从 LeNet 到 ResNet:读懂经典卷积网络的设计取舍
如果只把经典 CNN 记成一串名字,很容易得到一条失真的时间线:网络越来越深,准确率越来越高。真正值得学的不是年份和榜单,而是研究者每次遇到了什么约束,又用什么结构把约束绕开。
LeNet-5 把局部连接和权重共享变成了可训练的识别系统;AlexNet 把大规模数据、GPU 和一组有效的训练方法接到一起;VGG 用重复的小卷积核控制设计变量;Inception 把多尺度特征和计算预算放进同一个模块;ResNet 则正面处理“更深的网络反而更难优化”的退化问题。
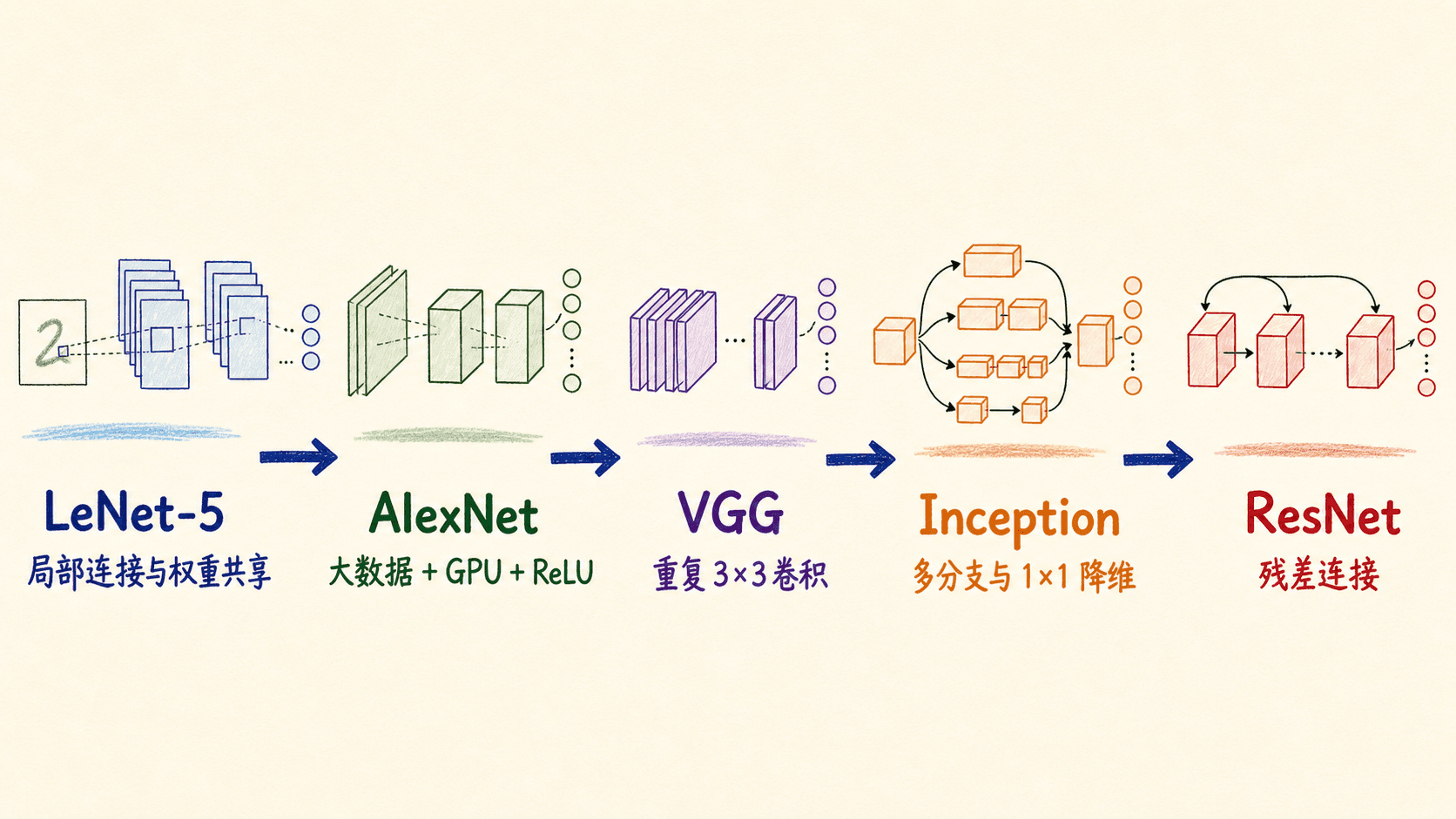
这条路线并没有告诉我们“旧模型一定差、新模型一定好”。它更像一组工程样本:面对数据、显存、计算量、优化难度和部署延迟时,架构应该怎样做取舍。读完这一节,你应该能从张量形状、参数量、计算量和梯度路径四个角度解释一张网络结构图,也能更稳妥地使用预训练模型。
本节出现的层数、错误率和参数量都保留其具体口径。论文中的单模型、模型集成、验证集、测试集、Top-1 与 Top-5 不是同一个指标,不能拿出两个数字直接比较,更不能据此写出“某模型超越人类”一类没有限定条件的结论。
先用四本账看架构
看一个 CNN,我建议先别急着背层名,先对四本账。
第一本是形状账。二维卷积的单个空间维度满足:
这里 是卷积核大小, 是步幅, 是 padding, 是 dilation。宽度用同样的公式计算。只要空间尺寸或通道数变化,后面的相加、拼接和全连接层输入都要跟着变。
第二本是参数账。普通二维卷积若使用偏置,参数量为:
参数量不随输入图像的高宽变化,因为同一组卷积核会在所有位置共享。第三本是计算账。若把一次乘加记为一次 MAC,单层的大致 MACs 为:
有的工具把一次乘法和一次加法分别算作一次 FLOP,于是会报告约 。比较模型前必须确认工具使用的口径、输入尺寸和是否计入偏置、激活等操作。
第四本是感受野账。设第 层的理论感受野为 ,相邻特征在输入上的间距为 ,则:
从 开始逐层递推,就能知道一个深层位置理论上能看到多大范围。理论感受野只是结构上“可能影响”的范围;实际贡献通常集中在中心区域,不能把两者混成一个概念。
1
输入通道为 32、输出通道为 64、卷积核为 3×3,且使用偏置时,这一卷积层有多少个参数?
