从巨大设计空间回到任务:如何选择可视化方案
面对一份数据,我们很容易从“该画什么图”开始:柱状图还是折线图,要不要加颜色,要不要做成仪表板。这个顺序看似直接,却会把人带进一个几乎无穷的选择空间。单张静态图已经有许多画法;再加入筛选、缩放、联动、高亮、下钻和多视图组合,候选数量会迅速增加。
更稳妥的起点是先问清楚:谁要借助这份数据完成什么任务,结果需要多准确,哪些信息绝不能被弱化? 这些问题会把大量“能做”的方案,缩小成少数“适合做”的方案。
可视化方案不是一个图表名称。它是一套独特的表达与操作方法,由视觉编码和交互共同组成。相同的柱状图,只要筛选方式、联动关系或下钻路径不同,就可能成为不同的方案。
先弄清楚“方案”包含什么
视觉编码决定数据怎样出现在屏幕上。例如,数值可以映射为长度、位置、面积或颜色;类别可以分配到不同的行列;关系可以画成连线,也可以通过相邻位置表达。交互则决定用户能对这个表达做什么,例如筛选一个时间段、选中一组对象、展开层级或切换聚合粒度。
最简单的方案可能只是一张静态散点图、条形图或折线图。复杂方案会把多张图连接起来:用户点击条形图中的一个地区,旁边的散点图同步突出该地区的门店;继续点击某个门店,明细表再显示具体订单。每增加一种编码、一个视图或一次交互,就多出一组组合方式。
因此,设计空间大,不只是因为图表类型多。真正让它膨胀的是下面这些选择可以相互组合:
- 数据用什么位置、形状、大小和颜色表达;
- 数据拆成一张图还是多个视图;
- 是否筛选、聚合或只展示局部;
- 视图之间是否联动;
- 用户从总览走到细节时,要经过哪些操作。
如果没有任务约束,讨论“哪种图最好”不会得到稳定答案。同一个方案可能非常适合查找离群点,却不适合逐项读取精确数值;也可能适合个人探索,却不适合在短时间内向他人说明结论。
把业务说法翻译成可判断的任务
真实需求通常先以领域语言出现。例如,“看看本月华东区为什么掉出前三”“判断这批设备是否有异常”“给管理层说明预算变化”。这些说法提供了背景,却还不足以直接选择方案。我们需要把它们翻译成更稳定的任务描述。
以“华东区为什么掉出前三”为例,可以继续拆问:是要查找排名发生变化的时间点,比较各地区的增减幅度,还是定位少数拖累整体的门店?三种任务面对同一份销售数据,合适的表达并不相同。查时间点更需要连续趋势,比较幅度更依赖可对齐的长度或位置,定位异常门店则需要保留单个对象及其整体分布。
