进阶 SQL:从正确查询到可治理的数据边界
基础查询解决的是“从一张表里取出哪些行和列”,进阶 SQL 继续处理几个更接近真实系统的问题:数据分散在多张表里时怎样拼接;应用该看到哪些数据;多条修改怎样成为一个不可分割的动作;什么规则必须由数据库兜底;数据类型、索引和权限又该怎样配合。
下面统一使用一个在线学习平台的场景。核心表包括学习者 learner、课程 course、选课 enrollment、课程分类 category 和学习活动 learning_event。示例采用 PostgreSQL 可执行语法;涉及不同产品实现差异时,会把可直接运行的做法和概念模型分开说明。
阅读这些 SQL 时,先判断“结果必须保留谁”,再判断“通过什么条件匹配”,最后考虑性能和权限。连接、视图、约束、索引与授权分别解决不同层次的问题,互相不能替代。
把多张表连接成可信结果
关系数据库把不同主题的数据拆进不同表。课程名称在 course,学习者姓名在 learner,二者之间的报名关系在 enrollment。连接不是简单地把两张表横向贴在一起,而是从两侧各取一行,检查它们是否满足匹配条件,再决定是否进入结果。
从笛卡尔积理解内连接
先看两张精简表:
sql
create table learner (
learner_id bigint primary key,
learner_name varchar(40) not null,
region varchar(20) not null
);
create table enrollment (
learner_id bigint not null,
course_id bigint not null,
enrolled_at timestamp not null,
status varchar(12) not null
);CROSS JOIN 会让左表每一行和右表每一行配对。若学习者有 1000 行,报名有 8000 行,中间结果就是 800 万行。等值连接是在这些候选配对中只保留编号相同的组合:
sql
select l.learner_id,
l.learner_name,
e.course_id,
e.status
from learner as l
join enrollment as e
on e.learner_id = l.learner_id;不写 INNER 时,JOIN 默认就是内连接。它只返回两侧都能匹配的行,所以没有任何报名记录的学习者不会出现。
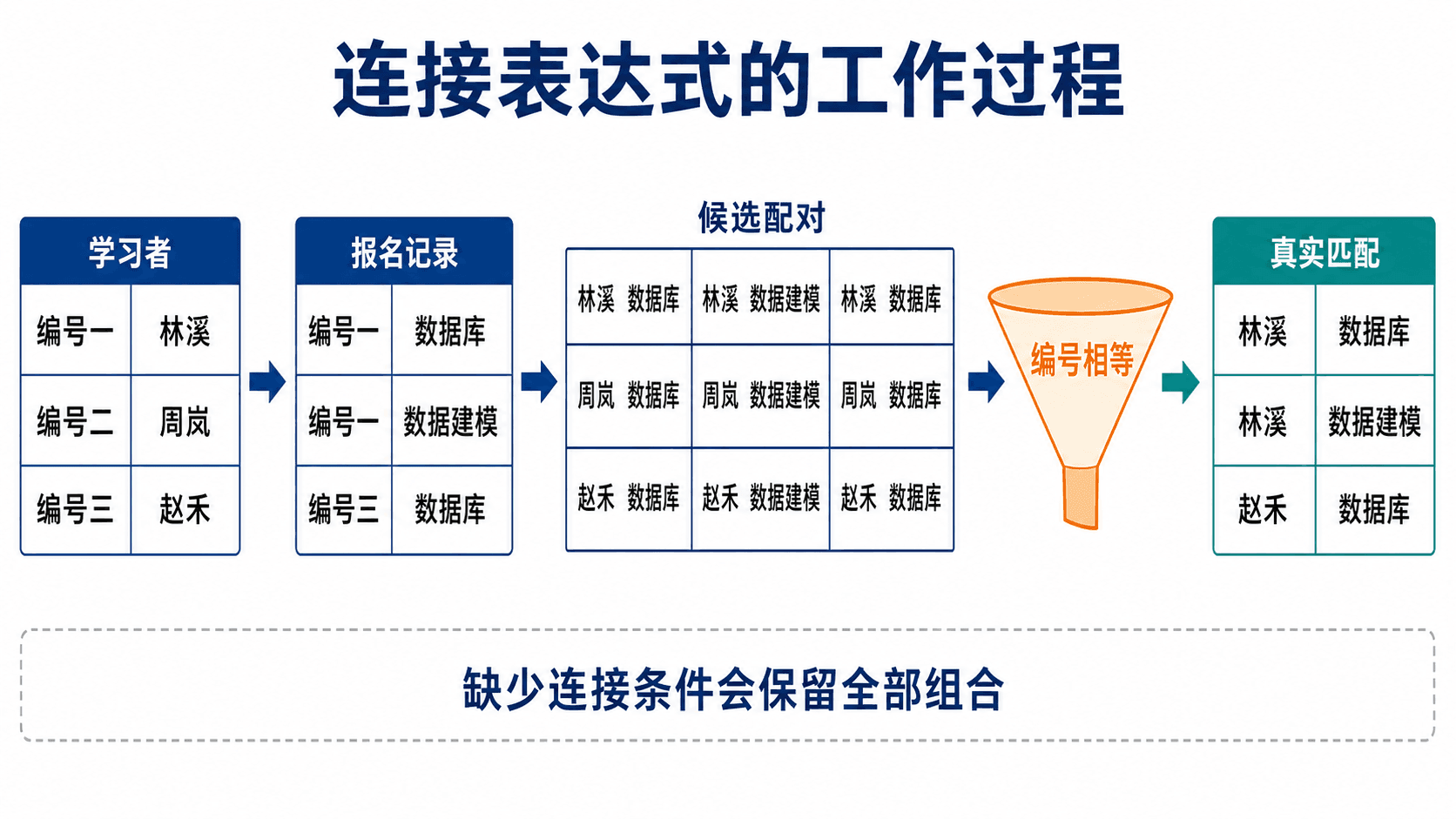
内连接保留满足匹配谓词的行;连接条件缺失时会退化成笛卡尔积。
ON、USING 与 NATURAL JOIN
ON 接受一般谓词,列名不同、需要范围匹配或需要多个条件时都能使用:
sql
select l.learner_name,
e.course_id,
e.enrolled_at
from learner as l
join enrollment as e
on e.learner_id = l.learner_id
and e.enrolled_at >= timestamp '2026-01-01 00:00:00';USING 适合两边连接列同名的等值连接。连接列在结果里只保留一份:
sql
select learner_id, learner_name, course_id
from learner
join enrollment using (learner_id);NATURAL JOIN 会自动把两表所有同名列都当成等值条件。它看起来很短,却把查询语义交给了当前表结构。假设 learner 和 course 都有 region,下面的多表自然连接会同时比较 course_id 和 region;跨地区选课会被意外删除。
sql
-- 不建议:新增同名列后,结果可能静默改变
select learner_name, course_title
from learner
natural join enrollment
natural join course;更稳妥的写法是明确连接键:
sql
select l.learner_name, c.course_title
from learner as l
