外部表示与视觉:把认知负担放到屏幕上
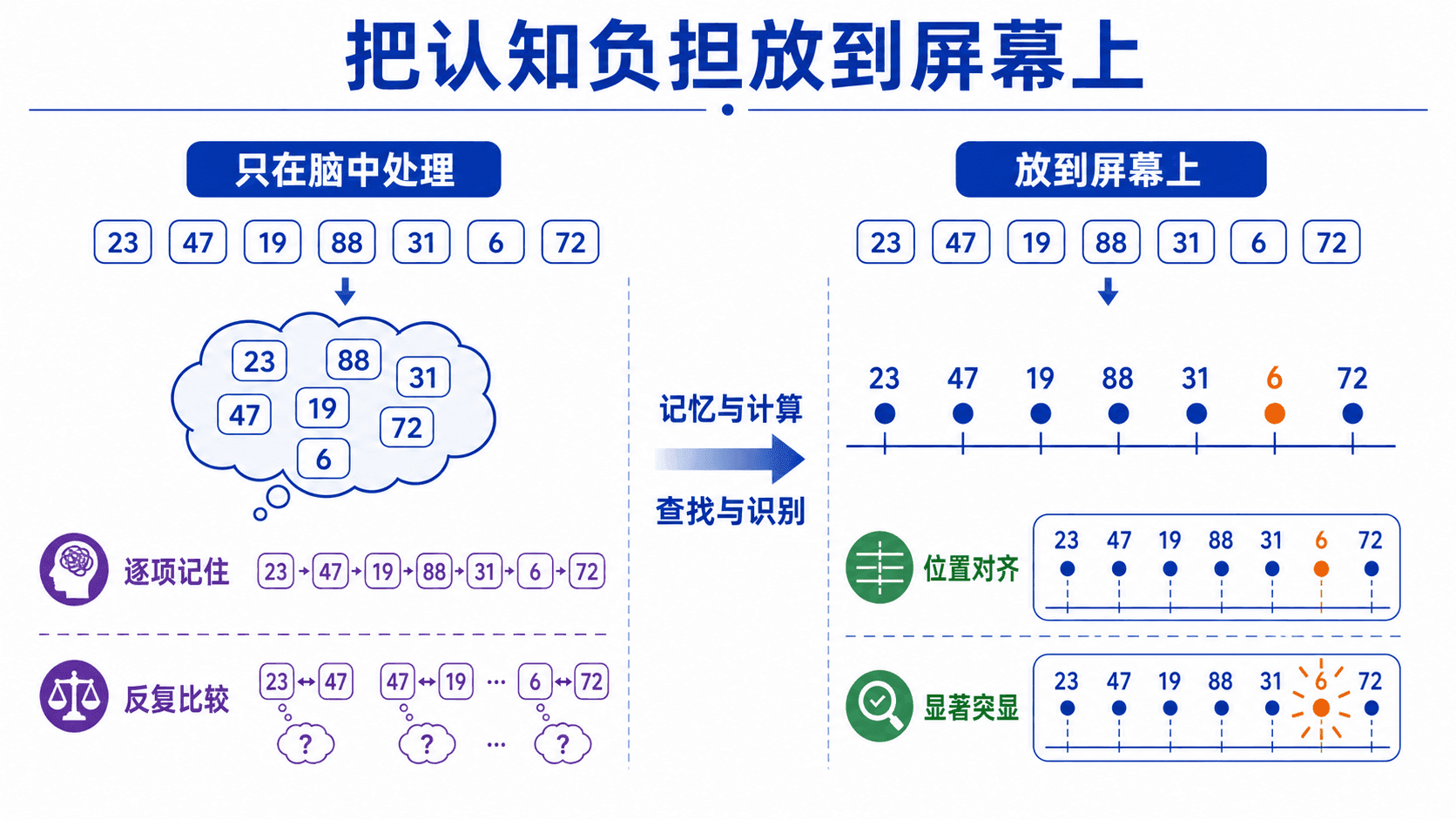
假设你要从八个城市的运营数据里找出异常值。有人依次念出八个数字,你需要一边记住前面的数字,一边比较刚听到的数字;即使数字不多,这件事也很快变得吃力。把同样的数据写成一列并按大小对齐,再用一个克制的强调色标出偏离项,任务就变了:你不再主要依赖记忆,而是在屏幕上查找位置、辨认差异。
这正是外部表示的价值。图表、表格和图示并不会替我们完成所有思考,却能把一部分记忆、匹配和计算转交给感知系统。好的设计让该比较的对象靠近,让相同含义稳定地出现在同一位置,让真正需要注意的差异自己浮现。坏的设计则会制造额外的来回查找,甚至比直接看数字更累。
从脑中运算到屏幕操作
“外部”不是指信息放在身体之外这么简单。关键在于:信息一旦被稳定地留在纸面或屏幕上,人就可以随时重新查看,不必在工作记忆里持续保存一份副本。算盘、便签、路线图、排班表和散点图形式不同,作用却很相似——它们都是可以反复读取的外部记忆。
看一个小例子。你要比较六个项目的完成率:72、81、69、88、76、84。如果这些数字逐个消失,你需要记住项目与数值的对应关系,还要在脑中维护当前最大值。若把它们排成共享基线的点图,最高点和最低点可以直接从位置判断;项目名与点放在同一行,也省去了把符号标签重新配对的步骤。
这个变化可以拆成三类“卸载”:
- 记忆卸载:数值、标签和状态持续可见,不用反复默念。
- 计算卸载:差值、顺序和聚类通过位置与距离显现,减少心算。
- 控制卸载:已完成、待处理和异常项有稳定标记,不用在脑中维护进度。
外部表示不是把思考交给图形,而是改变思考所需的动作。原来要“记住再比较”,现在可以“定位后识别”;原来要“回忆上一步”,现在可以“回看屏幕上的状态”。
屏幕是人和计算之间的交接面
当问题已经定义得很清楚,例如“找出所有低于阈值的记录”,计算可以直接筛选,没必要让人逐行检查。真正适合保留人的场景,通常是问题还没有完全定型:我们要探索哪些指标值得追问、某个模式是否合理,或者自动结果里有没有违背常识的部分。
这时,人和计算各做擅长的事。计算负责处理大量记录、更新布局、执行筛选和保持一致;人负责提出下一步问题、识别有意义的模式、判断结果是否可信。外部表示把机器整理出的结果放到一个可观察、可操作的空间里,人才能继续追问。
大量对象也说明了为什么布局应由计算生成。几十个节点还可能手工摆放,几百或几千个对象若逐个定位、着色和连线,很快就会超出人的耐心。自动布局节省的是制作劳动;布局规则是否支持当前任务,仍需要人的判断。
空间排列如何降低查找与推断成本
屏幕最有用的资源不只是像素,而是位置关系。对象放在哪里、彼此离多远、是否对齐,会直接改变读者需要执行多少次眼动、匹配和回忆。
把同一次推断需要的信息放在一起
如果判断一台设备是否异常需要查看温度、阈值和最近一次维护时间,就应让这三项出现在同一张设备卡片或同一行。把温度放在左侧表格、阈值放在右侧图例、维护时间藏在悬浮提示里,读者每判断一次都要跨区域取数,并记住刚才看到的值。
