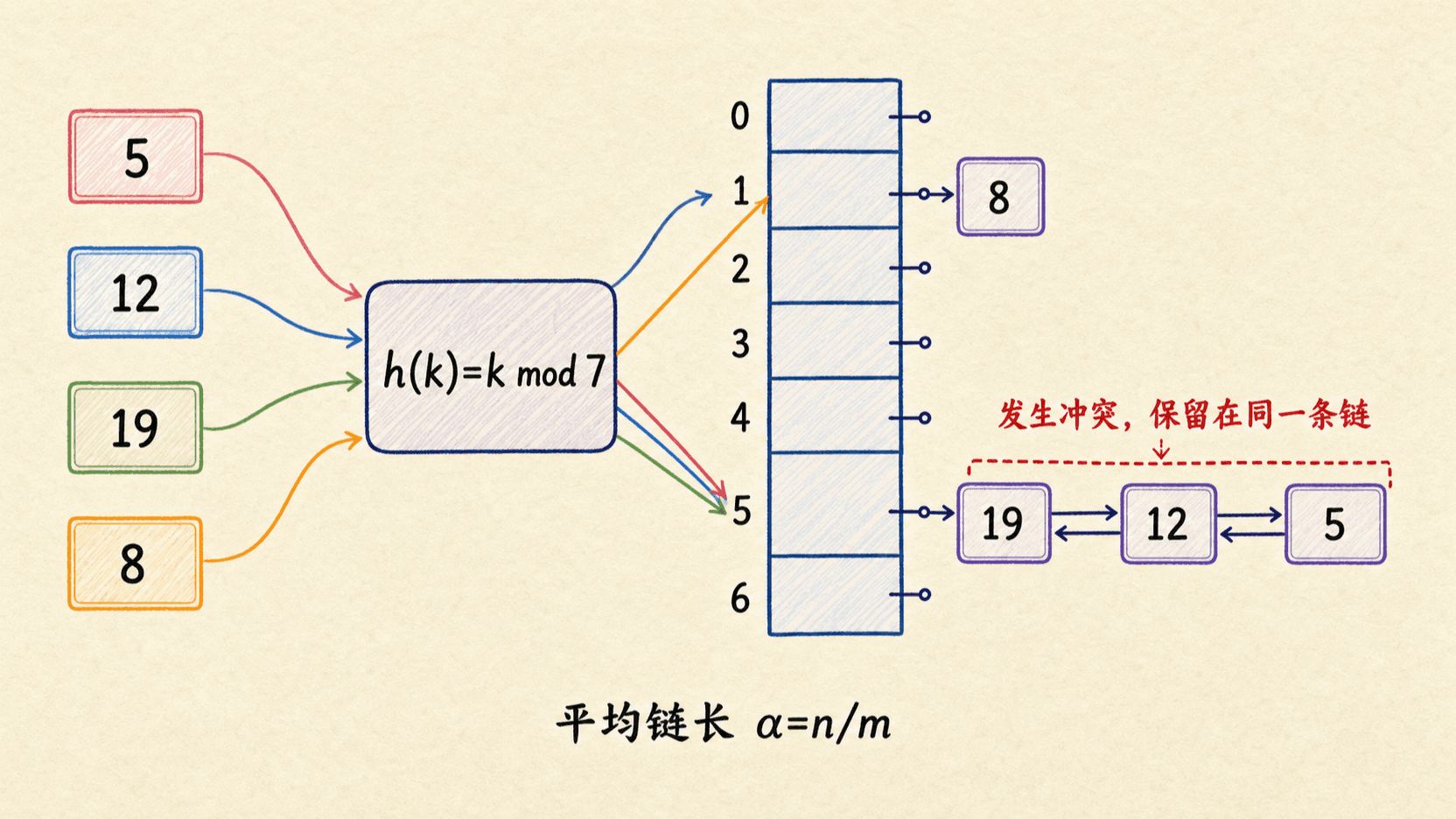
操作怎样完成
若确认新键尚不存在,把新元素插到链表头即可:
text
链接插入(T, x):
把 x 插入链表 T[h(x.key)] 的表头
链接查找(T, k):
在链表 T[h(k)] 中查找键 k
链接删除(T, x):
从链表 T[h(x.key)] 中移除 x表头插入的最坏情况时间是 ,但这个结论假设调用方已经知道键不重复。如果 insert 还要实现“同键更新”,就必须先在对应链中查找。
删除也要看接口。若传入的是元素指针,而且桶使用双向链表,已知节点可以在 最坏时间摘除。若只传入键,或者桶是单向链表,就要先定位元素或它的前驱,代价与查找相同。
简单均匀哈希假设
为了分析平均代价,先引入一个理想化条件:每个键都等概率落入 个桶之一,而且与其他键落入哪里相互独立。它叫简单均匀哈希。
记桶 的链长为 ,则
并且在上述假设下
查找一个不存在的键,要走完整条链,期望检查 个元素。再算上求哈希值与访问桶的常数时间,失败查找的期望时间为
成功查找还要说明“要找哪个元素”。若表中每个元素被查找的概率相同,并且新元素总插在链首,那么期望检查元素数为
所以成功查找的期望时间同样是 。当 时,,查找才得到期望 。
简单均匀哈希是分析模型,不是某个普通哈希函数自动附带的保证。真实键可能有关联,甚至可能被刻意构造。后文的全域哈希会把随机性放到函数选择上,使结论不再依赖键本身的概率分布。
一个会自动扩容的 C++ 实现
下面的实现把桶设为双向链表,insertOrAssign 支持同键更新。当插入会使装载因子超过阈值时,表会扩容并重新计算所有元素的桶位置。
cpp
#include <cstddef>
#include <functional>