join enrollment as e
on e.learner_id = l.learner_id
join course as c
on c.course_id = e.course_id;自然连接最大的风险不是语法报错,而是表新增同名列后查询仍能执行、含义却已经改变。长期维护的业务查询应优先写明确的 ON 或 USING。
用别名消除列名歧义
learner_id 同时存在于两张表时,直接 select learner_id 可能产生“列引用不明确”的错误。表别名既缩短 SQL,也准确表达列来自哪里:
sql
select l.learner_id as learner_id,
l.learner_name,
e.status as enrollment_status
from learner as l
join enrollment as e
on e.learner_id = l.learner_id;使用 ON 时,两侧连接列仍各自存在;使用 USING (learner_id) 时,结果中只有一列 learner_id。显式列清单比 select * 更稳定,因为表增加列后不会改变接口返回结构。
外连接保留未匹配行
如果报表要求列出所有学习者,包括尚未选课的人,内连接就不够。左外连接先计算匹配结果,再把左侧未匹配行补回,右侧字段填 NULL:
sql
select l.learner_id,
l.learner_name,
e.course_id,
e.status
from learner as l
left join enrollment as e
on e.learner_id = l.learner_id
order by l.learner_id, e.course_id;右外连接保留右表全部行。实际开发中常交换表顺序并写成左连接,让阅读方向保持统一。全外连接同时保留两侧未匹配行,适合做系统间对账:
sql
select coalesce(a.external_key, b.external_key) as external_key,
a.amount as billing_amount,
b.amount as ledger_amount
from billing_snapshot as a
full outer join ledger_snapshot as b
on b.external_key = a.external_key;COALESCE 返回第一个非空值,因此对账键只显示一列。全外连接的结果由三部分组成:匹配行、仅左侧存在的行、仅右侧存在的行。
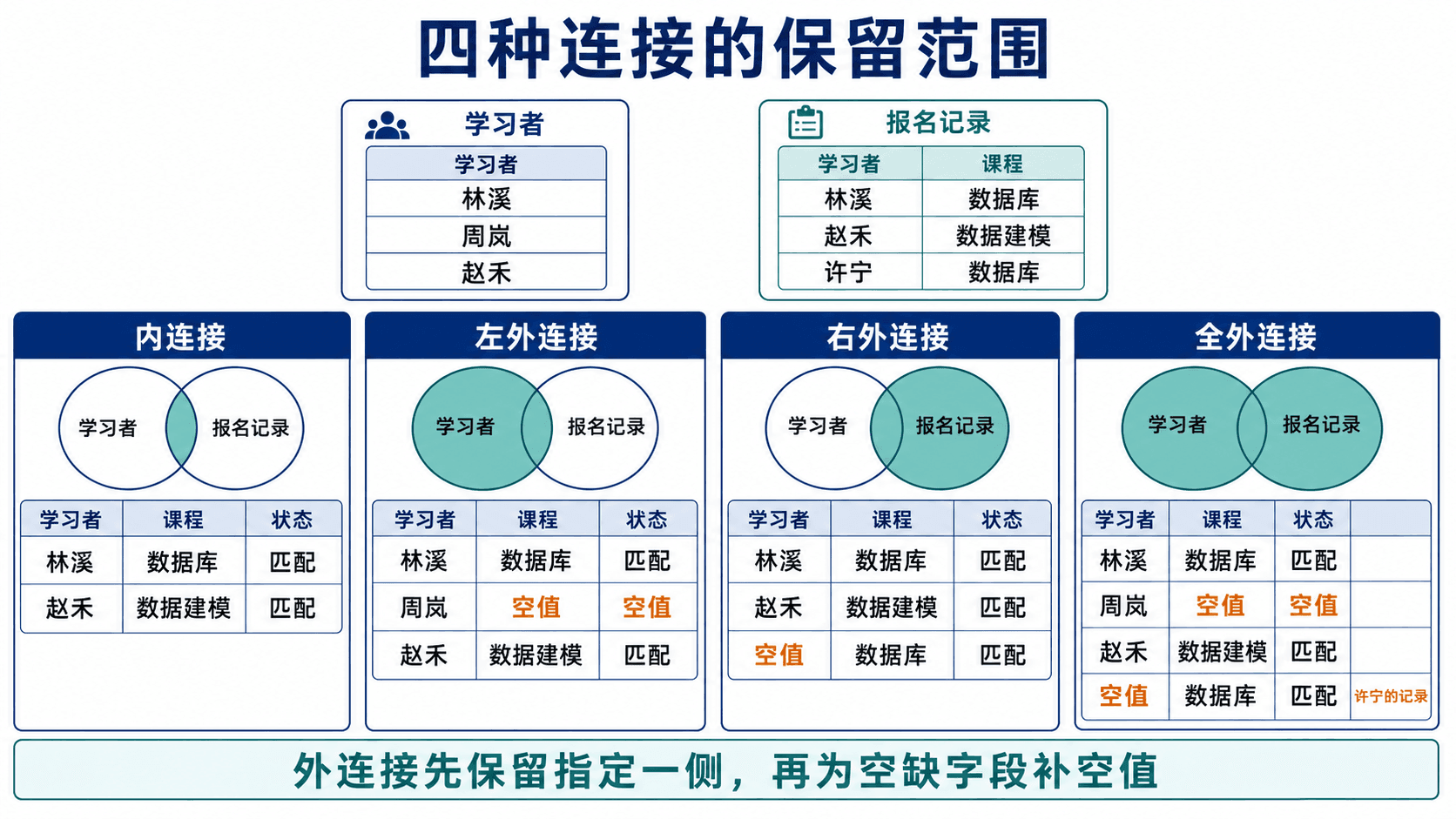
外连接的方向决定哪一侧未匹配行仍会进入结果,缺少的字段用 NULL 补齐。
ON 与 WHERE 在外连接中不可互换
下面查询的目标是“列出所有学习者,并只拼接已完成的报名”:
sql
select l.learner_name, e.course_id
from learner as l
left join enrollment as e
on e.learner_id = l.learner_id
and e.status = 'completed';状态条件属于匹配规则。没有已完成报名的学习者仍会被保留,只是 course_id 为 NULL。若把状态条件移动到 WHERE:
sql
select l.learner_name, e.course_id
from learner as l
left join enrollment as e
on e.learner_id = l.learner_id
where e.status = 'completed';补出的空值行无法满足 e.status = 'completed',会被 WHERE 删除,效果接近内连接。可以把 ON 理解成“哪些行算匹配”,把 WHERE 理解成“连接结果形成后还保留哪些行”。
下面的模拟器用同一组数据比较四种连接,并允许把报名状态条件放进 ON 或 WHERE。观察未报名的“周岚”在不同选择下是否仍存在。
1
要列出全部学习者,并且只拼接状态为 completed 的报名,同时保留没有此类报名的学习者,状态条件应放在哪里?
