深度学习导论
第一次接触深度学习,很容易被名词淹没:神经网络、反向传播、卷积、注意力、Transformer……它们看上去像一组彼此独立的技术。其实可以先抓住一条主线:模型接收数据,产生预测,再根据预测与答案之间的差距修正参数。 网络更深、任务更复杂之后,这条主线并没有变。
本章不急着搭一个庞大的模型。我们先把深度学习放回机器学习的坐标系里,再从一个神经元和逻辑回归出发,看清表示学习、端到端学习与训练闭环。读完后,你应该能回答三个实际问题:一个任务为什么可能适合深度学习,模型训练时到底发生了什么,以及二分类问题该怎样写成数学对象。
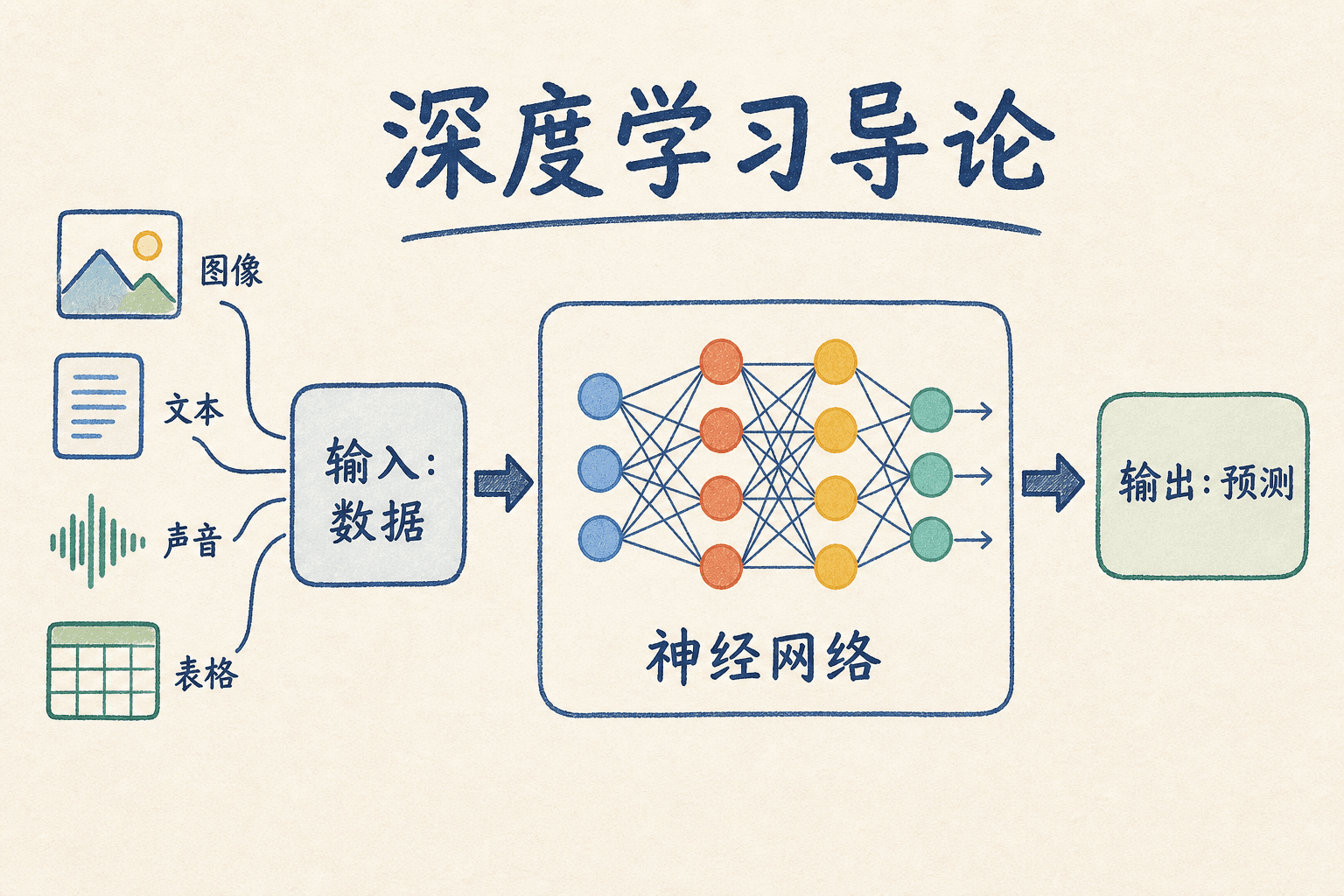
深度学习到底在学习什么
深度学习是机器学习的一类方法。它通常使用由多层可学习变换组成的神经网络,让模型从数据中学习完成任务所需的表示。这里的“深”首先指计算路径中有多层变换,不是说模型像人一样进行更深刻的思考。
