Go 复合类型:把一组数据组织成可用的模型
写业务代码时,我们很少只处理一个孤立的 int 或 string。订单有编号、金额和状态;一次接口响应里有列表、分页和错误信息;一段文本要统计每个字符出现多少次。这些问题都在问同一件事:怎样把多个值组织起来,同时保留清楚的边界和语义。
Go 给出的核心工具是数组、切片、映射和结构体。数组与结构体的大小由类型决定,复制它们就是复制整个值;切片和映射更适合动态数据,但它们背后有共享状态,赋值并不等于复制所有元素。随后,encoding/json 可以把这些结构转换成 JSON,模板包则能把结构化数据渲染成文本或安全的 HTML。
这几个类型的语法不难。真正容易出错的是它们的行为边界:append 之后两个切片还共享数组吗?map 中的零值究竟表示“不存在”还是“存在且为零”?结构体嵌入是不是继承?为什么同一份输入交给 text/template 和 html/template 会得到不同结果?我们沿着数据在内存、编码和输出之间的流动,把这些问题一次说清。
先建立一张选择地图
面对一组数据,先问三个问题,往往就能选对类型。
例如,SHA-256 摘要固定为 32 字节,[32]byte 能把长度约束交给编译器;HTTP 请求头的数量不固定,适合 map;一批用户记录数量会变化,适合 []User;单个用户的姓名、年龄和权限含义不同,适合 User 结构体。
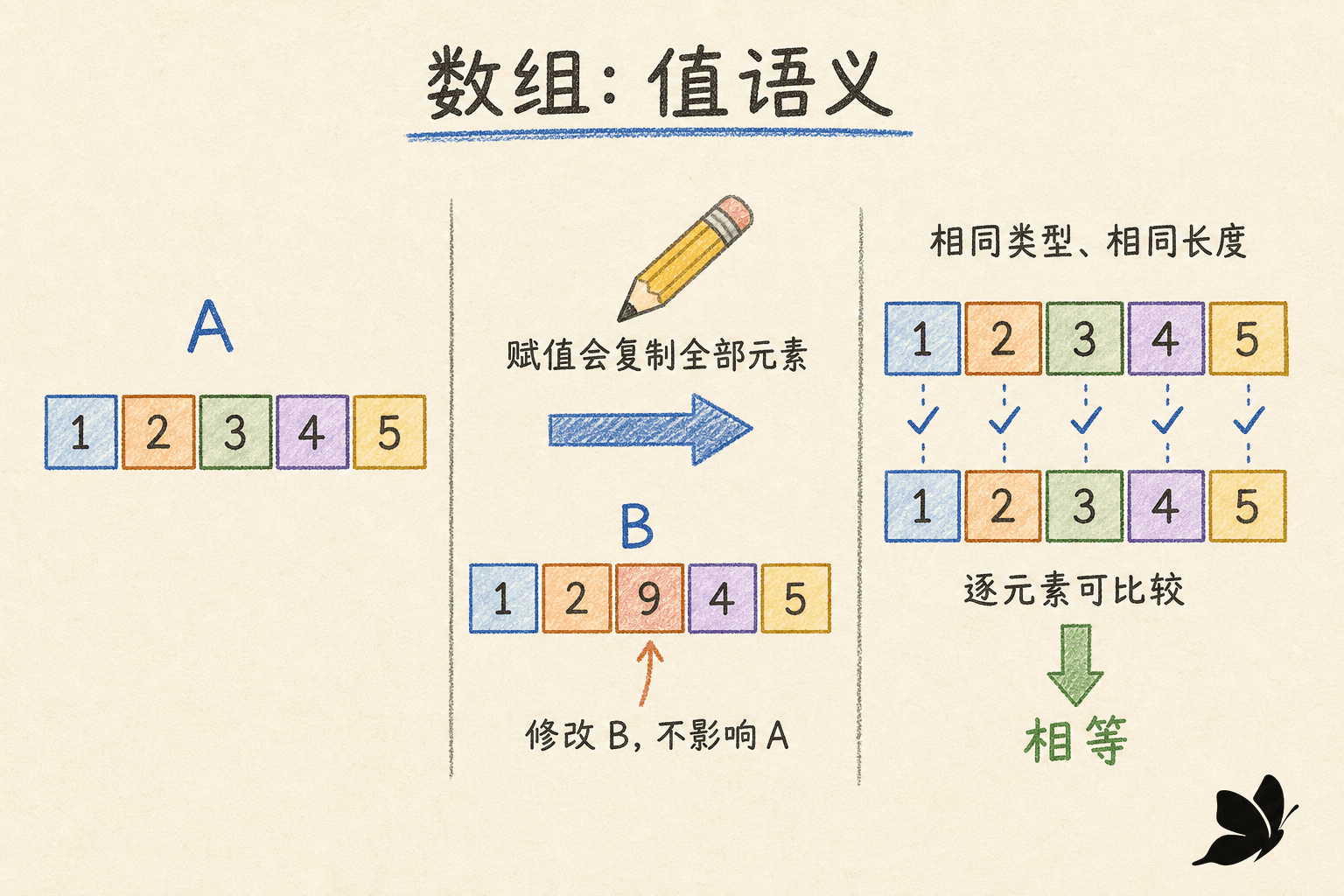
还有一个贯穿全章的判断:修改会不会影响别处?数组和结构体是值语义,赋值或传参会得到一个完整副本。切片复制的是“观察底层数组的窗口”,map 复制的是指向运行时数据结构的描述,因此多个变量可能看到同一份元素变化。理解这一点,比记住一串语法更有用。
即时检查:类型选择
导读-1
下面哪些建模选择能把约束表达得更清楚?
动手想一想:一个棋盘永远是 8×8,但每个格子里保存的是棋子类型。你会怎样声明?
