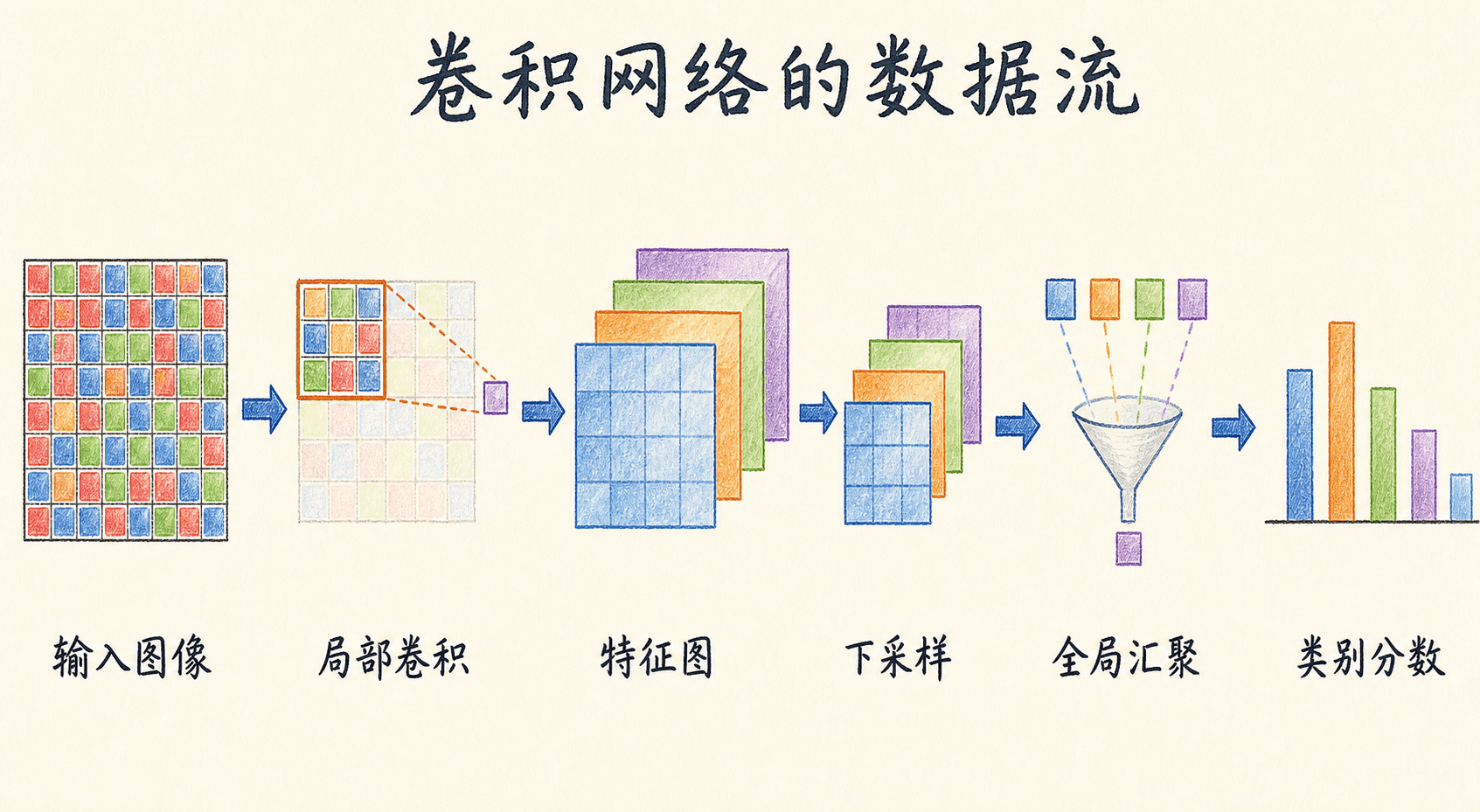
卷积神经网络:从一块局部窗口到完整的视觉模型
第一次看卷积神经网络时,人很容易把注意力全放在那个不断滑动的小方框上。可如果只记住“卷积核在图像上滑动”,很快就会在三个地方卡住:一个卷积核怎样处理 RGB 三个通道,padding、stride、dilation 到底怎样共同决定尺寸,以及网络堆深以后一个神经元究竟看到了原图多大范围。
这一篇从张量和计算出发,把这些问题连成一条线。我们会自己算一次互相关,追踪通道变化,写出通用输出尺寸公式,再把池化、参数共享、平移等变性和感受野放进同一张结构表。最后用一个可直接运行的 PyTorch 小网络检查最常见的工程错误。
深度学习框架里的 Conv2d 通常计算互相关,而不是先把卷积核翻转后再做数学卷积。训练时卷积核本来就是可学习参数,所以这种命名差异不会削弱模型的表达能力;但手算、复现传统滤波器或对照信号处理公式时,必须先约定是否翻转卷积核。
图像为什么需要一种带空间结构的线性层
先看一个朴素方案。一张 的 RGB 图像包含 个数。若把它展平后连接到 1000 个神经元,仅权重就有约 1.5 亿个。更麻烦的是,展平把“相邻像素通常有关”这件事从结构中抹掉了:左上角学到的边缘检测规则,不能直接拿到右下角复用。
卷积层把两个关于图像的假设写进了网络:
- 局部连接:一个输出位置先只读取输入中的小窗口,例如 ,不必一开始就观察整幅图。
- 参数共享:同一组窗口权重在所有空间位置重复使用,因此同一种局部模式可以在不同位置被检测。
假设输入有 3 个通道,卷积层用 64 个 卷积核。它的权重数是 ,若每个输出通道再带一个偏置,总参数量为 1792。这个数字不会随着输入从 变成 而改变。
参数少不等于计算一定少。卷积核仍要在许多空间位置执行乘加;高分辨率特征图上的小卷积,计算量也可能很大。卷积的首要结构优势是共享局部规则,计算效率还要结合输出高宽、通道数和具体实现判断。
这类先验也叫归纳偏置。它不是在宣称“自然图像永远只依赖局部信息”,而是先让网络用更省参数的方式组合局部模式,再通过堆叠层逐步汇合成纹理、部件与更大范围的证据。Goodfellow、Bengio 和 Courville 的卷积网络章节把稀疏交互、参数共享与等变表示列为卷积网络的核心动机。
小测
1
把224×224的RGB图像直接连接到1000个神经元,最直接的问题是什么?