用视图封装稳定的数据边界
视图给一条查询一个长期可复用的名字。数据库通常保存查询定义,而不是保存普通视图的结果;每次查询视图时,优化器会把视图定义展开并与外层条件一起规划。
创建、命名与查询视图
客服只需要学习者编号、显示名和状态,不应看到邮箱。可以创建只暴露必要列的视图:
sql
create view support_learner as
select learner_id,
learner_name,
account_status
from learner;
select learner_id, learner_name
from support_learner
where account_status = 'active';视图与一次查询里的公共表表达式不同:WITH 定义的名字只在当前语句内有效,视图则一直存在,直到显式 DROP VIEW。
聚合表达式应给出稳定列名。可以在视图名后声明列清单,也可以在 SELECT 中使用别名:
sql
create view category_metrics
(category_id, course_count, avg_price) as
select category_id,
count(*),
avg(price)
from course
group by category_id;一个视图还可以引用另一个视图。这样可以分层封装,但层级过深会让依赖和调试变复杂。设计时应让每层都有清楚的业务边界,而不是只为了缩短 SQL。
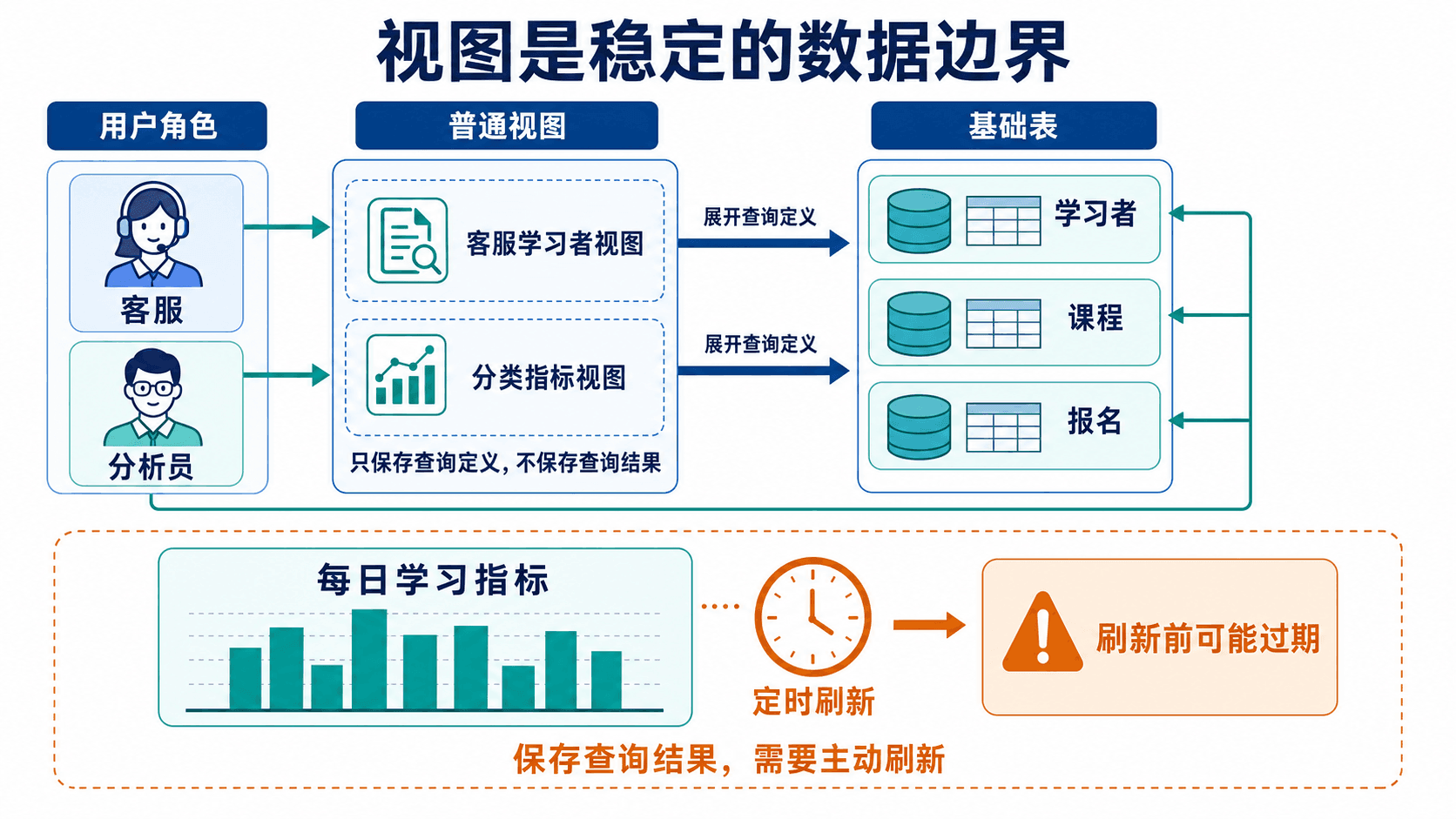
应用查询视图时,数据库把视图定义展开到基础表;授权检查仍以用户可见的对象边界为准。
普通视图与物化结果
普通视图每次都反映基础表当前状态,没有额外刷新动作。大型聚合如果被频繁读取,可以保存预计算结果,这就是物化视图的思想:
sql
create materialized view daily_learning_metrics as
select event_time::date as metric_date,
course_id,
count(*) as event_count,
count(distinct learner_id) as learner_count
from learning_event
group by event_time::date, course_id;
refresh materialized view daily_learning_metrics;查询物化视图通常更快,因为不必每次扫描全部活动事件;代价是占用存储、刷新消耗资源,并且两次刷新之间的数据可能过期。要根据业务容忍的陈旧时间选择同步刷新、按需刷新或周期刷新。不同数据库对物化视图语法和刷新能力的支持不同。
为什么有些视图不能更新
通过视图执行 INSERT、UPDATE 或 DELETE 时,数据库必须把动作唯一映射回基础表。下面的单表投影视图通常可以更新:
sql
create view active_course as
select course_code, course_title, price, course_status
from course
where course_status = 'active'
with local check option;它只有一个基础表,输出列直接对应基础列,没有聚合、DISTINCT、GROUP BY 或计算表达式。未出现在视图中的基础列必须允许为空或有默认值,否则插入仍会失败。
WITH CHECK OPTION 防止一条通过视图写入的数据写完后立即从视图里消失:
sql
-- 被拒绝:新行不满足 course_status = 'active'
insert into active_course
(course_code, course_title, price, course_status)
values
('SQL-9001', 'SQL 审计实践', 199.00, 'draft');连接视图常常不能安全插入,因为一行视图结果对应多张基础表;聚合视图也不能直接更新,因为“把平均价格增加 10 元”并没有唯一的基础行修改方案。复杂写入需要应用服务明确操作基础表,或使用数据库提供的 INSTEAD OF 触发机制定义映射规则。
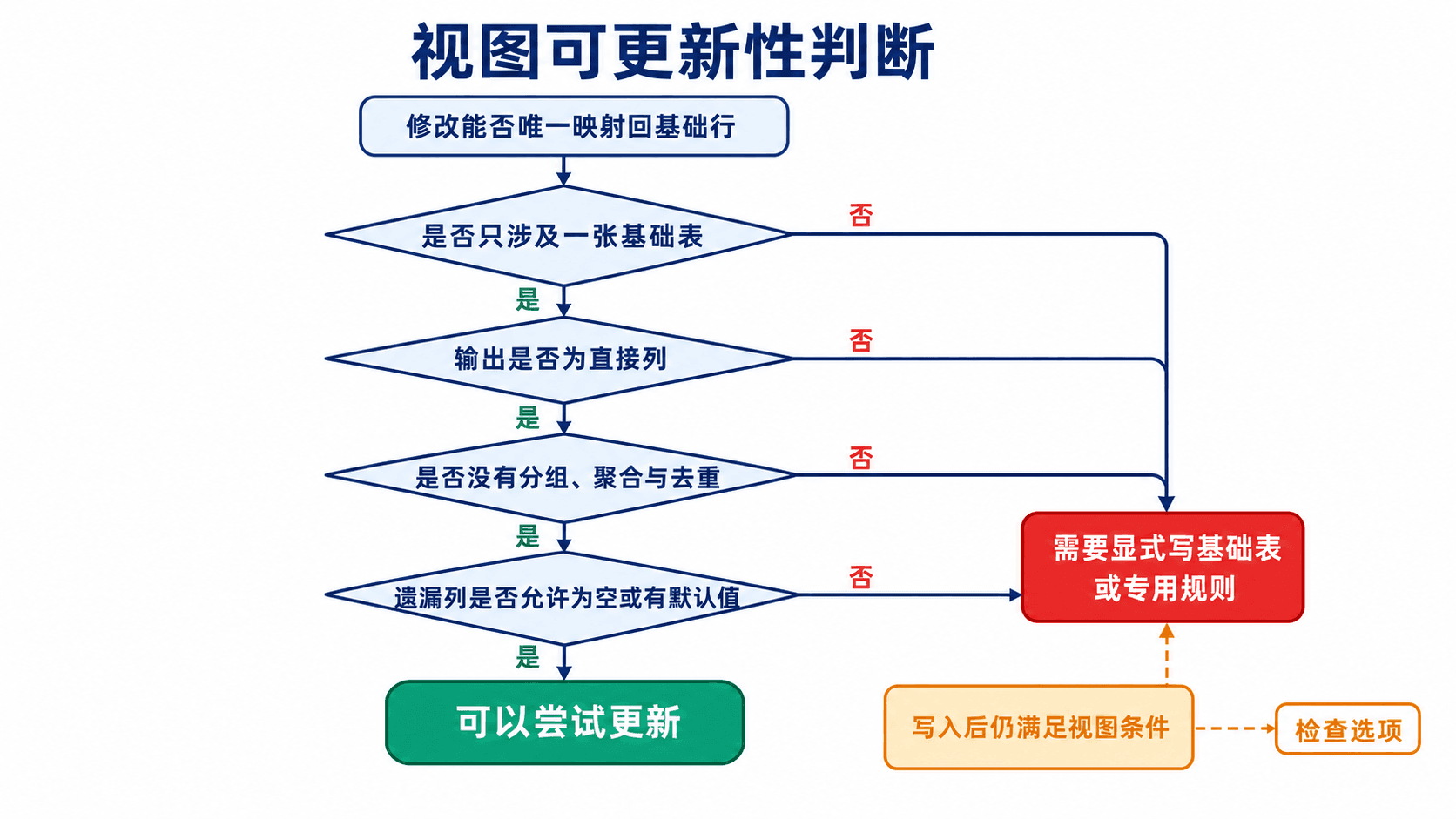
能否更新视图,关键在于一次修改能否无歧义地映射为基础表上的修改。
下面的判断器把常见条件组合起来。它给出保守结论,并解释是哪一项阻断了自动更新。
2
下列哪些因素通常会让数据库无法把视图更新自动且唯一地映射回基础表?