数组:长度属于类型,复制就是复制全部元素
数组写作 [N]T,表示恰好有 N 个 T。N 必须是非负、可表示为 int 的常量表达式。因此 [3]int 与 [4]int 是两个不同的类型,哪怕它们的元素类型相同。
go
package main
import "fmt"
func main() {
var zeros [3]int
scores := [3]int{86, 91, 78}
inferred := [...]int{86, 91, 78}
sparse := [...]int{2: 30, 5: 60}
fmt.Println(zeros) // [0 0 0]
fmt.Println(scores == inferred) // true
fmt.Println(len(sparse), sparse) // 6 [0 0 30 0 0 60]
}未显式初始化的元素使用元素类型的零值。字面量中的 ... 只是在编译期让编译器根据最大索引推导长度,并没有把数组变成动态结构。[...]int{2: 30, 5: 60} 的最大索引是 5,所以类型是 [6]int。
数组的值语义
数组变量保存整个数组值。赋值时,所有元素都会被复制;按值传入函数时,形参同样得到副本。下面的 changeCopy 不会修改调用者:
go
package main
import "fmt"
func changeCopy(a [3]int) {
a[0] = 99
}
func changeOriginal(a *[3]int) {
a[0] = 99
}
func main() {
original
数组指针允许函数修改原数组,也避免复制大型数组。不过指针类型仍然带着长度:*[3]int 不能接收 *[4]int。一般业务代码会用切片接受任意长度序列;数组更适合长度本身有含义的值,例如固定摘要、颜色通道、矩阵或协议字段。
比较、遍历与边界
只要元素类型可比较,数组就可比较。比较要求左右两边类型相同,并按索引逐个比较元素。数组中若包含切片、map 或函数等不可比较元素,整个数组也不能用 ==。
go
package main
import "fmt"
func main() {
a := [3]string{"红", "绿", "蓝"}
b := [...]string{"红", "绿", "蓝"}
c := [3]string{"红",
range 提供索引和元素值。这里的 color 是元素的副本;给它重新赋值不会改动数组。如果需要修改元素,应使用索引:
go
for i := range a {
a[i] = "已处理:" + a[i]
}数组长度是类型的一部分,不能把运行时变量直接写进 [n]T。如果长度来自用户输入、文件或接口响应,就应使用 make([]T, n) 创建切片。
即时检查:数组到底复制了什么
数组-1
执行 b := a 后再修改 b[0],什么情况下 a[0] 也会变化?
编程题:实现 DifferentBits(a, b [32]byte) int,统计两个固定摘要有多少个二进制位不同。
切片:一个指向底层数组的可变窗口
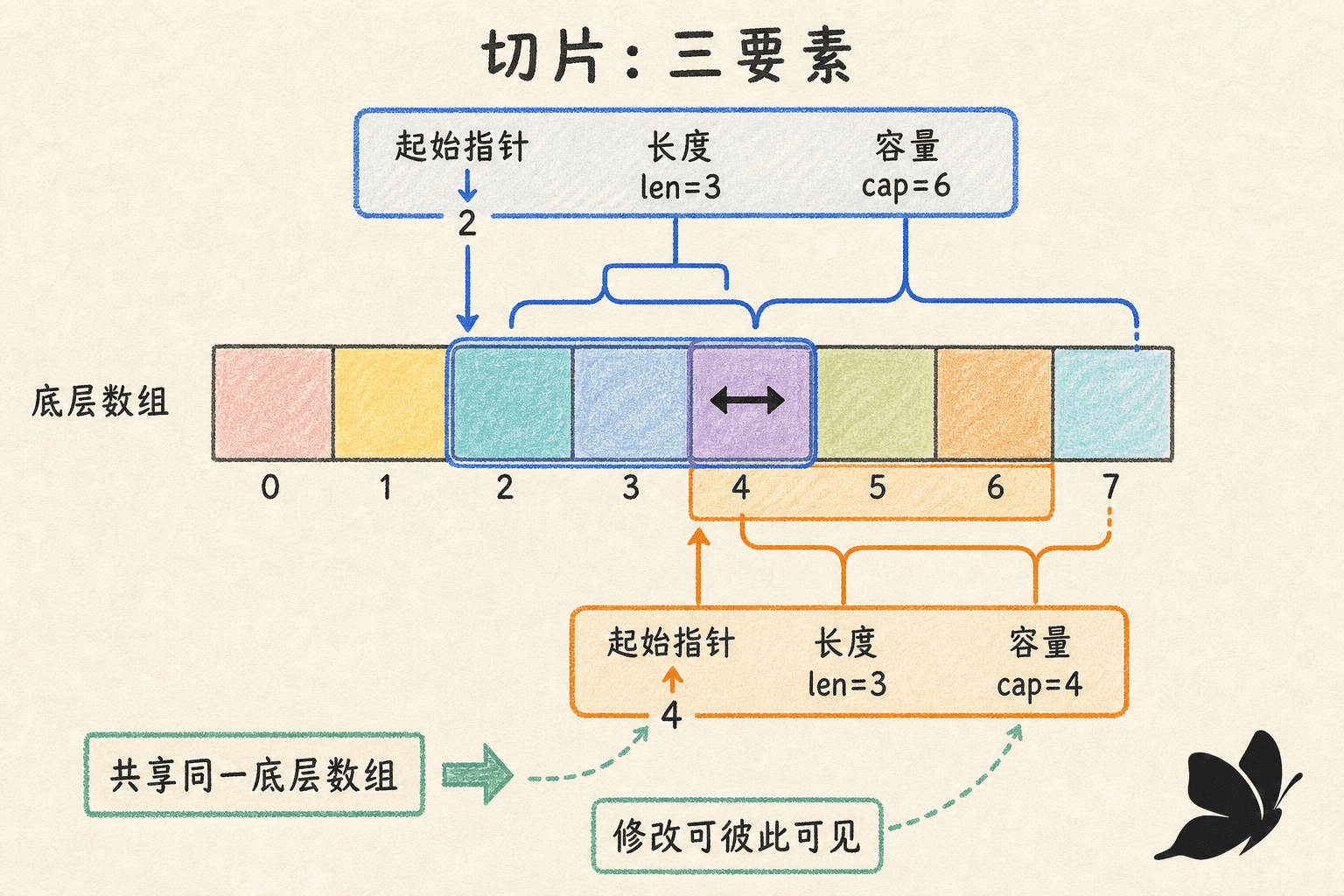
切片类型写作 []T。它可以理解成三个信息组成的描述符:起始位置、长度 len 和容量 cap。长度决定当前能直接索引的元素数量;容量表示从起始位置到其底层数组末端还能延伸多远。
go
package main
import "fmt"
func main() {
data := [6]int{10, 20, 30, 40, 50, 60}
s := data[1:4]
fmt.Println(s) // [20 30 40]
fmt.Println(
data[1:4] 包含索引 1、2、3,左闭右开。它的长度是 3;从 data[1] 到数组末尾共有 5 个位置,所以容量是 5。重新切片可以越过当前长度,但不能越过容量,否则运行时会 panic。
创建切片与 nil 状态
切片通常来自字面量、数组的切片表达式,或 make:
go
literal := []int{1, 2, 3}
array := [5]int{1, 2, 3, 4, 5}
window := array[1:4]
buffer := make([]byte, 4, 16)make([]byte, 4, 16) 创建长度 4、容量 16 的切片。四个可见元素已经存在,值都是 0;剩余容量是为后续增长预留的空间。常见错误是把容量当成长度,然后直接写 buffer[4],这仍然越界。应该写 buffer = append(buffer, value),或先重新切片到更长的长度。
