循环神经网络:把“先后顺序”变成可学习的状态
同一组词换个顺序,意思可能完全不同;同一台机器的温度读数,今天的异常也可能是几小时前的变化累积出来的。序列数据真正麻烦的地方不只是“长度不固定”,而是当前判断往往依赖前面发生过什么。
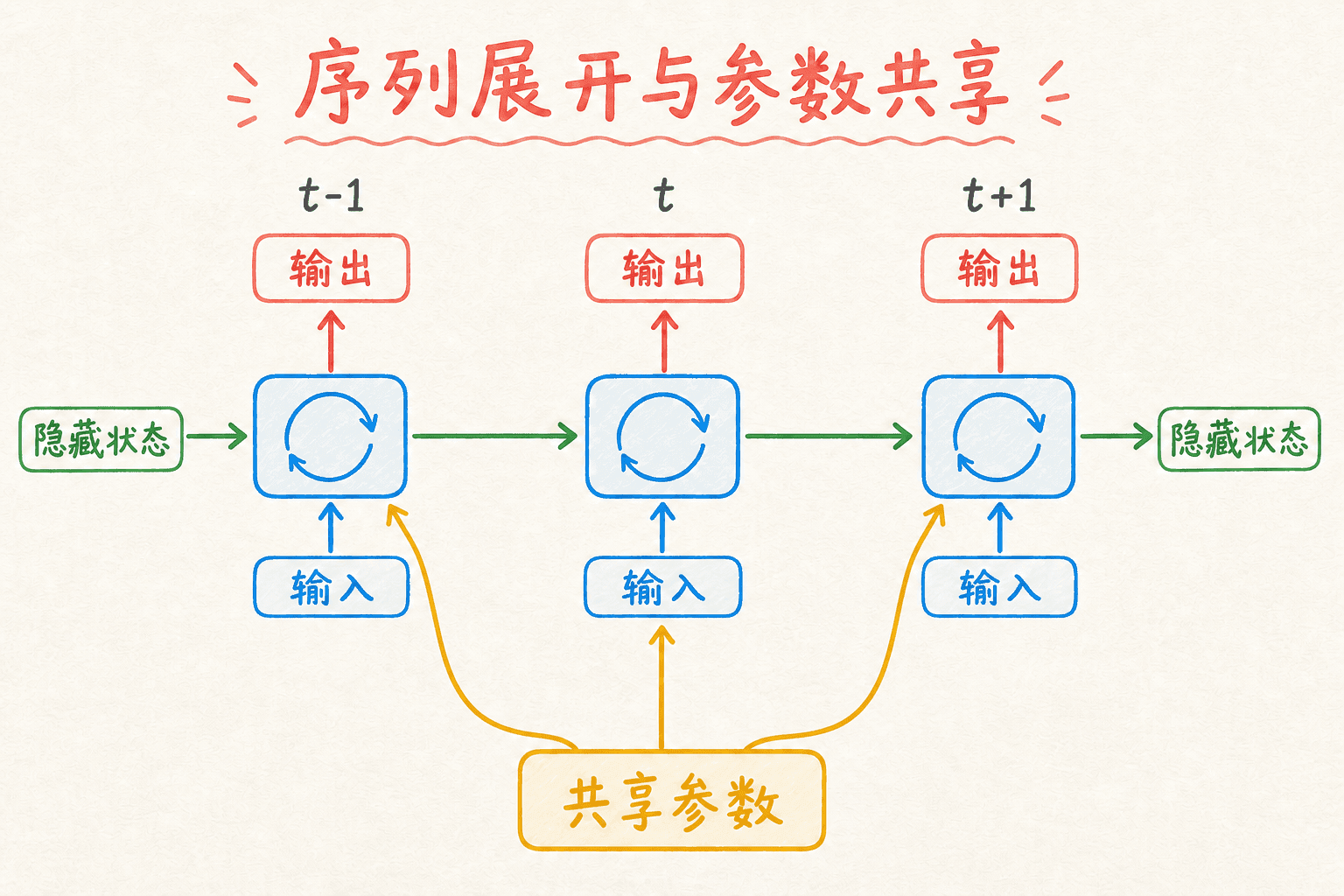
循环神经网络(Recurrent Neural Network,RNN)给这个问题提供了一种直接的建模方式:每读入一个时间步,就更新一次隐藏状态;下一步再把这个状态和新输入一起处理。于是,模型的计算虽然逐步进行,参数却能在所有位置共享。
这篇内容不会只停在几个门控公式上。我们会把张量形状、时间展开、BPTT、梯度裁剪、LSTM、GRU、双向网络、padding、mask 和 PackedSequence 连成一条完整路线。读完后,你应该能说清楚每个张量到底代表什么,也能解释训练代码为什么会在“看起来能跑”的情况下悄悄学错。
序列任务难在哪:长度、顺序和输出方式
先看一句很短的话:“小王告诉小李,他通过了考试。”如果我们判断“他”指谁,就不能只看“他”这个词;前面的名字、句法和语境都会影响答案。时间序列也一样:某个时刻的传感器读数是否异常,要结合之前的趋势判断。
把长度为 的序列写成
其中 是第 个时间步的特征向量。序列模型通常要同时处理三件事。
- 顺序有意义:交换 和 ,结果可能改变。
- 长度会变化:一句话可以有 5 个词,也可以有 50 个词。
- 输出结构不统一:有的任务每步都输出,有的只输出一个结果,还有的输出另一条不同长度的序列。
常见任务可以按输入和输出的对应关系来理解:
固定窗口的全连接网络也能接收序列,但它要预先规定窗口长度,而且不同位置通常使用不同参数。RNN 在时间维共享参数,因此同一套状态更新可以作用于任意位置。这里要把话说准确:共享参数让模型可以接收不同长度,不等于模型自动学会任意长的依赖。 后者还受优化难度、状态容量和训练方式影响。
序列不一定来自钟表时间。句子中的词、DNA 中的碱基、用户连续点击的商品,都可以按位置排成序列。只要先后关系会影响任务,就可以用序列建模的视角分析。
1
下列哪个任务最自然地属于“每个时间步都要输出”的序列任务?
2
RNN 在时间维共享参数,所以它一定能记住任意久以前的信息。
先把张量轴说清楚:批次、时间和特征
很多 RNN 代码的错误不是公式错,而是轴弄反了。我们先约定五个符号:批大小 、序列长度 、输入特征数 、隐藏维度 、层数 。如果是双向网络,再用 表示方向数:单向时 ,双向时 。
在 PyTorch 里,batch_first=True 时,一个批次的输入通常是:
例如 X.shape == (32, 50, 128) 表示一个批次有 32 条序列,每条补齐到 50 个时间步,每步由 128 维特征表示。若使用默认的 batch_first=False,前两轴换成 。
单层单向 RNN 的初始状态是 。多层或双向后,第一维合并“层”和“方向”:
一个很容易踩的坑是:batch_first=True 只改变 input 和 output 的轴顺序,不改变 h_0、h_n,也不改变 LSTM 的 c_0、c_n。 这些状态仍然把“层 × 方向”放在第一轴。
时间展开只是看法,不是复制参数
RNN 常画成一排相同单元。左边的状态流向右边,看起来像一张 层的网络。这个画法叫时间展开:它把递归计算显式写成 次状态更新,方便我们理解前向传播和反向传播。
但图上每个单元并不持有一套独立权重。若状态更新函数是 ,那么所有时间步都使用同一个 :
序列变长时,计算图变长,参数量并不会随 增加。这也是 RNN 能把“在某个位置学到的模式”迁移到其他位置的原因。
3
一个双层双向 GRU 的 hidden_size=64、batch=20。h_n 的形状应是哪一个?
4
设置 batch_first=True 后,LSTM 的 c_n 也会变成 (batch, layers×directions, hidden)。
基础 RNN 如何更新隐藏状态
最常见的简单 RNN 会把当前输入 和上一时刻状态 分别做线性变换,再经过非线性函数:
若任务需要每步分类,可以继续计算:
把当前输入送进隐藏空间, 让历史状态参与当前更新。隐藏状态并不是一段可以直接读出的文字记忆,而是模型在训练目标约束下学到的连续向量。它可能编码语法线索、趋势、阶段信息,也可能学到我们难以逐维命名的特征。
我们用一个长度为 3 的序列走一遍:
用初始状态 和第一个输入 计算 。若没有显式传入 ,PyTorch 的 RNN 模块默认使用全零状态。
对应的最小 PyTorch 形状实验如下:
python
import torch
from torch import nn
B, L, I, H = 4, 7, 10, 16
x = torch.randn(B, L, I)
rnn = nn.RNN(
input_size=I,
hidden_size=H,
num_layers=1,
batch_first=True,
nonlinearity="tanh",
)
对单层、单向、等长序列来说,output[:, -1, :] 与 h_n[0] 对应同一批最终状态。但一旦加入双向、padding 或 packed sequence,这种“直接取最后一列”的习惯就可能出错,后面会专门处理。
5
基础 RNN 在 t=5 更新隐藏状态时直接使用哪些量?