2
卷积层参数量不随输入空间尺寸增长,因此它的计算量也与输入高宽无关。
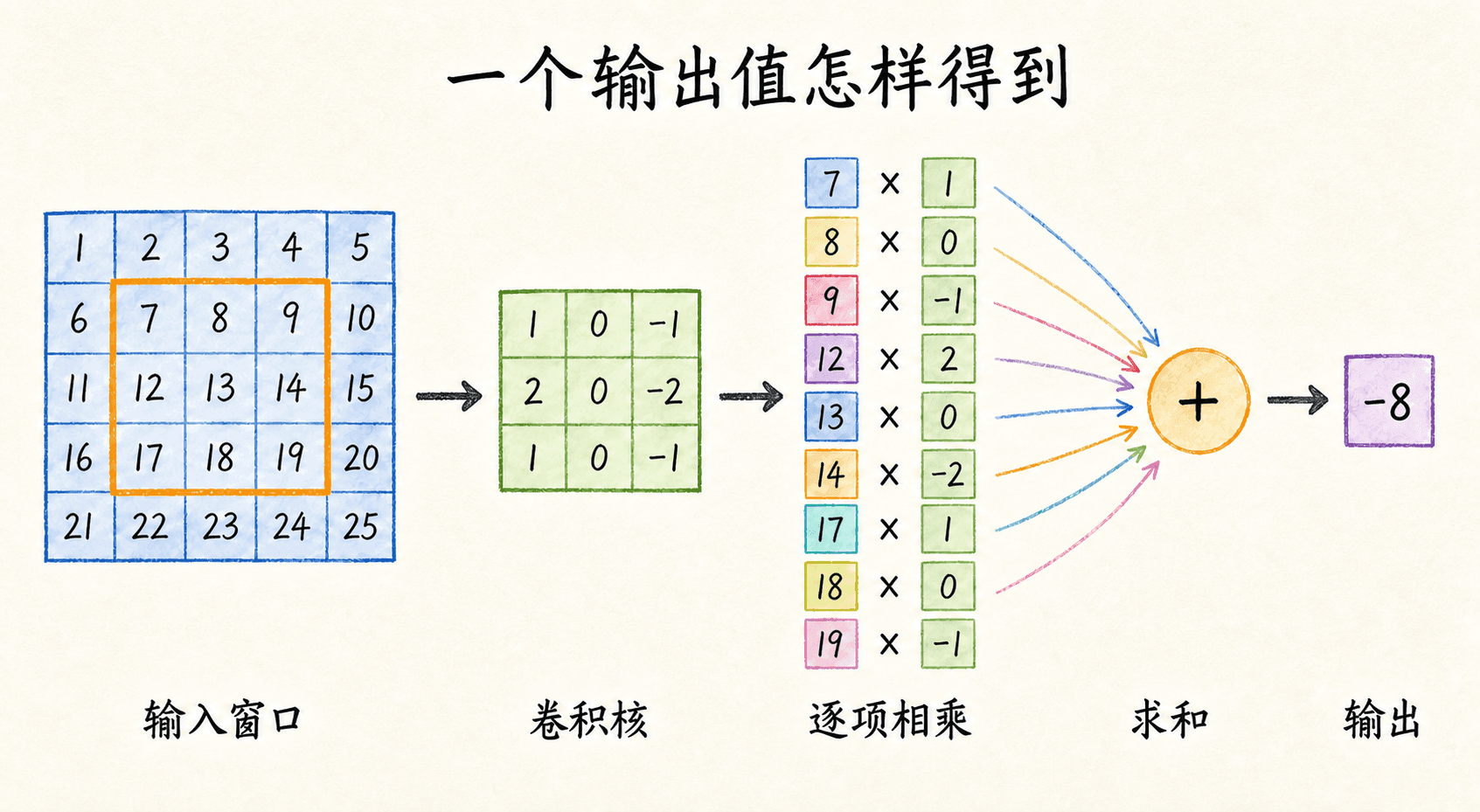
一次互相关到底算了什么
先暂时忽略批次和通道。输入是一张二维数表 ,卷积核是一张较小的数表 。在输出位置 ,我们从输入中取出与核同样大小的窗口,逐项相乘,再把结果相加:
这正是多数深度学习框架所说的二维卷积,更严格地讲是互相关。例如输入窗口与核分别是:
这个位置的输出是 。核的左列为正、右列为负,因此它会对“左侧数值大、右侧数值小”的局部变化产生较强正响应;方向相反时则可能产生负响应。
数学卷积会先在高、宽两个方向翻转 ,再做同样的乘加。若记翻转后的核为 ,则有:
当卷积核由反向传播学习时,网络可以把想要的方向直接学进权重,所以使用互相关不会少掉一类可学习模式。真正容易出错的是把一个手工给定的 Sobel 核、图像处理库和深度学习框架混在一起,却没有检查三者的翻转约定。
下面的交互实验允许你修改输入和核,逐格查看乘积;切换“翻转卷积核”后,同一组数字会按数学卷积重新计算。
在训练网络时,卷积核不必由人指定成边缘检测器。权重从初始化值出发,损失函数通过梯度告诉每个系数怎样变化。较浅层常能学到方向、颜色对比或简单纹理,但不应把“第一个核一定检测竖直边缘”当成规则;核的具体含义取决于数据、目标、初始化以及其他通道如何配合。Zeiler 与 Fergus 的卷积网络可视化研究展示了用中间激活分析模型的思路,同时也提醒我们,解释应基于实际响应而不是只看一张权重图猜名称。
小测
3
深度学习框架中的Conv2d通常与数学卷积相比少了哪一步?