用事务划清不可分割的业务动作
事务是一组查询和修改语句组成的工作单元。它要么整体提交,要么在失败时整体撤销。以“报名课程并扣减名额”为例,插入报名和减少剩余名额必须一起成功;只执行一半会让报名人数与容量对不上。
显式开始、提交与回滚
sql
begin;
update course
set seats_left = seats_left - 1
where course_id = 42
and seats_left > 0;
insert into enrollment
(learner_id, course_id, enrolled_at, status)
values
(1008, 42, current_timestamp, 'active');
commit;COMMIT 让当前事务中的修改成为持久状态。ROLLBACK 撤销自事务开始以来尚未提交的修改:
sql
begin;
update wallet
set balance = balance - 199.00
where learner_id = 1008;
-- 应用检查到支付账户状态异常
rollback;COMMIT WORK 与 ROLLBACK WORK 也是完整形式,WORK 通常可以省略。事务提交后会话继续执行下一条语句时,会进入新的事务工作单元。
提交以后,再执行 ROLLBACK 不能撤销已经提交的事务。业务上的退款必须作为新的补偿事务记录,而不是期待数据库倒转历史。
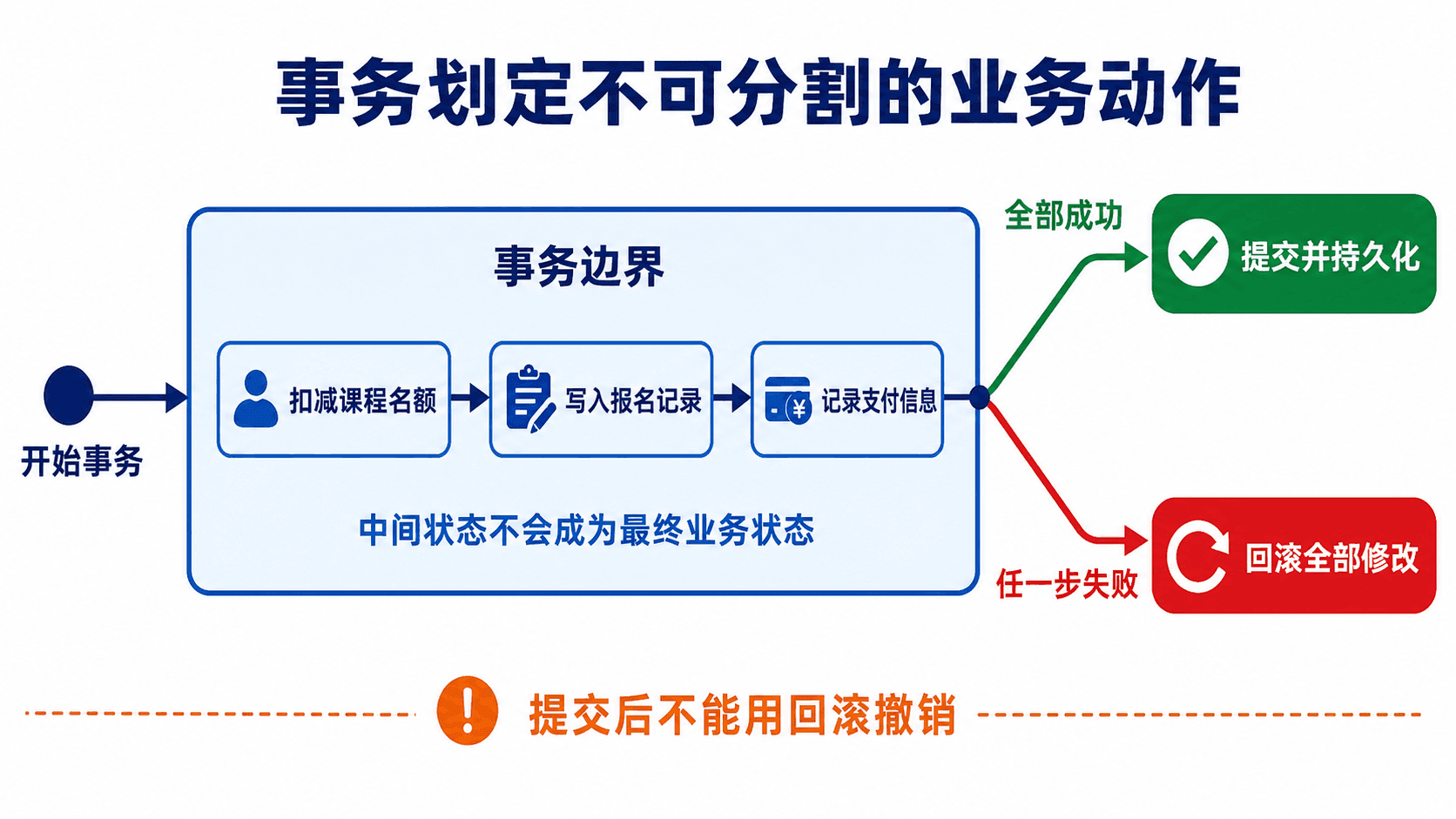
事务内的中间修改尚未形成最终业务状态;提交固定全部修改,回滚撤销未提交修改。
隐式事务与自动提交
SQL 会话执行语句时会进入事务。许多客户端启用自动提交,把每条语句各自当成一个事务;这对独立修改很方便,却无法保证多条语句的原子性。需要多步一致时,应使用显式 BEGIN … COMMIT,并让应用在异常路径执行 ROLLBACK。
SQL 也有用 BEGIN ATOMIC … END 把一组语句声明为原子块的思想,但常见产品的支持范围不同。PostgreSQL 这类系统更常见的事务控制是 BEGIN 开始、以 COMMIT 或 ROLLBACK 结束。程序退出或连接断开时怎样处理未显式结束的事务,也不能依赖模糊默认值。
不同产品对事务块、DDL 是否隐式提交、断开连接时如何处理未提交事务有差异。可靠做法是:
- 在应用连接配置中明确自动提交策略,不依赖客户端默认值。
- 让事务边界与一个业务动作对齐,异常路径明确回滚。
- 不把网络调用、人工等待等慢操作放进长事务,以免长期持锁。
- 检查每条修改影响的行数;
UPDATE更新 0 行可能意味着名额已用完,而不是成功。
原子性不等于业务校验
事务能保证两条修改一起提交,却不会自动判断余额是否足够、课程是否开放。条件必须写在修改谓词或约束中:
sql
begin;
update wallet
set balance = balance - 199.00
where learner_id = 1008
and balance >= 199.00;
-- 应用必须确认上一步恰好更新 1 行
insert into payment
(learner_id, course_id, amount, paid_at)
values
(1008, 42, 199.00, current_timestamp);
commit;如果扣款更新 0 行,应用应回滚,不能继续插入支付记录。并发隔离、锁与死锁处理属于更深入的事务主题,这里先把最基本的边界写对。
3
开启自动提交后,连续执行两条 UPDATE 就会自动成为一个不可分割的事务。
让完整性约束替所有写入者守门
应用校验可以改善交互提示,数据库约束负责最终一致性。无论数据来自网页、后台任务、批量导入还是运维脚本,只要写入同一张表,都必须通过同一组约束。
在一张表内约束值
下面把常用约束放进课程表:
sql
create table course (
course_id bigint generated always as identity,
course_code varchar(30) not null,
course_title varchar(120) not null,
course_status varchar(12) not null default 'draft',
price numeric(10, 2) not null default
