SQL:把业务问题写成可执行的数据操作
SQL 的特别之处在于,我们通常只描述“要什么”,不必在语句里逐行安排数据库怎样扫描、匹配和排序。数据库会把声明式语句转换成内部执行计划,再选择具体算法。学习 SQL 时,真正需要建立的是集合思维:每个查询接收一张或多张表,产生一张新的结果表;修改语句则在约束允许的范围内改变表中的行。
下面统一使用一个企业培训平台。部门开设课程,讲师负责教学班,学员报名并获得成绩。所有示例都围绕同一组表展开,这样你能看到简单筛选怎样逐步长成多表查询、聚合和子查询,而不用在每个小节重新理解业务背景。
示例优先使用通用 SQL。不同数据库在大小写比较、集合运算、LATERAL、UNIQUE 谓词和删除列等细节上可能不同。把语句放进实际系统前,应检查当前数据库的语法说明和排序规则。
先看清 SQL 能做什么
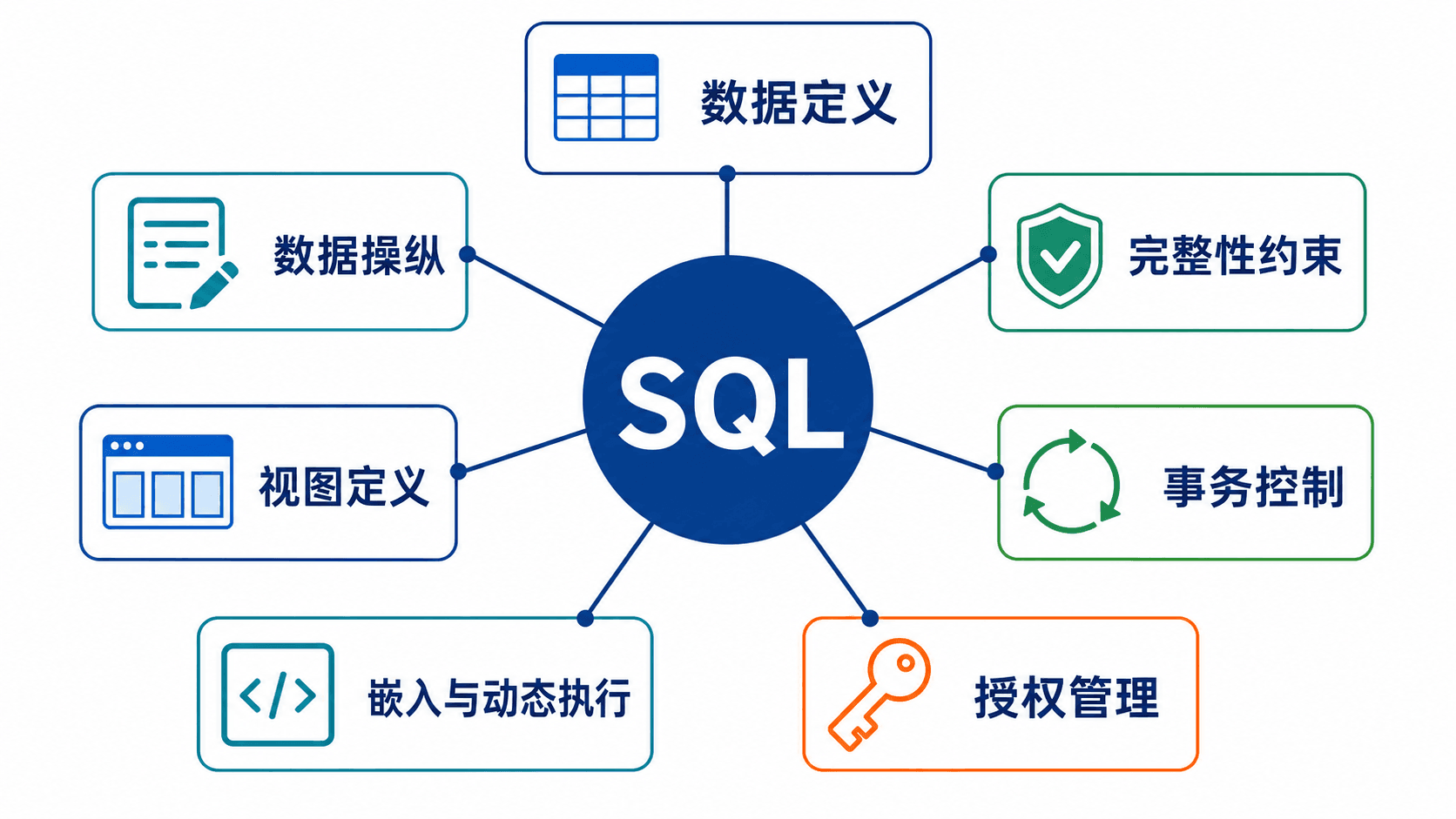
SQL 常被叫作查询语言,但查询只是它的一部分。一个实际数据库还需要定义结构、维护数据、限制非法状态、控制事务和权限。把这些能力放在一起看,SQL 大致承担以下工作:
- 数据定义:用 DDL 创建、修改和删除表、视图、索引等数据库对象。
- 数据操纵:用 DML 查询、插入、删除和更新行。
- 完整性约束:声明主键、外键、非空等规则,拒绝破坏一致性的修改。
- 视图定义:把查询封装成可复用的虚拟表。
- 事务控制:划定一组操作的开始、提交和回滚边界。
- 嵌入与动态执行:让应用程序生成或执行 SQL。
- 授权:规定用户或角色能读取、修改哪些对象。
SQL 最初在关系数据库研究项目中形成,后来经过多次标准化。标准提供共同词汇,但数据库产品并不是标准的逐字复制品。实际工作中常见三种差异:某个产品暂未实现较新的标准特性;某个产品保留自己的历史语法;同名函数在参数或返回值上略有不同。因此,掌握标准语义与识别方言边界同样重要。
一条 SQL 学习主线,从结构定义延伸到查询、约束、事务与授权。
声明结果,不手写遍历过程
下面两段代码表达相同意图:找出数据部门预算超过 80 万元的部门名称。伪代码需要说明怎样循环;SQL 只写结果应满足的条件。
text
逐行读取 department
如果 dept_name = '数据部' 且 budget > 800000
输出 dept_namesql
select dept_name
from department
where dept_name = '数据部'
and budget > 800000;这不代表 SQL 没有执行顺序。它只是把物理执行交给优化器。我们仍需理解语句的逻辑执行顺序,否则很容易在别名、聚合和过滤位置上犯错。
1
下列哪一项属于 SQL 的数据定义工作?
