标记、导出与多平台发布镜像
镜像只有能被可靠识别和传递,才算交付物。这一节先在不依赖账号的情况下完成标签、导出和加载,再说明怎样发布到 Registry,以及 arm64 与 amd64 的差异。
知识点:标签不是复制镜像
下面的命令给同一镜像增加一个名字:
shell
$ docker tag docker-task-api:1.0 docker-task-api:stable
$ docker image ls docker-task-api \
--format 'table {{.Repository}}\t{{.Tag}}\t{{.ID}}'
REPOSITORY TAG IMAGE ID
docker-task-api 1.0 1cbf65b021c2
docker-task-api stable 1cbf65b021c2两个标签指向同一镜像 ID,不会把所有层再复制一份。版本标签应描述可追溯版本,例如 1.0.0 或提交 SHA;latest 只是普通标签,不等于最新构建的证明。
仓库、标签、镜像 ID 与摘要各管一层
以 registry.example.com/team/task-api:1.0.0 为例:
text
registry.example.com / team/task-api : 1.0.0
Registry 仓库 标签- 仓库名组织同一个应用的一组版本。
- 标签是仓库中的可移动引用,方便人类选择版本。
- 镜像 ID 标识当前引擎镜像配置和根文件系统内容。
- Registry digest 是内容寻址引用,用于精确确认远端分发内容。
同一个标签被重新推送后可能指向新摘要;摘要引用不会因为标签移动而改变。一个实用的发布策略是同时推送人类可读版本标签和不可变的提交标签,部署与审计记录摘要。
为什么不要只推 latest
latest 没有自动排序含义,也不会告诉你对应源码、构建时间或兼容性。回滚时若只有 latest,你甚至无法可靠描述“上一个版本”。版本标签不是为了好看,而是建立源码、构建产物、测试结果和部署记录之间的追踪链。
实操:导出和加载镜像
docker save 保存镜像内容和标签,适合离线传递或短期备份:
shell
$ docker save -o docker-task-api-1.0.tar docker-task-api:1.0
$ ls -lh docker-task-api-1.0.tar
-rw------- 1 user staff 23M ... docker-task-api-1.0.tar先删除标签,再加载文件:
shell
$ docker image rm docker-task-api:1.0
$ docker load -i docker-task-api-1.0.tar
Loaded image: docker-task-api:1.0结果展示
shell
$ docker image inspect docker-task-api:1.0 \
--format '{{.RepoTags}}'
[docker-task-api:1.0]docker export 导出的是某个容器的文件系统快照,不保留镜像分层和构建元数据。分发镜像应使用 docker save/load 或 Registry,不要用 export/import 代替。
save/load 和 export/import 的对象不同
容器 export 不会把数据卷内容打进快照,因为卷是独立挂载;import 后还会缺失原镜像的许多配置语义。看到文件“都在”不代表它仍是可追溯、可维护的镜像交付物。
离线文件也要校验
tar 文件在复制过程中可能损坏或被替换。生成后记录哈希:
shell
$ shasum -a 256 docker-task-api-1.0.tar
<sha256> docker-task-api-1.0.tar接收方在 docker load 前重新计算并核对。这个哈希验证的是 tar 文件本身;加载后还应检查镜像 ID、标签和实际运行结果。
