从 Seq2Seq 到 Transformer:把序列生成的每一步都讲清楚
如果输入和输出都是序列,麻烦就不只是“长度不固定”。翻译时,源句和目标句的长度可能不同;摘要时,一个事实可能隔着几段文字才出现;生成时,前一个词一旦选错,后面的输入环境也会跟着变。模型既要理解整段输入,又要知道当前该看哪里,还要在巨大的候选空间里逐步作出决定。
这篇内容沿着一条完整的技术路线展开:先从经典 RNN 编码器—解码器出发,解释 teacher forcing 为什么方便训练却会带来训练—推理落差;再拆开 Bahdanau 与 Luong 注意力,讲清分数、softmax、上下文向量和 mask;最后进入 Transformer,处理自注意力、多头、位置编码、因果 mask、填充 mask,以及真正落地时最常见的诊断问题。
你不需要把注意力理解成一种神秘的“聚焦能力”。它首先是一套可计算、可检查的加权读取过程。只要把张量轴、可见范围和训练目标对齐,许多看似复杂的实现问题都能变成普通的工程检查。
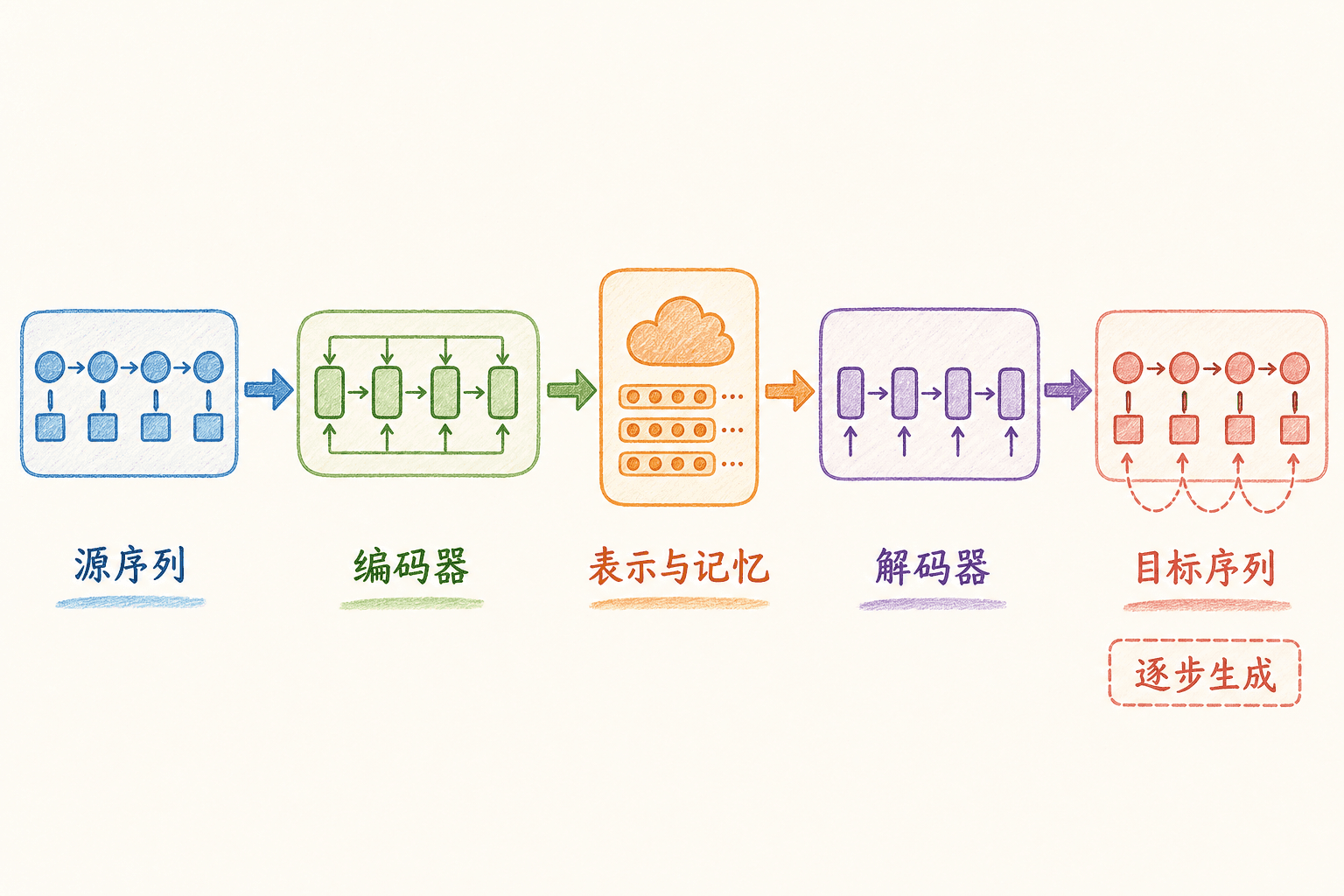
序列到序列任务到底在建模什么
给定输入序列 ,序列到序列模型要产生输出序列 。 与 不必相等,这一点把机器翻译、摘要、对话回复、语音识别后的文本生成等任务统一到了同一个框架里。
生成模型通常把整条输出序列的条件概率分解为一串“下一个 token”的概率:
这里的 表示 到 。这条公式看起来平常,却同时决定了训练和推理的基本形态。
- 训练时,数据集已经给出完整目标序列,我们可以并行或逐步计算每个位置的条件概率。
- 推理时,真实目标不存在,模型必须把自己已经生成的 token 当作后续条件。
- 序列得分是各步对数概率之和,而不是只看最后一步。
加入开始标记 <bos> 和结束标记 <eos> 后,一条目标序列会变成:
text
输入给解码器:<bos> 我 喜欢 深度 学习
监督目标: 我 喜欢 深度 学习 <eos>这其实是目标序列整体右移一位。模型在每个位置看到“前缀”,学习预测紧随其后的 token。若词表大小为 ,解码器每一步通常输出 个 logits,再用交叉熵约束正确 token 的 logit。
为什么要显式建模结束标记
如果没有 <eos>,模型只能依赖一个外部设定的最大长度停下。学习 <eos> 后,停止也成了一个预测决策。不过,这并不保证停止一定合理:模型仍可能过早结束、迟迟不结束,或者因长度偏好产生过短输出。后面讲 beam search 时会再回到这个问题。
“序列到序列”描述的是输入输出结构,不限定内部网络。编码器和解码器可以是 RNN、CNN、Transformer,也可以是不同结构的组合。
1
把 p(y|x) 自回归分解后,第 t 步主要预测什么?
