Go 函数:从调用契约到错误边界
程序真正变大以后,函数的价值不在于“少写几行重复代码”,而在于把边界说清楚:调用者交进来什么,函数保证返回什么,失败如何表达,资源由谁释放,意外状态又在哪里被截住。
这一页会沿着一次函数调用的完整生命周期来讲。我们先看签名和值传递,再走进递归调用栈、多返回值和错误链;然后把函数当作值,理解匿名函数、闭包和可变参数;最后用 defer、panic 与 recover 画出一条可靠的清理与故障边界。
阅读示例时,可以一直问三个问题:数据由谁拥有,失败由谁处理,清理动作在哪个函数返回时发生。只要这三件事能回答清楚,函数通常就不会写得含糊。
函数声明与调用契约
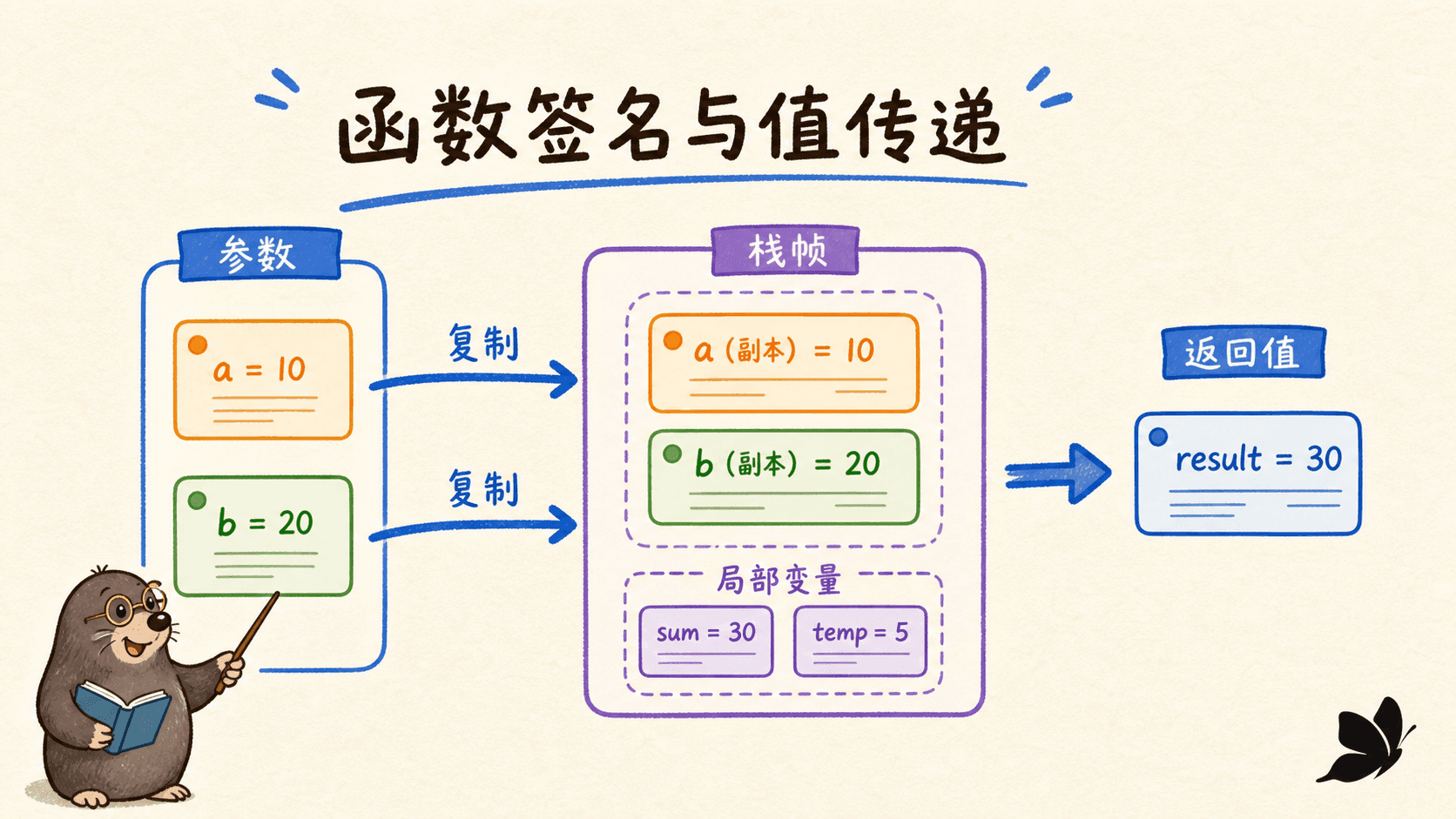
一份签名到底约定了什么
函数声明由 func、函数名、参数列表、结果列表和函数体组成:
go
func Divide(dividend, divisor int) (quotient int, remainder int) {
return dividend / divisor, dividend % divisor
}dividend 和 divisor 是形参;Divide(17, 5) 中的 17、5 是实参。连续参数类型相同时可以合并书写。只有一个未命名结果时通常省略括号;没有结果时直接省略结果列表。
函数类型由参数类型序列和结果类型序列决定,参数名、结果名以及是否合并书写都不参与类型判断。下面四个函数具有相同的类型 func(int, int) int:
go
func add(x int, y int) int { return x + y }
func sub(x, y int) (z int) { z = x - y; return }
func first(x int, _ int) int { return x }
func调用时必须按声明顺序提供每个实参。Go 没有默认参数,也没有按参数名调用。结果参数一旦命名,就会在函数进入时创建为局部变量并初始化为零值。
极少数底层函数声明没有 Go 函数体,这表示实现由汇编等外部机制提供;这类声明仍然定义完整签名。日常业务代码不应把“省略函数体”当成接口声明方式,接口行为应通过接口类型的方法集合表达。
1.1
下面哪一项会改变函数的类型?