NOT NULL禁止缺失值。主键天然不允许NULL,无需重复声明。UNIQUE保证列组合没有重复,但多数数据库允许唯一列出现多个NULL。若业务要求“必填且唯一”,要同时写NOT NULL。CHECK要求每行谓词不能为FALSE。当表达式因NULL得到UNKNOWN时通常仍算通过,因此check (price > 0)不能替代price not null。- 给约束命名后,错误信息更清楚,也能用名字删除或替换约束。
sql
alter table course
drop constraint ck_course_price;给已有表补约束时,可以使用 ALTER TABLE … ADD CONSTRAINT。数据库会先检查现有行;只要已有数据违反新规则,添加操作就会失败,必须先清理数据或调整规则。
用外键维护表之间的引用
报名必须指向真实存在的学习者和课程:
sql
create table enrollment (
enrollment_id bigint generated always as identity primary key,
learner_id bigint not null,
course_id bigint not null,
enrolled_at timestamptz not null default current_timestamp,
status varchar(12) not null default 'active',
score numeric(5, 2),
外键引用的目标列必须是主键或候选键,复合外键的列数、顺序和类型要兼容。默认行为通常是拒绝破坏引用的删除或更新。可选动作包括:
外键列默认可以为 NULL,除非同时声明 NOT NULL。复合外键只要包含空值,常见实现就不会要求它匹配目标行,因此“关系必须存在”需要显式非空约束,不能只写 FOREIGN KEY。
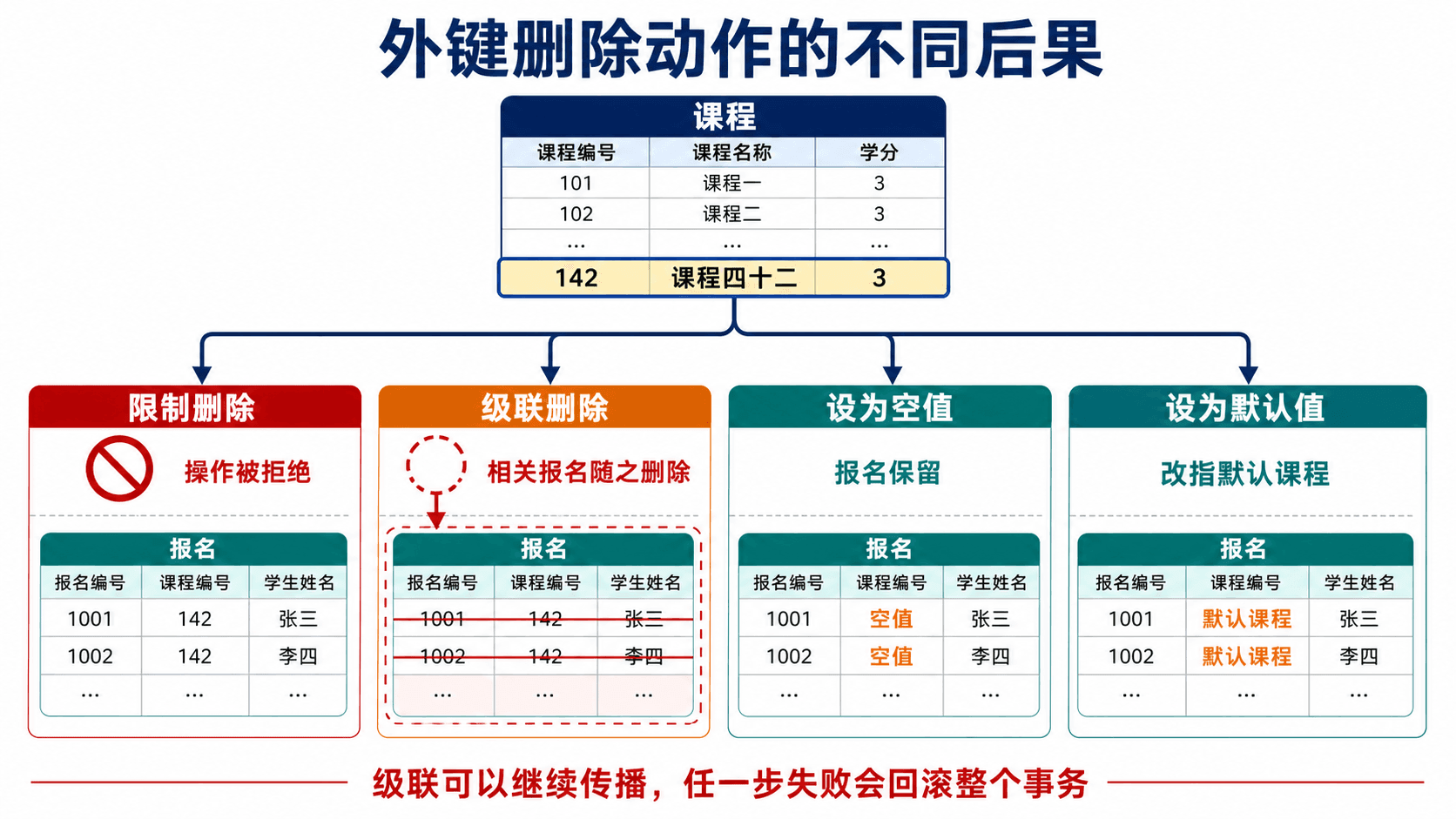
父表发生删除时,限制、级联、置空和默认值会产生完全不同的数据后果。
级联可以沿外键链继续传播。如果链中某一步无法满足约束,整个事务应失败并撤销。不要因为“省事”就普遍使用 ON DELETE CASCADE;课程报名、付款记录和审计记录通常有独立保留期。
事务中的延迟检查
有些业务需要在事务中短暂违反外键,但提交前恢复一致。例如两名员工互相登记为协作人。可延迟约束允许把检查推迟到事务末尾:
sql
create table collaboration (
member_id bigint primary key,
partner_id bigint,
constraint fk_partner
foreign key (partner_id)
references collaboration (member_id)
deferrable initially deferred
);
begin;
insert into collaboration values (1, 2);
insert into collaboration values (2, 1);
commit;不是所有数据库都支持延迟约束。若目标系统不支持,可以先插入 NULL,再在同一事务中回填,但前提是列允许为空。
跨表规则与断言思想
“每门上架课程至少有一位讲师”“学习者累计学分等于所有已完成课程学分之和”都涉及多张表。理想的声明式写法是定义一个始终为真的数据库级谓词,并拒绝任何破坏它的修改。这就是断言的思想。
概念形式如下:
sql
create assertion active_course_has_instructor
check (
not exists (
select 1
from course as c
where c.course_status = 'active'
and not exists (
select 1
from course_instructor as ci
where ci.course_id = c.course_id
)
)
通用 CREATE ASSERTION 和带子查询的 CHECK 在常见数据库中通常不能直接使用,因为任意表变化都可能触发昂贵检查。可运行方案一般是重新设计数据流程、使用触发器或在受控事务中执行显式校验。无论选择哪种方式,都要同时考虑哪些表的插入、更新和删除可能破坏规则。
4
关于完整性约束,下列哪些说法正确?