#include <list>
#include <utility>
#include <vector>
template <class K, class V, class Hash = std::hash<K>>
class ChainedHashTable {
using Entry = std::pair<K, V>;
std::vector
这段 erase 接收键,所以仍要遍历桶。若接口接收稳定的节点句柄,双向链表才能发挥“已知节点常数时间删除”的优势。扩容也不是免费的:一次重哈希要搬动 个元素,代价为 ;把它分摊到很多次插入上,才通常得到摊还常数级插入。
交互实验:观察冲突链
输入整数后可以插入、查找和删除。演示表固定为 7 个桶,并使用 ,所以负数也会得到合法下标。
3
在链接法中,下列哪些说法需要额外条件才成立?
4
只要使用链接法,成功与失败查找就都能保证 O(1) 最坏时间。
哈希函数:目标是打散输入模式
哈希函数首先要满足确定性:同一个键在表的结构没有改变时必须得到同一个位置。它还应当算得快,并尽量让输入中的规律不直接变成桶分布中的规律。
“均匀”不能只看函数公式,还要看键从哪里来。例如,若业务编号的低位总是偶数,而桶数又是 的幂,直接取余会浪费一半桶。设计哈希函数时,我们真正要避免的是函数结构与数据模式互相配合,造成集中冲突。
先把复合键变成自然数
许多公式把键写成非负整数。字符串可以按某个进位制逐字符折叠。设字符编码为 ,基数为 ,对应整数可写成
不需要真的构造这个可能很大的整数。若最后只需要 ,可以逐字符维护余数:
处理完全部字符后, 就是结果,额外空间为常数。字符顺序参与每一步乘法,因此它比简单相加更能区分排列不同的字符串。