“放在一起”也要围绕任务,而不是把所有信息挤成一团。只在比较时需要的字段可以并排;低频说明可以按需展开。相关内容相距过远会增加查找,彼此无关的内容挤得太近又会暗示并不存在的关系。
用对齐替代标签匹配
表格的列、条形图的共享基线、时间序列的共同横轴,都在利用对齐。稳定位置让读者形成预期:这一列永远是状态,那一列永远是更新时间。预期一旦建立,目光可以直接落到目标区域,而不用每行重新解释结构。
对齐还能支持直接推断。两根条从同一基线出发,谁更长可以从端点位置判断;若它们漂浮在不同起点上,读者就必须先找基准,再估计差值。数据相同,操作成本并不相同。
用排序和分组缩小搜索范围
任意顺序的名单要求逐项扫描。按值排序后,最大值在一端;按地区分组后,比较华东地区时不必穿过整张表。排序和分组相当于在屏幕上提前完成了一部分搜索。
但分组必须对应真实问题。若读者要比较产品,却按录入时间把记录分成许多块,同一产品会被拆散。这样的空间组织虽然整齐,仍会迫使读者来回跳转。
空间接近会被自然地理解成“这些内容有关”。如果布局把无关信息放在一起,或把一个对象的关键信息拆散,外部表示会反过来增加认知负担。整齐不等于有效,关键要看排列是否支持当前问题。
视觉为什么适合展示整体结构
视觉能在一个二维平面上同时保留许多对象及其位置关系。读者可以先获得整体印象,再把注意力移到局部。这种“全局在场、局部细看”的方式,很适合回答哪里密集、哪里断裂、谁偏离群体等问题。
声音的体验不同。口头播报是一条随时间推进的序列,前一个数字说完就消失了。要比较开头和结尾,听者必须回忆先前内容,或者要求重播。屏幕上的二维排列则一直保留着开头、结尾和它们之间的关系,目光可以在任意两处来回移动。
这不表示声音没有价值。提示音很适合提醒事件发生,也能在视线被占用时提供补充。只是当任务要求浏览大量对象、比较多个位置并形成总体概览时,二维视觉空间通常更合适。
并行处理与视觉突显
视觉系统会在我们有意识逐项检查之前,先处理当前视野里的部分基本特征。例如,一枚橙色圆点放在一片灰色圆点中,往往会迅速跳出来。这个现象常被称为视觉突显。目标之所以显眼,不是因为读者依次检查了每个圆点,而是颜色差异可以在广阔视野内并行参与处理。
视觉突显的设计意义很直接:如果只有少量对象真的需要立即处理,可以给它们一个独特且稳定的视觉通道,例如明显不同的颜色、方向或形状。强调色越稀少,含义越一致,越容易成为有效线索。
若所有卡片都用了高饱和颜色、多个徽标同时闪烁、标题和数字都在争夺注意,屏幕上就没有真正的“突出”。显著性是一种相对差异;把每个对象都加强,等于没有加强。
目标与干扰项的差异也会改变搜索方式。单一、清楚的特征差异更容易形成突显;如果目标必须同时满足“某种颜色”和“某种形状”,而干扰项分别共享其中一个特征,读者通常需要更有意识地检查。后面的互动可以直接体验这种区别。
细节能揭示摘要丢掉的结构
摘要能快速压缩信息,却会丢失个体差异。假设两组客服通话的平均时长都是 5 分钟:一组大多集中在 4 到 6 分钟,另一组则大量集中在 1 分钟和 9 分钟附近。只显示平均值,两组看起来相同;把每次通话画成点,集中形态、间隙和极端值会立即变得可见。