用 DDL 建立可验证的数据结构
表结构不是字段名称的清单。它还规定每列能保存什么类型的值、哪组列唯一标识一行、哪些列必须有值,以及一张表怎样引用另一张表。约束写进数据库之后,任何应用都要遵守同一套规则。
常用数据类型与选择依据
例如 numeric(5,2) 一共只能容纳 5 个十进制数字,其中 2 位在小数点后。999.99 可以精确保存,1000.00 超出总位数,1.234 则需要舍入或被拒绝,具体取决于系统规则。
char(8) 保存 'D01' 时会在末尾补空格;varchar(8) 不补。两个 char 值比较时,系统通常会把较短者补齐后比较。char 与 varchar 混合比较的行为可能随数据库或排序规则变化。除非业务值真的固定长度,否则 varchar 往往更省心。
一套可运行的培训平台模式
以下脚本先创建被引用的表,再创建引用它们的表。这个顺序可以避免外键找不到目标表。
sql
create table department (
dept_id varchar(8),
dept_name varchar(40) not null,
office varchar(40),
budget numeric(12,2),
primary key (dept_id)
);
create table learner (
learner_id varchar(10),
learner_name
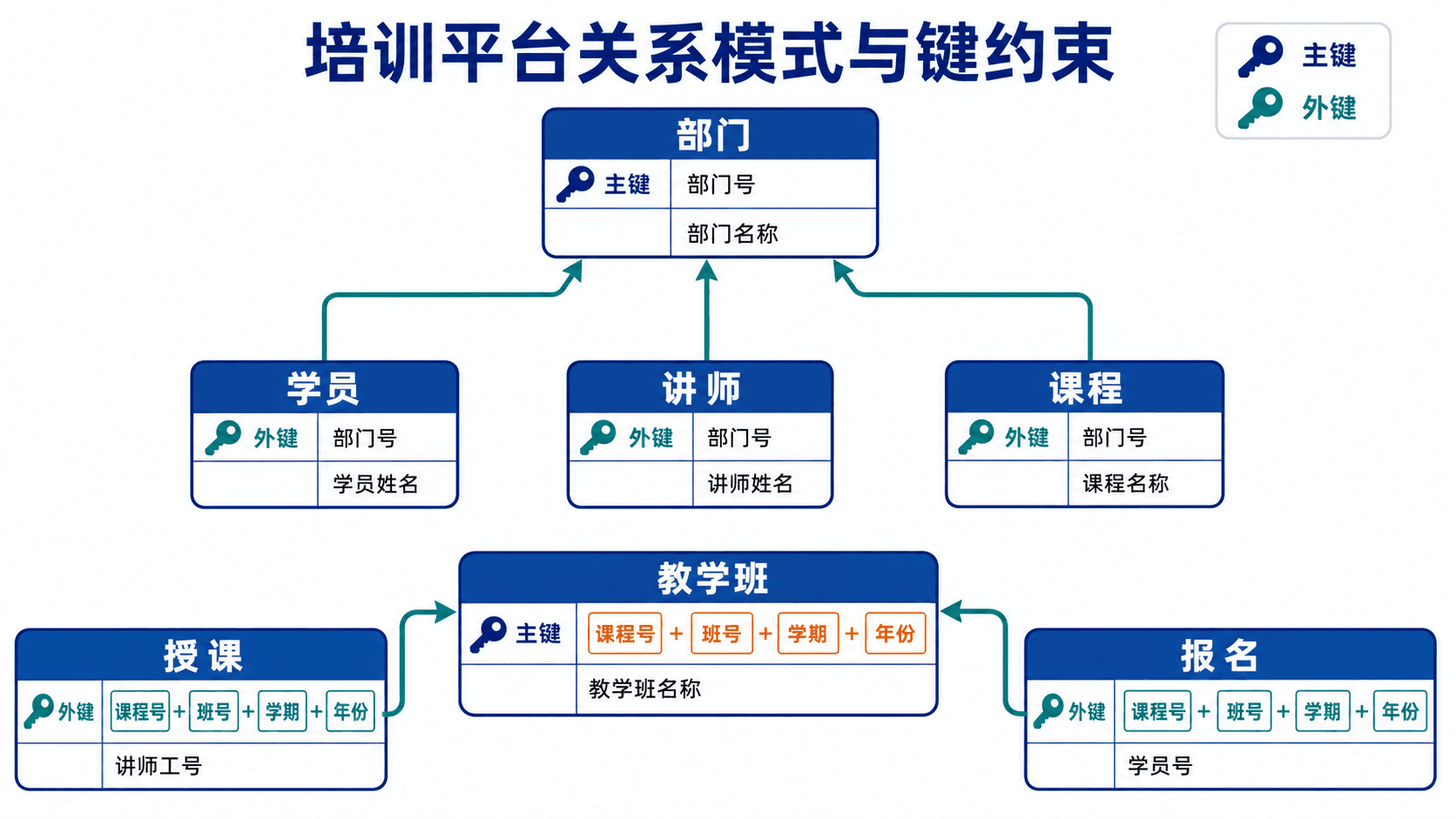
复合外键必须与被引用表的复合主键在列数、顺序和类型上对应。
primary key 同时要求唯一和非空。class_section 的主键由四列组成,因为同一课程可在不同学期、年份和教学班号下反复开班。foreign key 要求每个非空引用值在目标键中找到对应行。向 course 插入不存在的 dept_id,或向 enrollment 插入不存在的教学班,都会被拒绝。
not null 只回答“能否缺值”,并不保证唯一。反过来,普通业务列即便允许重复,也可能需要非空。例如每位讲师都必须有姓名,但两位讲师可以同名。
修改和删除结构
sql
alter table learner add email varchar(120);
alter table learner drop email;添加新列时,已有行在该列上通常得到 NULL,所以如果要直接增加 NOT NULL 列,应先设计默认值或分阶段回填。删除列并非所有系统都支持同样语法,且会影响查询、视图和应用代码。
sql
drop table enrollment;drop table 删除表结构和全部数据。它与 delete from enrollment 不同:后者只删除行,表仍然存在。若其他表通过外键引用当前表,删除结构或数据还会受到参照约束限制。
不要用 DROP TABLE 代替“清空数据”。前者会让表、约束和相关对象一起消失;后者保留模式。执行结构性删除前,还要检查依赖对象和备份策略。
2
关于培训平台模式,下列哪些说法正确?