值传递不等于“里面一定改不到外面”
Go 的参数传递始终是值传递:调用发生时,每个实参的值被赋给对应形参。修改一个普通数值参数,只会改函数自己的副本。
go
func addOne(n int) {
n++
}
func main() {
n := 10
addOne(n)
fmt.Println(n) // 10
}容易产生误会的是切片、映射、指针、通道和函数值。它们传进去的仍然是一个值的副本,只是这个值内部能定位到共享数据。复制切片只复制切片头;两个切片头仍可能指向同一底层数组,所以改元素可能被调用者看到。
go
func changeFirst(values []int) {
values[0] = 99 // 改共享底层数组,调用者可见
values = append(values, 100) // 改的是形参这份切片头
}
func main() {
values := []int{1, 2, 3}
changeFirst(values)
fmt.Println(values) // [99 2 3]
如果函数要替调用者更换整个切片,可以返回新切片,或接收 *[]T。工程上通常优先返回新值,因为所有权变化更直观。
1.2
把切片传给函数属于引用传递。
小节练习
写一个 Normalize(values []int) []int:返回一份每个元素都不小于零的新切片,不修改调用者的底层数组。
多返回值与清晰的 API
结果与状态一起返回
函数可以返回多个值。最常见的组合是“结果 + error”或“结果 + bool”:
go
func LookupPrice(prices map[string]int, name string) (int, bool) {
price, ok := prices[name]
return price, ok
}
func ParsePort(text string) (int, error) {
port, err := strconv.Atoi(text)
if err != nil
只有“找到 / 没找到”两种状态,并且不需要解释原因时,bool 足够。失败原因可能很多、调用者需要记录或分类时,返回 error。
多值调用可以直接转交:
go
func ParseServicePort(text string) (int, error) {
return ParsePort(text)
}也可以在多参数函数的唯一实参位置展开,例如 fmt.Println(ParsePort("8080"))。这种写法适合临时观察结果,业务代码里显式接收通常更容易继续处理。
2.1
哪些场景适合返回第二个 bool 结果?
命名结果与裸返回要克制
多个同类型结果有名字时,阅读调用契约会更轻松:
go
func SplitSeconds(total int) (hours, minutes, seconds int) {
hours = total / 3600
minutes = total % 3600 / 60
seconds = total % 60
return hours, minutes, seconds
}命名结果允许只写 return,称为裸返回。它在很短的函数或需要让 defer 修改结果时有用;一旦函数较长、结果较多,裸返回会迫使读者回头寻找当前结果变量的值。此时写全 return hours, minutes, seconds 更稳妥。
当函数返回非 nil 错误时,其他结果通常不应再使用,除非文档明确承诺了“结果可能部分有效”。io.Reader.Read 就是典型例外:它可能同时返回 n > 0 和非 nil 错误,调用者应先处理已读到的字节,再判断错误。
2.2
按 Go 的惯例,函数返回多个值时,错误值通常放在第 ____ 个位置。
小节练习
设计 MinMax(values []int) (min, max int, ok bool)。空切片返回 ok=false,非空切片返回最小值和最大值。
递归与调用栈
先写终止条件,再写递归关系
递归函数会直接或间接调用自己。树、目录、表达式和图的深度优先遍历,本身就是递归结构,用递归表达往往比手工维护栈更自然。
go
type Node struct {
Name string
Children []*Node
}
func Walk(n *Node, depth int) {
if n == nil { // 终止条件
return
}
