高级 SQL:从应用访问到递归分析
基础查询解决的是“从哪些表取哪些行”。业务系统真正运行起来后,问题会继续向外延伸:应用怎样安全地传入参数,几步写操作怎样共同提交,数据库内部怎样复用业务规则,数据变化时怎样自动留下痕迹,层级关系怎样一直向下展开,报表又怎样同时计算明细、小计、排名和移动平均。
这一页用同一个“星河零售”场景贯穿这些问题。示例 SQL 采用 PostgreSQL 语法,表名与字段名保持一致;JDBC 示例只依赖标准 java.sql 接口。即使你使用的是其他数据库,连接、参数绑定、触发时机、递归不动点和窗口帧这些核心概念也不会改变,需要调整的主要是例程与触发器的声明语法。
高级 SQL 不是把所有逻辑都塞进数据库。更实用的判断是:集合计算尽量交给 SQL,必须贴近数据一致性的规则放进事务或数据库约束,界面交互、外部调用和长耗时流程留在应用层。
建立贯穿全文的业务模型
星河零售有多家门店。顾客下单后,系统写入订单与明细、扣减门店库存,并把每天的销售额汇总给运营人员。门店又按“总部—区域—城市—门店”组成层级。后面每一种高级 SQL 能力,都在解决这条链路中的一个具体问题。
下面是一组最小表结构。你可以在一个空的 PostgreSQL 数据库中执行它,随后运行各小节的查询。
sql
CREATE TABLE store (
store_id bigint PRIMARY KEY,
store_name text NOT NULL,
parent_id bigint REFERENCES store(store_id),
store_type text NOT NULL
CHECK (store_type IN ('总部', '区域', '城市', '门店'))
);
CREATE TABLE customer (
customer_id bigint PRIMARY KEY,
customer_name text NOT NULL,
member_level text NOT NULL DEFAULT '普通'
);
CREATE TABLE product (
product_id bigint PRIMARY KEY,
product_name text NOT NULL,
category text NOT NULL,
unit_price numeric(12, 2) NOT NULL CHECK (unit_price >= 0)
);
CREATE TABLE inventory (
store_id bigint REFERENCES store(store_id),
product_id bigint REFERENCES product(product_id),
quantity integer NOT NULL CHECK (quantity >= 0),
reorder_level integer NOT NULL DEFAULT 10 CHECK (reorder_level >= 0),
PRIMARY KEY (store_id, product_id)
);
CREATE TABLE sales_order (
order_id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
store_id bigint NOT NULL REFERENCES store(store_id),
customer_id bigint NOT NULL REFERENCES customer(customer_id),
status text NOT NULL DEFAULT '待支付',
ordered_at timestamptz NOT NULL DEFAULT current_timestamp,
total_amount numeric(14, 2) NOT NULL DEFAULT 0
);
CREATE TABLE order_item (
order_id bigint REFERENCES sales_order(order_id) ON DELETE CASCADE,
product_id bigint REFERENCES product(product_id),
quantity integer NOT NULL CHECK (quantity > 0),
unit_price numeric(12, 2) NOT NULL CHECK (unit_price >= 0),
PRIMARY KEY (order_id, product_id)
);
CREATE TABLE inventory_audit (
audit_id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
store_id bigint NOT NULL,
product_id bigint NOT NULL,
old_quantity integer NOT NULL,
new_quantity integer NOT NULL,
changed_at timestamptz NOT NULL DEFAULT current_timestamp,
changed_by text NOT NULL DEFAULT current_user
);
CREATE TABLE restock_task (
store_id bigint NOT NULL,
product_id bigint NOT NULL,
requested_qty integer NOT NULL CHECK (requested_qty > 0),
task_status text NOT NULL DEFAULT '待处理',
created_at timestamptz NOT NULL DEFAULT current_timestamp
);
CREATE TABLE daily_sales (
sale_date date NOT NULL,
store_id bigint NOT NULL REFERENCES store(store_id),
category text NOT NULL,
amount numeric(14, 2) NOT NULL,
PRIMARY KEY (sale_date, store_id, category)
);这个模型刻意保留了三类边界。CHECK、主键和外键表达始终成立的静态规则;订单、明细与库存要靠事务组成一次完整动作;审计、层级展开和经营分析则分别交给触发器、递归查询与窗口聚合。
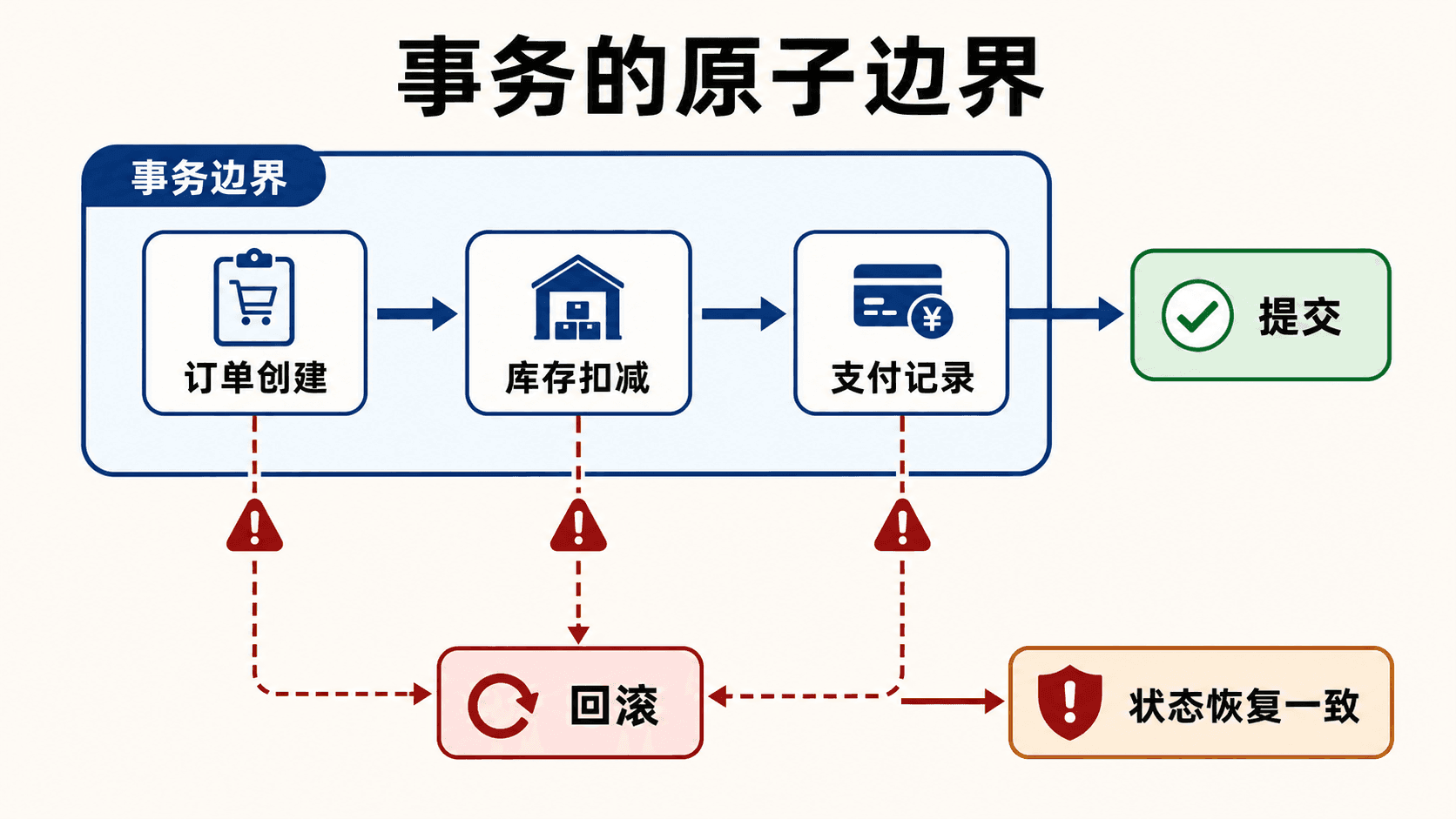
订单创建、库存扣减和支付记录要么一起提交,要么在失败时一起回滚。
1
一次下单需要写订单、写明细并扣减库存。哪种设计最能保证不会只完成其中一部分?