从 SELECT、FROM、WHERE 开始查询
基础查询由三个核心子句组成:FROM 指定数据来源,WHERE 筛选行,SELECT 决定输出哪些列或表达式。语句书写顺序是 SELECT → FROM → WHERE,理解结果时却应先想 FROM → WHERE → SELECT。
sql
select instructor_name
from instructor
where dept_id = 'DATA'
and salary > 180000;逻辑上,数据库先从 instructor 取得候选行,再留下部门为 DATA 且薪资超过 180000 的行,最后只投影 instructor_name。实际执行计划可以使用索引、交换过滤顺序或采用其他等价算法,只要结果语义不变。
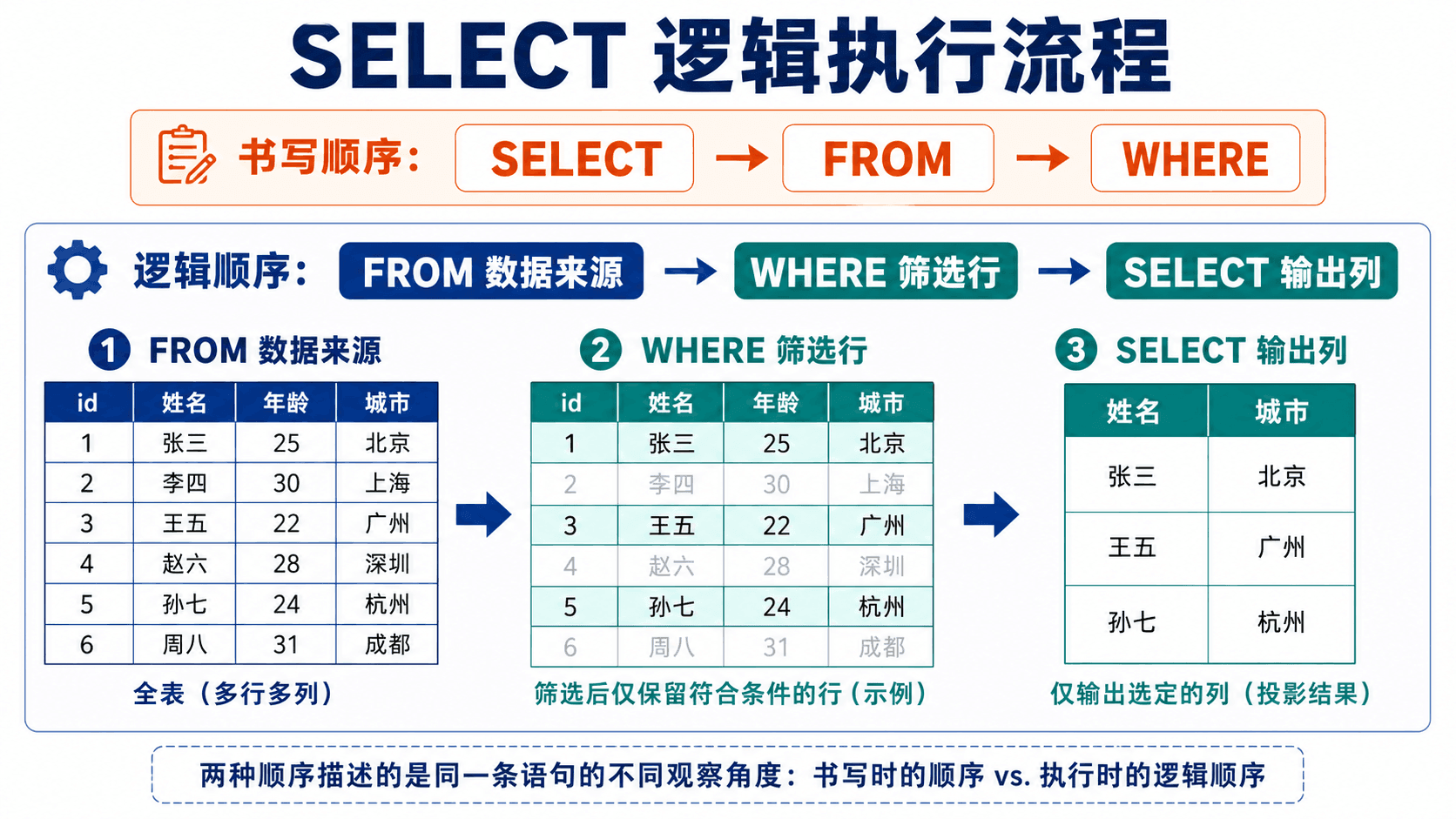
书写顺序服务于可读性,逻辑推演顺序决定我们怎样判断中间结果。
选择列、表达式与重复行
sql
select instructor_id,
instructor_name,
salary * 1.05 as estimated_salary
from instructor;这里的乘法只计算查询结果,不会改写原表。表达式若没有别名,结果列名可能难以阅读,所以用 AS 命名。SQL 查询默认保留重复行。查询所有讲师的部门编号时,同一部门会出现多次:
sql
select dept_id
from instructor;需要每个部门只出现一次时才加 DISTINCT:
sql
select distinct dept_id
from instructor;ALL 表示明确保留重复,但它是默认值,因此很少需要写。去重通常要排序或建立哈希结构,会产生额外成本,不要把 DISTINCT 当成修复错误连接的万能补丁。
比较与逻辑连接词
WHERE 可以使用 <、<=、>、>=、=、<>,再用 AND、OR、NOT 组合。字符串常量使用单引号;列名和 SQL 关键字不是字符串,不应随意放进单引号。
sql
select course_id, course_title
from course
where dept_id = 'DATA'
and credits >= 2
and credits <= 4;AND 的优先级通常高于 OR,但混合使用时最好加括号,把业务意思写清楚:
sql
select learner_id, learner_name
from learner
where joined_year = 2025
and (dept_id = 'DATA' or dept_id = 'OPS');下面的拼装器不会连接真实数据库,而是把每一步对应的中间关系显示出来。修改部门、薪资阈值和输出列,观察逻辑顺序怎样改变行数和列数。
3
查询写成 SELECT ... FROM ... WHERE ...,判断结果时应优先按什么逻辑顺序推演?