2
两个工具报告的 GFLOPs 不同,就一定说明其中一个实现有错误。
LeNet-5:局部连接如何成为完整系统
1998 年的论文《Gradient-Based Learning Applied to Document Recognition》讨论的不只是一个孤立分类器,而是一套把字符识别、文档分析和梯度学习连起来的系统。LeNet-5 是其中最常被引用的卷积网络实例。
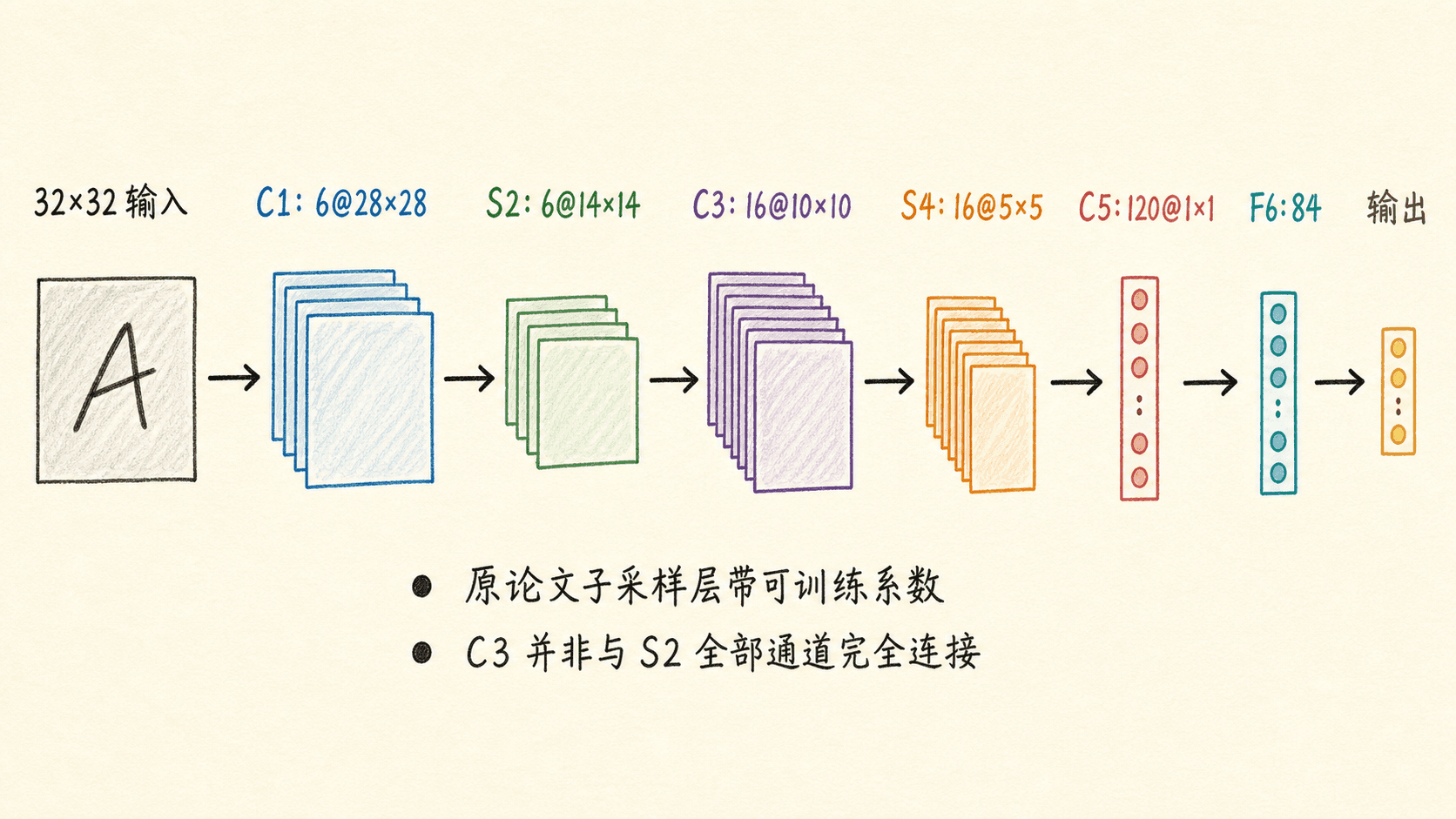
从 灰度输入开始,原始结构可以写成:
text
32×32 输入
→ C1:6 个 5×5 卷积特征图,得到 6@28×28
→ S2:2×2 子采样,得到 6@14×14
→ C3:16 个 5×5 卷积特征图,得到 16@10×10
→ S4:2×2 子采样,得到 16@5×5
→ C5:120 个 5×5 卷积特征图,得到 120@1×1
→ F6:84 个单元
→ 输出层今天的教材常把 S2、S4 直接写成平均池化,把 C5 和 F6 都写成全连接层。这样实现便于教学,但要知道它与原论文并不完全相同。原始子采样层先对 区域求和,再乘以可训练系数、加偏置并通过非线性函数。C3 也没有让每个输出特征图连接 S2 的全部六个通道,而是使用了一张精心安排的稀疏连接表。这样既打破了特征图之间的对称性,也减少了当时宝贵的计算。
C5 为什么叫“卷积层”,明明输出已经是 ?因为它仍然把同一个卷积定义应用在空间位置上。只是 S4 恰好是 ,C5 的卷积核也恰好是 ,所以每个输出只剩一个位置。若输入更大,同一层仍可产生空间特征图。这一点后来影响了“把全连接层改写为卷积层”的全卷积推理思路。
原论文的输出也不是今天最常见的“线性层加 Softmax”,而是用输出向量到类别原型之间的欧氏距离构造径向基函数。现代 LeNet 教学实现通常会换成十类线性分类头和交叉熵。这样的改写适合当代框架,但复现报告里应该说明自己复现的是核心卷积结构,还是逐项遵循原论文。
LeNet-5 的关键不在于今天还要照抄 tanh、子采样或输出层形式,而在于它把三个结构先验放进了模型:局部邻域相关、同一视觉模式可出现在不同位置、逐级降采样能扩大后层看到的范围。现代 CNN 换了激活、归一化和池化方法,这三条思路仍能在架构里找到。
3
关于原始 LeNet-5,哪一项描述更准确?