从宿主语言安全访问 SQL
应用程序通常处理按钮、网络请求、文件和对象,SQL 则一次处理一组行。两者之间存在一个结构差异:查询返回的是关系,Java 或 C 一次操作的往往是一个变量或一个对象。数据库访问接口负责跨过这道边界,把连接、SQL、参数、结果集和事务暴露成宿主语言可以管理的对象。
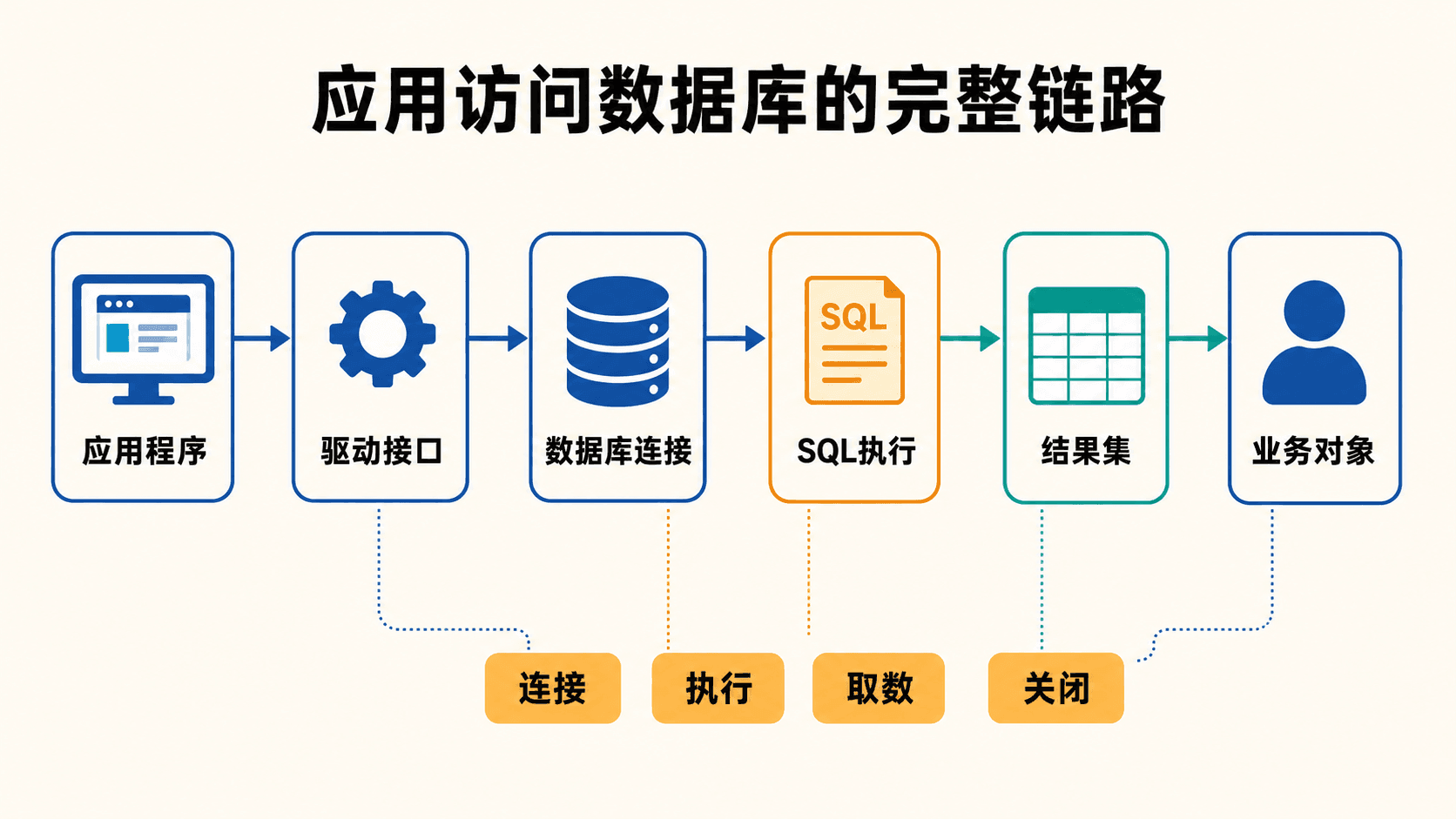
数据库接口把“连接、执行、逐行取数、关闭资源”组织成稳定的调用链。
动态 SQL、JDBC 与 ODBC
动态 SQL 在运行时构造并提交语句。JDBC 为 Java 定义统一接口,驱动把统一调用翻译成某个数据库能理解的协议;ODBC 则通过驱动管理器和数据库驱动,为 C、C++、统计工具或其他程序提供相似的通用入口。二者的对象名称不同,生命周期却很接近:
- 建立到指定数据库的连接。
- 创建语句或预编译语句对象。
- 绑定参数并执行查询或更新。
- 从结果集中逐行读取列值。
- 提交或回滚事务。
- 关闭结果集、语句与连接。
JDBC 连接 URL 选择主机、端口、数据库与驱动协议。账号和密码不应写死在源码里,通常由密钥管理服务或运行环境注入。下面的方法查询某门店指定日期之后的订单,并用 try-with-resources 保证异常路径也能释放连接、语句和结果集。
java
import java.math.BigDecimal;
import java.sql.*;
import java.time.LocalDate;
public final class OrderReader {
private final String url;
private final String user;
private final String password;
public OrderReader(String url, String user, String password) {
this.url = url;
this.user = user;
executeQuery() 用于会返回结果集的查询,executeUpdate() 用于 INSERT、UPDATE、DELETE 等操作,并返回受影响的行数。ResultSet.next() 既移动游标,也告诉我们是否还有下一行。列可以按名称读取,也可以按从 1 开始的位置读取;业务代码更适合使用列名,因为查询增加一列时不容易读错位置。
ODBC 的环境句柄、连接句柄和语句句柄,对应 JDBC 的驱动环境、Connection 和 Statement。SQLBindCol 把结果列绑定到 C 变量,SQLFetch 每次取一行。可变长列还要同时提供缓冲区长度和实际长度位置;实际长度为负通常表示 NULL。ODBC 也能预编译带占位符的语句、查询表与列的目录信息。连接默认常见行为是单句自动提交,关闭自动提交后要用提交或回滚函数结束事务。工程上要检查每一次调用的返回码,而不是只在最后判断成功或失败。
Python DB-API 也沿用同一模型:连接创建游标,execute() 接收 SQL 与独立参数序列,游标可以逐行迭代。占位符样式由驱动决定,不能想当然地把 JDBC 的 ? 原样搬过去。下面使用 PostgreSQL 驱动的 %s 占位符;这里的 %s 不是 Python 字符串格式化,参数仍由驱动绑定。
python
import psycopg
def load_orders(dsn: str, store_id: int):
with psycopg.connect(dsn) as connection:
with connection.cursor() as cursor:
cursor.execute(
"""
SELECT order_id, ordered_at, total_amount
FROM sales_order
WHERE store_id = %s
ORDER BY ordered_at, order_id
""",
(store_id,),
)
return list(cursor)连接上下文正常退出时提交事务,异常退出时回滚;游标上下文负责关闭资源。不同驱动在连接参数、自动提交和占位符上会有小差别,迁移时要核对驱动约定,但不要退回字符串拼接。
预编译与参数绑定