fmt.Printf("%s%s\n", strings.Repeat(" ", depth), n.Name)
for _, child
检查递归代码时,先别急着在脑中展开几十层。只确认两件事:是否存在覆盖所有出口的终止条件;每次递归是否都让问题靠近终止条件。缺少任何一个,都会出现无限递归或栈耗尽。
3.1
递归函数最关键的两个结构是什么?
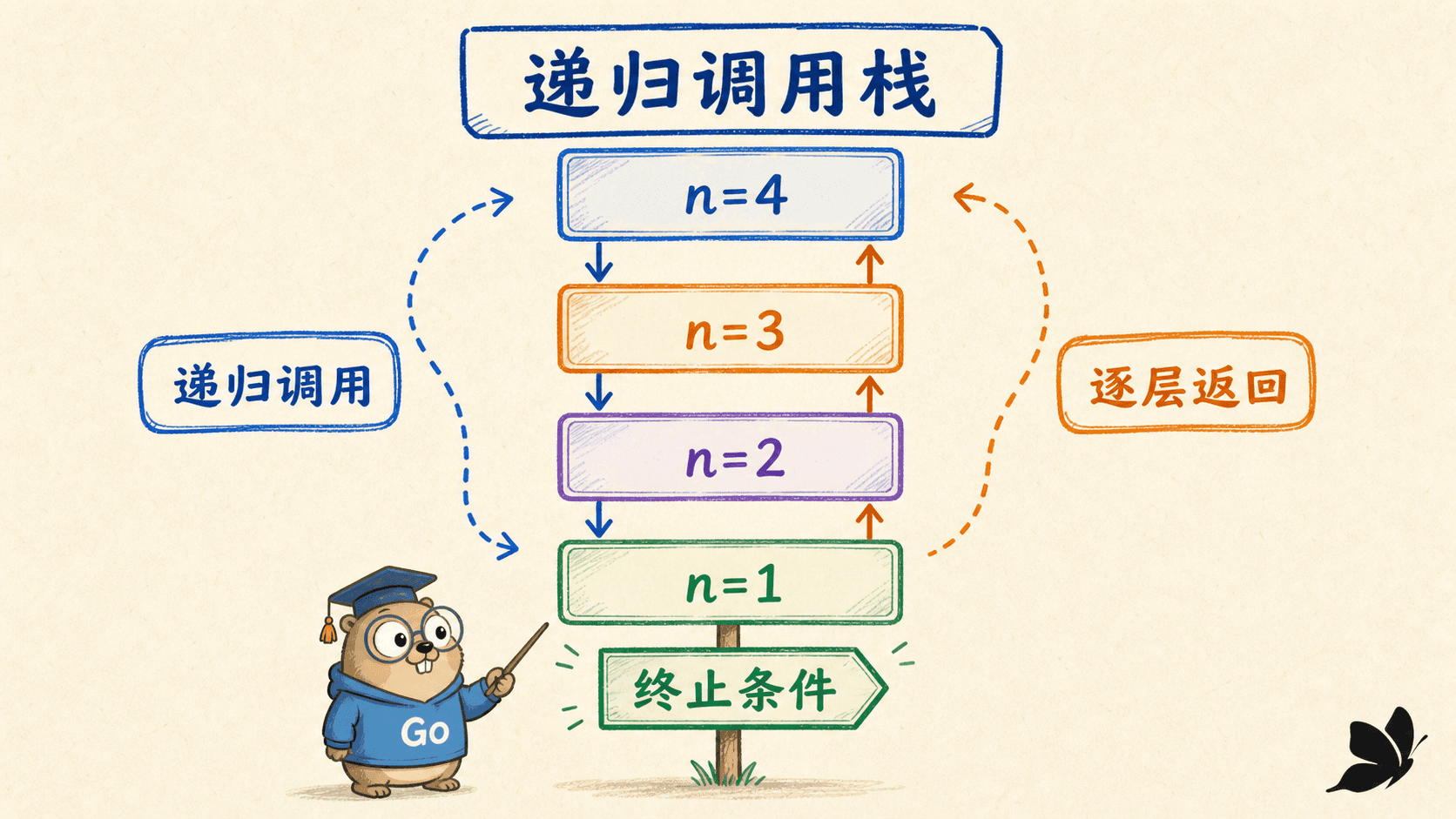
每次调用都有自己的活动记录
一次调用尚未返回时,运行时要保存参数、局部变量、返回位置等信息。递归深度增加,活动调用也会增加。下面的阶乘在下降阶段不断创建调用,在到达 n == 0 后逐层返回:
go
func factorial(n int) int {
if n == 0 {
return 1
}
return n * factorial(n-1)
}Go 的 goroutine 栈会按需要增长,但它不是无限资源。输入可能形成数十万层链表或恶意嵌套结构时,显式栈和循环通常更可控;它们也便于设置深度上限。递归还有另一个常见工程问题:图中存在环。此时需要 visited 集合,否则“问题规模看似变小”仍可能沿环路不断访问。
3.2
goroutine 的栈可以增长,所以递归深度不需要任何边界。
小节练习
把下面的链表求和改成循环版本,并比较两者的空间复杂度。
go
func Sum(n *NodeInt) int {
if n == nil {
return 0
}
return n.Value + Sum(n.Next)
}错误是值,也是 API 的一部分
error 契约与失败路径
error 是内置接口。nil 表示成功,非 nil 表示失败。因为错误是普通值,我们用 if、return、变量和类型系统处理它,而不是把常见失败藏在另一套控制流里。
go
func LoadConfig(path string) ([]byte, error) {
data, err := os.ReadFile(path)
if err != nil {
return nil, fmt.Errorf("load config %q: %w", path, err)
}
return data, nil
}先处理失败并尽早返回,成功路径就能保持在较浅的缩进层级。库函数通常返回错误;命令入口、请求边界或任务调度器再决定记录、重试、降级还是终止。
不要同时记录并返回同一个错误,除非这两个动作服务于不同责任。否则上层每传播一次就可能多打一条重复日志。一般让能够最终处理错误的边界记录一次。
4.1
一个通用库函数读文件失败时,通常最合适的做法是什么?
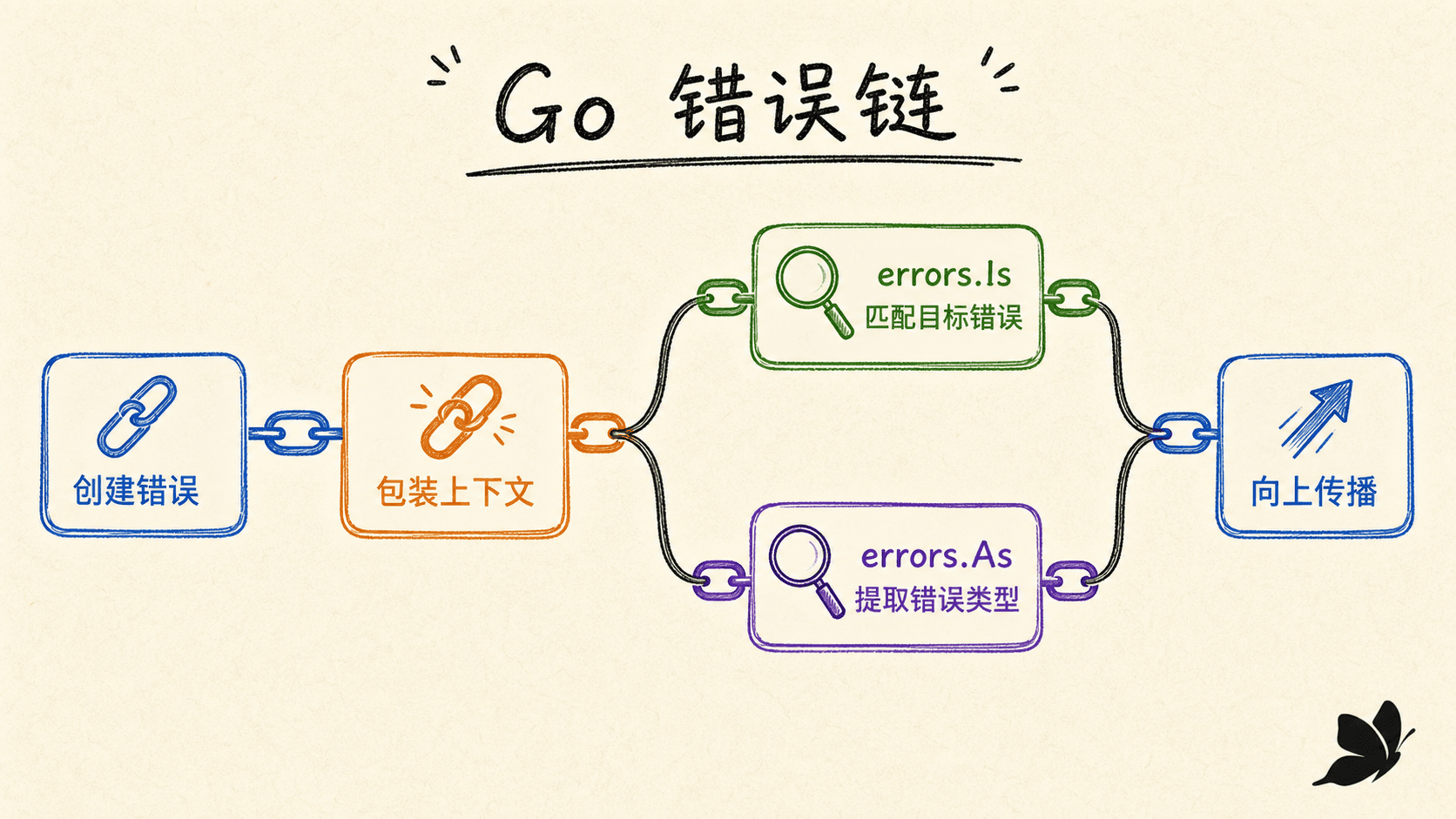
创建、包装与传播错误
固定错误可以用 errors.New 创建。要加入动态信息,用 fmt.Errorf。如果调用者还需要识别底层原因,使用 %w 包装,而不是 %v 只拼接文字。
go
var ErrNotReady = errors.New("service not ready")
func OpenProfile(path string) ([]byte, error) {
data, err := os.ReadFile(path)
if err != nil {
return nil, fmt.Errorf("open profile %q: %w", path, err)
}
return data,
错误信息通常使用小写开头,不在每层加句号或换行。每一层只补充自己掌握的新上下文:正在做什么、哪个对象失败。这样最外层打印一次时,会自然形成从业务动作到根因的因果链。
errors.Join 可以把多个独立失败组合成一棵错误树。例如关闭多个资源时,不必为了返回第一个错误而丢掉其他错误;errors.Is 和 errors.As 会遍历包装链或错误树。
4.2
希望保留底层错误供 errors.Is / errors.As 检查时,fmt.Errorf 应使用格式动词 ____。
按值、类型和行为分类
调用者需要分支处理时,常见分类方式有三种:
- 哨兵值:稳定、简单,例如
io.EOF、fs.ErrNotExist。用errors.Is检查,别依赖错误字符串。 - 具体类型:需要读取路径、偏移量等结构化字段。用
errors.As提取,例如*fs.PathError。 - 行为接口:调用者只关心“是否可重试”等能力,可以检查一个小接口,而不耦合具体类型。