传统机器学习也从数据中学习参数。区别往往出现在表示从哪里来。以图片分类为例,经典流程可能先由工程师设计边缘、纹理、颜色直方图等特征,再把特征交给逻辑回归或支持向量机。深度网络则可以把“从像素中提取表示”和“根据表示进行分类”放进同一个可训练系统。
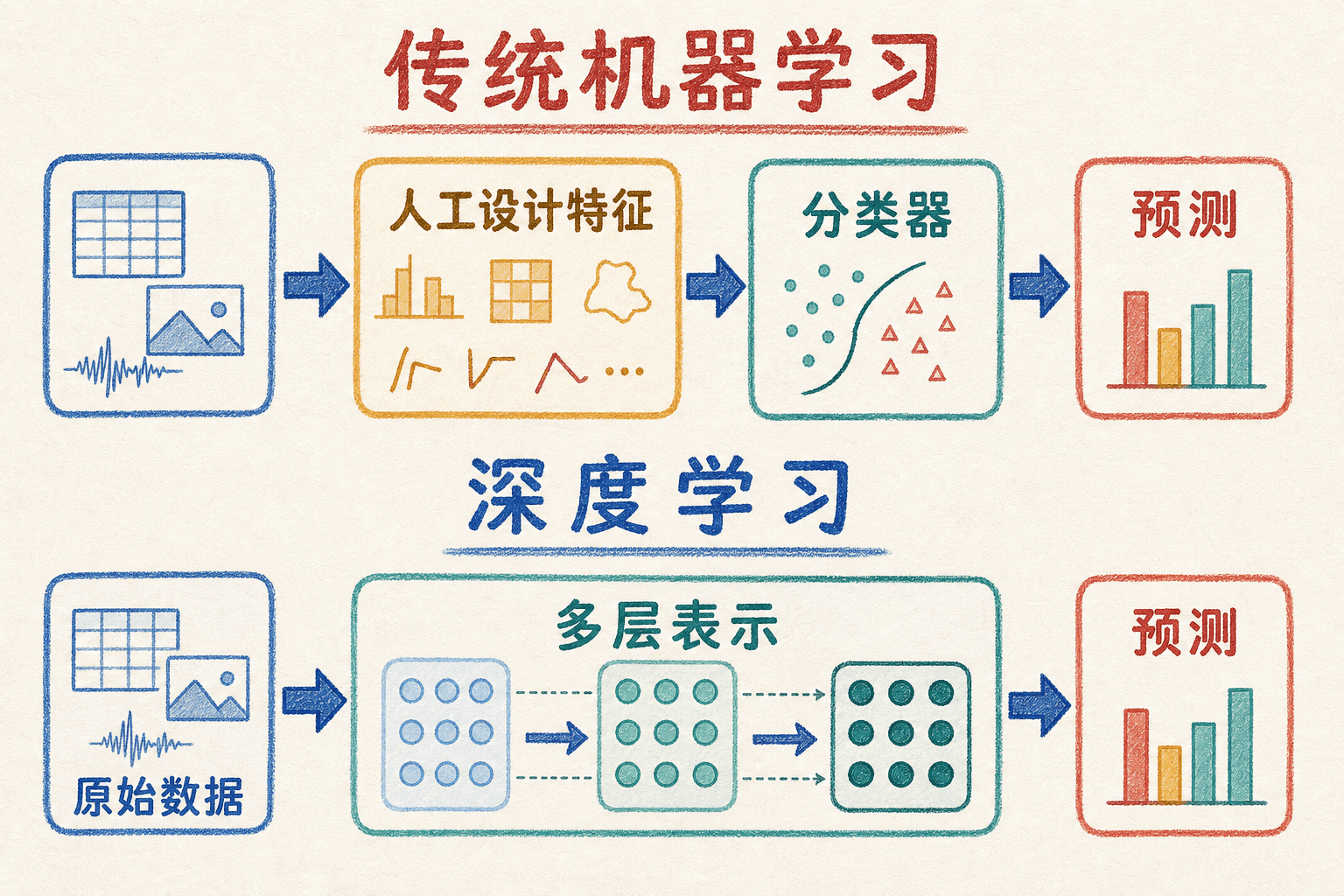
这不是一张“旧方法一定输、新方法一定赢”的排名表。任务的数据量、标签质量、成本约束和评价指标都会改变结论。表格数据上,树模型常是很强的起点;样本很少时,一个参数较少的模型也可能更稳。工程上更可靠的做法,是先建立简单基线,再用验证集比较新增复杂度是否真的带来收益。
深度学习减少的是一部分手工特征设计,并没有取消人的工作。数据怎么采集、标签如何定义、损失函数怎样选择、哪些错误最不能接受,仍然需要人做决定。
1
下面哪句话最准确地描述了深度学习中的“深”?