因此,概览不应等同于只给一个汇总数字。更实用的安排是先让整体结构可见,再允许筛选、放大或查看单个对象。摘要回答“总体大约怎样”,细节帮助我们继续问“这个总体是怎样形成的”。
看见很多,不等于看清很多
视觉的并行处理能力很强,但不是无限容量。我们会感觉自己一次看到了整块屏幕,实际上,任一时刻只有视线中心附近的小范围最清晰。周边视野能提供颜色、运动和大致结构等线索,却不能让每个标签都同样清楚。
有意识的注意同样有限。屏幕里即使发生了很大的变化,只要注意力正被别处占用,也可能没有察觉。这就是为什么状态更新不能只依赖短暂闪动:变化发生后应保留结果,必要时提供位置稳定的提示、历史记录或明确的前后差异。
工作记忆也很有限。信息一旦不再直接可见,人很容易忘记具体值,视觉信息同样如此。弹窗遮住底层内容、翻页后丢失筛选条件、悬浮提示移开即消失,都会迫使读者记住刚才看到的状态。设计时应问:完成当前判断需要的证据,能否在同一时刻重新看到?
屏幕本身也有容量边界。把所有细节同时塞进有限像素会造成重叠和噪声。解决办法不是无限缩小字号,而是让概览、筛选与按需细节协同:先显示支持定位的结构,再让用户调出当前需要的细节。
可以把边界概括为四点:
- 整体视野可以并行感知部分特征,但清晰阅读集中在小范围内。
- 注意力会选择性聚焦,未被关注的变化可能被漏掉。
- 离开视野的信息很难长期、准确地保留在工作记忆中。
- 像素有限,过度叠加会破坏原本想利用的空间关系。
互动:比较串行查找与视觉突显
下面的互动把两种任务并排放在一起。左侧要求在外观相同的代码中匹配指定代码,更接近逐项核对;右侧要求寻找具有特定视觉特征的图形。你可以改变对象数量、目标特征和干扰项相似度,再观察自己的查找过程。
这不是对个人认知能力的精确测量。计时会受设备、窗口大小、鼠标操作和练习次数影响。它更适合用来体验:外部表示的编码方式一变,注意力需要执行的动作也会跟着改变。
把原则落到具体布局上
设计一张界面时,可以按下面的顺序检查。它不是固定模板,而是一条从任务回到布局的路径。
先写清楚读者要完成的判断。是找最大值、比较两组、追踪变化,还是检查异常?如果任务说不清,就无法判断哪些信息应该靠近。
列出当前判断必须同时看到的证据。把这些字段放在同一视野内,优先使用直接标签、同行对齐和共享尺度,减少跨区域匹配。
决定哪些关系可以交给空间表达。顺序可用位置,大小可用共享基线上的长度或位置,群组可用克制的间距和边界。不要让装饰破坏这些关系。
只为需要立即处理的对象保留强突显。检查强调色是否有单一含义,以及色觉差异、低对比度或黑白显示时是否仍有形状、文字等补充线索。
一个小练习
某运行面板把设备名称放在左侧固定表格,把实时温度放在需要横向滚动到最右侧才能看到的列,告警阈值则只出现在鼠标悬停提示中。值超过阈值时,整行短暂闪红一次,随后恢复原样。请找出至少三处认知负担,并给出调整办法。
外部表示做得好,读者会少记一点、少找几次、少在相隔很远的区域之间来回确认。判断标准并不神秘:完成同一个问题时,屏幕是否保留了必要证据,空间是否直接表达了关系,注意力是否被引向真正需要处理的差异。