go
func Explain(err error) string {
switch {
case err == nil:
return "成功"
case errors.Is(err, fs.ErrNotExist):
return "文件不存在"
}
var pathErr *fs.PathError
if errors.As(err, &pathErr) {
return "路径操作失败:" + pathErr.Path
错误是否值得公开包装,是 API 设计决定。包装某个底层哨兵值,等于允许调用者把它当成你 API 的稳定行为来判断;以后替换实现时也要考虑兼容这份承诺。
4.3
关于 errors.Is 与 errors.As,哪些说法正确?
重试、降级、终止与忽略
收到错误后,处理方式取决于责任边界:
- 能增加上下文但不能解决:包装并传播。
- 明确是短暂失败:在有次数、总时长和退避上限的前提下重试。
- 功能可选:记录一次并降级,同时让状态可观测。
- 程序无法继续:通常只在
main或请求边界决定退出。 - 确认不影响正确性:可以忽略,但最好用注释说明这是有意决定。
重试前必须先分类。语法错误、权限不足和参数非法不会因为多试几次就好;不加判断地重试只会扩大负载。对写操作重试还要考虑幂等性。
io.EOF 表示输入正常结束,不等同于“读取失败”。读取循环通常单独处理它。更稳妥的代码用 errors.Is(err, io.EOF),这样即使中间层包装了 EOF 也能识别。
4.4
任何网络错误都应该无限重试,直到成功。
小节练习
补全 ReadLabel:读到 EOF 正常结束;其他错误加上“read label”上下文后返回。
函数值与高阶函数
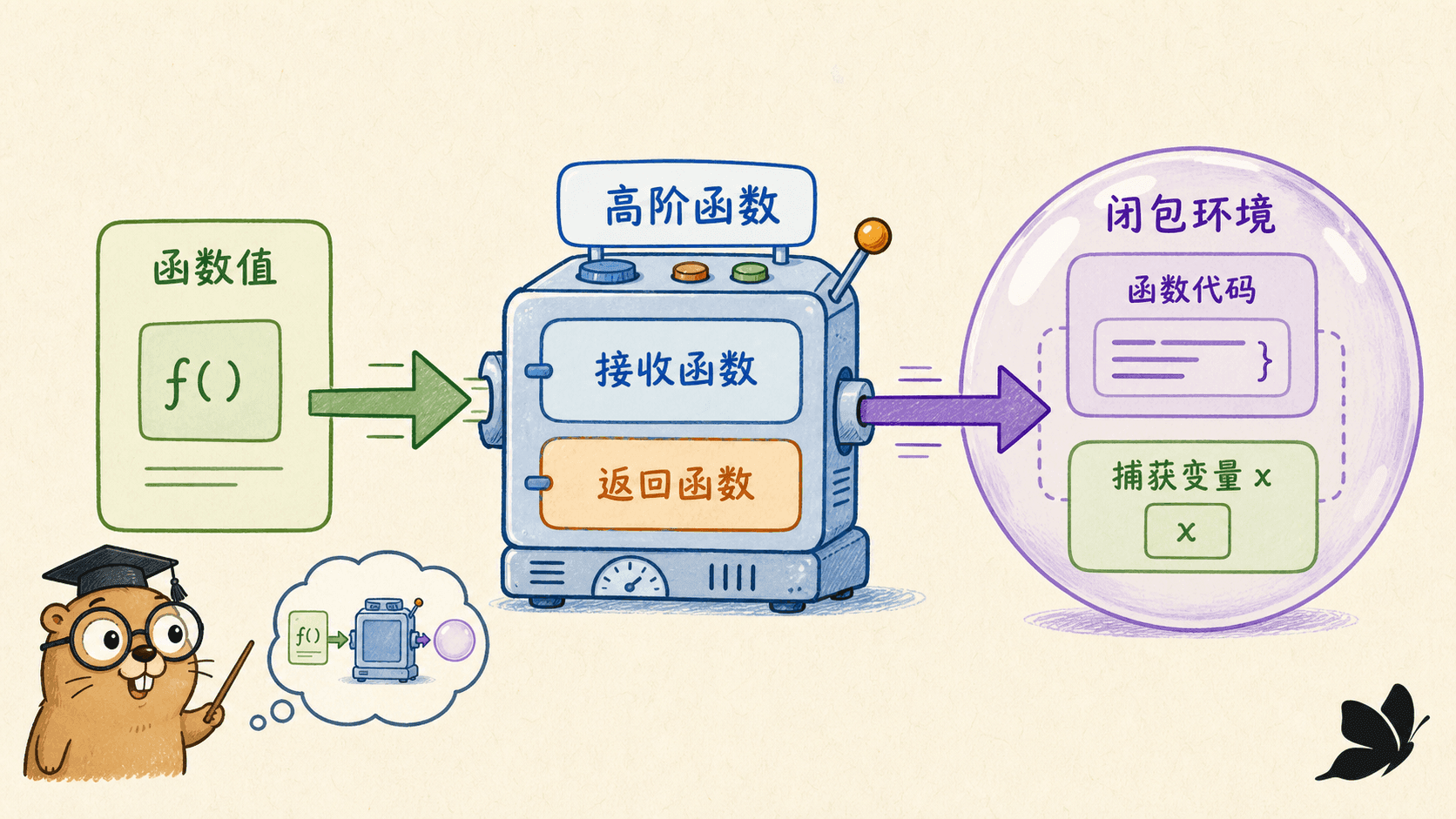
把行为当作参数
函数值有具体类型,可以赋给变量、传入函数,也可以从函数返回:
go
type Predicate func(int) bool
func Filter(values []int, keep Predicate) []int {
result := make([]int, 0, len(values))
for _, value := range values {
if keep(value) {
result = append(result, value)
}
Filter(values, isEven) 把遍历机制与筛选策略拆开。类似设计常见于排序比较器、中间件、访问器和回调。
函数类型的零值是 nil。调用 nil 函数会 panic,所以可选回调要么先判断,要么在构造阶段填入默认实现。函数值只能与 nil 比较,不能彼此比较,也不能作为 map 键。
5.1
函数值可以进行哪些操作?
可选回调与提前停止
高阶函数的接口不应只追求“万能”。遍历函数如果需要提前终止,就把这个能力写进回调结果:
go
func Visit(n *Node, fn func(*Node) bool) bool {
if n == nil {
return true
}
if !fn(n) {
return false
}
for _, child := range n.Children {
if !Visit(child, fn) {
return
这里 false 的语义是“停止整个遍历”,而不是“跳过当前节点”。这种约定必须通过命名和文档写清楚。如果回调还可能失败,可以把结果改为 error,用 nil 继续、非 nil 中止。
5.2
函数值的零值是 nil,直接调用它会产生 panic。
小节练习
实现 First(values []int, match func(int) bool) (int, bool),返回第一个匹配值。
匿名函数与闭包
闭包捕获的是变量,不是快照
函数声明只能出现在包级;函数表达式可以出现在任何表达式位置。匿名函数能够访问外层词法作用域中的变量:
go
func Counter(start int) func() int {
current := start
return func() int {
current++
return current
}
}
func main() {
a := Counter(0)
b := Counter(10)
fmt.Println
返回的函数不仅包含代码,还保留了对 current 的访问。Counter 已经返回,current 仍然存活;两次调用 Counter 会得到两套互不共享的状态。