2
决定是否采用深度学习时,哪些因素值得先检查?
从神经元到逻辑回归
我们先看一个最小计算单元。输入特征记作向量 ,权重记作 ,偏置记作 。神经元先计算加权和:
每个权重控制一个输入对结果的影响方向和强度,偏置则允许决策边界不必穿过原点。随后,激活函数 把 变为输出 :
在二分类输出层中,我们常把 选为 Sigmoid:
Sigmoid 把任意实数映射到 。如果模型和训练目标设置得合适,这个输出可以解释成正类的预测概率。逻辑回归于是写成:
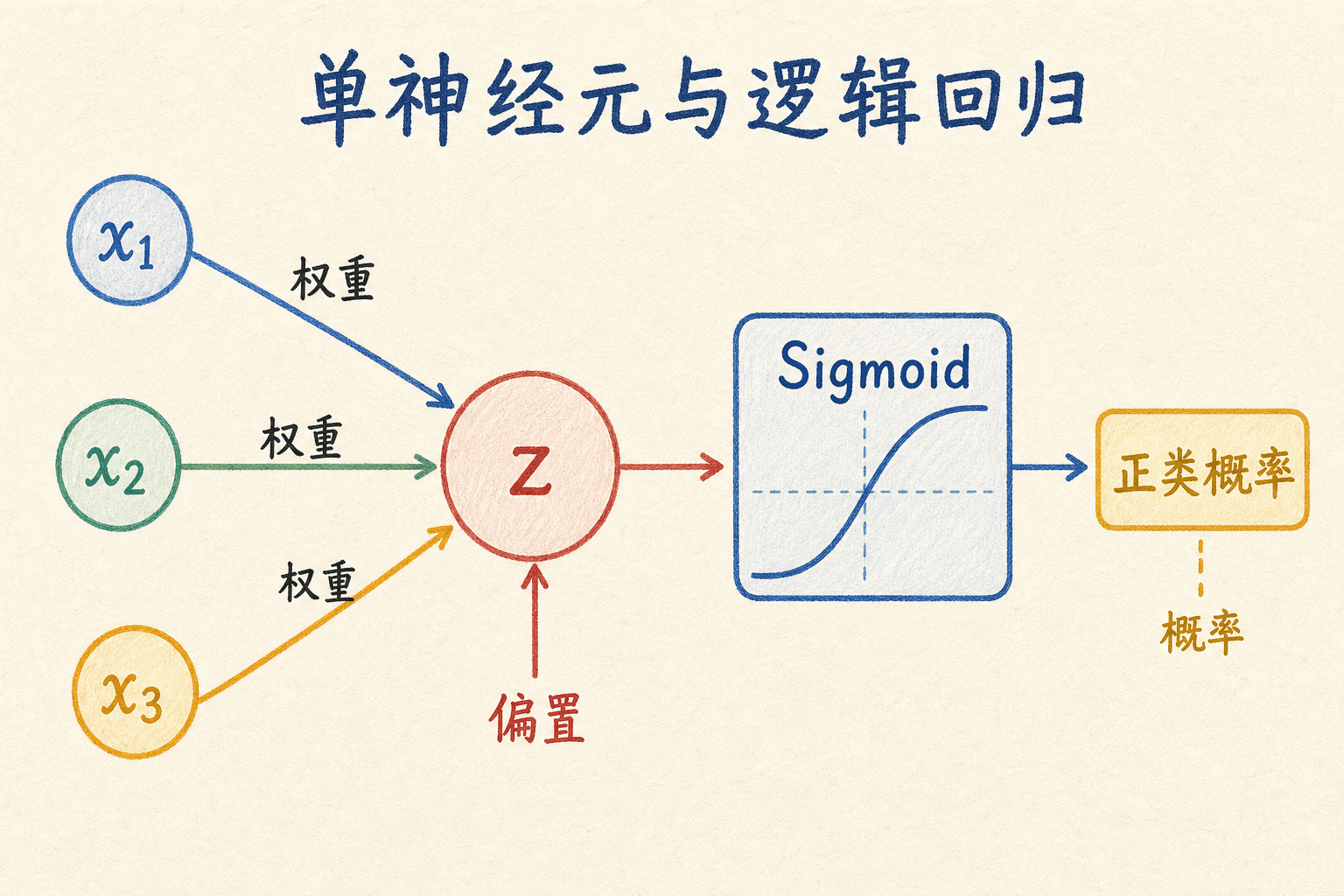
下面这个实验台把公式拆成可调的数值。你可以观察某个特征、权重或偏置发生变化时, 和预测概率怎样改变。
假设我们识别邮件是否为垃圾邮件, 表示垃圾邮件, 表示正常邮件。特征可以包括链接数量、某些词的频率等。训练不会直接手写“链接多就判为垃圾邮件”的规则,而是从样本中调整 与 。
概率还需要一个阈值才能变成类别。 是常见的讲解起点,却不是固定法规。如果漏掉一次欺诈的代价远高于多发一次人工复核,业务可能会降低报警阈值。阈值选择要在验证集上结合精确率、召回率和真实成本判断,不能只凭习惯。