4
判断一个已训练卷积核在检测什么时,哪些证据更可靠?
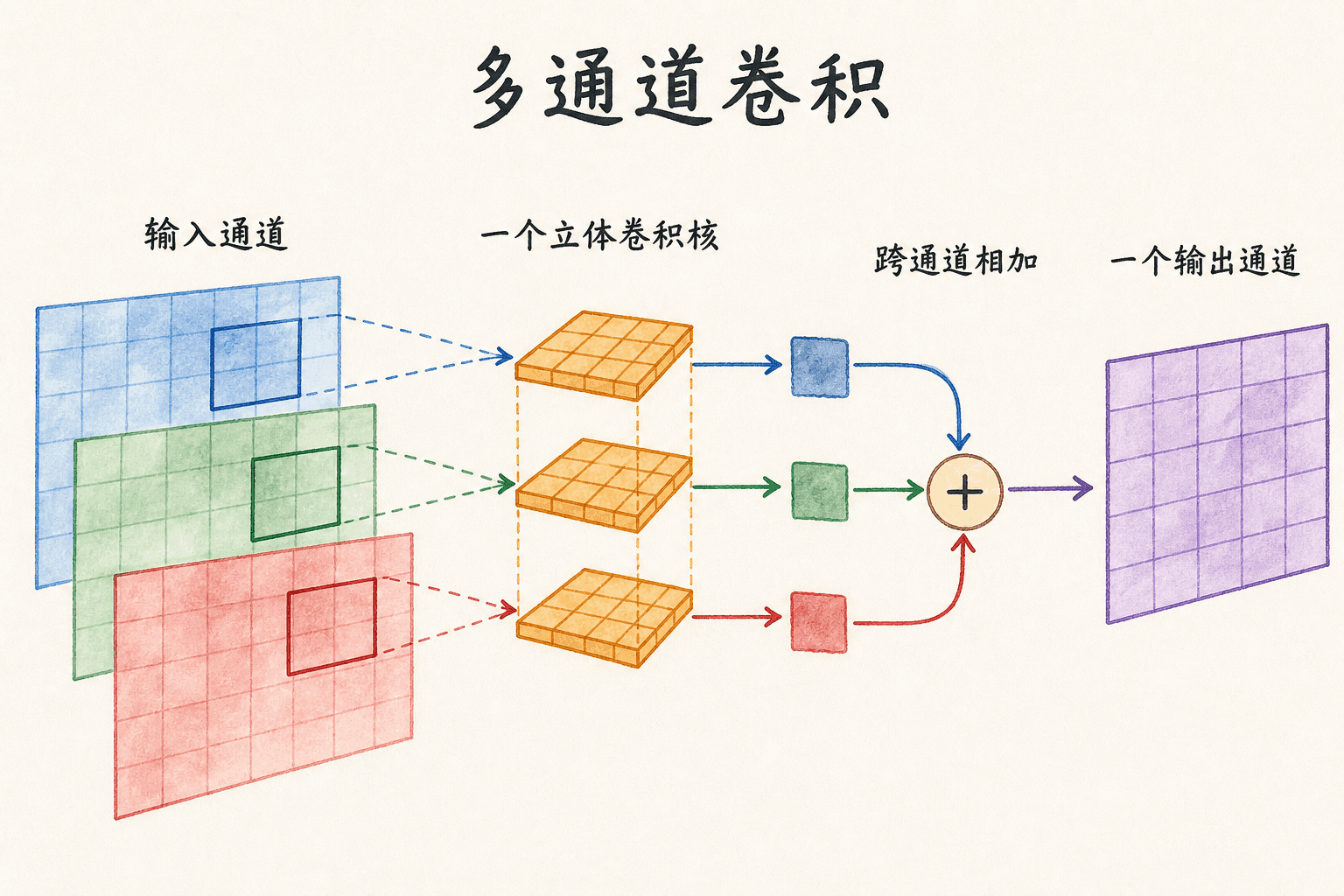
通道不是三张互不相干的灰度图
真实网络处理的是带批次和通道的张量。PyTorch 默认使用 NCHW 排列:
其中 是批次大小, 是输入通道数。一个标准二维卷积层的权重形状是:
对某一个输出通道 来说,卷积核在深度方向必须覆盖全部输入通道。它分别读取每个通道的局部窗口,再把所有乘积相加,并加上该输出通道的偏置:
一个三通道卷积核不是产生三个输出通道,而是把三个输入通道融合成一个输出特征图。想得到 64 个输出通道,就需要 64 组这样的核。于是,out_channels 的含义是“要学习多少组输出特征”,不是输入图像原来有多少种颜色。
标准卷积在 groups=1 时的参数量为:
这里 表示是否为每个输出通道使用一个偏置。批次大小和特征图高宽都不出现在公式中。
groups 会改变通道连接方式。分成 组后,每个输出通道只读取 个输入通道,权重参数量变为:
当 groups=C_in,并且输出通道数是输入通道数的整数倍时,就得到深度卷积:每个空间核只在一个输入通道内工作。它常与 点卷积配合,前者提取每个通道的空间模式,后者重新混合通道。分组并不是免费午餐;连接被限制后,参数和计算减少,但通道间的信息交换也变少。
TensorFlow/Keras 常见的默认布局是 NHWC,PyTorch 常见默认布局是 NCHW。把形状为 [N,H,W,C] 的数组直接交给期望 [N,C,H,W] 的卷积层,错误信息可能只说“输入通道不匹配”。调试时先打印每个轴的含义,不要只看四个数字。
小测
5
输入有3个通道,标准卷积层out_channels=16。一个输出位置会得到多少个数?