2
序列到序列任务要求输入长度与输出长度相同。
经典编码器—解码器如何传递信息
2014 年的经典 Seq2Seq 工作使用一个多层 LSTM 读取输入,再用另一个 LSTM 生成输出。编码器在每个时间步更新状态:
是源语言嵌入。最朴素的做法把最终状态 当作整条输入的表示,交给解码器初始化:
解码器随后不断接收前一个目标 token 的嵌入并更新状态:
如果编码器与解码器层数或隐藏维度不同,不能直接把状态硬塞过去。常见做法是增加一个投影层 ,或者分别映射 LSTM 的隐藏状态和记忆单元。
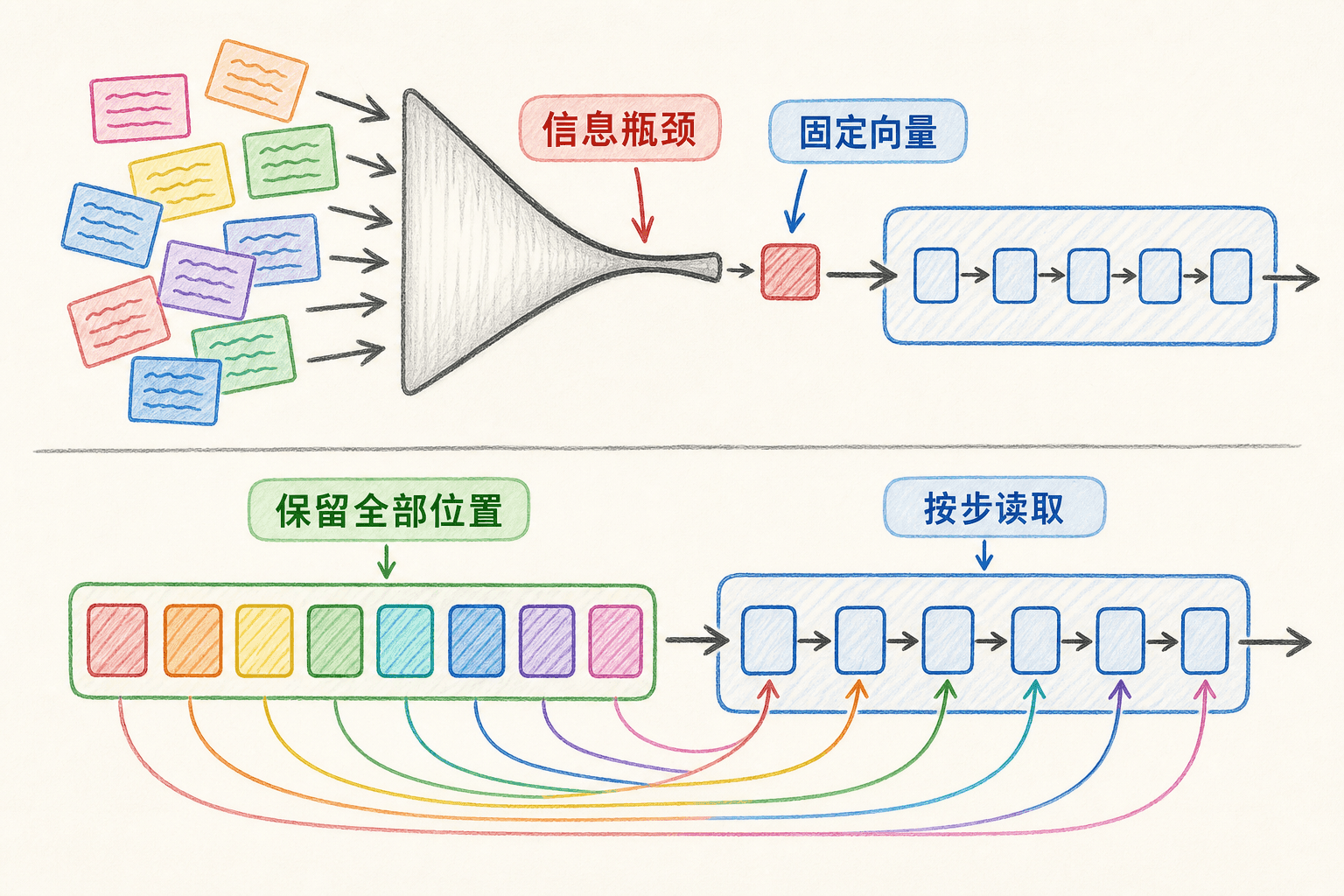
固定向量为什么会成为瓶颈
固定向量方案要求 同时保留句子中的实体、关系、语序和细节。输入变长后,所有信息都要穿过同一个窄口。Bahdanau 等人的工作正是从这个限制出发:不再要求解码器只依赖一个固定向量,而是保留每个源位置的编码表示,让解码器在每一步重新读取。
这里不要把论文结论简化为“LSTM 完全不能处理长句”。经典 Seq2Seq 论文在特定实验中取得了有效结果,还发现反转源句能缩短部分源—目标依赖,帮助优化。更准确的说法是:把整段输入压进单个固定向量会给表示与优化增加压力,注意力为解码器提供了一条更直接的读取路径。
形状先对账
采用 batch_first=True 时,可以把编码器输出记成:
是批大小, 是源序列长度, 是编码表示维度。若双向 RNN 每个方向的隐藏维度为 ,拼接后的 通常等于 。解码器单步状态可写为 。
python
import torch
from torch import nn
B, S, E, H = 16, 30, 256, 512
src_emb = torch.randn(B, S, E)
encoder = nn.GRU(E, H, batch_first=True, bidirectional=True)
encoder_outputs, encoder_state = encoder(src_emb)
print(encoder_outputs.shape) # (16, 30, 1024)
print(encoder_state.shape) # (2, 16, 512)encoder_outputs 保留所有位置,适合后续注意力;encoder_state 只保留每层、每方向的最终状态。两者不是同一个概念。
3
经典固定向量 Seq2Seq 中,信息瓶颈主要发生在哪里?
4
双向 GRU 每个方向 hidden_size=256,encoder_outputs 最后一维通常是多少?
Teacher forcing 为什么好用又危险
训练自回归解码器时,我们已知正确目标。最直接的做法是把真实的 输入第 步,而不是把模型刚预测的 输入进去。这就是 teacher forcing。
它的优势很实际:每一步都处在较合理的目标前缀上,训练信号稳定,早期预测错误不会立刻污染后面的所有状态。标准的 token 级负对数似然为:
是有效 token 掩码,padding 位置取 0。PyTorch 中常用 ignore_index=pad_id 让填充 token 不参与交叉熵。
训练与推理看到的前缀不同
推理时没有 ,模型只能使用自己的输出。如果某一步生成错误,下一步的条件就会偏离训练分布;偏差继续累积,后面的句子可能语法通顺却语义跑远。这种训练时依赖真实前缀、推理时依赖模型前缀的落差,常被称为暴露偏差。
可以把两条路径并排写出来:
text
训练:<bos> → 真实词1 → 真实词2 → 真实词3 → ...