6
时间展开图中每个时间步都画了一个 RNN 单元,因此长度为 100 的序列会使用 100 套互不相同的循环权重。
BPTT:梯度为什么要沿时间倒着走
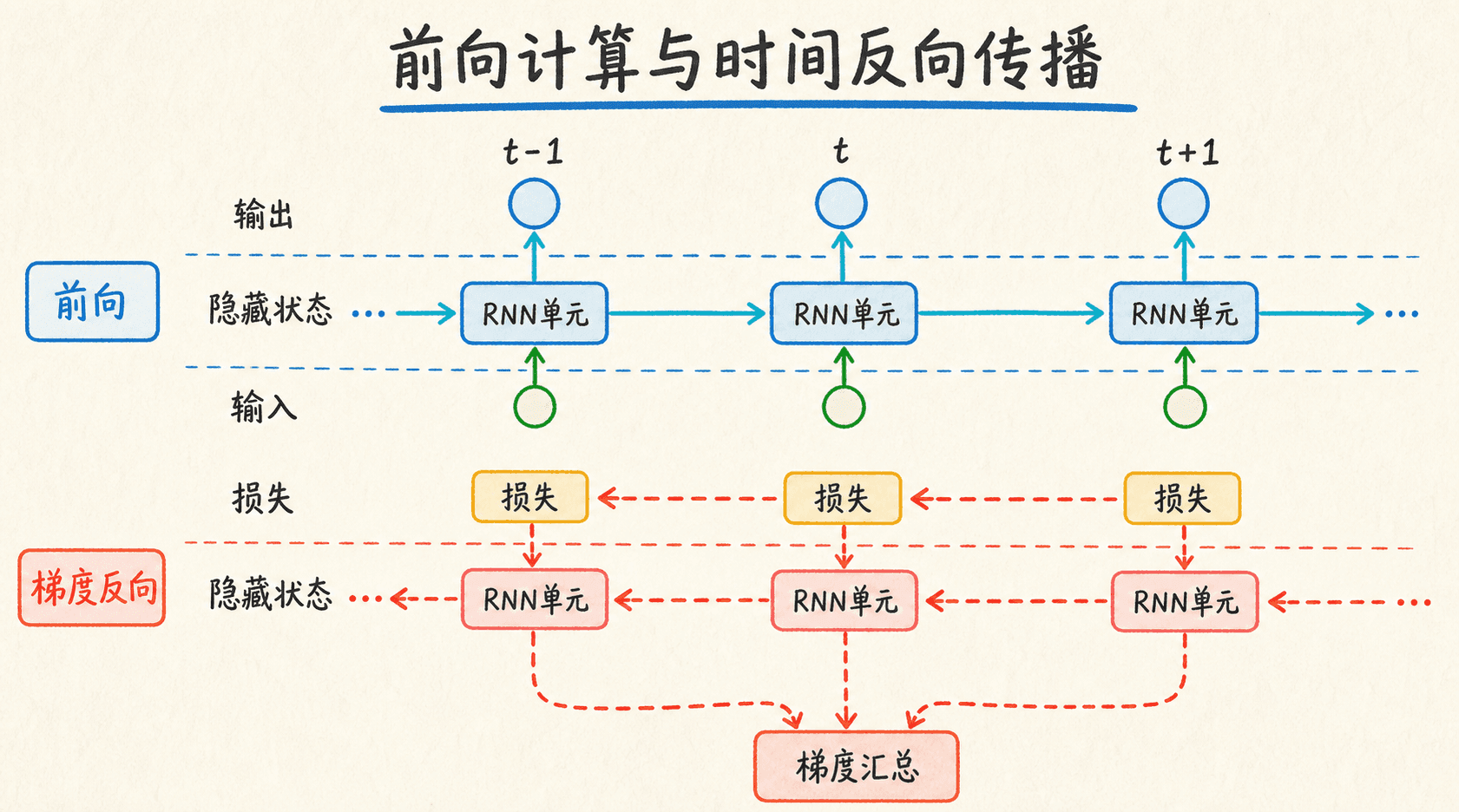
训练时,我们先完成整段或一段序列的前向计算,再把损失对参数的影响沿展开图反向传递。这就是通过时间的反向传播(Backpropagation Through Time,BPTT)。
假设每个时间步都有损失 ,总损失为
由于同一参数 在每个时间步都被使用,最终梯度要累加它在所有展开节点上的贡献:
早期状态还会通过后续状态间接影响后面的损失。以 对 的影响为例,其中 :
这串 Jacobian 连乘就是长期依赖难学的数学入口。连乘中的尺度反复小于 1,梯度会衰减;反复大于 1,梯度会放大。tanh 的导数最大为 1,而且在饱和区接近 0,因此简单 RNN 很容易让遥远时间步收到极小的训练信号。
完整 BPTT 与截断 BPTT
若一次对整条序列反向传播,计算图和中间激活会随序列增长,占用更多显存。长流式数据常用截断 BPTT:把序列分成长度为 的片段,状态可以传给下一片段,但在片段边界用 detach() 切断旧计算图。
python
hidden = None
for x_chunk, y_chunk in stream:
optimizer.zero_grad()
output, hidden = rnn(x_chunk, hidden)
loss = loss_fn(output, y_chunk)
loss.backward()
optimizer.step()
# 保留数值状态,但不让下一段继续追溯旧计算图
hidden = hidden.detach()这里做的是一个明确取舍:模型仍把上一片段的状态数值带到下一片段,但梯度最多回传 步。片段太短会削弱长期信用分配,太长则提高内存与计算成本。
不要因为看到 detach() 就到处添加。若你本来要对一条完整短序列做 BPTT,在每个时间步都 detach 会把时间上的梯度切断,模型只能学习一步关系。detach 主要用于明确的片段边界、跨批状态管理或不需要梯度的分支。
7
截断 BPTT 在片段边界 detach 隐藏状态,最准确的含义是什么?
8
BPTT 中同一个循环参数在不同时间步产生的梯度贡献需要累加。
梯度消失、梯度爆炸和裁剪
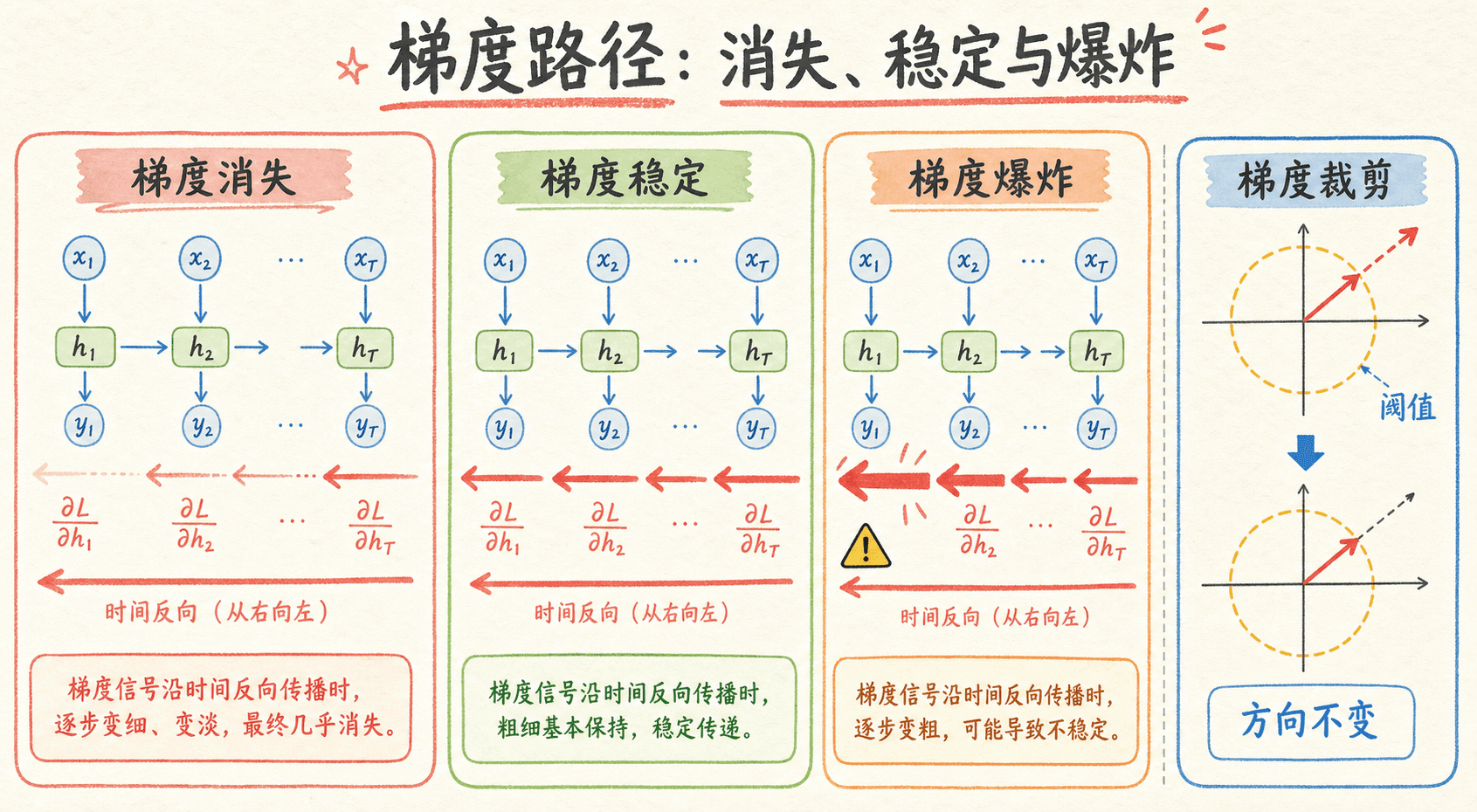
梯度消失和梯度爆炸来自同一类连乘,只是结果朝两个方向发展。
- 梯度消失:较早位置几乎收不到后面损失的信号,长期依赖学不动。
- 梯度爆炸:梯度范数突然很大,参数更新过猛,损失出现尖峰,严重时变成
inf或nan。
梯度裁剪主要处理爆炸,不是消失。最常见的是按全局范数裁剪。设所有参数梯度合成后的范数为 ,阈值为 :
当范数没超过阈值,梯度不变;超过时,所有梯度按同一比例缩小,整体方向基本保持。PyTorch 中要把裁剪放在 backward() 之后、step() 之前:
python
optimizer.zero_grad()
output, h_n = model(x, h_0)
loss = criterion(output, target)
loss.backward()
total_norm = torch.nn.utils.clip_grad_norm_(
model.parameters(),
max_norm=1.0,
)
optimizer.step()排查训练不稳定时,不要只看 loss。至少记录梯度范数、学习率、序列长度分布和有效 token 数。如果梯度总在阈值上方被裁剪,阈值可能太小,也可能学习率、初始化或数据存在更根本的问题。
面对消失梯度,常用办法包括改用 LSTM/GRU、缩短反传跨度、改善初始化、规范化输入、调整优化器和使用残差式结构。门控网络能改善梯度路径,但也不是“从此不消失”的保证。
9
下列哪些现象可能提示梯度爆炸?
10
梯度裁剪在标准训练循环中的正确位置是哪里?