6
一个不带偏置的3×3标准卷积从32通道映射到64通道,参数量是 ____。
Padding、Stride 与 Dilation 要一起算
输出尺寸最容易被“背了一个简化公式”拖累。通用做法是先算卷积核在输入上真正覆盖的有效尺寸。对高方向而言,核大小为 、膨胀率为 时:
再把 padding、stride 放进输出公式:
宽方向同理:
这个形式与 PyTorch Conv2d 官方文档给出的形状规则一致。Dumoulin 与 Visin 的卷积算术指南则系统讨论了输入、卷积核、padding、stride 与输出之间的关系。
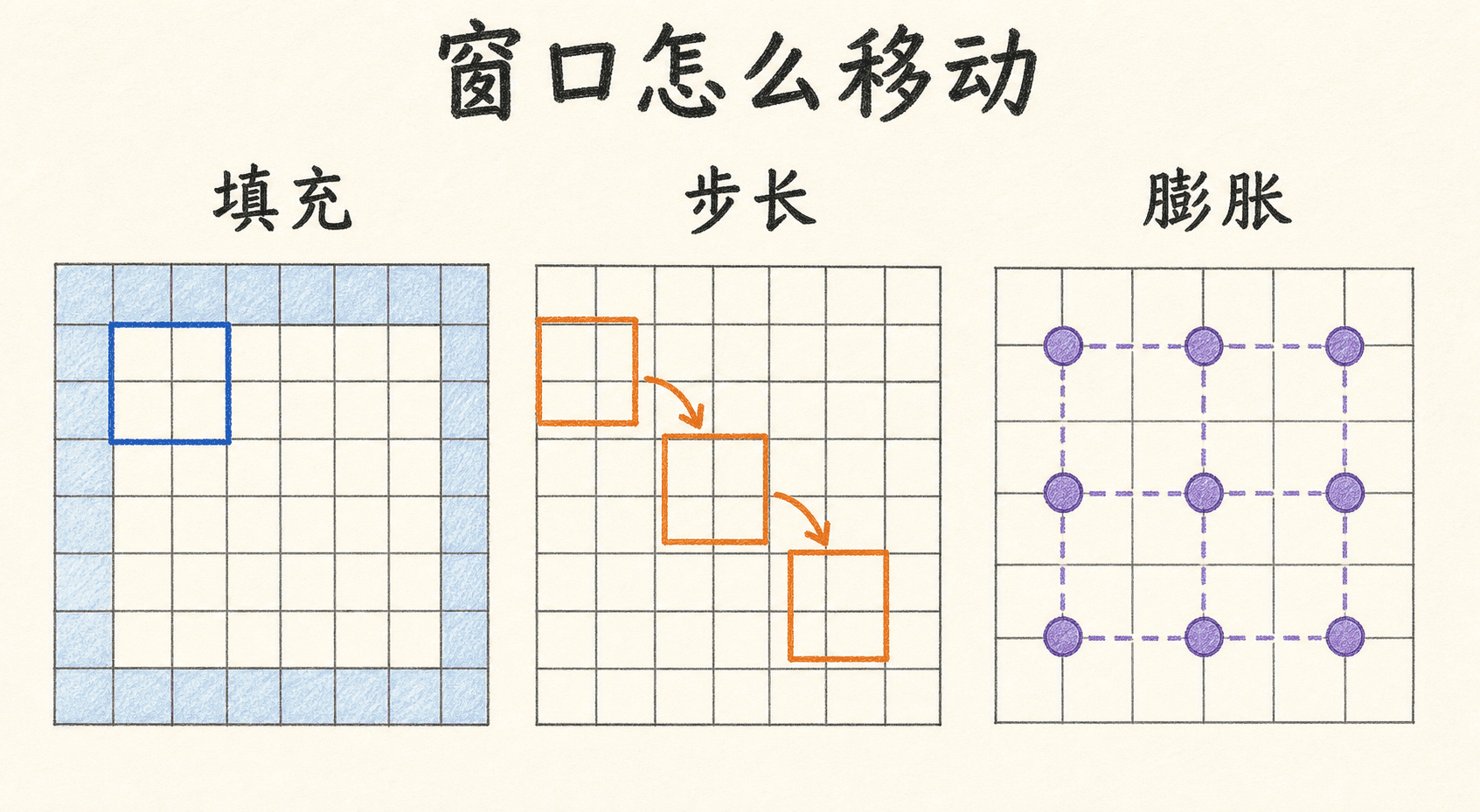
四个量可以这样理解:
padding在边界外补值,让边缘位置也能参与更多窗口;零填充最常见,但不是唯一方式。stride决定窗口起点每次跳多远。步长大于 1 会同时完成特征提取和下采样。dilation决定卷积核相邻采样点之间隔多少输入位置。它扩大覆盖范围,却不增加核参数个数。- 向下取整意味着右侧或下侧可能剩下一小段无法组成完整窗口的输入。
例如输入高宽都是 32,核为 3,padding 为 2,stride 为 2,dilation 为 2。有效核大小是 ,所以:
“same padding”也不能脱离框架和 stride 单独理解。TensorFlow 的 Conv2D 文档明确说明,padding="same" 且 stride 为 1 时输出空间尺寸与输入相同;PyTorch 的字符串 padding='same' 目前不支持 stride 大于 1。偶数有效核或 stride 大于 1 时,左右两侧所需 padding 还可能不对称,因此工程代码中最好让框架给出实际输出并做断言,而不是默认 永远成立。
小测
7
一个3×3卷积核使用dilation=2时,它的有效空间尺寸是多少?