用数据类型和命名空间表达真实语义
数据类型不只是存储宽度。它决定可接受的值、比较方式、计算规则和应用接口。把日期存成字符串、把金额存成浮点数、把所有编号都存成一个含义模糊的文本列,短期能写入,长期会把校验和转换成本推给每一次查询。
日期、时间、时间戳与时区
SQL 把几个看似相近的概念分开:
日期与时间字面量应使用明确类型:
sql
select date '2026-09-01' as publish_date,
time '19:30:00' as live_start_time,
timestamp '2026-09-01 19:30:00' as local_schedule,
timestamptz '2026-09-01 19:30:00+08' as actual_start;time(p) 和 timestamp(p) 中的 p 控制秒的小数位精度。带时区时间戳通常适合跨地区系统:写入时代表同一绝对时刻,显示时再按会话或用户时区转换。不要把“北京时间字符串”当作时区模型。
常用时间函数和运算如下:
sql
select current_date,
current_time,
current_timestamp,
localtime,
localtimestamp;
select extract(year from enrolled_at) as enrolled_year,
extract(month from enrolled_at) as enrolled_month
from enrollment;
select current_date - date '2026-01-01' as elapsed_days;
select current_timestamp + interval '7 days' as trial_expires_at;两个日期相减可得到天数或间隔;时间点加减 interval 得到新的时间点。不同数据库对日期相减的精确返回类型稍有不同,应在目标环境执行验证。
显式转换、格式化与空值替代
CAST 把一个值转换为另一个类型。比如外部系统把课程编号传成文本,而目标列需要整数:
sql
select cast('4201' as bigint) as course_id;
select cast(course_id as varchar(30)) as course_id_text
from course;PostgreSQL 也支持 value::type 简写,但 CAST 更容易迁移。转换失败通常会直接报错,因此批量导入时应先在暂存表验证脏数据。
格式化改变展示文本,不应反过来替代正确类型。下面把时间戳格式化为报表文本,底层列仍应保留时间戳:
sql
select to_char(enrolled_at, 'YYYY-MM-DD HH24:MI:SS') as enrolled_text
from enrollment;COALESCE 从左到右返回第一个非空值,所有参数需要能归并为兼容类型:
sql
select learner_id,
coalesce(score, 0) as displayed_score
from enrollment;这里把“尚无成绩”显示为 0 只是展示选择,可能混淆“未评分”和“确实得 0 分”。如果业务必须区分,就保留 NULL,在界面显示“待评分”。
默认值只处理省略,不处理显式 NULL
sql
create table learning_event (
event_id bigint generated always as identity primary key,
learner_id bigint not null,
course_id bigint not null,
event_type varchar(30) not null,
event_time timestamptz not null default current_timestamp,
payload jsonb
);
insert into learning_event
(learner_id, course_id, event_type)
values
省略 event_time 时才使用默认值。若显式写入 NULL,NOT NULL 会拒绝,而不是自动替换为当前时间。默认值是写入便利,不是历史数据修复机制。
大对象与流式访问
长文本和二进制对象需要与普通短字段区别对待。SQL 概念上把大字符对象称为 CLOB,把大二进制对象称为 BLOB。不同数据库使用的具体类型名不同;PostgreSQL 常用 text 保存大文本、bytea 保存二进制,也提供独立 large object 机制。
sql
create table course_asset (
asset_id bigint generated always as identity primary key,
course_id bigint not null references course(course_id),
asset_name varchar(160) not null,
mime_type varchar(100) not null,
binary_content bytea,
transcript_text text
);多兆字节乃至更大的对象不适合每次随结果整块载入内存。应用接口通常先取得 locator、对象标识或流,再分块读取。真实系统也常把文件放在对象存储中,只在数据库保存 URL、大小、摘要和权限信息。选择哪一种方案,要同时评估事务一致性、备份、访问控制和传输开销。
用有效时间保存历史
只保存“当前课程价格”会丢失历史。可以为每个价格记录增加有效区间:
sql
create table course_price_history (
course_id bigint not null references course(course_id),
price numeric(10, 2) not null check (price >= 0),
valid_from date not null,
valid_to date,
primary key (course_id, valid_from),
check (valid_to is null or valid_to > valid_from)
);
valid_from 与 valid_to 表达业务事实何时有效,不等同于数据库何时写入这行。某些数据库提供原生时间段和“as of”查询扩展;没有这些扩展时,也能用范围列与约束实现。
用户定义类型与域
两个字段底层都是 numeric(12,2),也不代表它们可以随便相加。美元和积分、价格和折扣率在业务上属于不同概念。SQL 的用户定义 distinct type 思想是创建强区分的新类型:即使底层表示相同,也不能直接赋值或比较,必须显式转换。这样可以在执行前发现混用。
域更像“带公共规则的基础类型”。PostgreSQL 可以直接运行:
sql
create domain nonnegative_money as numeric(12, 2)
constraint nonnegative_money_check
check (value >= 0);
create domain course_state as varchar(12)
constraint course_state_check
check (value in ('draft', 'active', 'archived'));
create table
域可以携带 CHECK、NOT NULL 或默认规则,并复用于多列;它通常仍与底层类型兼容,不提供 distinct type 那么强的隔离。不同数据库对 CREATE TYPE 和 CREATE DOMAIN 的支持差异很大,迁移前要确认实际语法。
