形式化关系查询语言:把查询写成可推导的表达式
日常写 SQL 时,我们习惯直接写 SELECT、FROM 和 WHERE。形式化查询语言把表面语法拿掉,只保留查询的逻辑骨架:输入是什么关系,经过哪些运算,最后得到什么关系。这样做的直接好处,是同一个查询可以被检查、组合、等价改写,也可以画成一棵表达树交给系统执行。
这一页使用同一个“云帆学习平台”场景。我们会先建立一组很小的关系,再从选择、投影一路走到连接、集合运算、赋值、重命名与等价变换。关系演算部分聚焦声明式思想,不额外引入元组变量、域变量和安全表达式等完整形式系统中的规则。
为什么要把查询写成形式语言
查询语言都在回答“怎样从已有数据得到目标信息”,但表达请求的方式并不相同。可以先用三个问题区分它们:是否给出逐步修改状态的命令,是否组合无副作用的函数,还是只描述结果应满足的性质。
- 命令式语言给出一连串操作,并在执行中更新状态变量。
- 函数式语言把计算写成函数求值;函数可以接收数据,也可以接收另一个函数的结果,但不依靠修改程序状态获得答案。
- 声明式语言描述目标信息的性质,不指定取得它的操作顺序,系统负责寻找计算方法。
关系代数属于函数式查询语言。很多讲解也会把它称为“过程式”,因为表达式明确展示了选择、连接、投影等运算的组合路线。不过,这里的“过程性”不等于命令式程序:关系代数表达式没有循环修改状态的副作用,它只是把关系映射成新关系。
元组关系演算与域关系演算属于声明式查询语言。它们用数学逻辑刻画结果应满足的条件,重点是“答案是什么”。在实际查询语言中,命令式、函数式和声明式成分可能同时出现;形式语言的价值,是让我们先把这些成分背后的数据变换看清楚。
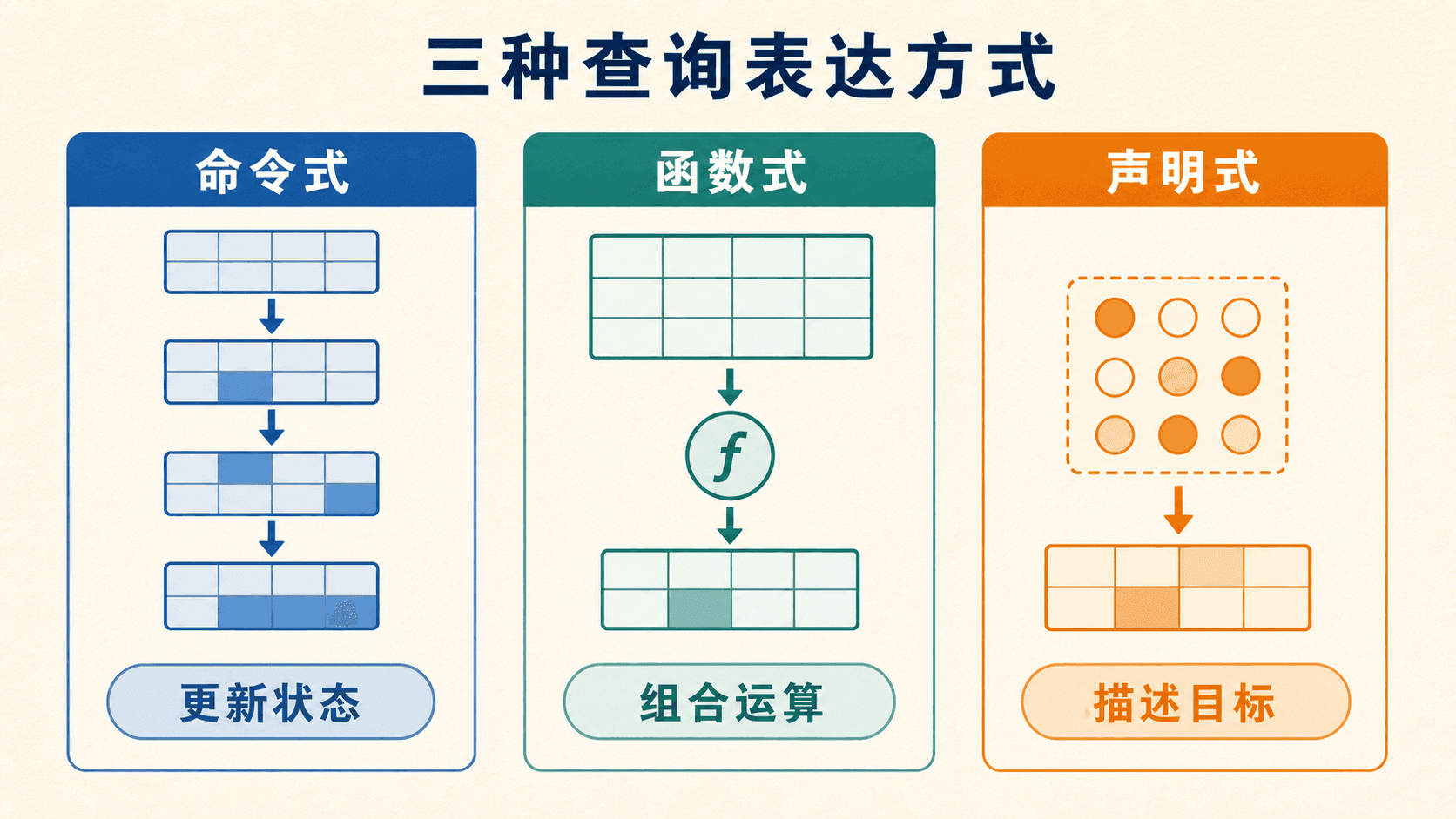
三类语言的区别在于请求的表达方式,不在于最终能否返回一张表。
形式化表达带来的检查能力
形式表达式很短,却能暴露自然语言中容易隐藏的问题。例如“找出进阶课程的学习者姓名”至少要回答四件事:进阶条件来自哪张关系,学习者与学习记录怎样匹配,重复姓名是否消除,最后保留哪些属性。把查询写成运算后,每一步的输入模式和输出模式都可以检查。
形式表达式还能支持等价改写。两棵表达树的运算顺序不同,只要它们在每一个合法数据库实例上产生相同的元组集合,就可以视为等价。系统因此不必机械照着书写顺序执行,而能在保持结果不变的前提下寻找更合适的计算路线。
判断一种表达是否“形式化”,关键不在于符号看起来复杂,而在于运算对象、输入条件和结果语义都有明确规则。符号只是把规则压缩成便于组合的写法。
1
哪一项最准确地描述了关系代数中的‘过程性’?