切片的零值是 nil:
go
var a []int
b := []int{}
c := make([]int, 0)
fmt.Println(a == nil, len(a), cap(a)) // true 0 0
fmt.Println(b == nil, len(b), cap(b)) // false 0 0
fmt.Println(c == nil, 三者都可以安全地 append、range 和 len。判断“是否没有元素”应使用 len(s) == 0;只有当接口协议需要区分 JSON 的 null 与 [],或 API 明确赋予 nil 特殊语义时,才检查 s == nil。
两个切片不能直接使用 == 比较内容,唯一允许的切片比较是与 nil 比较。元素类型可比较时,可以使用 slices.Equal(a, b);需要自定义相等规则时用 slices.EqualFunc。这些比较检查当前元素,不代表两个切片是否共享底层数组。
即时题:长度和容量
切片-1
data := [8]int{};s := data[2:5]。此时 len(s) 是 ____,cap(s) 是 ____。请用英文逗号分隔。
多个切片共享底层数组
切片赋值只复制描述符,不复制底层元素。由同一数组切出的窗口可以重叠,修改重叠区域会被其他窗口看到。
go
package main
import "fmt"
func main() {
base := []string{"一", "二", "三", "四", "五"}
left := base[1:4] // 二 三 四
right := base[2:] // 三 四 五
right[0] =
把切片传给函数时也一样:函数得到描述符的副本,但通过它写元素会改到共享数组。若函数只调整自己的切片长度,调用者的 len 不会自动变化,因为长度字段已经复制;函数必须返回新切片,调用者再接住它。
go
func addMarker(s []string) []string {
s[0] = "已处理" // 调用者能看到元素变化
return append(s, "结束") // 长度变化必须通过返回值带回
}
items = addMarker(items)要得到独立副本,可以使用 slices.Clone,或自己 make 加 copy:
go
clone := make([]string, len(items))
copy(clone, items)这里复制的是元素。如果元素本身仍是切片、map 或指针,那么只是浅复制;要完全隔离嵌套数据,还需逐层复制。
切片共享实验室
点击按钮观察两个窗口何时共享、何时因扩容分离。这个实验只模拟语言规则,不依赖外部脚本。
即时题:共享与隔离
切片-2
只要执行过 append,返回切片就一定与原切片使用不同的底层数组。
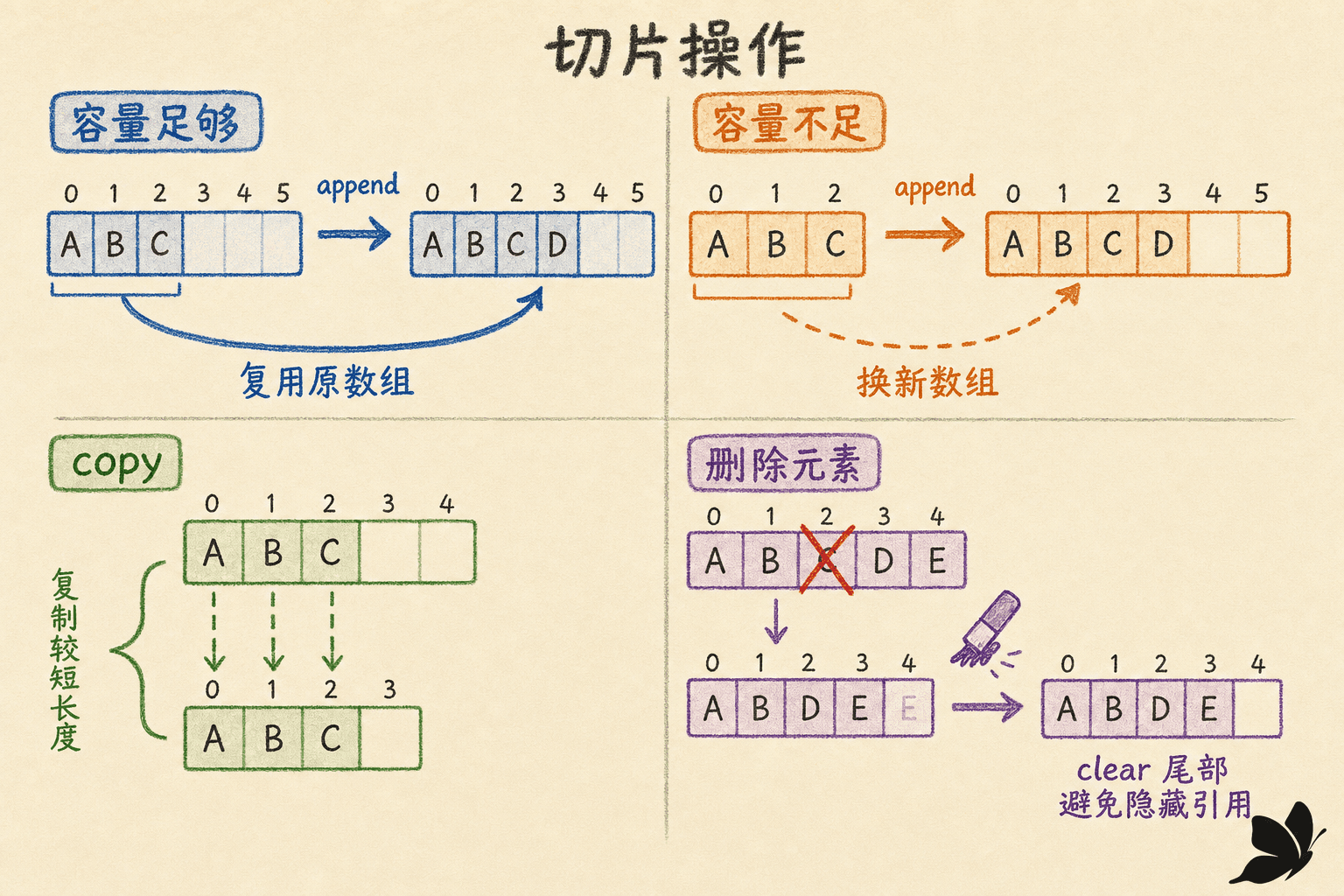
append、容量与增长边界
append 返回一个新的切片描述符。容量足够时,它复用原数组;容量不足时,它分配更大的数组并复制旧元素。具体增长倍数属于实现细节,不应写进业务逻辑。
go
package main
import "fmt"
func main() {
s := make([]int, 0, 3)
s = append(s, 10, 20, 30)
before := &s[0]
s = append(s, 40)
after
这里最重要的代码习惯只有一句:
go
s = append(s, values...)若函数可能改变切片长度、容量或底层数组,同样让它返回切片并接住结果。预先知道大致元素数时,可以 make([]T, 0, expected) 减少扩容与复制,但不要为了猜容量而让代码变复杂。
还可以用完整切片表达式限制容量:
go
head := s[:2:2]
head = append(head, 99) // cap(head)==2,必然不能写入 s 原数组的后续位置三下标形式 s[low:high:max] 让新切片容量变为 max-low。它适合在 API 边界防止被调用方通过 append 意外覆盖同一数组中不属于它的后续数据。
即时题:接住返回值
切片-3
函数 func add(s []int) { s = append(s, 1) } 被调用后,调用者为什么不能依赖自己的切片长度增加?