8
输入28×28,卷积核5×5,padding=0、stride=2、dilation=1,输出高宽均为 ____。
卷积块怎样把像素变成可分类的表示
卷积本身仍是线性运算。若连续堆叠多个不带非线性激活的卷积层,它们整体仍可合并成一个线性映射,深度没有发挥预期作用。因此常见卷积块会把卷积与逐点非线性、归一化或下采样组合起来。
一种便于入门和调试的数据流是:
浅层保持较大空间尺寸,用来记录模式出现在哪里;越往后,空间尺寸通常逐步缩小,通道数逐步增加,让模型用更多特征维描述更大范围的内容。这个趋势很常见,但不是必须遵守的固定模板。分割和关键点定位等密集预测任务还要恢复或保留空间分辨率。

下面是一份可追踪尺寸的小型分类网络。AdaptiveAvgPool2d(1) 把任意空间尺寸汇成每个通道一个数,避免把全连接层输入长度写死在某个图像尺寸上。
python
import torch
from torch import nn
class TinyCNN(nn.Module):
def __init__(self, num_classes: int = 10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(
分类器返回的是 logits,不要在模型末尾先做 softmax 再交给 CrossEntropyLoss。这个损失内部会以数值更稳定的方式组合 log-softmax 与负对数似然。只有展示概率或做需要概率的后处理时,才对 logits 使用 softmax。
卷积块中也常加入 BatchNorm、GroupNorm 或残差连接。它们解决的不是“卷积算不出来”,而是训练稳定性、尺度和深层优化等问题。选择时要结合批次大小和网络结构;初学阶段先把形状、损失和基础前向传播跑对,比盲目堆组件更重要。
小测
9
示例网络使用AdaptiveAvgPool2d((1,1))的主要作用是什么?
10
使用PyTorch的CrossEntropyLoss时,模型应先输出softmax概率。
池化与下采样是在丢信息,也是在换尺度
池化在每个通道内对局部窗口做固定聚合。最大池化保留窗口中的最大值,平均池化保留均值。对窗口 ,可以写成:
池化通常没有可学习参数,但它不是“没有后果”。空间尺寸缩小后,后续层的计算和激活内存减少,同一个输出单元对应的原图范围变大;代价是精确位置信息和部分高频细节被丢掉。