闭包捕获的是变量本身,所以外层后续修改对闭包可见。需要固定快照时,把值作为参数传入一个立即调用的函数,或显式复制到新的局部变量。共享可变闭包被多个 goroutine 调用时,还需要锁或原子操作保护;“变量被藏在闭包里”并不会自动带来并发安全。
6.1
两次调用 Counter(0) 返回的闭包会怎样?
递归匿名函数要先声明变量
匿名函数若要调用自己,不能用短变量声明一步完成,因为变量在函数表达式内部尚未进入作用域:
go
var walk func(*Node)
walk = func(n *Node) {
if n == nil {
return
}
fmt.Println(n.Name)
for _, child := range n.Children {
walk(child)
}
}写成 walk := func(...) { walk(...) } 会在函数体中的 walk 处编译失败。先声明函数变量,再赋值,递归调用才能引用已经存在的绑定。
6.2
递归匿名函数通常要先用 var 声明函数 ____,再把函数表达式赋给它。
当前 Go 的循环变量捕获规则
这里必须按当前语言规则理解。Go 1.22 起,如果循环变量由 for 的初始化语句或 range 子句使用 := 声明,每次迭代都会有新的变量。下面三个闭包在当前语义下分别打印 alpha、beta、gamma:
go
names := []string{"alpha", "beta", "gamma"}
var printAll []func()
for _, name := range names {
printAll = append(printAll, func() { fmt.Println(name) })
}
for _, printName := range printAll {
printName()
}旧项目如果在模块中选择早于 Go 1.22 的语言版本,仍可能采用旧语义。还有一种当前代码也会共享变量的写法:循环变量在外面声明,循环里使用 = 反复赋值。
go
var name string
var printAll []func()
for _, name = range []string{"alpha", "beta", "gamma"} {
printAll = append(printAll, func() { fmt.Println(name) })
}
// 三个闭包都引用外面的同一个 name,最后都会看到 gamma。因此判断闭包是否安全,关键不是看到 range 就机械地写 name := name,而是确认变量在哪里声明、项目选择哪个语言版本、闭包何时执行。
6.3
当前 Go 中,只要 range 使用 := 声明迭代变量,每轮闭包就会捕获该轮的新变量。
小节练习
解释下面代码为什么连续返回 2、4、6,并说明 sum 的生命周期。
go
func accumulator() func(int) int {
sum := 0
return func(n int) int {
sum += n
return sum
}
}
add := accumulator()
fmt.Println(add(2), add(2), 可变参数函数
...T 在函数内部就是 []T
可变参数必须是最后一个参数。在函数体内,它的类型是切片:
go
func Sum(prefix string, values ...int) string {
total := 0
for _, value := range values {
total += value
}
return fmt.Sprintf("%s%d", prefix, total)
}
fmt.Println(Sum("总计:")) // 总计:0
fmt.Println已有切片时,在调用处用 ... 展开:
go
values := []int{2, 3, 5}
fmt.Println(Sum("总计:", values...))func(...int) 与 func([]int) 是不同的函数类型。前者允许调用者逐个提供参数,后者要求一个切片。API 设计时要看调用场景:参数天然来自集合时,直接收切片更清楚;参数通常只有少量、逐个书写更自然时,可变参数更顺手。
7.1
已有 nums := []int{1,2,3},如何传给 func Sum(nums ...int)?