让数据库生成唯一键
人工执行“先查最大编号再加一”在并发下会产生重复,也会扫描不必要的数据。identity 列让数据库原子地产生新值:
sql
create table instructor (
instructor_id bigint generated always as identity primary key,
instructor_name varchar(60) not null
);
insert into instructor (instructor_name)
values ('陈沐')
returning instructor_id;GENERATED ALWAYS 不允许普通插入自行指定值;GENERATED BY DEFAULT 允许显式覆盖,适合数据迁移但更容易误用。序列是独立计数器,可跨表使用:
sql
create sequence global_actor_id start with 10000 increment by 1;
select nextval('global_actor_id');序列保证取出的值唯一递增,但事务回滚后通常不会把已取出的值退回,因此键出现空洞是正常现象。代理键的职责是稳定标识,不应被当作连续业务流水号。
复制表结构与固化查询结果
创建相同结构的临时工作表时,可以复制表定义:
sql
create table enrollment_stage
(like enrollment including all);把查询当前结果固化成一张新表,可以使用 CREATE TABLE AS:
sql
create table completed_enrollment_snapshot as
select *
from enrollment
where status = 'completed';新表保存创建那一刻的结果,以后不会跟着基础表变化;视图则在查询时反映当前结果。不同产品对复制索引、约束、默认值和数据的默认行为不同,使用 LIKE 时要明确包含哪些对象。
目录、模式与连接环境
数据库对象需要层次化命名。通用模型是:
catalog.schema.object
目录位于最上层,模式位于目录内,表、视图、索引等对象位于模式内。有些产品把 catalog 称为 database,也有产品不支持跨目录查询。连接建立后,会话具有当前用户、默认目录和默认模式,未限定名称按当前环境解析。
sql
create schema analytics;
create view analytics.active_course as
select course_id, course_title
from public.course
where course_status = 'active';
select *
from analytics.active_course;完整限定名能避免同名冲突,也便于让生产、测试和分析对象分开。course、public.course 与更完整的三段名是否等价,取决于当前连接的默认目录和模式。
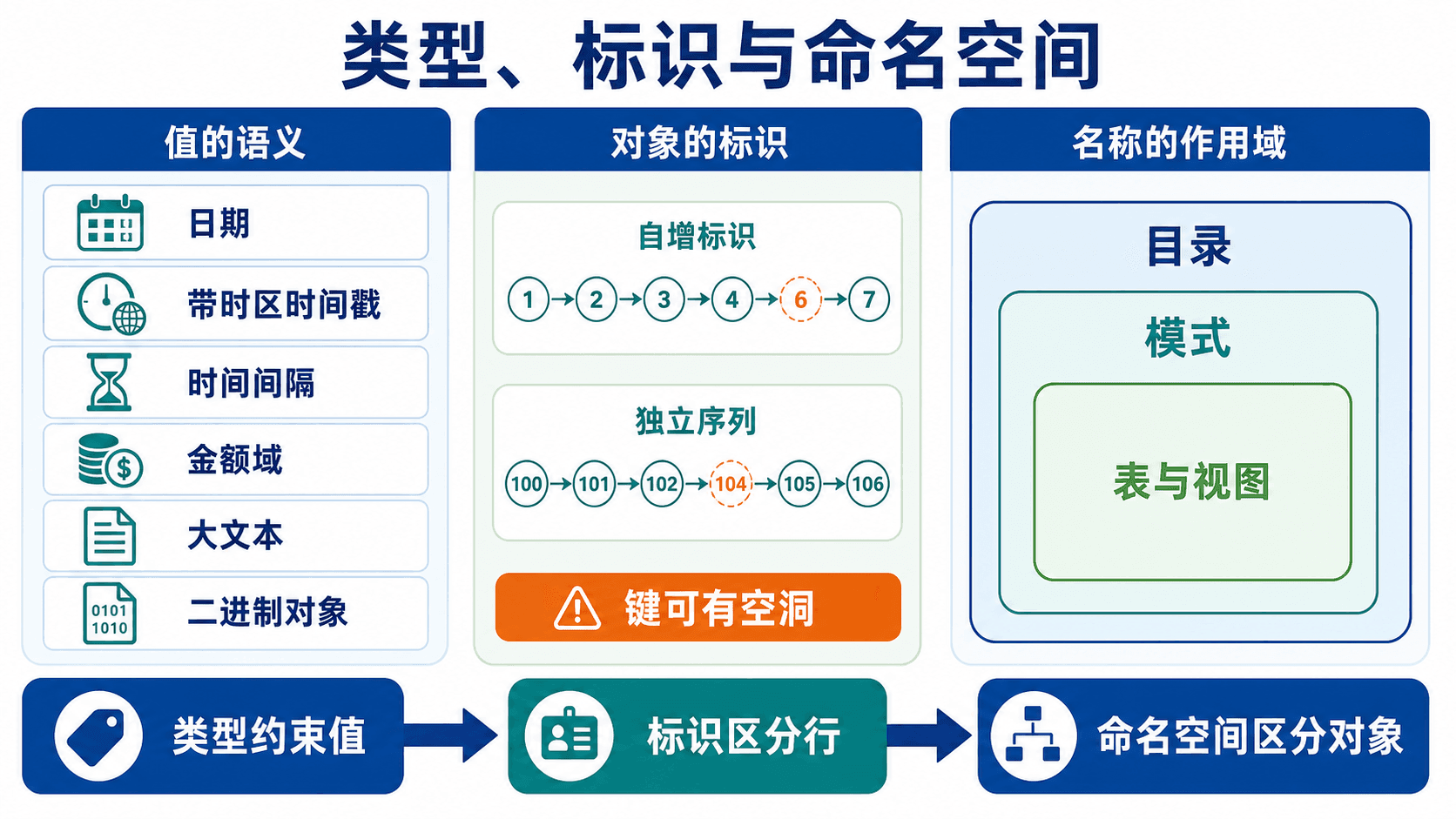
类型约束单个值的语义,生成机制负责标识,模式和目录负责对象名称的作用域。
5
跨时区平台要记录作业提交的真实发生时刻,哪种设计最稳妥?
让索引服务真实查询而不是堆积结构
索引是额外维护的数据结构,帮助数据库快速定位满足搜索键的行。没有索引时查询仍应返回正确结果,只是可能需要扫描整张表。因此索引属于物理设计,不改变关系的逻辑含义。
定义、使用与删除索引
课程列表经常按状态和发布时间筛选:
sql
create index idx_course_status_publish
on course (course_status, published_at);优化器发现查询能从索引受益时会自动选择它,应用不需要在普通 SQL 中手工“调用索引”:
sql
select course_id, course_title, published_at
from course
where course_status = 'active'
and published_at >= timestamptz '2026-01-01 00:00:00+08'
order by published_at;索引不再需要时,应通过名字删除:
sql
drop index idx_course_status_publish;CREATE INDEX 和 DROP INDEX 的基本形式被广泛支持,但索引类型、在线创建、并发创建和聚簇方式属于具体产品能力。
常见物理结构包括适合范围查找的 B 树和适合等值查找的哈希索引;有些系统还允许把表数据按某个索引键聚簇存放。选择这些能力前应先观察查询计划,而不是根据名称猜测收益。
复合索引的列顺序
复合索引 (course_status, published_at) 先按状态组织,再按发布时间组织,适合先限定状态、再筛时间的查询。只按 published_at 搜索时,它未必是最佳索引。列顺序应来自真实谓词、排序和数据分布,不是把查询中出现的所有列机械放进去。
主键和唯一约束通常会由数据库创建支持性索引,但“约束”表达数据规则,“唯一索引”是物理实现手段。两者概念不同:
sql
create unique index uq_course_slug
on course (course_slug);创建唯一索引时,现有重复数据会让操作失败;创建成功后,后续重复写入也会失败。如果目标只是声明业务唯一性,优先使用 UNIQUE 约束,让意图更明确。
索引也有写入成本
每次插入、删除或更新索引列,数据库都要同步维护索引。索引还占用磁盘、缓存和备份空间。给低选择性列单独建很多索引,可能没有明显查询收益,却持续拖慢写入。
评估一个索引时至少检查:
- 查询是否高频,过滤后是否只读取表中较小比例的行。
- 搜索键列顺序能否匹配常见谓词与排序。
- 该表读多写少还是写入密集。
- 是否与已有索引重复或前缀高度重叠。
- 索引是否用于高效验证主键、唯一键或外键相关操作。
6
索引是查询正确性的必要条件;没有索引时,WHERE 查询可能合法地返回不同结果。
按最小权限组织用户、角色与对象
授权回答的是“谁可以对什么对象执行什么动作”。完整性约束防止有权限的人意外写坏数据,授权则防止没有权限的人读取或修改数据;两者解决的问题不同。
分开授予读、写、改、删
SQL 常见对象权限包括 SELECT、INSERT、UPDATE 和 DELETE:
sql
grant select on course to content_reader;
grant insert on course to content_editor;
grant insert (course_code, course_title, price)
on course
to content_editor;
grant update (course_title, price, course_status)
on course
to content_editor;
grant delete on course_draft to content_admin;列级 UPDATE 让编辑者只能修改标题、价格和状态,不能修改课程所有者等敏感列。部分产品也支持列级 SELECT 或 INSERT;更通用的列隐藏办法是创建只暴露允许列的视图,再只授予视图查询权。
列级 INSERT 只允许语句显式提供获准列,其他列必须能使用默认值或 NULL。ALL PRIVILEGES 可以一次授予对象支持的全部权限,但除管理员维护场景外,逐项授权更容易审计。