4
C5 输出 120@1×1,所以它在任何输入尺寸下都等价于固定输入维度的全连接层。
AlexNet:架构、数据与硬件一起工作
AlexNet 经常被压缩成一句“更深的 CNN 赢了 ImageNet”。这样说漏掉了最有用的部分:2012 年的结果来自模型、数据处理、优化方法和 GPU 实现共同配合。
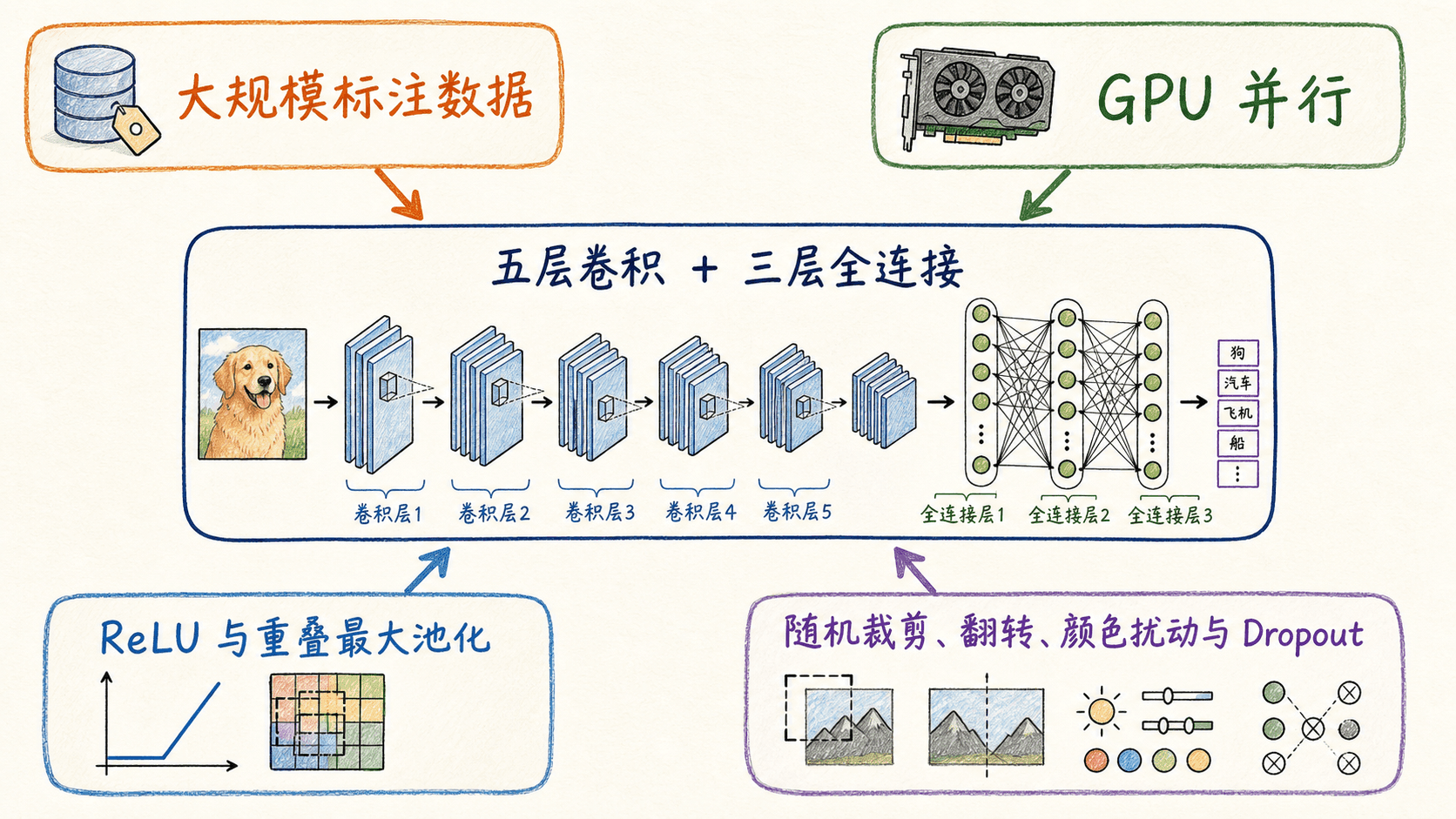
论文中的网络有五个卷积层和三个全连接层,约六千万参数。前几层使用较大的卷积核和步幅,后面逐渐转向更小的卷积核。ReLU 替代了当时常见的饱和激活,使正区间的梯度路径更直接;重叠最大池化让池化窗口的步幅小于窗口大小;局部响应归一化出现在原始网络中,但它后来并没有成为现代 CNN 的必需组件。
显存约束直接进入了架构。原论文把网络分到两块 GPU 上训练,并对部分层限制跨 GPU 的连接。今天在单卡上复现时,框架实现通常会移除这种分组方式,输入尺寸和层细节也可能不同。所以“torchvision 里的 AlexNet”应理解为一个可用实现,不宜逐层当作论文版的字面复制。
过拟合由两类方法缓解。输入端从缩放后的图像中随机取训练裁剪并做水平翻转,还使用基于 RGB 主成分的颜色扰动;分类器端在前两个全连接层使用 Dropout。测试时又会组合多个裁剪的预测。这里最容易误读的是数字口径:论文报告了 ILSVRC-2010 测试集结果,也报告了参加 ILSVRC-2012 时的模型集成结果;单模型与集成、2010 与 2012 不是同一行实验。
AlexNet 给工程实践留下的不是“所有网络都要照抄 LRN”,而是一条更可靠的判断:当一个模型取得跃迁时,先检查数据规模、训练管线、正则化、硬件实现和评估方式,再讨论某个结构部件是否单独解释了结果。
5
哪些因素确实属于 AlexNet 论文所用的训练或实现方案?