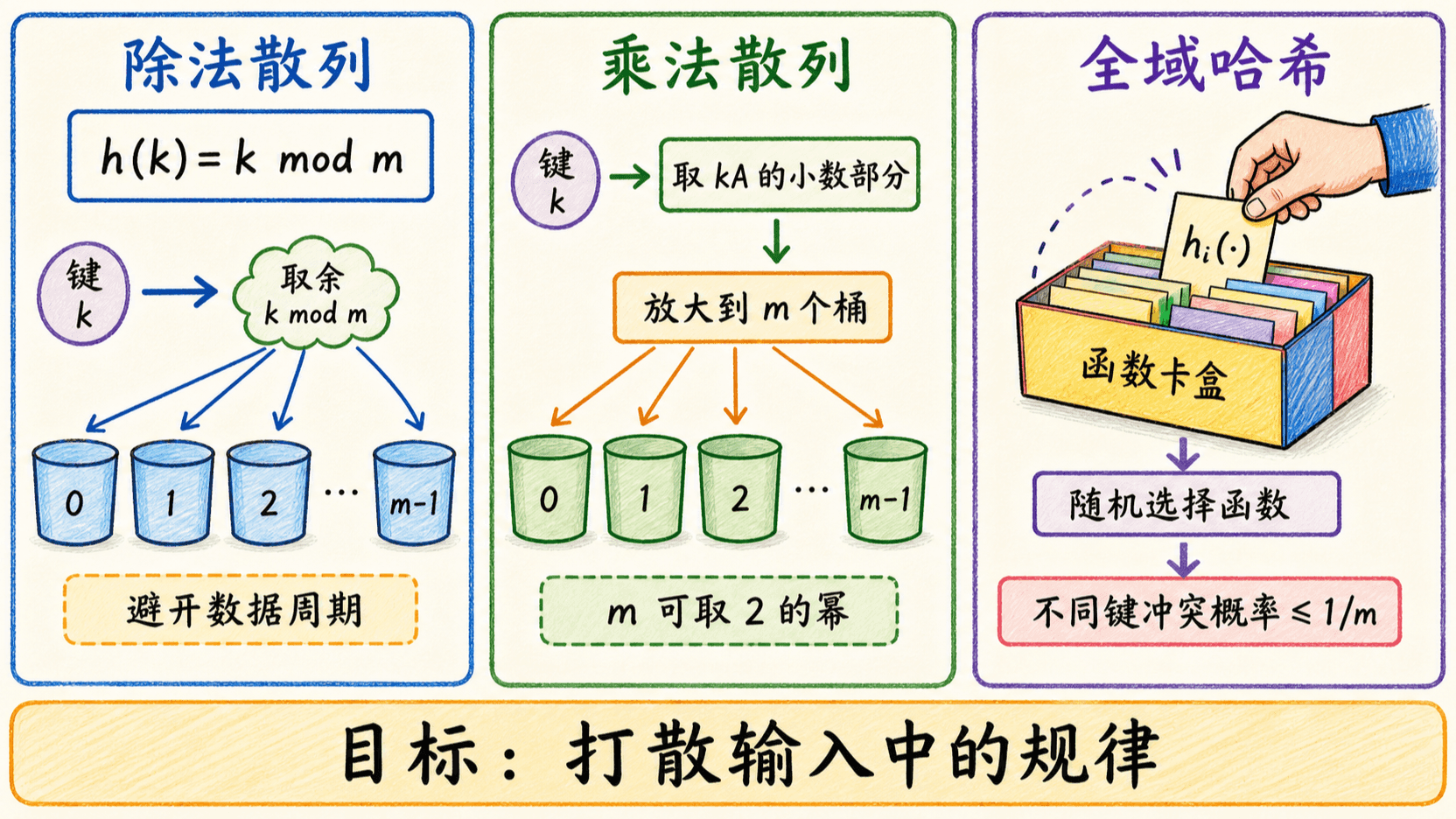
除法散列
除法散列直接取余:
它只需一次除法,速度快,但 的选择很关键。若 ,结果只取决于 的最低 位;低位分布不好时,其他位再丰富也无济于事。常用经验是选择不接近 的整数幂、也不与数据周期相关的素数。
这不是“素数必然均匀”的定理。若所有输入都恰好相差 的倍数,素数同样救不了分布。桶数选择必须和已知的数据规律一起判断。
乘法散列
选定常数 ,满足 ,先取 的小数部分,再放大到 个槽:
其中 。乘法散列对 的选择不太敏感,工程上常令 ,利用整数乘法结果中的一段高位完成映射。一个常见的经验常数是
这个数通常表现不错,但不是对所有数据都最优;最合适的 仍与键的特征有关。
全域哈希把随机性放进函数选择
固定函数可能被针对:只要有人找到一批同余或结构相似的键,就可能把它们全部送入同一桶。全域哈希不假设键随机,而是在程序开始时从一族函数中随机选择一个函数,并让选择独立于将要存储的键。
若函数族 满足:任意两个不同键 ,随机选择 后有
就称它是全域的。这里的期望来自随机选函数,不是来自“输入恰好随机”。
一个可证明全域的构造如下。选一个素数 ,使所有键都落在 ,并且 。随机选择
定义
对任意不同键,它们在模 的线性变换后仍不同;再压到 个槽时,冲突概率至多为 。用链接法保存 个键时,不存在于表中的键所落链长的期望不超过 ;表内键所在链长的期望小于 。
全域哈希不等于密码学哈希。这里要控制的是字典操作中的冲突概率;密码学哈希还要求抗原像、抗第二原像等更强性质。不要用普通哈希表函数替代密码、签名或完整性校验中的专用算法。
5
使用 h(k)=k mod m 时,为什么通常不在未知数据分布下直接令 m=2^p?
6
关于全域哈希,下列哪些表述正确?