权重的正负不能脱离特征定义直接解释。如果“负债率越大”与正类“会违约”对应,权重可能为正;如果正类被定义成“不会违约”,同一关系的方向就会反过来。
3
逻辑回归先计算 z = wᵀx + b,再用 ____ 函数把 z 映射到 0 与 1 之间。
4
把二分类阈值从 0.5 降到 0.3,通常最直接的变化是什么?
表示学习与端到端学习
“表示”可以理解成模型内部用来完成任务的编码方式。同一张图片既可以表示成像素矩阵,也可以表示成边缘响应、局部形状或更抽象的特征向量。表示是否好用,不取决于它听起来是否高级,而取决于它能否让目标任务更容易完成。
多层网络把前一层的输出交给后一层。在图像模型中,早期层经常对局部边缘和纹理敏感,后续层组合更大的空间模式;在语言模型中,词元会被映射为向量,并在上下文交互中逐层更新。教材常用“像素—边缘—部件—对象”解释层次表示,这是一种有用的直觉,但真实网络里的每个通道未必都对应一个能被人直接命名的概念。
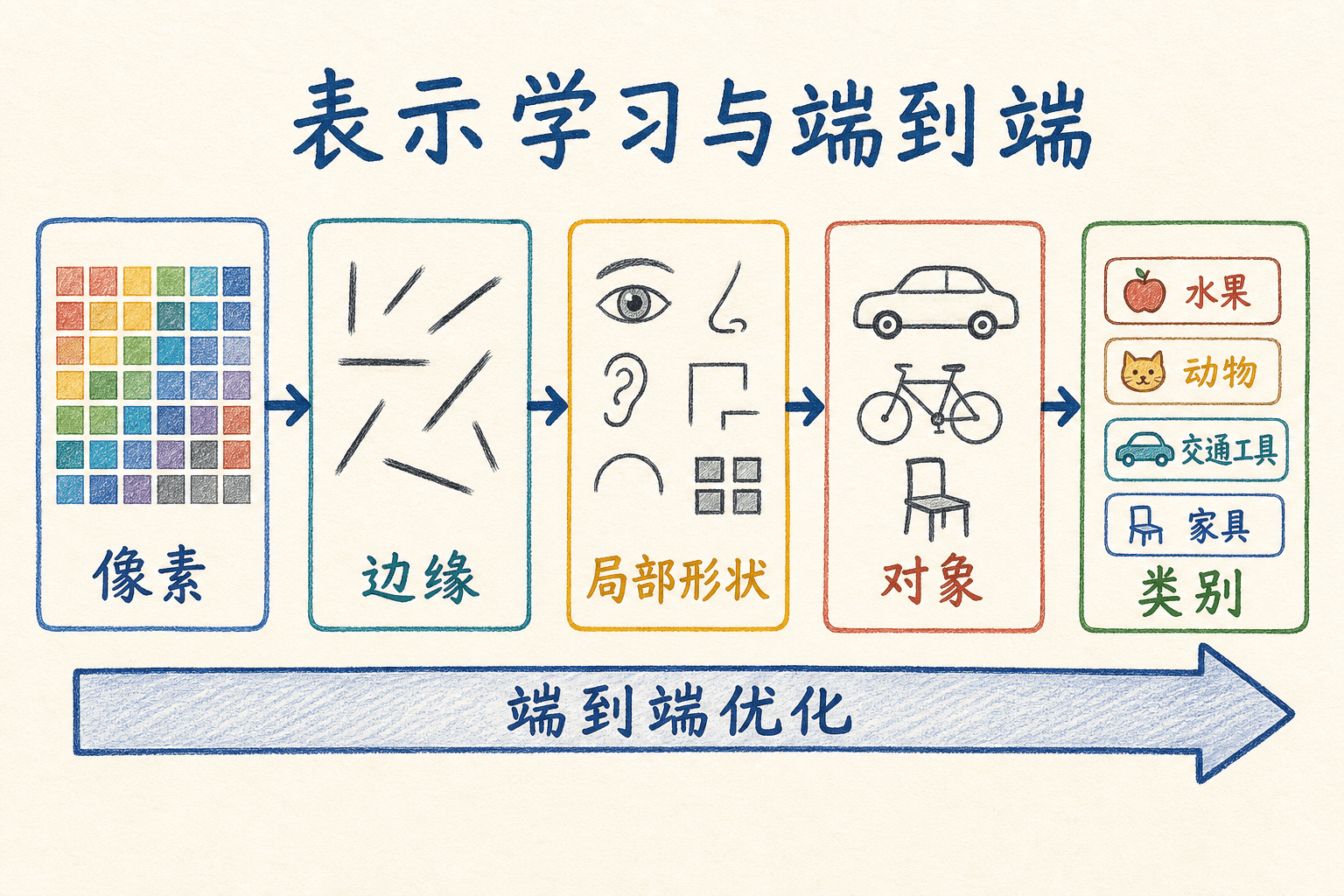