copy、原地算法与删除
copy(dst, src) 复制 min(len(dst), len(src)) 个元素并返回实际数量。源和目标可以重叠,因此它适合在同一底层数组里移动元素。
go
package main
import "fmt"
func removeStable(s []int, i int) []int {
copy(s[i:], s[i+1:])
clear(s[len(s)-1:])
return s[:len(s)-1]
}
func removeFast(s
稳定删除要移动后半段,时间复杂度是 O(n);不要求顺序时,用最后一个元素填洞是 O(1)。两种写法都清理了缩短后隐藏在尾部的旧值。对 int 来说这只是整洁;如果元素保存指针、切片、map 或含指针的结构体,尾部旧引用会让本可回收的大对象继续存活。
Go 1.21 提供内置 clear:对切片,它把当前长度范围内的元素设为零值;对 map,它删除全部条目。Go 1.22 起,标准库 slices.Delete、slices.Compact 等会主动清理失效尾部,因此现代代码可以直接写:
go
import "slices"
s = slices.Delete(s, i, i+1)仍然要接住返回值,并把旧切片视为不再可用,因为它的底层数组已经被改动。
另一个内存问题来自“小切片留住大数组”:
go
func prefix(data []byte) []byte {
return data[:16]
}如果 data 来自一个数百 MB 的文件,返回的 16 字节切片仍指向原数组,垃圾回收器不能释放整块存储。需要长期保存这 16 字节时,应复制:
go
func prefix(data []byte) []byte {
n := min(16, len(data))
return append([]byte(nil), data[:n]...)
}即时题:删除后的内存
切片-4
从 []*Image 中删除元素后,哪些做法有助于避免无用对象被隐藏引用长期保留?
动手题:写一个原地函数,移除 []string 中相邻的重复项,并清理失效尾部。
小节练习:用切片实现队列时的取舍
切片-5
反复执行 queue = queue[1:] 能立即归还已经出队元素所在的整个底层数组。
设计题:一个服务维护最近 1000 条日志。请说明为什么“无限 append,超过 1000 就 logs = logs[1:]”不是最稳妥的长期方案。
映射:把可比较的键关联到值
map 类型写作 map[K]V。所有键都是 K,所有值都是 V,两者不必相同。键必须可比较,因为运行时需要判断两个键是否相等;布尔、数字、字符串、指针、通道,以及字段都可比较的数组和结构体都可以成为键。切片、map 和函数不能直接作为键。
go
package main
import "fmt"
func main() {
stock := map[string]int{
"铅笔": 12,
"橡皮": 0,
}
stock["铅笔"] += 3
stock["尺子"]++
delete(stock, "不存在的键") // 安全,无操作
make(map[string]int) 和 map[string]int{} 都会创建可写的空 map。make 还可接收容量提示,但它只是性能提示,不限制条目数量。
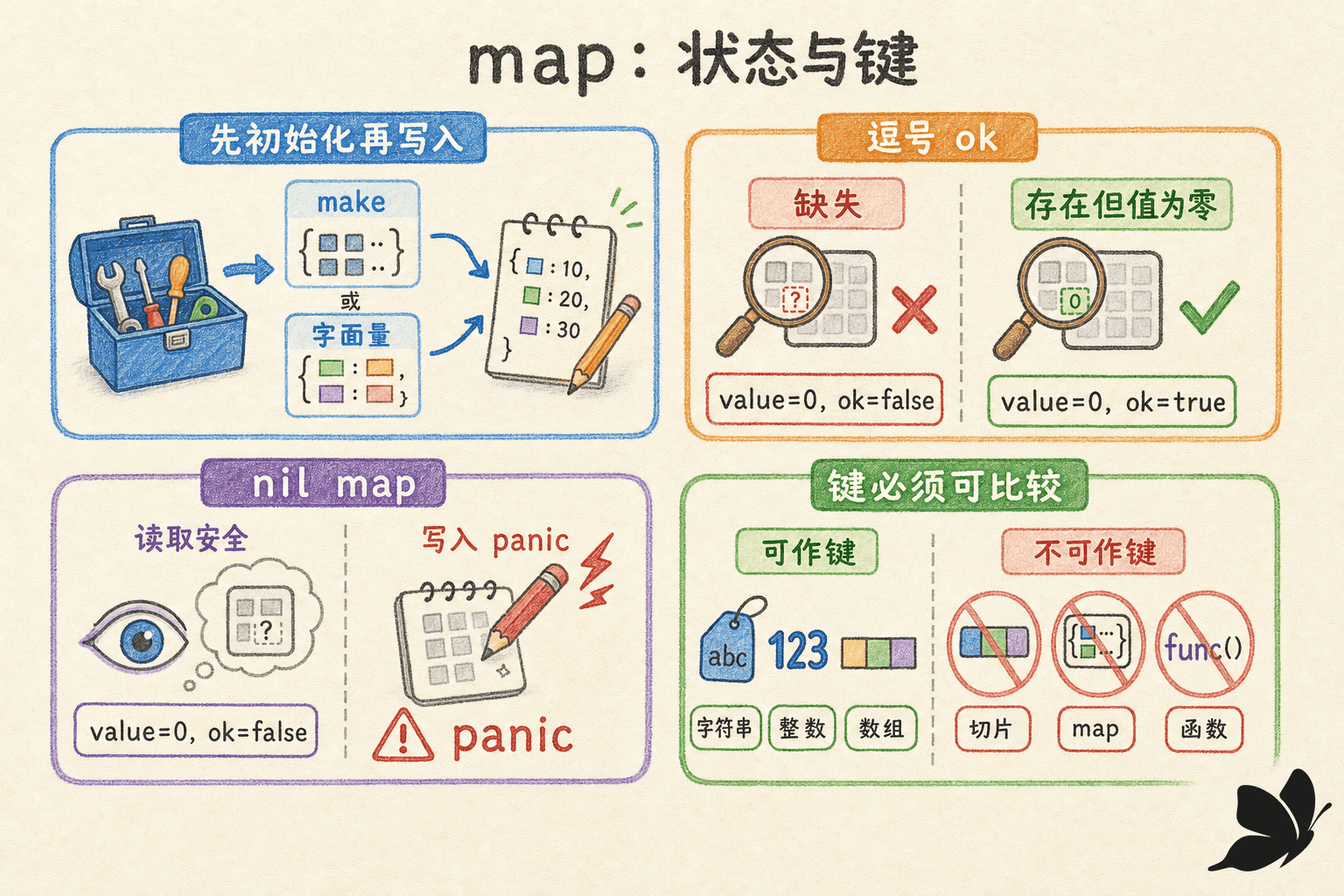
查询必须区分“缺失”与“零值”
读取不存在的键不会报错,而是返回值类型的零值。因此单值查询无法区分“键不存在”和“键存在、值刚好为零”。逗号 ok 形式专门解决这个问题:
go
count, ok := stock["橡皮"]
if !ok {
fmt.Println("没有橡皮这条记录")
} else {
fmt.Println("橡皮库存:", count)
}这条规则也影响 map 相等判断。若只比较 x[k] == y[k],map[string]int{"A": 0} 可能被误判为和不含 A 的 map 相等。应同时检查 ok,或在值可比较时使用标准库 maps.Equal。
go
func equal(x, y map[string]int) bool {
if len(x) != len(y) {
return false
}
for k, xv := range x {
yv, ok := y[k]