开放寻址:把所有元素留在数组里
开放寻址不为桶挂链表。每个数组槽只保存一个元素、空标记 NIL,或者删除标记 DELETED。冲突发生后,算法按照由键决定的顺序继续检查其他槽。
探查序列必须覆盖整张表
开放寻址把哈希函数扩展为两个参数:
第二个参数 是第几次探查。对每个键 ,序列
应当是所有槽号的一个排列。这样只要表里还有空位,插入最终就有机会找到它;若序列提前循环,即使其他槽为空也会错误地报告失败。
插入和查找必须走同一条序列
不考虑重复键时,基本插入算法是:
text
开放插入(T, k):
for i = 0 到 m - 1:
j = h(k, i)
if T[j] == NIL:
T[j] = k
return j
报告“表已满”查找必须重放相同的探查序列:
text
开放查找(T, k):
for i = 0 到 m - 1:
j = h(k, i)
if T[j] == k:
return j
if T[j] == NIL:
return 未找到
return 未找到为什么遇到 NIL 就能停止?因为插入同一个键时会先到达这里。若它当时是空槽,键不可能越过它存到后面。这个推理要求插入和查找使用完全相同的序列。
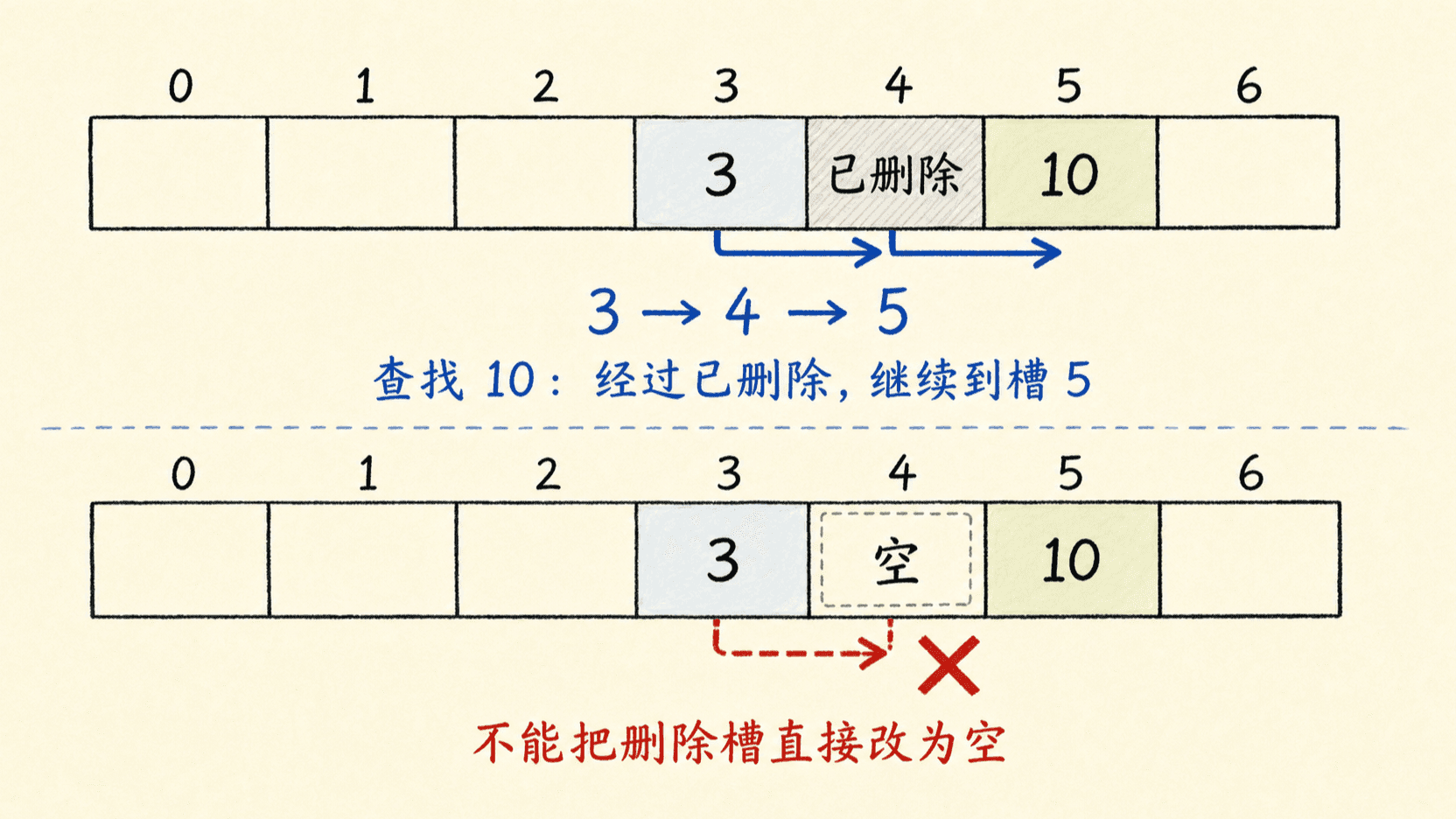
删除不能直接写回空槽
设键甲和键乙的探查序列都经过槽 3。甲先占槽 3,乙只好存到槽 4。若删除甲后把槽 3 改成 NIL,查找乙走到槽 3 就会提前停止,错误地认为乙不存在。
解决办法是写入特殊标记 DELETED,也常叫墓碑:
- 查找遇到
DELETED必须继续; - 插入可以复用墓碑,但若要防止重复键,最好记住遇到的第一个墓碑,继续查到
NIL或找到同键后再决定写入; - 删除标记积累后,探查长度不再只由当前 决定,因为墓碑也会阻止失败查找提前结束。
把这些规则合在一起,一个兼顾同键更新与墓碑复用的插入过程可以写成:
text
开放插入或更新(T, k):