6
为什么不能把 AlexNet 论文中的所有错误率数字直接放在同一张排名表里?
VGG:用重复的小卷积核控制变量
VGG 的问题意识很清楚:如果尽量固定其他设计,只逐步增加卷积层深度,图像识别表现会怎样变化?论文比较了 11 到 19 个带权重层的多种配置,常用的 VGG-16 指 13 个卷积层加 3 个全连接层。
VGG 的卷积通常使用 核、步幅 1、padding 1,因此卷积后空间尺寸不变;若干卷积后接 、步幅 2 的最大池化。通道数从 64 逐步增加到 512,空间尺寸则逐级缩小。这样的规则性让我们容易追踪张量,也让“深度”成为更干净的实验变量。
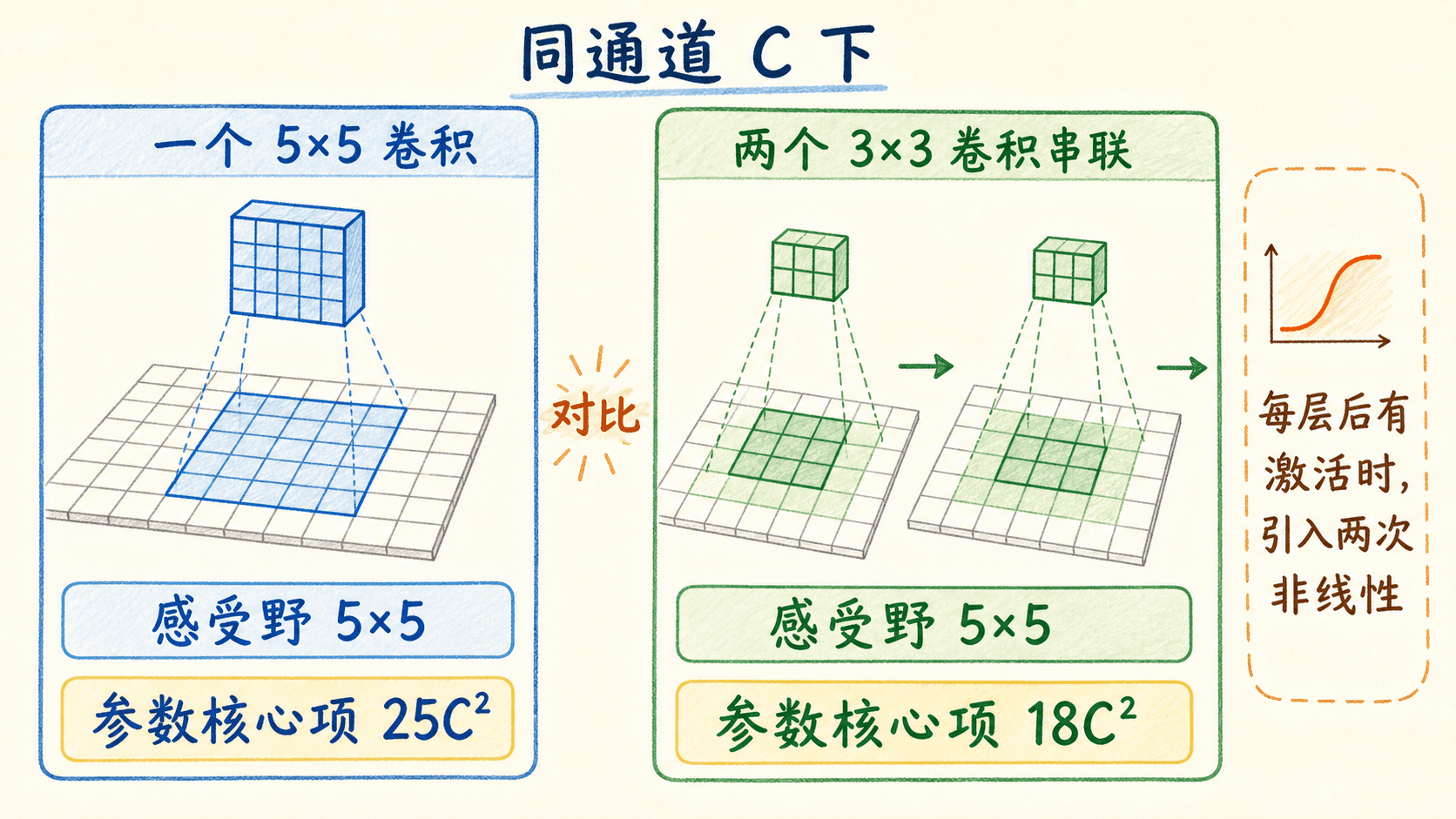
为什么连续使用 ?在步幅 1、无 dilation 的情况下,两个 卷积的理论感受野是 ,三个则是 。如果输入输出通道都近似为 ,一个 卷积的权重核心量是 ,两个 是 。后者还可以在两层之间加入非线性。
这个参数比较有前提。若两层中间通道数不同、包含归一化、偏置或分组卷积,数字会变化;输入输出形状和硬件内核也会影响真实延迟。因此“两个 总比一个 快”不是普遍定律,它只是解释了 VGG 在同通道普通卷积假设下的设计动机。
VGG-16 的代价同样明显。按 torchvision 当前实现,模型约有 1.38 亿参数,大量参数集中在分类器的全连接层,224 像素输入下报告约 15.47 GFLOPs。它的规则结构很适合教学和特征提取,但若目标是移动端延迟或显存占用,不能因为结构整齐就忽略部署成本。
7
在步幅 1、无 dilation、每层都不改变空间尺寸时,连续三个 3×3 卷积的理论感受野是多少?