端到端学习说的是:从系统输入到最终目标之间的多个可微模块,由同一个目标联合优化。例如语音识别可以让模型直接从声学特征预测文字序列,图像分类可以从像素预测类别。误差会从输出端一路传回前面的层,所以前面学到的表示会服务于最终任务。
它的好处是减少模块之间手工规定的接口,并允许各层共同适配目标。代价也很具体:端到端模型可能需要更多配对数据,错误来源更难定位,中间结果也未必满足业务约束。实际系统常采用混合方案,例如保留确定性的数据清洗、检索或安全规则,只让适合学习的部分参与联合训练。
判断一个系统是否“端到端”,关键不在于输入是不是最原始的字节,而在于多个可学习环节是否围绕最终目标联合优化。合理的预处理并不会自动破坏端到端学习。
5
关于表示学习,哪些说法是合理的?
6
只要系统使用了深度神经网络,就一定应该删除所有人工规则和预处理。
一次训练到底发生什么
训练神经网络可以看成一个反复对账的闭环。模型先用当前参数给出预测,损失函数再把预测和标签的差距压缩为一个可优化的数值。反向传播计算这个损失对各参数的梯度,优化器据此更新参数,然后下一批数据重新开始。
把全部参数统一记作 ,一个批次的输入和标签记作 、。前向计算得到:
对单个二分类样本,常用二元交叉熵:
它会在模型高置信度地犯错时给出较大惩罚。对一个批次通常取各样本损失的平均,得到 。最简单的梯度下降更新是:
其中 是学习率。学习率太大,更新可能越过较好的区域甚至发散;太小,训练会非常慢。Adam 等优化器会改变具体更新规则,但“利用梯度修正参数”这件事没有变。
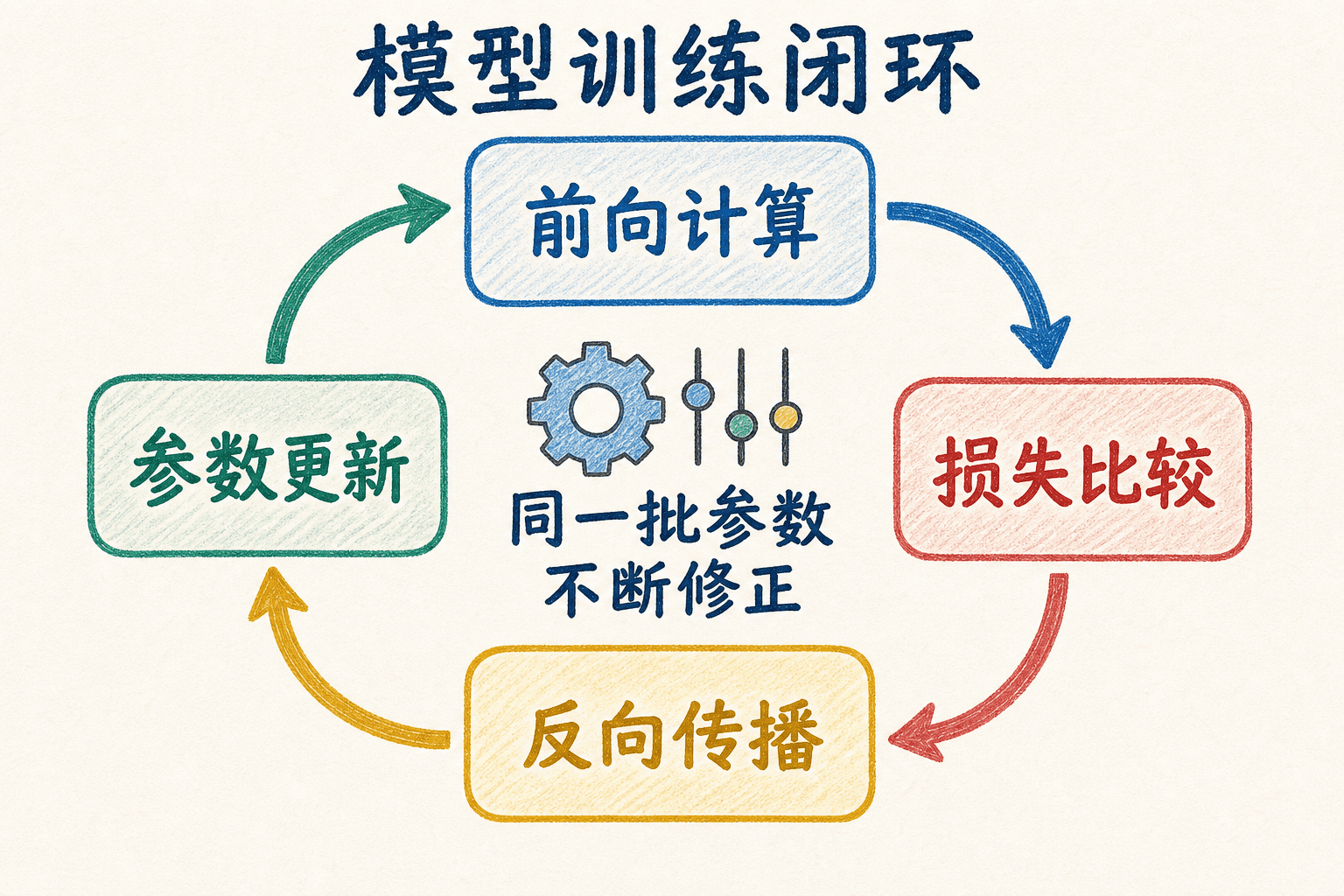
前向计算:把一批输入送入模型,逐层计算,得到预测概率或其他任务输出;框架同时记录构成计算图的操作。
计算损失:用与任务匹配的损失函数比较预测和标签。损失是优化信号,准确率等指标则更多用于解释模型表现,两者不必相同。
反向传播:从标量损失出发,按链式法则反向计算各参数的梯度。PyTorch 的自动微分会完成这些局部导数的组合。
参数更新:优化器根据梯度和学习率修改参数,并在下一批数据到来前按框架约定清理或重置梯度。
训练损失下降,只能说明模型越来越适合已见过的训练数据。我们还要观察验证集:如果训练损失继续下降,而验证损失开始上升,模型可能在记忆训练集中的偶然模式。数据划分、正则化、早停和数据增强,都是为了让“学会训练样本”更接近“能处理新样本”。
7
反向传播在训练闭环中的直接作用是什么?