firstDeleted = 未记录
for i = 0 到 m - 1:
j = h(k, i)
if T[j] == k:
更新该键的值并返回 j
if T[j] == DELETED 且 firstDeleted 尚未记录:
firstDeleted = j
if T[j] == NIL:
target = firstDeleted 已记录 ? firstDeleted : j
T[target] = k
return target
if firstDeleted 已记录:
T[firstDeleted] = k
return firstDeleted
报告“表已满”即使先遇到墓碑,也不能立即写入后返回,否则探查序列更后面可能已有同键。先继续查到 NIL,才能确认不存在重复键。若整条序列没有 NIL,但记录过墓碑,仍可复用第一个墓碑。
工程实现通常同时记录“有效元素数”和“已占用或墓碑槽数”。墓碑太多时,应重建表,把有效元素重新插入一张干净数组。
它为什么仍然有吸引力
开放寻址没有节点指针。同样的内存预算下,它往往能分配更多槽;元素连续存储也更利于缓存。但它不能让 超过 ,而且接近满表时探查代价会急剧上升。是否比链接法快,要由键大小、缓存、删除频率和负载阈值一起决定。
7
开放寻址查找遇到 DELETED 时,可以像遇到 NIL 一样立即判定键不存在。
8
开放寻址表有 100 个槽,最多保存一个元素的槽数为 ____;因此装载因子 α 不会超过 ____。
三种探查方法怎样分散冲突
探查公式决定了冲突之后往哪里走。线性探查最简单,二次探查让步幅变化,双重哈希则让步幅也依赖键。三者都只是对理想“随机排列”的近似。
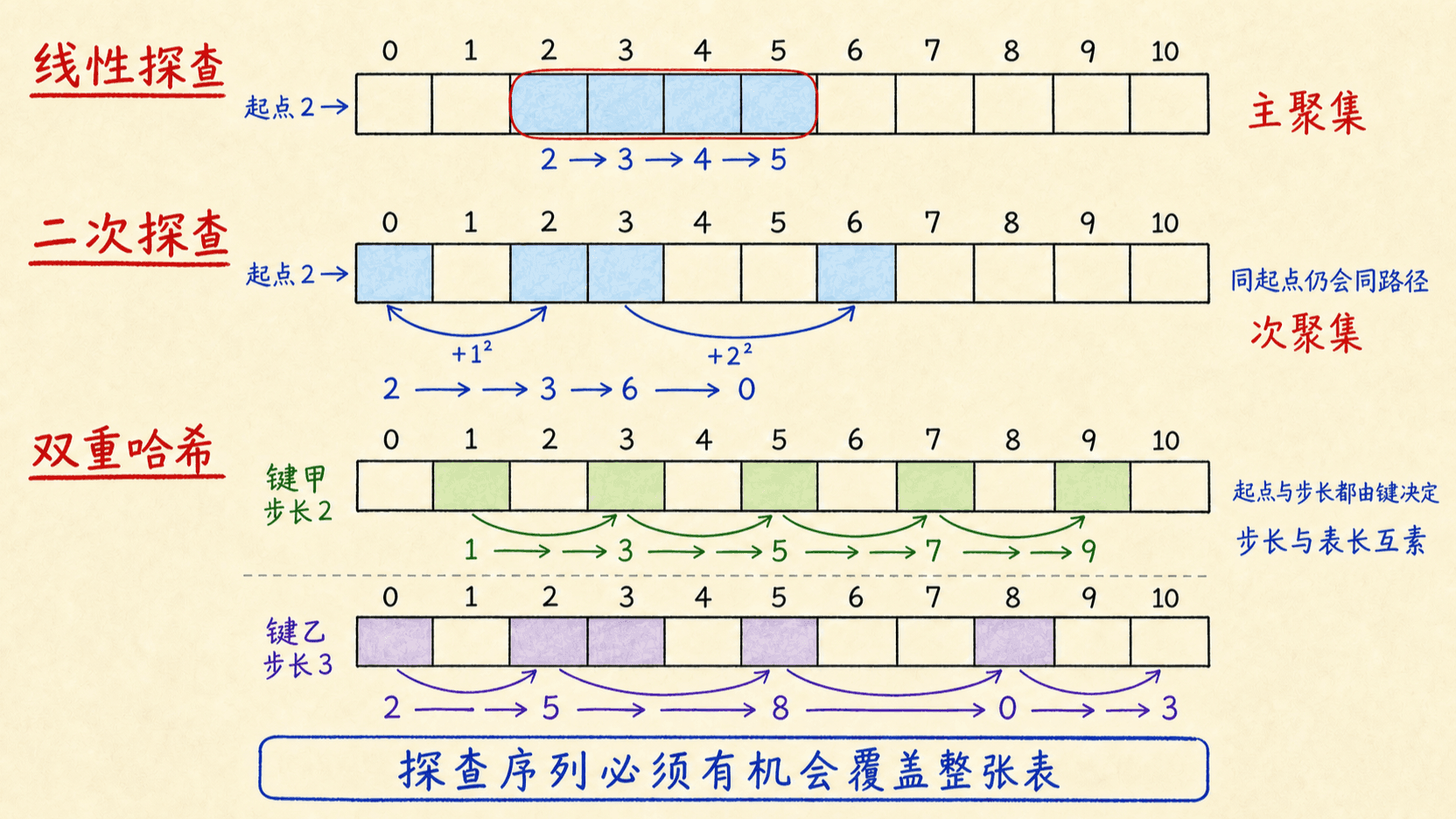
线性探查会形成主聚集
给定辅助函数 ,线性探查定义为
它依次查看初始位置、下一个位置,再下一个位置,到数组末尾后绕回开头。每个键的序列只由起点决定,因此只有 条不同探查序列。