推理:<bos> → 预测词1 → 预测词2 → 预测词3 → ...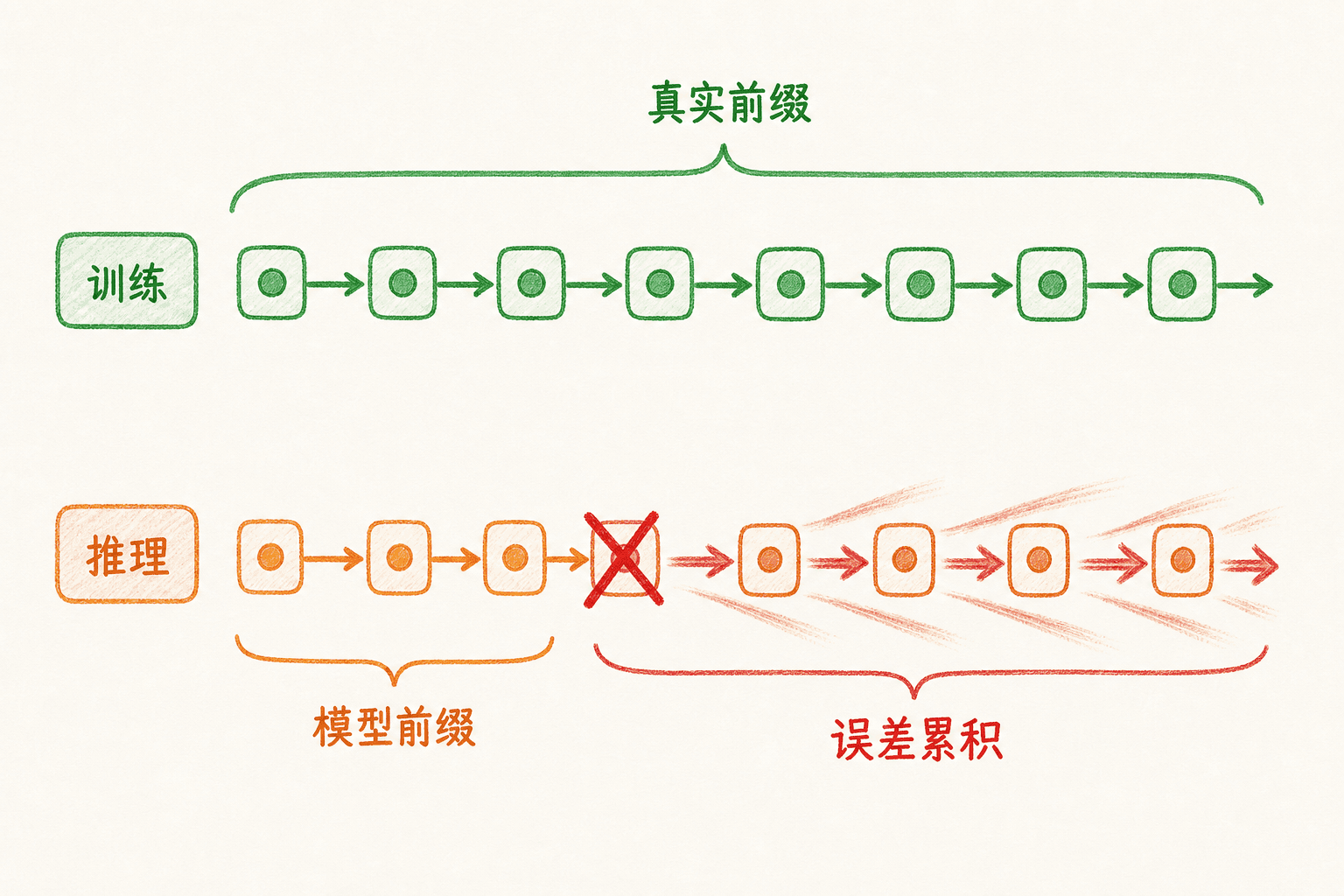
PyTorch 的 seq2seq 教程也提醒:teacher forcing 往往让训练更快,但模型可能在真实解码时不稳定。调整 teacher_forcing_ratio、scheduled sampling 等方法会让部分训练步骤改用模型输出,不过它们不是无条件更优的开关。使用何种训练目标,应通过开发集上的真实生成结果判断。
Transformer 也有同一类落差
Transformer 训练时能一次输入右移后的完整目标序列,但因果 mask 会阻止每个位置查看未来 token。它仍然是在真实目标前缀上计算损失;推理时仍然要逐步使用自己的生成结果。因此,“训练能并行”没有消除 teacher forcing 式的前缀分布差异。
python
# logits: (B, T, V),targets: (B, T)
loss = nn.functional.cross_entropy(
logits.transpose(1, 2),
targets,
ignore_index=pad_id,
)训练损失持续下降,只能说明模型更会在真实前缀下预测下一个 token。要判断生成是否可用,还必须运行与线上一致的自回归解码,并检查完整序列、停止行为和任务指标。
5
teacher forcing 训练第 t 步时,通常把什么作为解码器的前一个 token?