if !ok || yv != xv {
return false
}
}
map 状态观察器
输入键并切换“存在但为零”与“不存在”,观察单值查询为什么不够。
即时题:逗号 ok
映射-1
对于 m := map[string]bool{"已读": false},表达式 v, ok := m["已读"] 的结果是什么?
nil map、共享修改与不可寻址元素
map 的零值是 nil。对 nil map 执行查询、len、range、delete 和 clear 都安全,行为像空 map;向它写入会 panic。
go
var m map[string]int
fmt.Println(m["x"], len(m)) // 0 0
delete(m, "x") // 安全
clear(m) // 安全
// m["x"] = 1 // panic: assignment to entry in nil map
m = make(map[string]int)
m["x"] = 1map 赋值或传参不会复制所有键值对。函数收到的 map 描述仍指向同一运行时结构,所以增删改会被调用者看到。若需要独立的顶层副本,可使用 maps.Clone;它和切片克隆一样是浅复制,值若是切片或指针,内部数据仍可能共享。
map 元素不是可寻址变量,不能写 &m[key],也不能直接修改结构体值的某个字段:
go
type User struct{ Score int }
users := map[string]User{"小林": {Score: 10}}
// users["小林"].Score++ // 编译错误
u := users["小林"]
u.Score++
users["小林"] = u另一种设计是 map[string]*User,这样可以通过指针修改对象,但也引入 nil 指针、对象共享和生命周期问题。是否用指针取决于是否需要共享身份,不应只为少写两行代码。
即时题:nil 与共享
映射-2
对 nil map 可以安全执行哪些操作?
键约束、遍历顺序与集合
map 键的相等关系必须稳定。因此切片不能直接做键;浮点数虽可比较,但 NaN 不等于自身,用它做键通常会得到难以理解的行为。需要用复合键时,优先考虑可比较结构体:
go
type Endpoint struct {
Host string
Port uint16
}
hits := map[Endpoint]int{}
hits[Endpoint{Host: "api.example.com", Port: 443}]++如果原始键是切片,可以先转换为具有稳定、无歧义编码的字符串或数组。简单地 strings.Join(parts, ",") 可能发生碰撞:["a,b", "c"] 和 ["a", "b,c"] 会得到同一个结果。更稳妥的做法是长度前缀编码、标准序列化,或在长度固定时转换成数组。
map 的 range 顺序没有规定,不能把当前观察到的输出顺序当成合同。需要稳定输出时,先收集键再排序:
go
keys := make([]string, 0, len(stock))
for key := range stock {
keys = append(keys, key)
}
slices.Sort(keys)
for _, key := range keys {
fmt.Println(key, stock[key])
}用 map[T]struct{} 可以表达集合:值不携带信息,存在性由键决定。
go
seen := make(map[string]struct{})
seen["go"] = struct{}{}
if _, ok := seen["go"]; ok {
fmt.Println("见过")
}
不要在 map 遍历中依赖添加新键是否会在本轮出现。规范不保证新条目一定出现;删除尚未到达的条目后,该条目不会再产生。若算法依赖固定集合,先复制键列表。
小节练习:词频统计
映射-3
若 counts 的类型是 map[string]int,统计单词 word 最惯用的一行代码是 ____。
编程题:统计输入切片中每个单词的次数,并按单词字典序输出。结果必须稳定。
结构体:用字段名表达一条完整记录
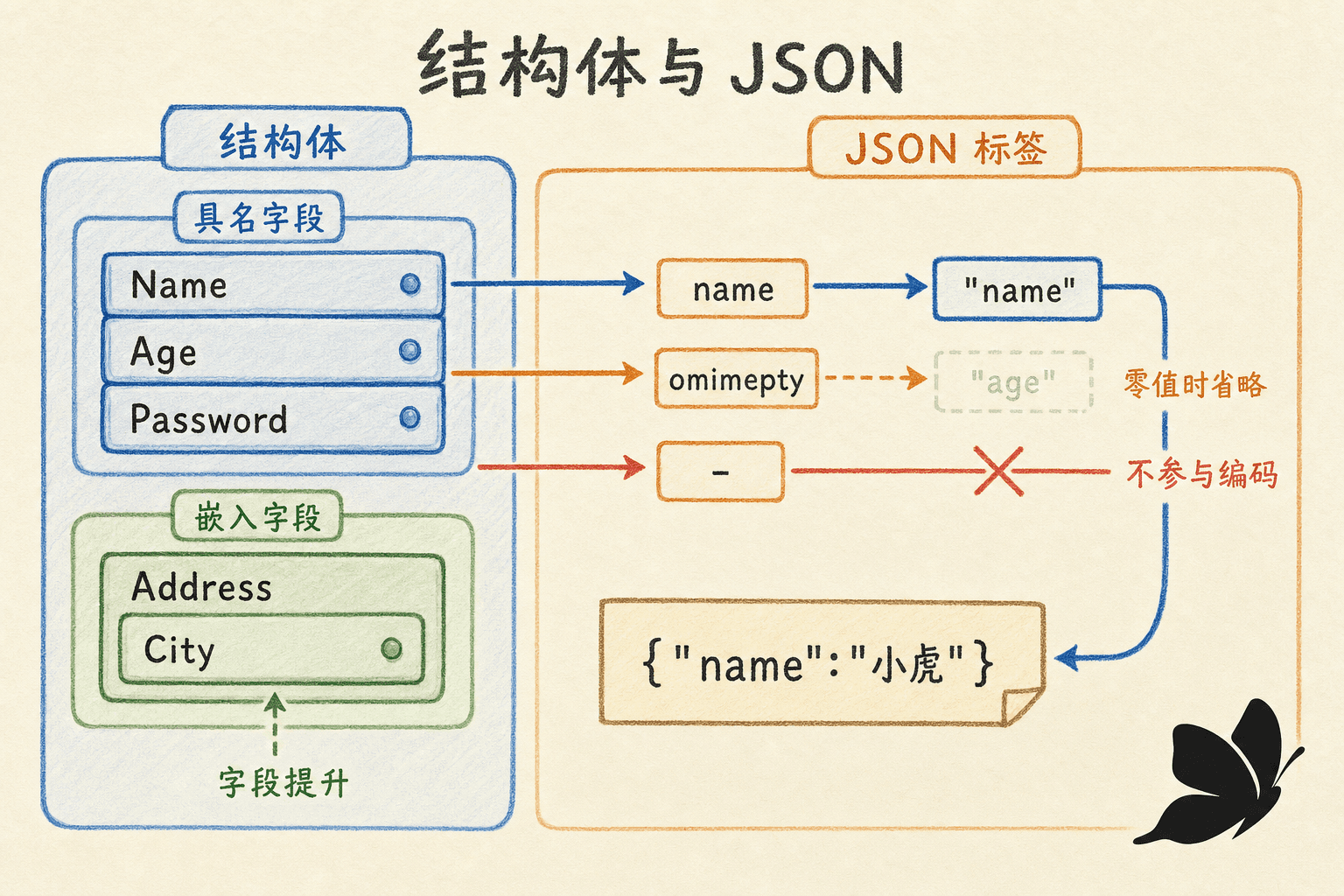
结构体把若干具名字段组合成一个值。字段可以有不同类型,字段顺序、名称、类型、标签以及是否嵌入都会参与未命名结构体的类型身份。