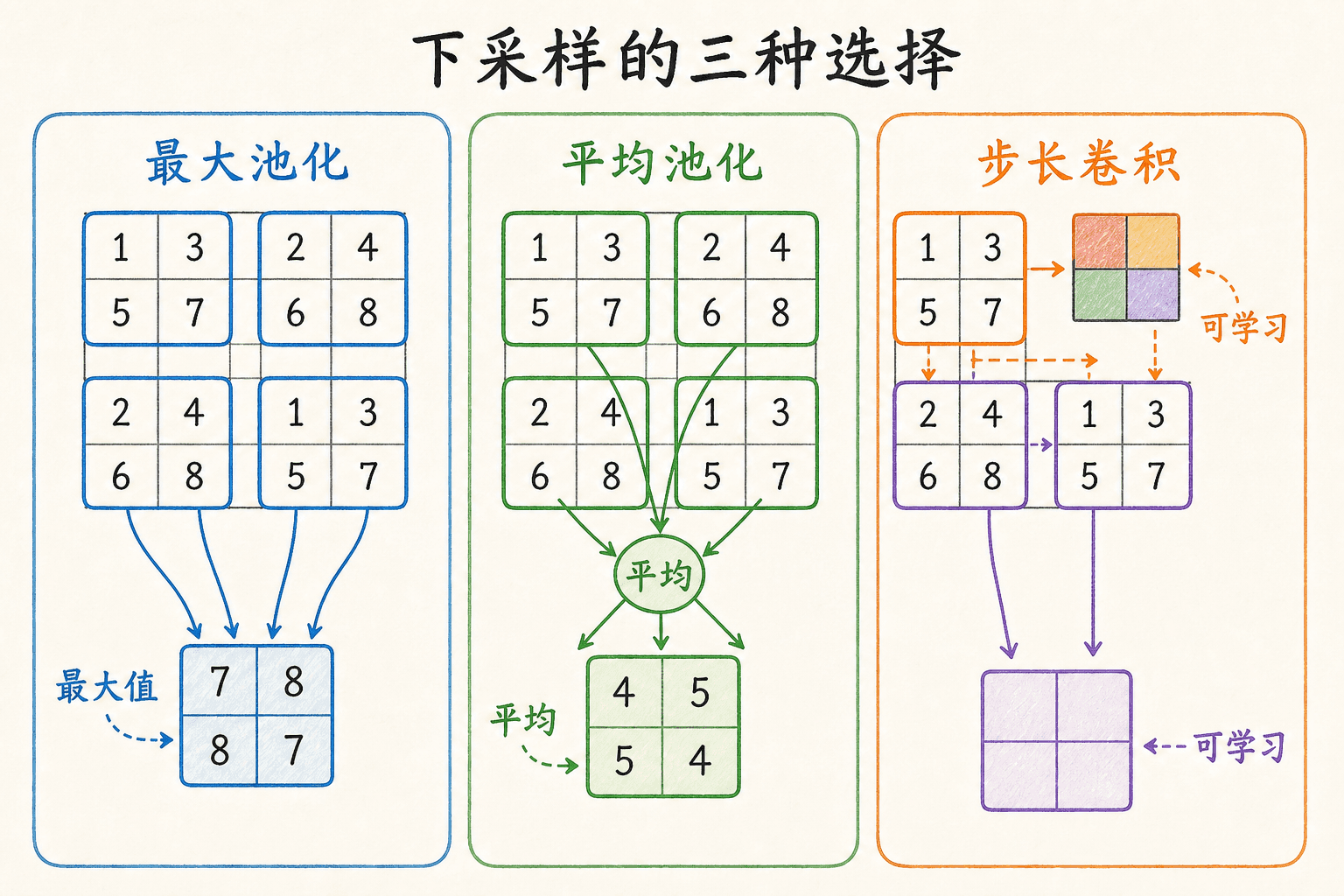
最大池化反向传播时,梯度主要流向前向窗口中取得最大值的位置;平均池化则把梯度分配给窗口里的各个位置。PyTorch 的 MaxPool2d 文档还说明了 padding、dilation 与 ceil_mode 对窗口边界和输出尺寸的影响。
很多现代网络也会使用 stride 大于 1 的卷积完成下采样。两者差别在于,池化使用固定聚合规则,而步长卷积可以学习怎样组合窗口内容。后者表达能力更强,也多了参数和训练依赖;应该通过任务与预算决定,不存在对所有数据都更好的选择。
“池化带来平移不变性”需要加条件。小幅移动如果没有改变窗口中的主导响应,池化输出可能保持稳定;但目标一旦跨过窗口边界,结果仍会变化。stride 大于 1 还会跳过采样位置,输入中的高频变化可能发生混叠。对定位、分割或小目标任务,过早、过强的下采样尤其危险。
池化不改变通道数,但步长卷积可以同时改变空间尺寸和通道数。画网络结构表时,要分别追踪 C、H、W,不能把“尺寸减半”笼统地理解成整个张量元素都只剩一半。
小测
11
对2×2、stride=2的最大池化,下列哪些说法正确?
12
只要网络用了最大池化,任意幅度的输入平移都不会改变最终输出。
参数共享带来等变性,不会自动带来不变性
同一个卷积核在各位置共享,使卷积对平移具有一种自然关系:如果输入平移,特征图中的响应也随之平移。这叫平移等变性。用平移算子 表示移动 ,理想边界条件下,stride 为 1 的卷积满足:
等变表示的是“输出跟着输入一起移动”。不变性则要求输入移动后输出完全相同:
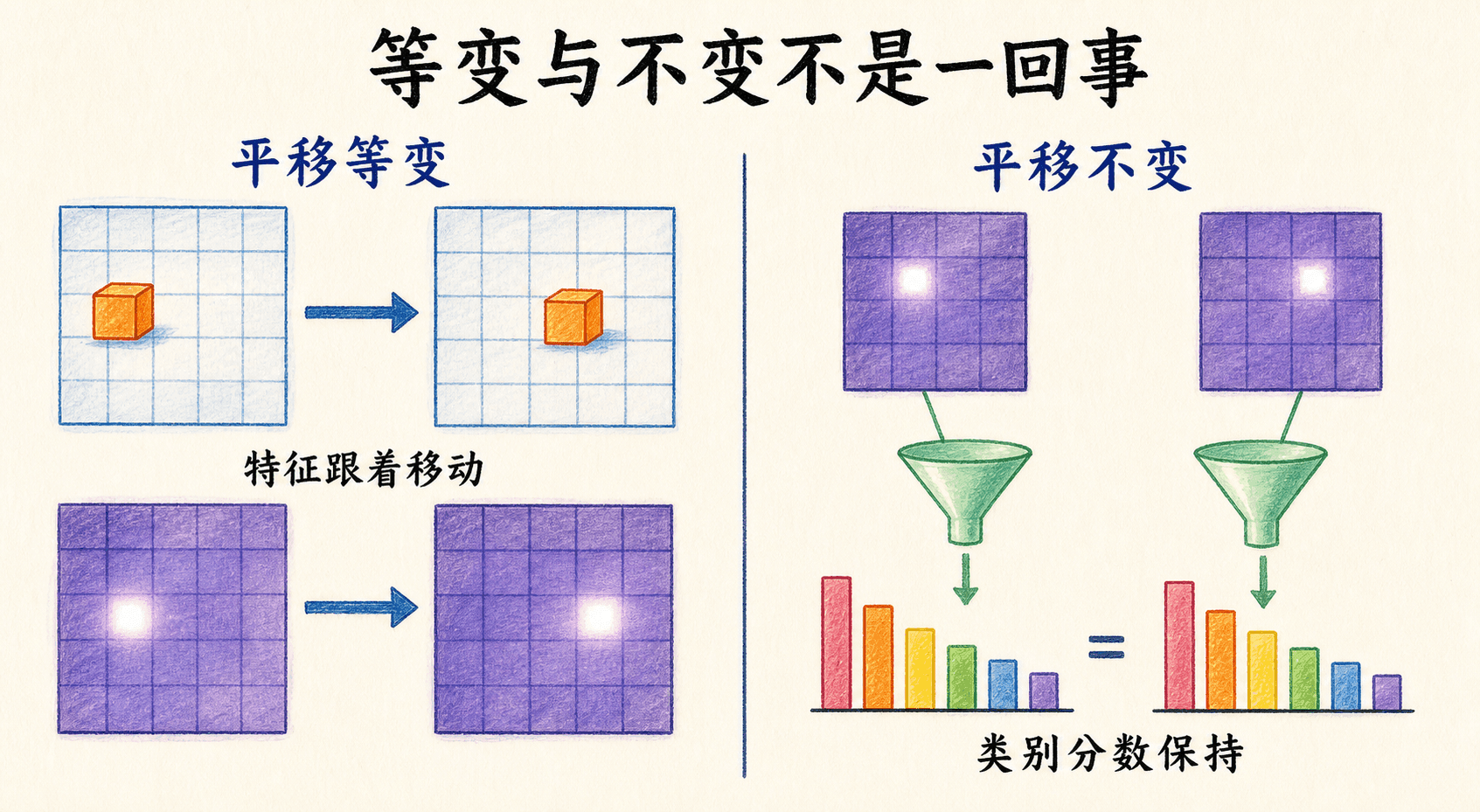
局部卷积保留位置信息,因此它更接近等变而不是不变。分类网络后面的全局平均池化会把空间位置汇总,能够为最终类别分数提供更强的平移不变倾向;检测与分割却需要知道目标在哪里,不能把空间位置全部抹掉。
实际网络也只是在一定条件下近似满足这些性质:
- 零填充在图像边界制造了与内部不同的上下文。
- stride 大于 1 只保留部分采样位置,一像素平移可能得到完全不同的采样相位。
- 裁剪、缩放和插值并不是简单的整数平移。
- 展平后连接位置敏感的全连接层,会削弱前面卷积的等变结构。