先固定关系、模式与集合语义
云帆学习平台维护四个关系。为了让后续表达式可读,我们只保留本页会使用的属性。
text
学习者(学员号, 姓名, 方向, 等级)
课程(课程号, 课程名, 方向, 学分)
学习记录(学员号, 课程号, 学期, 状态, 成绩)
讲师(讲师号, 姓名, 方向, 课酬)示例实例如下。这里的关系按数学集合处理,同一元组不能出现两次,行的排列次序也不属于关系语义。
text
学习者
学员号 姓名 方向 等级
S01 林舟 数据方向 进阶
S02 周宁 产品方向 入门
S03 叶岚 数据方向 进阶
S04 唐可 设计方向 入门
课程
课程号 课程名 方向 学分
C10 关系数据库 数据方向 4
C20 数据可视化 数据方向 3
C30 用户研究 产品方向 2
C40 交互原型 设计方向 3
学习记录
学员号 课程号 学期 状态 成绩
S01 C10 2026春 已完成 92
S01 C20 2026春 学习中 88
S02 C30 2026春 已完成 84
S03 C10 2025秋 已完成 90
S03 C20 2026春 已完成 95关系代数的闭包
关系代数运算接收一个或两个关系,结果仍是一个关系。这条性质称为闭包。设关系的全集记作 ,一个一元运算 与一个二元运算 可以概括为:
闭包让运算可以嵌套。前一步的输出无需转换类型,就能直接成为下一步的输入。选择、投影与重命名是一元运算;并、差、笛卡尔积和连接是二元运算。
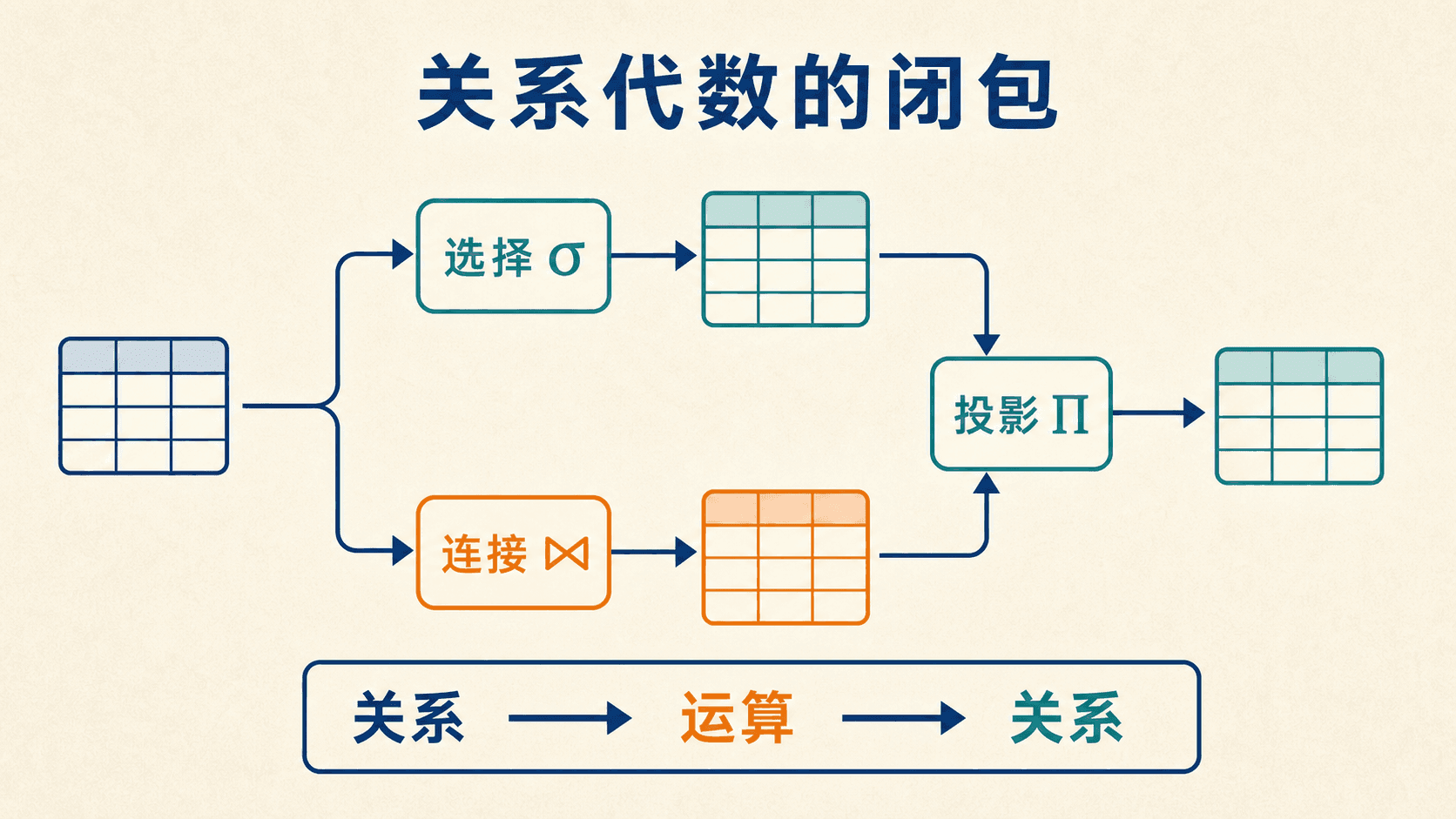
每个运算节点都“吃进关系、吐出关系”,因此表达式可以一直组合下去。
集合关系与实际表的差别
形式关系代数采用集合语义,所以投影等操作会消除重复元组。实际数据库表通常允许重复行,SQL 的输入和输出常按多重集处理。两者的区别不能忽略:若两位学习者同名,集合投影姓名可能只保留一个“林舟”,而多重集投影可以保留多份同名值。
多重集版本仍能定义选择、投影和笛卡尔积,但要记录每个元组出现的次数。例如,输入中某元组有 份且满足选择条件,选择结果中仍有 份;两个输入元组分别有 与 份,它们拼接而成的积元组会出现 份。