8
训练损失持续下降,就足以证明模型对未见数据的表现也在改善。
9
在 θ ← θ - η∇θL 中,η 通常称为 ____。
任务决定输出,数据影响架构
选架构之前,先把任务写清楚。输入是什么?输出是一种类别、一个数值、一段序列,还是每个像素的位置?这些问题比“哪个模型最近更热门”更先决定实现方式。
CNN 并非“只能看图”,Transformer 也并非“只能处理文字”。架构名称描述的是计算结构和归纳偏置,同一种结构可以迁移到不同模态。反过来,同一个任务也常有多种可行架构。数据规模、延迟和硬件支持会决定哪个方案更合适。
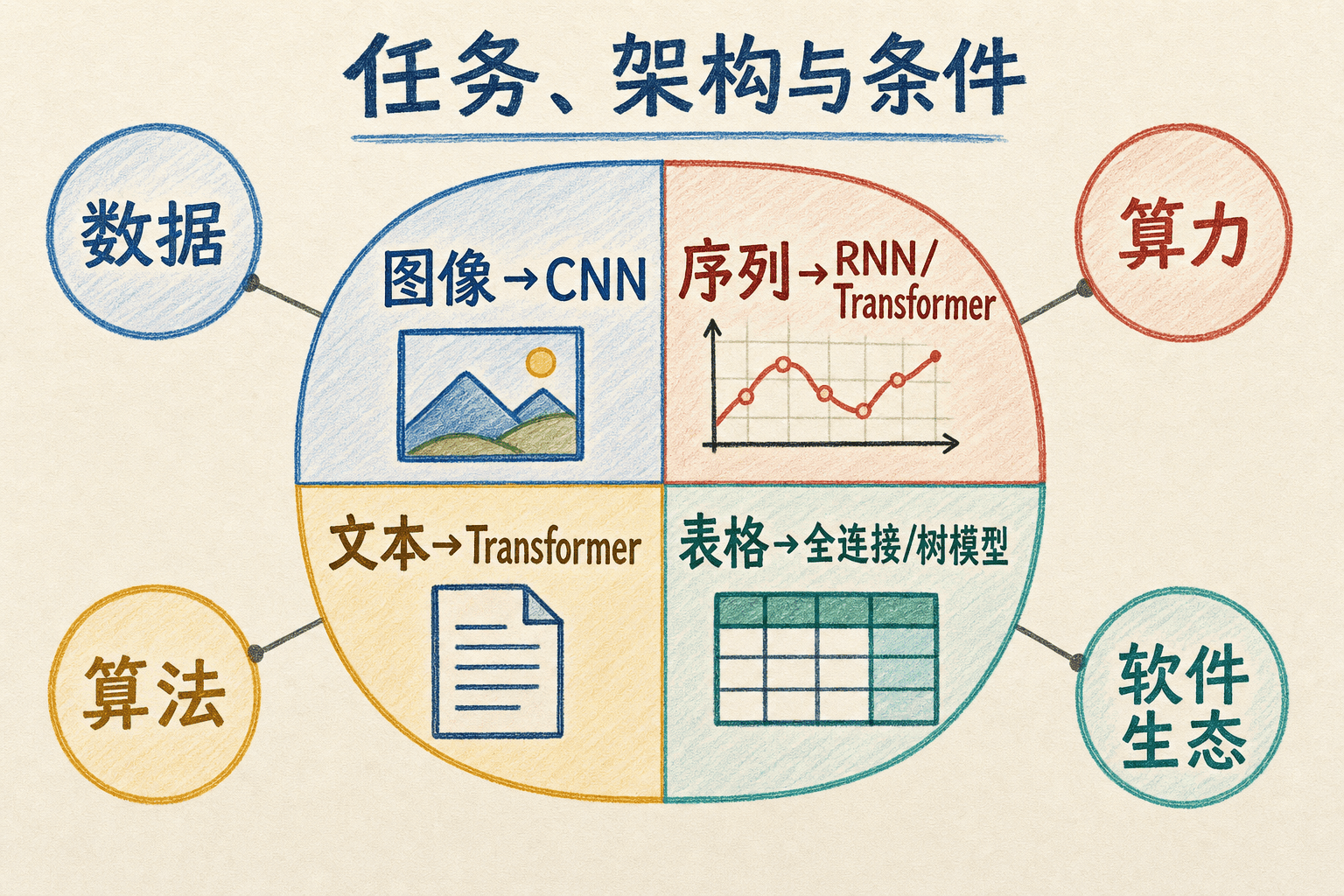
下面的匹配器给出的是建模起点,不是自动得出的最终答案。真正的选择仍要通过统一数据划分、统一指标和可复现实验比较。
先做一个可解释、训练快的基线,能帮你判断问题究竟来自数据、指标还是模型容量。没有基线时,一个复杂模型即使得到不错的数字,也很难知道复杂度是否值得。
10
为新任务选择模型起点时,哪些信息会直接影响判断?
11
对一个样本不多的表格二分类任务,最稳妥的第一步通常是什么?