组合多张表并用别名消除歧义
当所需列分散在不同表中,FROM 可以列出多张表。逻辑上,它先形成笛卡尔积:第一张表的每一行都与第二张表的每一行配对。WHERE 中的连接条件再留下有业务关系的组合。
sql
select i.instructor_name,
d.dept_name,
d.office
from instructor as i, department as d
where i.dept_id = d.dept_id;dept_id 同时出现在两张表里,所以用 i.dept_id 和 d.dept_id 指明来源。AS 给表起别名,也能给结果列起名。部分数据库不允许在表别名之前写 AS,遇到这种方言时可写 from instructor i。
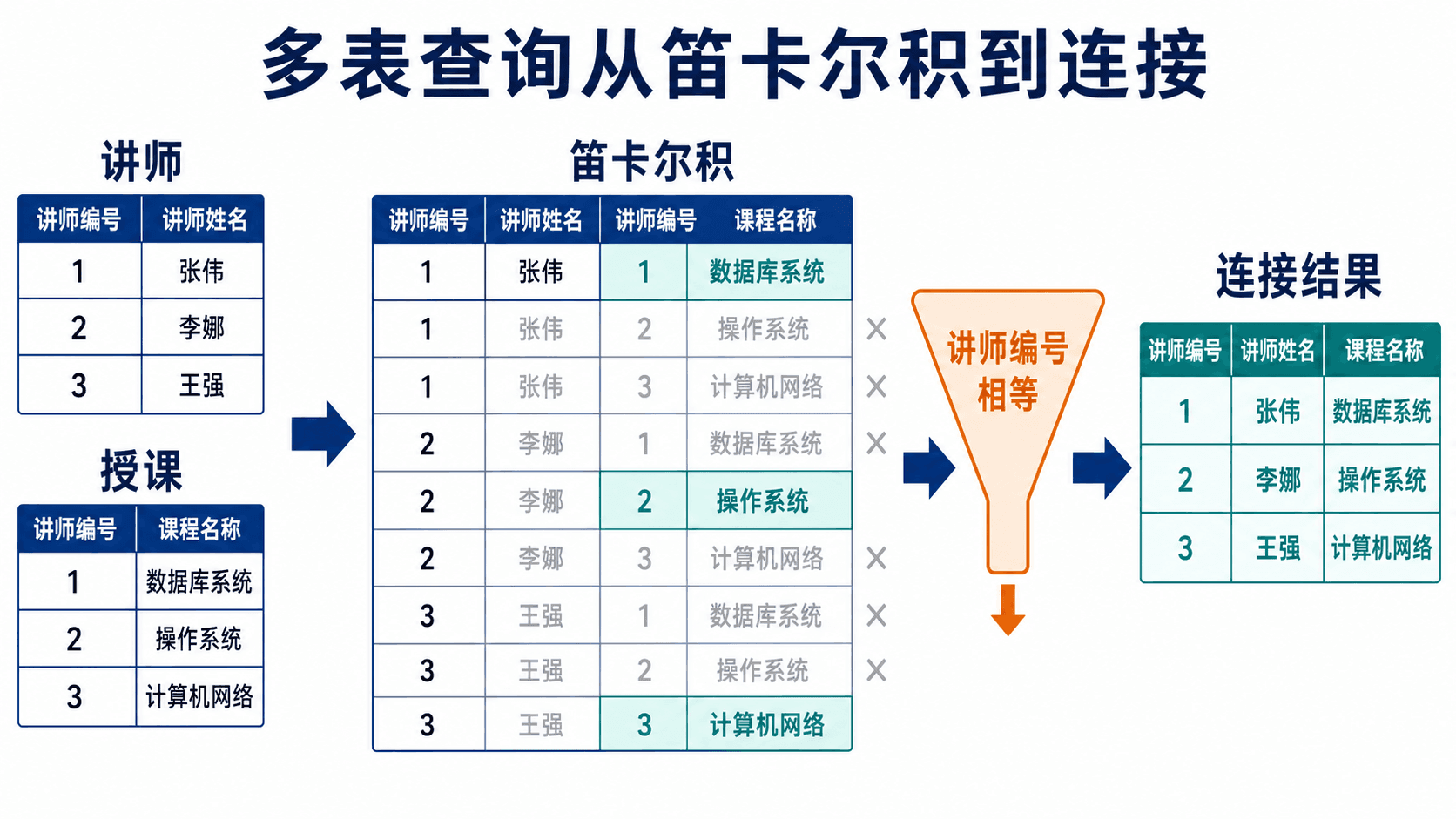
没有连接谓词时会保留全部组合;等值条件把配对收缩为真正相关的行。
如果 instructor 有 200 行,teaches 有 600 行,裸笛卡尔积会产生 120000 个组合。遗漏连接条件不仅结果错误,还可能造成巨大的中间结果。
sql
select i.instructor_name, t.course_id
from instructor as i, teaches as t
where i.instructor_id = t.instructor_id
and i.dept_id = 'DATA';这条查询只返回有授课记录的讲师。没有授课的讲师不会出现在结果里;若业务要求保留他们,需要外连接,不能靠删除连接条件解决。
自连接与相关名称
同一张表出现两次时,别名不再只是缩写,而是区分两个逻辑角色的必要手段。下面找出薪资高于数据部至少一位讲师的人:
sql
select distinct higher.instructor_name
from instructor as higher, instructor as baseline
where higher.salary > baseline.salary
and baseline.dept_id = 'DATA';higher 和 baseline 都指向 instructor,但分别代表“待检查的讲师”和“比较基准”。别名也叫相关名称或元组变量。
星号与结果列控制
select * 返回 FROM 结果的全部列;select i.* 只返回别名 i 对应表的全部列。教学演示时星号很方便,生产查询则更适合明确列名:表新增列后,结果契约不会突然变化,也能避免传输无用数据。
4
在两表查询中省略连接条件,只会多返回几行,但每一行仍然代表正确的业务配对。
处理字符串、排序、范围与集合
基础比较之外,SQL 还提供模式匹配、范围判断、结果排序和集合运算。它们看似分散,实际都在回答同一问题:怎样把结果整理成业务真正需要的形状。
字符串、LIKE 与转义
字符串用单引号括住。字符串本身若包含单引号,就写两次,例如 '学员''s Guide'。常见字符函数包括 upper、lower、trim、长度计算、子串提取和拼接;具体函数名可能随数据库略有不同。
LIKE 使用两个通配符:
%匹配任意长度字符串,也可以是空串;_恰好匹配一个字符。
sql
select course_id, course_title
from course
where course_title like '%SQL%';sql
select dept_id, dept_name
from department
where lower(dept_name) like '%data%';大小写是否敏感由数据库和排序规则决定。若要匹配字面量 % 或 _,需要声明转义字符:
sql
select course_title
from course
where course_title like '完成率\_%' escape '\';这表示标题以字面量 完成率_ 开头,而不是把下划线当成任意单字符。NOT LIKE 表示不匹配。
排序、范围和行值比较
结果表没有天然顺序。只有写出 ORDER BY,展示顺序才有保证:
sql
select instructor_name, salary
from instructor
order by salary desc, instructor_name asc;先按薪资降序;薪资相同时再按姓名升序。ASC 是默认方向,DESC 表示降序。没有 ORDER BY 时,即使某次执行看起来按主键排列,也不能依赖这种偶然顺序。