这套多重集运算也能说明基础 SQL 查询的逻辑结构。若查询从 取数,用谓词 过滤,并输出属性 ,其内部骨架可以写成:
这也再次说明:关系代数的选择对应 SQL 的 WHERE,关系代数的投影才对应 SQL SELECT 后面的输出列表。
本页没有特别说明时,所有公式都采用集合语义。把等价规则搬到 SQL 前,要先检查 DISTINCT、ALL 和重复行计数是否会改变结论。
2
在集合版关系代数中,关系包含相同的两条元组时,可以靠它们的先后位置区分这两条元组。
用选择与投影完成一元变换
选择和投影很容易被名称误导。选择 过滤行,投影 保留列。SQL 里的 WHERE 更接近关系代数的选择,SQL 里的 SELECT 列表更接近投影。
选择:保留满足谓词的元组
要找出数据方向的进阶学习者,可以写成:
选择谓词可以使用 、、、、、,也能用合取 、析取 和否定 组合条件。谓词还可以比较同一元组的两个属性,例如在带有“计划学分”和“已修学分”的关系中筛选两者相等的记录。
选择不改变关系的属性列表,只减少或保留元组。若输入模式为 ,选择结果仍使用同一模式。
投影:保留指定属性并去重
若只关心学习者的姓名与方向,可以写成:
投影会改变模式。若只投影“方向”,四位学习者会得到“数据方向、产品方向、设计方向”三个元组,因为重复的“数据方向”按集合语义合并。
广义投影允许投影列表出现属性表达式。假设要把讲师课酬换算成按月预算,可以写成:
组合:先过滤,再缩窄模式
“找出数据方向进阶学习者的姓名”可以组合成:
内层选择先得到完整的学习者元组,外层投影再只保留姓名。若把投影提前,就必须保证后续谓词需要的“方向”和“等级”仍在中间关系中,否则表达式将无法求值。
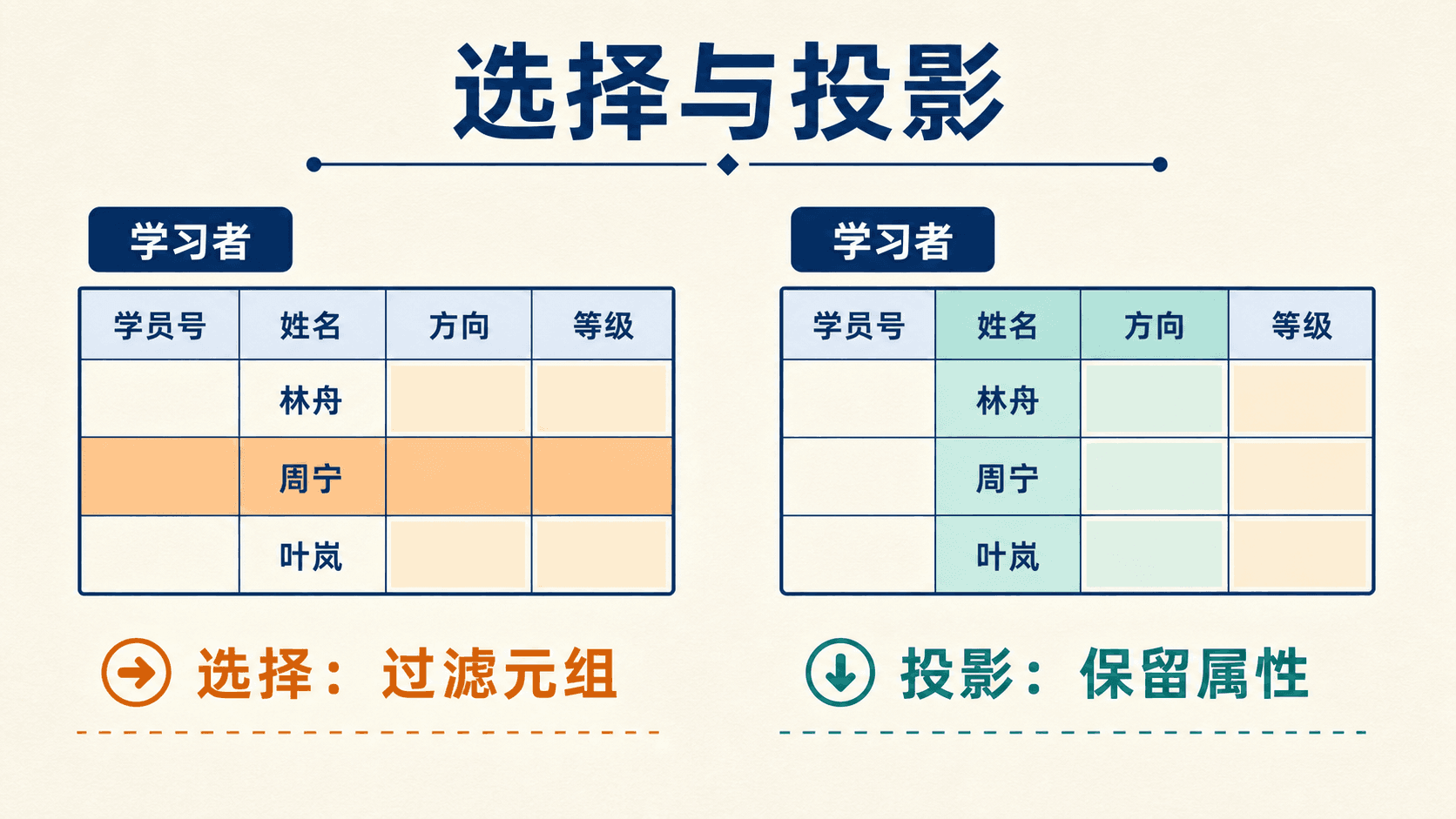
选择沿纵向减少元组,投影沿横向缩减属性;两者组合时要保留后续步骤仍要使用的属性。
3
要查询‘2026 春成绩不低于 90 的学习者姓名’,哪种运算顺序保留了后续步骤所需属性?