预编译语句先固定 SQL 的结构,再把外部输入作为有类型的值绑定到占位符。数据库可能在准备阶段或首次执行时编译执行计划,驱动实现存在差异;无论计划是否复用,结构和值分离始终是防注入的关键。
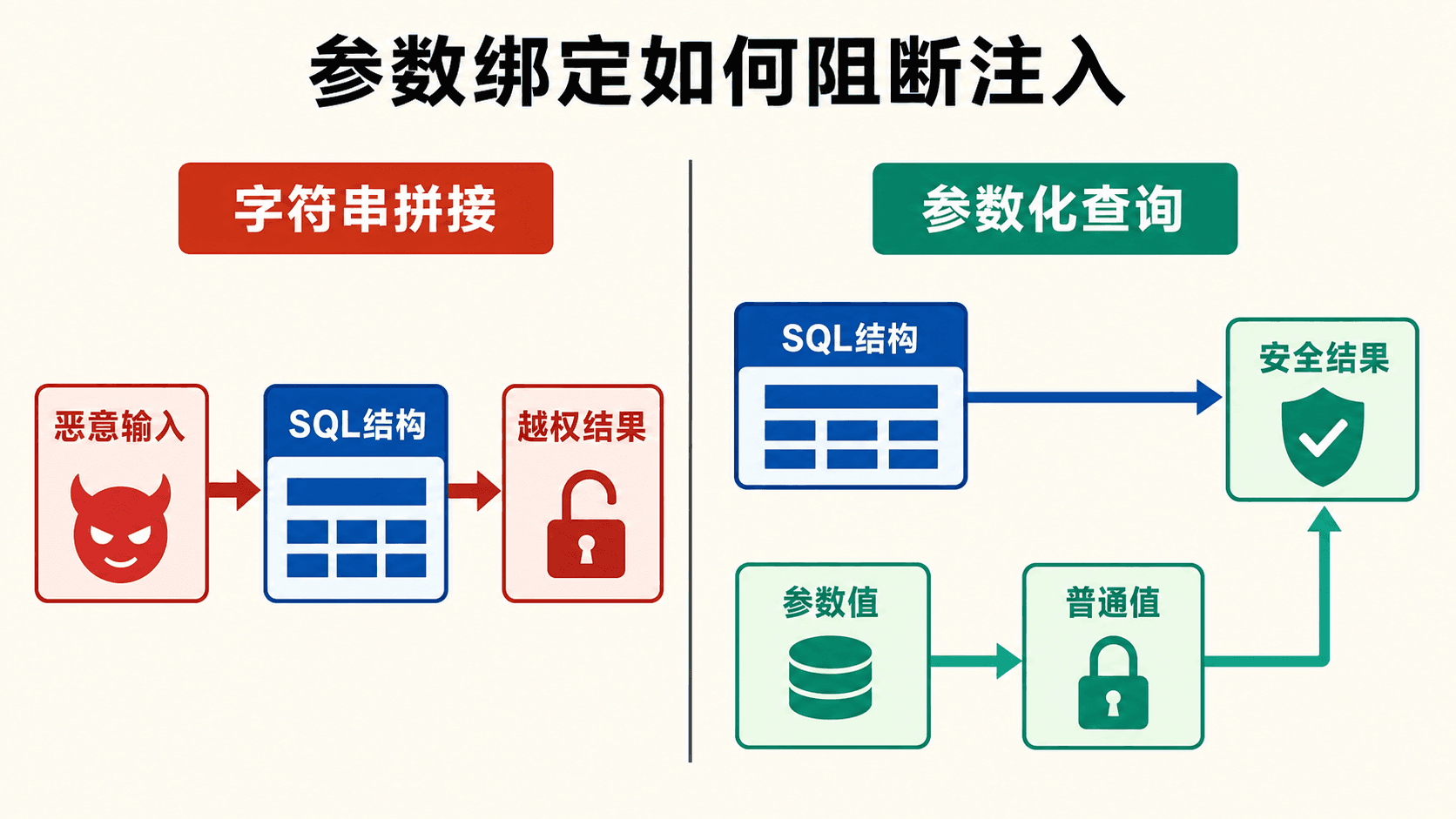
参数值只能填入预留位置,不能逃出引号去改写谓词或追加语句。
java
String unsafe =
"SELECT customer_id FROM customer WHERE customer_name = '" + input + "'";
String safe =
"SELECT customer_id FROM customer WHERE customer_name = ?";
try (PreparedStatement statement = connection.prepareStatement(safe)) {
statement.setString(1, input);
try (ResultSet result = statement.executeQuery()) {
// input 始终按一个字符串值参与比较
}
}如果 input 是 某人' OR '1'='1,字符串拼接会改变 WHERE 的语法树,条件可能对所有行成立。参数绑定把整段输入当成一个姓名值,里面的引号、空格和关键字都不会成为 SQL 结构。手工替换单引号不等于安全参数化:它容易漏掉字符编码、驱动模式、数字参数或多语句执行等边角情况。
事务边界与异常路径
JDBC 默认常见行为是每条语句自动提交。这适合互不相关的单句操作,不适合“写订单—写明细—扣库存”这种组合。关闭自动提交后,成功路径显式 commit(),失败路径显式 rollback();连接关闭前还应恢复或丢弃,不要把一个未完成事务交还连接池。
java
connection.setAutoCommit(false);
try {
insertOrder(connection, order);
insertItems(connection, order.items());
int changed = decreaseInventory(connection, order.items());
if (changed != order.items().size()) {
throw new SQLException("部分商品库存不足");
}
connection.commit();
} catch
事务保证原子性,但不能自动解决并发超卖。扣库存应在一条带条件的语句中完成,例如 UPDATE inventory SET quantity = quantity - ? WHERE ... AND quantity >= ?,再检查受影响行数;这样检查与扣减不会分成两个可被并发插入的步骤。
可调用语句、元数据与大对象
CallableStatement 用于调用存储函数或过程。输入参数照常绑定,返回值与 OUT 参数要先注册类型再读取。结果结构未知时,ResultSetMetaData 能读取列数、列名和类型;DatabaseMetaData 能查询表、列、主外键以及数据库能力,数据库浏览器和通用导出工具正是靠这些信息工作。
对于 BLOB/CLOB,不必把整个对象一次装进内存。驱动可以返回定位器并以流读取,也可以把输入流绑定到预编译语句。这里依然要把流、语句与连接一起纳入资源关闭策略。
JDBC 还支持可更新结果集与 RowSet。前者允许对满足条件的简单查询结果逐行修改,并把变化写回基础表;后者可以缓存一批结果,在组件之间传递、前后移动甚至离线修改。它们方便,但更新映射和并发语义受驱动限制。业务写入通常仍适合显式 UPDATE ... WHERE ...,因为受影响条件、权限与行数都更容易审查。
嵌入式 SQL 与嵌入式数据库不是一回事
嵌入式 SQL 把 EXEC SQL 标记的语句写进 C 等宿主语言,预处理器在正式编译前把它转换成数据库调用。宿主变量通常以冒号标记,查询多行结果时要声明、打开、抓取并关闭游标。它的优势是部分语法和类型问题能更早暴露,代价是多一道预处理、调试要面对生成代码,而且可移植性受具体实现影响。
嵌入式数据库则表示数据库引擎随应用进程一起运行,通常不需要独立服务器。它和嵌入式 SQL 分别回答“数据库运行在哪里”与“SQL 怎样写进宿主代码”,不要混为一谈。
2
下面哪些做法能直接降低应用访问数据库时的注入或资源泄漏风险?