空参数与 nil 语义要先定义
可变参数可以接收零个值。Max(values ...int) 在没有参数时应返回什么,不能靠猜。可以返回 (int, bool)、(int, error),或者把第一个参数设为必填:
go
func Max(first int, rest ...int) int {
max := first
for _, value := range rest {
if value > max {
max = value
}
}
return max
}...any 很灵活,但会放弃一部分静态类型约束。除格式化、日志和确实异构的参数外,优先使用具体元素类型。
7.2
设计可变参数 API 时,应明确哪些问题?
小节练习
实现至少接收一个字符串的 JoinNonEmpty(first string, rest ...string) string,忽略空字符串并用逗号连接。
defer:把清理动作贴在资源获取之后
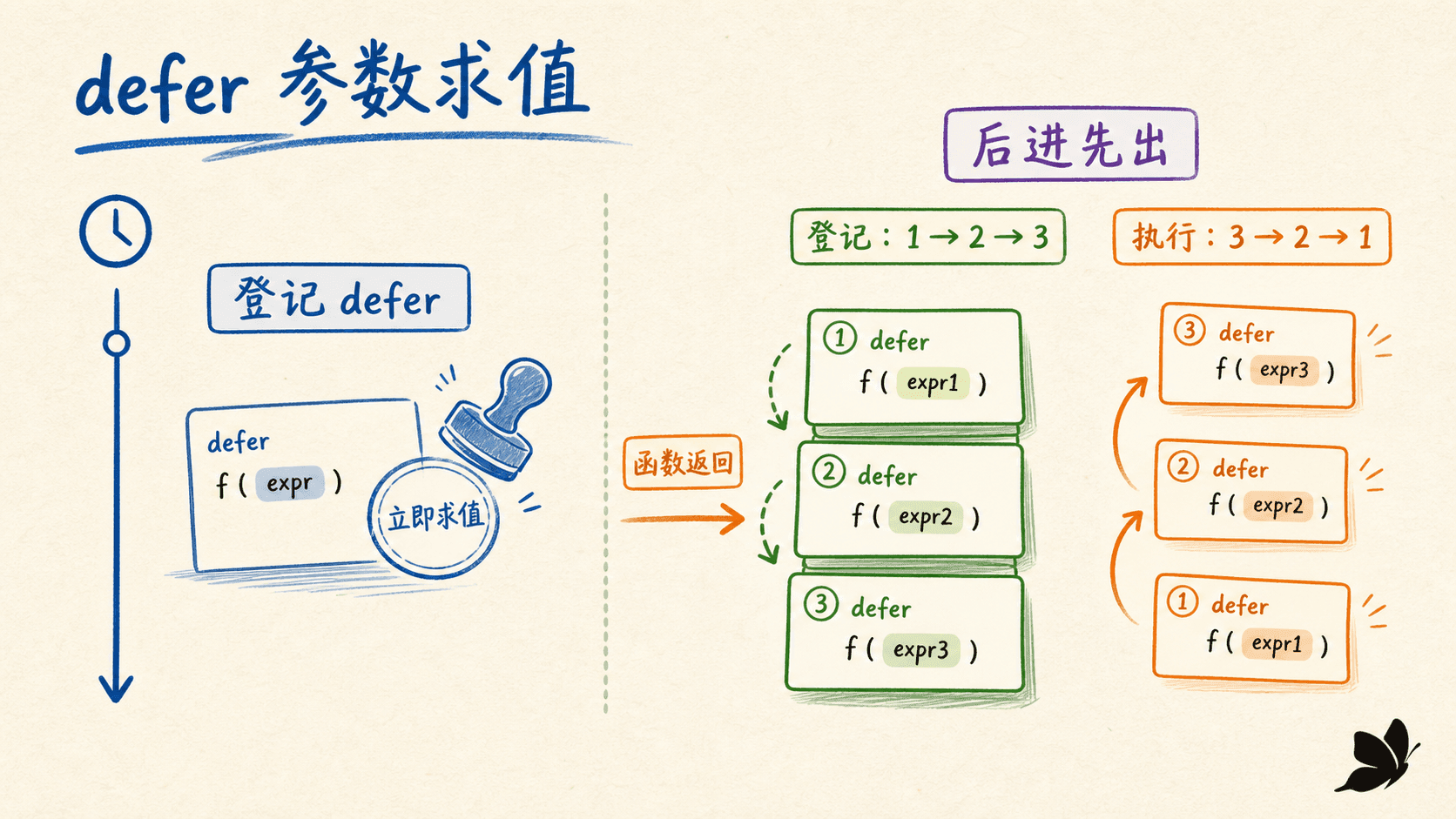
注册时求值,返回前调用
defer 后面必须是函数或方法调用。执行到 defer 语句时,函数值、接收者和实参会立刻求值并保存;真正的调用发生在当前函数即将返回时。
go
func demo() {
n := 1
defer fmt.Println("参数:", n)
defer func() { fmt.Println("闭包:", n) }()
n = 2
}输出顺序是“闭包:2”“参数:1”。第一条延迟调用保存了当时的参数值;第二条保存的是一个闭包,执行时再读取变量 n。
同一函数注册多个 defer 时按后进先出执行。显式 return 会先给结果变量赋值,再执行延迟调用,最后才真正返回给调用者。因此延迟闭包能够读取,甚至修改命名结果。
如果注册时求得的函数值是 nil,defer 语句本身仍能完成注册,直到函数返回、真正尝试调用它时才触发 panic。方法调用的接收者同样在注册时求值。
8.1
多个 defer 的执行顺序是 ____(填英文缩写)。
资源获取成功后立刻安排释放
最稳妥的模式是:获取资源,检查错误,紧接着 defer 释放。
go
func ReadHeader(path string) ([]byte, error) {
file, err := os.Open(path)
if err != nil {
return nil, fmt.Errorf("open %q: %w", path, err)
}
defer file.Close()
data := make([]byte, 16
文件描述符、响应体、互斥锁等不是普通内存,不能指望垃圾回收器及时释放。defer 把释放动作放在获取动作旁边,即使中间有多个提前返回也不容易漏掉。
Close 也可能失败。只读资源往往可以在清理时忽略关闭错误;写文件则可能直到关闭时才报告落盘失败。需要保留它时,可让延迟函数更新命名错误结果:
go
func WriteReport(path string, data []byte) (err error) {
file, err := os.Create(path)
if err != nil {
return fmt.Errorf("create report: %w", err)
}
defer func() {
if closeErr := file.Close(); err == nil
8.2
只要使用了 defer file.Close(),写文件的所有错误就一定被检查到了。
循环里的 defer 属于函数,不属于代码块
defer 在当前函数返回时执行,不会在一次循环迭代结束时执行。循环打开成千上万个文件并逐个 defer Close,资源会一直积压到整个外层函数返回。