用积、连接和集合运算组合关系
二元运算接收两个关系。笛卡尔积负责产生所有组合,连接从组合中保留有业务意义的配对;并、交、差则把兼容关系当作集合计算。
笛卡尔积:列拼接、行全配对
设 有 个元组, 有 个元组,则 把每个 元组与每个 元组拼接,元组数为:
若把“学习者”与“学习记录”直接相乘,4 位学习者与 5 条记录会产生 20 个组合,其中绝大部分把一个学习者拼到了别人的记录上。两个输入若都有“学员号”,结果必须用“学习者.学员号”和“学习记录.学员号”区分归属;只在一侧出现的属性通常可以省略关系名前缀。
连接:在积上施加匹配条件
要把学习者与自己的学习记录配对,可以先做积再做选择:
theta 连接把这两个步骤合成一个运算。对关系 、 和定义在 属性上的谓词 ,定义为:
因此上面的表达式也可以写为:
连接结果会同时保留两侧的学员号。若最终不需要重复的连接键,可以再投影目标属性。自然连接进一步省去显式谓词:它要求两侧所有同名属性相等,并把重复的同名属性保留一份。写起来方便,但模式增加同名属性时,连接条件也会悄悄变化,所以长期复用的查询更适合把条件写清楚。
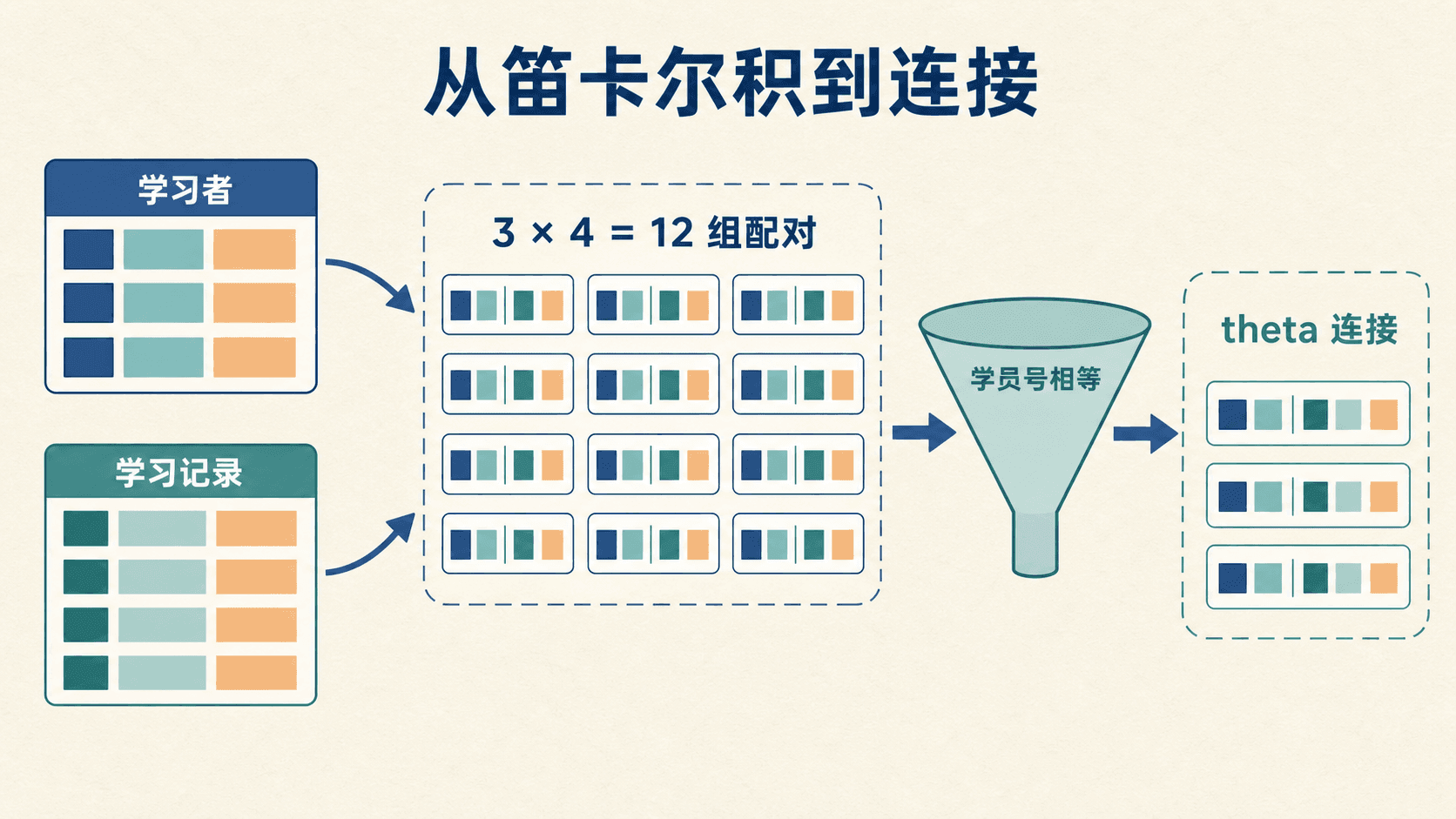
连接不是凭空“合表”,而是笛卡尔积加匹配谓词的紧凑写法。
并、交和差:先检查相容性
设 表示 2025 秋完成的课程号集合, 表示 2026 春完成的课程号集合:
是两个学期至少完成过一次的课程; 是两个学期都有人完成的课程; 是 2025 秋有人完成、但 2026 春无人完成的课程。并、交、差都要求输入相容:属性个数相同,并且每个对应位置的属性类型一致。
差集有方向, 通常不等于 。交集可以由差集表示:
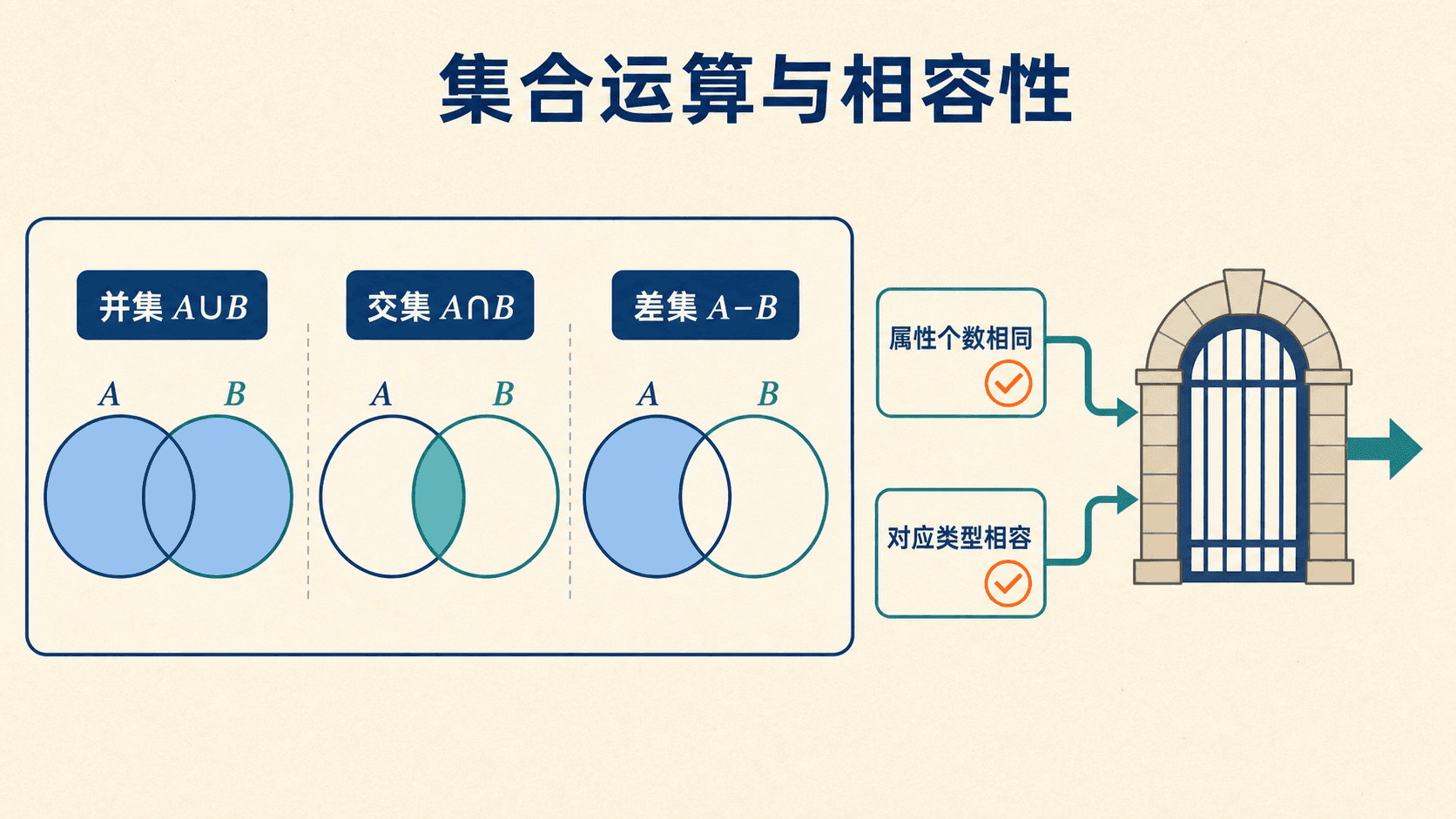
集合运算先比较模式,再比较元组;“都有四列”仍不够,对应列类型也必须匹配。
聚合、自然连接与外连接
基础运算之外还有一些常见扩展。聚合运算能在整个关系上,或按一组属性分组后计算平均值、总和、最小值与最大值。例如,按方向计算讲师平均课酬可以记为:
聚合结果仍是关系,所以可以继续参与选择、投影或连接。自然连接用两侧所有同名属性的相等条件替代显式 ;外连接则保留一侧或两侧未匹配的元组,并用空值补齐缺失属性。它们都让常见查询更短,但没有免除模式与空值检查。
存在性查询还常用半连接与反连接表达。 对 的半连接只保留 中至少能在 找到匹配的元组;反连接只保留 中找不到匹配的元组。它们可以由其他关系代数运算组合出来,因此不增加表达能力,却能清楚表示“存在匹配”和“不存在匹配”,也便于系统采用专门的高效实现。
外连接会保留未匹配元组,并用空值补齐缺失一侧;它与普通连接的等价规则不同。特别是把选择推到外连接输入端时,未匹配行是否被保留可能改变,不能照搬内连接的推导。
4
关于二元关系运算,哪些说法成立?