把可复用逻辑写成函数与过程
函数和过程都把一段逻辑注册在数据库中,但调用语义不同。函数通常参与表达式并返回一个值或一张表;过程更适合执行一连串动作,通过 IN、OUT 或 INOUT 参数交流结果。表函数可以理解成带参数的视图:调用者传入筛选条件,函数返回可继续连接、过滤和聚合的关系。
一些数据库允许例程重载:同名过程可以按参数个数区分,同名函数还可以按参数类型区分。重载能让调用形式统一,也可能让隐式类型转换造成歧义;公共接口更适合使用稳定、容易辨认的参数类型。
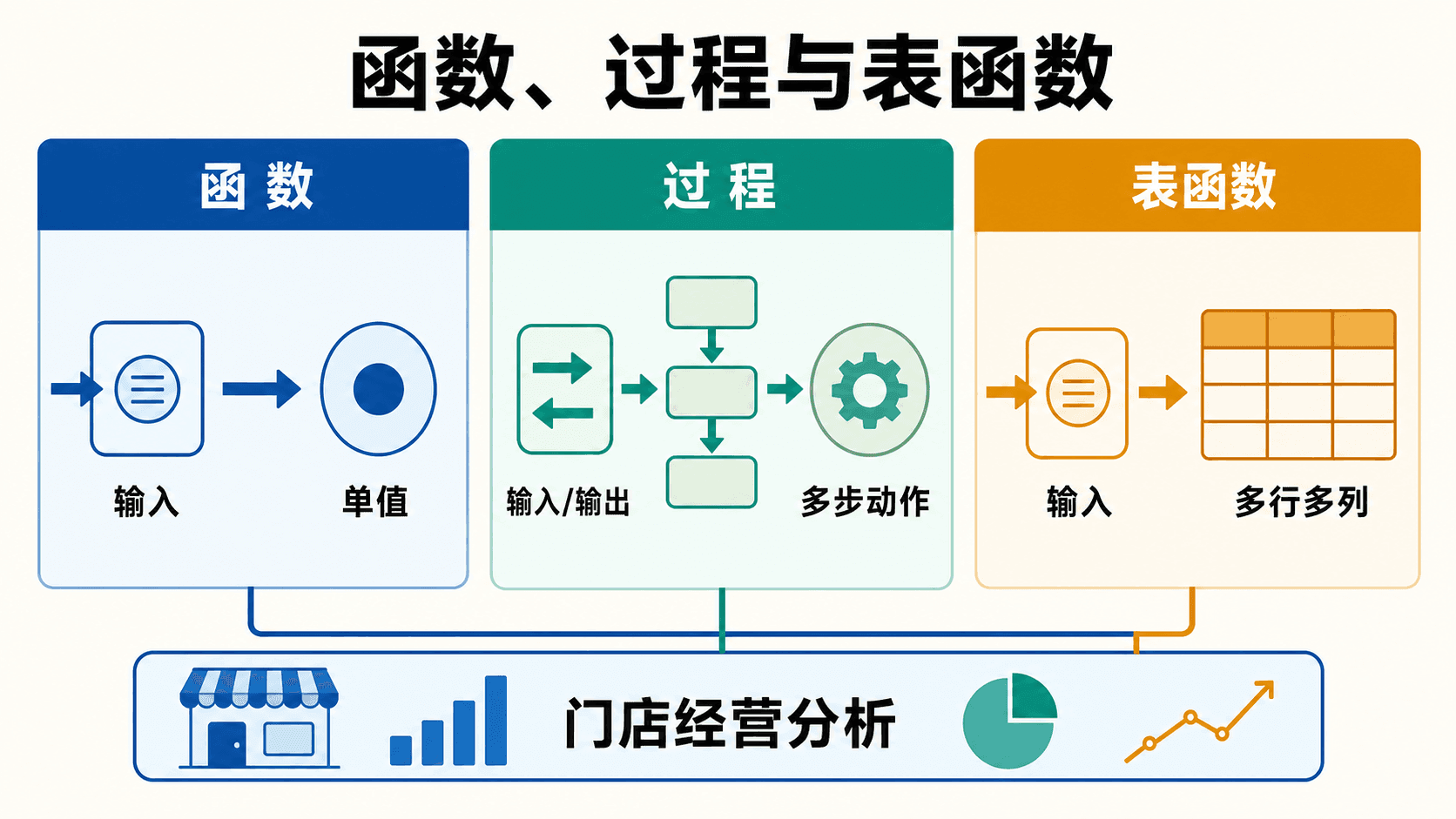
选择例程之前,先看调用方需要一个值、一组行,还是一次有副作用的流程。
标量函数与表函数
门店区间销售额是稳定的集合计算,适合写成 SQL 函数。参数名加前缀,避免与列名混淆。
sql
CREATE OR REPLACE FUNCTION store_revenue(
p_store_id bigint,
p_from date,
p_to date
)
RETURNS numeric(14, 2)
LANGUAGE sql
STABLE
AS $$
SELECT COALESCE(SUM(ds.amount), 0)::numeric(14, 2)
如果函数被放在大表每一行的谓词中,它可能执行很多次。能改写成一次连接或一次分组时,集合式 SQL 往往更快,也更容易被优化器重排。函数的价值是明确边界和复用,不是把普通查询包一层名字。
表函数返回多行多列。下面的函数把某门店低于补货线的商品作为一张表返回,调用者还能继续加 WHERE 和 ORDER BY。
sql
CREATE OR REPLACE FUNCTION low_stock_products(p_store_id bigint)
RETURNS TABLE (
product_id bigint,
product_name text,
quantity integer,
shortage integer
)
LANGUAGE sql
STABLE
AS $$
SELECT p.product_id,
p.product_name,
i.quantity,
声明、控制流与异常
过程化 SQL 的标准化部分常称为持久存储模块,它提供局部变量、赋值、BEGIN ... END 复合语句、IF/CASE 条件,以及 LOOP、WHILE、FOR 等循环。数据库产品的实现语法差异较大,下面使用 PL/pgSQL。过程按门店扫描低库存商品,并把尚未存在的补货任务写入队列表。
sql
CREATE OR REPLACE PROCEDURE create_restock_tasks(p_store_id bigint)
LANGUAGE plpgsql
AS $$
DECLARE
item record;
v_created integer := 0;
BEGIN
FOR item IN
SELECT product_id,
reorder_level - quantity + 10 AS requested_qty
FROM inventory
WHERE store_id = p_store_id
AND
FOR item IN SELECT ... 逐行把查询结果放进记录变量。EXIT 可以提前离开循环,CONTINUE 可以跳过当前迭代。异常处理器要解决一个明确问题:转换错误、补充上下文、清理临时状态,或把错误继续抛给调用方。吞掉异常并假装成功,会让应用无法判断事务是否完成。
标准概念里,原子复合语句要求内部动作作为一个事务单元执行。具体产品对“函数/过程内部能否提交”的规则不同。最稳妥的边界仍由调用链统一决定:如果下单过程只是更大事务的一部分,就不要在例程深处擅自提交。
外部语言例程的取舍
某些系统允许数据库调用 Java、C、Python 等外部例程。这能处理 SQL 不擅长的算法或自定义数据类型,但也引入运行时、权限与故障隔离问题。原生代码若与数据库进程共享地址空间,错误可能破坏数据库内部状态;放到独立进程更安全,却增加进程通信开销;受控运行时可以用沙箱限制文件、网络和内存访问,是两者之间的折中。
外部例程必须明确处理 NULL、返回状态和异常,还要遵守最小权限。若一个逻辑能用普通集合 SQL 清楚表达,通常没有必要为它引入新的语言运行时。
3
需要接收门店编号,并返回该门店所有低库存商品,且调用方还要继续筛选和排序。最合适的数据库例程是什么?