领域术语告诉我们问题发生在哪里,抽象任务告诉我们用户要做什么。设计时要同时保留两者:只懂领域说法,方案难以迁移;只写“分析数据”,又会因为任务过于宽泛而失去约束。
可以先用四个常见动词给需求定方向:
“查找”还可以是开放探索,也可以是验证一个已有判断。前者需要允许用户尝试不同切片,后者更重视明确条件和可复核结果。看起来相同的动词,仍要结合目的细化。
不要把数据类型当成任务。时间数据并不自动等于折线图:用户可能要读取某天的精确值、比较几个关键节点,也可能只想看长期走势。数据限定了哪些表达可行,任务才决定哪一种表达有效。
有效性有三条底线
可视化首先要帮助用户完成任务。美观可以降低阅读阻力,也能建立清楚的视觉层级,但它不能替代正确、准确和忠实。
正确:表达规则不能把关系画错
坐标、排序、聚合和筛选都要与数据含义一致。把没有大小顺序的类别放进连续色阶,容易让人误以为类别之间存在高低;把不同口径的数值放在同一尺度上比较,也会制造并不存在的差异。
准确:用户要能辨认任务所需的差异
“没有画错”并不等于“足够好读”。如果任务是比较几个接近的数值,角度和面积通常不如对齐的位置或长度容易判断。如果任务只需看总体结构,过多数字标签又会遮住模式。精度要求不同,编码选择也应改变。
忠实:强调与省略都要经得起说明
任何画面都会取舍。筛选决定哪些记录进入视图,聚合决定哪些细节被合并,坐标范围决定差异看起来有多强。可视化不可能同时呈现数据的所有侧面,因此“忠实”不是拒绝取舍,而是让取舍与任务一致,并把会影响判断的口径和范围说清楚。
地图可以帮助理解这种边界:它一定会省略真实世界中的大量细节,并强化道路、边界或地形中的一部分。省略本身不是问题;如果用户要规划步行路线,却拿到只强调行政区面积的地图,才是任务与抽象之间的错配。
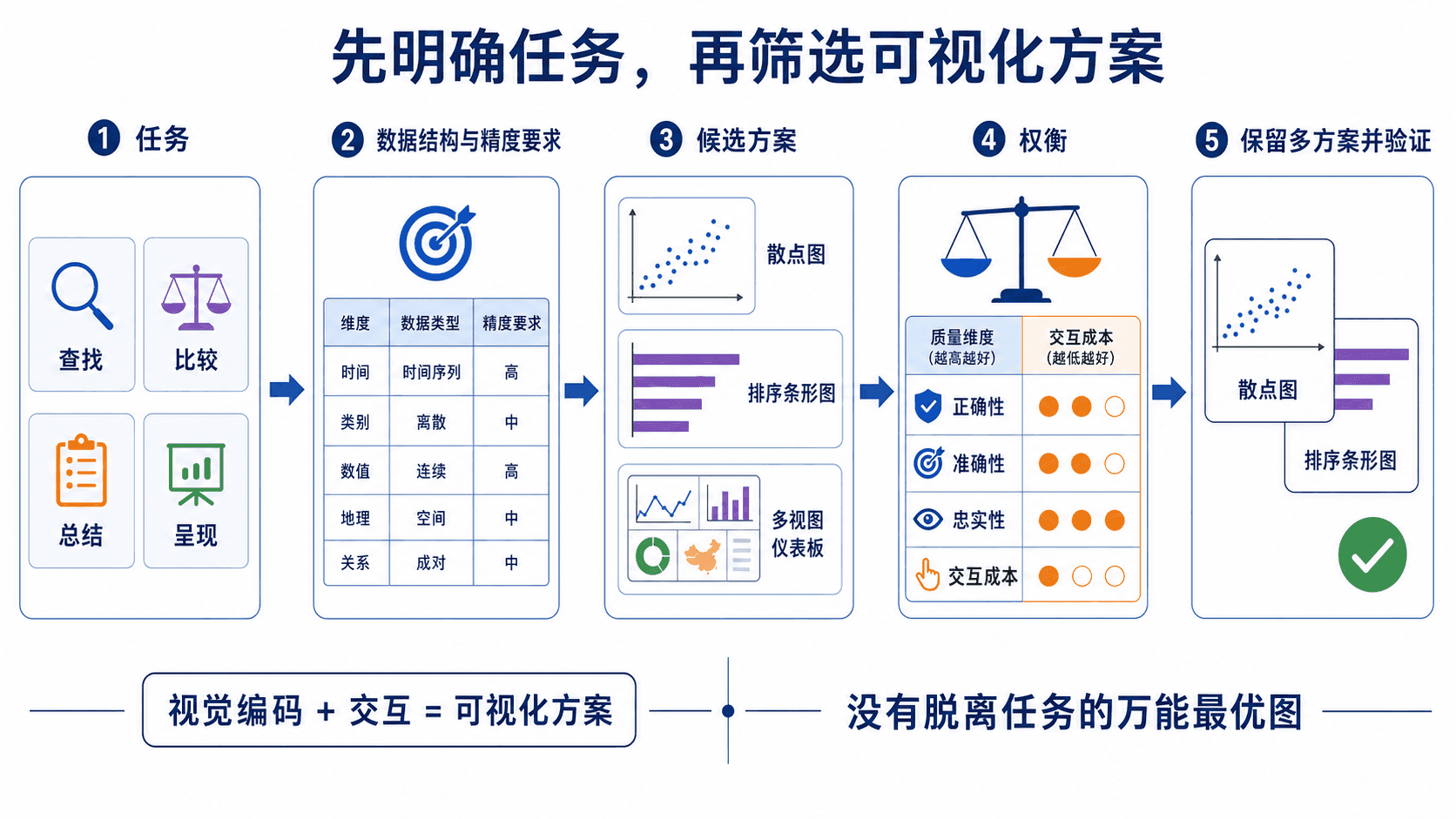
不要把第一个可用图当成答案
所有可能方案中,只有一部分是我们知道的;知道的方案中,只有一部分会被认真考虑;认真考虑后,又只有少数值得做成原型。经验不足时,最大的风险不是没有灵感,而是候选空间过窄:脑中先出现一种熟悉图表,就立刻围绕它修饰。
更可靠的做法是并行提出几种结构明显不同的候选。例如,同一任务可以同时考虑排序条形图、散点图加筛选器、总览与明细联动的双视图。先用任务、数据和精度排除明显错配,再对剩下的方案做小成本验证。
候选之间通常存在权衡:
- 单视图阅读路径短,但可能容不下多层细节;