用赋值、重命名与表达树组织复杂查询
嵌套表达式很快会变长。赋值给中间结果一个临时变量,重命名解决同一关系多次出现时的歧义,表达树则把嵌套结构变成可视的求值依赖。
赋值:给中间关系取临时名字
“同时在 2025 秋和 2026 春完成过的课程”可以拆成三行:
前两行只把结果绑定到临时关系变量,不向用户显示结果;最后一行才产生查询答案。赋值没有增加表达能力,它只是减少重复并让推导更容易阅读。这里的左箭头不能指向永久关系,否则含义会从查询变成数据库修改。
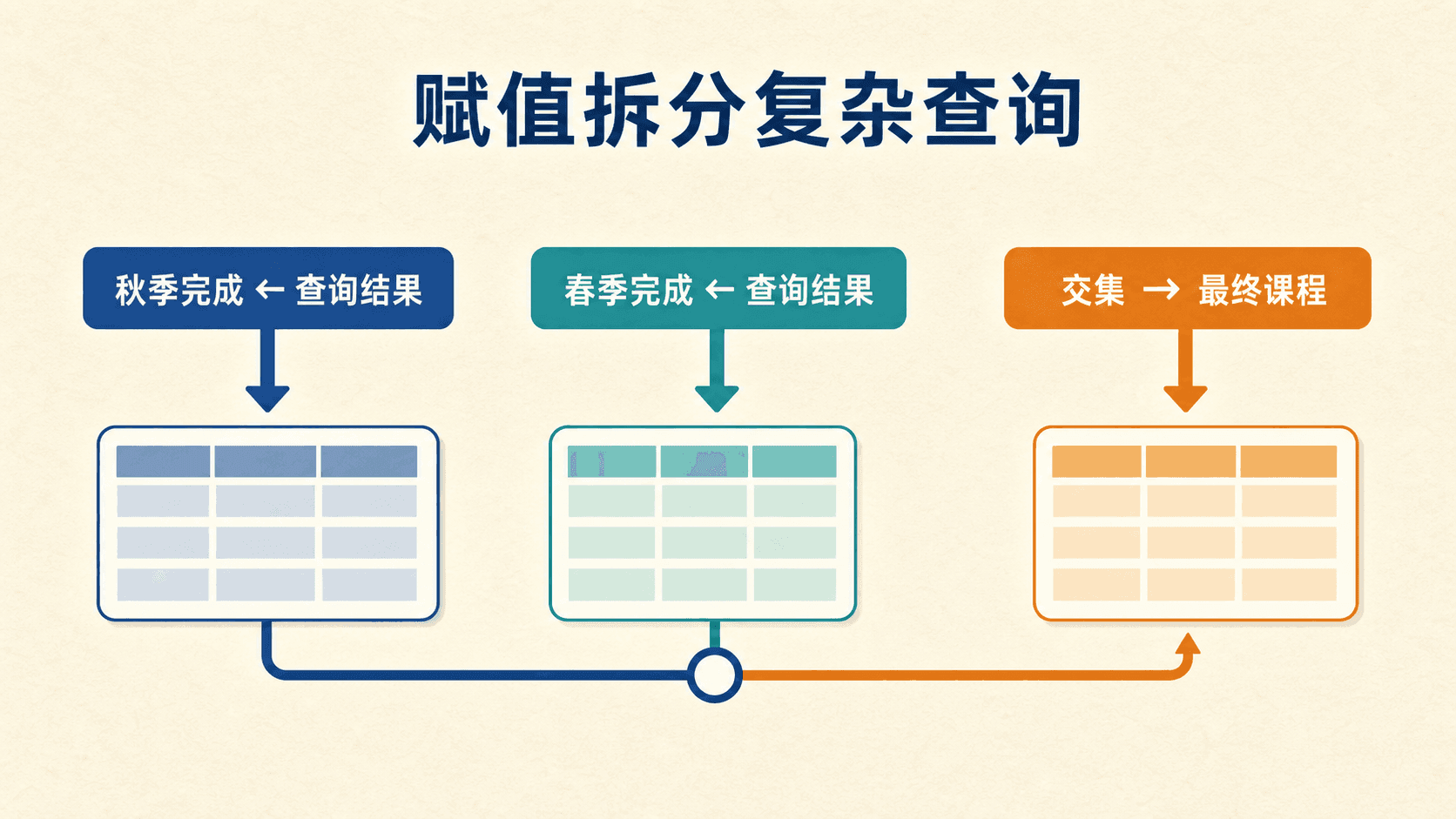
临时关系变量像演算草稿中的中间量,帮助阅读,但不改变代数能表达的查询集合。
重命名:区分关系的两次出现
重命名运算用 表示。 把表达式 的结果命名为 ;若结果有 个属性,还可以同时给关系和属性命名:
假设要找出“课酬高于讲师 T02 的讲师号与姓名”。同一个“讲师”关系必须出现两次:一次代表候选讲师,一次只取 T02 作为比较基准。给两次扫描分别取名 与 后,属性归属才清楚:
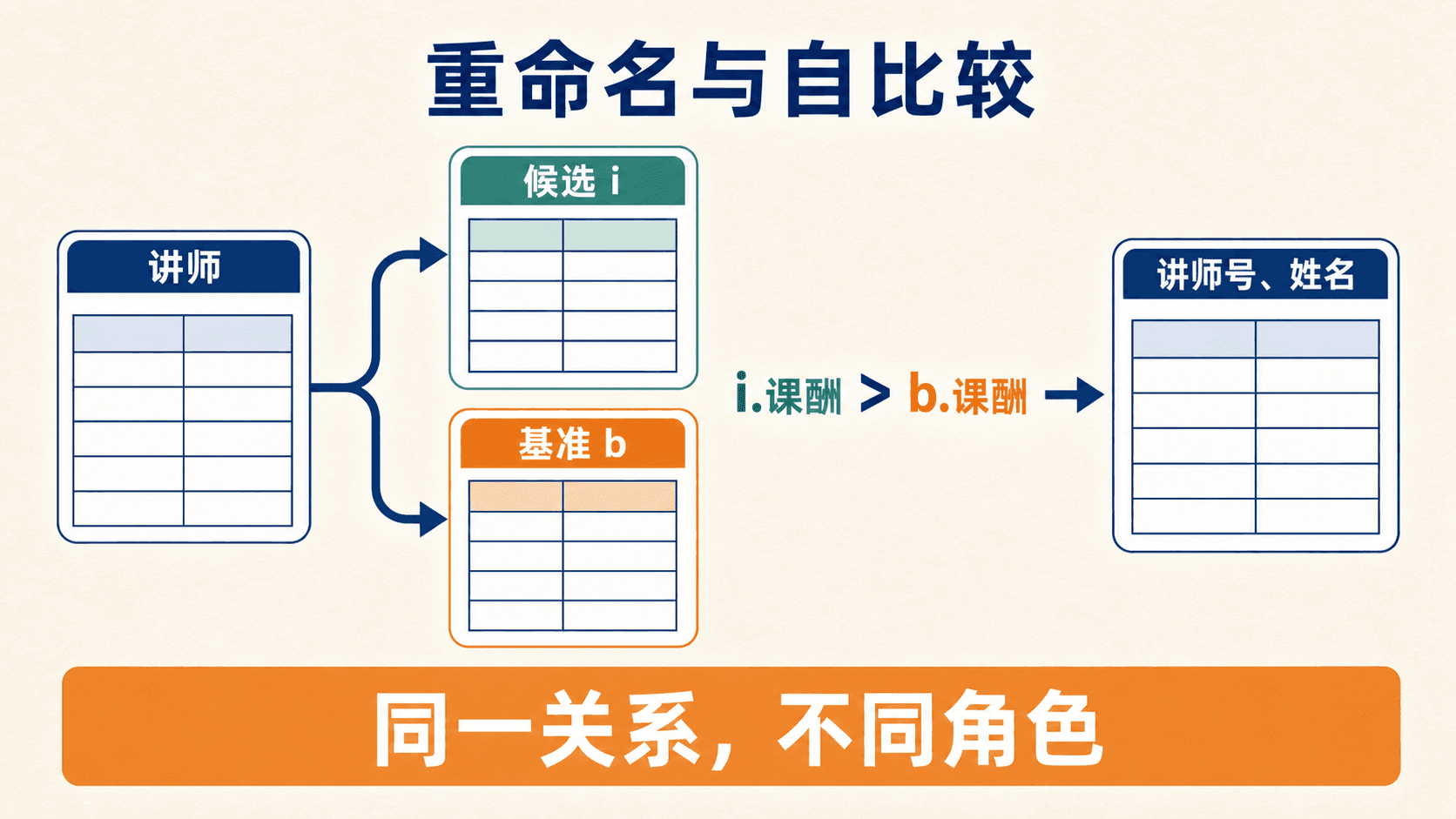
重命名改变引用名称,不复制或修改原关系;它让自比较中的角色分工可见。
表达树:从叶子到根求值
关系名位于叶子,运算符位于内部节点,根节点给出最终结果。下式“找出 2026 春完成数据方向课程的学习者姓名”包含三个输入、两个连接、两个选择和一个投影:
上式故意埋了一个模式错误:关于“学习记录.学期”和“学习记录.状态”的选择被错误地放在“学习者”上,那个节点没有这两个属性。表达树的好处之一,就是能沿每个节点核对模式并迅速发现这种错误。正确写法应把该选择放到“学习记录”输入上:
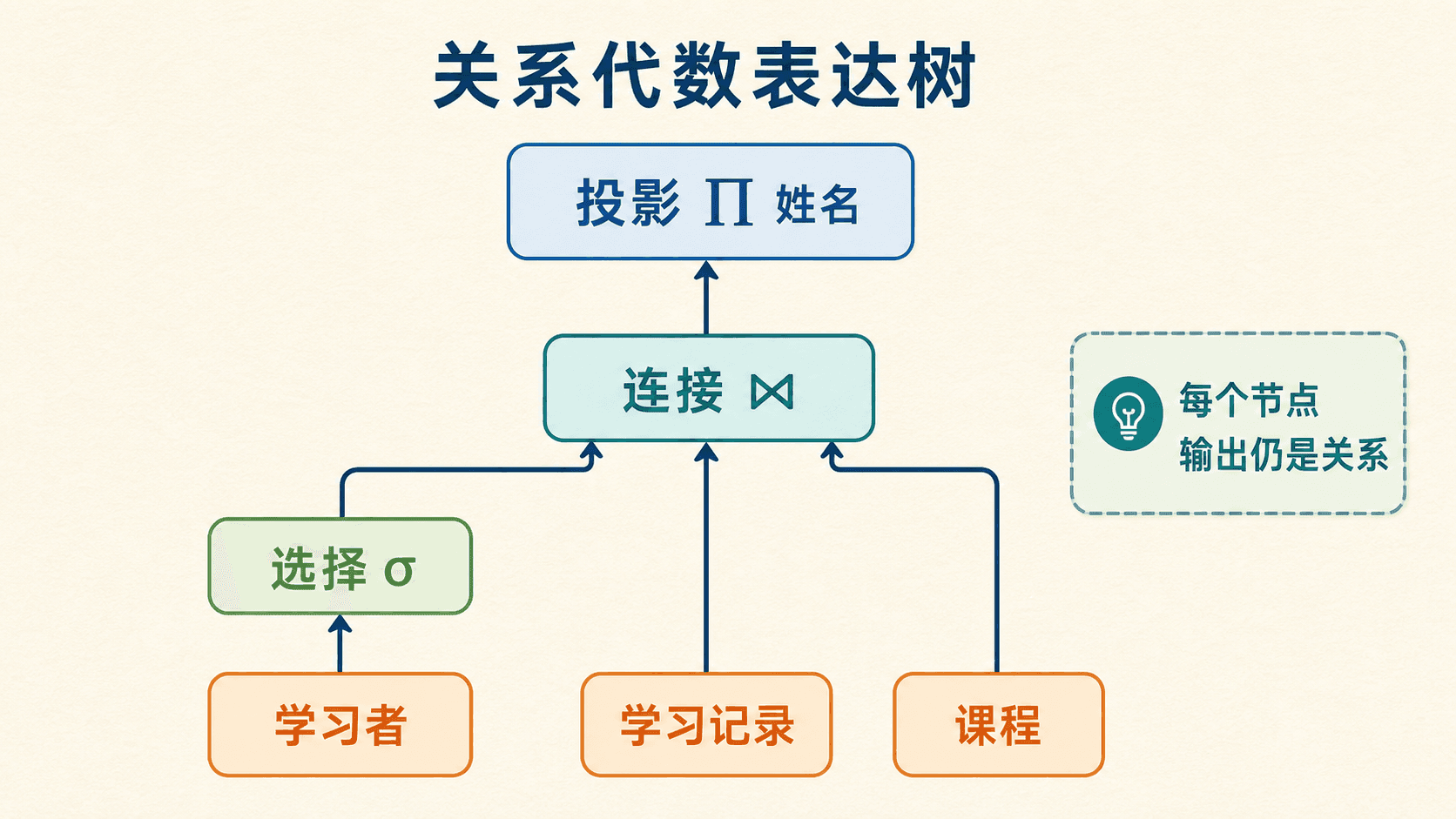
从叶子标注模式,向上计算每个节点的输出模式,是检查长表达式最稳妥的方法。
5
同一‘讲师’关系在表达式中出现两次,一次代表候选讲师,一次代表比较基准。为什么要使用重命名?