用触发器响应数据变化
触发器把“发生什么事件”“在什么时机检查”“对哪些行执行”“满足什么条件”“执行什么动作”注册进数据库。事件通常是 INSERT、UPDATE 或 DELETE,动作与原语句位于同一事务中:触发器报错,触发它的语句也会失败。
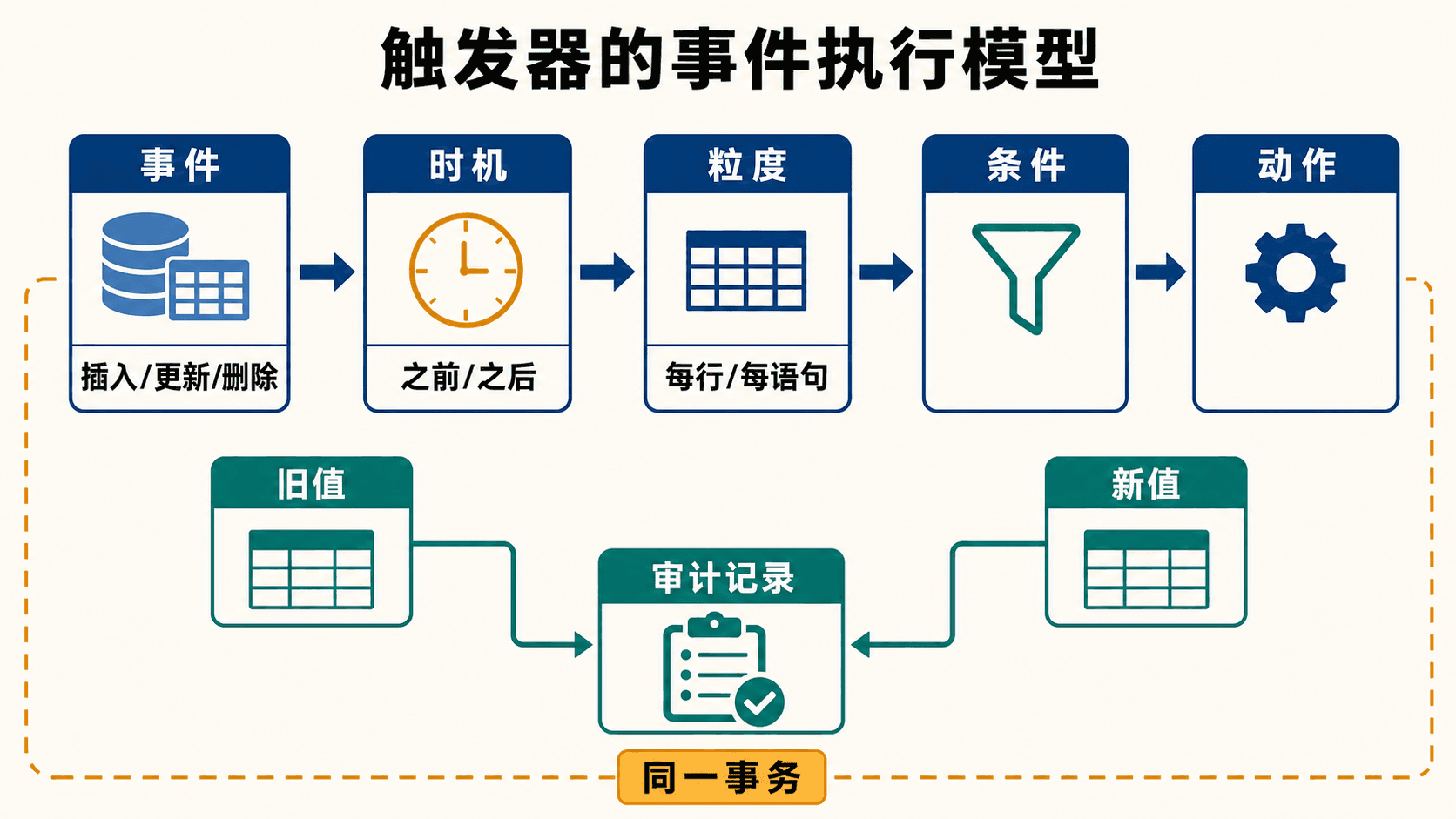
旧值和新值让触发器判断字段是否真的变化,并把变化写入审计表。
时机、粒度与新旧值
BEFORE 触发器在写入前运行,适合校验或规范化新值;AFTER 触发器在写入成功后运行,适合依赖最终行值的审计和派生动作;部分系统还支持 INSTEAD OF,常用于把对视图的修改改写成基础表操作。
行级触发器对受影响的每一行执行一次,能访问 OLD 与 NEW。插入只有 NEW,删除只有 OLD,更新两者都有。语句级触发器对整条 SQL 只执行一次,更适合批量汇总;支持过渡表的系统还能一次看到本语句产生的全部旧行或新行。
下面的 PostgreSQL 触发器只在库存数量实际变化时写审计日志。IS DISTINCT FROM 对 NULL 也有明确语义,比 <> 更适合比较可能为空的列。
sql
CREATE OR REPLACE FUNCTION audit_inventory_change()
RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
IF OLD.quantity IS DISTINCT FROM NEW.quantity THEN
INSERT INTO inventory_audit(
store_id, product_id, old_quantity, new_quantity
)
VALUES (
NEW.store_id, NEW.product_id, OLD.quantity
触发事件限定为 UPDATE OF quantity,可以避免其他列更新时进入函数。函数内部再次比较新旧值,是因为“列出现在 SET 中”不一定表示值真的变化。
语句级触发器与过渡表
批量调价可能一次更新几万行。若目标是生成一条批次记录,行级触发器会制造几万次函数调用;语句级触发器更合适。下面的例子把本条语句变更的行作为 new_rows 过渡表交给函数,然后一次插入所有需要补货的任务。
sql
CREATE OR REPLACE FUNCTION enqueue_restock_from_batch()
RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
INSERT INTO restock_task(store_id, product_id, requested_qty)
SELECT n.store_id,
n.product_id,
n.reorder_level - n.quantity + 10
FROM new_rows AS n
WHERE n.quantity <=
不同产品对过渡表、WHEN、回滚和触发器主体的写法差异明显。迁移触发器时不能只改关键字,还要核对它到底按行还是按语句执行、能否访问修改表、多个触发器的顺序是否确定。
触发器做不到什么
触发器适合短小、确定、必须随数据变更一起成功的动作。它通常不能可靠地完成数据库之外的现实操作,例如直接向供应商下单或发送不可撤回的消息。事务后来可能回滚,但外部邮件无法“回滚”。更安全的办法是触发器或业务事务只写一条待处理任务,再由独立工作进程发送,并用唯一键保证重试不会重复执行。
触发器还有四类常见风险:
- 隐蔽副作用:应用只写了一张表,触发器却修改多张表,排查路径变长。
- 级联与递归:一个触发器的动作触发另一个,甚至重新触发自己,形成长链或死循环。
- 批量放大:行级触发器在大批量更新中执行成千上万次。
- 回放误触发:导入备份或复制日志时,已经发生过的副作用又执行一遍。