6
Transformer 训练可以并行处理目标位置,所以它天然不存在训练—推理前缀不一致。
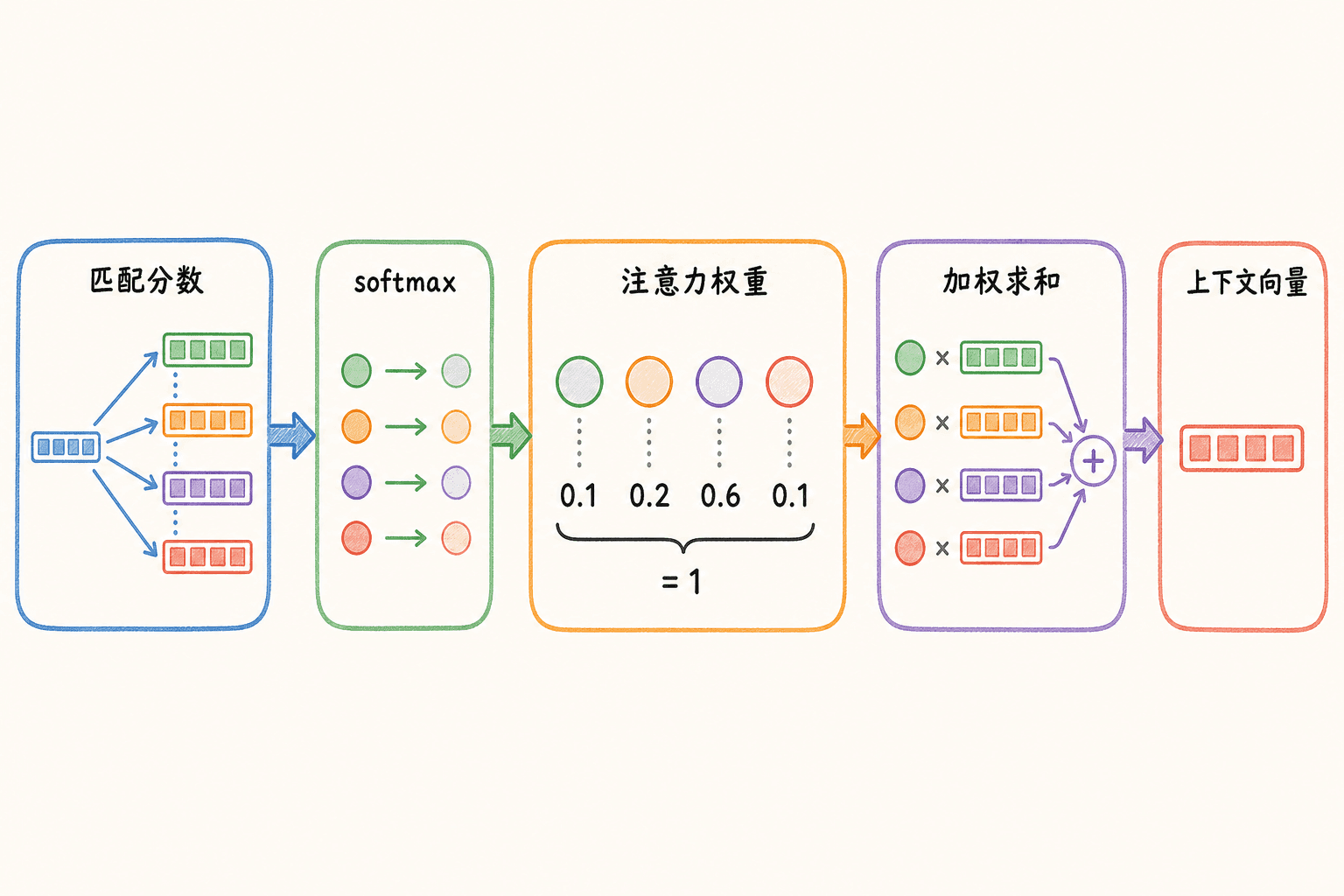
注意力如何从分数变成上下文向量
注意力的核心过程可以压缩成三步:算匹配分数、把分数归一化、按权重读取值。 在 RNN 编码器—解码器里,解码第 个 token 时,用解码状态去比较所有编码器表示。
Bahdanau 加性注意力常写成:
它用一个小前馈网络衡量解码状态 与源位置表示 的匹配程度。Luong 的全局注意力讨论了几种更直接的评分函数,例如点积:
若两边维度不同,可以加入可学习矩阵:
得到每个源位置的分数后,在源序列轴做 softmax:
最后用权重对编码器表示求和:
是当前解码步的上下文向量。它不是永久固定的“句子向量”,而是随 改变的读取结果。生成不同目标 token 时,模型可以读取不同源位置。
softmax 应沿哪一维
如果分数张量是 scores.shape == (B, T, S),其中 是目标长度、 是源长度,那么每个目标位置需要在所有源位置之间分配权重,softmax 应沿最后一维:
python
# query: (B, T, D), keys/values: (B, S, D)
scores = torch.matmul(query, keys.transpose(-2, -1))
weights = torch.softmax(scores, dim=-1) # 在 S 轴归一化
context = torch.matmul(weights, values) # (B, T, D)若误在目标轴 dim=1 上归一化,代码仍能运行,权重也仍在某个方向和为 1,但语义已经错了。注意力调试时,“能跑”远远不够,必须检查轴。
注意力图能解释到什么程度
权重矩阵能显示某个查询在这次前向计算中如何混合各位置的 value,因此它是很有用的诊断信号。但高权重不自动等同于人类意义上的因果解释;多层、多头和后续非线性还会继续改变信息。更稳妥的用法是把注意力图和输入扰动、错误样例、输出变化一起看。
7
scores 的形状是 (B,T,S) 时,为每个目标位置在源位置上分配注意力,应在哪一维做 softmax?
8
上下文向量 c_t 在整条目标序列的所有解码步中保持不变。
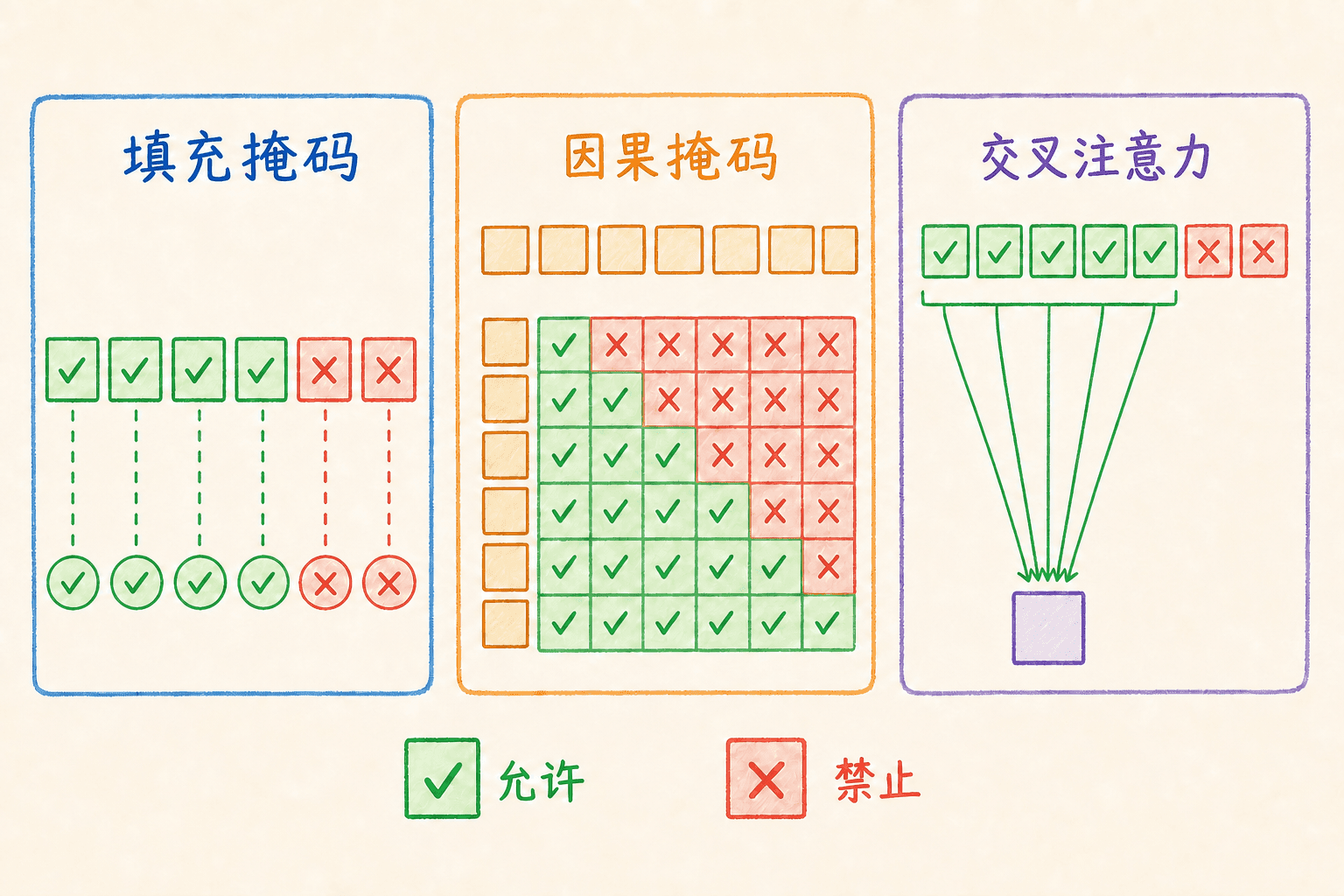
Mask 决定模型哪些位置根本不能看
真实批次往往包含不同长度的序列。为了组成规则张量,我们会用 <pad> 补齐短序列。padding 只是排版,不是语义内容,因此不能让它进入注意力分母,也不能让它贡献训练损失。
假设某条源序列有效长度为 3、补齐长度为 5,其 key padding mask 可以写成:
text
token: A B C <pad> <pad>
mask: False False False True True对布尔掩码语义为“True 表示禁止”的 PyTorch nn.MultiheadAttention,可以直接传入形状为 的 key_padding_mask。若手写分数,则常在 softmax 前把禁止位置设为负无穷:
经过 softmax 后,被屏蔽位置的权重为 0。
因果 mask 解决的是另一件事
目标端自注意力在训练时一次接收整条右移目标序列。若不加因果 mask,第 个位置会直接看到 及更后的真实 token,训练就发生了标签泄漏。
长度为 4 的目标序列,允许关系应是下三角:
text
查询\键 1 2 3 4
1 ✓ × × ×
2 ✓ ✓ × ×
3 ✓ ✓ ✓ ×
4 ✓ ✓ ✓ ✓padding mask 与因果 mask 不能混为一谈:
key_padding_mask通常随样本变化,屏蔽补齐位置。attn_mask或 causal mask 通常随位置关系变化,屏蔽未来位置。- 交叉注意力一般需要源端 padding mask,但通常不需要因果地屏蔽源序列,因为解码器可以查看全部已编码输入。
PyTorch 不同接口的布尔语义要核对
PyTorch 官方文档明确提示:nn.Transformer 中布尔 mask 的 True 表示该位置不允许参与注意力,而 torch.nn.functional.scaled_dot_product_attention 的布尔 attn_mask 语义与之不同。工程上不要凭记忆拼 mask;应查看当前调用接口与版本文档,并用一个四五个 token 的小矩阵做单元测试。
python
pad_mask = src.eq(pad_id) # (B, S),True 表示需忽略
causal_mask = torch.triu(
torch.ones(T, T, dtype=torch.bool, device=tgt.device),
diagonal=1,
) # 对 nn.MultiheadAttention:True 表示禁止查看若训练时忘记目标因果 mask,损失可能下降得异常快,甚至几乎完美;推理时模型却完全不可用。因为训练阶段已经偷看了要预测的 token,这不是模型学得好,而是数据泄漏。
9
下列哪些位置通常应该被屏蔽?
10
只要张量形状相同,PyTorch 所有注意力接口的布尔 mask 语义都完全一致。
贪心与 Beam Search 都只是在近似搜索
模型给出了每一步的条件概率,但我们还要从指数级的序列空间中选出一条输出。长度最多为 、词表大小为 时,粗略搜索空间可达 ,穷举不可行。
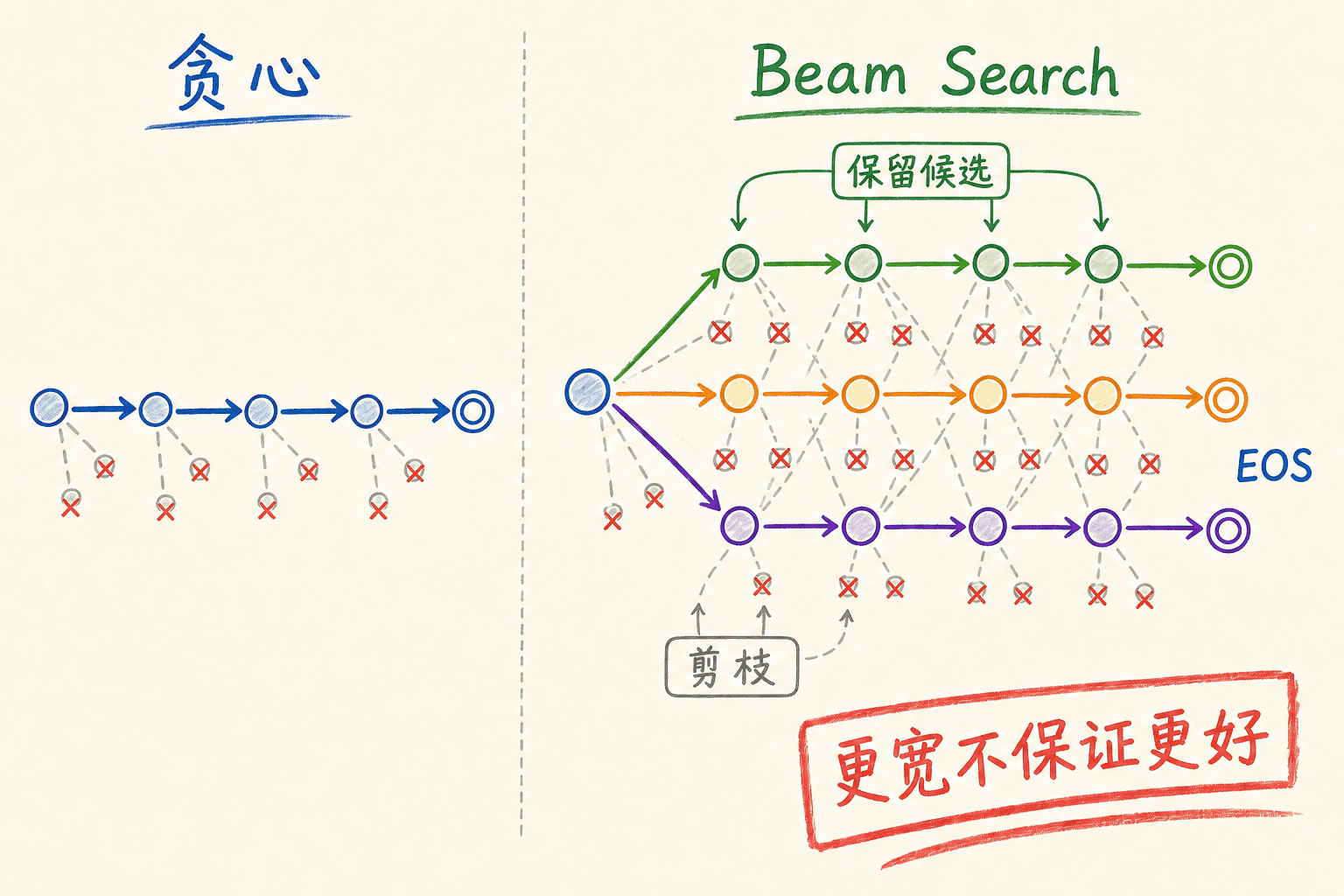
贪心解码
贪心解码在每一步选择当前概率最高的 token:
它速度快、实现简单,是很好的基线。但局部最佳不保证整条序列得分最高。某个略低概率的开头,可能通向后续一串高概率 token;贪心一旦剪掉它,就没有机会回头。
Beam search
Beam search 每一步保留 个候选前缀。扩展后,把累计分数最高的 个继续向前搜索:
beam_size=1 就退化为贪心。 增大通常会增加计算与显存开销,也会扩大搜索范围,但它仍是剪枝搜索,不保证找到全空间的真正最优序列。
为什么原始累计分数偏爱短序列
对数概率通常不大于 0。序列每延长一步,累计值往往更负,因此过早生成 <eos> 可能占便宜。实践中常使用长度归一化、长度惩罚或任务相关重排序。一个常见形式是:
不是越大越好,应该在开发集上选择。停止条件也会影响结果:是出现第一个完成候选就停,还是等当前未完成候选不可能超越最佳完成候选再停?这些细节会改变质量与延迟。
beam 更宽不保证输出更好
研究中观察到,某些神经机器翻译系统在 beam 过宽时质量反而下降,问题与长度偏好、模型概率校准和停止准则有关。Beam search 优化的是模型赋予的序列分数,不是直接优化“事实正确”“翻译自然”或某个业务指标。如果模型分布本身有偏差,更强的搜索可能更忠实地暴露这个偏差。
python
def normalized_score(log_prob_sum, length, alpha=0.6):
return log_prob_sum / (max(length, 1) ** alpha)11
beam_size=1 时,标准 beam search 等价于哪种策略?
12
只要不断增大 beam_size,生成质量就一定单调提高。
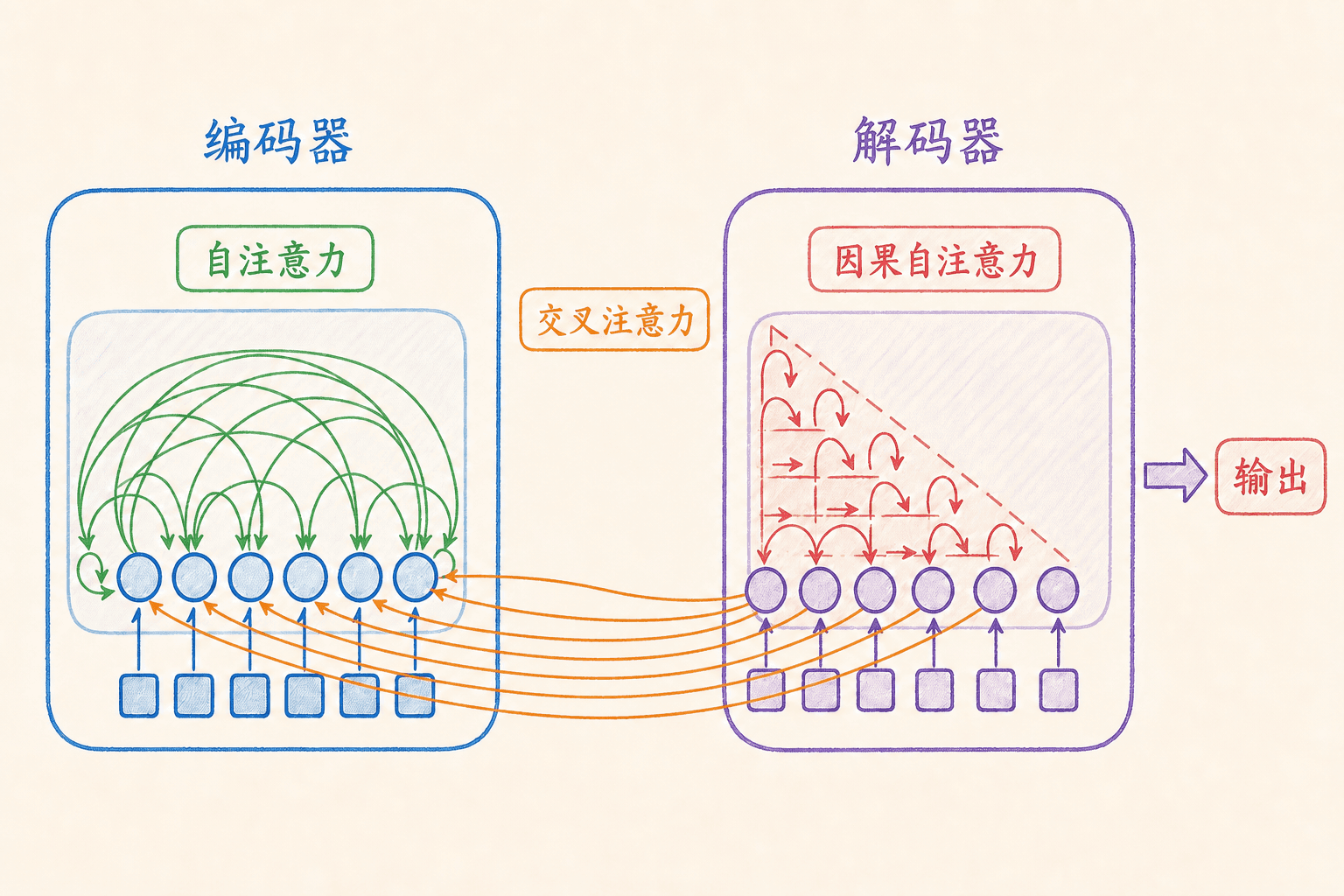
自注意力把同一序列变成查询、键和值