8
两个 3×3 卷积在所有硬件和所有通道配置上都必然比一个 5×5 卷积更快。
Inception:先安排计算,再并行看尺度
Inception v1 的核心不只是“同时用几种卷积核”。论文更关心的是:怎样在不让计算预算失控的前提下,增加网络的深度和宽度,让不同尺度的变换在同一层共存。
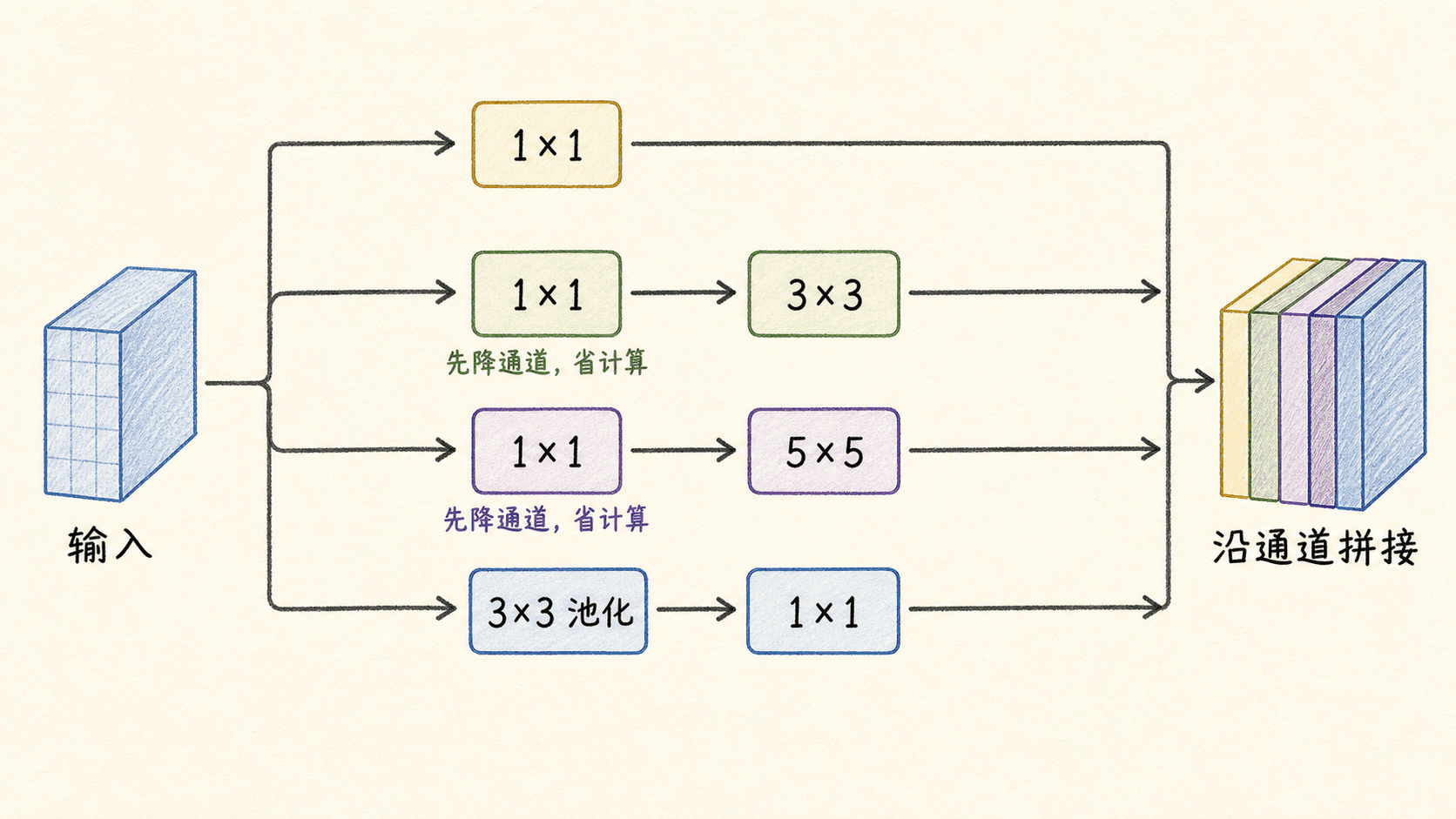
经典 Inception 模块有四条分支: 卷积; 后接 ; 后接 ; 最大池化后接 。四路输出的高宽必须一致,最后沿拼接。这里是 ,不是逐元素相加。
卷积的作用可以从成本看得很直观。假设输入为 ,目标是产生 32 个 输出通道。直接卷积约需:
如果先用 16 个 卷积把 192 通道压到 16,再做 32 个 卷积,约需:
这个例子里计算量下降接近一个数量级。 不是在空间上“看更小的物体”,它在每个空间位置混合通道,并通过输出通道数控制后续昂贵卷积的输入宽度。若后面接非线性,它还会增加一层通道变换。
GoogLeNet 把多个 Inception 模块串起来,论文按其计数方式称为 22 层。网络末端使用全局平均池化,避免像 VGG 那样依赖巨大的全连接分类器;训练时还在中段接辅助分类器,帮助较深网络传播监督信号,并带来一定正则化效果。辅助头通常不用于最终推理。
9
Inception 模块四条分支的输出通常如何合并?