把单次迭代提取成小函数,就能让每个资源按迭代释放:
go
func ProcessAll(paths []string) error {
for _, path := range paths {
if err := processOne(path); err != nil {
return err
}
}
return nil
}
func processOne(path string) error {
file, err := os.Open
8.3
循环中每次都获取资源时,哪种写法最容易控制释放时机?
小节练习
预测输出,并说明第一行与第二行为什么读取到不同的 n。
go
func sample() {
n := 1
defer fmt.Println(n)
defer func() { fmt.Println(n) }()
n = 3
}panic:正常控制流之外的故障信号
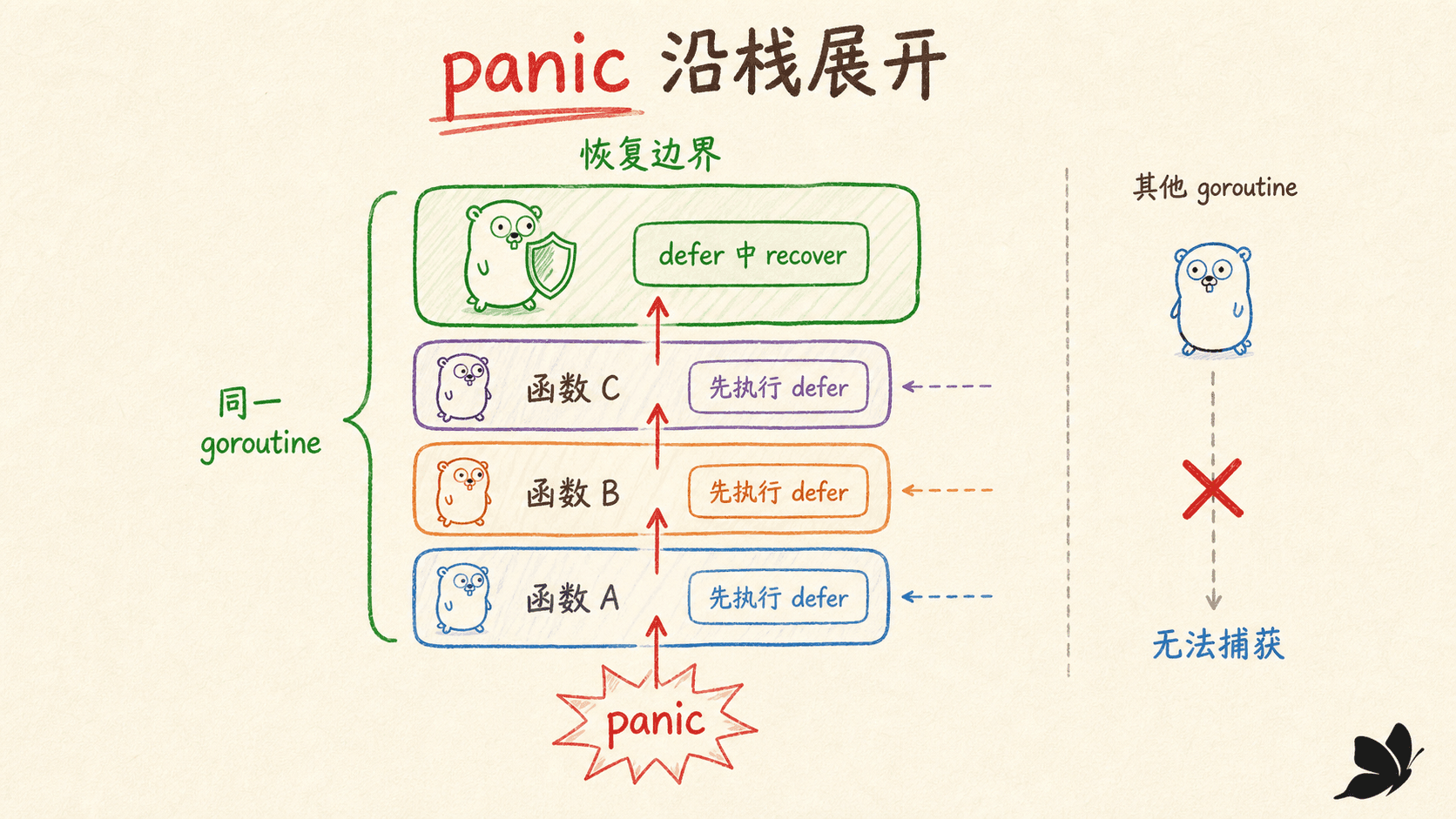
panic 会沿当前 goroutine 的栈传播
数组越界、空指针解引用、失败的类型断言等运行时错误会触发 panic;程序也可以显式调用 panic(value)。当前函数的正常执行立刻停止,先运行它已经注册的 defer,然后把 panic 传给调用者;这个过程沿当前 goroutine 的调用栈继续。
如果没有恢复点,运行时终止程序并输出 panic 值与栈信息。诊断时应保留完整堆栈。runtime/debug.Stack() 可以取得当前 goroutine 的格式化栈信息,适合在边界记录;不要只保存一条被截断的错误文字。
go
func mustPositive(n int) int {
if n <= 0 {
panic("n must be positive")
}
return n
}
9.1
panic 发生后,当前 goroutine 中已经注册的 defer 仍会按规则执行。
预期失败用 error,程序不变量破坏才考虑 panic
用户输入错误、文件不存在、网络超时都属于正常世界会发生的失败,应返回 error。panic 更适合表示调用者违反了无法合理恢复的内部约束,或程序到达逻辑上不可能出现的状态。
Must 前缀常用于把“配置阶段不允许失败”的选择写进 API:
go
var idPattern = regexp.MustCompile(`^[a-z][a-z0-9_]*$`)这里模式来自程序源码,失败表示开发时写错了常量。若模式来自用户输入,应调用 regexp.Compile 并把错误返回给用户。
库不应把普通错误随意升级为 panic,因为这会剥夺调用者选择重试、降级或展示错误的机会。反过来,也不必为运行时已经能清楚报告的空指针再写一层没有更多信息的手工 panic。
9.2
哪种场景最适合 panic?
小节练习
判断下面两个接口哪个应该返回错误,哪个可以提供 Must 包装器,并说明理由。
go
func CompileTemplate(text string) (*Template, error)
func MustCompileTemplate(text string) *Templaterecover:只在清晰的边界恢复
recover 必须被延迟函数直接调用
recover 只有在当前 goroutine 正在 panic,并且由一个延迟执行的函数直接调用时,才能取得 panic 值并停止传播。其他位置调用会返回 nil。
go
func SafeRun(fn func()) (err error) {
defer func() {
if value := recover(); value != nil {