PUBLIC 代表所有当前和未来用户。把权限授予 PUBLIC 影响范围很大,应只用于真正公开的数据:
sql
grant select on public_course_catalog to public;撤销权限使用 REVOKE:
sql
revoke update (price)
on course
from content_editor;对象创建者通常拥有该对象的全部权限。数据库管理员还可以管理用户、角色、结构和全局策略。
用角色复用权限集合
不要为每位新员工重复执行几十条授权。先创建角色,把权限授给角色,再把角色授给用户:
sql
create role content_reader;
create role content_editor;
create role content_manager;
grant select on course, category to content_reader;
grant content_reader to content_editor;
grant insert, update on course to content_editor;
grant content_editor to content_manager;
grant delete on course to content_manager;
grant content_editor content_editor 继承 content_reader,content_manager 又继承前两级。用户的有效权限包括直接授予的权限,以及通过角色链继承的权限。角色层次不宜过深,否则很难回答“这个用户为什么有权限”。
共享一个“编辑员账号”会丢失执行人身份,审计记录无法区分具体的人。正确做法是每人使用自己的账号,通过角色取得相同能力。
视图、模式与引用权限
用户查询视图时不一定需要直接查询基础表;系统应先根据视图边界检查用户权限,再在内部展开定义。视图创建者只能把自己拥有的能力安全封装出去,不能凭空扩大权限。
sql
create view finance_course_income as
select course_id,
sum(amount) as paid_amount
from payment
group by course_id;
grant select on finance_course_income to finance_reader;模式所有者通常负责在模式中创建、修改和删除对象。创建外键还会限制被引用表未来的删除和更新,因此 SQL 设计了 REFERENCES 权限:
sql
grant references (course_id)
on course
to integration_builder;如果任何人都能随意让自己的表引用 course.course_id,课程表的删除就会被他们创建的约束阻挡,所以“只创建一条外键”也需要明确授权。
函数与过程的执行权限
函数或存储过程可以封装查询和修改。用户需要 EXECUTE 权限才能运行:
sql
grant execute on function
calculate_course_progress(bigint, bigint)
to learner_app;定义者权限模式下,函数以创建者的权限访问内部对象,适合封装受控操作,但必须防止参数注入、不安全的对象搜索路径和越权逻辑。调用者权限模式下,函数使用调用者自己的权限,适合通用工具。不同数据库使用 SECURITY DEFINER、SECURITY INVOKER 或类似语法表示。
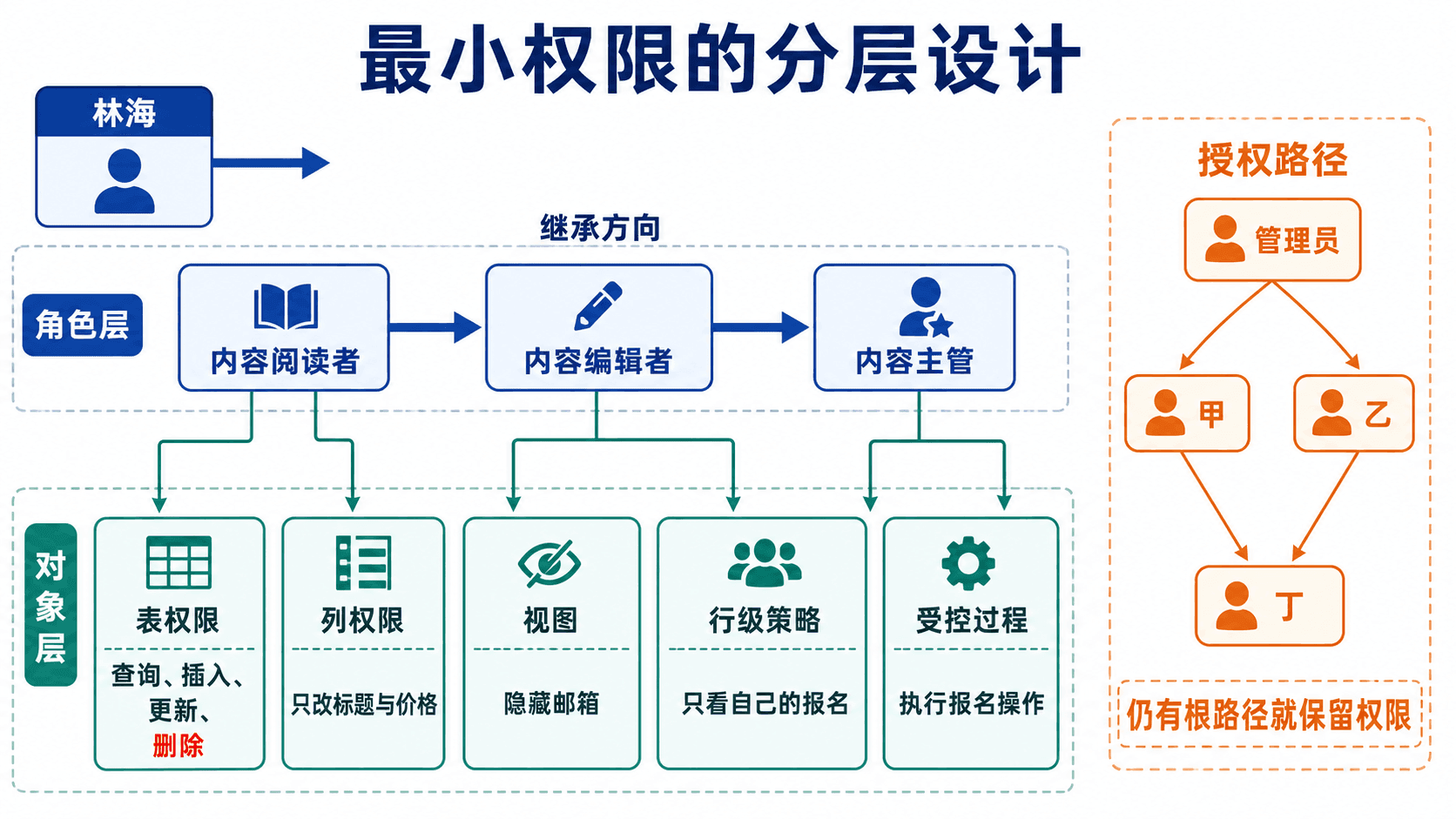
用户通过角色取得对象权限;视图、列级授权和受控函数继续缩小可见数据与可执行动作。
7
内容编辑员只应修改课程标题和价格,不应改课程所有者。哪些设计符合最小权限原则?
从授权图推导回收与细粒度访问
授权不只是“管理员直接给用户一条权限”。当接收者带着 WITH GRANT OPTION 把权限继续传下去时,系统会形成授权图。回收某条边时,必须重新判断每个用户是否仍能从权限根节点获得一条有效路径。
传递权限与授权图
sql
grant select on course
to user_a
with grant option;
-- user_a 执行
grant select on course
to user_b
with grant option;图中的节点是用户或角色,边表示“谁把某项权限授给谁”。只有从对象所有者或管理员这个根节点可达的节点才真正保有权限。两个用户互相授予不能凭空制造根路径;上游授权全部被撤销后,环上的权限也会消失。
一个用户可能从多条路径获得同一权限。管理员撤销 user_a 的授权时,经 user_a 唯一到达的下游用户会失去权限;若某人同时还有 user_c 提供的路径,则继续保留。
CASCADE、RESTRICT 与只回收授权能力
级联回收会移除因这次撤销而失去全部根路径的下游授权:
sql
revoke select on course
from user_a
cascade;RESTRICT 在发现会引发下游回收时拒绝当前操作,让管理员先显式处理依赖:
sql
revoke select on course
from user_a
restrict;有时只想禁止 user_a 继续转授,但仍允许他查询:
sql
revoke grant option for select
on course
from user_a;部分数据库不支持这条精细语法,需要先撤销权限,再不带授权选项重新授予。
下面的授权图实验器模拟管理员分别撤销 U1、U2 的直接授权。U5 同时拥有两条路径,因此只撤销一侧时仍然可达。
用角色作为稳定授权者
如果部门主管以个人身份把编辑角色授给同事,主管离职并被回收权限时,可能连带影响下游。更稳定的做法是让当前会话激活“部门主管”角色,并让授权记录的授予者是角色:
sql
set role content_manager;
grant content_editor
to user_chen
granted by current role;这样人员更替时,只需更换谁拥有 content_manager;由该角色发出的组织性授权不会依赖某个自然人的账号。具体 GRANTED BY CURRENT ROLE 支持情况因数据库而异,但设计原则一致:长期组织权限应归属于角色。
行级、列级和受控执行
表级 SELECT 往往太宽。学习者只能看自己的报名记录,可以使用 PostgreSQL 行级安全策略:
sql
alter table enrollment enable row level security;
create policy learner_reads_own_enrollment
on enrollment
for select
to learner_app
using (
learner_id = current_setting('app.learner_id')::bigint
);数据库会把策略谓词附加到查询中。应用必须以可信方式设置会话变量,连接池复用前也必须清理。行级过滤还会改变聚合语义:用户执行 avg(score) 得到的是自己可见行的平均值,不是整张表的平均值。界面和接口应明确数据范围。
列级权限可用 GRANT SELECT (col1, col2)(目标产品支持时)或投影视图实现。受控写入可用存储过程配合 EXECUTE。选择时可按三层判断:
- 只需要隐藏列:优先列授权或视图。
- 同一张表的不同用户只能看到不同行:使用行级策略。
- 修改包含多步校验或需要有限的高权限:使用受控函数或过程,严格审查定义者权限。
8
管理员撤销 U1 的权限后,U5 还保留一条来自 U2 的有效授权路径。级联回收的正确结果是什么?