go
type User struct {
ID int64
Name string
Email string
Active bool
Tags []string
}结构体的零值由所有字段的零值组成。设计类型时,尽量让零值能安全使用,例如 bytes.Buffer 的零值就是可用的空缓冲区。若零值不能直接使用,应通过构造函数建立不变量,并在文档中写清楚。
字段访问、指针与值传递
结构体赋值和按值传参会复制所有字段。与数组一样,若字段包含切片、map 或指针,复制的是这些字段的描述或地址,内部数据仍可能共享。
go
package main
import "fmt"
type Profile struct {
Name string
Tags []string
}
func renameCopy(p Profile) {
p.Name = "副本"
p.Tags[0] = "共享元素"
}
func renameOriginal(p *Profile) {
p.Name =
p *Profile 也能直接写 p.Name,Go 会自动解引用,不必写 (*p).Name。使用指针通常有三个理由:需要修改原值、结构体很大而复制成本明显、或对象需要共享身份。小型不可变值用值传递往往更简单。
结构体不能直接包含自身,否则大小无法确定;可以包含指向自身的指针,从而建立链表或树:
go
type Node struct {
Value int
Left *Node
Right *Node
}即时题:复制的深浅
结构体-1
结构体按值复制后,两个结构体绝不会再共享任何数据。
结构体字面量与可维护性
结构体字面量有按位置和按字段名两种形式:
go
type Point struct{ X, Y int }
p1 := Point{10, 20}
p2 := Point{Y: 20, X: 10}
p3 := Point{X: 10} // Y 使用零值按位置写法要求提供全部字段,并依赖声明顺序。它适合字段极少、顺序约定明确且位于同一包内的值。跨包或会演化的业务结构,优先使用字段名:新增或调整字段时,旧代码更不容易悄悄把值放错位置。
取复合字面量地址会得到指向新值的指针:
go
user := &User{Name: "小林", Active: true}包外代码只能通过导出字段构造和访问值。导出字段以大写字母开头;小写字段只在声明它的包内可见。不能用按位置字面量绕过未导出字段限制。
即时题:字面量选择
结构体-2
对于会持续增加字段的公共配置结构体,推荐哪种初始化方式?
比较与作为 map 键
如果所有字段都可比较,结构体就可比较,并可成为 map 键。比较按字段声明顺序进行。只要加入一个切片、map 或函数字段,整个结构体就不能再用 ==。
go
type Cell struct {
Row int
Col int
}
blocked := map[Cell]bool{
{Row: 2, Col: 3}: true,
}
fmt.Println(blocked[Cell{Row: 2, Col: 3}]) // true结构体作为复合键比拼字符串更安全:字段边界和类型都由编译器保留。若结构体含接口字段,接口动态值若不可比较,运行时比较仍可能 panic,因此用作键的类型应尽量保持“严格可比较”。
嵌入是字段提升,不是继承
嵌入字段只写类型,不写显式字段名:
go
type Point struct {
X, Y int
}
type Circle struct {
Point
Radius int
}
type Wheel struct {
Circle
Spokes int
}访问时可以写 w.X,它会提升为 w.Circle.Point.X 的简写。显式完整路径始终有效。方法也可以随嵌入字段提升,这是 Go 组合行为的常用方式。
但字面量必须忠实反映嵌套结构,不能把提升字段当成外层真实字段:
go
w := Wheel{
Circle: Circle{
Point: Point{X: 8, Y: 8},
Radius: 5,
},
Spokes: 20,
}如果同一层级有两个路径都能提升出同名字段,选择器会产生歧义,必须写完整路径。嵌入表达的是“组合并提升访问”,外层值仍然包含一个真实的嵌入字段;不要用面向对象语言的继承规则来推断可替换性。
即时题:嵌入
结构体-3
关于结构体嵌入,哪些说法正确?