BETWEEN 的两个边界都包含在内:
sql
select instructor_name, salary
from instructor
where salary between 150000 and 200000;它等价于 salary >= 150000 and salary <= 200000。NOT BETWEEN 表示范围之外。
部分数据库支持行构造器,把多列作为整体比较:
sql
select course_id, section_id
from class_section
where (academic_year, term) = (2026, '春季');跨产品使用前需要确认支持程度。对于等值连接,逐列写 AND 通常最稳妥。
UNION、INTERSECT 与 EXCEPT
集合运算要求两边列数相同、对应位置的数据类型兼容。列名通常由第一个查询决定。
sql
(select course_id
from class_section
where term = '秋季' and academic_year = 2025)
union
(select course_id
from class_section
where term = '春季' and academic_year = 2026);UNION 返回至少出现在一边的课程,并自动去重;INTERSECT 返回两边都出现的课程;EXCEPT 返回只在左边出现、右边没有的课程。部分数据库用 MINUS 表示差集,也有产品不直接支持 INTERSECT 或 EXCEPT。
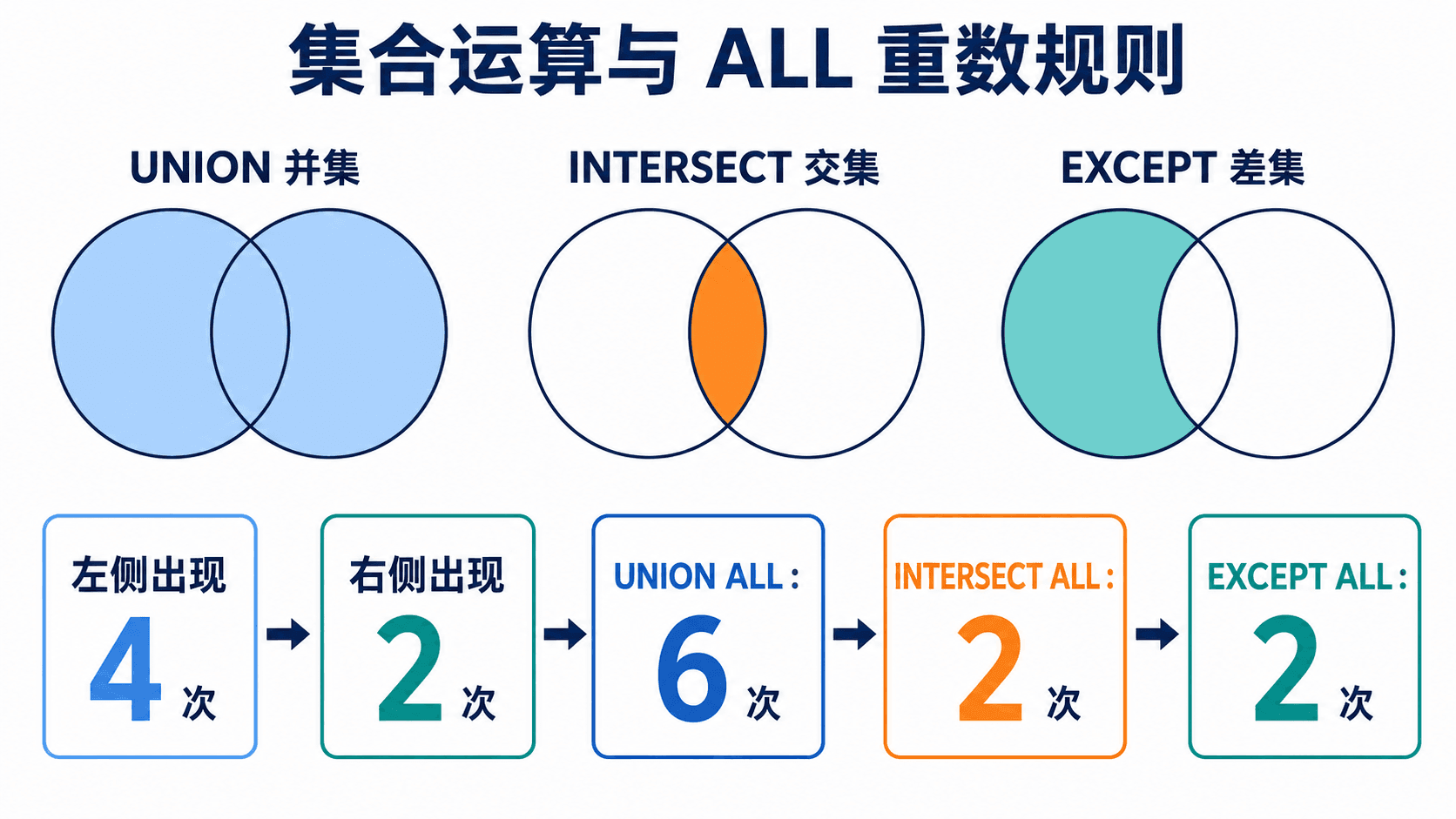
不带 ALL 时采用集合语义;带 ALL 时按每个元组在两边出现的次数计算。
带 ALL 的版本保留重数。若某课程在左边出现 4 次、右边出现 2 次:
UNION ALL中出现 6 次;INTERSECT ALL中出现min(4,2)=2次;EXCEPT ALL中出现max(4-2,0)=2次。
不带 ALL 时,三种操作都先按集合语义消除重复。要特别区分:普通 SELECT 默认保留重复,集合运算默认去重。
5
左查询中课程 C 出现 4 次,右查询中出现 2 次。哪些重数判断正确?
理解 NULL 和三值逻辑
NULL 表示值缺失:它可能暂时未知,也可能对当前行不适用。它不是 0、空字符串或字符串 'NULL'。一旦 NULL 进入计算和比较,普通的真假二值逻辑就不够用了。
算术、比较与 UNKNOWN
只要算术表达式有一个输入为 NULL,结果通常也是 NULL。例如 salary + 5000 在 salary 缺失时仍然未知。
普通比较遇到 NULL 会得到 UNKNOWN:
text
salary > 150000 → UNKNOWN(当 salary 为 NULL)
salary = NULL → UNKNOWN
NULL = NULL → UNKNOWNWHERE 只保留谓词为 TRUE 的行。FALSE 和 UNKNOWN 都被过滤。因此,下面的写法找不到空薪资:
sql
-- 错误思路
select instructor_name
from instructor
where salary = null;应该使用专用谓词:
sql
select instructor_name
from instructor
where salary is null;IS NOT NULL 检查已有值。部分系统还支持 IS UNKNOWN 和 IS NOT UNKNOWN,但可移植性不如前两者。

FALSE AND UNKNOWN 为 FALSE,TRUE OR UNKNOWN 为 TRUE,其余组合要按完整真值表判断。
三值逻辑的关键组合如下:
下面的实验器会逐步计算比较、NOT、AND 与 OR,并说明该行能否通过 WHERE。
去重与集合运算中的 NULL
谓词中的 NULL = NULL 是 UNKNOWN,但 DISTINCT 为了消除重复,会把对应位置上的两个 NULL 当作相同。UNION、INTERSECT 和 EXCEPT 判断重复元组时也采用这种规则。这是专门为集合去重定义的相同性,不要把它误推回普通 WHERE 比较。
6
某行 salary 为 NULL,WHERE salary > 150000 的结果怎样处理?