能用外键级联、CHECK、生成列、物化视图自动维护或显式存储过程解决的规则,优先使用这些更可见的机制。触发器留下来的部分,要写进数据字典和测试用例,并监控执行耗时与失败次数。
4
AFTER 行级触发器每次只执行一遍,所以批量更新十万行时不会产生明显额外开销。
用递归查询展开层级与传递闭包
层级查询的难点不在于连接两张表,而在于不知道要连接多少次。总部下面可能只有两层,也可能有很多层;配送路线里还可能出现环。递归查询用一个非递归的锚点建立初始集合,再让递归项基于当前结果扩展一层,直到某一轮没有新行,这个稳定结果就是不动点。
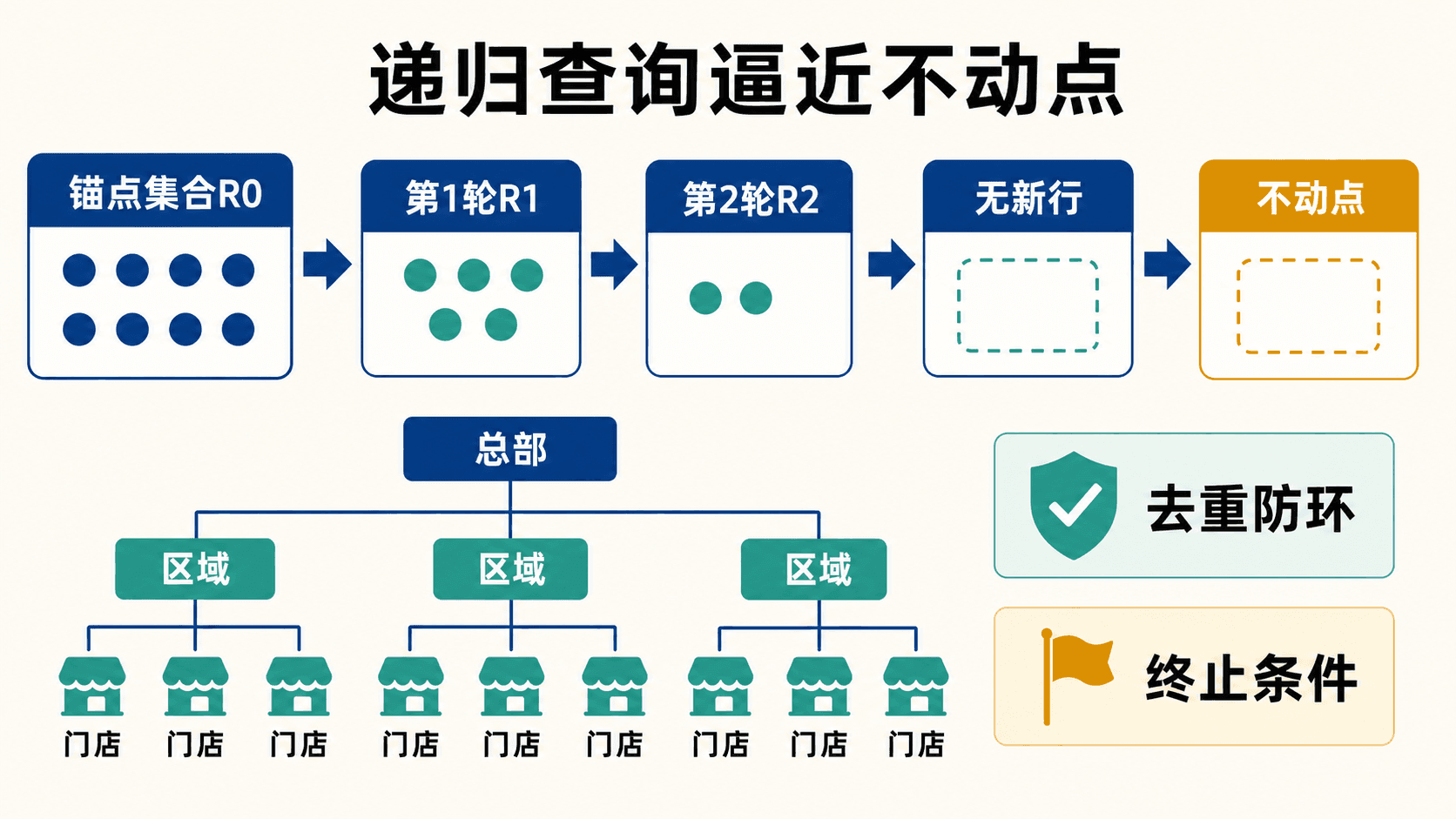
每一轮只扩展上一轮可达的节点;没有新节点时查询终止。
层级树与路径
store.parent_id 指向直接上级。下面的查询从总部 1 出发,返回所有下级、深度和完整路径。路径数组既用于展示,也用于拒绝再次访问已经出现的节点。
sql
WITH RECURSIVE store_tree AS (
-- 锚点:选定根节点
SELECT s.store_id,
s.store_name,
s.parent_id,
0 AS depth,
ARRAY[s.store_id] AS path
FROM store AS s
WHERE s.store_id = 1
UNION ALL
-- 递归项:把当前节点与其直接子节点连接
SELECT
锚点只执行一次;递归项反复读取上一轮产生的工作集合。外层 SELECT 不参与递归,只负责呈现最终结果。把根节点限制写进锚点,通常比先计算整张组织图再在外层筛选更省工作。
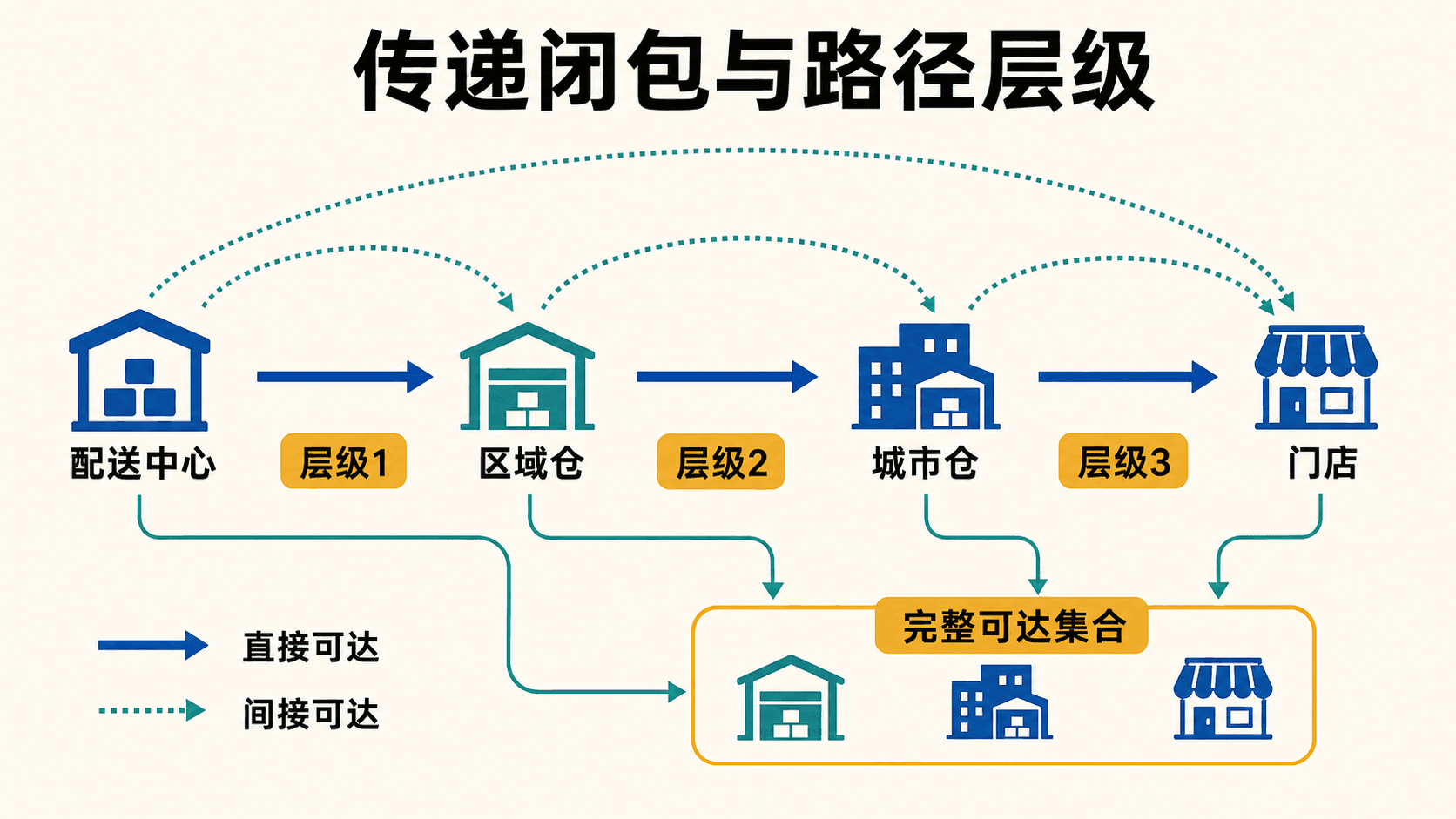
传递闭包保存任意两点之间“经过一条或多条边可达”的全部关系。
传递闭包
如果要反复回答“任意配送节点能到哪些节点”,可以计算全部起点的传递闭包。delivery_route(from_store_id, to_store_id) 保存直接路线,下面先建表再展开所有可达节点对:
sql
CREATE TABLE delivery_route (
from_store_id bigint REFERENCES store(store_id),
to_store_id bigint REFERENCES store(store_id),
PRIMARY KEY (from_store_id, to_store_id),
CHECK (from_store_id <> to_store_id)
);
WITH RECURSIVE reachable(from_id, to_id) AS (
SELECT from_store_id, to_store_id
FROM delivery_route
UNION
SELECT r.from_id, d.to_store_id
这里使用 UNION,不是 UNION ALL。UNION 在每轮排除已经出现的 (from_id, to_id),即使路线图有环,有限节点对最终也会耗尽并停止。传递闭包不保留具体路径和深度;如果把 depth 加进结果,同一节点对在不同深度会被视为不同行,单靠 UNION 就不能防止环无限产生,必须增加路径检测或最大深度条件。
终止、去重与单调性
一个可靠的递归查询要回答三个问题:
- 锚点是否足够窄,能定义正确起点?
- 每轮是否朝目标扩展,并且能识别已经访问的状态?
- 数据异常形成环时,靠
UNION、路径数组还是最大深度终止?
递归项通常要求单调:已有结果增加后,下一轮不能反过来撤销先前结果。因此,递归项里不能随意对递归关系做聚合、在 NOT EXISTS 中否定它,或把它放在集合差右侧。这些操作会让“不断加入新行直到稳定”的含义变得不确定。聚合和最终筛选通常放在递归完成后的外层查询。
5
递归结果中同时保存节点、深度和完整路径,而且原始数据可能有环。哪种终止策略最可靠?
用高级聚合完成经营分析