LSTM:给状态更新增加可控的信息通道
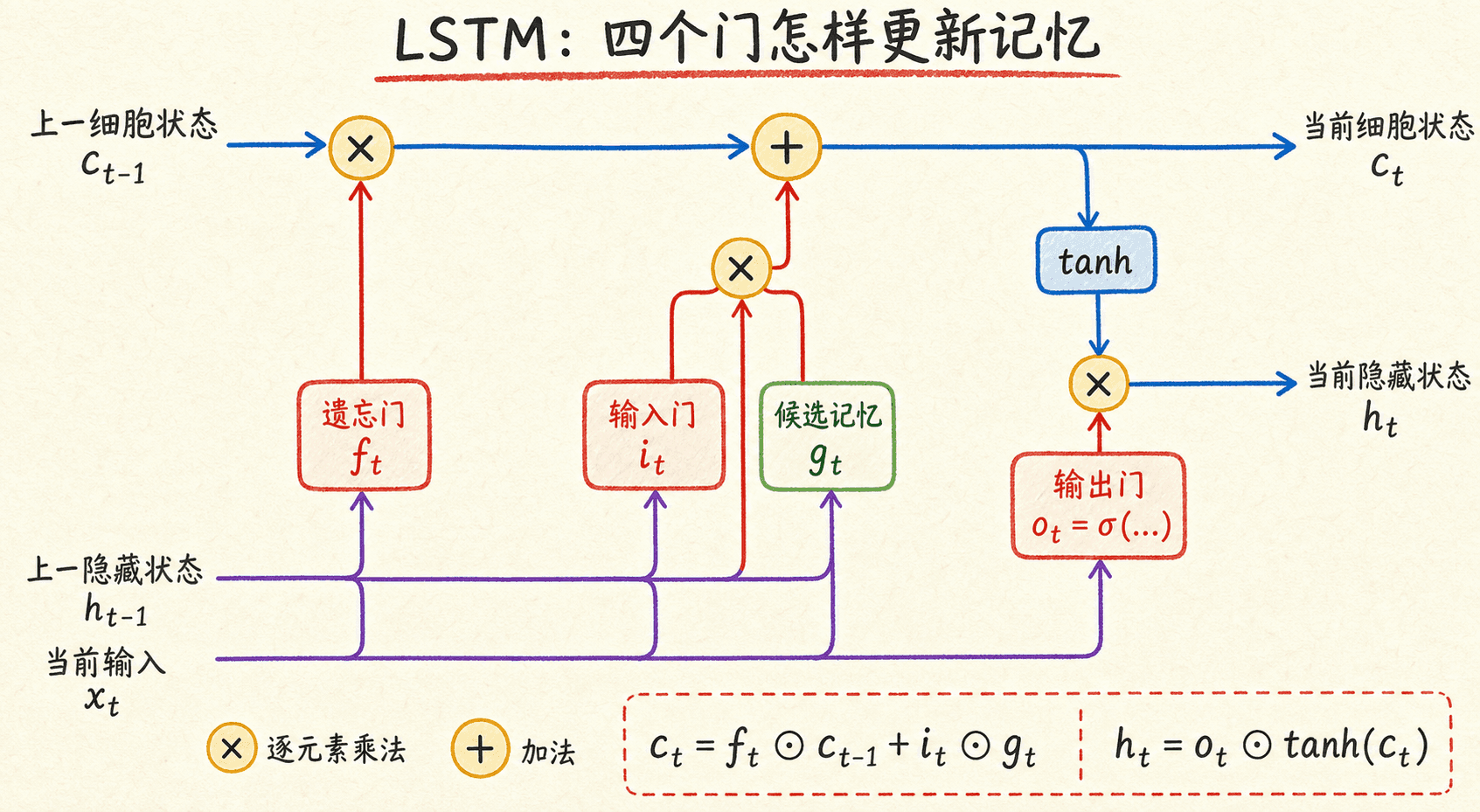
简单 RNN 每一步都把新旧信息混合后再通过非线性,长期信息很容易在反复变换中衰减。LSTM(Long Short-Term Memory)额外维护细胞状态 ,并用门控决定保留、写入和读出多少信息。
下面写的是现代实现中常见、没有 peephole 连接的 LSTM 形式。先把当前输入与上一隐藏状态分别做线性变换,计算四组向量:
是输入门,控制候选内容 写入多少; 是遗忘门,控制旧细胞状态保留多少; 是输出门,控制细胞状态向隐藏状态暴露多少。更新为:
关键不在“门有三个”这句口诀,而在 的加法路径。信息可以沿 传播,梯度在这条路径上主要受 调节,比简单 RNN 每步都经过完整的循环矩阵和 更容易保留。
但遗忘门若长期接近 0,旧信息照样会被抹掉;门控饱和、序列过长或训练设置不合适时,LSTM 也会遇到优化问题。所以更准确的说法是:LSTM 缓解长期依赖的训练困难,而不是数学上消灭它。
PyTorch 的 LSTM 返回两类状态:
python
lstm = nn.LSTM(
input_size=128,
hidden_size=256,
num_layers=2,
batch_first=True,
)
output, (h_n, c_n) = lstm(x)h_n 是各层最终隐藏状态,适合接输出头;c_n 是各层最终细胞状态,通常在继续处理下一段序列时与 h_n 一起传入。只传其中一个会破坏 LSTM 状态的完整性。
11
LSTM 中哪一个门直接缩放上一时刻细胞状态 c_(t-1)?