用聚合、分组与 HAVING 概括数据
聚合函数把一组值压缩成一个值。SQL 的五个标准聚合函数是 AVG、MIN、MAX、SUM 和 COUNT。SUM 与 AVG 需要数值输入;MIN、MAX 和计数也可用于适当的非数值类型。
sql
select avg(salary) as avg_salary,
min(salary) as min_salary,
max(salary) as max_salary,
sum(salary) as total_salary,
count(*) as instructor_rows
from instructor
where dept_id = 'DATA';COUNT(*) 计算行数。COUNT(salary) 只计算 salary 非空的行。COUNT(DISTINCT instructor_id) 先按讲师编号去重,再计数。COUNT(DISTINCT *) 不是标准写法。
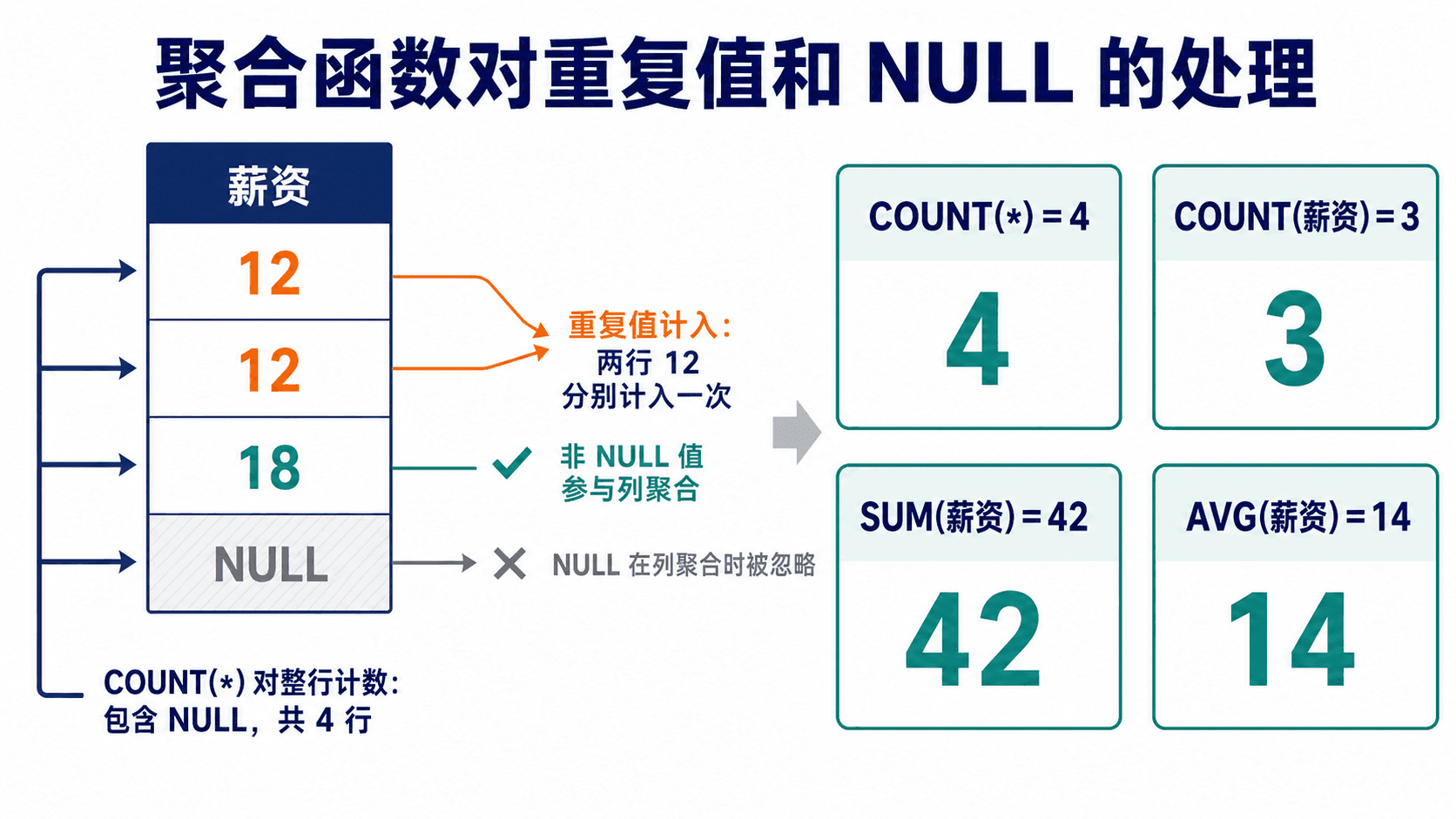
AVG 会保留重复数值的贡献并忽略 NULL;COUNT 星号统计所有输入行。
除 COUNT(*) 外,聚合函数都会忽略输入中的 NULL。过滤后没有输入行时,COUNT 返回 0,其余聚合通常返回 NULL。这意味着下面两个平均数的分母可能不同:
sql
select avg(salary), sum(salary) / count(*)
from instructor;若存在空薪资,AVG(salary) 的分母是非空薪资数量,COUNT(*) 却包含空薪资所在的行,两边不一定相等。
GROUP BY:每组产生一行
sql
select dept_id,
avg(salary) as avg_salary,
count(*) as instructor_count
from instructor
group by dept_id;GROUP BY dept_id 把部门编号相同的行放在同一组,再对每组计算聚合。没有 GROUP BY 时,满足 WHERE 的全部行被视为一个组。
在标准 SQL 中,SELECT 里未被聚合的列必须出现在 GROUP BY 中。下面的语句错误,因为一个部门有多位讲师,数据库无法为每个部门组挑出唯一的 instructor_name:
sql
-- 错误示例
select dept_id, instructor_name, avg(salary)
from instructor
group by dept_id;WHERE 筛行,HAVING 筛组
sql
select dept_id, avg(salary) as avg_salary
from instructor
where salary is not null
group by dept_id
having avg(salary) > 160000;WHERE 在分组前删除行,不能在这里直接判断本次查询计算出的组平均值;HAVING 在分组后删除不满足条件的组,可以使用聚合函数。完整逻辑顺序是:
FROM形成输入关系;WHERE筛选行;GROUP BY划分组,没有它时视为一个整体组;HAVING筛选组;SELECT为每个保留组计算结果列;ORDER BY对最终结果排序。
多表聚合要先控制重数
下面统计每个部门在 2026 年春季参与授课的不同讲师数:
sql
select i.dept_id,
count(distinct i.instructor_id) as instructor_count
from instructor as i, teaches as t
where i.instructor_id = t.instructor_id
and t.term = '春季'
and t.academic_year = 2026
group by i.同一讲师可能教多个班,所以要 COUNT(DISTINCT ...)。如果直接 COUNT(*),得到的是讲师-教学班配对数,不是讲师人数。
下面的推演器让你选择筛选年份、分组列和 HAVING 阈值,观察行过滤、分组与组过滤的区别。
7
要找平均薪资超过 160000 的部门,条件 avg(salary) > 160000 最合适放在哪里?