小节练习:安全复制资料
编程题:给 Profile 实现 Clone,要求返回值的 Tags 修改后不影响原值。
JSON:在 Go 值与外部数据之间建立清晰边界
encoding/json 把 Go 的布尔、数字、字符串、数组、切片、map 和结构体转换为 JSON,也能反向解码。数组和切片通常对应 JSON 数组;结构体对应 JSON 对象;map 通常以字符串类键编码为对象。
字段标签与编码规则
go
type Article struct {
ID int64 `json:"id"`
Title string `json:"title"`
Draft bool `json:"draft,omitempty"`
Tags []string `json:"tags"`
Internal string `json:"-"`
}只有导出字段会被默认编码。标签 json:"title" 改变 JSON 名称;omitempty 在字段为空值时省略它;json:"-" 始终忽略字段。标签属于结构体字段元数据,通常使用反引号原始字符串写成。
go
package main
import (
"encoding/json"
"fmt"
)
func main() {
article := Article{
ID: 7,
Title: "理解切片",
Tags: []string{"Go", "内存"},
Internal: "不应暴露",
}
compact, err := json.
Marshal 返回紧凑的 []byte;MarshalIndent 适合日志、配置或人工检查。编码可能失败,例如数据里含通道、函数,或浮点值是 NaN、正无穷、负无穷,所以不要忽略错误。
nil 切片默认编码为 null,非 nil 的空切片编码为 []。这会影响接口合同。若 API 要求始终返回数组,可以在构造响应时把 nil 规范化为 make([]T, 0),或使用自定义编码逻辑。
即时题:标签
JSON-1
要把导出字段 Password 从 JSON 编码和解码中都忽略,标签应写为 json:"____"。
解码、选择字段与未知字段
json.Unmarshal 要接收可写目标的指针:
go
raw := []byte(`{"id":7,"title":"理解切片","extra":"ignored"}`)
var article Article
if err := json.Unmarshal(raw, &article); err != nil {
return err
}解码到结构体时,默认会忽略没有对应字段的 JSON 成员。这对兼容新增字段很方便,但配置文件和严格 API 入参可能更希望尽早发现拼写错误,此时使用流式解码器并调用 DisallowUnknownFields:
go
dec := json.NewDecoder(reader)
dec.DisallowUnknownFields()
var article Article
if err := dec.Decode(&article); err != nil {
return fmt.Errorf("解析文章: %w", err)
}解码时可以只声明关心的字段,其余输入会被忽略:
go
var summary struct {
ID int64 `json:"id"`
Title string `json:"title"`
}
if err := json.Unmarshal(raw, &summary); err != nil {
return err
}若解码到 any,JSON 数字默认变成 float64,对象变成 map[string]any,数组变成 []any。需要保留大整数文本精度时,可让 Decoder 使用 UseNumber,或更直接地定义准确的结构体字段类型。
不要把“能成功解码”当成“业务输入有效”。JSON 解码只负责语法和类型映射;金额范围、必填字段、字符串长度、枚举取值等仍要在解码后验证。
即时题:解码边界
JSON-2
处理外部 JSON 输入时,哪些做法更稳妥?
流式 Decoder 与 Encoder
数据已经在 io.Reader 或要直接写入 io.Writer 时,Decoder 和 Encoder 可以避免先把全部内容拼成一个大字节切片,并支持连续处理多个 JSON 值。
go
package main
import (
"encoding/json"
"fmt"
"io"
"strings"
)
type Event struct {
Type string `json:"type"`
ID int `json:"id"`
}
func decodeEvents(r io.Reader) error {
dec
HTTP 响应体解码时要先检查状态码,并确保 Body 被关闭。写响应时可以直接 json.NewEncoder(w).Encode(value);Encode 会在 JSON 后追加换行。若输出会嵌入 HTML <script>,默认 HTML 转义是安全的;只有明确理解上下文时才考虑 SetEscapeHTML(false)。
JSON 字段映射实验室
小节练习:严格读取单个 JSON 值
编程题:从 io.Reader 严格读取一个配置对象:拒绝未知字段,并拒绝对象后还有第二个 JSON 值。
模板:把数据渲染逻辑从业务代码中分离
模板由普通文本和 {{...}} 动作组成。执行时,“点” . 表示当前数据;range 改变循环体中的当前值;管道 | 把前一步结果传给后一步函数。模板适合格式较复杂、又希望布局与数据获取逻辑分开的输出。
text/template 的数据驱动写法
go
package main
import (
"log"
"os"
"text/template"
)
type Item struct {
Name string
Count int
}
const reportText = `库存报告
{{range .Items -}}
- {{.Name}}:{{.Count}}
{{else -}}
暂无库存
{{end}}`
var report = template.
模板通常在程序启动或包初始化时解析一次,再用不同数据反复执行。固定模板解析失败属于程序缺陷,template.Must 适合让它尽早暴露;运行时加载的用户模板则不能直接 Must,应把解析错误返回给调用方。
自定义函数要在 Parse 前通过 Funcs 注册:
go
funcMap := template.FuncMap{
"upper": strings.ToUpper,
}
t := template.Must(
template.New("report").Funcs(funcMap).Parse(`{{.Name | upper}}`),
)模板定义方必须是可信的。text/template 不会自动转义输出,它适合纯文本、邮件正文、配置片段等非 HTML 场景。不要把用户提供的模板当成普通数据执行。
即时题:模板执行流程
模板-1
固定模板在服务中被大量请求复用时,推荐的流程是什么?