普通 GROUP BY 把每行分进一个组。经营报表还需要三个方向的能力:同一批明细同时生成不同粒度的小计;在组内排序并保留每一行;让一个聚合窗口随着当前行移动。ROLLUP、CUBE、GROUPING SETS 和窗口函数分别解决这些问题。
多粒度汇总
ROLLUP(a, b, c) 生成按前缀逐级收起的分组:(a,b,c)、(a,b)、(a)、()。它适合有明确层次的报表,例如“门店—品类—日期”的明细、门店品类小计、门店小计与总计。
sql
SELECT store_id,
category,
sale_date,
SUM(amount) AS revenue
FROM daily_sales
GROUP BY ROLLUP (store_id, category, sale_date)
ORDER BY store_id NULLS LAST,
category NULLS LAST,
sale_date NULLS LAST;CUBE(a, b, c) 生成三个维度的所有子集,一共最多 种分组。它适合用户会从任何维度切片的分析,但维度一多,分组数呈指数增长,输出与计算量都会迅速变大。
GROUPING SETS 只计算明确列出的组合。若运营只关心“门店×品类”“日期×品类”和全局总计,不必生成完整立方体。
sql
SELECT store_id,
category,
sale_date,
SUM(amount) AS revenue
FROM daily_sales
GROUP BY GROUPING SETS (
(store_id, category),
(sale_date, category),
()
);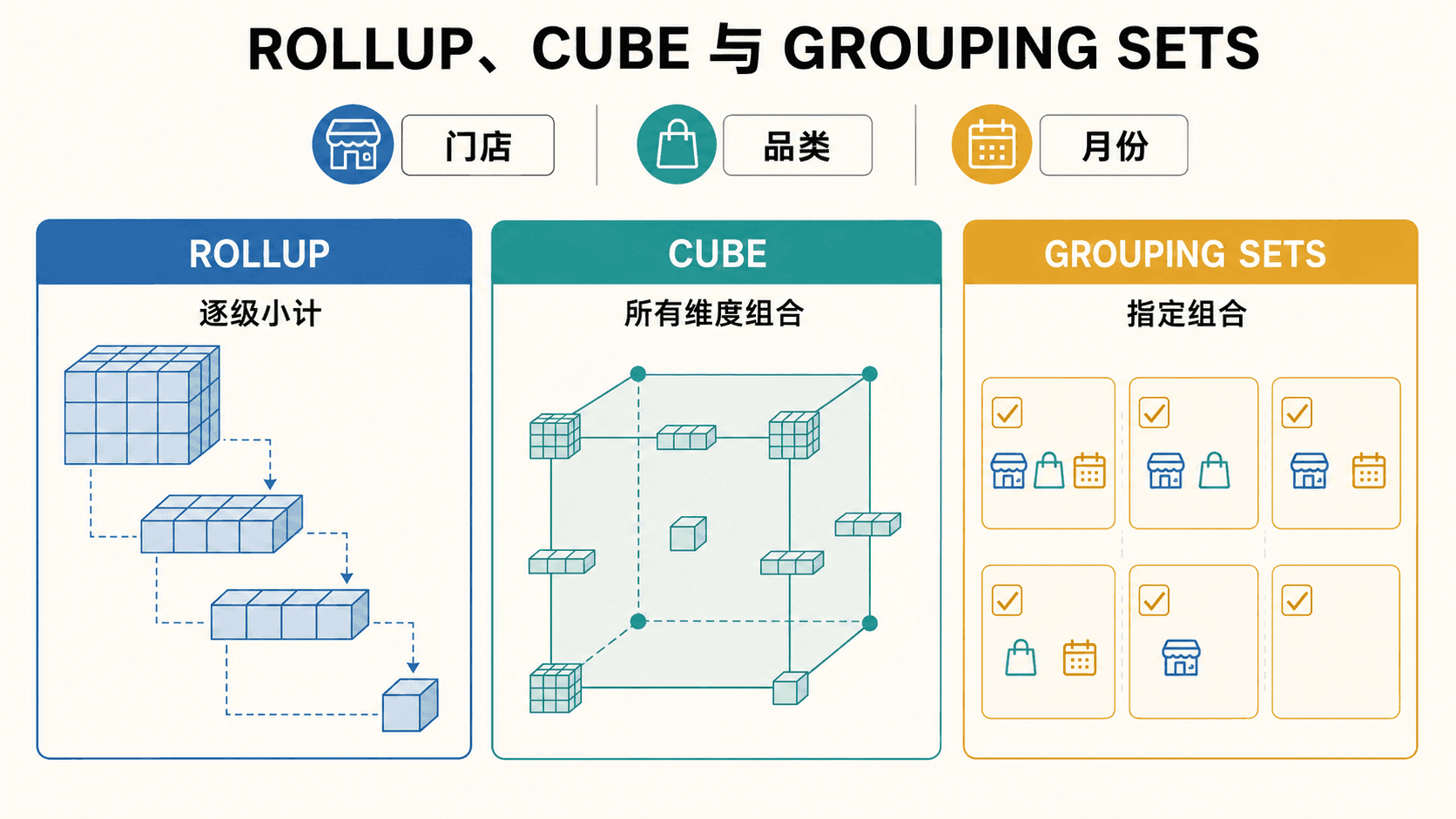
ROLLUP 沿层次逐级小计,CUBE 枚举全部组合,GROUPING SETS 只取指定组合。
汇总行用 NULL 填充没有参与该层分组的列,但业务原始数据也可能真的包含 NULL。GROUPING(column) 在该列由汇总层产生空值时返回 1,在它是普通分组列时返回 0,因此比 COALESCE 更准确。
sql
SELECT CASE WHEN GROUPING(store_id) = 1
THEN '全部门店' ELSE store_id::text END AS store_scope,
CASE WHEN GROUPING(category) = 1
THEN '全部品类' ELSE category END AS category_scope,
SUM(amount) AS revenue
FROM daily_sales
GROUP BY ROLLUP (store_id, category);交叉表与条件聚合
交叉表把某列的值变成输出列,例如把品类“食品、日用品、服饰”转成三列。部分数据库提供 PIVOT,PostgreSQL 常用带 FILTER 的条件聚合获得同样结果:
sql
SELECT store_id,
SUM(amount) FILTER (WHERE category = '食品') AS food_revenue,
SUM(amount) FILTER (WHERE category = '日用品') AS daily_revenue,
SUM(amount) FILTER (WHERE category = '服饰') AS clothing_revenue
FROM daily_sales
GROUP BY store_id
ORDER BY store_id;交叉表的列集合通常要提前确定。若品类随数据动态增长,应由报表层生成列,或者先返回“门店、品类、金额”长表,避免每增加品类就修改 SQL 接口。
排名与并列
窗口函数在保留每一行的同时,读取它所在分区中的其他行。RANK() 让并列值获得相同名次并留下空档;DENSE_RANK() 不留空档;ROW_NUMBER() 无论是否同分都给唯一序号。若排序键相同而没有额外稳定键,ROW_NUMBER() 在同分行之间的顺序不确定。