用子查询表达集合问题
子查询是一条嵌在另一条语句中的查询。它可以返回一列值、一张派生表,或恰好一个标量。理解子查询时,不要只盯着括号;先说清内层产生什么集合,再判断外层如何使用它。

一列集合适合成员判断,单值结果可进入表达式,多列结果可作为派生表继续查询。
IN 与 NOT IN:成员资格
找出 2025 年秋季和 2026 年春季都开设过的课程:
sql
select distinct course_id
from class_section
where term = '秋季'
and academic_year = 2025
and course_id in (
select course_id
from class_section
where term = '春季'
and academic_year = 2026
);内层返回 2026 年春季课程编号集合,外层检查秋季课程是否属于该集合。IN 也可接枚举集合:
sql
select instructor_name
from instructor
where dept_id in ('DATA', 'OPS');NOT IN 要特别小心 NULL。如果子查询结果中包含 NULL,外层“是否不等于所有成员”可能变为 UNKNOWN,导致意外的空结果。目标列可能为空时,优先使用 NOT EXISTS,或在子查询中明确排除 NULL。
部分系统支持多列行值成员测试:
sql
select count(distinct e.learner_id)
from enrollment as e
where (e.course_id, e.section_id, e.term, e.academic_year) in (
select t.course_id, t.section_id, t.term,
可移植写法可以改用相关 EXISTS,逐列比较。
SOME、ANY 与 ALL:量化比较
“薪资高于数据部至少一位讲师”可以写成:
sql
select instructor_name
from instructor
where salary > some (
select salary
from instructor
where dept_id = 'DATA'
);SOME 与 ANY 同义,表示至少一个比较为真。> ALL 表示大于集合中的每一个值:
sql
select instructor_name
from instructor
where salary > all (
select salary
from instructor
where dept_id = 'DATA'
);= SOME 与 IN 表达同类成员判断;<> ALL 与 NOT IN 对应。不要把 <> SOME 当成 NOT IN:只要集合里有一个不同值,<> SOME 就可能为真。
量化比较还要考虑空集合。> SOME (空集) 没有任何见证值,结果为假;> ALL (空集) 没有反例,结果为真。子查询含 NULL 时还会引入 UNKNOWN,因此薪资比较通常应在内层加 salary is not null。
EXISTS 与相关子查询
EXISTS 只关心内层是否至少返回一行,不关心返回列的具体内容。找出至少开过一个班的课程:
sql
select c.course_id, c.course_title
from course as c
where exists (
select *
from class_section as s
where s.course_id = c.course_id
);内层引用了外层的 c.course_id,所以它是相关子查询。可以把它理解为:对外层当前课程,检查是否存在一条匹配教学班。别名的作用域与程序变量相似:子查询可以使用自己定义的别名和外层可见别名;内层若重名,会遮蔽外层同名别名。
NOT EXISTS 擅长表达“不存在反例”。找出完成了数据部全部课程的学员,核心逻辑是:不存在一门数据部课程,学员没有完成它。
sql
select l.learner_id, l.learner_name
from learner as l
where not exists (
select c.course_id
from course as c
where c.dept_id = 'DATA'
and not exists (
select *
from enrollment as e
where
若数据部没有任何课程,上述条件对每位学员都成立,因为找不到反例。这叫空集上的真值,写“全部”问题时必须确认它是否符合业务要求。
UNIQUE 与重复性测试
标准 SQL 定义 UNIQUE (subquery),当子查询结果没有重复元组时为真;空结果也满足唯一。下面的思想是找出 2026 年开班不超过一次的课程:
sql
select c.course_id
from course as c
where unique (
select s.course_id
from class_section as s
where s.course_id = c.course_id
and s.academic_year = 2026
);这个谓词并未被广泛实现。更可移植的写法是计数:
sql
select c.course_id
from course as c
where 1 >= (
select count(*)
from class_section as s
where s.course_id = c.course_id
and s.academic_year = 2026
);NOT UNIQUE 表示存在重复。标准定义在元组含 NULL 时有细微边界,因为普通元组相等比较可能得到 UNKNOWN;实际工作更推荐用 GROUP BY ... HAVING COUNT(*) 明确表达重复判定。
FROM 子查询、WITH 与 LATERAL
查询结果仍是一张关系,因此可以放进 FROM:
sql
select dept_id, avg_salary
from (
select dept_id, avg(salary) as avg_salary
from instructor
group by dept_id
) as dept_avg
where avg_salary > 160000;派生表通常需要别名。复杂逻辑可用 WITH 给临时结果命名,并在同一条查询中复用:
sql
with dept_total as (
select dept_id, sum(salary) as total_salary
from instructor
group by dept_id
),
overall_avg as (
select avg(total_salary) as avg_total
from dept_total
)
select d.dept_id, d.total_salary
from dept_total as d, overall_avg as a
WITH 定义的是该语句范围内的命名查询,不等于一定把结果物理写成临时表。优化器可以内联或物化它。
普通 FROM 子查询通常不能引用同一 FROM 中前面表的列。支持 LATERAL 的系统可以这样写每位讲师及本部门平均薪资:
sql
select i.instructor_name, i.salary, a.avg_salary
from instructor as i,
lateral (
select avg(j.salary) as avg_salary
from instructor as j
where j.dept_id = i.dept_id
) as a;LATERAL 的支持程度存在产品差异,常见等价写法是相关标量子查询或连接一个预先分组的派生表。
标量子查询
标量子查询必须返回一列且至多一行,可以出现在需要单值表达式的地方:
sql
select d.dept_id,
d.dept_name,
(
select count(*)
from instructor as i
where i.dept_id = d.dept_id
) as instructor_count
from department as d;若标量子查询运行时返回多行,数据库会报错。使用无 GROUP BY 的 COUNT(*) 能保证只返回一个值。某些数据库允许不带 FROM 的纯计算:
sql
select
1.0 * (select count(*) from teaches)
/ (select count(*) from instructor)
as avg_sections_per_instructor;乘以 1.0 是为了避免整数除法截断。有些系统要求顶层必须有 FROM,可使用其提供的单行虚拟表。还要处理分母为 0 的情况,例如用 NULLIF(count, 0),具体函数支持请按当前系统确认。
8
关于子查询,下列哪些说法正确?