局部连接和参数共享的真正价值,是把“同一种局部模式可在不同位置出现”写进模型。它减少参数,也让数据利用更高效;但旋转、尺度、透视和遮挡并不会因此自动解决。数据增强、结构设计与训练分布仍然决定模型能否应对这些变化。
小测
13
输入向右移动时,中间卷积特征也大致向右移动,这描述的是哪种性质?
14
哪些因素会破坏或限制理想的逐像素平移等变性?
感受野回答“这个位置看过原图多大范围”
某层一个单元所依赖的输入区域叫感受野。单个 卷积只看前一层的 ,但前一层每个值又来自更早的一块区域,因此堆叠会让感受野逐层扩大。
计算感受野时同时维护两个量:
- :第 层一个单元对应原始输入的感受野尺寸。
- :第 层相邻单元的中心在原始输入上相隔多远,也叫 jump。
从 、 开始。若第 层有效核尺寸是 ,stride 是 ,递推为:
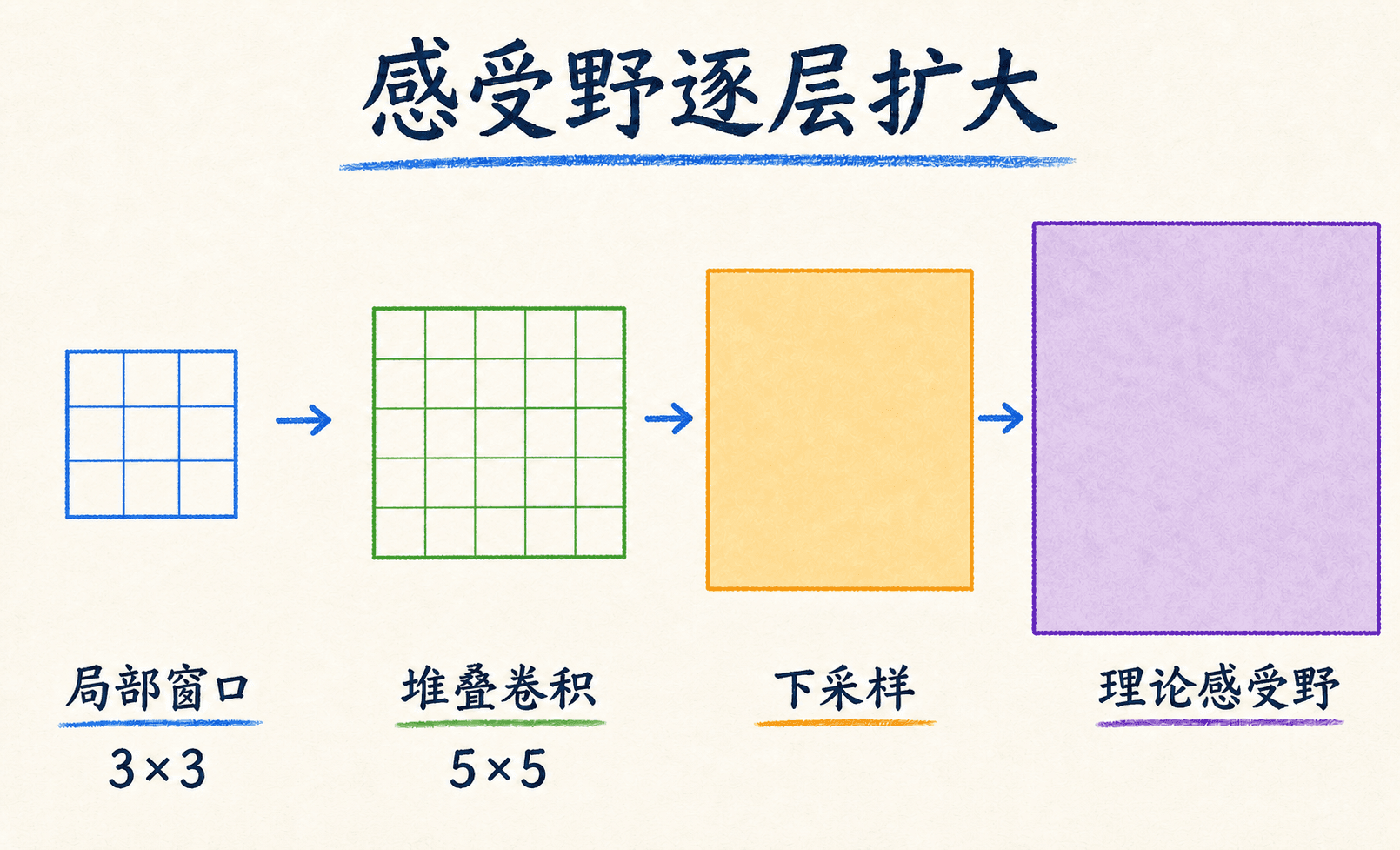
举个例子:两层 、stride 1 卷积后接 、stride 2 池化,再接一层 卷积。逐层结果如下:
最后一个特征位置理论上覆盖原图 的区域。注意,padding 改变边界位置实际包含多少有效像素,但在常用的理论感受野尺寸递推中,它主要影响感受野中心的位置,不直接改变上述 的增长量。
理论感受野只说明“可能产生影响”的最大区域,不说明每个像素影响一样大。Luo 等人在 NeurIPS 论文《理解深度卷积网络的有效感受野》中分析到,有效感受野通常集中在理论范围中央,外围影响较弱。因此,结构表里的感受野够大,不代表模型已经充分使用了整块上下文。
感受野太小会让模型看不见完整对象或长距离关系;过快下采样虽然能迅速扩大感受野,却可能损害小目标和边界。设计时要把任务需要的上下文、空间精度、算力和实际激活分析放在一起看。
小测
15
连续两层3×3、stride=1、dilation=1卷积的理论感受野边长是 ____。
16
理论感受野中的每个输入像素,对输出单元的实际影响通常完全相同。
用形状断言和最小测试排查工程错误
卷积网络最常见的 bug 往往不是公式不会,而是轴顺序、尺寸、损失或数据范围在代码里悄悄错位。下面这套检查顺序很朴素,却比直接调超参数有效。
先检查输入契约
确认输入是浮点张量,形状与框架一致,像素缩放和归一化符合训练配置。PyTorch 图像批次通常是 [N,C,H,W]。如果原始数组来自常见图像库,很可能是 [H,W,C];加批次维之前还要显式调整轴顺序。
python
import torch