html/template 的上下文自动转义
html/template 与 text/template 有相似 API 和模板语言,但它会根据动作所在的 HTML、属性、URL、CSS 或 JavaScript 上下文自动转义普通字符串。生成 HTML 时应默认选它。
go
package main
import (
"html/template"
"os"
)
const page = `<!doctype html>
<h1>{{.Title}}</h1>
<a href="{{.URL}}">打开详情</a>`
func main() {
t := template.Must(template.New("page").Parse(page))
data := struct {
Title string
URL
标题会显示成普通文本,不会变成可执行标签;危险 URL 也会按 URL 上下文过滤。自动转义不是简单地统一替换 < 和 >,而是先理解动作处在什么语法位置,再选择匹配的编码方式。
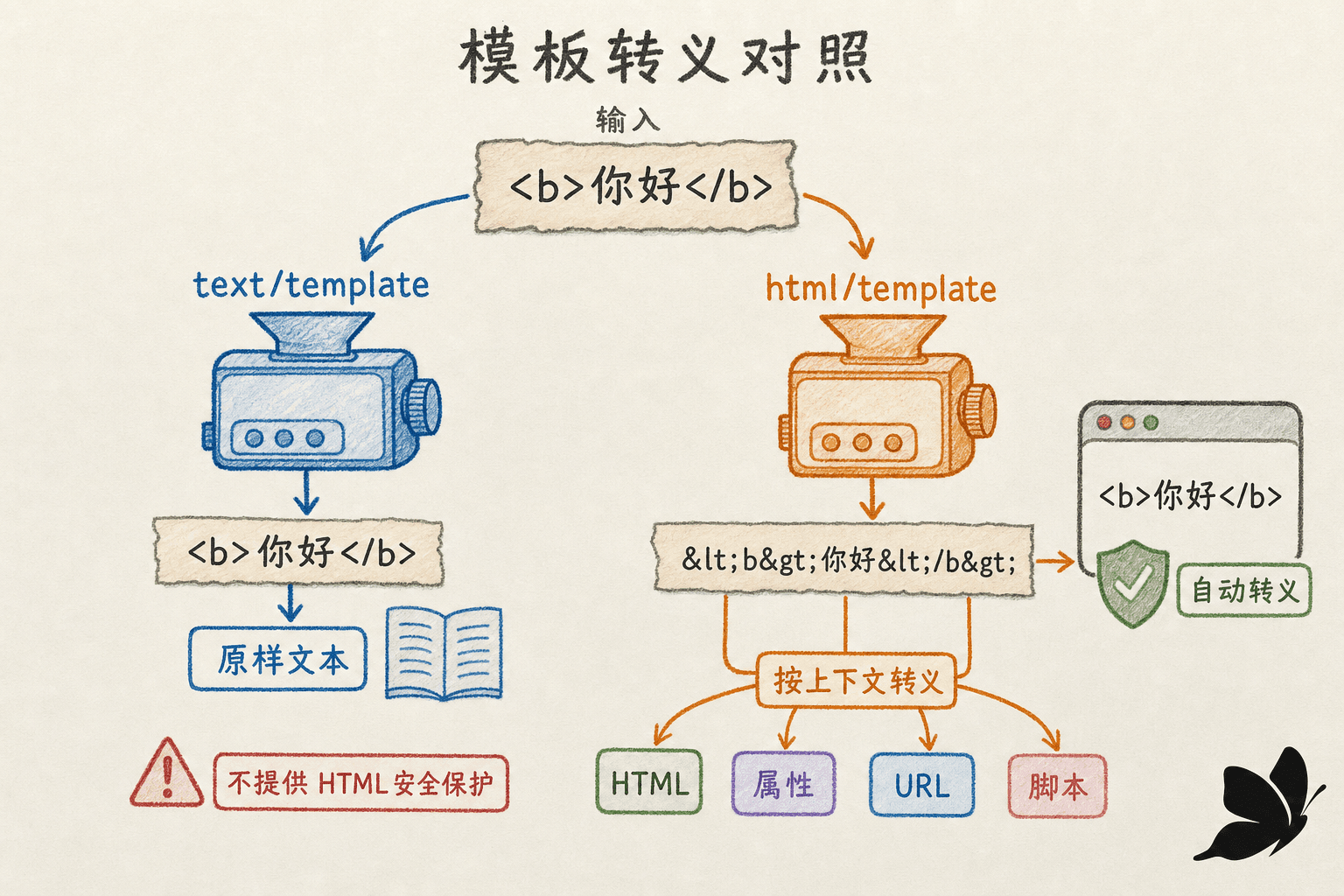
只有数据已经过可信、严格的净化,并且明确要插入 HTML 片段时,才使用 template.HTML。这个类型是在向模板系统声明“这里已经可信,不要转义”,它不是净化函数:
go
type PageData struct {
SafeBody template.HTML
}把未经验证的用户输入直接转换成 template.HTML 会关闭保护,形成注入漏洞。同理,template.URL、template.JS 和 template.CSS 都是安全承诺,不是快捷转义工具。
转义对照实验室
即时题:可信类型
模板-2
把用户提交的字符串转换为 template.HTML,就能安全地阻止 XSS。
执行错误、并发与工程边界
解析成功不代表执行一定成功。写入目标可能失败,模板中访问的方法也可能返回错误,因此 Execute 的错误必须处理。模板解析完成后可以并发执行;如果多个执行共享同一个 io.Writer,输出可能交错,应为每次请求使用独立 writer 或自行同步。
模板负责呈现,不应承担复杂业务计算。先在 Go 代码中完成查询、权限检查、排序和聚合,把一个结构清楚的视图模型交给模板。这样既方便测试,也能减少模板中的隐含状态。
生成 HTML 时不要误用 text/template,也不要通过 template.HTML 给不可信输入“取消转义”。模板文件本身也应来自可信代码或受控资源;模板定义方可以调用暴露给模板的方法与函数。
小节练习:安全的文章列表
模板-3
渲染含用户标题的 HTML 列表时,哪些做法正确?
编程题:实现一个 HTML 列表模板,数据为空时显示“暂无文章”,标题必须按普通文本输出。
综合练习:从 JSON 请求到安全 HTML
最后把整条链路接起来。设想一个小型接口接收 JSON 文章列表,按分类统计数量,再渲染 HTML。你需要同时做出这些判断:
- 请求体用结构体解码,字段标签明确外部名称;
- 严格接口拒绝未知字段,并验证标题、URL 与分类;
- 列表用切片保存,分类计数用 map;
- 稳定输出时先排序分类键;
- HTML 使用
html/template,用户标题保持普通string; - 任何解码、写入或模板执行错误都不能丢弃。
综合判断
综合-1
下面哪些现象说明代码可能跨越了不安全的数据边界?
综合-2
切片删除后若元素含指针,应清理失效的 ____,避免隐藏引用延长对象寿命。
综合编程题
实现 Render(r io.Reader, w io.Writer) error:输入格式为 {"articles":[...]},拒绝未知字段,按 Category、Title 排序,并输出安全 HTML。每篇文章包含 title、url、category。
最后的自检清单
综合-3
如果一个程序能编译并输出看似正确的结果,就可以依赖 map 当前遍历顺序和 append 当前扩容倍数。
写完复合类型相关代码,可以顺手核对下面几项:固定长度是否真的属于领域约束;切片是否被意外共享或长期留住大数组;append 和删除函数的返回值是否保存;map 查询是否需要逗号 ok;结构体复制是否包含需要深复制的字段;JSON 是否检查错误并验证业务输入;HTML 是否使用 html/template 且没有把不可信字符串标成可信类型。把这些边界守住,复合类型就会从“容易踩坑的语法”变成一套可靠的数据建模工具。