12
LSTM 有了细胞状态后,从理论上保证任何长度的依赖都不会出现梯度衰减。
GRU:用更少的状态完成门控更新
GRU(Gated Recurrent Unit)把记忆与输出都放在同一个隐藏状态 中,不再单独维护 。它通常使用重置门 、更新门 和候选状态 。
按 PyTorch 官方实现,计算是:
从最后一式看最直观:当 接近 1,GRU 更倾向保留旧状态;当 接近 0,更倾向采用候选状态。重置门影响旧状态在候选内容计算中的参与程度。
原始 GRU 论文与 PyTorch 的候选状态公式有一个实现细节差异。原始形式先计算 ,再乘隐藏权重;PyTorch 为提高效率,把重置门乘在隐藏线性变换之后。这提醒我们:写复现代码时不能只说“用了 GRU”,还要确认所用框架的具体定义。
GRU 还是 LSTM
GRU 门更少,也没有独立细胞状态,参数量和单步计算通常更少。LSTM 的状态控制更细。二者没有脱离任务的固定胜负关系,合理做法是把它们当成需要验证的架构选择:在同一数据划分、训练预算和隐藏规模约束下比较验证集表现、速度与内存。
“GRU 更快,所以一定更好”和“LSTM 门更多,所以一定更准”都不是可靠结论。隐藏维度相同不代表总参数完全相同,比较时要同时报告参数量、训练预算和验证指标。
13
按本文采用的 GRU 公式,当更新门 z_t 接近 1 时,h_t 更接近什么?
14
比较 GRU 和 LSTM 时,哪些做法更合理?
双向与堆叠 RNN:方向和层数不能混为一谈
单向 RNN 在位置 只能利用 到 。离线词性标注、整段语音分析等任务通常已经拿到完整序列,这时可以再用一个反向 RNN 从 处理到 。两个方向在每个位置的状态拼接为:
若每个方向隐藏维度都是 ,逐步输出的最后一维就是 。双向网络的代价也很明确:它需要未来上下文,因此普通双向 RNN 不能直接用于要求“输入到一帧就立刻输出”的严格因果流式任务。实际系统若需要有限延迟,可以使用固定右上下文或分块方案,但那已经改变了可用信息边界。
正确读取双向最终状态
PyTorch 的双向输出把前向和反向状态拼在特征轴上。若 batch_first=True:
python
output, h_n = bigru(x)
# output: (B, L, 2H)
forward_each = output[:, :, :H]
backward_each = output[:, :, H:]一个常见错误是把 output[:, -1, :] 当作两个方向的最终摘要。它的前半段确实是前向网络读完整条序列后的状态;后半段却是反向网络在原序列最后一个位置的输出,此时反向网络刚从该位置开始处理,并没有读完整条序列。
稳妥做法是重排 h_n,显式取最后一层的两个方向:
python
# h_n: (num_layers * 2, B, H)
h_n = h_n.view(num_layers, 2, B, H)
last_forward = h_n[-1, 0]
last_backward = h_n[-1, 1]
summary = torch.cat([last_forward, last_backward], dim=-1)堆叠增加表示层级,不增加时间方向
num_layers=3 表示把三层 RNN 纵向堆叠:第二层在每个时间步接收第一层的输出,第三层再接收第二层输出。它与序列长度 是两种不同的“深度”。
PyTorch 中 RNN/LSTM/GRU 的 dropout 参数只作用在相邻循环层之间,并且不作用于最后一层输出。设置 num_layers=1 时,它不会在单层内部自动加入循环 dropout。
15
双向 RNN 的逐步输出形状为 (B,L,2H) 时,output[:, -1, H:] 表示什么?