RNN 注意力通常让解码状态查询编码器输出。Transformer 把这个计算抽象成查询(Query)、键(Key)和值(Value)。可以把它理解成一次可微分检索:查询和键决定“匹配多少”,值决定“实际取回什么”。
对输入表示矩阵 ,先做三个线性投影:
缩放点积注意力为:
是可选 mask。允许位置加 0,禁止位置加一个足够大的负值或负无穷。
为什么要除以根号 d_k
如果查询与键的各维大致独立、方差相近,点积的尺度会随维度 增长。数值过大时,softmax 容易进入很尖锐的区域,梯度变小。除以 是为了控制分数尺度,使训练更稳定。
三类注意力在 Transformer 中如何对应
- 编码器自注意力: 都来自源序列表示,通常只需屏蔽源 padding。
- 解码器自注意力: 都来自目标前缀,必须使用因果 mask,并处理目标 padding。
- 编码器—解码器交叉注意力: 来自解码器, 来自编码器输出;它让每个目标位置读取源序列。
自注意力摆脱了 RNN 沿时间步的递归依赖,训练时可以并行计算多个位置。不过标准注意力的分数矩阵是 ,计算量和显存占用会随序列长度近似二次增长。并行不等于免费。
PyTorch 的 scaled_dot_product_attention 还要求调用者显式处理评估阶段的 dropout:该函数会按传入的 dropout_p 应用 dropout,因此模块处于评估模式时通常要传 0.0。它的布尔 attn_mask 中 True 表示允许参与注意力,恰好与 MultiheadAttention 中“True 表示屏蔽”的常用布尔语义相反。
python
import math
import torch
def scaled_dot_product_attention(q, k, v, blocked=None):
scores = q @ k.transpose(-2, -1) / math.sqrt(q.size(-1))
if blocked is not None:
scores = scores.masked_fill(blocked, float("-inf"))
weights = torch.softmax(scores,
13
在交叉注意力中,Q、K、V 通常分别来自哪里?
14
缩放点积注意力为什么除以 sqrt(d_k)?
多头注意力与位置编码各自补什么
单个注意力头只在一组投影空间里计算关系。多头注意力把表示投影到多个子空间,分别计算后再拼接:
若模型维度为 、头数为 ,常让每头维度 。因此 通常要能被 整除。
“多头会分别学习语法、指代、位置”可以当直觉,但不应当成固定分工。头之间可能冗余,具体行为取决于训练数据和目标。工程上更可靠的检查是:维度是否正确、mask 是否广播到所有头、返回的权重是否被平均,以及改动头数是否真正改善开发集指标。
注意力本身不知道顺序
如果只对一组 token 做不带位置信息的自注意力,同时以相同方式重排输入,输出也会随之重排;模型没有“第一个”“相邻”“相距三步”的先验。Transformer 因此要给 token 表示加入位置信息。
原论文使用正弦、余弦位置编码:
位置编码与 token 嵌入相加后送进网络。现代模型也常使用可学习绝对位置、相对位置偏置或旋转位置编码等方案。这里的稳定认识是:模型必须以某种方式接收顺序或相对位置信息,具体方案则是架构选择。
残差、归一化和前馈层没有消失
Transformer 层不只包含注意力。每个位置还会经过前馈网络,子层外有残差连接和归一化。简化表示为:
注意力负责位置之间的信息交换,前馈层对每个位置独立变换特征。二者承担不同角色。
python
from torch import nn
mha = nn.MultiheadAttention(
embed_dim=512,
num_heads=8,
batch_first=True,