连续占用区间会吸引更多键:只要一个键的起点落在区间内或紧邻区间之前,它最终就会填到区间末尾,使区间更长。这叫主聚集。占用段越长,后续插入和失败查找越容易走过很长一段。
二次探查减轻主聚集
二次探查使用
其中 为选定常数。探查偏移不再每次加一,因此能打散连续占用区间。但若两个键的 相同,它们仍会拥有完全相同的后续序列,这叫次聚集。
更重要的是, 不能随意搭配。错误参数可能让序列在访问所有槽之前重复。实现时必须证明所选参数能覆盖需要的槽,或使用有明确保证的组合,而不是看到公式里有平方项就认为它一定完整。
双重哈希让步长也取决于键
双重哈希定义为
决定起点, 决定步长。为了访问全部 个槽,必须满足
如果最大公因数是 ,序列只会访问 个槽就回到起点。常见安全选法有两种:
- 令 为 的幂,并保证 总为奇数;
- 令 为素数,并保证 。
当 为素数时,可以取
线性和二次探查大约只有 条不同序列,双重哈希由“起点、步长”共同决定,能产生约 条序列,因此通常更接近理想的均匀探查。
交互实验:同一批键的三种落点
下面的表长为 13。切换策略后会重新插入同一批键;点击槽位还可以查看该键实际经过的探查路径。
9
双重哈希中,为什么要求 h₂(k) 与表长 m 互素?
10
下列现象与探查策略的对应关系哪些正确?
装载因子怎样改变期望代价
哈希表的复杂度结论总带着条件。链接法依赖简单均匀哈希或类似保证;开放寻址的经典上界则使用更强的均匀哈希假设:每个键的整条探查序列,等概率是 个槽位排列中的任意一个。
线性、二次和双重哈希都无法真的生成全部 个排列。这个模型是分析基准,双重哈希通常最接近它,但仍不能把理论上界不加说明地当成任意实现的严格保证。
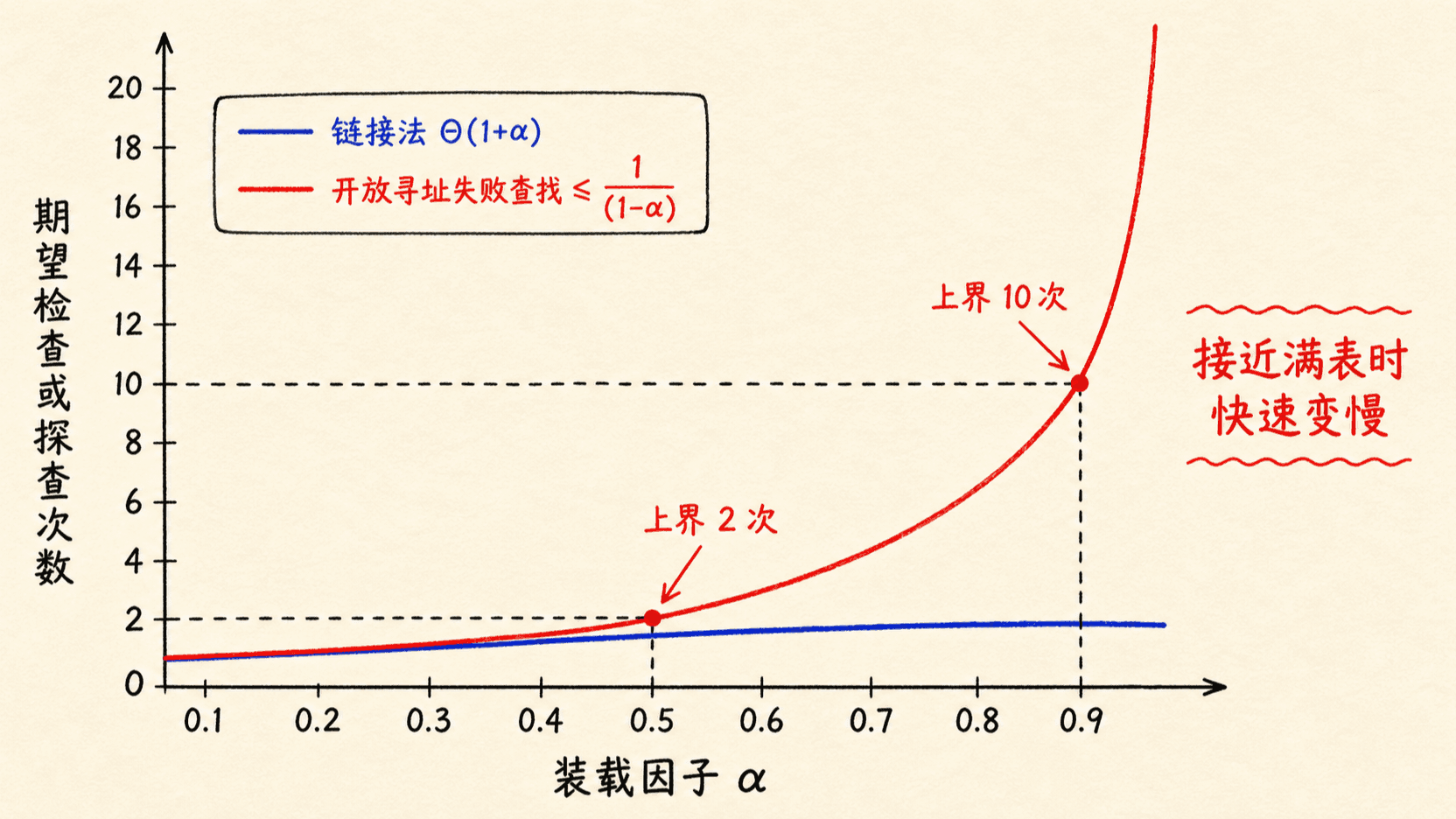
链接法的代价近似线性增长
在简单均匀哈希下,链接法失败查找的期望检查数是 ,加上求哈希与定位桶的时间,总期望时间为 。成功查找也是同一数量级。