# 假设images来自数据加载器
assert images.ndim == 4
assert images.shape[1] == 3
assert images.dtype in (torch.float16, torch.float32, torch.float64)
assert torch.isfinite(images).all()再让每一层报告形状
对复杂模型,可以给关键层挂临时 hook,打印输入与输出。确认完成后移除 hook,避免训练日志爆炸。
python
handles = []
def report_shape(name):
def hook(module, inputs, output):
print(f"{name:20s}: {tuple(inputs[0].shape)} -> {tuple(output.shape)}")
return hook
for name, layer in model.named_modules():
if isinstance(layer, (torch.nn.Conv2d, torch.nn.MaxPool2d,
torch.nn.AdaptiveAvgPool2d, torch.nn.Linear)):
最后做一个小批次过拟合测试
固定很小的一批样本,暂时关闭强数据增强,让模型反复训练这批数据。如果损失无法明显下降,先查标签索引、logits 形状、优化器是否拿到正确参数、梯度是否为有限值,以及训练模式是否正确。小批次能过拟合,不代表模型会泛化;但连这一步都做不到,继续扩大数据或长时间训练通常没有意义。
还要区分参数量、计算量和激活内存:
- 参数量由卷积核形状和通道连接决定。
- 计算量还乘上输出空间位置数与批次大小。
- 训练激活内存通常随批次、通道、高宽和需要保存的中间结果增长。
下面是一张适合放在实验记录里的结构表。每改一次网络,都让实际张量重新填写它,而不是手工复制旧数字。
小测
17
一个CNN训练损失完全不下降时,哪些检查适合优先做?
18
某卷积层参数不多却显存占用很高,最合理的第一条线索是什么?
现在你应该能把一个卷积网络拆成可核对的几件事:每个输出值读了哪个窗口,通道如何融合,形状为什么变化,感受野怎样扩大,以及最终损失拿到了什么张量。下一步再看 LeNet、AlexNet、VGG、Inception 和 ResNet 时,重点就不再是背网络名称,而是观察这些架构如何安排同一组基本零件。