10
Inception 中放在 3×3 或 5×5 卷积前的 1×1 卷积,主要用途之一是减少进入昂贵空间卷积的通道数。
ResNet:把退化问题改写成残差学习
在 ResNet 论文的 CIFAR-10 实验里,56 层普通网络的训练误差高于 20 层普通网络。因为连训练集都没有拟合得更好,这不是通常意义上的“模型太大导致验证集过拟合”,而是更深普通网络的优化退化。论文还指出,使用归一化初始化和批归一化后,前向与反向信号并非简单地全部消失,因此把问题只归结为“梯度消失”也不够准确。
残差块不直接逼近目标映射 ,而是让一组层学习 ,输出写成:
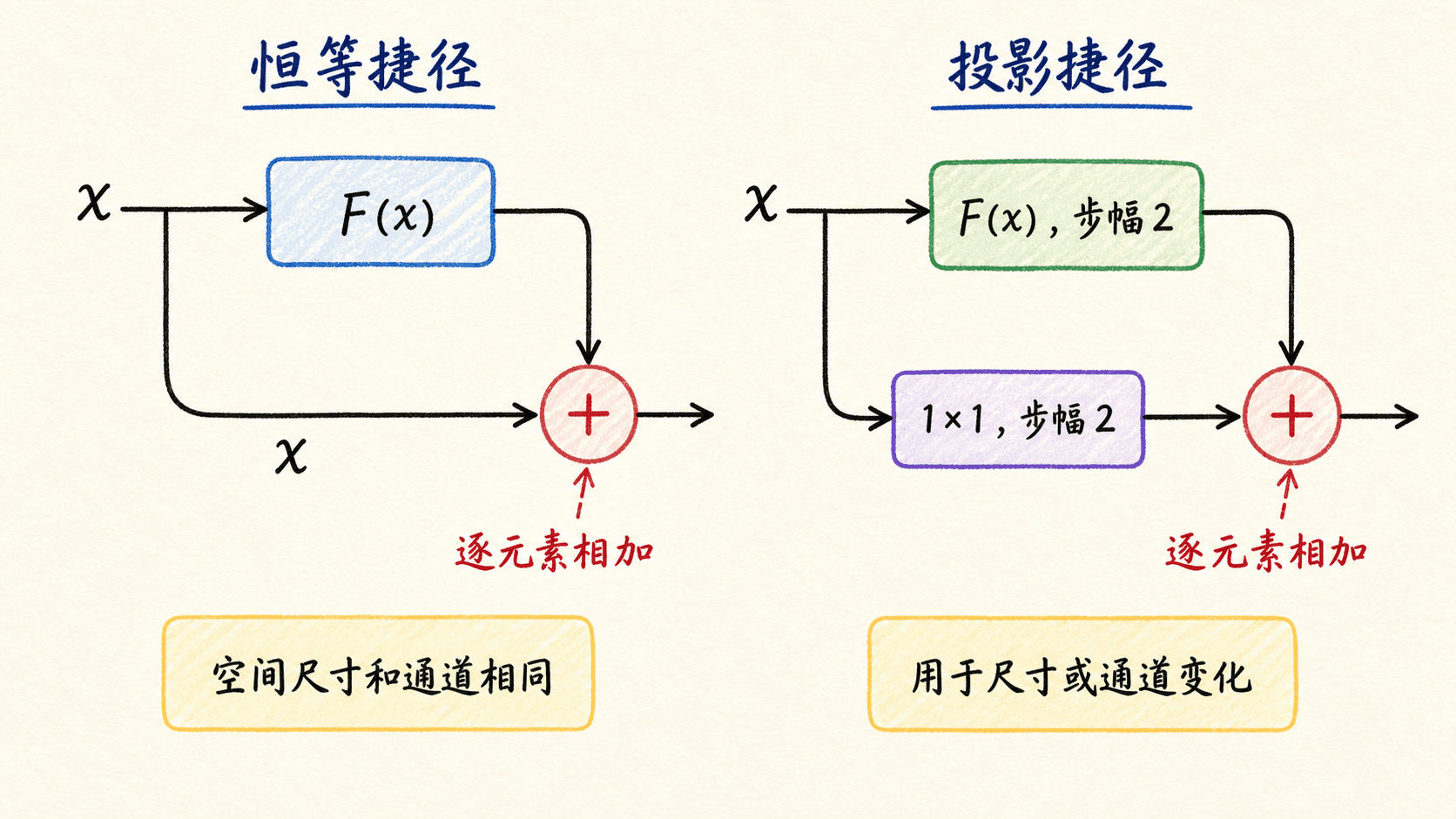
若最合适的变换接近恒等映射,残差分支只需把输出推向零附近。同时,捷径为信息和梯度提供了更直接的路径。这个解释说明了为什么残差参数化更容易优化,却不等于“残差分支学不好时网络永远无损”:激活位置、归一化、下采样和数值状态都会影响实际行为。
逐元素相加要求两个分支形状完全一致。若空间尺寸和通道数不变,可以使用没有参数的恒等捷径。若主分支通过步幅 2 下采样或改变通道数,常用 卷积投影捷径:
BasicBlock 通常使用两个 卷积,出现在 ResNet-18/34;Bottleneck 通常使用 ,先调整通道、做空间卷积,再扩展输出通道,出现在 ResNet-50/101/152。这里的“瓶颈”描述中间较窄的通道结构,不等于一定压缩整个网络的表示能力。
原论文报告 152 层残差网络在其设置下比 VGG 更深但计算复杂度更低,并以模型集成获得 ILSVRC 2015 分类任务 3.57% 的 Top-5 测试错误率。这个数字属于特定集成和比赛设置,不能直接写成单个 ResNet-152 的通用错误率,更不能脱离测试定义做“人类水平”比较。
11
输入是 56×56×64,主分支输出是 28×28×128。若要做残差相加,捷径分支最合理的处理是什么?