插入、删除和更新数据
查询产生结果,修改语句改变数据库实例。三类修改都要通过类型检查和完整性约束:插入的主键不能重复,外键不能指向不存在的行,非空列不能无故缺值。

INSERT 增加完整行,DELETE 删除完整行,UPDATE 修改选中行的列值。
INSERT:写一行或写入查询结果
显式列清单比依赖表定义顺序更安全:
sql
insert into course (course_id, course_title, dept_id, credits)
values ('SQL-201', 'SQL 查询设计', 'DATA', 3.0);列清单顺序可以与建表顺序不同,只要 VALUES 与它一一对应。省略的列会得到默认值或 NULL;若列不允许空且没有默认值,插入失败。
sql
insert into learner
(learner_id, learner_name, dept_id, joined_year, total_credits)
values
('L001', '顾川', 'DATA', 2026, null);也可以把查询结果整体插入目标表。目标列数、顺序和类型必须与查询结果兼容:
sql
insert into instructor
(instructor_id, instructor_name, dept_id, salary)
select learner_id, learner_name, dept_id, 120000
from learner
where total_credits > 100;逻辑上,数据库先完整计算 SELECT 结果,再执行插入。即使来源和目标是同一张表,也不会一边读取新插入的行一边无限复制。实际插入仍可能因主键冲突而失败。
DELETE:删除满足条件的整行
sql
delete from enrollment
where academic_year = 2024
and grade is null;DELETE 删除整行,不能只删除某个字段的值;若只想清空成绩,应写 UPDATE ... SET grade = NULL。省略 WHERE 会删除表内全部行,但保留表结构。
删除条件可以使用子查询:
sql
delete from instructor
where dept_id in (
select dept_id
from department
where office = '旧园区'
);一条标准 DELETE 只以一张表为目标,但条件可以读取多张表。外键可能阻止删除仍被课程、讲师或学员引用的部门。
删除低于全体平均薪资的讲师时,平均值按语句开始时的候选数据计算,再决定哪些行被删除;不会删一行就重算一次平均值:
sql
delete from instructor
where salary < (
select avg(salary)
from instructor
);UPDATE:改值而不替换整行
sql
update instructor
set salary = salary * 1.05
where salary < 160000;WHERE 决定哪些行被修改,SET 计算新值。省略 WHERE 会更新全部行。与删除类似,判断目标行时使用语句一致的输入语义,而不是一边更新一边让后续行看到不断变化的平均值。
需要分段规则时,用一个 CASE 比按顺序执行两条相互影响的更新更清晰:
sql
update instructor
set salary = case
when salary <= 200000 then salary * 1.05
else salary * 1.03
end;CASE 从上到下检查条件,返回第一个为真的分支;都不满足时使用 ELSE。它是一个值表达式,也能出现在 SELECT 中。
标量子查询可以放进 SET。下面根据学员已通过课程的学分重算累计学分:
sql
update learner
set total_credits = (
select coalesce(sum(c.credits), 0)
from enrollment as e, course as c
where e.learner_id = learner.learner_id
and e.course_id = c.course_id
and e.grade
若学员没有通过任何课程,SUM 对空输入返回 NULL;COALESCE(sum(...), 0) 取第一个非空值,于是得到 0。没有 COALESCE 的系统可以用 CASE WHEN sum(...) IS NOT NULL THEN sum(...) ELSE 0 END。
执行 UPDATE 或 DELETE 前,先把同一 WHERE 条件放进 SELECT,核对目标行和数量。对生产数据还应使用事务,并确认回滚、外键级联和审计策略。语法正确不等于修改范围正确。
9
为什么分段加薪更适合写成一个带 CASE 的 UPDATE?
把一条复杂 SQL 拆成可检查的步骤
面对复杂查询,最稳妥的方法不是从 SELECT 一口气写到结尾,而是把自然语言拆成集合问题。下面要求:找出 2026 年春季至少完成 2 门数据部课程、平均学分不低于 2.5 的学员,并按平均学分降序显示。
先确定结果粒度是“每位学员一行”,所以最终要按学员编号和姓名分组。只按姓名分组会把同名学员合并。
再确定事实来源。学员姓名来自 learner,报名成绩来自 enrollment,课程所属部门和学分来自 course,因此需要三表匹配。
把单行条件放进 WHERE:年份、学期、数据部课程、成绩非空且不是 F。这些条件都能在分组前判断。
把组条件放进 HAVING:完成课程数至少为 2,平均学分不低于 2.5。它们要等学员分组后才能计算。
按“不同课程编号”计数,可以写成:
sql
select l.learner_id,
l.learner_name,
count(distinct e.course_id) as completed_courses,
avg(c.credits) as avg_credits
from learner as l,
enrollment as e,
course as c
where l.learner_id = e
这条语句也提供了一份通用检查清单:
- 结果一行代表什么实体或分组?
- 每个输出列来自哪张表,是否需要聚合?
- 每一对表之间是否都有正确的匹配条件?
- 条件作用于单行还是分组,应放
WHERE还是HAVING? - 重复行是业务事实还是连接错误,是否真的需要
DISTINCT? NULL会让比较变成UNKNOWN,会让聚合忽略哪些值?- 子查询应返回集合、关系还是单值,空集时结果是否符合业务含义?
- 修改语句是否先用同条件的
SELECT核验过目标范围?
SQL 的各个语法块并不是互相孤立的技巧。DDL 先规定合法状态,查询在这些表上组合集合,NULL 和重复语义决定边界,聚合与子查询把行级事实变成组级判断,修改语句再在相同约束下改变实例。能按这条链路推演,就能解释结果为什么出现,也能在结果不对时定位是哪一步偏离了业务口径。
10
编写复杂聚合查询时,哪些检查方法有效?