- 多视图能同时保留总览和局部,却增加视线移动和学习成本;
- 聚合能减轻拥挤,但可能隐藏离群对象;
- 交互能按需展开信息,却要求用户知道“还可以操作”。
这里不必追求一个脱离环境的绝对最优解。实际目标是找到一个在当前用户、任务、数据规模和设备条件下足够好的方案,并明确它牺牲了什么。
动手做一次任务—设计匹配
下面的实验把任务、数据结构和精度要求放在设计之前。改变任意条件,候选排序和理由都会变化。分数只是帮助比较的提示,不是通用公式;真正要观察的是推荐理由和代价怎样随条件改变。
用一套流程收敛选择
先写清使用情境。说明谁会使用、在什么设备和时间压力下使用,以及结果会影响什么决定。一个面向分析人员的探索界面,和一个会议中展示三十秒的画面,约束完全不同。
把领域问题改写成任务。使用“查找、比较、总结、呈现”等动作,再补上对象和结果,例如“比较各地区本月与上月的增减幅度”,不要只写“分析销售情况”。
描述数据结构与必要精度。确认字段类型、数据规模、层级、缺失情况,并判断用户要读精确数值、相对顺序还是整体模式。
并行提出至少两到三种候选。候选之间要有结构差异,而不只是换颜色。为每个候选写出它支持的任务、容易误读的地方和交互成本。
这套流程的关键不是每一步都做得很重,而是保证选择有来路。小项目可以用纸面草图比较候选;复杂工具再增加交互原型和正式测试。
分清手段和目的
同一个操作在不同上下文中,角色可能相反。排序就是典型例子。
如果用户最终需要一份按增长率排列的地区名单,排序本身就是结果,设计应保证名次、数值和排序口径清楚。如果用户排序只是为了让偏离整体趋势的对象浮现出来,排序就是通往“找离群值”的中间手段。此时最终方案还要帮助用户判断偏离程度、查看对象细节,并回到整体分布中复核。
复杂分析往往由多个这样的环节连接:上一步筛选或聚合产生的数据,成为下一步比较或呈现的输入。只看某一步“用了什么图”,容易把操作误当成目标。每次都追问“这一步的输出接下来拿来做什么”,才能分清目的、数据和方法。
一个方案是否合适,最终要回到具体任务上判断:用户能否得到正确结果,能否看清所需差异,画面有没有隐瞒会改变判断的信息。候选越多越不等于设计越好,但过早固定第一个方案,通常会错过更合适的路径。
检查自己是否真的从任务出发
1
同一份门店销售数据,管理者要快速比较各门店本月增幅。选择方案时应先确认什么?
2
只要视觉效果足够美观,即使聚合隐藏了少数异常对象,也可以认为方案有效。