sql
WITH store_month AS (
SELECT store_id,
date_trunc('month', sale_date)::date AS month_start,
SUM(amount) AS revenue
FROM daily_sales
GROUP BY store_id, date_trunc('month', sale_date)::date
), ranked AS (
SELECT store_id,
month_start,
revenue,
RANK() OVER (
PARTITION BY month_start
ORDER BY
这个 Top-3 会保留第三名并列,因此某个月可能返回四家或更多门店。若业务必须“恰好三行”,使用 ROW_NUMBER() 并补充稳定排序键,但要明确这意味着主动打破并列。PERCENT_RANK() 给出相对名次,CUME_DIST() 给出累计分布比例,NTILE(4) 可以把有序行大致均分成四组。
分区、排序与窗口帧
窗口定义有三层:PARTITION BY 把行分成互不跨越的分区,ORDER BY 确定分区内顺序,帧子句再从当前行附近选出真正参与计算的行。没有帧子句时,默认帧会受数据库和排序类型影响,生产查询最好把意图写明。
sql
SELECT sale_date,
store_id,
category,
amount,
AVG(amount) OVER (
PARTITION BY store_id, category
ORDER BY sale_date
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS moving_avg_3_rows,
SUM(amount) OVER (
PARTITION BY store_id, category
ORDER BY sale_date
ROWS BETWEEN UNBOUNDED PRECEDING
前三天数据不足时,帧只包含实际存在的行,不会自动补零。ROWS 按物理行数取帧;如果同一天可能有多行,同一天的先后顺序还应增加唯一排序键。RANGE 按排序值的范围取帧,更适合“当前日期往前 6 天”的日历语义:
sql
SELECT sale_date,
store_id,
SUM(amount) AS day_revenue,
AVG(SUM(amount)) OVER (
PARTITION BY store_id
ORDER BY sale_date
RANGE BETWEEN INTERVAL '6 days' PRECEDING AND CURRENT ROW
) AS moving_avg_7_days
FROM daily_sales
GROUP BY sale_date, store_id
ORDER BY store_id, sale_date;这里先按日聚合,再对每日结果做窗口计算。SQL 的逻辑顺序是先形成 GROUP BY 结果,再在这些结果行上计算窗口函数。某天完全没有行时,RANGE 也不会凭空补出日期;若报表要求连续日历,应先用日期序列左连接补齐缺失日。
6
运营报表只需要门店×品类、日期×品类和全局总计,并要求三日移动平均。下面哪些选择正确?
把能力放回正确的工程边界
高级 SQL 最容易犯的错误,是因为某项能力“能做”,就默认它“应该做”。把需求放回执行边界,选择会清楚很多:
上线前再做四项检查:所有外部输入是否参数化;事务的失败路径是否真的回滚;触发器是否会在批量更新、复制或重试时重复执行;递归与窗口查询是否有确定的终止、排序和帧。做到这些,高级 SQL 才会从“语法很多”变成一组边界明确、可以组合的工程工具。
7
为了让业务规则集中管理,发送邮件、调用支付接口和长耗时网络请求都应该直接放进数据库触发器。