)
out, weights = mha(
query=q, # (B, T, 512)
key=memory, # (B, S, 512)
value=memory, # (B, S, 512)
key_padding_mask=src_pad_mask,
如果只需要输出而不需要画注意力图,把 need_weights=False 通常更利于 PyTorch 选择优化后的缩放点积注意力路径。若同时传 attn_mask 与 key_padding_mask,还要让两者类型保持一致。
15
不加入任何位置信息的自注意力天然知道 token 的绝对先后顺序。
16
一个标准 Transformer 层通常还包含哪些结构?
Transformer 编码器—解码器怎样训练与生成
完整 Transformer 翻译模型仍保留“编码器读取源序列、解码器生成目标序列”的分工。变化在于两边都用堆叠注意力层处理。
训练路径
- 源 token 经过嵌入与位置编码,进入编码器;源 padding mask 阻止模型读取补齐位置。
- 目标序列右移一位,以
<bos>开头,经过嵌入与位置编码进入解码器。 - 解码器自注意力同时使用目标因果 mask 和目标 padding mask。
- 解码器交叉注意力读取编码器 memory,并使用源 padding mask。
- 输出投影得到 logits,与未右移的真实目标计算交叉熵。
python
transformer = nn.Transformer(
d_model=d_model,
nhead=num_heads,
num_encoder_layers=6,
num_decoder_layers=6,
batch_first=True,
)
hidden = transformer(
src=src_embed,
tgt=tgt_input_embed,
tgt_mask=causal_mask,
src_key_padding_mask=src_pad_mask,
tgt_key_padding_mask
请注意:上面是用于理解结构的参考写法。PyTorch 官方把 nn.Transformer 定位为基础参考实现;生产项目还要结合具体版本、性能内核、缓存策略和生态中的更高层实现。
推理路径
推理时,编码器通常只运行一次,得到源序列 memory。解码器从 <bos> 开始:每生成一个新 token,就把它追加到目标前缀,再预测下一步,直到生成 <eos> 或达到长度上限。
python
generated = torch.full((B, 1), bos_id, device=device)
for _ in range(max_new_tokens):
logits = model.decode(generated, memory, src_pad_mask)
next_token = logits[:, -1].argmax(dim=-1, keepdim=True)
generated = torch.cat([generated, next_token], dim=1)
if torch.all(next_token.squeeze(1).eq(eos_id)):
这段代码能表达逻辑,却会重复计算旧前缀。实际部署通常缓存每层历史 key/value,避免每一步重新处理全部过去 token。缓存不会改变因果关系,只是复用已经算过的中间结果。
并行边界要说准确
训练时,目标各位置在因果 mask 下可以并行计算。自回归推理时,第 个 token 依赖第 个生成结果,时间维仍然是串行的。批次、注意力头和矩阵运算可以并行,但 token 步之间的依赖没有消失。
17
Transformer 解码器训练时,目标序列为什么要右移并加因果 mask?