12
哪些说法符合 ResNet 原论文的论证?
把经典模型放回同一张预算表
下面的数字用于建立数量级直觉,不用于宣布“谁最好”。LeNet-5 的参数量按原始结构通常近似说成六万;其余参数量和计算量可参考 torchvision 在 224 像素分类输入下对具体实现的统计。论文版、框架版和训练配方可能不同。
这张表至少能纠正三个直觉错误。
第一,层数不是成本的同义词。GoogLeNet 和 ResNet 可以比 VGG 更深,却通过 瓶颈、全局平均池化等设计减少参数或计算。第二,参数量不等于推理延迟。大特征图上的小参数卷积也可能有大量 MACs;不同硬件对分组卷积、宽通道和小批量的效率也不同。第三,理论 FLOPs 不等于显存占用。训练时还要保存激活和梯度,浅而宽的高分辨率阶段可能占用更多显存。
选择骨干网络时,至少同时记录:输入分辨率、批大小、精度类型、峰值显存、目标硬件上的吞吐和延迟、参数量、任务指标。只引用一个公开 GFLOPs 数字,往往无法预测你的部署结果。
13
哪一项最能解释“ResNet-50 比 VGG-16 更深,但参数量更少”?
14
两个模型的理论 GFLOPs 相同,就能保证它们在手机和服务器 GPU 上的延迟都相同。
迁移学习:先复用,再用实验决定解冻多少
迁移学习有两种常见起点:把预训练骨干当固定特征提取器,只训练新分类头;或者用预训练权重初始化整个网络,再微调部分或全部层。PyTorch 官方教程把这两种情形分别称为 fixed feature extractor 和 finetuning。
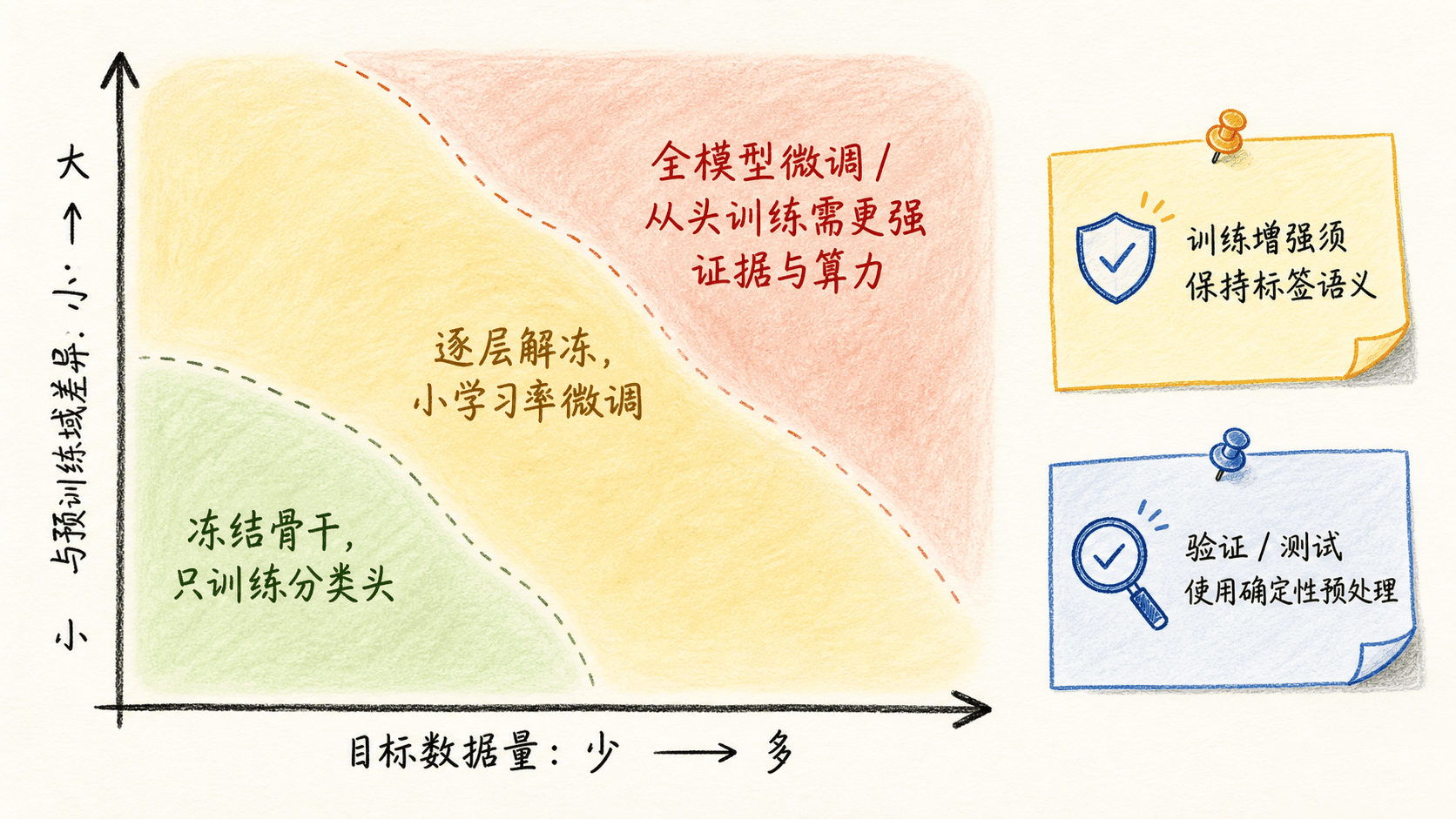
不要用“少于一千张就全部冻结、超过十万张就从头训练”这种硬阈值替你做决定。更有用的变量有四个:目标数据相对规模、与预训练域的差异、标注噪声、计算预算。自然图像细分类与 ImageNet 较接近,冻结骨干可能就是很强的起点;显微图、遥感多光谱或线稿与自然图像差异更大,后段甚至全模型微调的价值更可能增加,但仍要通过同一开发集上的受控实验确认。
现代 torchvision 使用权重枚举,而不是已经弃用的 pretrained=True。权重对象还携带匹配的推理预处理:
python
import torch
from torch import nn
from torchvision.models import resnet50, ResNet50_Weights
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights=weights)
eval_preprocess = weights.transforms()
# 先把骨干固定为特征提取器
for parameter in model.parameters():
parameter.requires_grad = False
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, num_classes)
训练新分类头收敛后,可以解冻 layer4,给预训练层更小学习率,给新分类头较大学习率:
python
for parameter in model.layer4.parameters():
parameter.requires_grad = True
optimizer = torch.optim.AdamW([
{"params": model.layer4.parameters(), "lr": 1e-4},
{"params": model.fc.parameters(), "lr": 5e-4},
], weight_decay=1e-4)这里还有一个容易漏掉的状态:把参数设为 requires_grad=False 不会自动停止 BatchNorm 更新运行均值和方差。调用 model.train() 后,BatchNorm 仍会按训练模式工作。如果你希望骨干严格保持固定,需要明确处理这些模块的训练/推理状态;如果你希望统计量适应新域,也要把它当成实验变量记录,而不是让它悄悄变化。