16
双向 RNN 可以不做任何改动就用于零延迟流式预测,因为反向分支不会使用未来输入。
变长批处理:padding、mask 与 PackedSequence
批处理要求张量形状一致,但真实序列长度常常不同。假设三条序列长度分别是 5、3、2,我们通常把短序列在尾部补到 5,再得到形状统一的张量:
text
A A A A A 长度 5
B B B PAD PAD 长度 3
C C PAD PAD PAD 长度 2padding 只是占位,不应被当成真实训练信号。这里有两个独立问题:
- 损失是否忽略 padding:逐 token 分类可以用布尔 mask 选出有效位置,或让交叉熵的
ignore_index忽略 PAD 标签。 - RNN 是否继续处理 padding:若直接把补齐张量送入 RNN,短序列的状态还会经过若干 PAD 步。即使 PAD 向量为零,循环偏置和旧状态也可能继续改变结果。
PackedSequence 解决第二个问题。它按每条样本的真实长度,把有效时间步重新组织成紧凑表示,让 PyTorch 的 RNN 模块跳过 padding:
python
import torch
from torch import nn
from torch.nn.utils.rnn import (
pack_padded_sequence,
pad_packed_sequence,
)
lengths = torch.tensor([5, 3, 2], dtype=torch.long)
x = torch.randn(3, 5, 8) # (B,L,I),尾部已经 padding
packed = pack_padded_sequence(
x,
enforce_sorted=False 允许传入未按长度降序排列的批次,函数内部会处理排序并在输出状态中恢复原批次顺序。若 lengths 是张量,官方文档要求它位于 CPU。total_length 可以让还原后的时间轴保持指定长度,在多设备汇总等场景中很有用。
mask 和 pack 不是二选一
pack 让循环层跳过 PAD 步;mask 或 ignore_index 让损失函数跳过 PAD 标签。一个模型完全可能两者都需要。
如果任务只做序列级分类,packed RNN 返回的 h_n 已对应每条序列的真实结束位置,比直接取 output[:, -1] 安全。如果任务要给每个有效时间步算损失,可以先 pad_packed_sequence 还原,再用 mask 筛掉无效位置;也可以在明确理解对齐关系时直接处理 packed_output.data。
17
对尾部 padding 的变长序列批次,下列哪些说法正确?
18
使用 pack_padded_sequence 且批次没有按长度降序排列时,通常应怎样设置?
从可运行到可信:一份 PyTorch 训练与排错清单
下面用双向 GRU 做一个变长序列分类器。代码不追求功能堆叠,只把容易写错的边界明确展示出来。
python
import torch
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence
class SequenceClassifier(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = 2
self.num_directions = 2
self.encoder
训练循环中再加上梯度裁剪:
python
model.train()
for x, lengths, target in train_loader:
x = x.to(device)
target = target.to(device)
optimizer.zero_grad(set_to_none=True)
logits = model(x, lengths)
loss = criterion(logits, target)
loss.backward()
grad_norm = nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()注意 lengths.cpu() 的位置:输入特征和标签通常搬到加速设备,长度张量则按 pack_padded_sequence 的接口要求留在 CPU。
六类“代码能跑但结果不可信”的错误
- 训练和验证混用模式:验证前忘记
model.eval(),多层 RNN 的层间 dropout 仍在随机工作;验证后又忘记切回model.train()。 - 跨样本错误传状态:本来每条样本互不相关,却把上一批的
h_n传给下一批,让批次边界变成虚假的时间连接。 - 状态没有 detach:确实要做有状态训练,却跨批保留完整计算图,显存逐步增长并意外反传到很久以前。
- 只屏蔽损失,不处理最终状态:用
output[:, -1]做分类时取到了 padding 后的状态。 - 双向最终状态取错:把
output[:, -1]的后半段当成反向最终摘要。 - 标签错位:做下一步预测时忘了让输入
x_1...x_{L-1}对齐目标x_2...x_L,或者 mask 与移位后的目标长度不一致。
还有一个工程上很实用的检查:用一个极小批次尝试过拟合。如果模型连十几条样本都压不下 loss,优先检查形状、标签、mask、学习率和状态边界,不要先盲目增加层数。
何时还会选择 RNN
Transformer 已经是许多自然语言任务的常见选择,但这不意味着 RNN 失去所有用途。RNN 的状态按步更新,适合计算预算有限、输入自然流式、延迟敏感或数据规模较小的场景。模型选择仍要回到约束:是否允许未来上下文、序列有多长、部署内存有多少、能否并行训练,以及验证集上谁更可靠。
19
下列哪些做法有助于发现 RNN 训练代码中的静默错误?
20
若不同 mini-batch 中的样本彼此独立,通常应把上一批的隐藏状态直接传给下一批。