这说明链接法允许 ,但不能说“超过 1 也完全没影响”。若 从 增到 ,平均链长也从 增到 。它仍能工作,只是常数不再小。
开放寻址在接近满表时急剧变慢
设 。在均匀哈希假设下,失败查找的期望探查次数至多为
插入就是一次直到找到空槽的失败查找,所以其期望探查次数也不超过这个值。
若表中每个键被查找的概率相同,成功查找的期望探查次数至多为
当 时,失败查找至多约 次,成功查找少于约 次;当 时,失败查找的上界升到 次,成功查找少于约 次。
失败查找增长得更快,因为它要一直探查到第一个真正的空槽。公式中的 也把边界说得很清楚:当 时,上界趋向无穷。
墓碑会让“当前有效元素数除以桶数”低估开放寻址的压力。大量删除后,即使 n/m 看起来很低,探查仍可能越过许多 DELETED。此时应把墓碑计入占用阈值,并通过重建清除它们。
交互实验:拖动装载因子
滑块展示理想均匀探查模型中的两个上界。它不是某次运行的实际次数,而是用来观察“接近满表”怎样放大风险。
11
在均匀探查模型下,开放寻址装载因子 α=0.8 时,失败查找的期望探查次数上界是多少?
12
开放寻址中,装载因子从 0.9 增到 0.95,只增加了 0.05,因此失败查找上界也只会小幅增加。
完全哈希:静态集合的最坏常数查找
普通哈希表把重点放在平均或期望性能上。如果键集合在构建后不再变化,我们可以花更多构建成本,换来查找时最坏情况只访问常数个位置。这就是完全哈希的使用场景,例如固定保留字集合、只读路由表或发布后不再变化的索引。
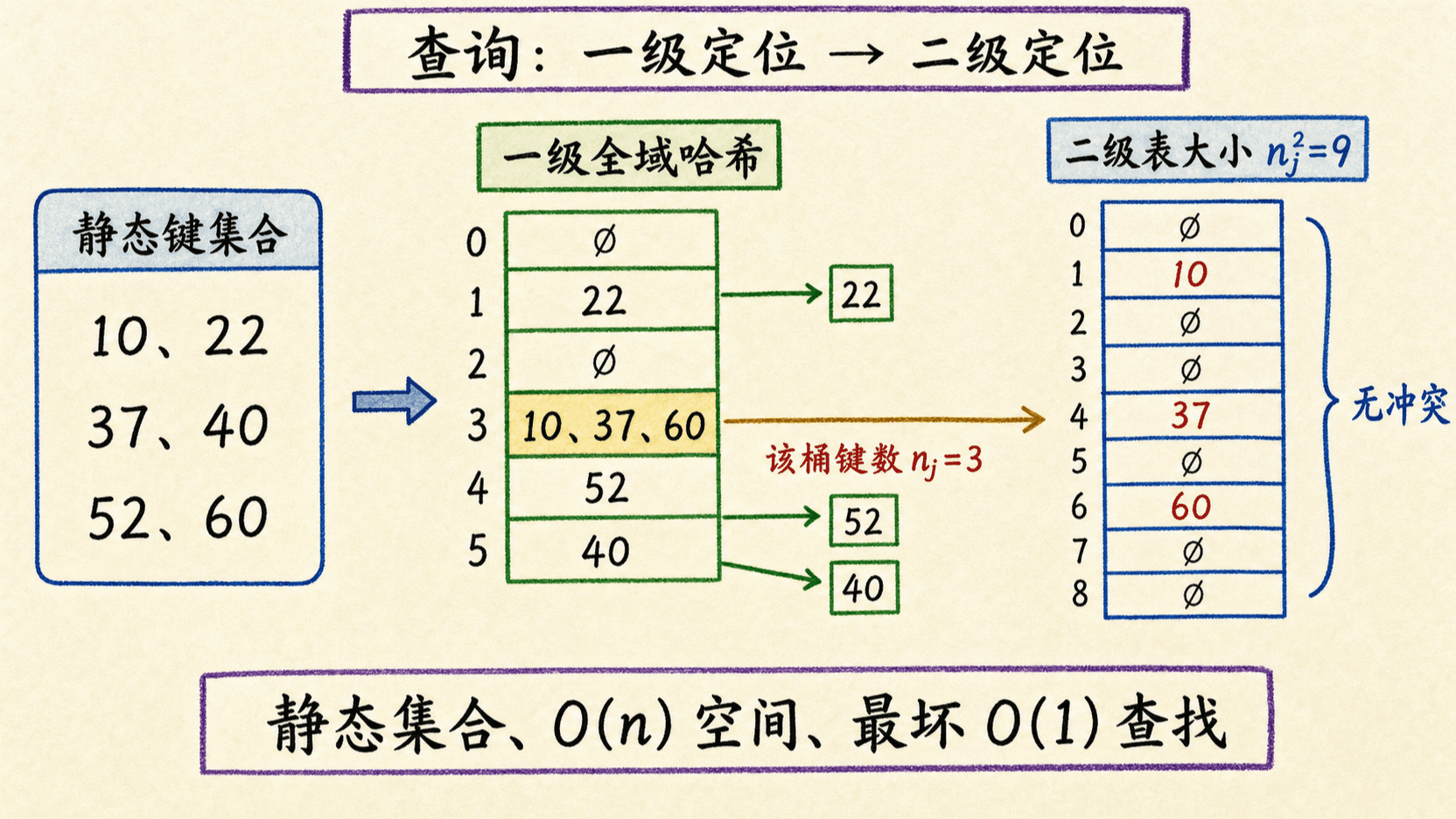
为什么单层平方空间能消灭冲突
先看一个小结论:用随机选自全域函数族的函数,把 个固定键放进 个槽。任意一对键的冲突概率至多为 ,键对数为 ,因此冲突对数量 的期望满足
由马尔可夫不等式,出现至少一次冲突的概率小于 。也就是说,随机挑一个函数,得到无冲突映射的概率大于 。若失败就换一组随机参数重试,期望只需常数次尝试。