数据、算力、算法与生态怎样合流
神经网络并不是 2012 年突然出现的。多层网络和反向传播的研究更早就已存在,但较大的数据集、适合矩阵并行计算的硬件、训练技巧与软件工具在这一时期形成了更有效的组合。
AlexNet 是一个清楚的历史节点。2012 年的论文在约 120 万张 ImageNet 训练图像上训练深层卷积网络,并使用两块 GTX 580 GPU。它在当年的大规模图像分类任务上显著降低错误率,让更多研究者看到深层卷积网络、GPU 计算与大规模数据组合后的效果。这里应把 2012 年理解成采用速度加快的节点,而不是神经网络的出生年份。
算法也在持续解决“网络能表示但难训练”的问题。ReLU 让正区间的梯度不再像饱和 Sigmoid 那样快速缩小;Dropout 在训练时随机屏蔽部分单元,用于减轻共适应和过拟合。2015 年提出的残差学习让层可以学习相对输入的残差,缓解了更深网络的优化困难。2017 年的 Transformer 用注意力机制构建序列模型,减少了循环结构对逐步计算的依赖。
软件生态把这些方法变成了可复用组件。现代框架提供张量运算、自动微分、优化器、数据加载与设备调度。你写出前向计算后,框架可以沿计算图组合局部导数。预训练权重和迁移学习又让许多任务不必从随机参数开始,但来源、许可、训练数据偏差和目标域差异仍需检查。
数据则决定模型能看到什么。更多数据不等于更好数据:重复样本、错误标签、训练与线上分布错位都会制造虚假的规模。算力也不是纯粹的“越多越好”,它伴随成本、能耗和部署限制。四个条件更像一个共同约束系统,任何一项短缺都可能成为瓶颈。
“数据越多,效果就会一直提升”不是普遍定律。模型容量、数据质量、任务噪声、训练方法和分布变化都会让收益变慢或反转。可靠结论应来自学习曲线和独立评估。
12
为什么常把 2012 年的 AlexNet 看成一个重要节点?
13
自动微分意味着框架不需要进行反向传播,也不需要计算梯度。
用二分类搭出第一个完整问题
二分类很适合当入口,因为输入、输出、损失和评价都能写得很清楚。假设我们要判断一张图片是否包含目标物体。每个样本由特征 和标签 组成:
含有 个样本的训练集写作:
数学推导中常把样本按列堆叠:
很多 Python 库更常把样本放在第一维,得到形状 (m, n_x)。两种约定都可以,关键是每次矩阵乘法前写清 shape,不要把“第 个样本”的上标误认成幂。
下面用 NumPy 写一个只做前向计算的逻辑回归。它还没有训练参数,但数据流已经完整:
python
import numpy as np
def sigmoid(z):
# clip 避免绝对值过大时 exp 溢出
z = np.clip(z, -30, 30)
return 1.0 / (1.0 + np.exp(-z))
def predict_proba(X, w, b):
"""X: (样本数, 特征数), w: (特征数,)"""
logits = X @ w + b
return sigmoid(logits)
X =
真正训练时,还要补上标签、二元交叉熵、梯度与参数更新。进入项目之前,再做三件事:先按样本来源合理拆分训练集、验证集和测试集;再处理缺失值、类别不平衡与数据泄漏;最后确定与业务相符的指标。类别极不平衡时,单看准确率可能掩盖模型几乎从不识别少数类的问题。
测试集应留到模型与阈值基本确定之后使用。如果根据测试集结果反复改模型,测试集也会被间接用于开发,最终数字就不再代表真正未见数据。
14
二分类标签 y 通常取值于集合 ____。
15
建立二分类数据集时,哪些做法有助于得到可信评估?
16
若 X 的形状是 (m, n_x),w 的形状是 (n_x,),那么 X @ w 的形状是什么?
形成一张可执行的学习地图
到这里,我们可以把深度学习压缩成一条能动手执行的路线:
- 定义任务:写清输入、输出、正负类含义和最不能接受的错误。
- 准备数据:检查来源、标签、许可和泄漏风险,划分训练、验证、测试集合。
- 建立基线:先训练逻辑回归、树模型或一个小网络,确认数据管道和指标能工作。
- 选择表示与架构:根据数据结构和输出形式选择网络起点,不追求无依据的复杂度。
- 运行训练闭环:前向计算、损失、反向传播和参数更新,并记录训练与验证曲线。
- 分析错误:观察模型错在什么样本上,再决定补数据、改目标、调阈值还是换模型。
下一章会把这条路线的数学地基补齐:向量和矩阵如何组织一批样本,导数与链式法则怎样连接多层计算,NumPy 中的广播又为什么能让公式高效运行。你不需要现在记住所有架构,只要先能沿着“输入—预测—损失—梯度—更新”讲清一次训练,就已经抓住了后续内容的骨架。
17
建立简单基线的价值之一,是判断复杂模型增加的成本是否换来了可验证的收益。
18
完成本章后,你应能用同一条主线解释哪些概念?