用等价规则改写而不改变答案
两个表达式在某一个示例实例上碰巧相同,还不能称为等价。等价要求它们在每一个满足模式与完整性约束的合法数据库实例上,都产生相同的元组集合;元组显示顺序不影响集合等价。在多重集语义下,等价还要求每个元组的出现次数相同。
从连接后选择到选择后连接
要找出数据方向学习者的学习记录,可以先连接再选择:
谓词“方向=数据方向”只引用“学习者”的属性,因此也可以先选择学习者,再连接:
两式在集合语义下等价。第二式通常产生更小的连接输入,但等价规则本身只说明结果相同,不保证在每一种存储、索引和数据分布下都更快。
常用规则与适用条件
合取选择可以拆成选择级联,选择次序可以交换:
连续投影中,只要外层属性集合包含关系正确,即 ,中间投影可省略:
theta 连接满足交换律;自然连接满足结合律。连接重排因此拥有多种候选树:
把投影推到连接两侧时,不能只保留最终输出列,还要保留连接谓词使用的属性。设最终需要 ,连接键分别在 与 中,则安全形式是:
并与交满足交换律和结合律,差不满足交换律;选择可以分配到并、交、差两侧;投影可以分配到模式相同的并两侧。这些规则的共同点是“条件不能省略”。每次变换前都要核对属性归属、模式相容性、空值行为与重复语义。
6
在集合语义下,哪些改写通常需要额外条件才能成立?
区分关系代数与声明式关系演算
关系代数与关系演算都属于简洁的形式查询语言,但它们站在不同的表达角度。关系代数提供一组预定义关系运算,通过函数组合描述逻辑求值路线;声明式关系演算用数学逻辑描述所需信息,不规定运算调用序列。
可以用同一个请求理解差别:“返回 2026 春完成数据方向课程的学习者姓名。”关系代数会显式组织这些动作:在课程上选择数据方向,在学习记录上选择学期与状态,按课程号连接,再按学员号连接学习者,最后投影姓名。声明式思路则把重点放在一个姓名应当满足的事实:存在相应的学习者、学习记录与课程,它们的标识能够对应,并且学期、状态、方向条件都成立。
元组关系演算和域关系演算都是声明式语言,它们用数学逻辑描述目标信息。这里把比较停在表达思想这一层,不单独摘用它们的变量语法、量词约束、安全表达式或互相转换规则;这些规则要放在各自完整的形式定义中才能准确使用。
“写出路线”不等于“锁死执行算法”
关系代数表达式规定的是逻辑运算,不是物理算法。表达式中的连接节点可以由嵌套循环、排序归并、散列等不同算法完成;选择可以用全表扫描,也可以借助索引。查询处理通常先把高级语言翻译成扩展关系代数的内部表示,再做等价变换,最后选择并执行物理计划。
这也解释了声明式语言为何实用:用户描述目标,系统把请求转换成可操作的内部表达式,再在等价空间中选择计算方法。关系代数处在声明式请求与物理执行之间,是一层便于推导、重排和估算的逻辑表示。
阅读查询时可以同时保留两种视角:用声明式语言确认“结果应满足什么条件”,再用关系代数检查“这些条件如何落到关系、属性和运算节点上”。
7
关于关系代数与声明式关系演算,哪项表述最稳妥?
从自然语言稳定构造关系代数表达式
面对长查询,最容易犯的错不是符号写错,而是属性归属、连接键或集合语义没有对齐。下面的方法把构造过程压缩成一条可以重复使用的检查链。
先写目标模式
先问“最终要哪几列”。如果目标是“学习者姓名和课程名”,最终投影就是 。先定结果模式能避免在中间步骤把注意力耗在无关属性上,也能提醒你最后是否需要消除重复。
再给每个条件找所属关系
把自然语言条件逐条贴到关系上:学习者等级属于“学习者”,课程方向属于“课程”,学期、状态与成绩属于“学习记录”。只引用一个输入的选择尽量靠近那个输入;跨关系比较则等待两侧进入同一连接节点。
标出连接图和连接键
“学习者”通过学员号连接“学习记录”,“学习记录”通过课程号连接“课程”。每加一条连接边,都检查两侧属性类型是否相容。不要把裸笛卡尔积误当成有意义的业务关联,也不要因自然连接写得短,就忽略新增同名属性可能改变条件。
最后决定嵌套、赋值与重命名
表达式短时直接嵌套;多个分支反复使用时用赋值;同一关系扮演两个角色时立即重命名。画树后从叶子向根写出每个节点的模式,任何谓词引用了当前模式不存在的属性,都说明运算位置错误或投影过早。
完整推导示例
目标是“找出 2026 春完成数据方向课程且成绩不低于 90 的学习者姓名”。先分别缩小两侧关系:
再按课程号连接,并保留后续仍需要的学员号:
最后按学员号连接学习者并投影姓名:
如果想写成一个嵌套表达式,只需把三个临时变量依次展开。两种写法表达能力相同;分步写法更适合检查,嵌套写法更紧凑。
交付前的五项自检
- 每个选择谓词引用的属性,是否存在于该节点的输入模式?
- 每个连接是否写明了真正的业务匹配条件?
- 并、交、差两侧是否具有相同元数和相容类型?
- 投影下推时是否保留了连接键与后续谓词属性?
- 当前推导采用集合还是多重集语义,重复元组是否会影响答案?
8
关系代数中,把同一关系用于自比较时,通常先用 ____ 运算给两次引用取不同名字。