18
Transformer 在自回归推理时可以一次独立算出所有未来 token。
用可观察证据调试序列生成系统
序列模型最棘手的情况不是直接报错,而是损失正常、输出也像句子,却在掩码、停止或数据对齐上悄悄出问题。下面给出一套从便宜检查到真实生成的诊断顺序。
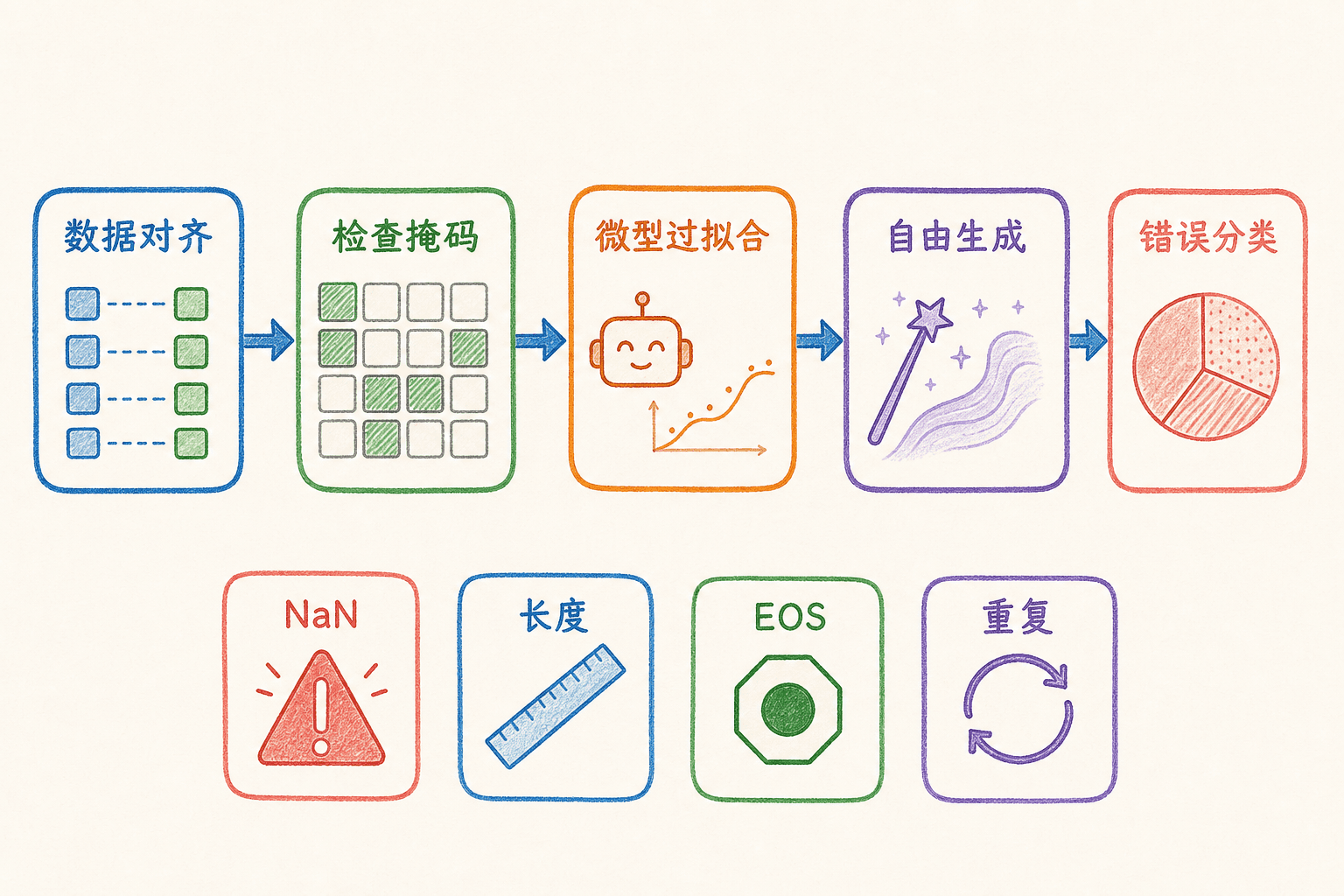
先用极小批次验证数据对齐
取两三条样本,直接打印 src、tgt_input 和 tgt_target。确认:
tgt_input以<bos>开头;tgt_target以<eos>结束;- 二者恰好错开一位;
- padding 只出现在有效内容之后;
- tokenizer、词表和 special token id 在训练与推理阶段一致。
这一关不通过,调模型没有意义。
再检查 mask 与注意力
用长度为 4 的人工序列,打印合并后的 mask 和 softmax 后权重。应满足:
- 被屏蔽位置权重接近 0;
- 每个查询在允许的键位置上权重和接近 1;
- 目标第 1 个位置不能看第 2、3、4 个位置;
- 不同样本的 padding 边界按各自长度变化;
- 没有整行全被屏蔽,否则 softmax 可能产生
NaN。
让模型过拟合一个微型数据集
选 16 到 64 条短样本,关闭多余正则,观察模型能否几乎记住训练集。若做不到,优先排查标签错位、mask、损失轴、学习率和梯度,而不是先扩大模型。
若能记住训练集却不能泛化,再看数据划分、领域偏移、正则化和模型容量。
把 teacher-forced 指标与自由生成分开
至少同时记录两组结果:
建议固定一组探针样例,每次实验都比较:漏译、重复、过早 <eos>、超长不停止、专有名词错误、数字错误、源文复制和幻觉。只看一个平均分,很容易错过模式性退化。
数值和性能问题也要分层定位
- 出现
NaN:检查是否存在全屏蔽注意力行、学习率过高、混合精度溢出或无效目标。 - 显存异常增长:检查序列长度、注意力矩阵、是否保留计算图、推理时是否忘记
no_grad。 - 推理越来越慢:检查是否重复计算完整前缀、KV cache 是否生效、完成序列是否仍在批次中继续扩展。
- 输出总是很短:检查
<eos>概率、训练长度分布、beam 长度惩罚和停止条件。 - 输出大量重复:比较贪心、beam 与采样,查看模型分布是否过尖、前缀错误是否累积,并检查数据重复与解码约束。
最有效的调试不是一次看几十个指标,而是让每个假设都能被一个小实验推翻:去掉 mask 会怎样、换成全相同长度会怎样、只训练 32 条样本会怎样、贪心和 beam 的长度分布差在哪。可证伪的检查比“再调一轮超参数”更快。
19
训练损失正常下降,但自由生成很差时,哪些检查最直接?
20
定位序列模型实现错误时,最适合作为早期检查的是哪一项?