docker save 不是长期镜像仓库方案。它缺少 Registry 的访问控制、按层传输、版本索引和团队协作能力,也不会自动包含数据卷。离线包应有明确保管、校验和过期策略。
知识点:Registry 命名规则
推送到 Docker Hub 前,镜像名通常要带账号或组织名:
text
<账号>/docker-task-api:1.0.0发布流程是:
shell
$ docker login
$ docker tag docker-task-api:1.0 <账号>/docker-task-api:1.0.0
$ docker push <账号>/docker-task-api:1.0.0在自动化流程中使用访问令牌,不要把密码写进脚本或命令历史。推送后记录 Registry 返回的 digest,部署端可以用 镜像名@sha256:... 精确拉取。
push 为什么不会每次上传全部内容
Registry 也按内容摘要保存层。推送时客户端会检查远端已有内容,只上传缺失的层,再提交镜像 manifest。多个版本共享同一基础层时,存储和传输可以复用;这与设备上多个镜像共享层是同一类内容寻址思想。
manifest 像一张装配清单
单平台镜像 manifest 记录镜像配置对象和一组有序层摘要。Registry 通过仓库引用找到 manifest,客户端再按摘要取得缺失内容。多平台场景会在上层再有 image index,按平台指向多个 manifest。
text
标签 1.0.0
│
▼
多平台 image index
├─ linux/amd64 manifest ─► config + layers
└─ linux/arm64 manifest ─► config + layers登录凭证的最低要求
交互式登录优先让凭证进入系统凭证存储;自动化使用最小权限、短生命周期的访问令牌,通过受保护输入传递。不要把 docker login -p ... 写入脚本,命令行参数和历史记录可能泄露值。发布账号只应拥有所需仓库的 push 权限。
实操:建立可追踪的发布标签
假设当前发布版本是 1.0.0,源码提交短 SHA 为 a1b2c3d。先给同一镜像增加两个不可含糊的标签:
shell
$ docker tag docker-task-api:1.0 <账号>/docker-task-api:1.0.0
$ docker tag docker-task-api:1.0 <账号>/docker-task-api:git-a1b2c3d
$ docker image ls <账号>/docker-task-api \
--format 'table {{.Repository}}\t{{.Tag}}\t{{.ID}}'结果展示
两个标签的镜像 ID 应一致,说明它们引用同一构建结果。版本标签服务于发布语义,提交标签服务于源码追踪。真实流程还应把测试报告、构建日志和推送后的 digest 关联到同一发布记录。
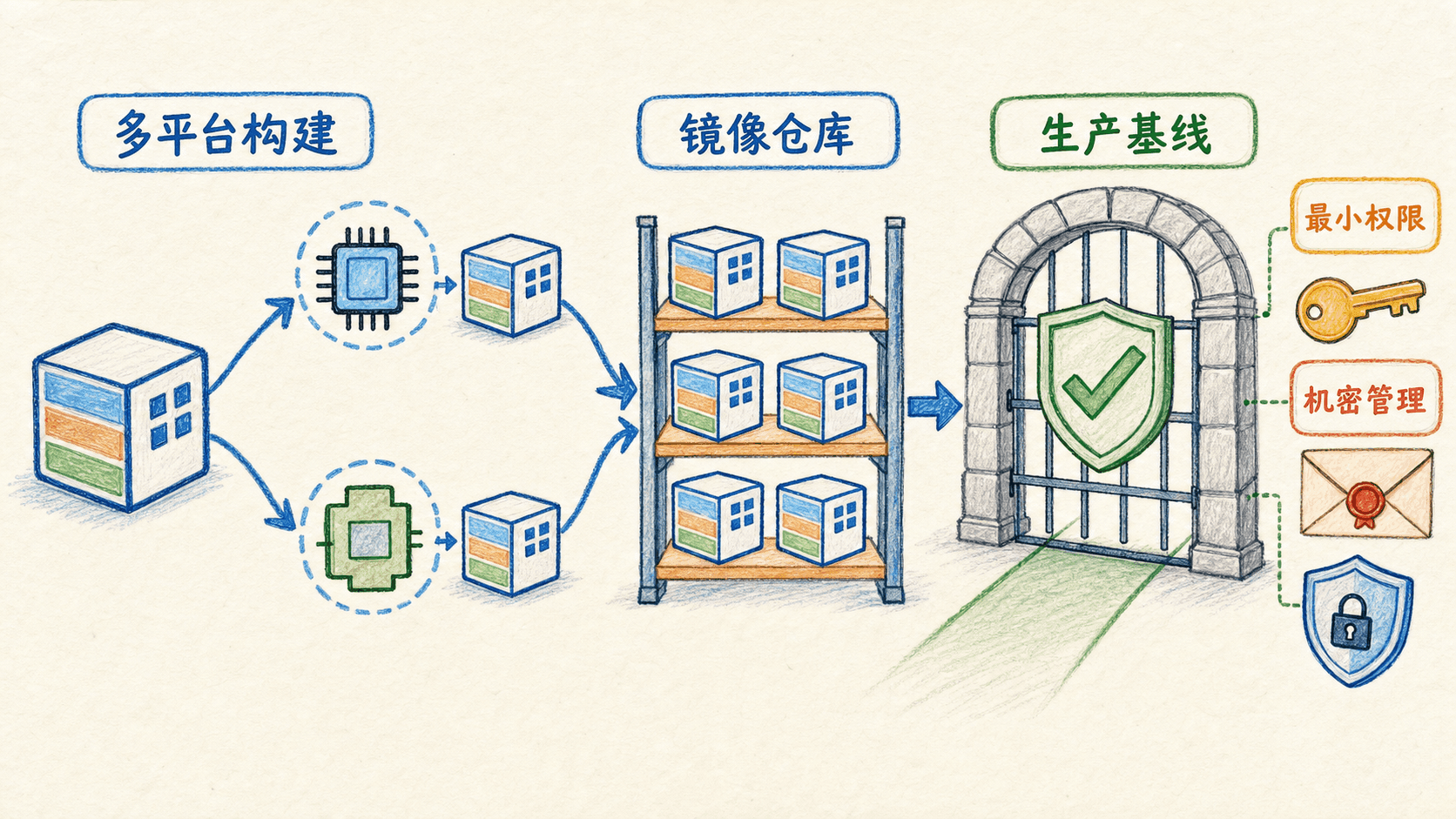
知识点:为什么需要多平台镜像
容器共享主机内核,应用二进制还必须兼容 CPU 架构。常见平台包括:
linux/amd64:常见 x86-64 服务器。linux/arm64:Apple 芯片、ARM 服务器和部分开发板。
多平台镜像在同一个标签下保存一份 manifest list,分别指向各平台镜像。拉取时,Docker 会选择匹配当前平台的版本。
“基础镜像支持多平台”还不够
完整构建链的每一部分都要支持目标平台:基础镜像需要对应 manifest,编译结果需要目标架构,构建脚本不能下载写死架构的二进制,运行依赖也必须兼容。本项目用 Go 编译,并显式设置 Linux 目标,比较适合多平台构建;若包含 C 依赖,交叉编译会更复杂。
三种构建策略的权衡
- 模拟执行:借助 QEMU 运行其他架构构建步骤,设置简单但编译较慢。
- 多原生节点:不同 CPU 节点各自构建对应平台,速度与兼容性更好,基础设施更复杂。