15
在 torchvision 的现代接口中,加载带有配套推理预处理的 ResNet-50 权重,推荐的写法是哪一个?
16
把骨干参数全部设为 requires_grad=False 后,BatchNorm 的运行均值和方差就必然不会再变化。
数据增强:变换必须保留任务语义
数据增强不是“把随机操作堆得越多越好”,它是在训练分布里写入我们愿意接受的不变性。水平翻转猫的照片通常不改变类别,但水平翻转带文字的交通标志可能改变内容;轻微颜色变化对物体类别可能合理,对病理染色定量却可能破坏诊断线索。
先划分训练、验证和测试集,再只对训练样本做随机增强。验证和测试应使用确定性的缩放、裁剪与归一化,以便不同实验在相同输入上比较。若先增强再划分,同一原图的不同变体可能进入训练和验证,形成数据泄漏。
torchvision v2 的一个基础分类训练管线可以这样写:
python
import torch
from torchvision.transforms import v2
train_transform = v2.Compose([
v2.RandomResizedCrop((224, 224), antialias=True),
v2.RandomHorizontalFlip(p=0.5),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(
mean=[0.485, 0.456, 0.406],
std
这只是起点。检测、分割和关键点任务不能只变换图像,还要同步更新边界框、掩码和关键点。类别不平衡也不能靠几何增强自动解决;应另外检查采样、损失权重和每类指标。MixUp、CutMix、RandAugment 等更强方法值得做消融,但它们改变了标签或增强分布,必须与任务语义和训练配方一起验证。
一个稳妥的增强实验顺序是:建立无增强基线;一次加入一类合理变换;记录训练损失、验证指标和典型失败样本;确认收益跨随机种子存在;最后再组合。这样才能分清提升来自哪一项,也更容易发现某个增强正在制造不可能样本。
17
哪些做法能减少数据增强引入的评估偏差或泄漏?
18
判断一个增强是否合适,最先应问什么?
从结构图到可复现实验
最后把阅读架构落到一次可复现的选择流程。
先固定任务、数据划分和指标。分类任务至少同时看总体指标、每类指标和混淆矩阵;类别不平衡时,不要只看总体准确率。
再建立一个可运行基线。使用明确版本的预训练权重及其配套预处理,记录输入分辨率、批大小、随机种子、优化器和学习率。
对形状、参数和计算做静态核对。给关键阶段打印张量尺寸,确认残差相加的两路形状一致、Inception 分支只在通道维拼接、分类头输入维度正确。
用受控实验比较冻结骨干、解冻后段和全模型微调。每次只改变一组关键因素,并记录峰值显存、训练时间和目标硬件上的推理延迟。
下面这段小工具可以快速检查各阶段输出形状。钩子只用于调试,正式训练前要移除,避免额外开销和重复输出。
python
hooks = []
def show_shape(name):
def hook(_module, _inputs, output):
print(name, tuple(output.shape))
return hook
for name in ["conv1", "layer1", "layer2", "layer3", "layer4"]:
module = getattr(model, name)
hooks.append(module.register_forward_hook(show_shape(name)))
with torch.no_grad():
_ =
19
要比较冻结骨干与全模型微调,哪种实验设计最可信?
20
如果验证误差高,继续增加网络层数通常就是最直接且最可靠的解决办法。