err = fmt.Errorf("task panicked: %v", value)
}
}()
fn()
return nil
}恢复以后,不会回到 panic 发生的那一行继续执行。发生 panic 的函数栈帧已经终止;控制流从完成恢复的边界函数返回。
recover 不能跨 goroutine 捕获。若新 goroutine 中执行不可信任务,就要在那个 goroutine 自己的入口设置恢复边界。
“直接调用”意味着不要再隔一层普通辅助函数。把 recover() 藏在 handlePanic() 中,再由延迟函数调用 handlePanic(),不会满足恢复条件。当前规范还保证:只要确实在恢复一个活跃 panic,直接调用 recover 得到的值就不是 nil;即使代码写了 panic(nil),运行时也会产生非 nil 的 panic 值。
10.1
recover 生效需要哪些条件?
恢复边界要窄,并且要保留证据
合理边界通常是 HTTP 请求处理器、任务 worker 入口、插件回调或包内解析器入口。在这些位置恢复的目的,是隔离一个失败单元,并把它转换为当前层能表达的结果。
恢复所有 panic 然后静默继续很危险:共享状态可能只更新了一半,锁或资源可能处在未知状态,真实缺陷也会被隐藏。更稳妥的策略是:
- 只包围最小的独立工作单元。
- 记录 panic 值和完整栈信息。
- 让当前工作单元失败,不继续使用可能损坏的局部状态。
- 如果只打算恢复自己定义的内部中断,就检查专用类型;遇到其他 panic 重新抛出。
go
type parseAbort struct{ err error }
func parse(input string) (result string, err error) {
defer func() {
value := recover()
if value == nil {
return
}
abort, ok := value.(parseAbort)
if !ok {
panic
这种“包内用 panic 快速中断、包边界转回 error”的技巧只适合复杂递归内部,而且公开 API 仍应返回错误。普通业务分支直接返回 error 往往更简单。
10.2
在服务器最外层 recover 后,当前请求可以从 panic 的语句下一行继续执行。
小节练习
改进下面的恢复代码,使它至少记录调用栈,并让当前任务返回错误。
go
defer func() {
_ = recover()
}()综合练习
下面四组题把本页的关键边界串起来。先独立作答,再展开参考方案。
11.1
函数打开文件、解析内容并返回结果时,最稳妥的结构是什么?
11.2
哪些代码审查意见是合理的?
11.3
包装错误时使用 %w,可以在增加上下文的同时保留底层错误身份。
11.4
在当前 Go 语义下,range 子句使用 ____ 声明迭代变量时,每轮会创建新变量。
编程题:可靠地批量解析文件
实现 LoadAll(paths ...string) (map[string]string, error):逐个读取 UTF-8 文本文件;成功时把路径映射到去除首尾空白后的内容;任一文件失败时返回带路径上下文的错误;不能泄漏资源。思考是否需要手工 os.Open。
设计题:给任务执行器划故障边界
一个任务执行器会从队列取出函数并运行:
go
type Task func(context.Context) error请设计 RunOne(ctx context.Context, task Task) error。要求:普通错误原样包装并返回;panic 转成错误并记录栈;不从故障点继续;不捕获其他 goroutine 的 panic。