- 交叉编译:编译器直接输出目标架构程序,速度快,但需要确保依赖和构建脚本支持。
Buildx 可以把这些策略统一到 builder 与输出流程中。选择时看构建耗时、依赖复杂度和验证能力,而不是只追求一个命令覆盖所有平台。
先查看一个公开镜像的平台清单:
shell
$ docker buildx imagetools inspect redis:8-alpine
Name: docker.io/library/redis:8-alpine
MediaType: application/vnd.oci.image.index.v1+json
Manifests:
Platform: linux/amd64
Platform: linux/arm64/v8
...实操:构建多平台版本
要把多个平台放进同一标签,通常直接构建并推送:
shell
$ docker buildx build \
--platform linux/amd64,linux/arm64 \
-t <账号>/docker-task-api:1.0.0 \
--push .--push 是必要的,因为 Docker Engine 的普通镜像存储不适合同时载入多个平台版本。若只想在当前平台验证,可以使用:
shell
$ docker buildx build --platform linux/arm64 \
-t docker-task-api:arm64 --load .结果展示
shell
$ docker image inspect docker-task-api:arm64 \
--format 'os={{.Os}} arch={{.Architecture}}'
os=linux arch=arm64注意:如果当前设备不是 arm64,这条 --load 示例可能依赖模拟器,运行验证也可能更慢。只检查 .Architecture 证明元数据是 arm64,不等于应用在真实 arm64 机器上通过了全部功能测试。
推送多平台标签后,验收 image index:
shell
$ docker buildx imagetools inspect <账号>/docker-task-api:1.0.0
Name: docker.io/<账号>/docker-task-api:1.0.0
MediaType: application/vnd.oci.image.index.v1+json
Manifests:
Platform: linux/amd64
Platform: linux/arm64结果展示:怎样判断发布真正完成
至少核对四项:Registry 中标签存在;输出包含目标平台;记录顶层 digest;分别在目标平台拉取并完成健康请求。只看到 build 命令成功,还没有证明 Registry 内容、平台选择和运行功能都正确。
知识点:发布与回滚是一对动作
发布前就要知道怎样回滚。因为版本标签和摘要可追踪,回滚应当是把部署引用改回已验证的旧版本或旧摘要,再重建容器,而不是在故障现场重新编译“记忆中的旧代码”。
同时要把数据兼容性纳入回滚:镜像可以回退,Redis 数据格式或迁移未必自动回退。当前项目的数据结构简单,真实系统应在发布设计中明确前后版本兼容、迁移备份和恢复步骤。
一个最小发布记录应包括:源码提交、Dockerfile 与依赖锁、构建平台、版本标签、镜像 digest、测试结论和回滚目标。
模拟其他 CPU 架构通常比原生构建慢,尤其是编译和压缩任务。发布流程规模变大后,可以使用对应架构的原生构建节点,或利用 Go 这类语言的交叉编译能力。
发布前检查表
- 使用可追溯的版本标签,不只依赖
latest。 - 构建前确认依赖锁文件已提交。
- 为需要的 CPU 架构生成镜像。
- 推送后记录 digest,并验证 Registry 中的平台清单。
- 不在镜像层、标签或构建参数中泄露密钥。
- 在至少一个真实目标平台完成启动、健康检查和核心业务请求。
- 保存上一个已验证版本的标签与 digest,确认回滚路径可执行。