直接为全部 个键分配 个槽太浪费。两级结构只在每个小桶内使用平方空间。
两级结构怎样构建
一级表分配 m=n 个桶,从全域函数族随机选择一级函数 h,把全部 n 个静态键分到桶中。记桶 j 的键数为 n_j。
桶 j 不再挂链表,而是分配大小 m_j=n_j^2 的二级表。空桶不分配存储,只有一个键的桶可直接保存该键。
为每个非平凡二级表独立随机选择全域哈希函数 h_j。若桶内有冲突,就只重选这个桶的函数,直到所有 n_j 个键各占一个槽。
查询键 k 时先算 j=h(k),再算二级位置 h_j(k),并核对槽中的键是否等于 k。两级哈希加一次键比较都是常数次数,因此最坏查找时间为 O(1)。
平方的二级表为何仍是线性总空间
二级表总槽数是
平方看起来危险,但一级函数从全域函数族随机选择且 时,有
理由可以从恒等式开始:
对所有桶求和,第一项总和是 ;第二项计算落在同一桶的键对数。任意键对的冲突概率至多 ,所以全部碰撞对的期望少于 ,最终总平方和的期望小于 。
进一步由马尔可夫不等式,二级表总空间达到或超过 的概率小于 。因此可以在一级阶段设置验收条件:若 ,就重选一级函数;通过后再构建各二级表。一级表、函数参数和二级槽加起来都是 空间。
完全哈希得到的是静态键集合上的 O(1) 最坏查找和 O(n) 空间。它并不适合频繁插入删除:键集合变化会破坏已经挑好的无冲突二级映射,通常需要局部或整体重建。
选择方案时先问四个问题
无论选择哪种方案,都还要统一键的相等规则与哈希规则:如果 a == b,必须保证 hash(a) == hash(b)。扩容后要重算桶位置;开放寻址要保留 NIL 与 DELETED 的区别;对外暴露复杂度时,还要说明是最坏、摊还还是期望结论。
13
两级完全哈希取得最坏 O(1) 查找依赖哪些设计?
14
一级桶 j 含 n_j 个键时,二级表分配 ____ 个槽;合格的整体构造可把总空间控制在 ____ 数量级。